최근에 카카오 사건으로 인해 늦었지만 한번 정리하고 넘어갈 필요가 있다고 생각되어 위에 영상을 보면서 DR에 대해 공부해보았다.
SLA
SLA는 서비스를 제공하는 기업과 서비스의 혜택을 받는 기업 간의 문서화된 합의를 뜻합니다. 기존 SLA는 벤더와 고객 간의 서비스 기대치를 정의하지만 같은 조직 내 부서 간에도 적용할 수 있습니다.
- Amazon [https://aws.amazon.com/ko/legal/service-level-agreements/]
- Google Cloud [https://cloud.google.com/compute/sla]
- Naver [https://www.ncloud.com/policy/sla/svc]
재해 복구 용어
-
AWS, Google Cloud , Azure
-
RTO (Recovery Time Objective) : 복구 시간 목표
⇒ 재해 발생시 서비스가 복구되는 데 걸릴 수 있는 시간
-
RPO (Recovery Point Objective ) : 복구 시점 목표
⇒ 재해 발생시 데이터 손실을 얼마나 감당 할 수 있는지, 마지막 백업 이후 재해 발생 시점까지 경과된 시간
재해 복구 전략
- Hour, Minutes, Real-time
- Backup and Restore → ‘Hour’기준
- 하나의 서버
- Active / Passive → ‘Minutes’ 기준
- 액티브 버전 실패시 대기 상태의 리소스를 패시브 버전으로 보유
- Active / Active → ‘Real Time’ 기준
- 동일한 서버의 여러 복사본을 나란히 실행하고, 서버와 유저사이에 Load Balancer(2개) 사용해 사용가능한 서버로 전달
- 전형적인 재해 복구 유형
- DMS ( Database Migration Service)
AWS DMS
- https://docs.aws.amazon.com/ko_kr/dms/latest/userguide/Welcome.html
- https://velog.io/@chan9708/AWS-Certified-Solutions-Architect-Associate-20-AWS-재해-복구-및-마이그레이션-6jmjo49b#재해-복구-전략
- Active/Active 시스템에서 AWS 클라우드로 데이터베이스를 마이그레이션 하고 싶을 때 사용
- AWS DMS 복제 프로세스
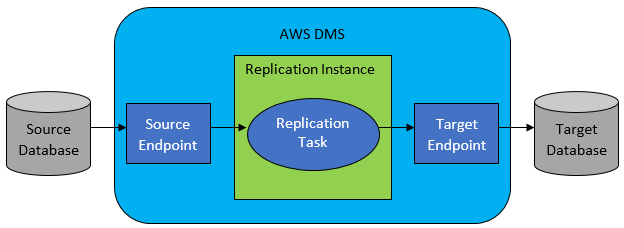
- 관계형 데이터베이스, 데이터 웨어하우스, NoSQL 데이터베이스 및 기타 유형의 데이터 저장소를 쉽게 마이그레이션할 수 있는 클라우드 서비스
테라폼
- 인프라를 쉽게 구축하고 안전하게 변경하고, 효율적으로 인프라의 형상을 관리할 수 있는 오픈 소스 도구
- Infrastructure as Code
- 인프라를 코드로 정의하여 생산성과 투명성을 높일 수 있고, 정의한 코드를 쉽게 공유해 효율적 협업
- Execution Plan
- 변경 계획과 변경 적용을 분리하여 변경 내용을 적용할 때 발생할 수 있는 실수 감소
- Resource Graph
- 사소한 변경이 인프라 전체에 어떤 영향을 미칠지 미리 확인 가능
- 종속성 그래프를 작성하여 이 그래프를 바탕으로 계획을 세우고, 이 계획을 적용했을 때 변경되는 인프라 상태를 확인
- Change Automation
- 여러 장소에 같은 구성의 인프라를 구축하고 변경할 수 있도록 자동화
- 인프라를 구축하는 데 드는 시간을 절약할 수 있고, 실수도 줄일 수 있다
넷플릭스와 카오스 몽키
- https://github.com/Netflix/SimianArmy/wiki/Chaos-Monkey
- 의도적으로 시스템에 장애를 일으켜 시스템의 탄력성을 더 높여준다.
- Chaos Monkey : 무기를 든 야생 원숭이가 데이터센터, 클라우드 영역에 들어와 무작위로 인스턴스를 파괴하고, 케이블을 끊더라도 중단없이 고객에게 서비스를 계속 제공한다는 개념
- Latency Monkey : Restful Client- 서버 통신간에 일부러 인위적인 지연을 발생시켜 서비스 저하를 발생시켜 정상적으로 업스트림 서비스가 반응하는지 측정
- Conformity Monkey : AWS 클라우드에서 모범사례에 대해 정의된 규칙을 따르지않는 인스턴스를 찾아 관리자에게 보고한다.
- Janitor Monkey : 클라우드 환경이 잡음이나 낭비 없이 작동하도록 보장해주고, 사용하지 않는 리소스들 을 찾고 제거할 수 있다.

success is within reach, allow yourself time