1. Seq2Seq Model
Many-to-Many RNN model
Encoder와 Decoder는 서로 Share하지 않는 모델들이다.
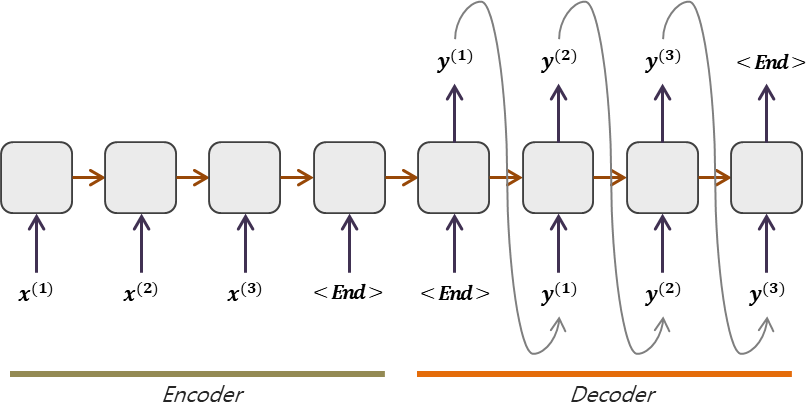
Encoder의 마지막 셀에서 출력한 Hidden state는 decoder의 h0가 된다.
Decoder에서 문장의 시작 입력데이터는 START, 또는 SOS라는 토큰을 사전에 등록하여 사용하고, 문장의 끝은 END 또는 EOS 토큰을 사용한다.
2. Seq2Seq Model with Attention
기존의 Seq2Seq의 구조에서는 고정된 Hidden Dimension을 가지고 주어진 문장의 Context 정보를 모두 담아야한다. 이는 LSTM을 사용한다 하더라도 아주 먼 시점의 정보는 소실될 수밖에 없다.
이는 처음에 주어가 나오는 형태의 경우 첫 시작부터 틀릴 가능성이 높다. 연구자들은 이를 해결하기 위한 하나의 트릭으로 처음부터 문장의 순서를 거꾸로 학습시키는 방법을 채택하기도 했다.
그럼 Attention의 구조를 간략하게 살펴보면 다음과 같다.
먼저, Encoder의 각 타임 스텝마다 출력되는 Hidden State를 활용한다. 각각의 정보는 각 시점마다의 주요 정보를 담고 있을 것이다. 여기서 나온 각 Hidden state를 모아서 Decoder에서 선별적으로 정보를 추가적으로 활용하는 형태이다.
구글에서 Seq2Seq, Attention에 대해 설명해놓은 자료를 참고하자.
그럼 이제부터 Seq2Seq with Attention의 구조를 자세히 살펴보겠다.
-
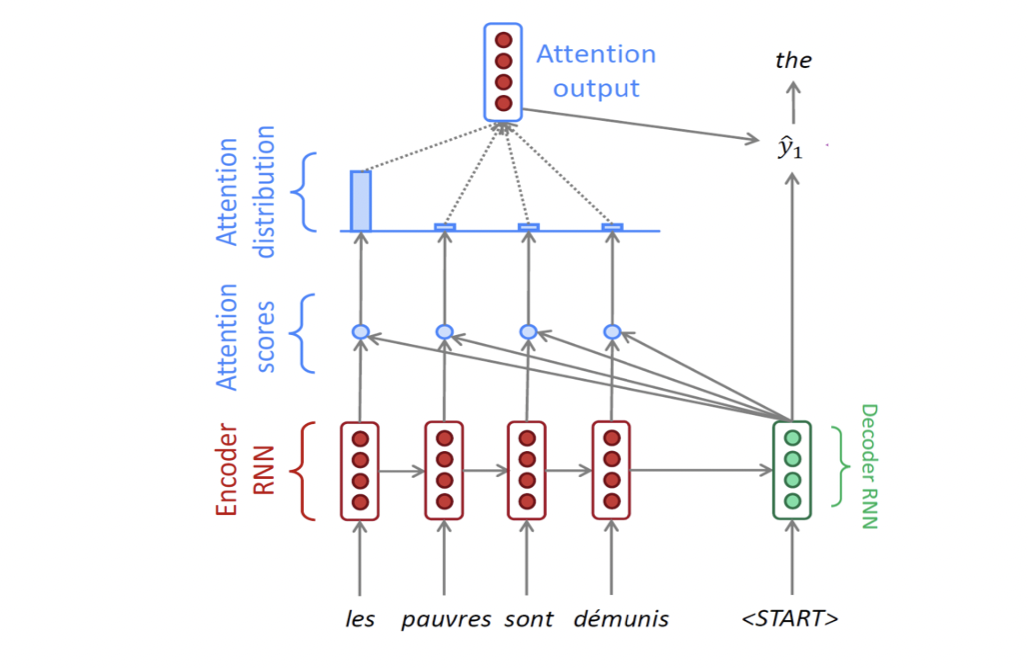
가장 먼저 Encoder에서 순서대로 진행해서 마지막 출력 Hidden State H0를 활용, Decoder에서 input token과 함께 decoder의 첫번째 Hidden State 값이 나오게 된다.
