다양한 내용 정리 링크
-
딥 러닝을 이용한 자연어 처리 입문
-
kcBERT, KcBERT Github(with Colab)
- NSMC와 같은 댓글형 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장한다.
- KcBERT는 위와 같은 특성의 데이터셋에 적용하기 위해, 네이버 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 BERT모델을 처음부터 학습한 Pretrained BERT 모델이다.
-
- Bert 구조에 대해 깔끔하게 잘 정리되어 있다.
"BERT 톺아보기 글 中"
어느날 SQuAD 리더보드에 낯선 모델이 등장했다. BERT라는 이름의 모델은 싱글 모델로도 지금껏 state-of-the-art 였던 앙상블 모델을 가볍게 누르며 1위를 차지했다. 마치 ELMo를 의식한 듯한 BERT라는 생소한 이름 그리고 구글에 모두가 궁금해하고 있을때, BERT의 등장을 알리는 논문이 공개됐다.
- Bert 구조에 대해 깔끔하게 잘 정리되어 있다.
-
- 처음에는 ALBERT의 Positional Embedding MF에 대해 알아보려고 찾은 블로그지만, 시각적으로 설명이 잘 되어있다.
-
- LightConv, DynamicConv 와 비교하여 간략히 정리해놓은 글이다.
- PAY LESS ATTENTION
WITH LIGHTWEIGHT AND DYNAMIC CONVOLUTIONS 논문 - DynamicConv 논문
Conv in NLP
“Pay Less Attention with Lightweight and Dynamic Convolutions”은 facebook AI research 팀의 논문으로 ICLR 2019년에 공개되었다. 이 논문에서는 셀프 어텐션의 단점으로 큰 연산 수를 지적하며 더 효율적인 어텐션인 lightweight 컨볼루션과 dynamic 컨볼루션을 제안했다. 저자는 WMT’14 영어-독일어 데이터 셋에서 dynamic 컨볼루션을 사용하여 그 당시 SOTA 기록인 29.7 BLEU를 달성함으로써 셀프 어텐션 없이도 훌륭한 성능의 모델을 만들 수 있음을 보여준다.
논문에서는 셀프 어텐션이 다음과 같은 문제점을 가지고 있음을 지적한다.
- 장기 의존성을 모델링하는 능력이 확실하지 않다.
- 필요한 연산 수가 시퀀스 길이의 제곱에 비례하기 때문에 컨텍스트 사이즈가 큰 경우에 사용하기 어렵다.
- 실제로 긴 길이의 시퀀스에 대해서는 계층 구조를 적용해야 한다.
저자는 이러한 문제점을 해결하기 위해 연산 수가 시퀀스 길이에 비례하지만 성능은 셀프 어텐션과 비슷하거나 나은 lightweight 컨볼루션, dynamic 컨볼루션을 제시한다. 두 컨볼루션에 대해 알아보기 이전에 depthwise 컨볼루션에 대해 먼저 알아보자.
