Python, mongoDB, Robo3T 다운
1) 2주차 복습
나홀로메모장에 들어가는 아티클들의 정보를 불러오는 OpenAPI를 이용해 저장된 포스팅 불러오기를 만들어보세요.

- 로딩 후 바로 실행하는 코드
$(document).ready(function(){
listing();
});
function listing() {
console.log('화면 로딩 후 잘 실행되었습니다');
}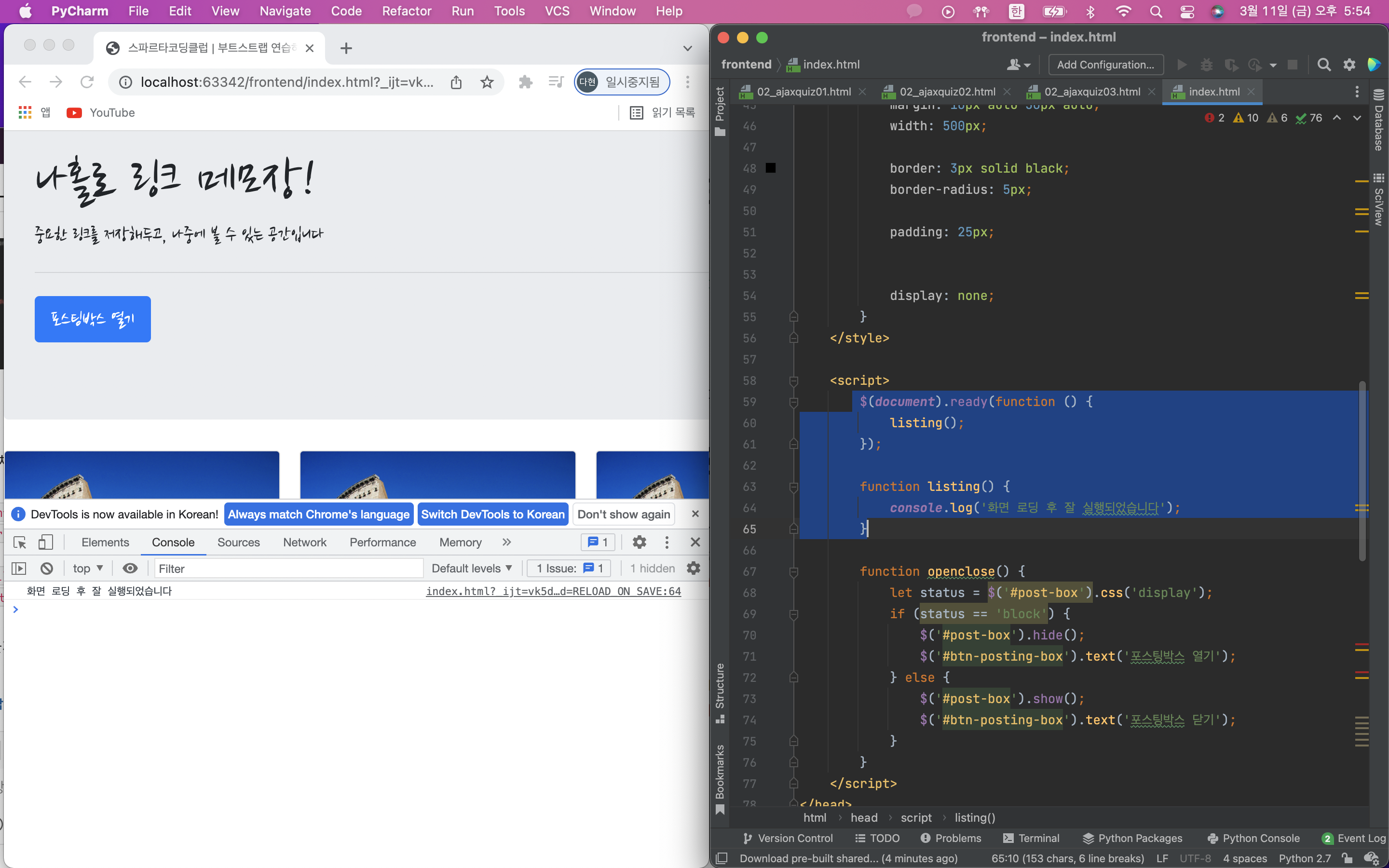
잘 실행되는 것을 확인 했으면 listing() 함수의 console.log('화면 로딩 후 잘 실행되었습니다'); 대신에 넣고자하는 ajax를 넣으면 된다.
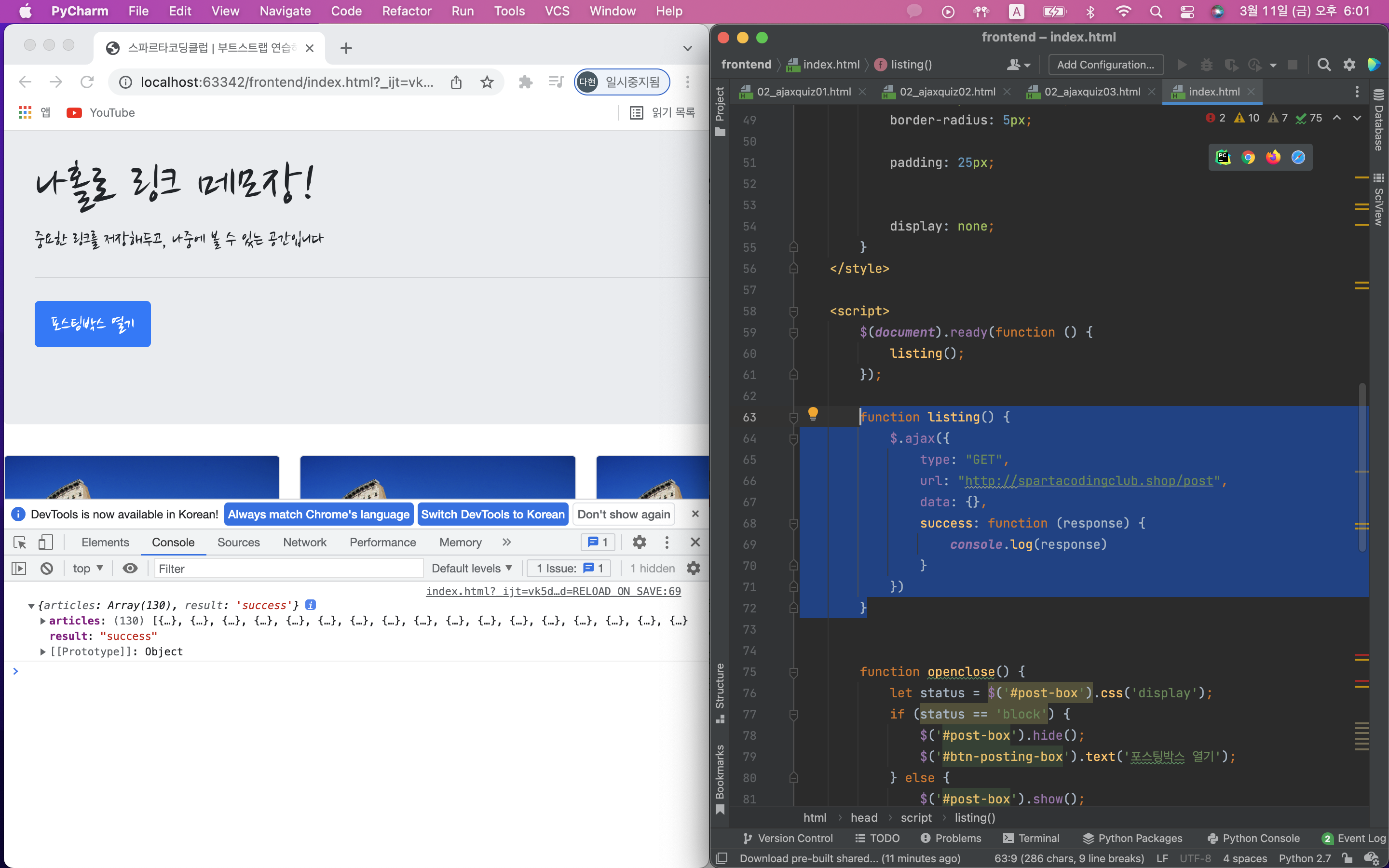
잘 찍히나 다 확인
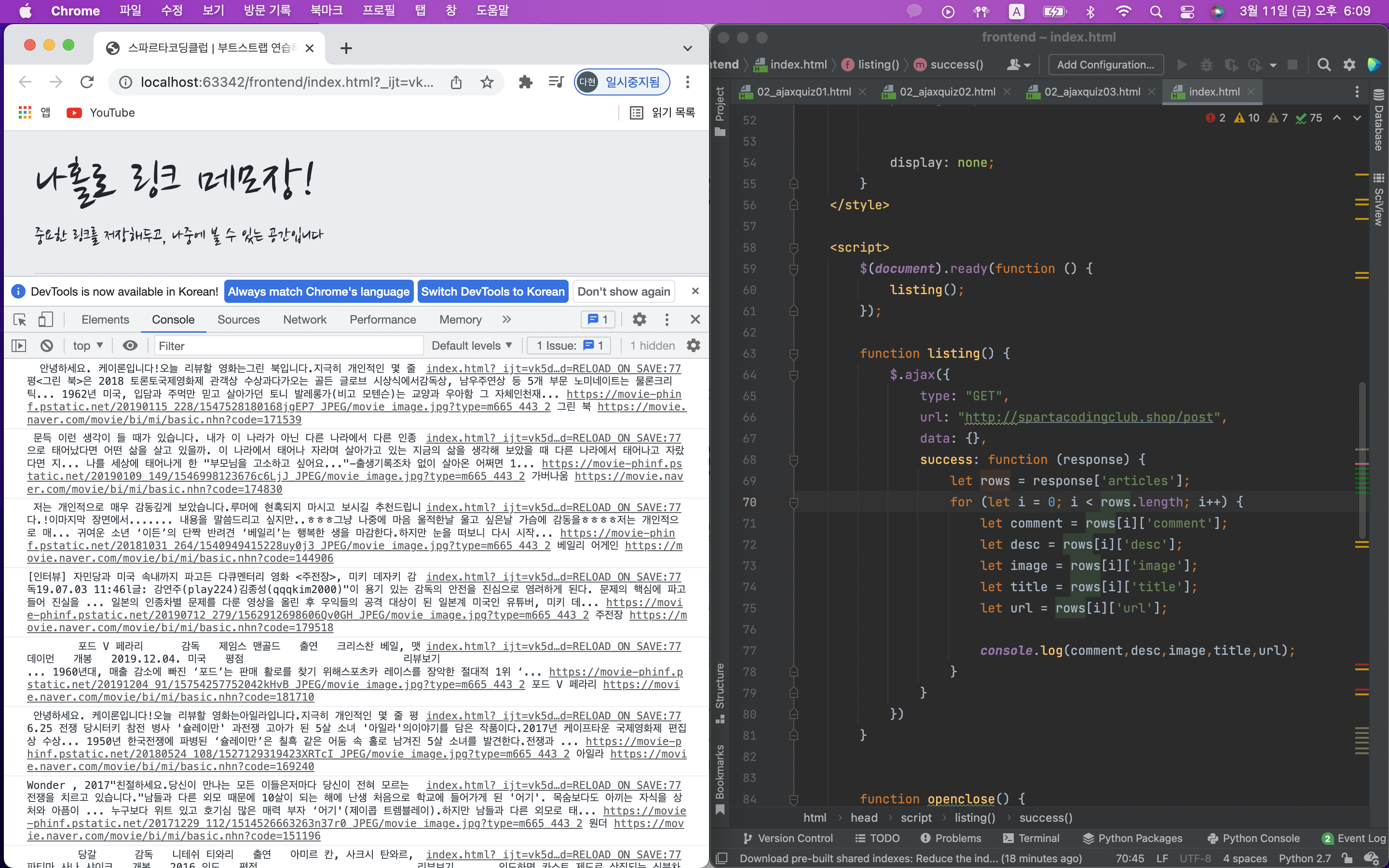
temp_html을 만들어서 붙여주기만 하면 된다.
먼저 있던 카드들을 $('#cards-box').empty();로 지워줘야함.
어떤 html? card-box라는 곳에 카드를 만들어주면 된다.
변경할 부분 변수 변경하기! {url},{desc},${comment}
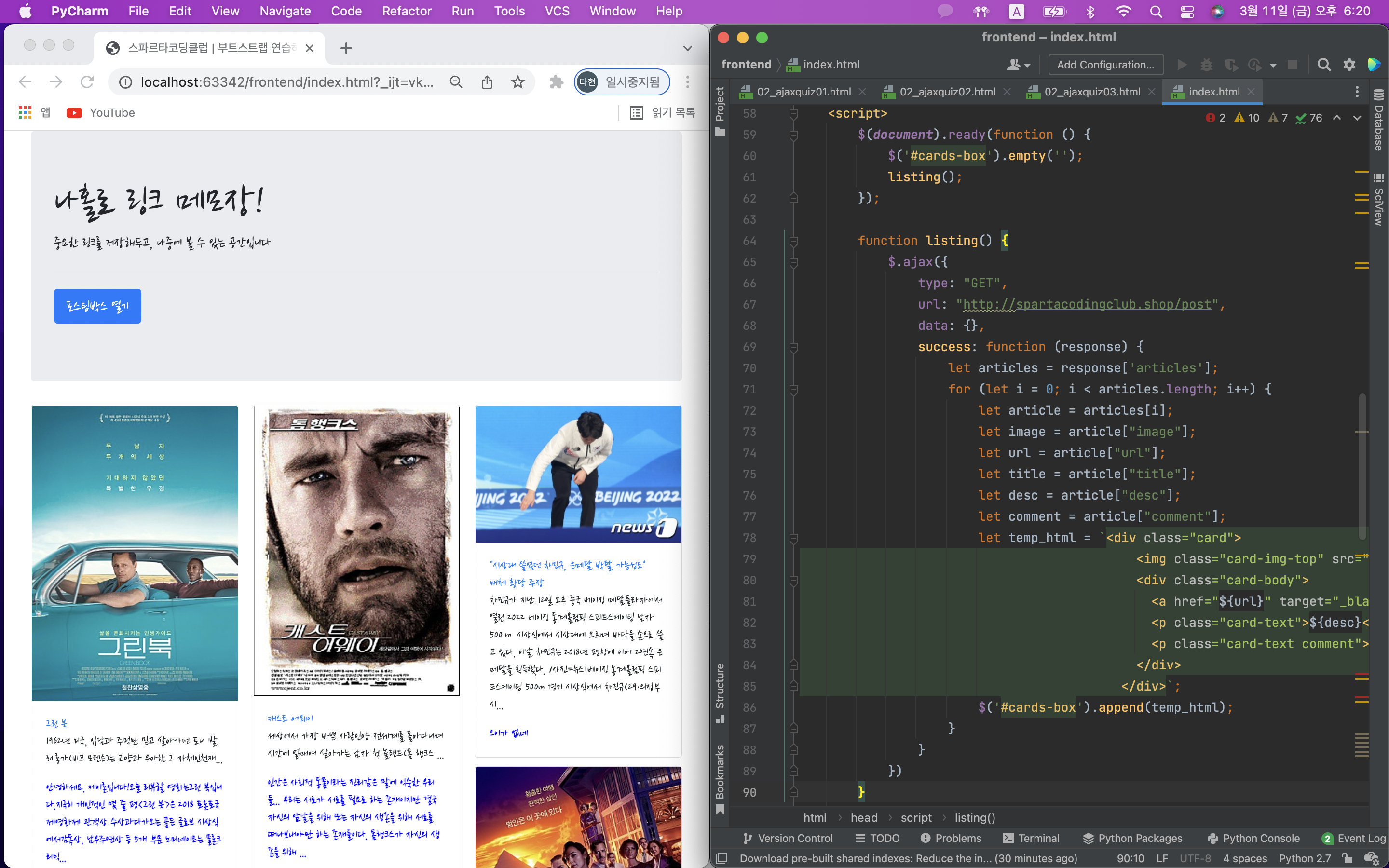
2) 파이썬
실행시 오른쪽 마우스 클릭 - run 누르기!
변수 & 기본연산
자료형
숫자, 문자형
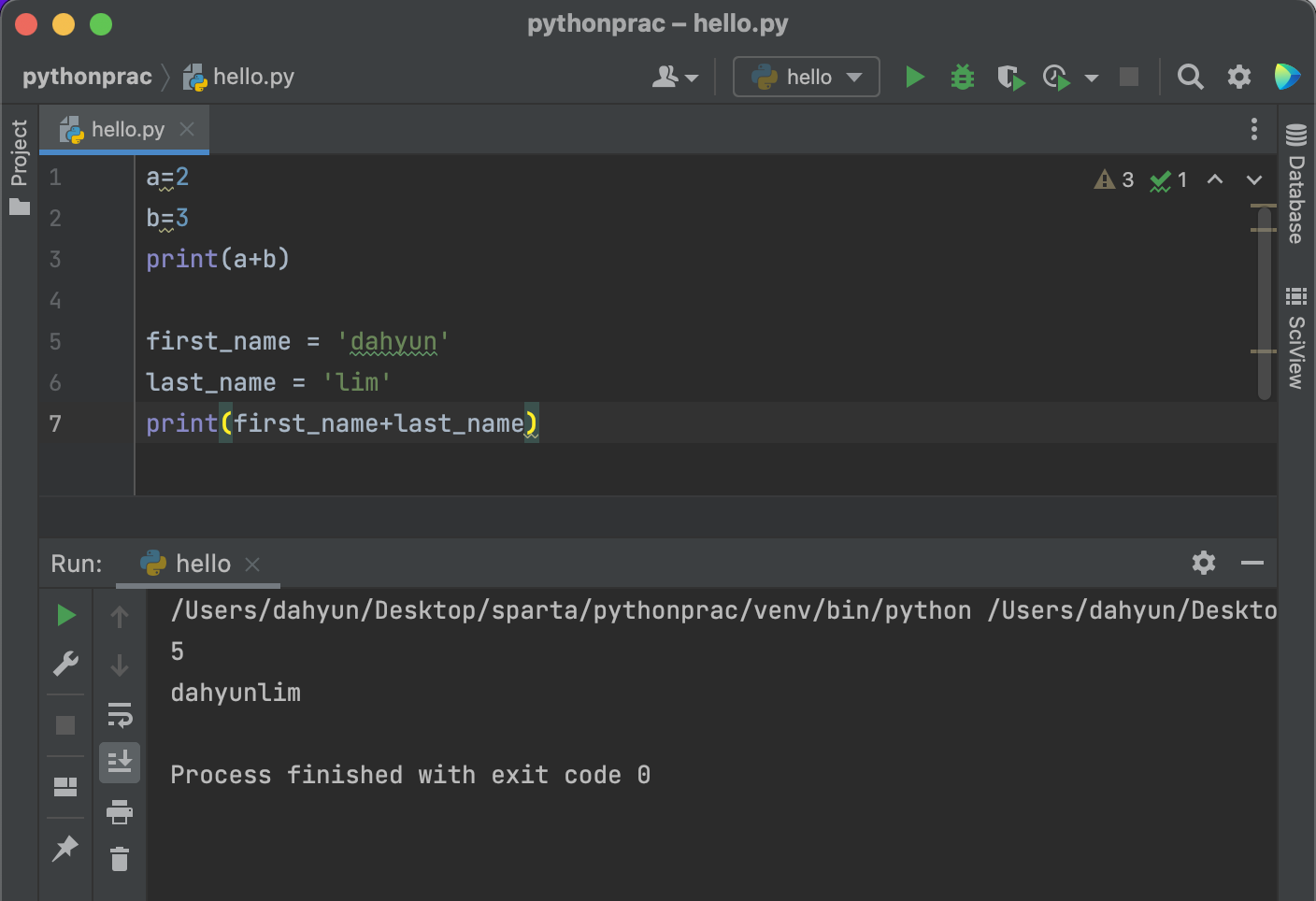
리스트형