-
여기서 나온 Decoder의 Hidden State와 Encoder의 각 시점에서 나온 Hidden State를 내적하게 되는데, 이를 Attention Score라고 한다. 그 뒤 Softmax를 취해서 나온 확률값을 가지고 각 Encoder Hidden State의 가중 평균을 구할 수 있고, 이를 Attention Output, Context Vector라고 부른다.
-
Attention Output을 1번에서 구한 Decoder의 Hidden State와 Concatnate하여 나온 값을 Decoder의 출력으로 만든다. 이는 두번 째 Decoder step의 입력 벡터가 된다.
-
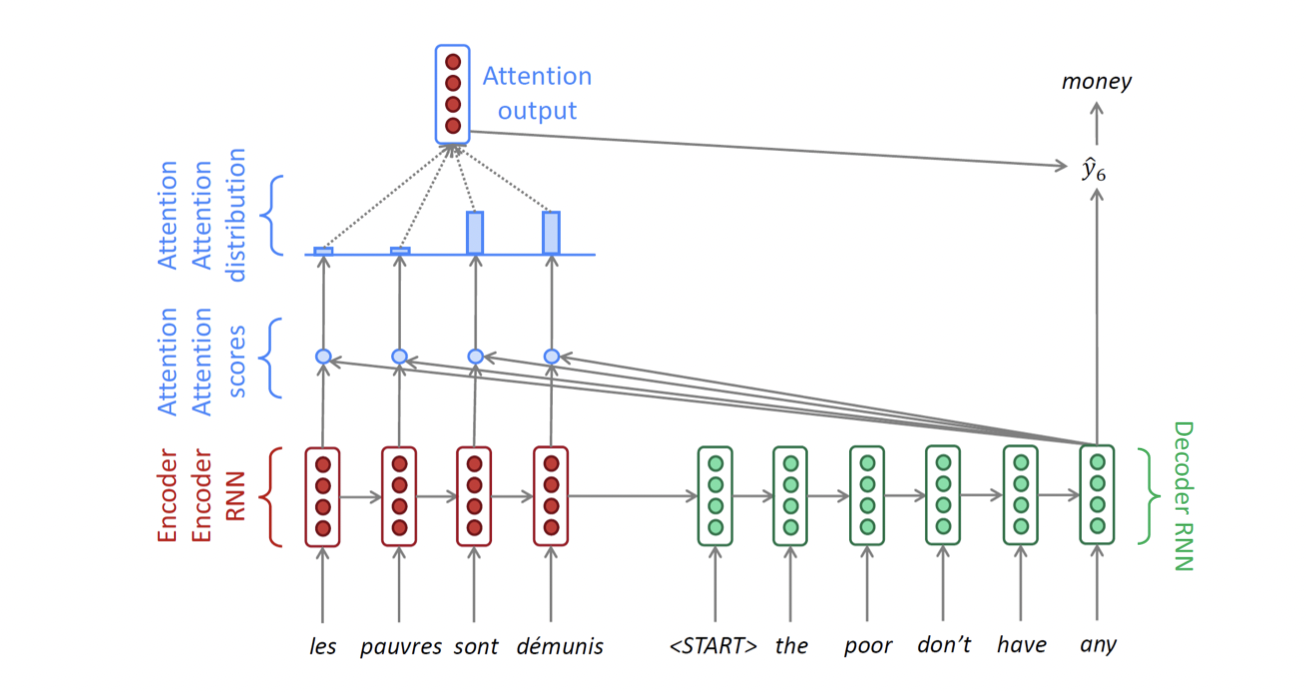
EOS가 나올 때까지 계속 반복한다.