normal 1D Conv
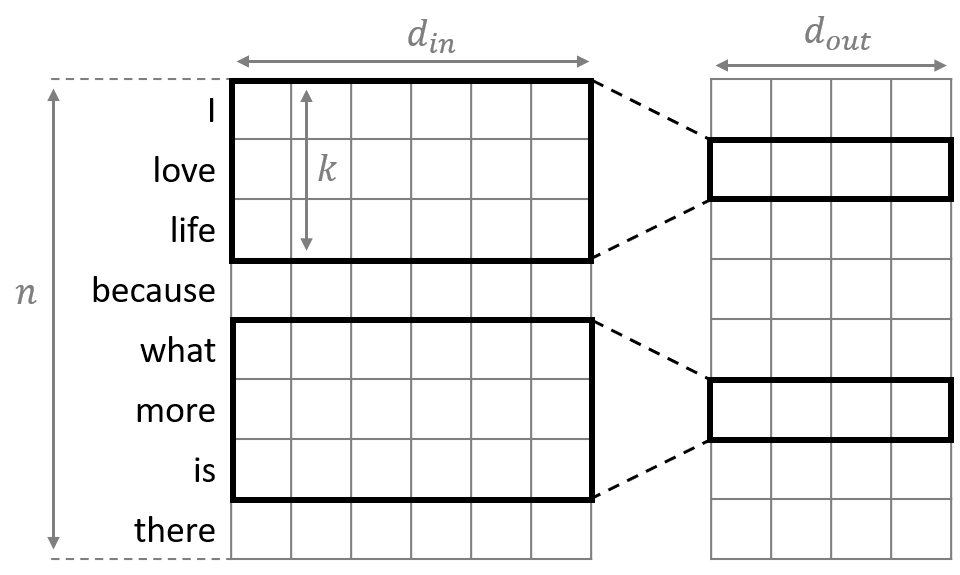
“Convolutional Neural Networks for Sentence Classification ; Yoon Kim”에서 콘볼루션 뉴럴 네트워크를 워드 벡터들에 적용하는 방법을 소개하고 있다. 일반적인 컨볼루션은 입력 벡터와 출력 벡터의 채널 수가 각각 이고 커널의 너비가 일 때, 총 개의 파라미터가 필요하다.
Depthwise Conv
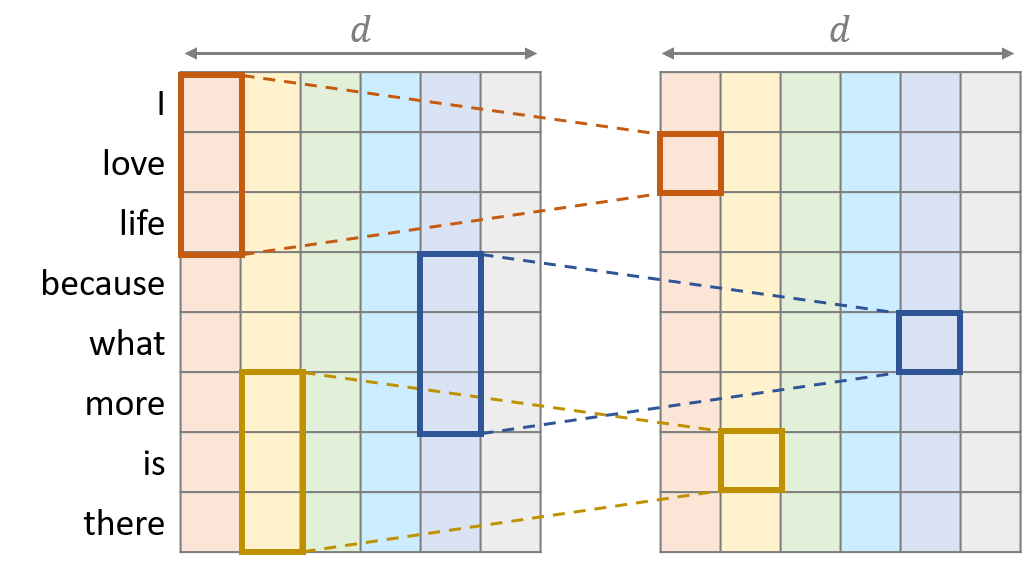
Depthwise 컨볼루션은 “Xception: Deep Learning with Depthwise Separable Convolutions”에서 연산량을 줄이기 위해 소개된 컨볼루션으로 각 채널마다 일반 컨볼루션을 독립적으로 적용한다. 컨볼루션이 같은 채널 내에 서만 계산되어야 하므로 입력 시퀀스의 채널 수와 출력 시퀀스의 채널 수는 로 일치하게 된다. 같은 입출력 시퀀스에 대해 일반 컨볼루션을 적용하기 위해서 개의 파라미터가 필요한 반면 Depthwise 컨볼루션은 더 적은 개의 파라미터를 사용한다.