딕셔너리형

딕셔너리형 + 리스트형
함수

조건문
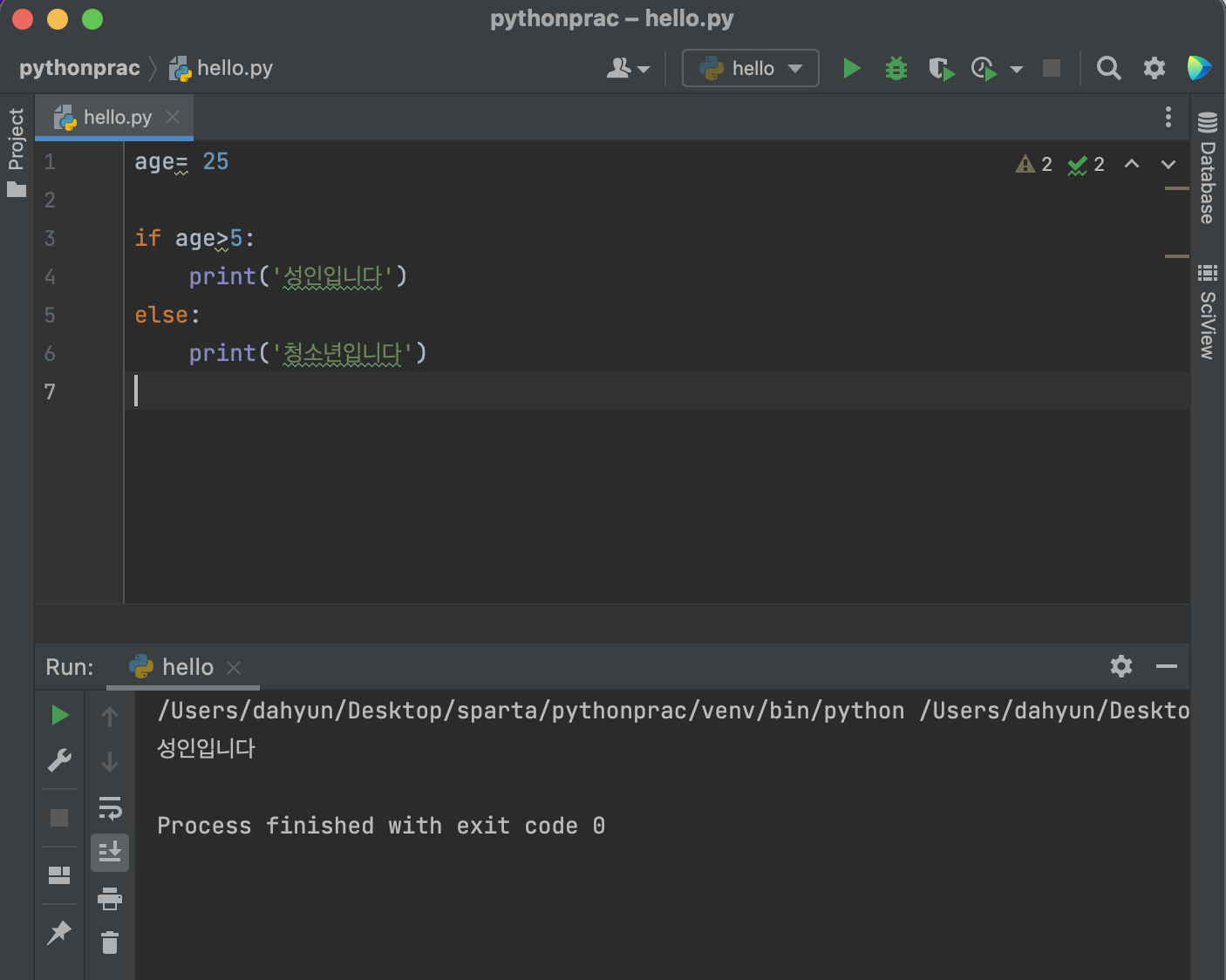
함수로 만들어서 사용해보기

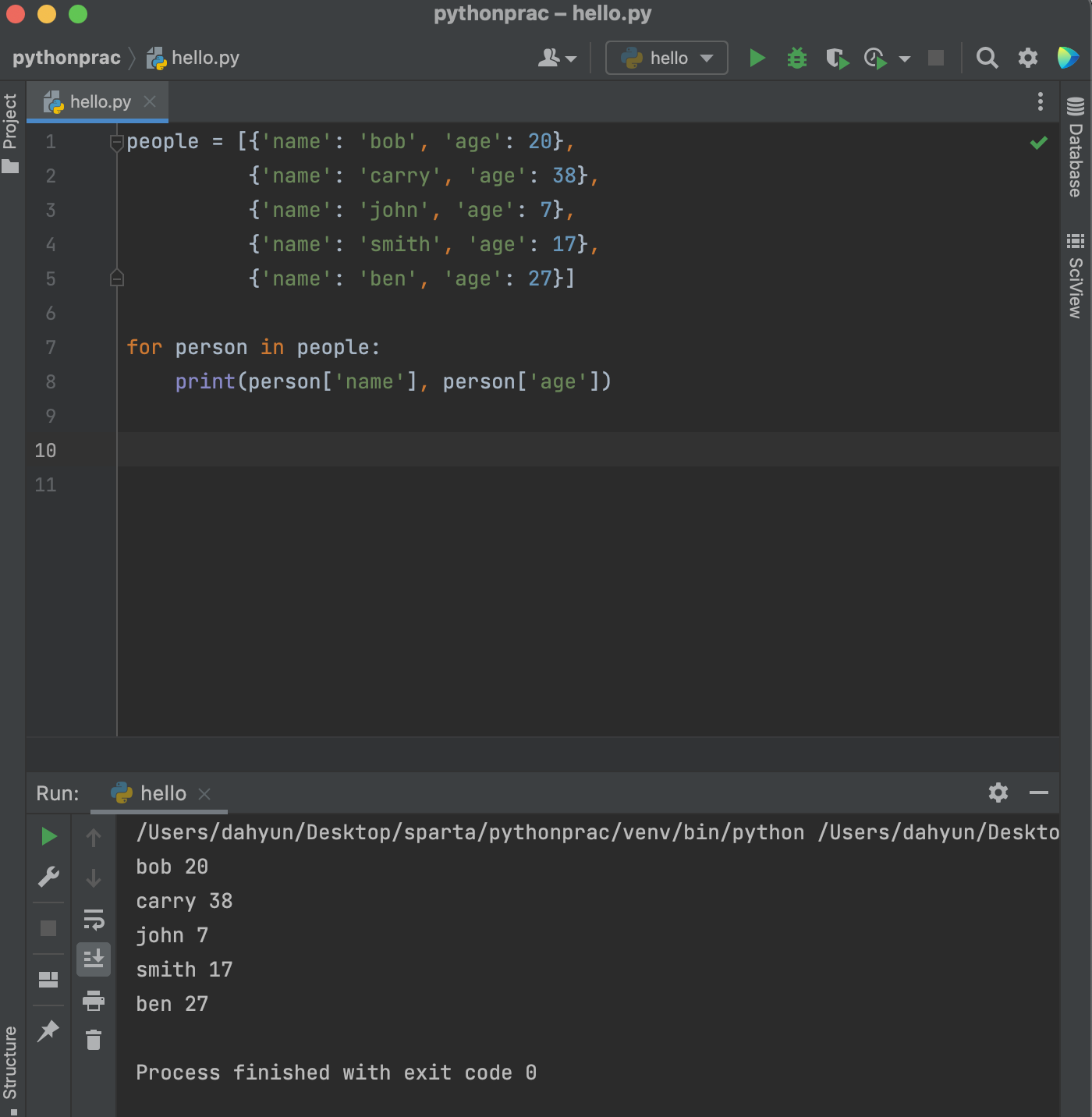
반복문
: 리스트의 요소들을 하나씩 꺼내쓰는 형태
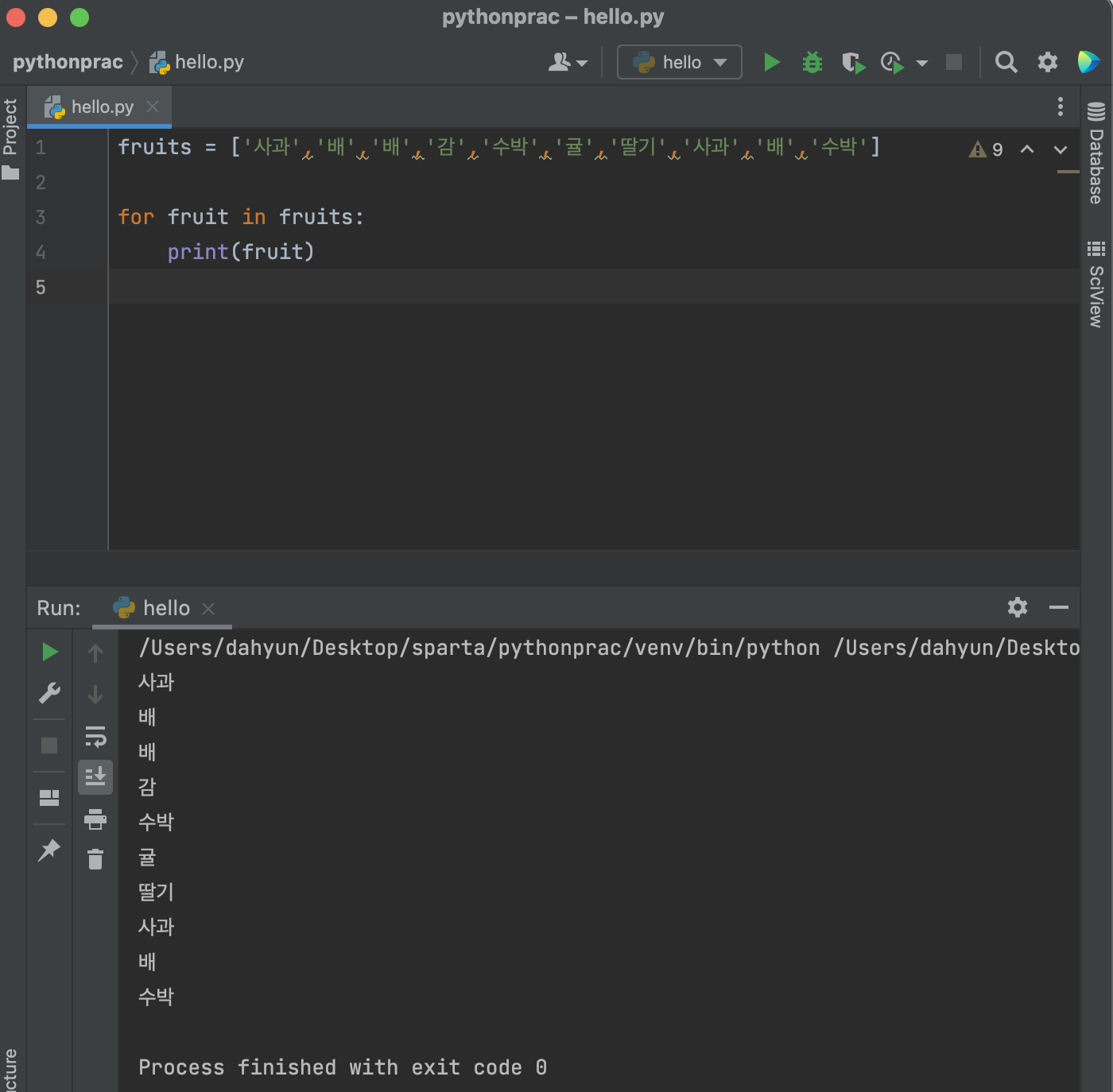

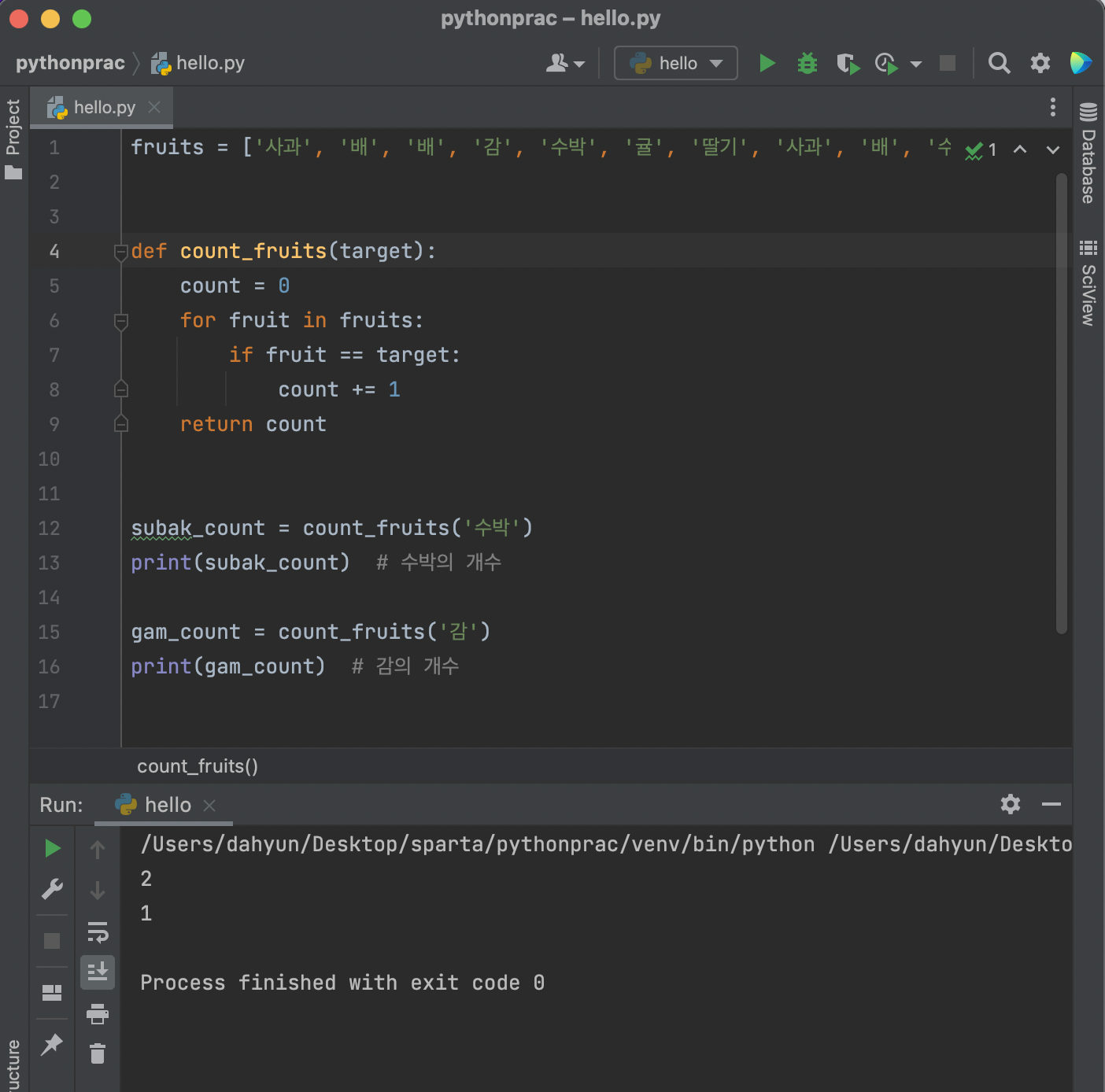
- 딕셔너리 예제
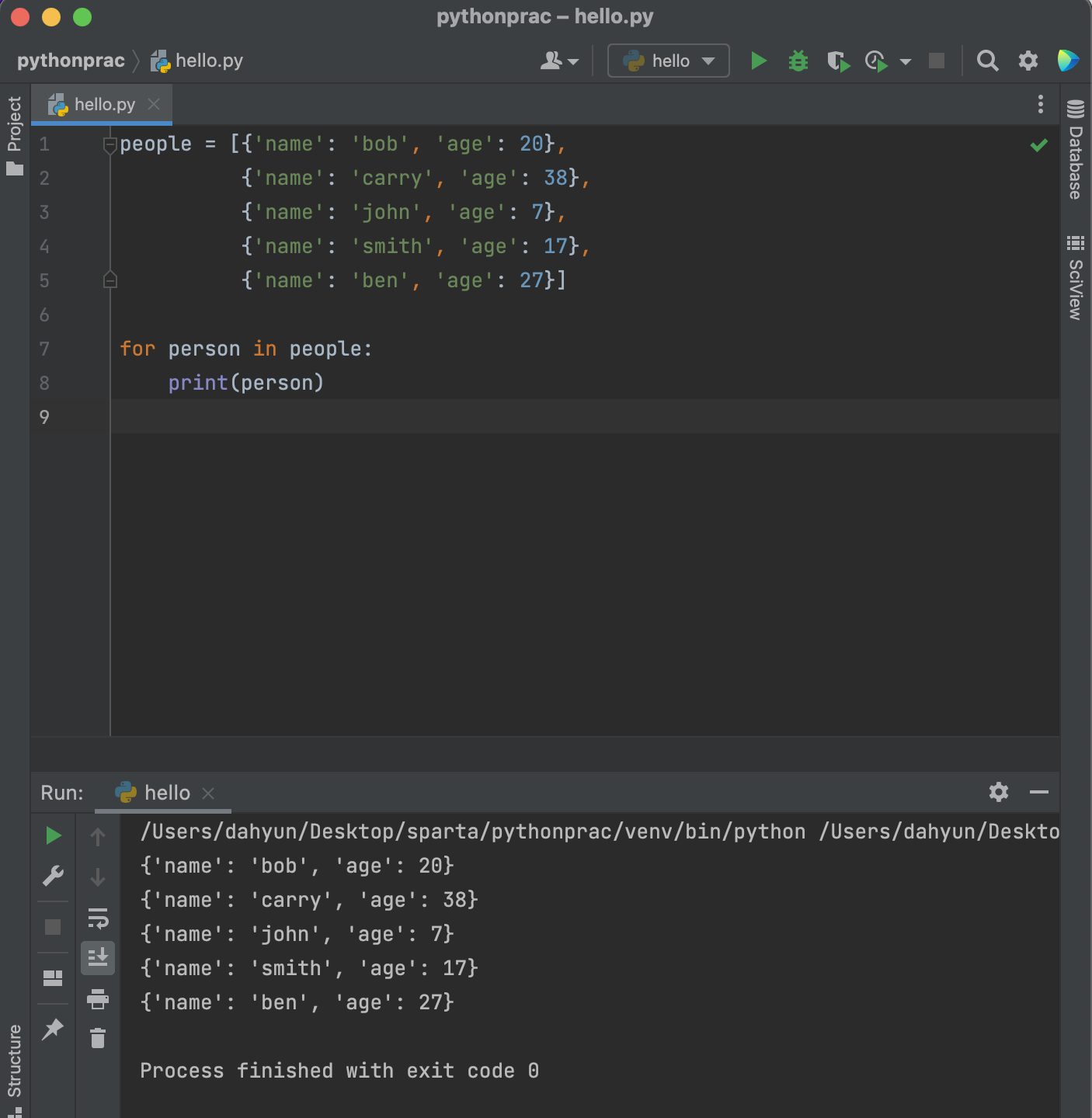

