Huggingface Course을 공부해보며 추후에 프로젝트에서 많이 활용될 Huggingface 활용법에 대해 알아보려 한다.
0. Setup
"We’ll cover two ways of setting up your working environment, using a Colab notebook or a Python virtual environment. Feel free to choose the one that resonates with you the most. For beginners, we strongly recommend that you get started by using a Colab notebook."
tutorial의 느낌이 강하기 때문에 Colab에서 진행되지만 현재 V100 GPU의 서버를 제공받고 있으므로 서버에서 conda 가상환경을 통해 실습해보도록 하겠다.
conda create -n hugginface
pip install transformers
pip install transformers[sentencepiece]transformers[sentencepiece]는 dev 버전으로 더 추천하는 버전이다.
1. Transformer Model
Introduction
This course will teach you about natural language processing (NLP) using libraries from the Hugging Face ecosystem — 🤗 Transformers, 🤗 Datasets, 🤗 Tokenizers, and 🤗 Accelerate — as well as the Hugging Face Hub.
현재까지 나온 Course는 Chapter 1~4까지로, 허깅페이스 허브에서 어떻게 모델을 사용하고 미세조정, 공유 등을 하는지에 대해 알게되고 친숙해질 것이라고 말한다.
앞서 글들에서 사실 NLP 이론과 관련하여 많이 다뤘었기 때문에, 이론적인 부분은 간략하게만 짚고 넘어가도록 하겠다.
NLP Tasks
- Classifying whole sentences
- sentiment, grammar correctness - Classifying each word in a sentence
- Pos tagging, name entities - Generating text content
- filling in the blanks in a text with masked words - Extracting an answer from a text
- QA - Generating a new sentence from an input text
- Translation, Summary
Transformers, what can they do?
아래는 NLP 분야에서 허깅페이스를 사용하는 대표적인 Company/organization이다.

The most basic object in the 🤗 Transformers library is the pipeline. It connects a model with its necessary preprocessing and postprocessing steps, allowing us to directly input any text and get an intelligible answer. The model is downloaded and cached when you create the classifier object
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")pipeline을 거치며 text는 3가지 단계를 지나게 된다.
1. The text is preprocessed into a format the model can understand.
2. The preprocessed inputs are passed to the model.
3. The predictions of the model are post-processed, so you can make sense of them.
현재 pipeline에서 가능한 목록
- feature-extraction (get the vector representation of a text)
- fill-mask
- ner (named entity recognition)
- question-answering
- sentiment-analysis
- summarization
- text-generation
- translation
- zero-shot-classification
위의 목록 중 몇 가지 예시를 들어 보겠다.
Zero-shot classification
This pipeline is called zero-shot because you don’t need to fine-tune the model on your data to use it. It can directly return probability scores for any list of labels you want.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
){'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}Text Generation
The main idea here is that you provide a prompt and the model will auto-complete it by generating the remaining text. Also, you can choose a particular model from the hub and use it in a pipeline.
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
'move your mental and physical capabilities to your advantage.'},
{'generated_text': 'In this course, we will teach you how to become an expert and '
'practice realtime, and with a hands on experience on both real '
'time and real'}]Mask filling
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)The top_k argument controls how many possibilities you want to be displayed. We used \ token but other mask-filling models might have different mask tokens, so it’s always good to verify the proper mask word when exploring other models.
How do Transformers work?
