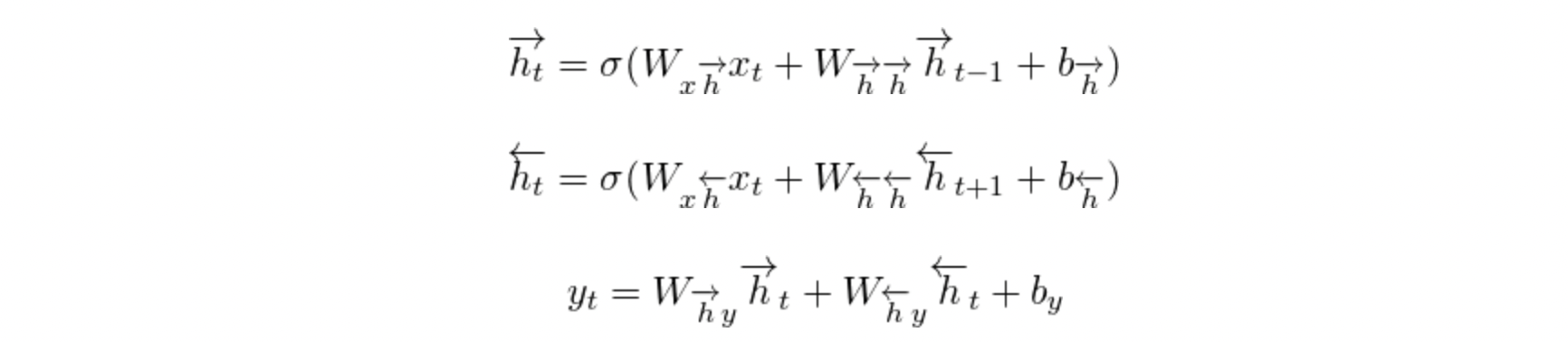Negative Sampling
Word2Vec의 출력층에서는 소프트맥스 함수를 지난 단어 집합 크기의 벡터와 실제값인 원-핫 벡터와의 오차를 구하고 이로부터 임베딩 테이블에 있는 모든 단어에 대한 임베딩 벡터 값을 업데이트한다. 만약 단어 집합의 크기가 수만 이상에 달한다면 이 작업은 굉장히 무거운 작업이므로, Word2Vec은 꽤나 학습하기에 무거운 모델이 된다.
Word2Vec은 역전파 과정에서 모든 단어의 임베딩 벡터값의 업데이트를 수행하지만, 만약 현재 집중하고 있는 중심 단어, 주변 단어들과 별 연관 관계가 없는 단어의 임베딩 벡터값까지 업데이트하는 것은 비효율적이다.
네거티브 샘플링은 Word2Vec이 학습 과정에서 전체 단어 집합이 아니라 일부 단어 집합에만 집중할 수 있도록 하는 방법이다. 아래의 Skip-gram 예시를 보자.
Skip-Gram with Negative Sampling(SGNS)
The fat cat sat on the mat
cat이라는 중심 단어를 통해 주변 단어를 예측하는 것이 Skip-Gram이다. 이 때, SGNS는 접근법이 다소 다르다. cat, sat이라는 두 단어를 넣었을 때 두 단어가 이웃하는 관계인지에 대한 확률값을 출력하는 형태가 된다.

따라서 SGNS를 수행하기 위해서는 아래 그림과 같이 변환된 형태의 데이터셋이 필요하게 된다.
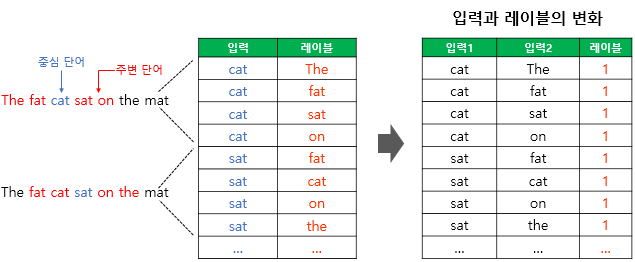
그 뒤, 위의 데이터셋에 label이 0인 무작위 단어를 추가하게 된다. 이 때, 무작위로 단어를 뽑는 확률 P는 아래와 같다.