-
Decoder 학습단계에서, 전 단계에서 잘못 예측했다고 하더라도 올바른 정답(Ground Truth)을 다음 스텝의 입력으로 넣어주게 되고, 이를 Teacher Forcing이라 부른다. Inference 과정에서는 Decoder의 각 출력이 다음 스텝의 입력이 된다. 학습 시 Teacher Forcing을 사용했을 경우 실제 Inference과정에서 괴리가 발생할 수 있기 때문에 Teacher Forcing을 하지 않는 방식이 실제 데이터와 더 가까울 수 있다. 그러나 Teacher Forcing을 사용하면 훨씬 빠른 학습 속도를 보인다.
(학습 초기에는 교사 강요의 학습 방식을 사용하다가 학습 후반에는 사용하지 않음으로써 효과를 올리는 방법도 있다.)
Different Attention
Decoder의 Hidden State와 Encoder의 시점별 Hidden State의 유사도를 구하는 과정에서 위에서는 Dot-Product방식을 사용했지만, 다른 방식들도 존재한다. Decoder의 Hidden State를 , encoder의 Hidden State를 라고 하자. 이 때
Mechanisms
Attention is Great!
- Attention significantly improves NMT performance
• It is useful to allow the decoder to focus on particular parts of the source - Attention solves the bottleneck problem
• Attention allows the decoder to look directly at source; bypass the bottleneck - Attention helps with vanishing gradient problem
• Provides a shortcut to far-away states - Attention provides some interpretability
• By inspecting attention distribution, we can see what the decoder was focusing on
• The network just learned alignment by itself
3. Beam Search
Andrew Ng 교수 DeepLearningAI 강의1
Andrew Ng 교수 DeepLearningAI 강의1
OpenNMT Beam Search
Test Time에 더 좋은 성능을 내는 방법
Greedy decoding
decoding 방식에서 매 타임 스텝마다 현재 가장 확률이 높은 단어만 선택해서 decoding하는 것을 greedy decoding이라고 한다. 이는 틀렸을 때 undo할 수 없다는 단점이 있다.
주어진 문장 x에 대한 출력문장 y의 joint probability를 다음과 같이 적을 수 있다.
즉, 매 타임 스텝에서 Greedy하게 뽑아도 전체적인 , joint prob.는 작아질 수도 있기 때문에 이를 고려한 decoding이 필요하다. 이는 매 타임 스텝에서 전체 단어 가지수만큼 고려하는 경우이기 때문에 의 경우가 생길 것이다. 이를 모두 알아보는 것은 너무 시간이 오래 걸리기 때문에 나온 것이 바로 Beam Search이다.
Beam Search는 매 타임 스텝에서 미리 정해놓은 K개의 높은 확률을 가지는 hypothesis 중에서 가장 확률이 높은 것을 선택하는 방식이다. k를 beam size라고 부르며, 5~10의 정도의 값을 가진다. 아래 예시를 살펴보자.