패키지 설치하기
requests 사용해보기
settings>Preference>Project:>Python Interpreter
requests install package
파이썬 XXX 패키지 검색하면 알 수 있음!
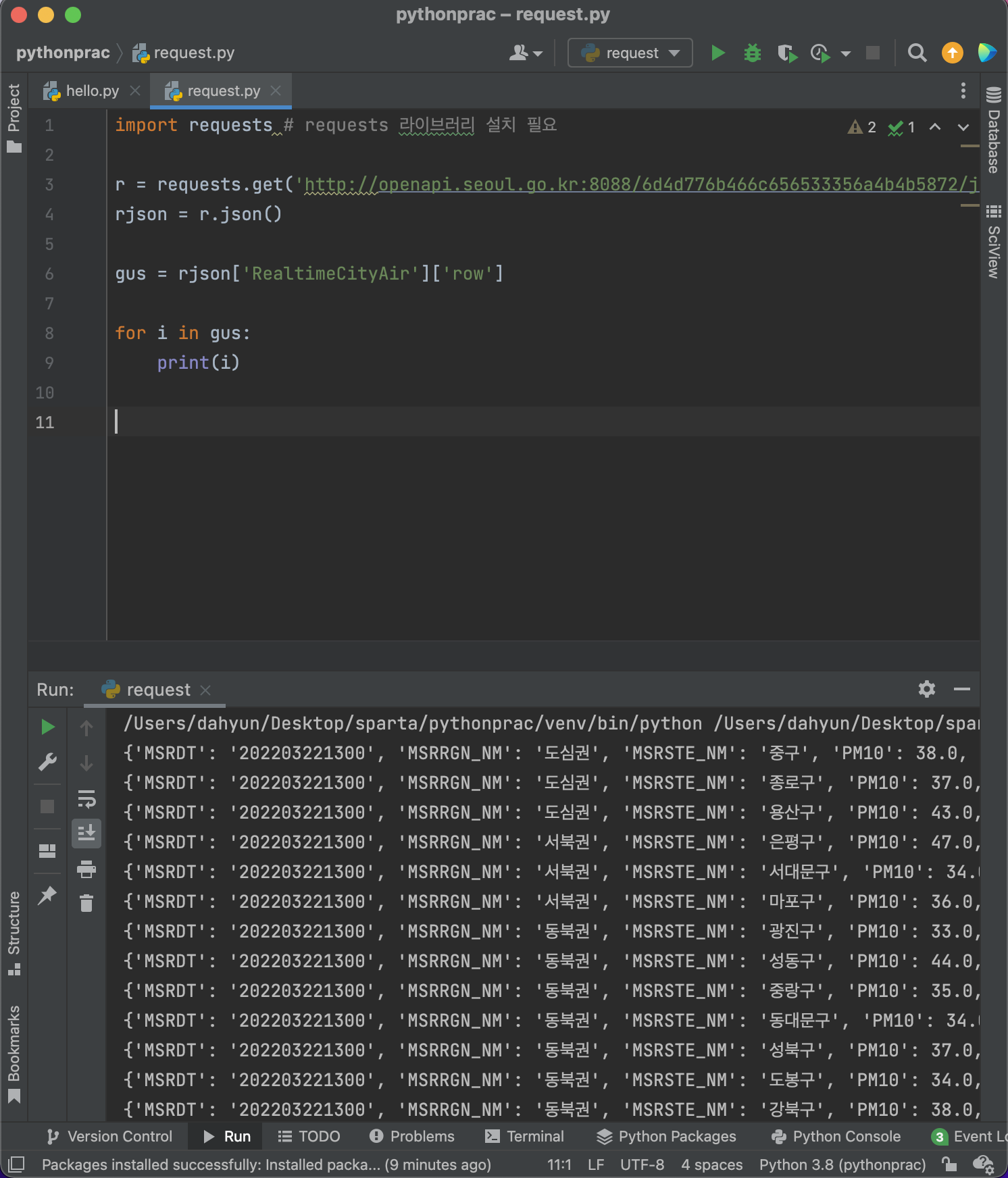
< 서울시 대기 OpenAPI에서, 중구의 NO2 값 가져오기 >
import requests # requests 라이브러리 설치 필요
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
print(rjson['RealtimeCityAir']['row'][0]['NO2'])request.get('url주소')
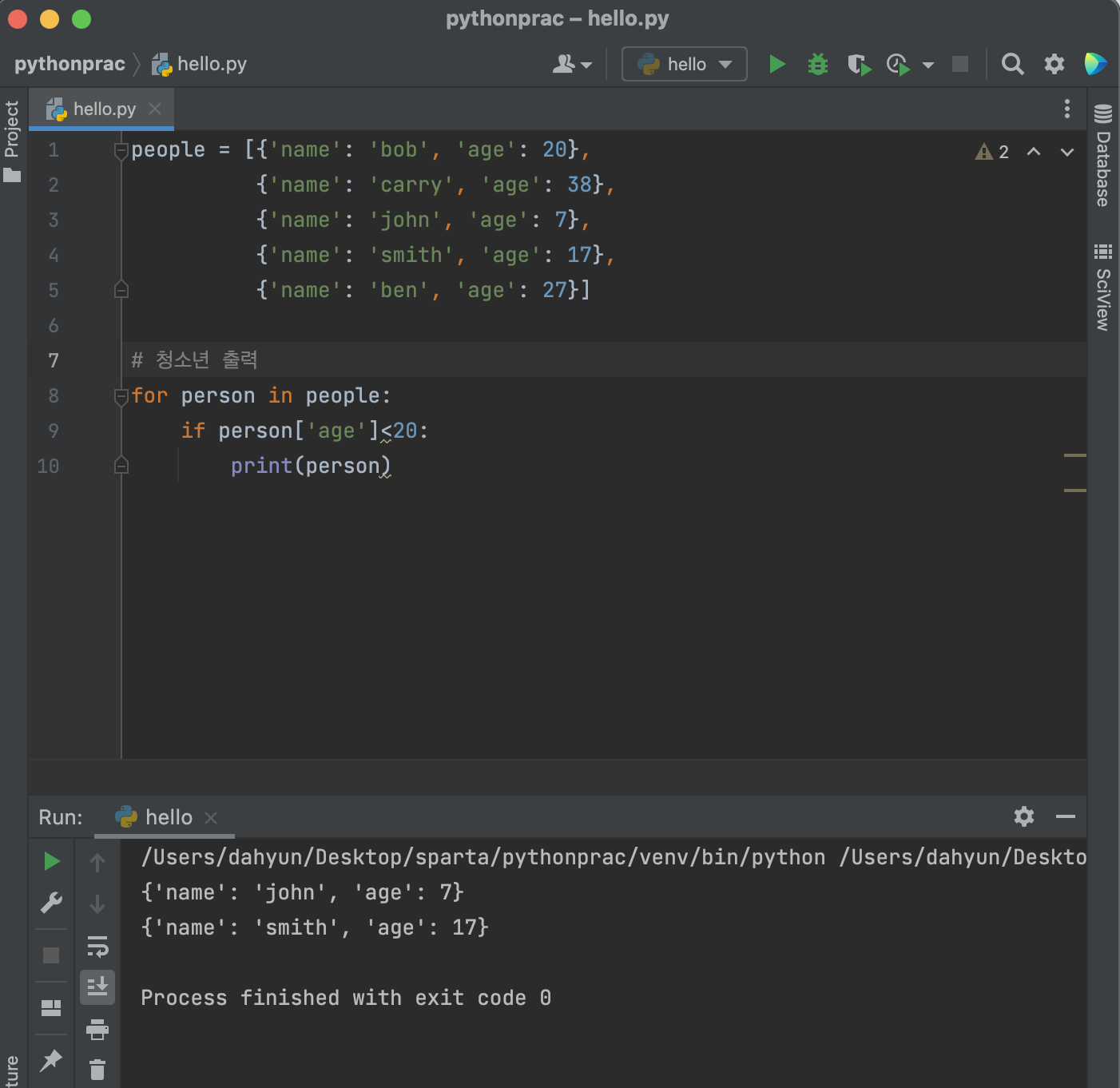
- 반복문을 이용해 구를 뽑아보기
차근차근~
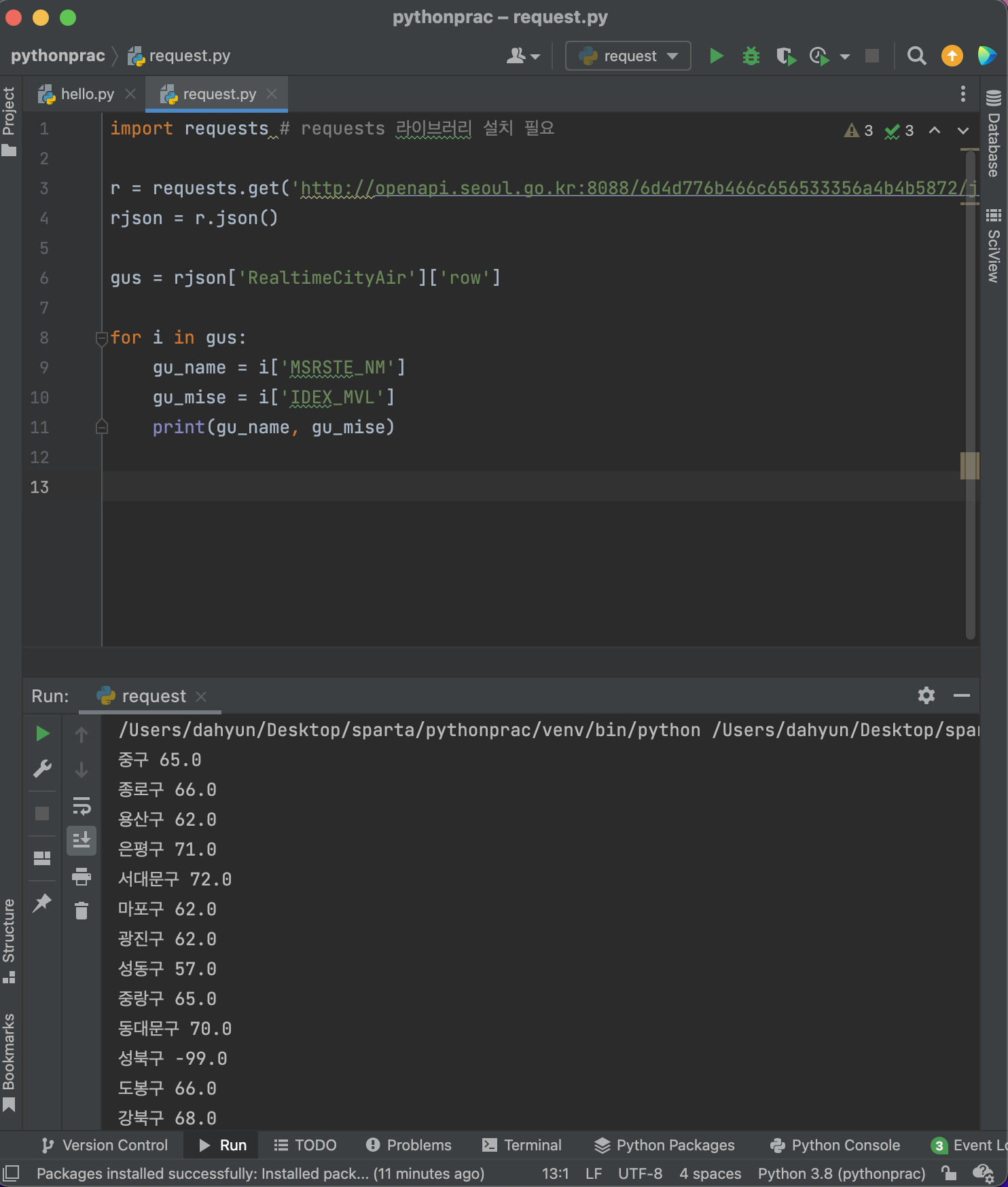
- 미세먼지 값이 70보다 큰 구만 뽑아보기

웹스크래핑(크롤링)
: 사이트 퍼오기
방법!
1. 브라우저를 키지 않고 요청하기 > reqests
2. 내가 원하는 정보만 뽑아내기 > bs4
크롤링을 하기 위해선,
beautifulsoup4 패키지 다운받아야함!(=bs4)
크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작순위, 영화명, 별점을 쭉 크롤링해보기.
⚠️ 겪은 문제
bs4 설치 했는데
cannot import name 'BeautifulSoup' from partially initialized module 'bs4'
오류가 발생한다. 설치했는데 왜 에러가 발생?