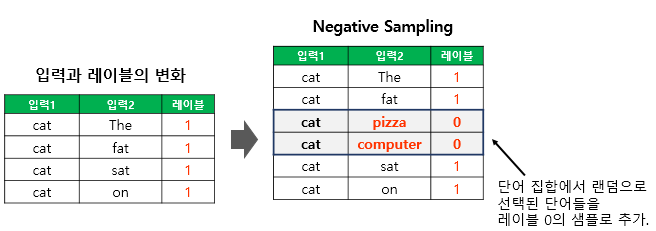
그 다음, 기존의 W2V의 형태와 같이 두 개의 임베딩 레이어를 준비하고, 해당 데이터셋에 맞게 내적 후 실제 label과의 차이를 줄이도록 학습한다.
Bidirectional RNN(BRNN)
Bidirectional Recurrent Neural Networks(BRNNs)는 과거의 상태뿐만 아니라, 미래의 상태까지 고려하는 확장된 Recurrent Neural Networks(RNNs) 형태이다.
기존의 Recurrent Neural Networks(RNNs)는 일반 Neural Networks에 비교해서, 데이터의 이전 상태 정보를 “메모리(Memory)” 형태로 저장할수 있다는 장점이 있었다. 하지만 시계열 데이터의 현재 시간 이전 정보뿐만 아니라, 이후 정보까지 저장해서 활용할 수 있다면 더 좋은 성능을 기대할 수 있다.
예를 들어
라는 문장에서 OO에 들어갈 단어를 예측하고자 한다면, 우리는 앞의 정보인 “푸른”, “하늘”이라는 정보를 가지고 OO에 들어갈 단어가 “구름”이라고 예측할 수도 있지만, 뒤의 정보인 “떠있다.”라는 단어까지 함께 고려하면 더 높은 확률로 정답이 “구름”이라는 것을 예측할 수 있을 것이다.
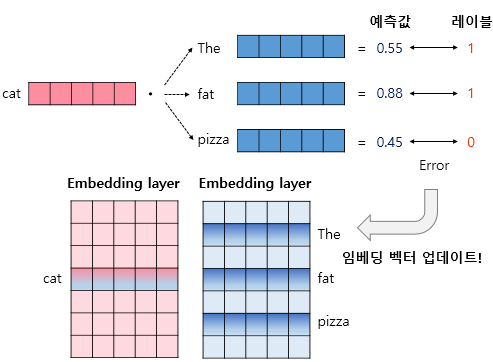
Bidirectional Recurrent Neural Networks(BRNNs)을 이용하면, 이렇게 이전 정보와 이후 정보를 모두 저장할 수 있다. BRNNs 구체적인 architecture는 아래와 같다.(unfolded) 형태이다.
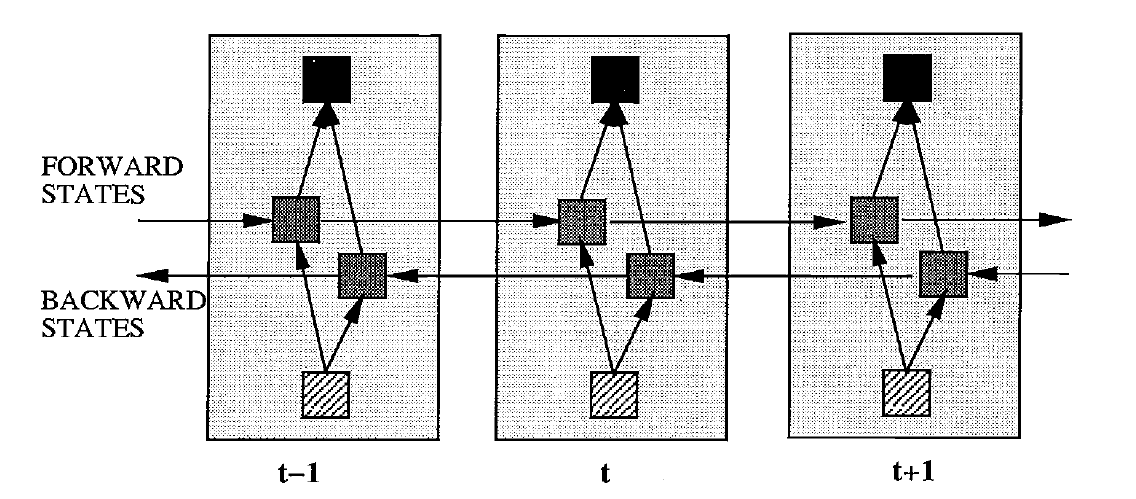
즉, 각 타임 스텝에서 Layer는 2개씩 존재하게 된다. 각 Forward states와 Backward states는 서로 연결되어 있지 않고 별개의 레이어로 존재하지만, Output에는 아래와 같이 두 정보를 모두 활용한다.