RNN
이전 시점의 hidden state와 현재 시점의 입력 데이터로 현재 시점의 출력 데이터를 만들어내는 순환적인 구조의 Neural Network이다. 매 타임 스텝에서 같은 W를 공유하는 것이 특징.
How to calculate the hidden state of RNNs
• We can process a sequence of vectors by applying a recurrence formula at every time
step
• : old hidden-state vector
• : input vector at some time step
• : new hidden-state vector
• : RNN function with parameters W
• : output vector at time step t
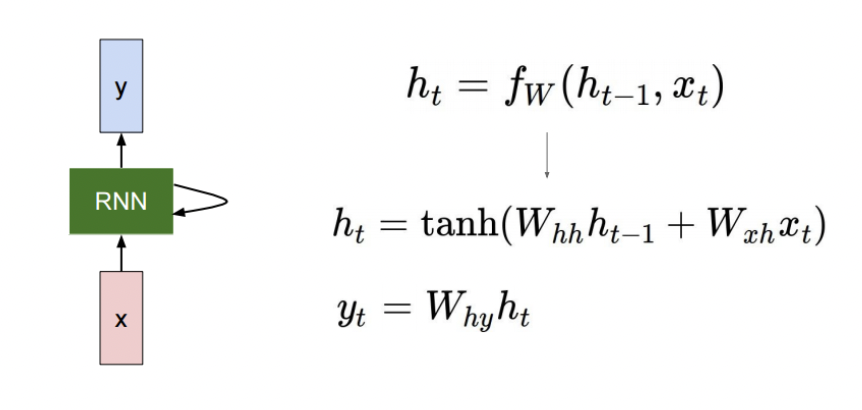
: 를 로 변환
: 를 로 변환
: 를 로 변환
Types of RNN
- One-to-one
- Standard Neural Network- Not Sequence Data
- One-to-Many
- Image Captioning- 입력은 time step이 아니지만 이미지를 입력으로 받아서 텍스트 데이터 출력
- 매 타임 스텝에 0행렬을 추가
- Many-to-one
- Sentiment Classification- sequence data를 받아서 마지막에 나온 결과값을 통해 긍정/부정 등의 분류 진행
- Many-to-many
- Machine Translation- encoding, decoding의 형태
- 입력이 끝나고 나면 출력 시퀀스 데이터 시작
- Many-to-many
- Video Classification on Frame Level
- 딜레이가 없는 입력이 들어올 때마다 출력하는 형태
Character-level Language Model
언어 모델이라는 것은 현재 주어진 문자열이나 단어를 보고 다음 단어를 예측하는 모델이다. 따라서 character-level에서 진행할 수 있다.
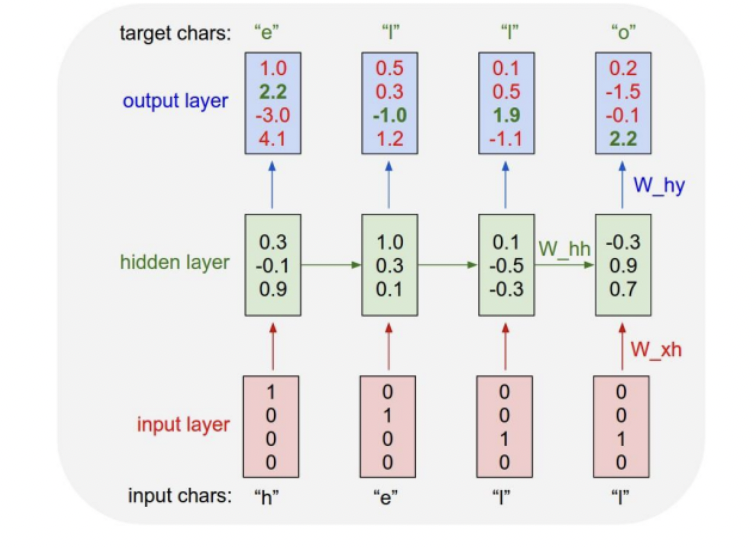
참고로, 첫 시점의 이전 hidden state인 는 처음에 0 벡터로 주어진다.
BPTT
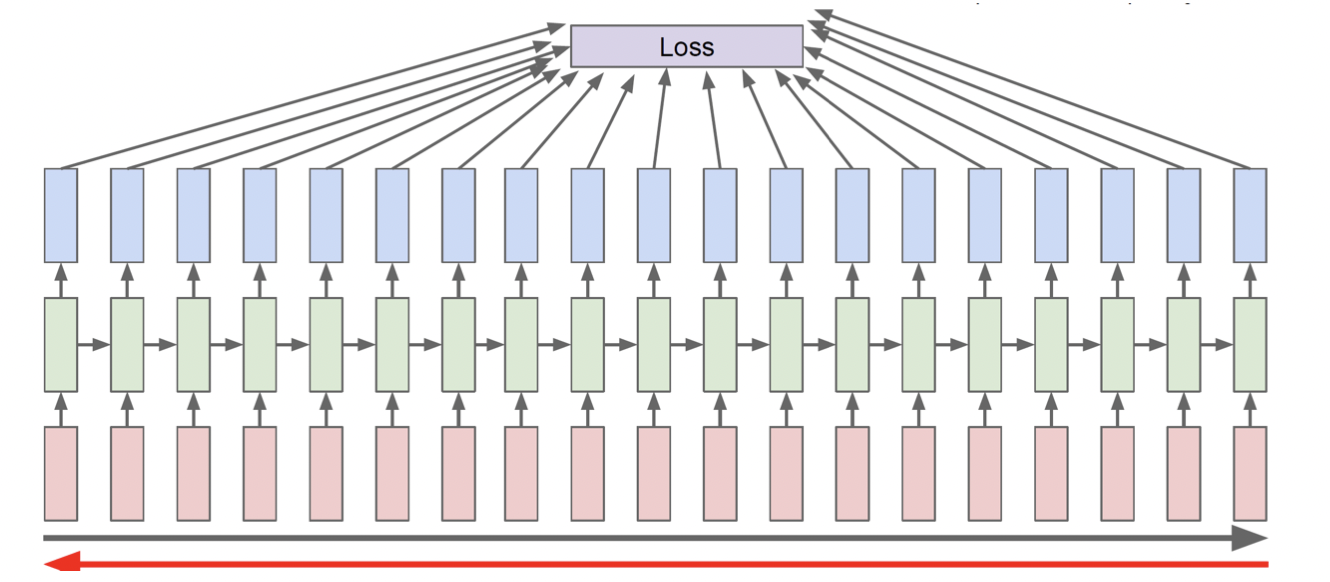
RNN's Problem
Multiplying the same matrix at each time step during backpropagation causes gradient vanishing or exploding
LSTM
Long Short Term Memory
LSTM 설명
Gradient문제를 해결하고 먼 time step의 정보도 기억할 수 있게끔 만들어졌다.