같은 폴더에 bs4.py가 있으면 안되는데, 파일 이름을 bs4.py로 정해서 에러가 발생한 것!
파일 이름을 바꾸면 해결 완료!
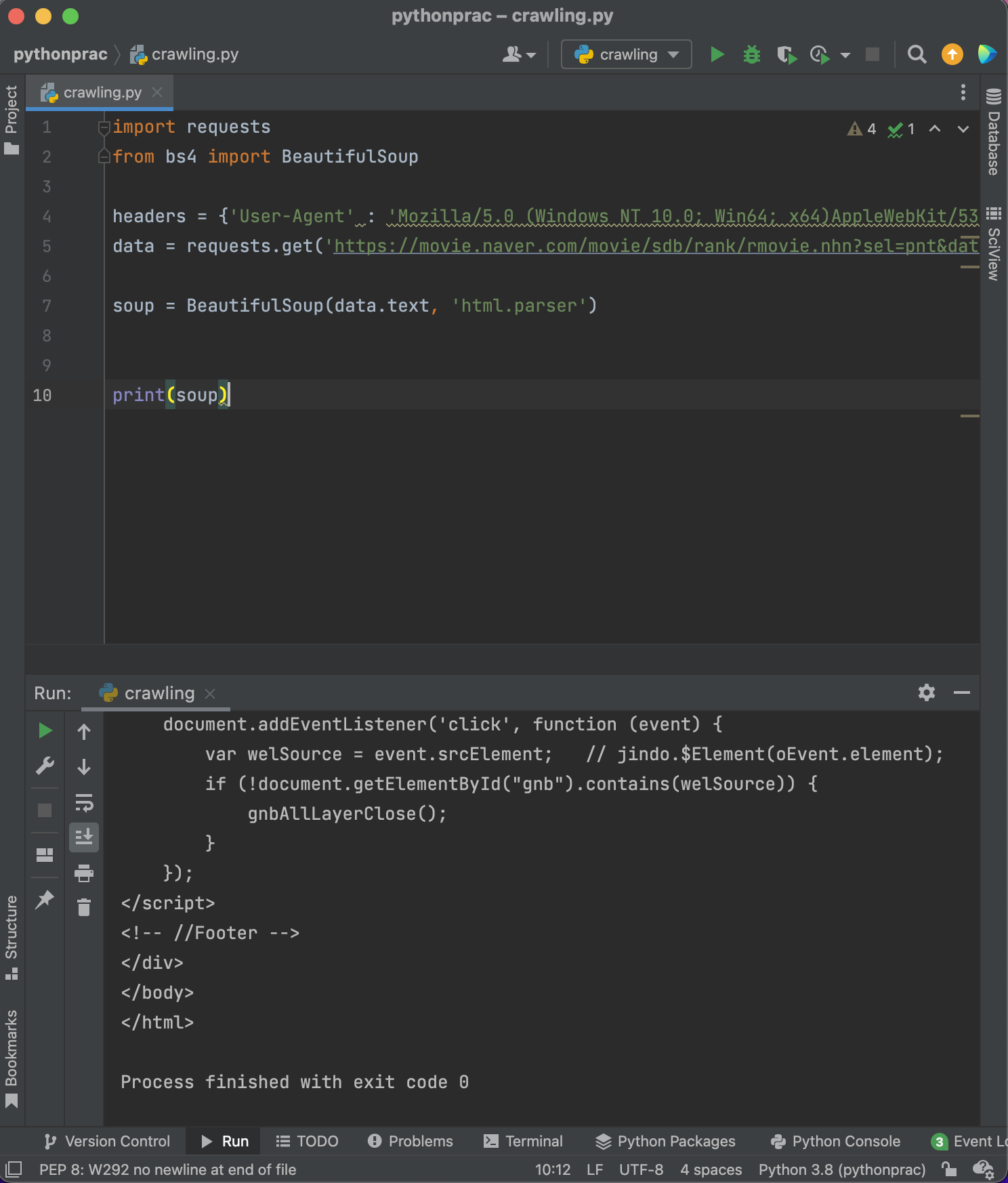
select / select_one
bs4를 사용하는 방법 2가지는 select와 select_one이 있다.
이는 선택자로, 내가 가져오고자 하는 정보의 위치를 알려준다.
select : 리스트로 여러개를 가져온다.
select_one : 하나를 가져온다.
select_one
우선 뽑고자하는 곳에서 검사>오른쪽클릭>copy>copy selector
ex. '그린북' 영화 추출하기

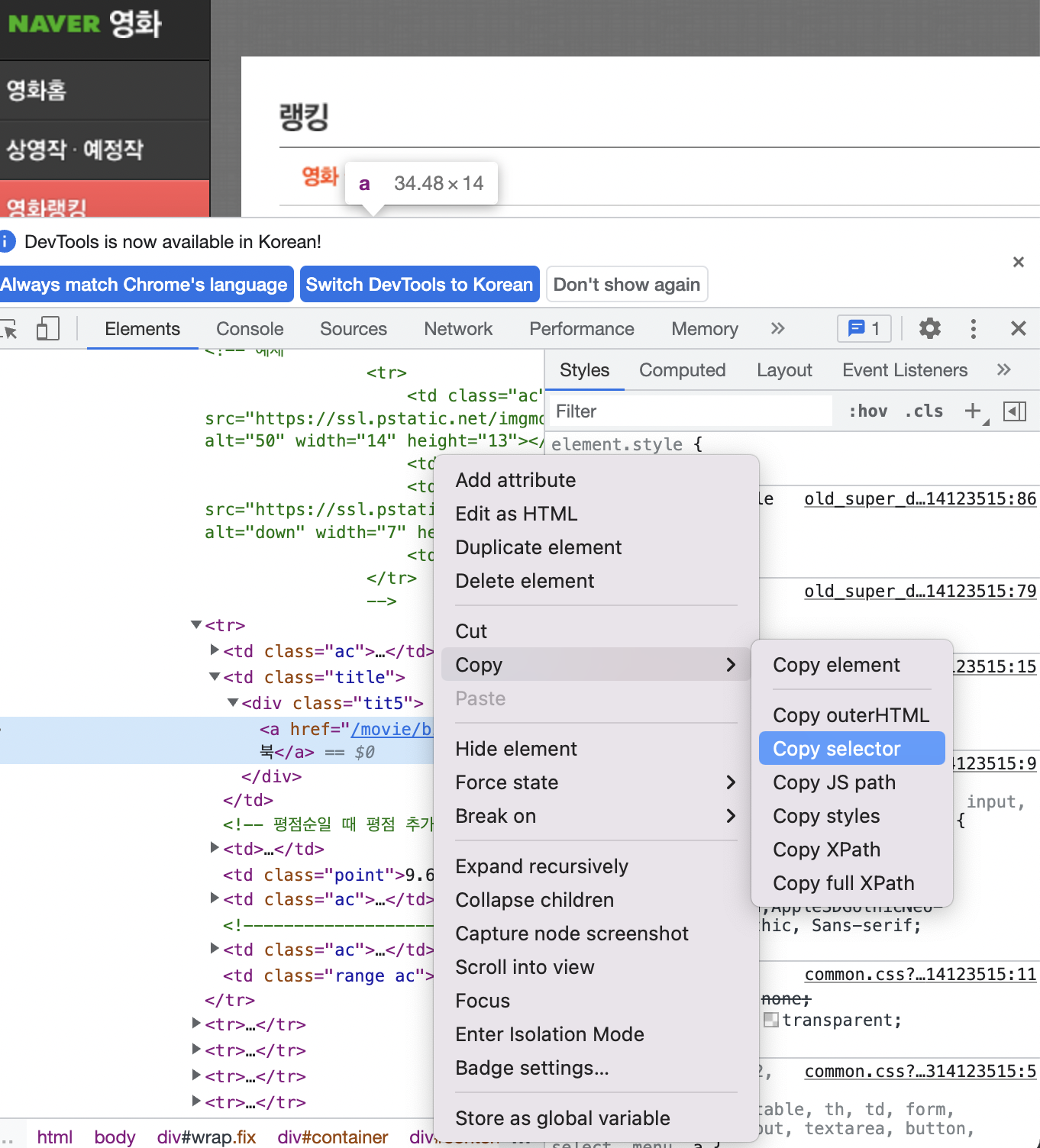
그후 ' '안에 복붙!
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
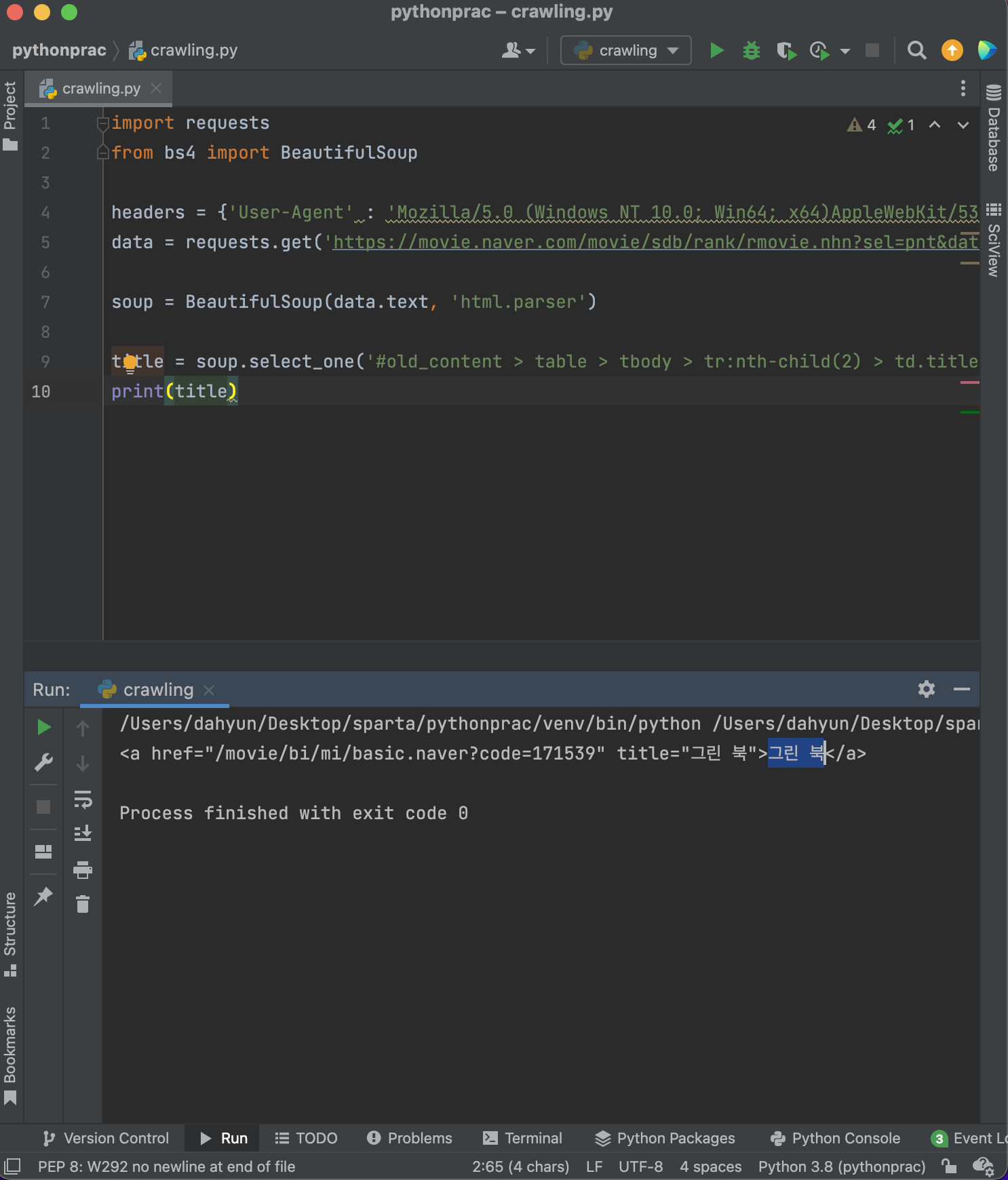
- 만약 태그와 태그 안에 있는 텍스트를 가지고 오고 싶다면?
.text를 이용하면 된다.

