
본격적으로 캐글 문제를 해결하기 앞서서, 모델이 높은 성능을 낼 수 있도록 하려면 좋은 모델링을 거치는 것도 물론 중요하지만 데이터를 잘 파악하는 것이 우선이다. 이러한 데이터 이해 과정을 EDA(탐색적 데이터 분석; Exploratory Data Analysis)라고 한다. 이 과정을 통해 데이터의 여러 패턴이나 잠재적인 문제점 등을 발견할 수 있다.
EDA를 진행하는데 특정한 규칙이 있지는 않다. 최대한 다양한 정보를 뽑아낼 수 있는 것으로도 충분하다. 예를 들면 평균값, 중앙값, 분포, 범위, Outlier 들을 알아보고 이를 히스토그램이나 다양한 그래프의 형태로 시각화하는 과정을 모두 포함하고 있다.
영화리뷰 데이터를 불러와 EDA를 연습해보려고 한다.
import os
import pandas as pd
import tensorflow as tf
from tensorflow.keras import utils
data_set = tf.keras.utils.get_file(
fname="imdb.tar.gz",
origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
extract=True)위의 keras.utils의 get_file함수를 사용하고나면 /root/.keras/datasets 경로에 origin경로에 있는 파일인 imdb.tar.gz파일을 다운로드 받을 수 있다.그리고 extract 값을 주어서 압축을 해제할 수 있다.
위의 코드가 실행되고 나면 aclImdb폴더가 생기고, 그 아래에 train, test 폴더가 생긴다. 각 폴더 내에는 pos, neg라는 폴더가 있고 그 안에 해당하는 리뷰들이 txt파일 형태로 저장되어있다. 이를 분석이 가능하도록 판다스 데이터프레임 형태로 바꾸는 과정은 다음과 같다.
def directory_data(directory):
data = {}
data["review"] = []
for file_path in os.listdir(directory):
with open(os.path.join(directory, file_path), "r", encoding='utf-8') as file:
data["review"].append(file.read())
return pd.DataFrame.from_dict(data)
def data(directory):
pos_df = directory_data(os.path.join(directory, "pos"))
neg_df = directory_data(os.path.join(directory, "neg"))
pos_df["sentiment"] = 1
neg_df["sentiment"] = 0
return pd.concat([pos_df, neg_df])
train_df = data(os.path.join(os.path.dirname(data_set), "aclImdb", "train"))
test_df = data(os.path.join(os.path.dirname(data_set), "aclImdb", "test"))directory_data함수는 어떤 경로를 파라미터로 받아서 그 경로 안에 있는 파일들을 python 내장함수인 open을 사용해 읽기 전용으로 열고, data라는 딕셔너리 형태의 'review' 키 값에 할당된다. 그리고 데이터프레임 형식으로 변환해 반환한다.
data함수는 위의 directory_data함수를 사용하여 각각의 pos(긍정), neg(부정) 폴더 안의 정보에 대해서 데이터 프레임을 만들고 새로 'sentiment'라는 컬럼을 부여하여 긍정의 경우 1, 부정의 경우 0을 지정했다. 결과값은 부정df와 긍정df의 결함(concat)형태로 반환한다.
결과를 출력하면 다음과 같다.
이렇게 DataFrame형태로 만들었다면 이제 다음과 같은 EDA분석을 할 수 있다.
reviews = list(train_df['review'])
# 문자열 문장 리스트를 토크나이즈(공백으로 구분)
tokenized_reviews = [r.split() for r in reviews]
# 토크나이즈 된 리스트에 대한 각 길이를 저장
review_len_by_token = [len(t) for t in tokenized_reviews]
# 토크나이즈 된 것을 붙여서 음절의 길이를 저장
review_len_by_eumjeol = [len(s.replace(' ', '')) for s in reviews]
import matplotlib.pyplot as plt
# 그래프에 대한 이미지 사이즈 선언
plt.figure(figsize=(12, 5))
# 히스토그램 선언
# bins: 히스토그램 값들에 대한 버켓 범위
# range: x축 값의 범위
# alpha: 그래프 색상 투명도
# color: 그래프 색상
# label: 그래프에 대한 라벨
plt.hist(review_len_by_token, bins=50, alpha=0.5, color= 'r', label='word')
plt.hist(review_len_by_eumjeol, bins=50, alpha=0.5, color='b', label='alphabet')
plt.yscale('log', nonposy='clip')
# 그래프 제목
plt.title('Review Length Histogram')
# 그래프 x 축 라벨
plt.xlabel('Review Length')
# 그래프 y 축 라벨
plt.ylabel('Number of Reviews')
plt.legend()위의 코드를 실행하면 다음과 같은 히스토그램을 얻을 수 있다.