LightWeight Conv
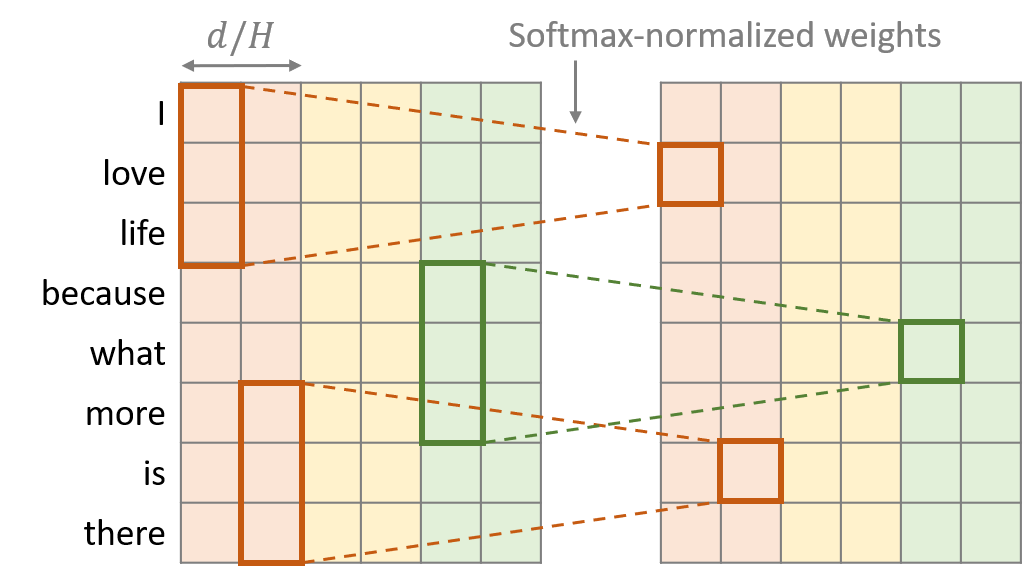
Lightweight 컨볼루션은 depthwise 컨볼루션과 비슷한 구조를 가졌지만 두 가지의 특징이 추가되었다. 첫 번째는 연속된 개의 채널마다 커널의 가중치를 공유했다는 점이다. 두 번째는 가중치를 타임 스탭방향으로 softmax-normalization을 했다는 점이다.
Dynamic Conv
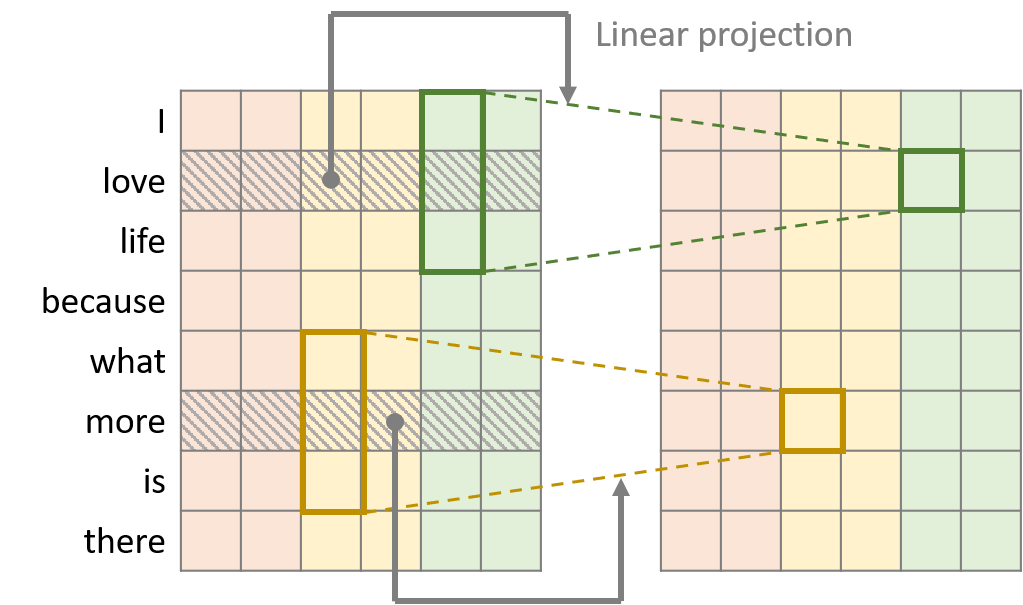
Dynamic 컨볼루션은 Lightweight 컨볼루션에서 커널을 타임 스탭에 의존하게 만든 컨볼루션입니다. 이 때, 커널 중앙에 위치한 워드 벡터를 선형 모듈을 통해 커널의 가중치를 형성한다. 예를 들어, 그림에서는 초록색 커널의 중앙에 love라는 단어가 위치해 있기 때문에 love의 워드 벡터를 가지고 커널의 가중치를 생성한 뒤, lightweight 컨볼루션과 같은 연산을 수행하게 된다.