- 만약 속성을 가지고 오고 싶다면? 꺽쇠 이용하기!
['href']를 이용하면 된다.
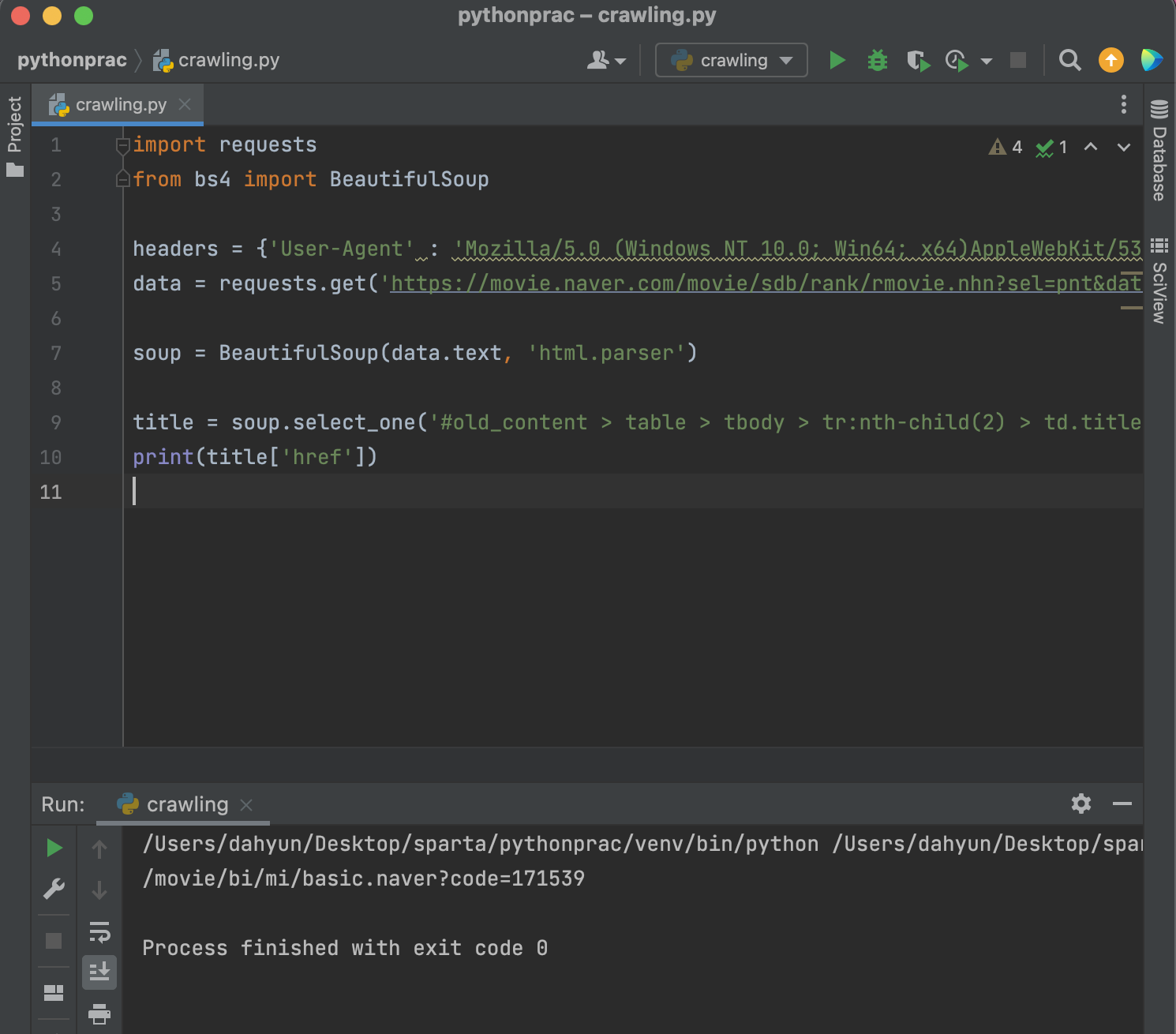
select
영화의 순위, 이름, 평점을 가져오고싶으면?
여러 영화 출력이니까 select
똑같이 copy>copy selector!
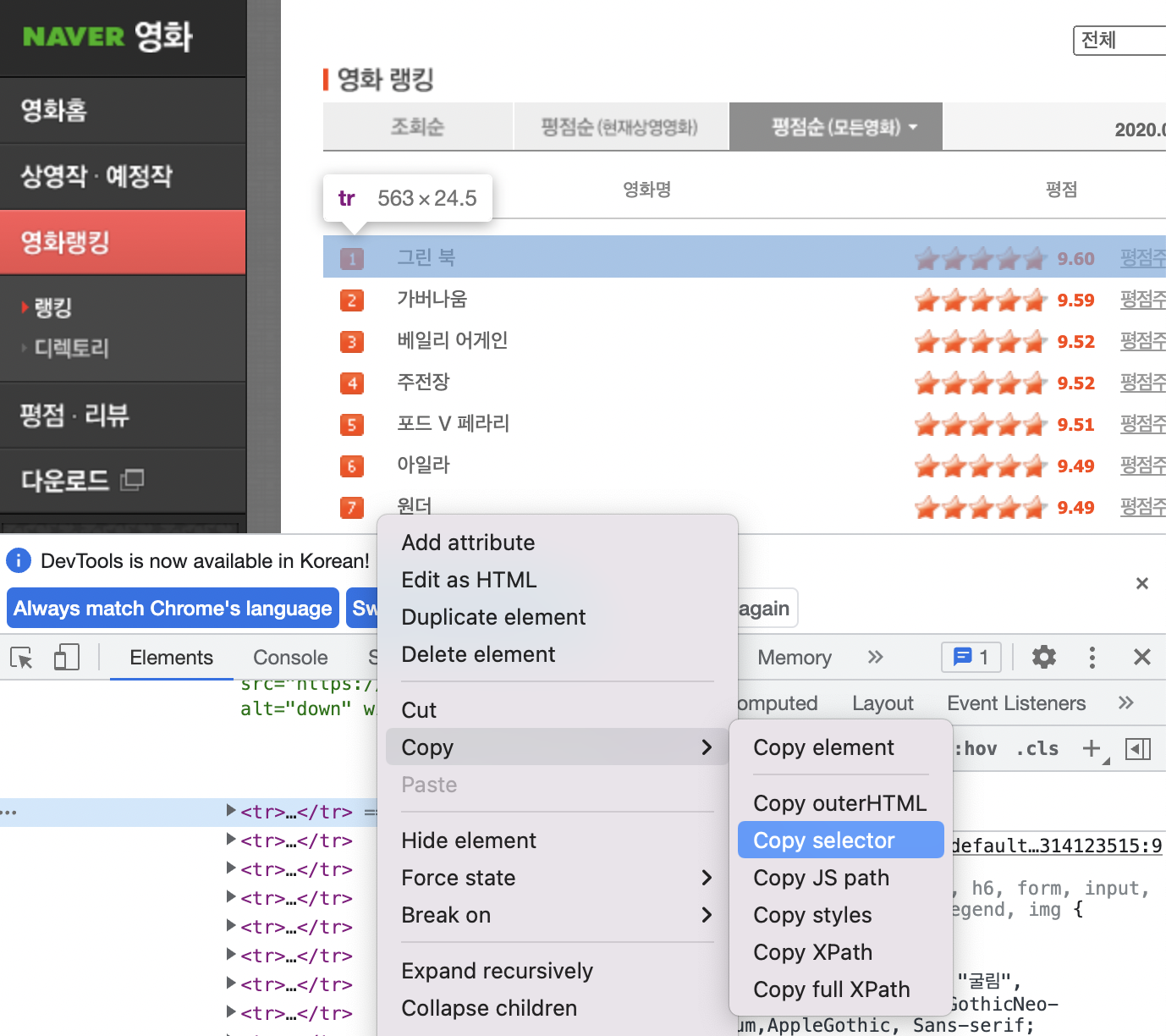
영화 1번째는
#old_content > table > tbody > tr:nth-child(2)
영화 2번째는
#old_content > table > tbody > tr:nth-child(3)
따라서 중복적인
#old_content > table > tbody > tr
를 입력하면 영화 목록 전체를 가져올 수 있다.
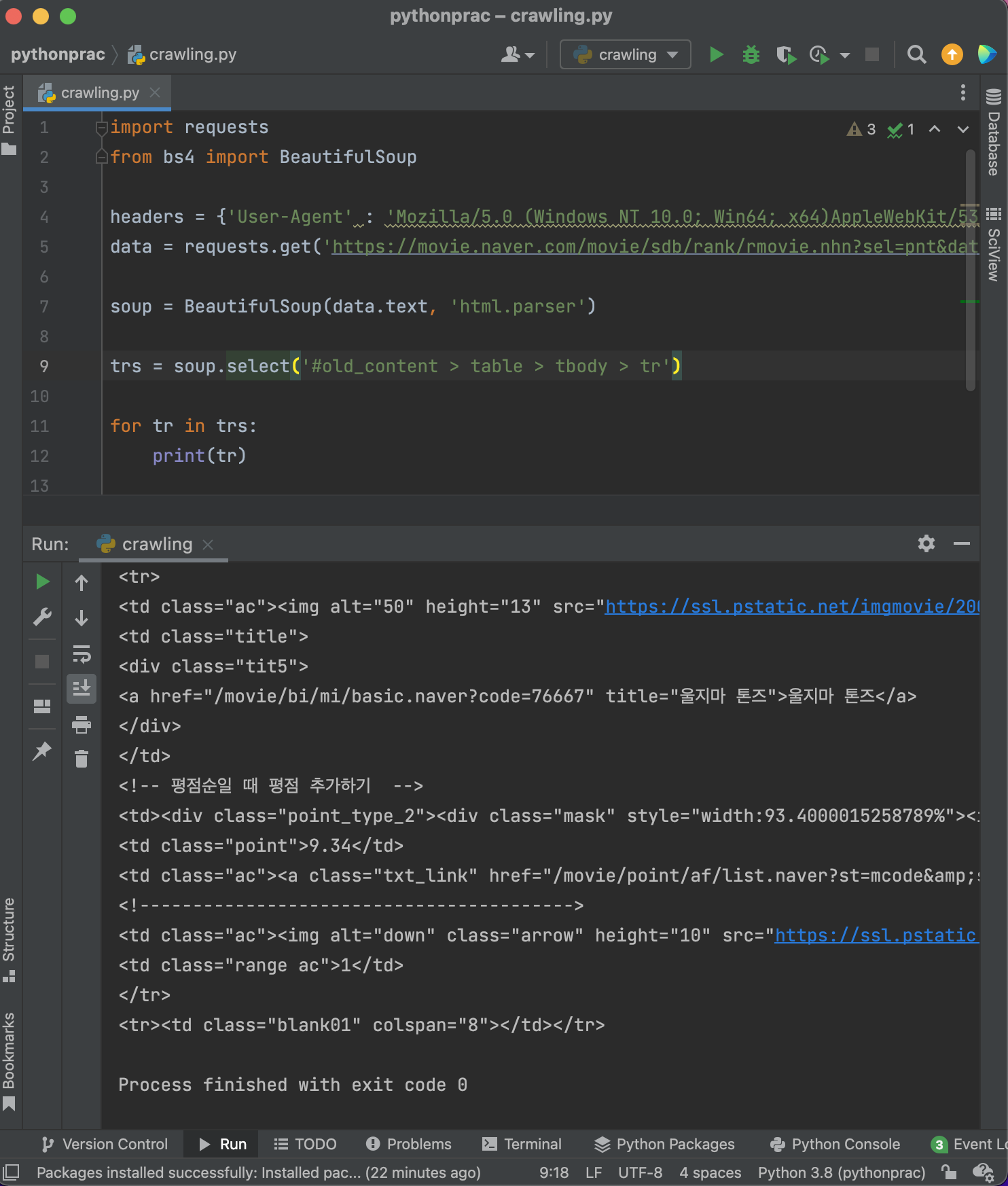
이 안에서 title을 찾아보자!
해당 부분을 다시 copy>copy selector
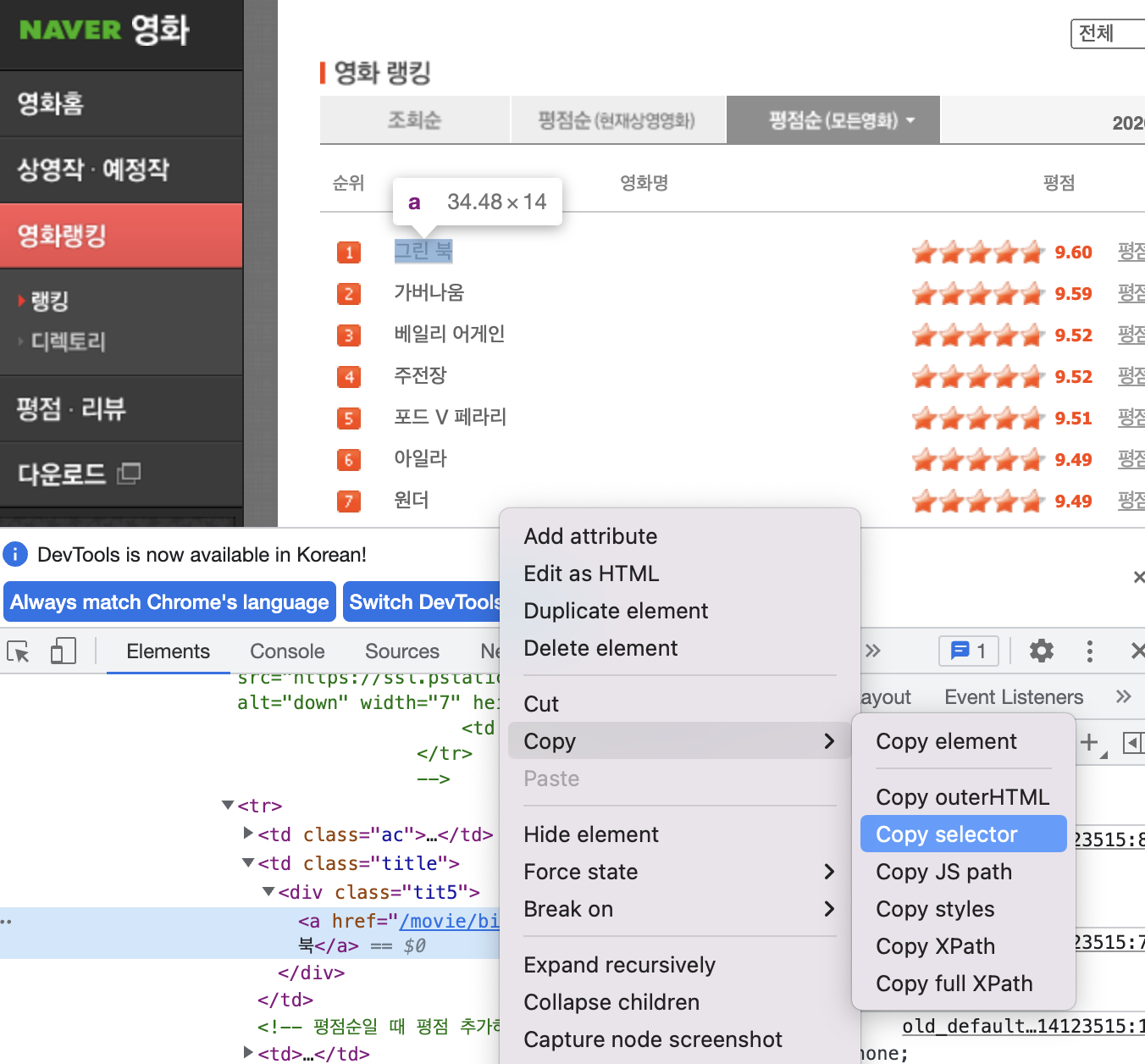
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
이 부분에서 title 부분(td.title > div > a)만 뽑아서 넣어주면 된다.
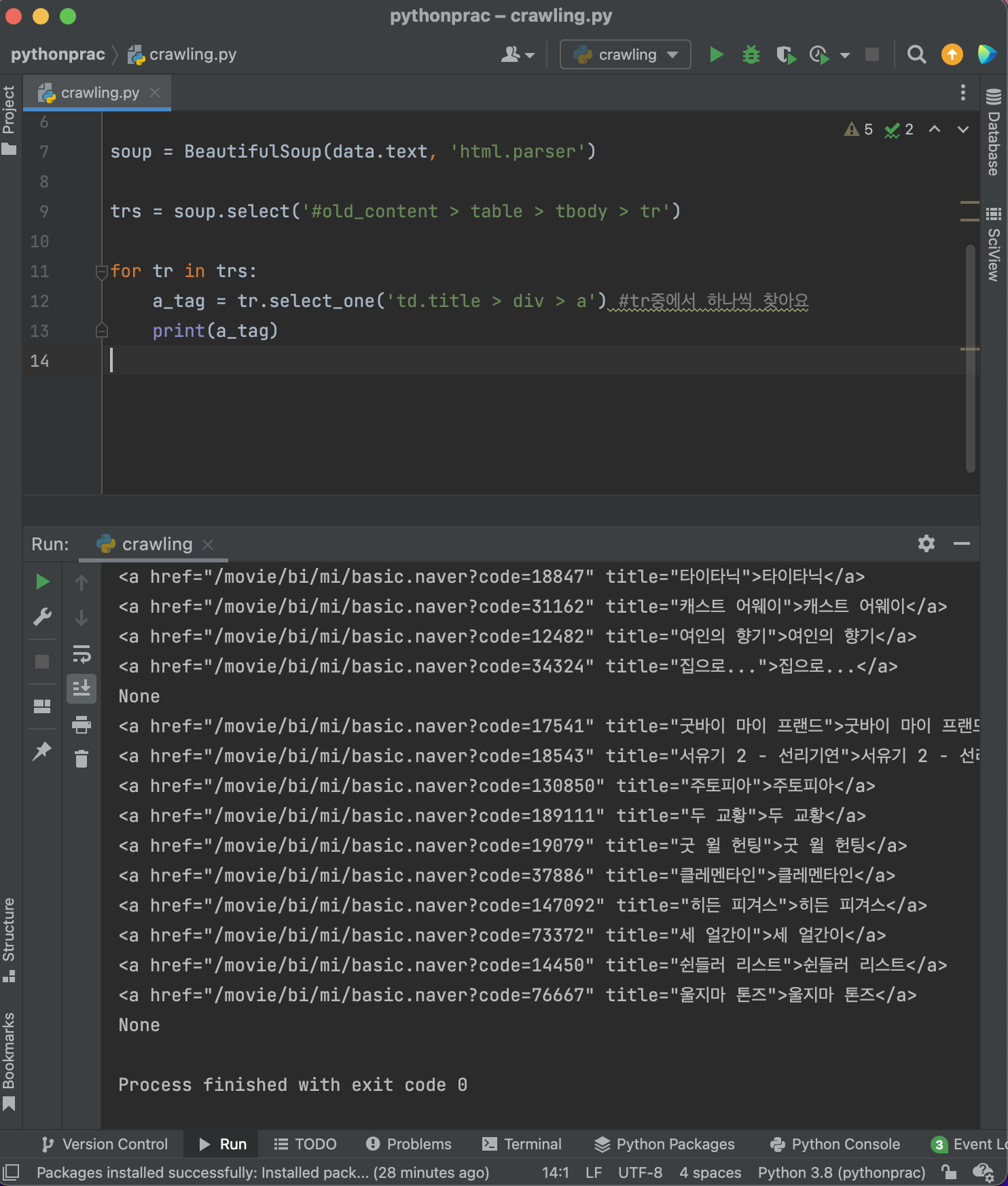
그런데 결과화면을 보니까 None이라는 애가 있다.
빈줄이라던지 화면상에 제목이 없는 부분에서 출력된 것!
None을 지워보자!
None이 아닐때 a_tag를 가져오면 된다.

그럼 텍스트만 가져온다면? .text를 쓰면 된다!
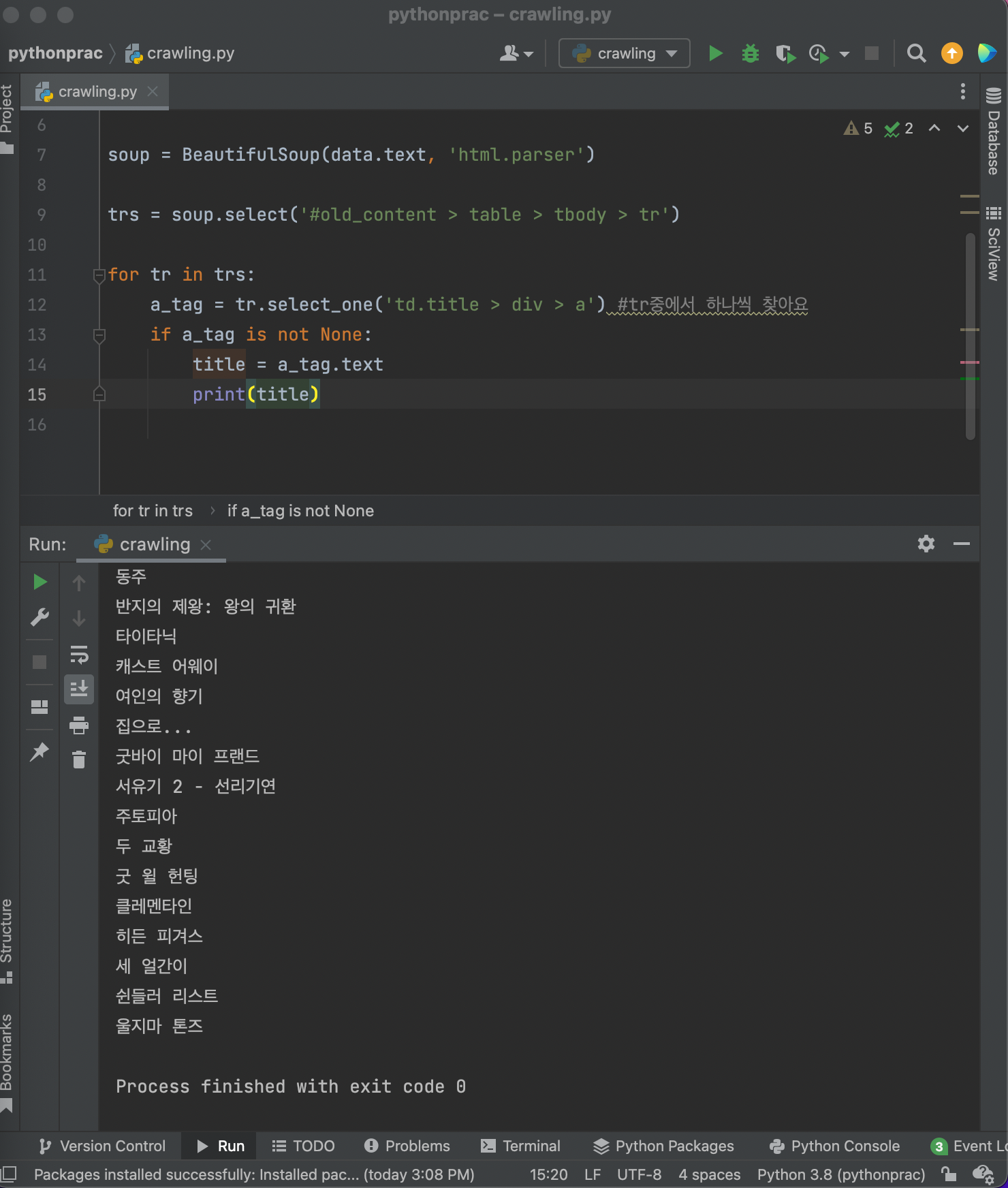
순위, 평점 가져오기!
⚠️ 겪은 문제
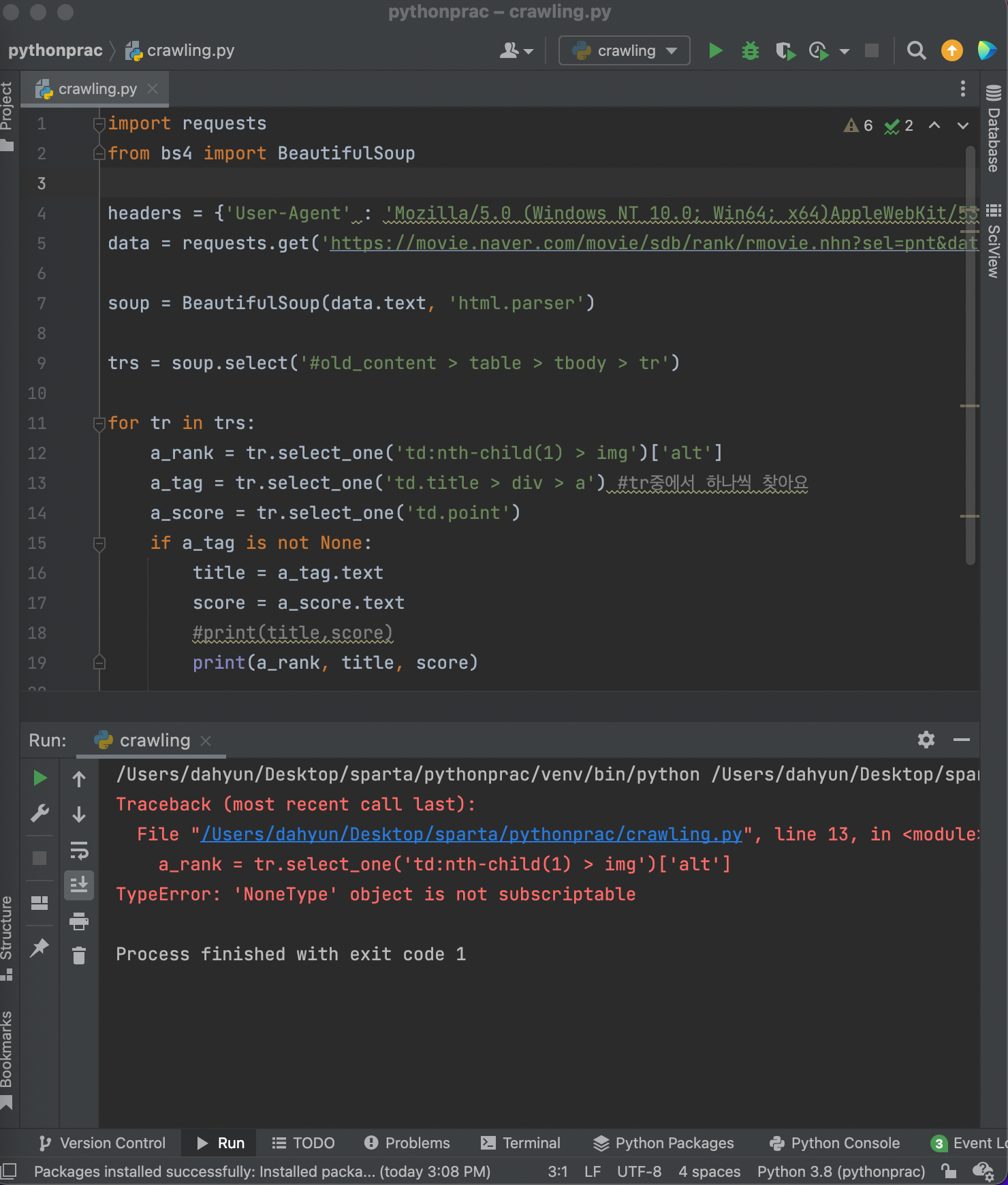
순위에도 None이 있어서 없애줘야하는데, a_tag와 동시에 어떻게 없앨수 있지..?
순서가 잘못됨.
if~is not None:
밑에다가 넣었어야했음

