
자연어 처리는 인간 세상에서 어떤 문제들을 해결해줄 수 있을까?
인공지능 개발을 하는 사람이라면 누구나 이런 생각을 하지 않을까 싶다. 인공지능이라는 것이 결국 인간이 하지 못하거나 하는데 너무 오래걸리는, 문제를 해결해주는 역할로서 작용하기 위해 만들어진 것이기 때문이다. 물론 인공지능 기술은 매우 빠르게 발전하고 있기 때문에 요즘에는 그 목적을 위해서만은 아닐 수도 있겠다.
자연어 처리, NLP는 보통 4가지 경우로 활용되며 문제를 해결한다.
텍스트 분류
텍스트 유사도
텍스트 생성
기계 이해
위 4가지 활용법에 대해 알아보기 이전에, 단어 표현이라는 것을 한 번 짚고 넘어가야 한다. 자연어 처리 문제의 사실상 기본 중의 기본 개념이고, 자연어를 어떻게 표현할지 정하는 것이 문제 해결의 시작점이라고 할 수 있기 때문이다.
단어 표현
자연어를 다루는 과정에서 이를 컴퓨터가 인식하도록 변환하는 방법에 대해서는 많은 고민이 있었을 것이다. 컴퓨터는 이진화된 값(0 또는 1로만 이루어진 값)으로 정보를 받아들이게 되므로 텍스트를 이진화하는 방식 역시 고려되었을 것이다. 하지만 자연어 처리에서 이러한 방식으로 사용하기에는 문제가 있다. 언어적 특성이 전혀 고려되지 않은, 순전히 컴퓨터가 이해하기 위해 만들어진 값이기 때문이다. 자연어 처리의 궁극적 목적은 컴퓨터가 언어-인간이 만들어낸 매우 고차원의 산물 중 하나인-를 이해하기까지 도달하는 것이고, 아직 완벽하진 않더라도 최대한 언어의 특성을 반영하여 자연어를 다루는 것이 NLP의 오랜 염원이었을 것이다.
이 과정에서 해답이 될 수 있는 것이 "단어 표현(Word Representation)"이다. 즉, 단어의 언어적 특성을 반영하여 수치화/ 혹은 벡터화 시키는 방법을 찾는 것이다. 이 표현은 "단어 임베딩(Word Embedding)", "단어 벡터(Word Vector)"로도 불린다.
- 원-핫 인코딩 (One-Hot Encoding)
가장 기본적인 방법은 원핫인코딩 방식으로, 단어를 하나의 벡터로 표현하며 각 값이 0 또는 1만 갖는 형태를 지니고 있다. 다시말하면 한 단어는 0과 1을 가지고 있는 1차원 열벡터로, 1은 단 하나, 그 단어를 설명할 수 있는 인덱스에서만 나타난다.
예를 들면 이렇다. 3개의 단어 (김밥, 개미, 우유)이 있다고 가정하면, 각 단어는
김밥 : [1, 0, 0]
개미 : [0, 1, 0]
우유 : [0, 0, 1]
이렇게 표현할 수 있을 것이다.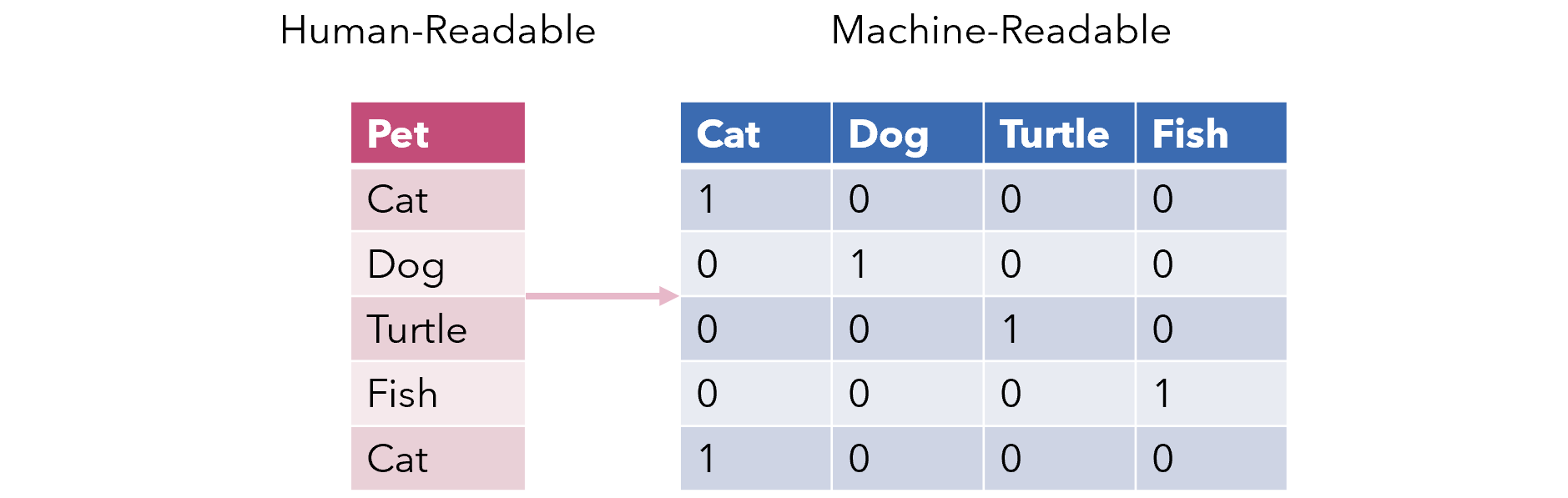