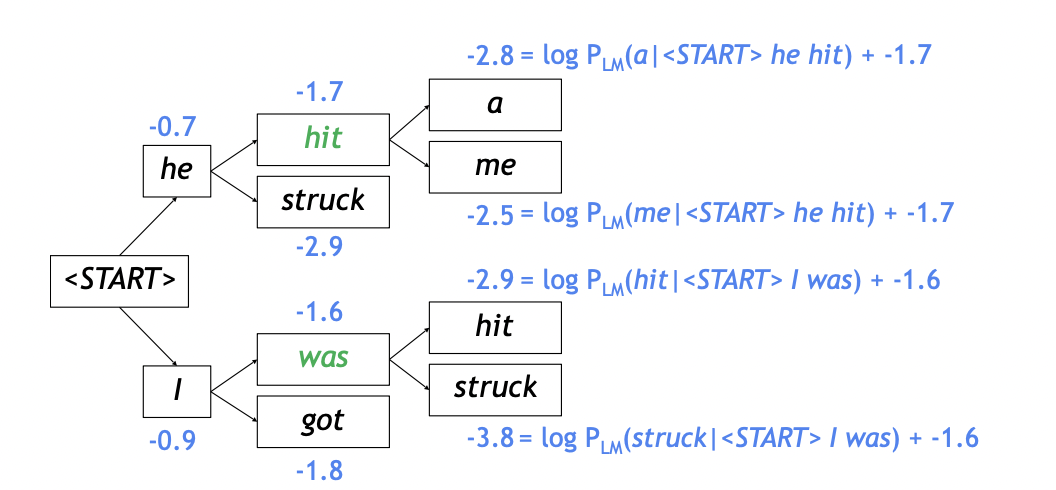
Greedy를 끝내는 시점은 END토큰이 나올 때 까지지만, Beam Search를 끝내는 지점은 각 hypothesis에서 서로 다른 지점에서 End토큰이 생성되는 형식이다.
보통 beam search는 임의로 지정해놓은 Time T와 Cutoff n에 대해서 time step이 T에 다다르거나, hypothesis로 저장된 것이 n개를 넘어서면 종료하게 된다.
최종적으로 Beam Search의 결과물로 completed hypothsis가 나오게 되고, 이를 위의 수식에 적용하여 joint probability가 최대가 되는 hypothesis를 채택하게 된다. 하지만 이 때 서로 다른 길이를 가지기 때문에 길이가 짧을 수록 score가 더 좋게 된다. 따라서 이를 공평하게 만들어주기 위해 아래와 같은 Normalize 방식을 사용한다.
4. BLEU score
BLEU score는 자연어 생성 모델의 품질, 결과의 정확도를 평가하는 척도이다.
Precision/Recall
생성된 문장을 평가하는데 있어서 고정된 타임 스텝 위치에서 평가하는 것은 적절하지 않다. 이 점을 고려하여 다음과 같은 평가 지표를 생각할 수 있다.
- 정밀도 : 예측된 결과가 노출되었을 때 실질적으로 느끼는 정확도
- 재현율 : 실제 원하는 데이터에서의 정확도 개념
위의 두 정확도를 산술 평균, 기하 평균, 조화 평균 등을 생각할 수 있다. 각 평균값들의 대소 비교는 산술평균 > 기하 평균 > 조화 평균이다. 즉, 조화 평균은 더 작은 값에 가깝게 되는 값이다. 우리는 조화 평균 형태를 아래와 같이 부른다.
한편, 위와 같은 평가 지표들은 단어의 위치를 고려하지 않았기 때문에 아래와 같은 현상이 발생한다. 아래의 문장들을 보자.
Predicted (from model 1): Half as my heart is in Obama ooh na
Reference---------------: Half of my heart is in Havana ooh na na
Predicted (from model 2): Havana na in heart my is Half ooh of na
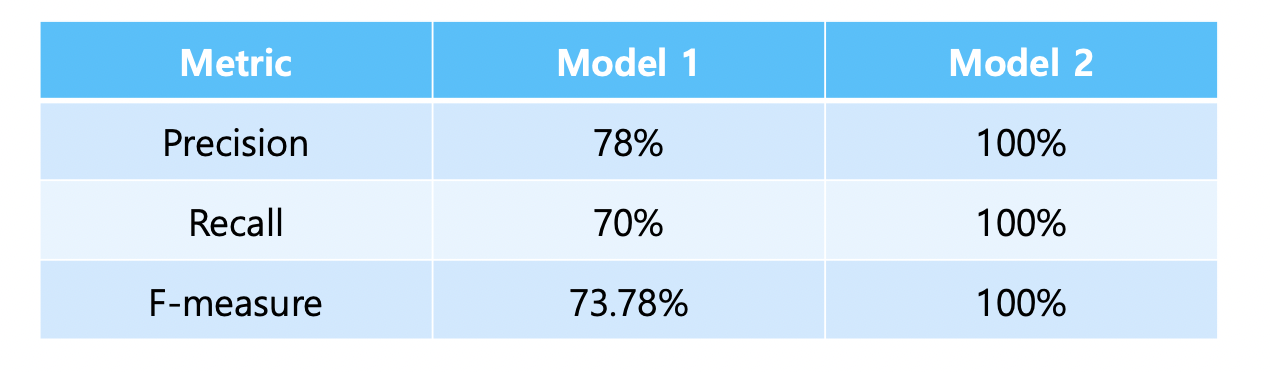
즉, model 2는 문장의 순서가 완전히 다름에도 불구하고 100%의 F-measure값을 가지게 되는 문제가 발생한다.
