TIL Python Basics Day 47 - Create an Automated Amazon/E-COM Price Tracker
Udemy Python Course

All I wanted to do is fetching your price!!!!!
It took a whole day to get it :(
Project
Goal: Scrape price from e-commerce website. If its price is lower than our target lowest price, send a price alert email.
1. Amazon
capcha kept me from scraping. When reading Q&A from Udemy, others got away with this problem by trying different solutions:
-header user-agent: defined
-http://myhttpheader.com/
-code below only to see print None
if price is not None:
price = price.getText()
someone said it might be to do with the amazon server. I ended up giving up on amazon and started scraping korean e-commerce website.
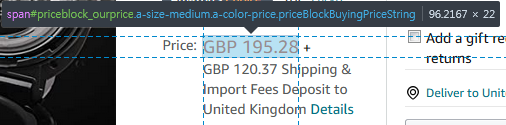
price = soup.find(id="priceblock_ourprice").get_text()for price history: camelcamelcamel
Final Code
import requests
from bs4 import BeautifulSoup
import lxml
url = "https://www.amazon.com/Cuckoo-CRP-P0609S-Cooker-10-10-11-60/dp/B01JRTZVVM/ref=sr_1_4?qid=1611738512&sr=8-4"
#url = "https://www.amazon.com/Cuckoo-CRP-P0609S-Cooker-10-10-11-60/dp/B01JRTZVVM/ref=sr_1_4?qid=1611738512"
#https://www.amazon.com/Duo-Evo-Plus-esterilizadora-vaporizador/dp/B07W55DDFB/ref=sr_1_4?qid=1597660904
#https://www.amazon.com/Cuckoo-CRP-P0609S-Cooker-10-10-11-60/dp/B01JRTZVVM/ref=sr_1_4?dchild=1&keywords=cuckoo+rice+cooker&qid=1611738512&sr=8-4
header = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36",
# "User-Agent":"Defined",
"Accept-Language": "en-GB,en-US;q=0.9,en;q=0.8"
}
response = requests.get(url, headers=header)
soup = BeautifulSoup(response.content, "lxml")
print(soup.prettify())
price_get = soup.find(id="priceblock_ourprice")
price_text = price_get.getText()
price_without_currency = price_text.strip("$")
price_as_float = float(price_without_currency)
print(price_as_float)
2. Gmarket
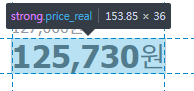
price = soup.find(class_="price_real").getText()import requests
from bs4 import BeautifulSoup
URL = "http://item.gmarket.co.kr/Item?goodscode=1918627515"
headers={
"User-Agent": "Defined",
}
response = requests.get(URL, headers=headers).text
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())
price = soup.find(class_="price_real").getText()
3. SSG.com

Learning
- Korean won have comma as a divider. To compare the price, I need to convert it into int.
To strip the comma, I used replace()
get_price.replace(',', '')- Korean language caused "'ascii' codec can't encode characters" problem. When I added '.encode()', It seemed working fine; however, It sent some random english words in the body of email. I couldn't figure out how to fix it, so I simply changed the content into English.
product_title = soup.find(class_="cdtl_info_tit").getText().encode()
#--------------------ssg.com----------------------
import requests
from bs4 import BeautifulSoup
import lxml
URL = "http://www.ssg.com/item/itemView.ssg?itemId=1000025465383&siteNo=6004&salestrNo=6005&tlidSrchWd=%EB%A9%94%EC%9D%B4%ED%94%8C%ED%8A%B8%EB%A6%AC%20%EC%9C%A0%EC%82%B0%EA%B7%A0&srchPgNo=1&src_area=ssglist"
headers={
"User-Agent": "Defined",
}
response = requests.get(URL).text
soup = BeautifulSoup(response, "html.parser")
# print(soup.prettify())
get_price = soup.find(class_="ssg_price").getText()
# print(get_price)
price_str = get_price.replace(',', '')
# print(price_str)
price = int(price_str)
# print(type(price))
product_title = soup.find(class_="cdtl_info_tit").getText().encode() #smtplib 'ascii' codec can't encode characters
# print(product_title)
link_to_buy = URL
# print(link_to_buy)
#--------------------EMAIL---------------
import smtplib
my_email = "testpythondy@gmail.com"
my_password = "P"
yahoo_email = "testpythondy@yahoo.com"
target_price = 18000 #15420
if price < target_price:
with smtplib.SMTP("smtp.gmail.com", port=587) as connection:
connection.starttls()
connection.login(user=my_email, password=my_password)
connection.sendmail(
from_addr=my_email,
to_addrs=yahoo_email,
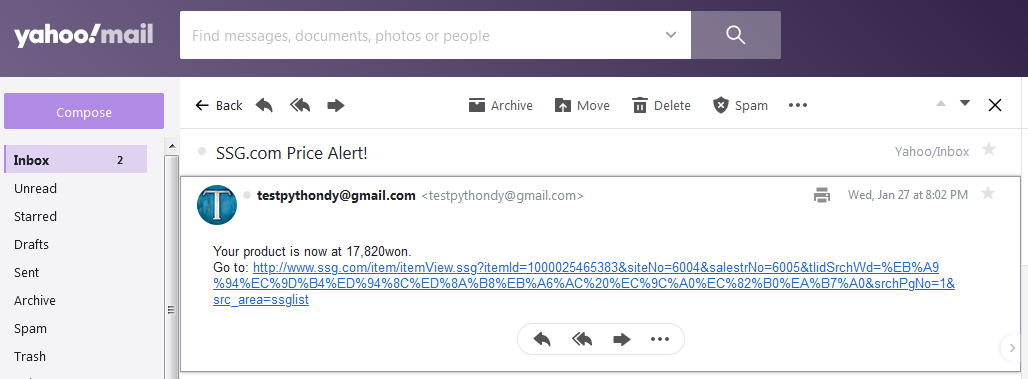
msg=f"Subject: SSG.com Price Alert! \n\n Your product is now at {get_price}won. \n Go to: {URL}")Note I left at Udemy Q&A
I also struggled with this project. I kept getting captcha message when I tried with my own header infomation and different amazon product(which I searched from Amazon and has a different URL.)
-
I fixed this problem by copying Angela's header information instead of my actual one.
-
I had to modify the URL of the product that I picked.
Anglea's example:
https://www.amazon.com/Duo-Evo-Plus-esterilizadora-vaporizador/dp/B07W55DDFB/ref=sr_1_4?qid=1597660904
I compared the structure of URL with Angela's exmaple one and matched it in a similar format.
However, it's not very stable. It sometimes works and sometimes doesn't. I have no idea why. I hope it helps anyone having a same problem. Also if anyone knows more stable way, let us know!