Lightweight, Dynamic
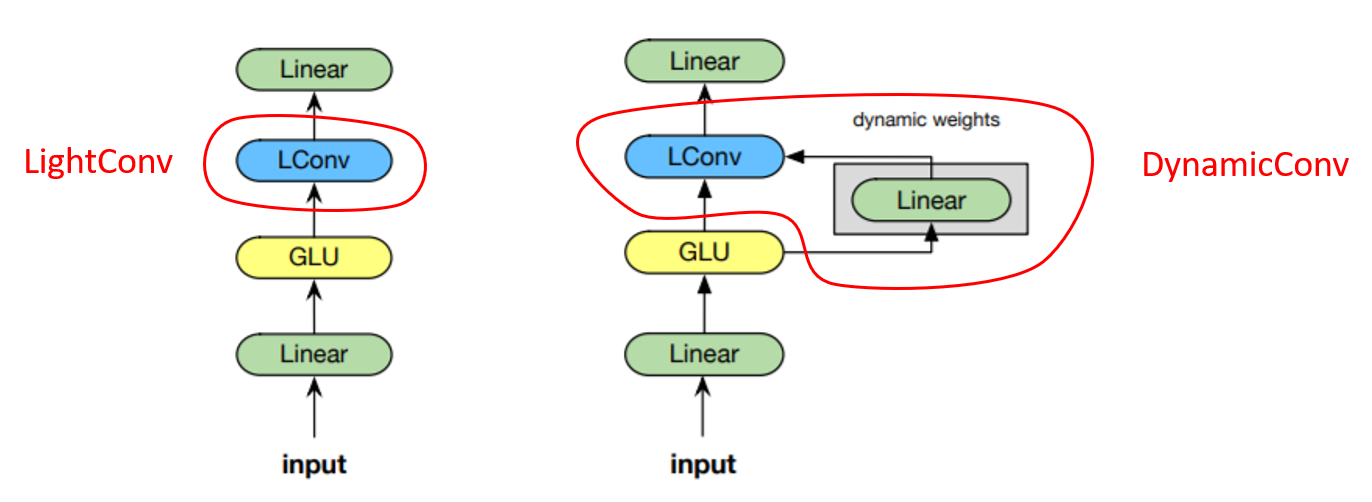
저자는 셀프 어텐션을 대체하기 위해 앞에서 설명한 Lightweight 컨볼루션 혹은 Dynamic 컨볼루션을 포함하여 모듈을 구성하였다. 왼쪽 그림은 lightweight 컨볼루션을 포함한 모듈의 구조를 나타낸다. 먼저, 입력 시퀀스가 들어오면 선형 모듈로 차원을 에서 로 늘려준 뒤, GLU 활성 함수, LightConv와 선형 모듈을 차례대로 적용한다. 오른쪽 그림은 dynamic 컨볼루션을 포함한 모듈의 구조를 나타낸다. 오른쪽 모듈은 왼쪽 모듈에서 LightConv 대신 DynamicConv를 사용했다는 점 이외에는 모두 동일한 구조를 갖고 있다.