기존의 Hidden state를 단기 기억이라고 표현한다면 이 기억을 길게 해준다는 의미로 Long Short Term Memory라고 부른다.
LSTM은 이전 시점에서 Hidden state와 Cell state두 개의 값을 넘겨받는다.
Cell state가 Hidden state보다 좀 더 완성되어있는 정보를 담고 있는 벡터이다. Hidden state 벡터는 Cell state를 한 번 더 가공한 정보를 담고 있는 벡터이고, 해당 time step에서 output vector로 활용된다.
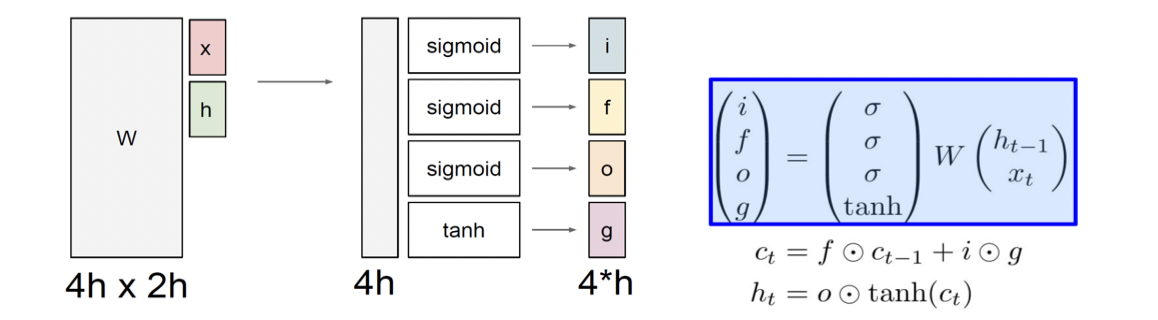
Forget Gate
Input Gate
Output Gate
가 가진 많은 정보를 filtering하는 느낌으로 생각할 수 있다.
ex) 따옴표가 열린 문장에서 Cell state에는 따옴표가 열려있는 정보, hidden state에는 각 단어의 정보가 포함되었다고 볼 수 있다.
이 때, 는 output layer의 입력 값이다.
GRU
LSTM에서 Cell state와 Hidden state를 일원화한 형태이다.
특히, LSTM이 Forget gate와 Input gate로 나뉘어져 있던 것을 의 형태로 나누어서 계산하는 것이 특징이다.
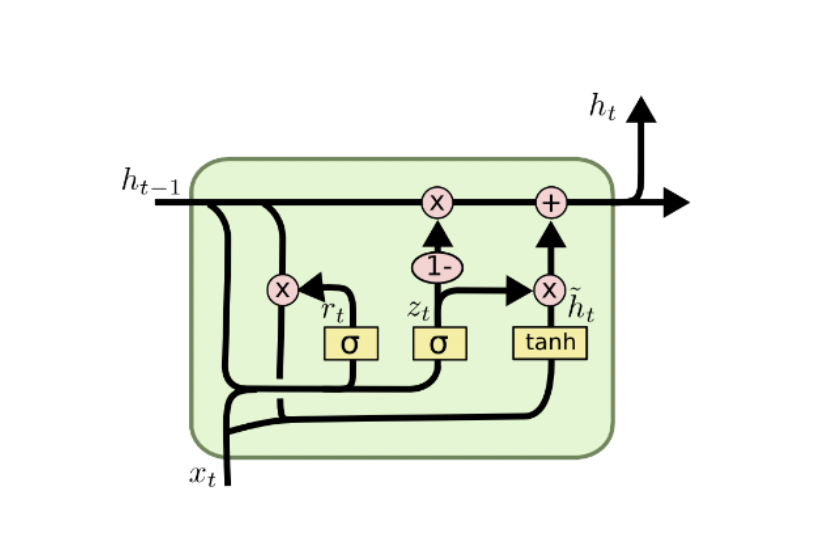
c.f) in LSTM
즉, 가중 평균의 형태로 를 더해주는 형식이다.
더 알아볼 것
Teacher Forcing의 장/단점 및 특징을 알아보자.
https://simonjisu.github.io/nlp/2018/07/05/packedsequence.html
Further Reading
RNN/LSTM/GRU 기반의 Language Model에서 초반 time step의 정보를 전달하기 어려운 점을 완화할 수 있는 방법
Bidirectional, Attention