Here are some reference points in the (short) history of Transformer models
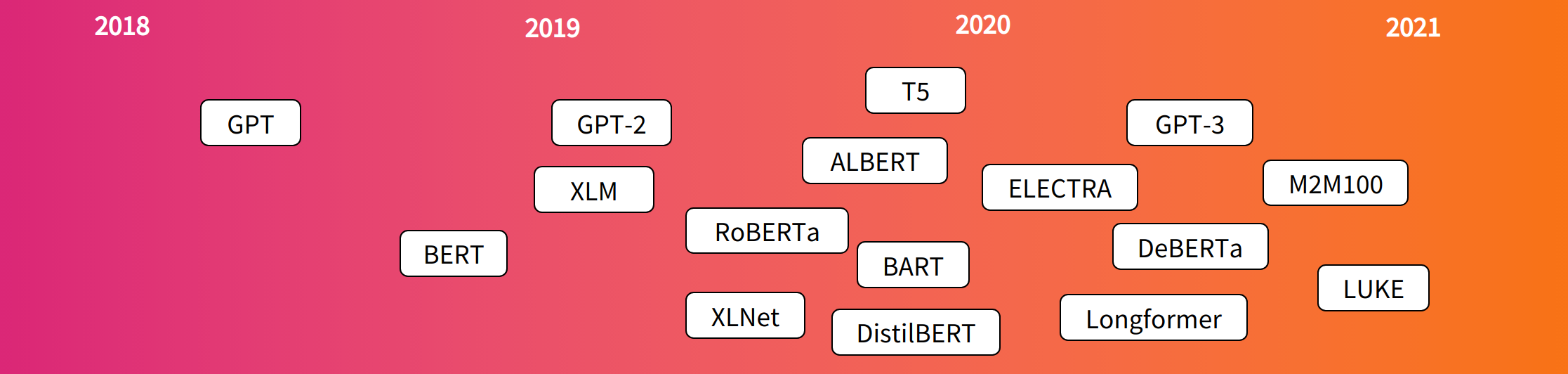
A lot of models' been released, but they can be grouped in three categories.
- GPT-like (also called auto-regressive Transformer models)
- BERT-like (also called auto-encoding Transformer models)
- BART/T5-like (also called sequence-to-sequence Transformer models)
Transformers are language models
All the Transformer models mentioned above (GPT, BERT, BART, T5, etc.) have been trained as language models. This means they have been trained on large amounts of raw text in a self-supervised fashion. Self-supervised learning is a type of training in which the objective is automatically computed from the inputs of the model.
이러한 모델들은 학습된 언어에 대한 통계적인 이해를 가지고 있기 때문에 Specific한 task에는 powerful하지 못한 모습을 보였다. 그래서 등장한 것이 바로 Transfer Learning이다. 이 과정에서 주어진 pretrained 모델에 supervised way로 fine tuning하게 된다.
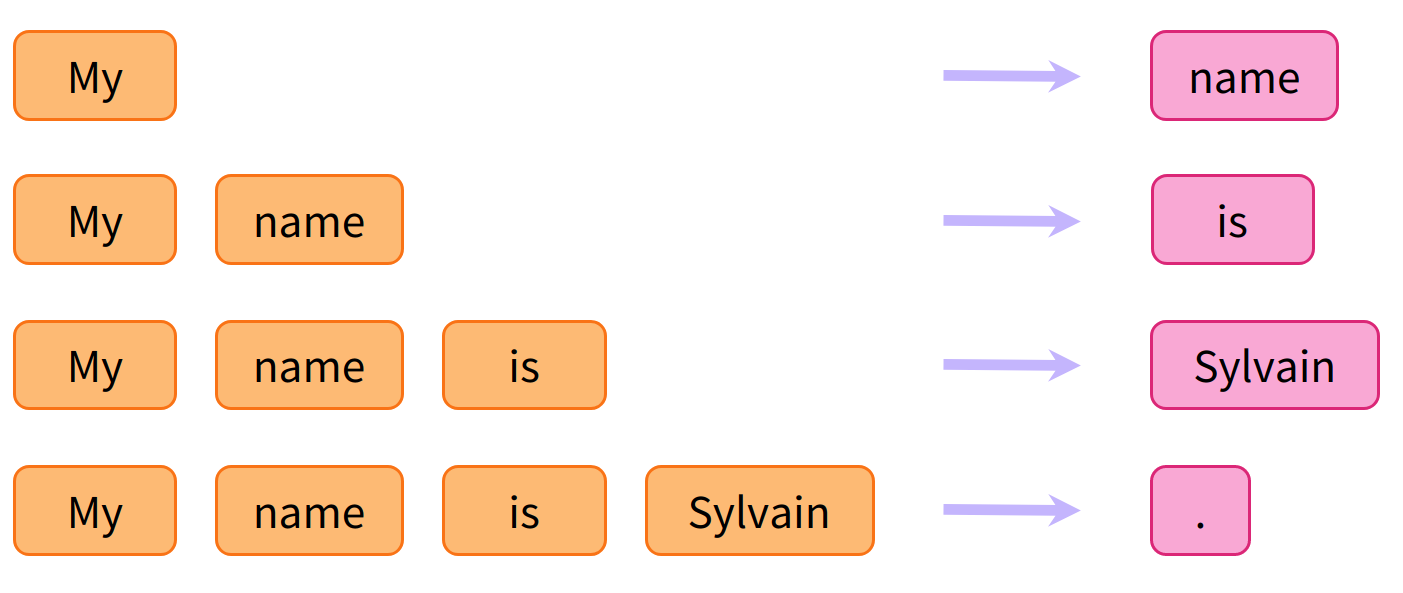
- Causal language modeling
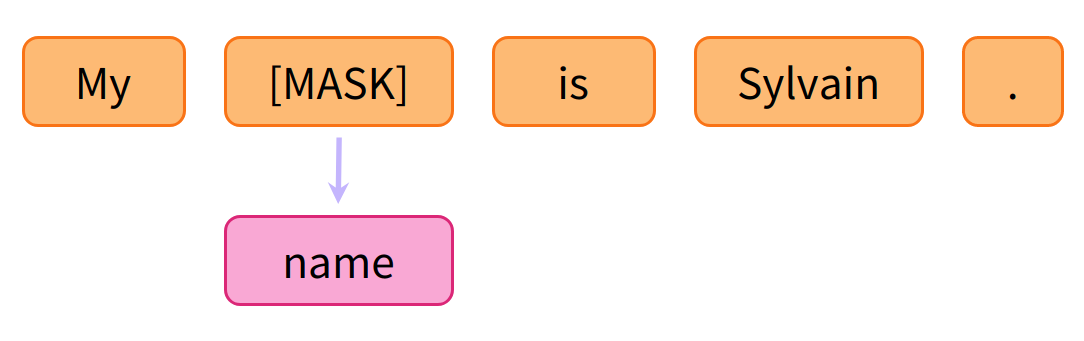
- Masked language modeling
Transformer is big model
This is why sharing language models is paramount: sharing the trained weights and building on top of already trained weights reduces the overall compute cost and carbon footprint of the community
Encoder - Decoder
- Encoder-only models: Good for tasks that require understanding of the input, such as sentence classification and named entity recognition.
- Decoder-only models: Good for generative tasks such as text generation.
- Encoder-decoder models or sequence-to-sequence models: Good for generative tasks that require an input, such as translation or summarization.
Bias and Limitation
from transformers import pipeline
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK].")
print([r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK].")
print([r["token_str"] for r in result])['lawyer', 'carpenter', 'doctor', 'waiter', 'mechanic']
['nurse', 'waitress', 'teacher', 'maid', 'prostitute']When you use these tools, you therefore need to keep in the back of your mind that the original model you are using could very easily generate sexist, racist, or homophobic content. Fine-tuning the model on your data won’t make this intrinsic bias disappear.
Summary
| Model | Examples | Tasks |
|---|---|---|
| Encoder | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | Sentence classification, named entity recognition, extractive question answering |
| Decoder | CTRL, GPT, GPT-2, Transformer XL | Text generation |
| Encoder-Decoder | BART, T5, Marian, mBART | Summarization, translation, generative question answering |