GLU(Gated Linear Unit)
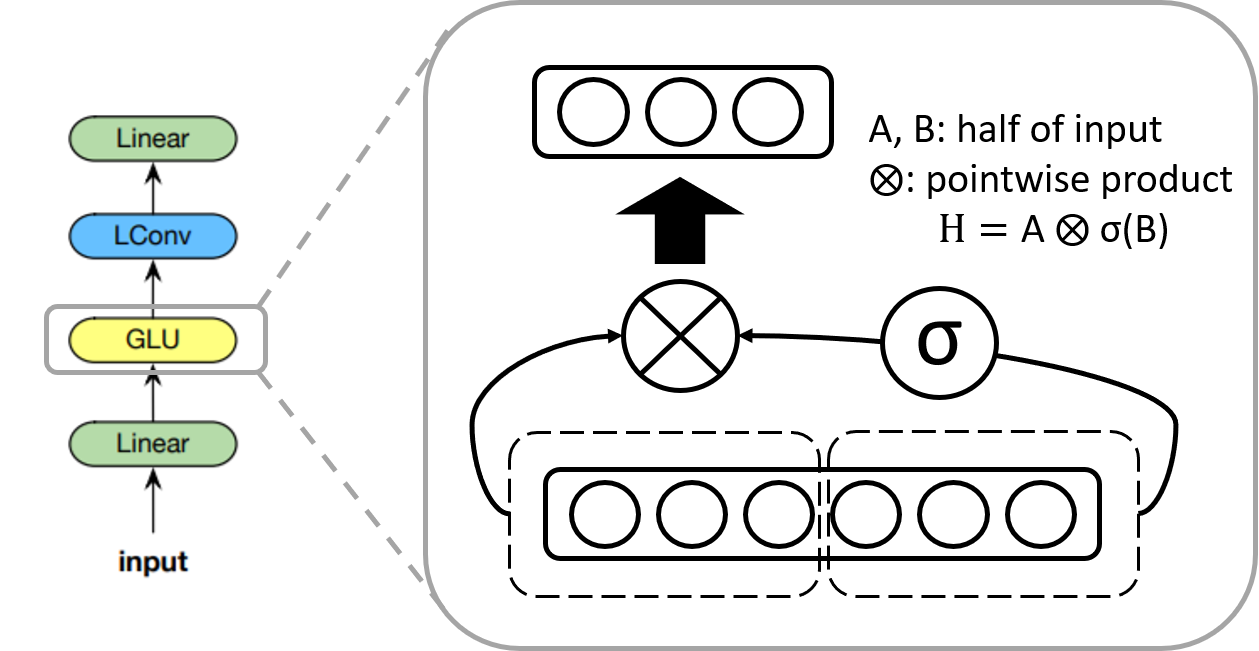
Language Modeling with Gated Convolutional Networks에서 소개된 활성화함수로, 입력의 절반에 시그모이드 함수를 취한 것과 나머지 입력의 절반을 가지고 pointwise 곱을 계산하는 형태이다. 따라서 출력 값의 차원은 입력 값의 차원의 절반이 된다. GLU는 비선형 기능을 유지하면서 선형 연산을 통해 vanishing gradient 문제를 완화한다.
Depthwise Seperable
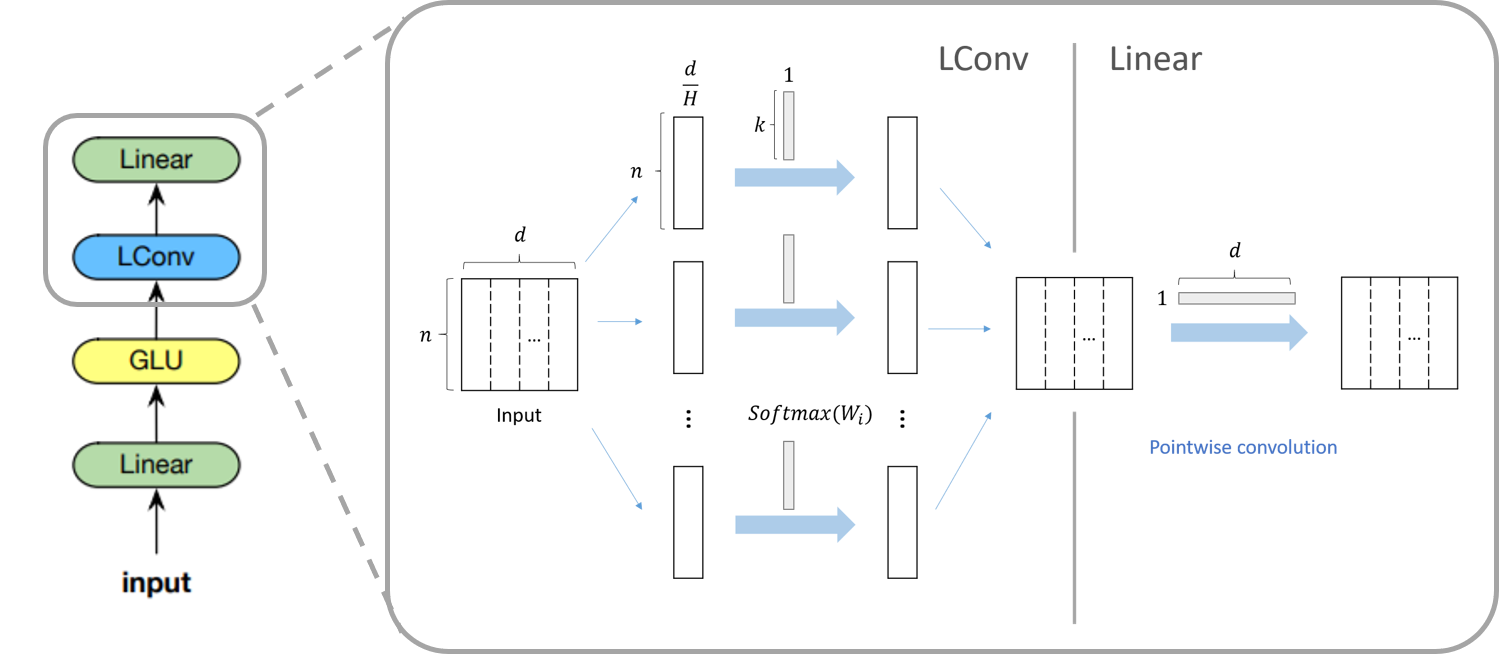
저자는 lightweight 컨볼루션이 depthwise separable하다고 언급했다. Depthwise separable 컨볼루션은 depthwise 컨볼루션과 pointwise 컨볼루션을 같이 사용하는 연산으로, Xception에서 기존의 컨볼루션을 이렇게 두 연산으로 나누면 더 적은 연산과 파라매터를 사용함에도 불구하고 좋은 성능을 낼 수 있음을 보였다. Pay less attention 논문에서는 어떤 부분이 depthwise separable한지 명확히 나오지 않았지만 모듈의 마지막 두 층의 구조를 가리킨 것으로 보인다. 실제로 LConv에 해당하는 부분은 depthwise 컨볼루션과 유사한 형태를 띄고 있고 그 뒤에 따라오는 선형 모듈은 pointwise 컨볼루션으로 생각할 수 있다. 결과적으로 이 구조는 효율적으로 컨볼루션 연산을 수행할 수 있게 한다.
