Parsing HTML file
When API is not provided, we need to scrape the data from the website.
Scraping is pulling data from the web or a database.
Beautiful Soup
is a Python library for pulling data out of HTML and XML files.
markup refers to all htlm
- Parser : what language HTLM or lxml (if error in parser, import lxml, use lxml as parser which is differnt way of understanding the content)
-lxml: If you get an error that says "bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: html-parser." Then it means you're not using the right parser, you'll need to import lxml at the top and install the module then use "lxml" instead of "html.parser" when you make soup.
from bs4 import BeautifulSoup
with open("website.html", encoding='UTF-8') as file:
contents = file.read()
soup = BeautifulSoup(contents, "html.parser" )
Access to the element in HTML
print(soup.title)
#<title>Angela's Personal Site</title>
print(soup.title.name)
#title
print(soup.title.string)
#content inside title : Angela's Personal Site
print(soup)
# the whole html file
print(soup.prettify())
#indented html file
returns the first element found
print(soup.a)
#returs the first anchor : <a href="https://www.appbrewery.co/">The App Brewery</a>
print(soup.li.string)
#returs the first list : The Complete iOS App Development Bootcampfind()
find_all()
find all of the content in 'a' tag & fetching each using for loop
all_anchor_tags = soup.find_all(name="a") #any tag names
print(all_anchor_tags)
[<a href="https://www.appbrewery.co/">The App Brewery</a>,
<a href="https://angelabauer.github.io/cv/hobbies.html">My Hobbies</a>,
<a href="https://angelabauer.github.io/cv/contact-me.html">Contact Me</a>]find_all() & getText() with loop
if only wanted a text in the anchor tag
all_anchor_tags = soup.find_all(name="a") #any tag names
for tag in all_anchor_tags:
print(tag.getText())
#The App Brewery
#My Hobbies
#Contact Me
find_all() & get() with loop
href stores actual link, fetch only links
all_anchor_tags = soup.find_all(name="a") #any tag names
for tag in all_anchor_tags:
print(tag.get("href"))
#https://www.appbrewery.co/
#https://angelabauer.github.io/cv/hobbies.html
#https://angelabauer.github.io/cv/contact-me.htmlfind() & tag, id
Unlike find_all(), find() only finds the first item matches the query
heading = soup.find(name="h1", id="name")
print(heading)
<h1 id="name">Angela Yu</h1>
find() & tag, class_
Class keyword is a reserved keyword in Python, only be used in creating a class, but we want to tap into an attribute, so add underscore after class so it won't clash.
section_heading = soup.find(name="h3", class_="heading")
print(section_heading)
#<h3 class="heading">Books and Teaching</h3>
print(section_heading.getText())
#Books and Teaching
print(section_heading.name) #name of the particular tag
#h3
print(section_heading.get("class"))
#['heading']Select()
select(selector=) & Narrowing down with CSS selectors
When it might not work, narrowing down the path with CSS selectors
select_one returns first matching item #a tag sits inside p tag
- select_one will give first maching item
- select will give all matching items
company_url = soup.select_one(selector="p a")
print(company_url)
#<a href="https://www.appbrewery.co/">The App Brewery</a>select(selector=#id/ class)
#pound sign is for id
Narrown down on the div, and element.
Drill through using CSS selectors to get any item you want.
name = soup.select_one(selector="#name")
print(name)
#<h1 id="name">Angela Yu</h1>
heading = soup.select(".heading") # no keyword argument'selector=' works too.
print(heading)
# [<h3 class="heading">Books and Teaching</h3>,
<h3 class="heading">Other Pages</h3>]
Task. scraping a live website
split(): text split
max(num): get the max num
.index(num): get the index of the value in a list
from bs4 import BeautifulSoup
import requests
#parsing titles and links only
response = requests.get("https://news.ycombinator.com/")
yc_web_page = response.text
soup = BeautifulSoup(yc_web_page, "html.parser")
articles = soup.find_all("a", class_="storylink")
article_texts = []
article_links = []
for article_tag in articles:
text = article_tag.getText()
article_texts.append(text)
link = article_tag.get("href")
article_links.append(link)
article_upvote = [int(score.getText().split()[0]) for score in soup.find_all(name="span", class_="score")]
largest_num = max(article_upvote)
largest_index = article_upvote.index(largest_num)
# print(articles)
print(article_texts)
print(article_links)
print(article_upvote)
print(max(article_upvote))
print(largest_index)
print(article_texts[largest_index])
print(article_links[largest_index])
print(largest_num)
# print(int(article_upvote[0].split()[0]))is Web Scraping legal?
- reCAPTCHA for catching robots
- root url/robots.txt for what they allow
- Limit your rate: 1 min
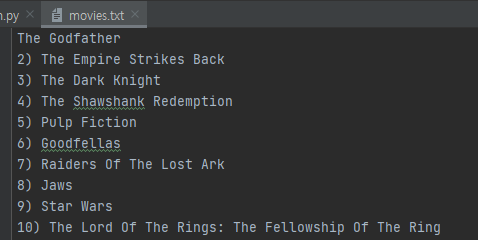
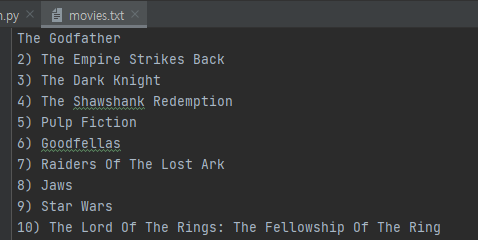
Project. 100 Movies You Must Watch
Reverse the list using slice(start, end, step)
start & end is ::
step -1 means reverse
from bs4 import BeautifulSoup
import requests
URL = "https://www.empireonline.com/movies/features/best-movies-2/"
response = requests.get(URL)
web_page = response.text
soup = BeautifulSoup(web_page, "html.parser")
list_of_movies = soup.find_all("h3", class_="title")
# print(list_of_movies)
movie_titles = [rank.getText() for rank in list_of_movies]
print(movie_titles)
movies = movie_titles[::-1] #reverse the list using slice
#1
with open("movies.txt", mode="w", encoding='UTF-8') as file:
for movie in movies:
file.write(f"{movie}\n")
#2
for n in range(len(movie_titles) -1, -1, -1):
print(movie_titles[n])Result