직관적으로 단어를 표현할 수 있어 간단하긴 하지만 자연어처리에서 원-핫 인코딩은 거의 사용하기 어렵다. 이미 눈치챘겠지만, 실제 자연어를 다루게 된다면 해당하는 단어의 수는 수십만, 수백만 그 이상이기 때문이다. 그 과정에서 한 단어(1)를 표현하기 위해 수많은 공백(0)들이 생기게 된다. 이를 Sparse하다 라고 한다.
이러한 원핫인코딩의 매우 비효율적인 특징들을 개선하고, 단어의 의미나 특성을 표현하기 위해 제안된 단어 표현 방식이 바로 분포 가설(Distributed Hypothesis) 기반 방법들이다.
같은 문맥의 단어, 즉 비슷한 위치에 등장하는 단어는 비슷한 의미를 가진다
분포 가설은 크게 두 가지 방법으로 나뉜다.
- 카운트 기반 방법
- 예측 방법
카운트 기반 방법
어떤 글의 문맥 안에 단어가 동시에 등장하는 횟수를 세는 방법이다. 동시에 등장하는 것을 Co-occurrence라고 부른다. 기본적으로 동시 등장 횟수를 하나의 행렬로 나타낸 뒤, 그 행렬을 이용해 단어 벡터를 만든다. 카운트 기반 방법에는 다음과 같은 바법들이 있다.
- 특이값 분해(SVD, Singular Value Decomposition)
- 잠재의미분석(LSA, Latent Semantic Analysis)
- HAL(Hypersoace Analogue to Language)
- Hellinger PCA(Principal Component Analysis)
참고로, 분포 가설이 카운트 기반과 예측방법으로 나뉘는 것에 앞서 배운 CountVec/TfidfVec 과 혼동을 가지는 사람이 있을까 싶어 글을 남긴다.
단어 표현은 기본적으로 국소 표현(Local Representation)과 분산 표현(Distributed Representation)으로 나뉜다. 앞서 말한 분포 가설 기반 방법이 결국 분산 표현인 것이다.한글로 번역하면서 Distributed가 분포/ 분산이 혼용된 것 같은데, 영어를 쓰는 것을 추천한다.
국소 표현에는 위에서 살펴본 One-Hot Vector와 N-gram, BoW(Bag of Words)가 있다. 그리고 이 중에서 BoW의 경우, 카운트 기반의 방법이며, 여기에 CountVectorization과 TfidfVectorization이 포함된다.
분산 표현은 다른 말로 연속 표현(Continuous Representation)이라고도 한다. 위에서 말한대로 여기에는 카운트 기반의 방법과 예측 방법이 있다.
아래의 사진에서 잘 표현하고 있는데, 더욱 자세한 내용은 나중에 단어 표현과 관련해서 다시 글을 쓰도록 하겠다.