Architecture
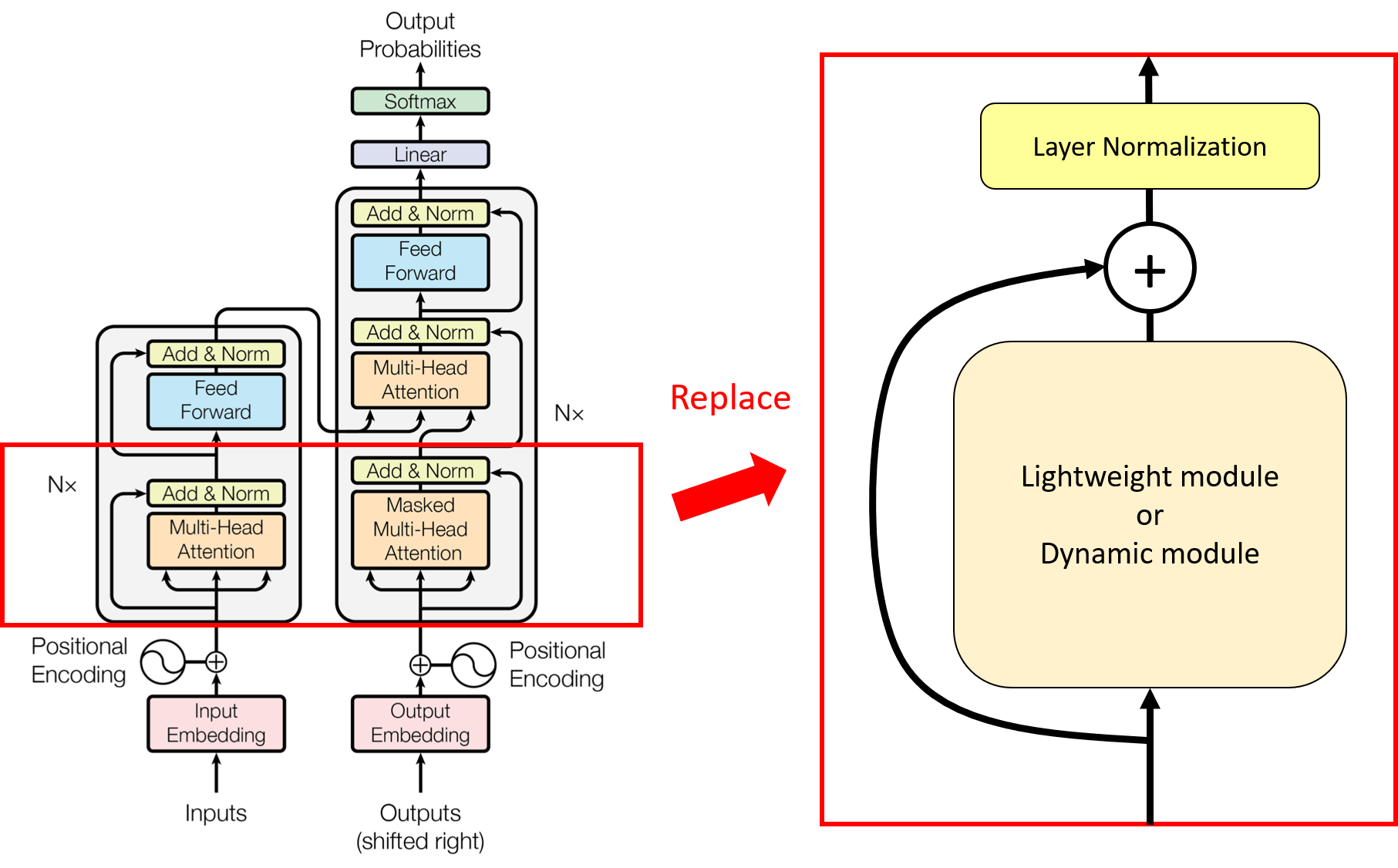
저자는 트랜스포머 아키텍쳐와 유사한 형태로 자신의 모델 아키텍쳐를 구현하였다. 셀프 어텐션 베이스라인으로 fairseq에서 재구현한 트랜스포머 아키텍쳐를 사용하고 셀프 어텐션 부분을 lightweight, dynamic 모듈로 바꿔서 제시한 모듈 성능을 테스트하였다.
선택과제 2번
Fairseq을 사용해서 BLEU score 25 이상이 목표였으나 Epoch만 늘려도 충분히 좋은 값이 나왔다. Model Architecture를 Light Weight Conv로 바꾸고 Epoch을 7로 올린 결과 BLEU Score 30.13이 나왔다.