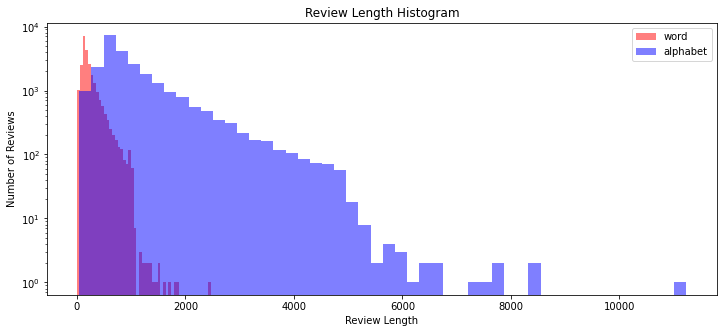
붉은색은 word, 즉 단어 개수에 대한 히스토그램이고 파란색은 알파벳 개수를 의미한다.
이렇게 리뷰 데이터의 단어 개수 분포가 어떻게 되는지 살펴보았다. 다음은 이상치를 확인해보겠다.
import numpy as np
print('문장 최대길이: {}'.format(np.max(review_len_by_token)))
print('문장 최소길이: {}'.format(np.min(review_len_by_token)))
print('문장 평균길이: {:.2f}'.format(np.mean(review_len_by_token)))
print('문장 길이 표준편차: {:.2f}'.format(np.std(review_len_by_token)))
print('문장 중간길이: {}'.format(np.median(review_len_by_token)))
# 사분위의 대한 경우는 0~100 스케일로 되어있음
print('제 1 사분위 길이: {}'.format(np.percentile(review_len_by_token, 25)))
print('제 3 사분위 길이: {}'.format(np.percentile(review_len_by_token, 75)))
plt.figure(figsize=(12, 5))
# 박스플롯 생성
# 첫번째 파라메터: 여러 분포에 대한 데이터 리스트를 입력
# labels: 입력한 데이터에 대한 라벨
# showmeans: 평균값을 마크함
grid = (1,2)
plt.subplot2grid(grid, (0,0),rowspan=1,colspan=1)
plt.boxplot([review_len_by_token],
labels=['token'],
showmeans=True)
plt.subplot2grid(grid, (0,1),rowspan=1,colspan=1)
plt.boxplot([review_len_by_eumjeol],
labels=['Eumjeol'],
showmeans=True)위의 코드를 실행하면 아래와 같이 나온다.
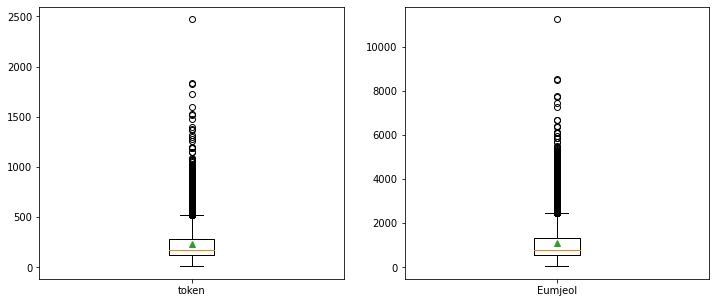
이 외에도 워드클라우드,
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
%matplotlib inline
wordcloud = WordCloud(stopwords = STOPWORDS, background_color = 'black', width = 800, height = 600).generate(' '.join(train_df['review']))
plt.figure(figsize = (15, 10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()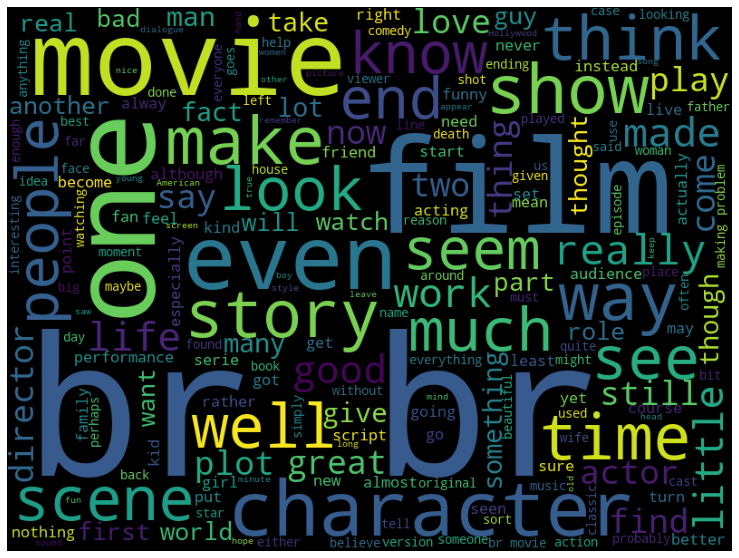
라벨 분포 확인 등 다양하게 EDA를 진행해서 데이터를 이해하는 과정을 거친다.
import seaborn as sns
import matplotlib.pyplot as plt
sentiment = train_df['sentiment'].value_counts()
fig, axe = plt.subplots(ncols=1)
fig.set_size_inches(6, 3)
sns.countplot(train_df['sentiment'])