DB설치 확인
크롬 창에 localhost:27017 이라고 쳤을 때, 아래와 같은 화면이 나오면 mongoDB가 잘 돌아가고 있는 것
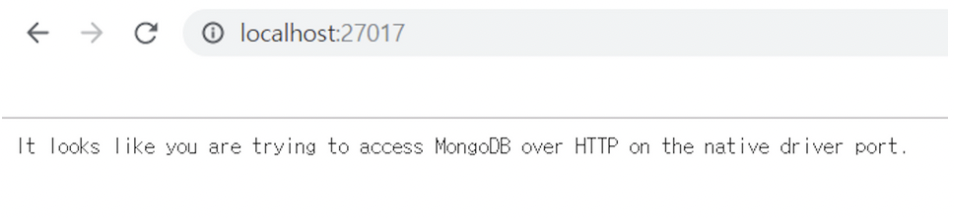
- robo 3T 준비하기
robo 3T : MongoDB의 데이터를 보기 위해 사용하는 프로그램
SQL vs NoSQL
- RDBMS(SQL)
행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사합니다. 데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 어려울 것입니다. 그러나, 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이할 수 있습니다.
ex) MS-SQL, My-SQL 등
- No-SQL
딕셔너리 형태로 데이터를 저장해두는 DB입니다. 고로 데이터 하나 하나 마다 같은 값들을 가질 필요가 없게 됩니다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있습니다.
ex) MongoDB
pymongo로 DB 조작하기
pymongo 라이브러리 설치
: mongoDB 프로그램을 조작하려면 pymongo가 필요
- pymongo 설치하기
Pycharm > Preferences > Python Interpretor > pymongo 설치
- pymongo 기본 코드
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# 코딩 시작pymongo(insert)
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)Robo 3T에 추가된 것을 볼 수 있다.
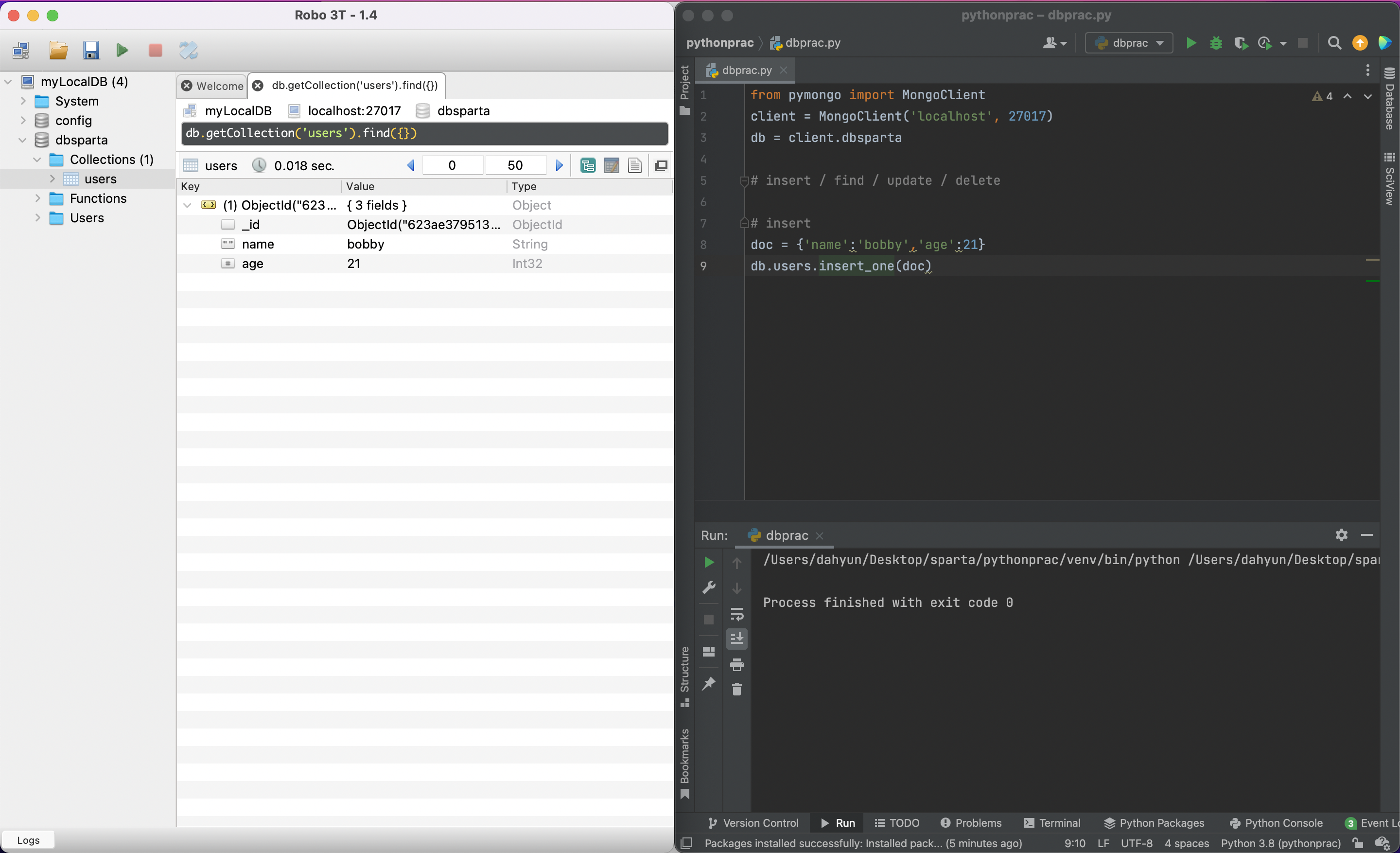
계속 추가하면 이렇게 쌓임
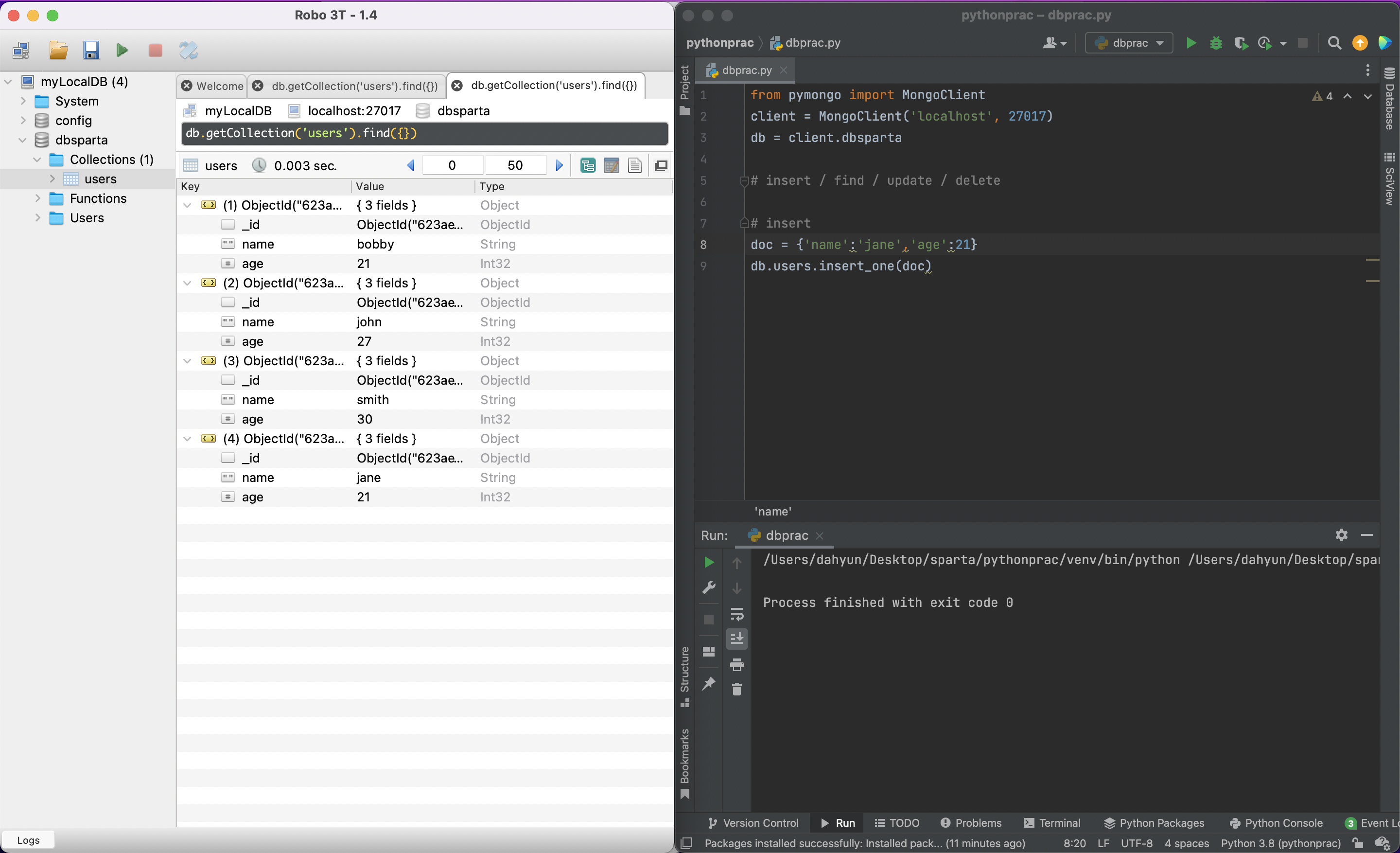
pymongo(find)
same_ages = list(db.users.find({'age':21},{'_id':False}))
리스트 안에 bobby가 들어왔고 jane도 들어옴
둘다 age가 21이니까!
따라서 db.콜랙션이름.find({조건}) 으로 찾을 수 있음
{'_id':False}는 뭐지?
_id의 값은 나타내지 말아라라는 뜻.
안쓰면 아래처럼 id가 출력됨!
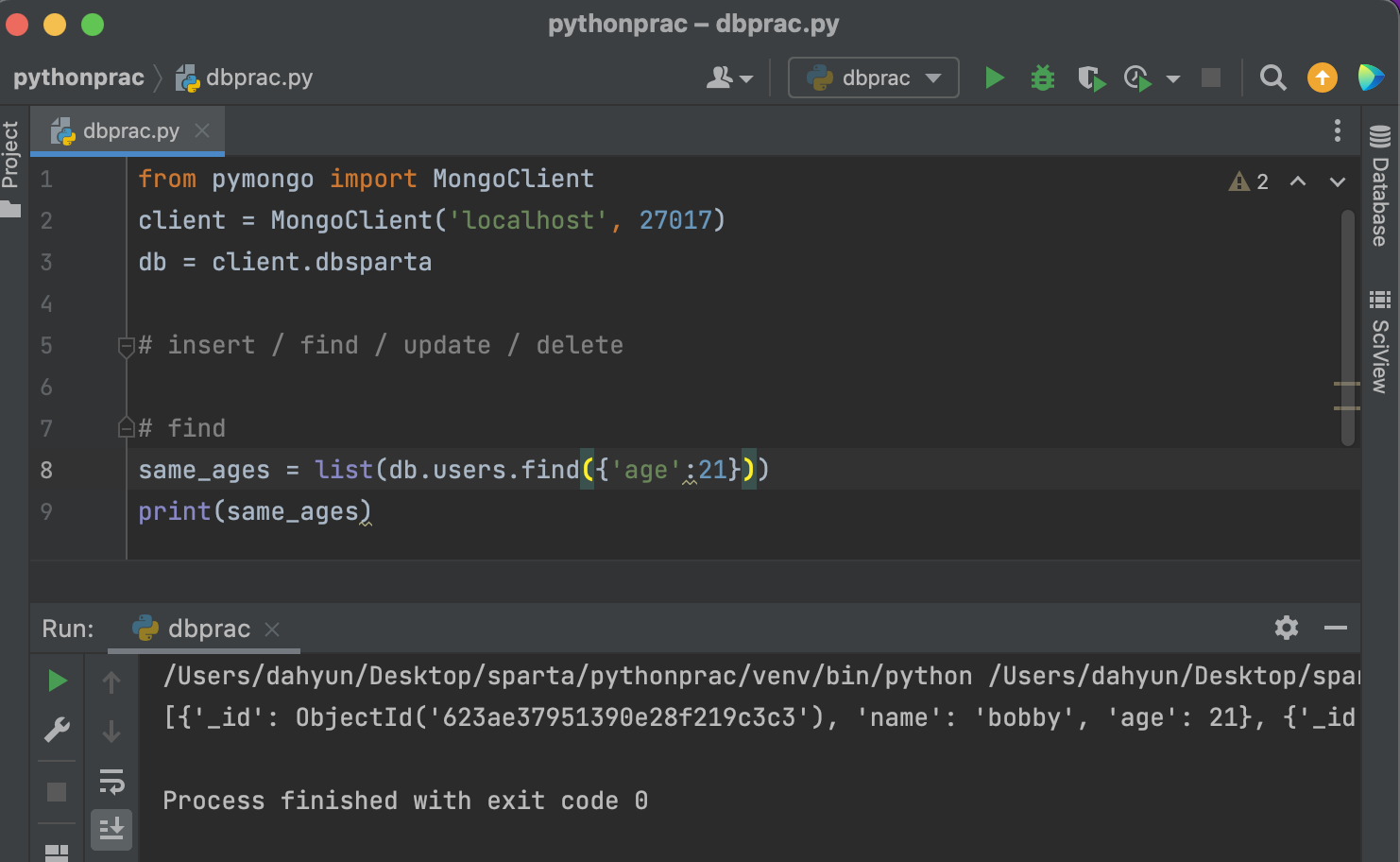
조건 주는 반복분(나이 21살)
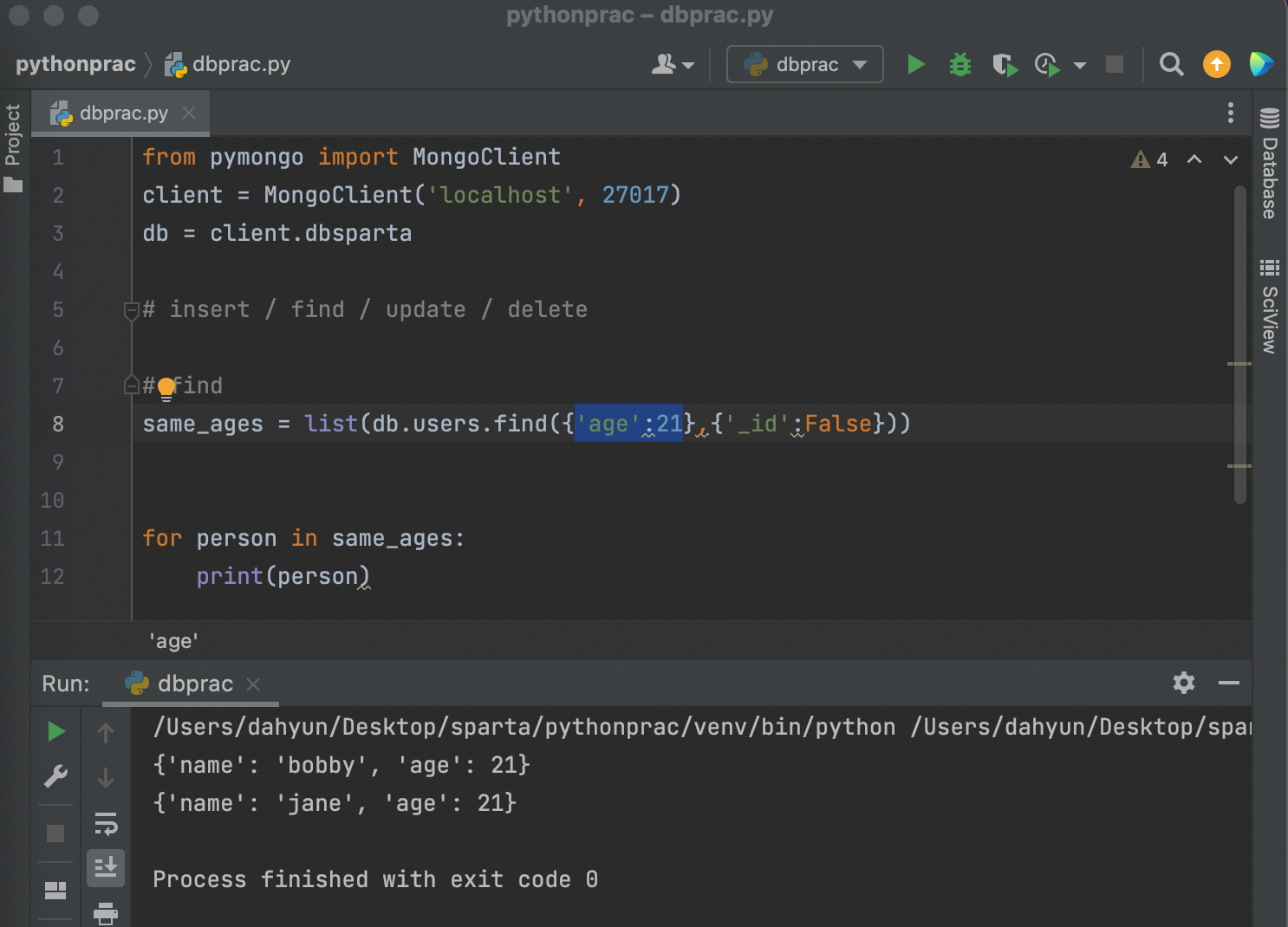
조건 없이 모든 document를 find -> 빈중괄호를 쓰면 된다.

그렇다면 list로 말고 하나씩만 추출하려면?
bobby 하나만 가져오면 다음과 같음.
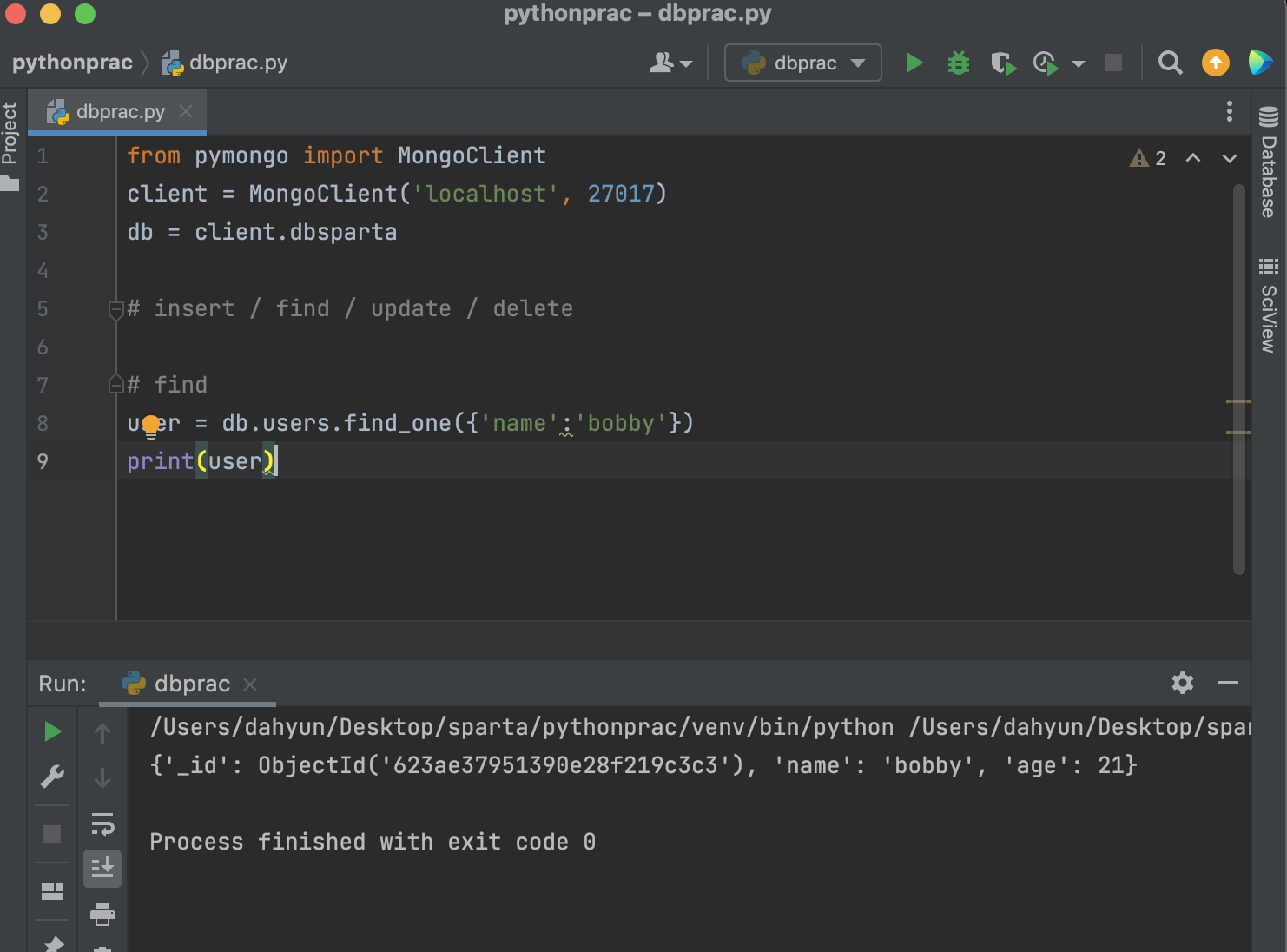
id출력안하는게 깔끔하고 좋으니까 다시!
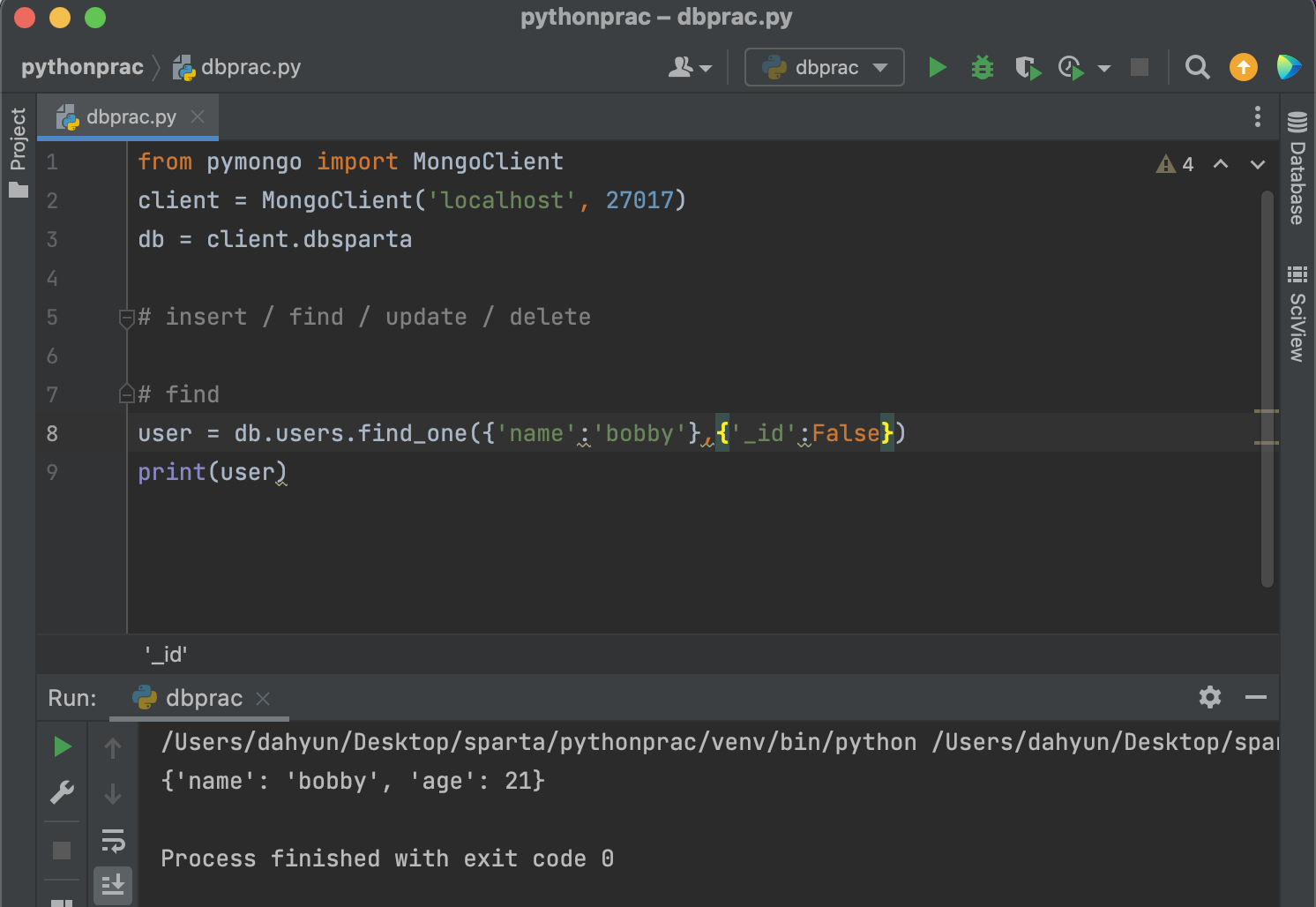
bobby의 age만 출력하려면?
print(user['age'])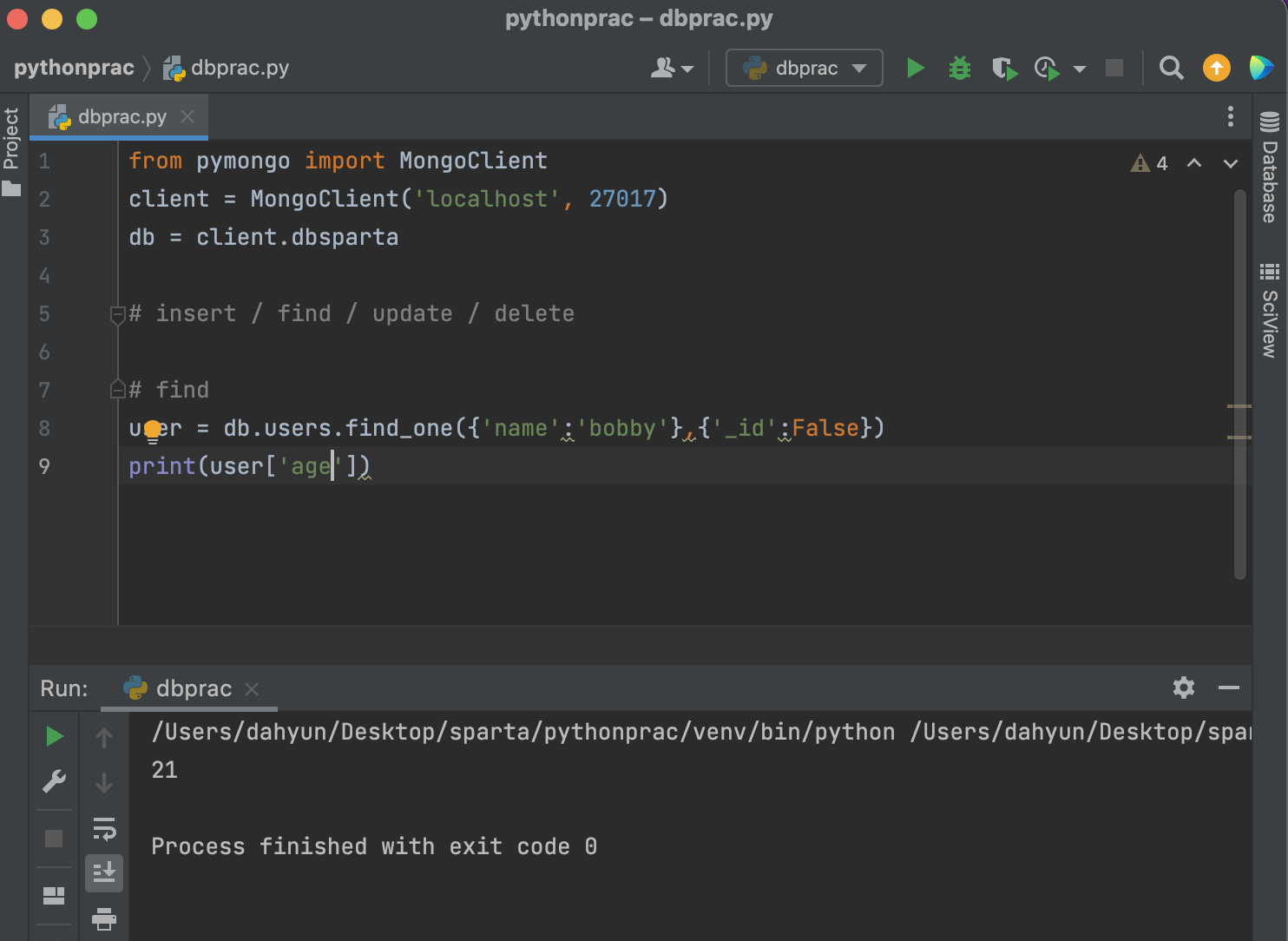
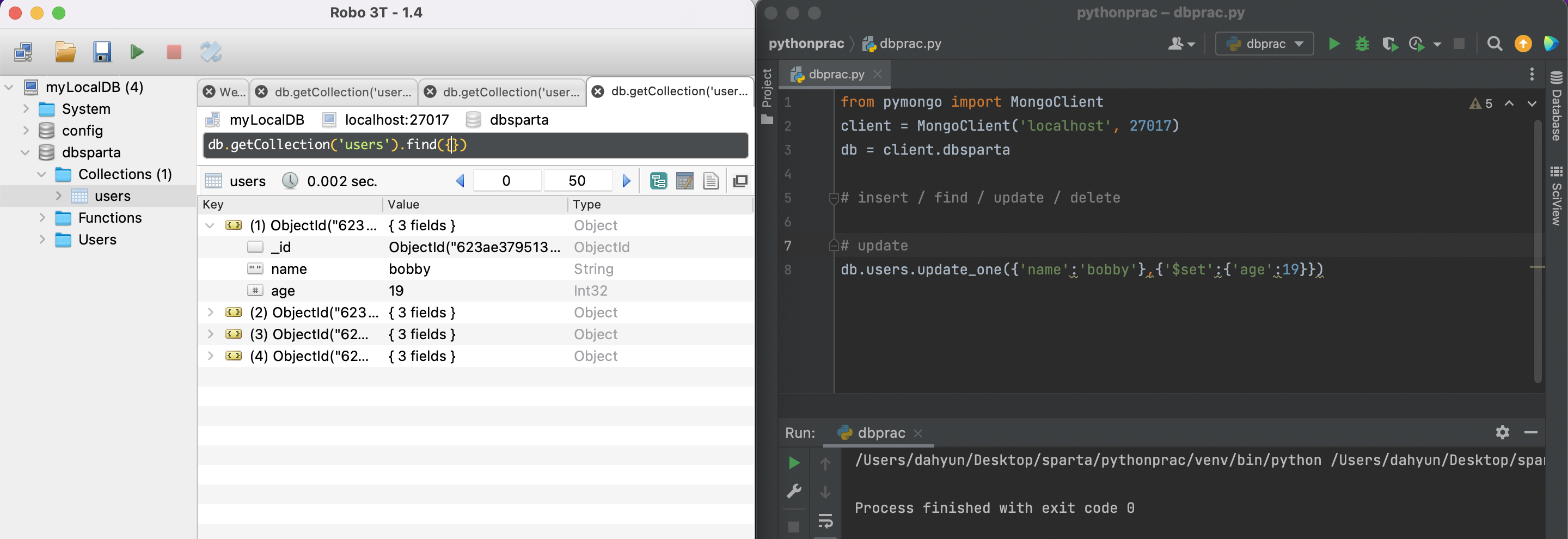
pymongo(update_one)
이름이 bobby의 age를 19로 변경(update)해라
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})Robo 3T를 보면 bobby의 나이가 변경된 것을 볼 수 있다.
pymongo(update_many)
잘 안쓰이긴함.
이름이 bobby인 애를 모두 찾아서 age를 19로 변경해라
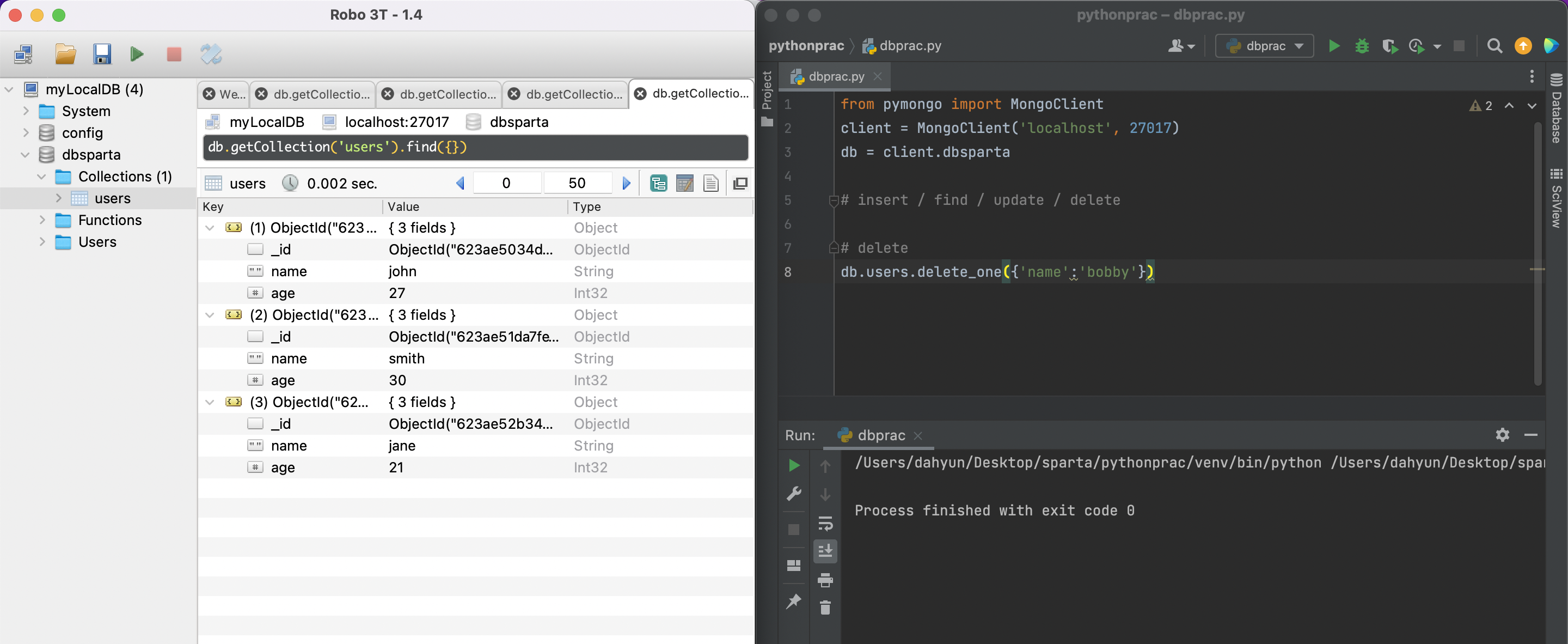
db.users.update_many({'name':'bobby'},{'$set':{'age':19}})pymongo(delete_one)
얘도 거의 안씀.
이름이 bobby인 애를 지워라
db.users.delete_one({'name':'bobby'})bobby가 사라짐.
pymongo(delete_one)
얘도 거의 안씀.
이름이 bobby인 애를 모두 지워라
db.users.delete_many({'name':'bobby'})pymongo 코드 요약
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# 코딩 시작
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})웹스크래핑 결과를 DB에 저장해보기
위에서 만들었던 영화 웹스크래핑을 이용!

import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a') #tr중에서 하나씩 찾아요
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
score = tr.select_one('td.point').text
print(rank, title, score)위의 코드에서
윗부분에 pymongo 기본 코드 입력 후
doc 생성, insert_one 코드 작성하면 됨!

QUIZ
(1) 영화제목 '매트릭스'의 평점을 가져오기
find_one 사용
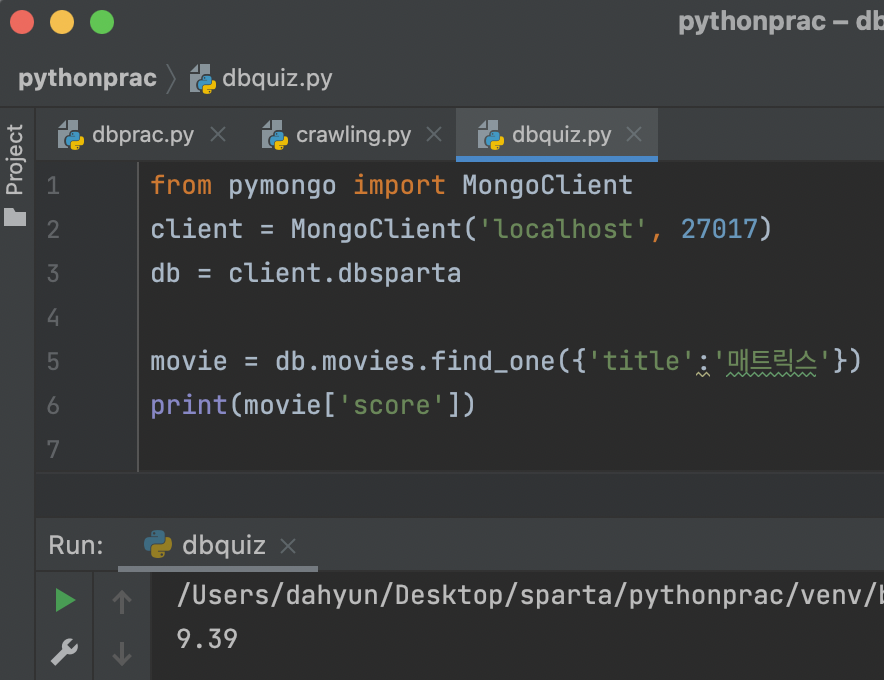
(2) '매트릭스'의 평점과 같은 평점의 영화 제목들을 가져오기

(3) 매트릭스 영화의 평점을 0으로 만들기

Robo3T를 보면 score가 ""로 문자열인 것을 알 수 있다.
따라서 update할때 통일을 위해서 '0'이렇게 넣어주는게 좋음.
그냥 0쓰면 숫자형으로 바뀌니까!
📚 지니뮤직 1~50위 스크래핑
Q) 1~50위의 순위, 제목, 가수 스크래핑하세요.
기본 세팅 코드 + html 잘 뜨는지 확인
import requests
from bs4 import BeautifulSoup
# DB 넣기 위한 기본 코드
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# html코드가 잘 print 되는지 확
print(soup)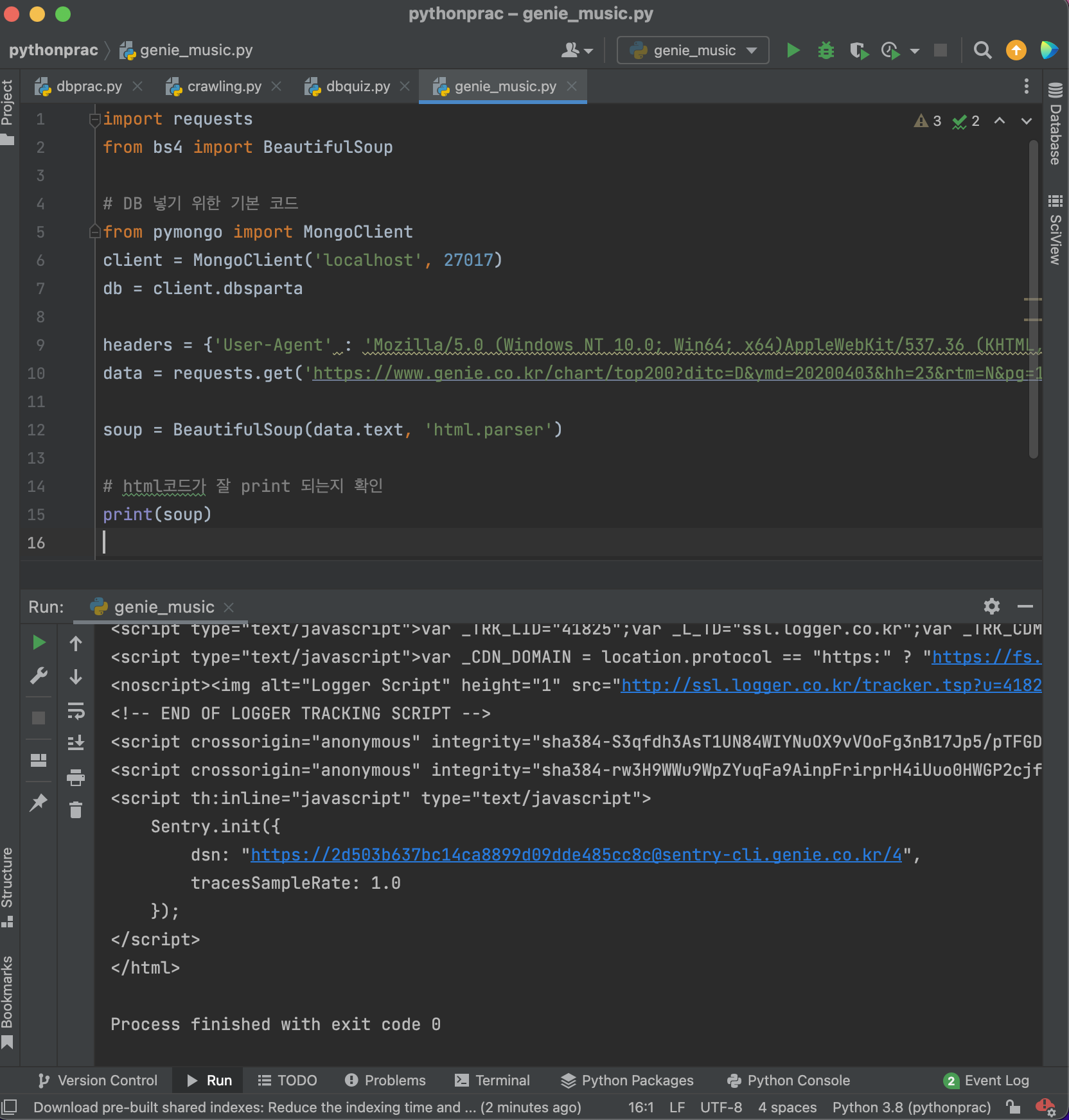
확인 완료!
⚠️ 겪은 문제
rank에서 1, 1상승 단어 2개가 출력됨. 1만 출력해야하는데,,
그리고 모양이 한줄로 안나오고 이상하게 나옴
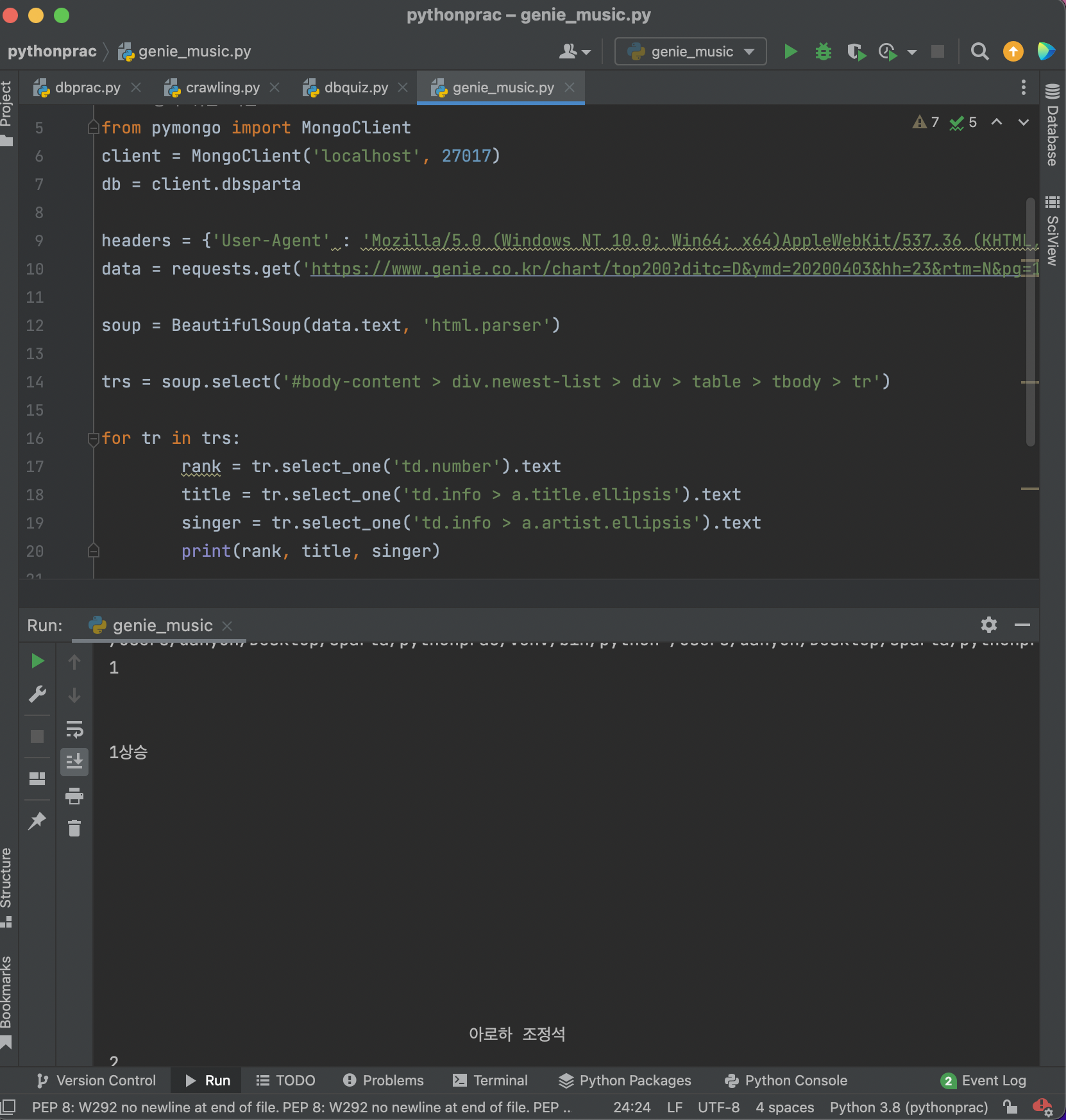
해결방법!
- 1 1상승 ~ 50 4하강 이니까 앞에서부터 2개만 단어 출력하면됨!
코드 수정 전
rank = tr.select_one('td.number').text코드 수정 후
rank = tr.select_one('td.number').text[0:2]- 파이썬 내장 함수인
strip()이용하기
코드 수정 전
for tr in trs:
rank = tr.select_one('td.number').text[0:2]
title = tr.select_one('td.info > a.title.ellipsis').text
singer = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, singer)코드 수정 후
for tr in trs:
rank = tr.select_one('td.number').text[0:2].strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
singer = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, singer)strip()
strip()을 이용하면 문자열에서 특정 문자를 제거
strip([chars]) : 인자로 전달된 문자를 String의 왼쪽과 오른쪽에서 제거
strip() : 양쪽 공백 모두제거
- 완성 코드
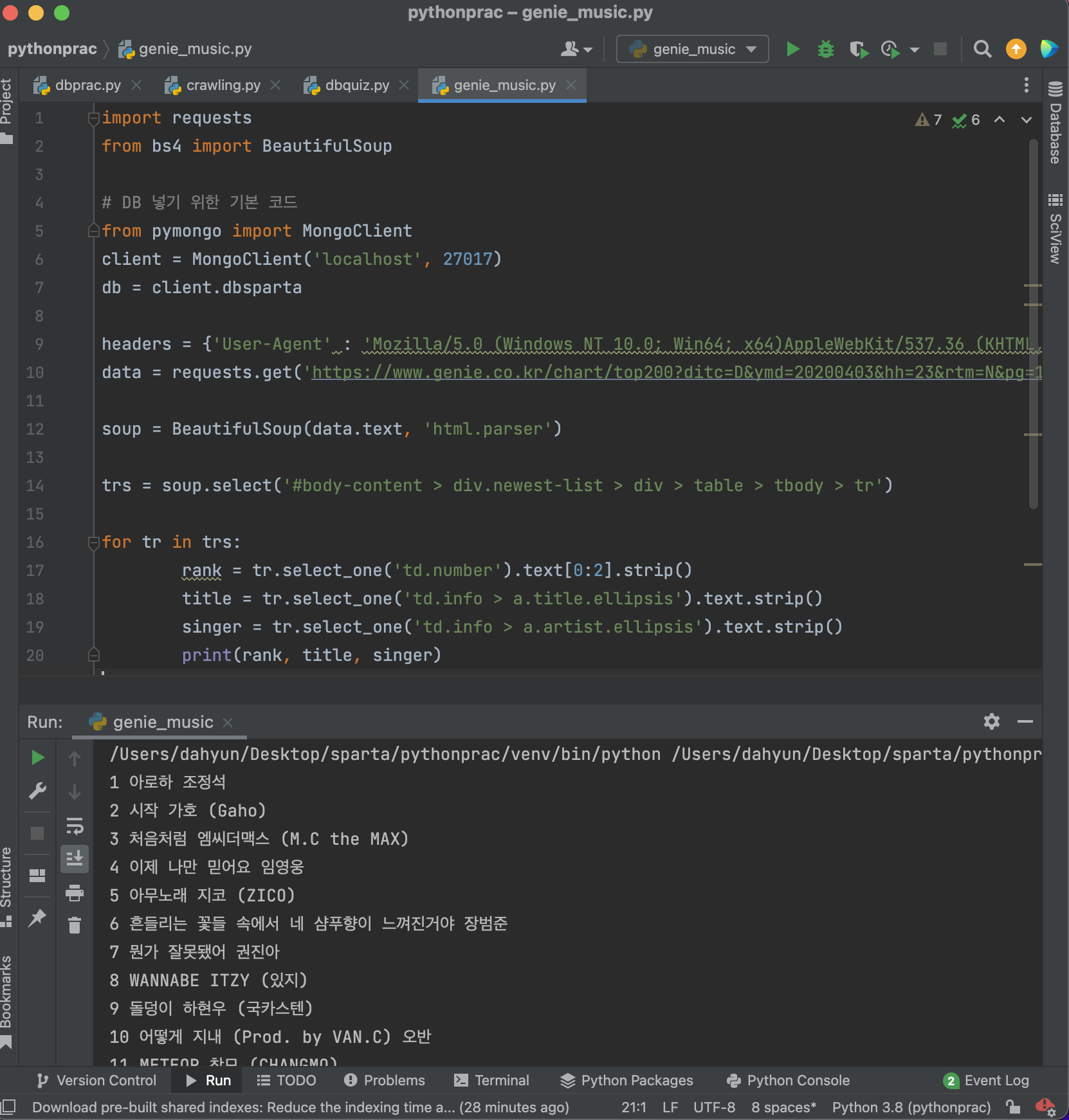
import requests
from bs4 import BeautifulSoup
# DB 넣기 위한 기본 코드
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text[0:2].strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
singer = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, singer)