이러한 문제들을 해결하는 성능 평가 measure로 BLEU가 나오게 된다.
BLEU
개별적인 단어의 Ground Truth와의 비교가 아니라, N-gram을 활용한 N개의 단어 내의 precision만 생각하는 것이 BLEU score이다. Recall을 생각하지 않는 이유는 실제 값에서 예측값이 포함하지 못하는 단어가 있다 하더라도 문장의 의미에 큰 차이를 주지 않을 가능성이 높기 때문이다. 하지만 예측한 값이 틀린 단어를 출력한다면 이것은 NMT개념에서 완전한 오역으로 볼 수 있기 때문에 Precision을 고려한다.
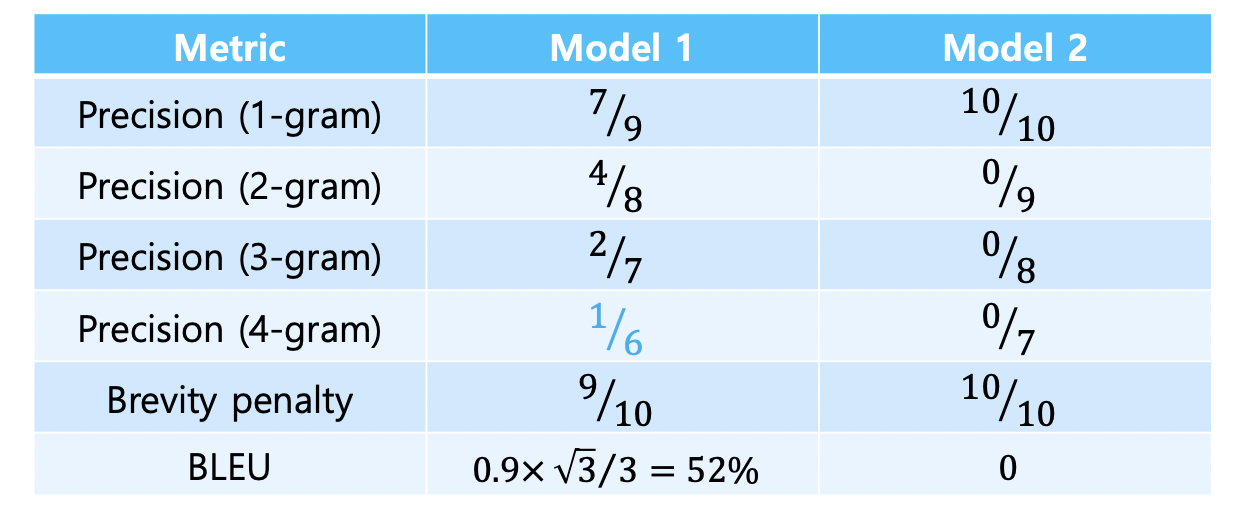
따라서 uni-gram 부터 four-gram까지의 단어들의 Precision을 계산하는데, precision을 구해서 곱한 후 4제곱근을 취하는 기하 평균의 형태를 취한다.
또한, 너무 짧은 예측값에 대한 penalty를 부여해주기도 한다.
이를 적용하여 위의 예시 문장의 BLEU score를 알아보자.
더 알아볼 것
- RNN의 출력에 대해서
- 기존 Seq2Seq의 Decoder 진행 과정
- dot-product Attention, Luong, badahnau Attention wikidoc 읽어보기
- Attention Backpropa
Further Question
BLEU score가 번역 문장 평가에 있어서 갖는 단점은 무엇이 있을까?
Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics