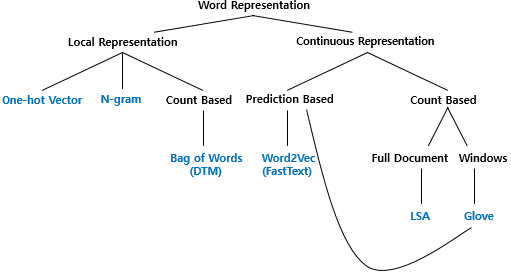
예측 방법
신경망 구조나 어떠한 모델을 활용해서 특정 문맥에 올 단어를 예측하는 방식이다.
- Word2Vec
- NNLM(Neural Network Language Model)
- RNNLM(Recurrent Neural Network Language Model)
이 중에서 가장 많이 사용되는 방법은 Word2Vec으로, 이 방법에 대해서 알아보겠다.
Word2Vec은 크게 두가지 모델로 나뉜다.
- CBOW(Continuous Bag of Words)
- Skip-gram
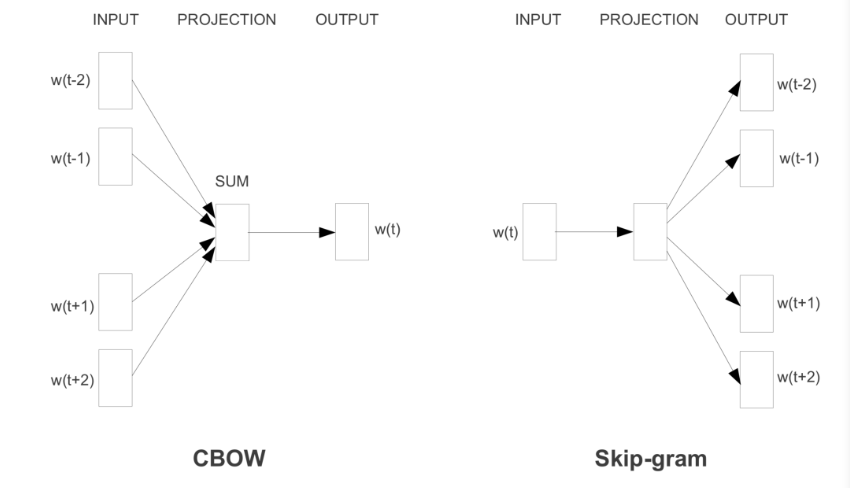
CBOW
- 각 주변 단어들을 원-핫 벡터로 만들어 입력값으로 사용(입력)
- 가중치 행렬을 각 원-핫 벡터에 곱해서 n차원 벡터로 만듬
- 더해진 개수로 나눠 평균 n차원 벡터로 만듬(출력)
- n차원 벡터에 다시 가중치 행렬을 곱해 원-핫 벡터와 같은 차원의 벡터로 만듬
- 만들어진 벡터를 실제 예측하려고 하는 원-핫 벡터와 비교하여 학습
Skip-gram
- 하나의 단어를 원-핫 벡터로 만들어 입력값으로 사용(입력)
- 가중치 행렬을 원-핫 벡터에 곱해 n차원 벡터를 만듬
- n차원 벡터에 다시 가중치 행렬 곱해서 원-핫 벡터와 같은 차원의 벡터로 만듬(출력)
- 만들어진 벡터를 실제 예측하려는 주변 단어들 각각의 원-핫 벡터와 비교해서 학습
이처럼 Word2Vec을 이용하여 단어 벡터를 예측하는 방식은 단어간 유사도를 잘 측정하고, 단어 사이의 복잡한 특징까지도 잘 잡아낸다. 예를 들어 (한국, 서울, 일본, 도쿄)가 있다고 한다면 Word2Vec을 사용하면 한국과 서울의 관계는 일본과 도쿄의 관계와 매우 흡사하게 측정된다.
일반적으로 Skip-gram이 성능이 좋아 많이 쓰이는 편이지만, 절대적이진 않다. 또한 카운트 기반과 예측 방법을 모두 포함하는 "Glove"방식이 있으니 추후에 알아보도록 하자.
