배민스토어의 WebFlux를 적용한 도입기 우아콘2023을 보고 정리한 글입니다.
https://youtu.be/pRpryoQphXQ?si=AYE3DWfrvrAETkG6
Spring WebFlux 는 웹 애플리케이션에 반응형 프로그래밍을 제공한다.
Reactive 디자인 의 비동기 및 비차단 특성 은 성능과 메모리 사용을 향상시킨다.
base
-
Spring WebFlux : Spring 5에서 도입된 모듈, 비동기(NonBlocking)와 반응형 프로그래밍을 기반으로한 웹 애플리케이션
-
반응형 프로그래밍 : 데이터 흐름과 변화를 다루는 프로그래밍 패러다임 ⇒ 비동기 처리가 중요 사항
-
Non-Blocking 하나의 작업이 끝날때 까지 기다리지 않고 다른 작업을 계속 수행할 수 있게 해준다.
⇒ 적은 수의 스레드로 많은 요청을 처리할 수 있고, 더 작은 하드웨어 리소스로 애플리케이션 성능을 확장할 수 있다. -
함수형 프로그래밍 : 함수를 객체 취급하여, 함수를 인자로 전달하거나 함수→함수로 반환할수 있다.
자바 8에서 람다 표현식의 도임으로 함수형 프로그래밍 지원을 시작
-
Project Reactor : Spring Web Flux의 기반이 되는 라이브러리, 비동기 데이터 스트림을 관리하는 데 유용한 기능 제공
- Mono, Flux를 사용해 데이터를 받아오거나 작업이 완료될때 신호(callback)를 보내준다.<br>
WebFlux : 패러다임의 변화
예) 가게 정보를 가져오는 로직 = Kotlin의 try-catch문을 이용해 로직을 이용해 작성해보자
val shop = try {
shopCacheRepository.findById(shopId)
} catch (e: Throwable) {
log.error("Received error on shop cache.", e)
null
}
return shop ?: shopDBRepository.findById(shopId) → after : Flux/Mono 의 어떤 연산자를 어떻게 조합해야 할까?
shopCacheRepository.findById(shopId)
.doOnError { e -> log.error("Received error on shop cache.",e) }
.onErrorComplete()
.switchIfEmpty { shopDBRepository.findById(shopId) }- 어떤 연산자의 어떻게 조합해야 하는지 초점을 맞추게 된다 → 지식이 경험적 지식 ⇒ 높은 러닝 커브
배민스토어가 그럼에도, WebFlux를 전면 도입한 이유
-
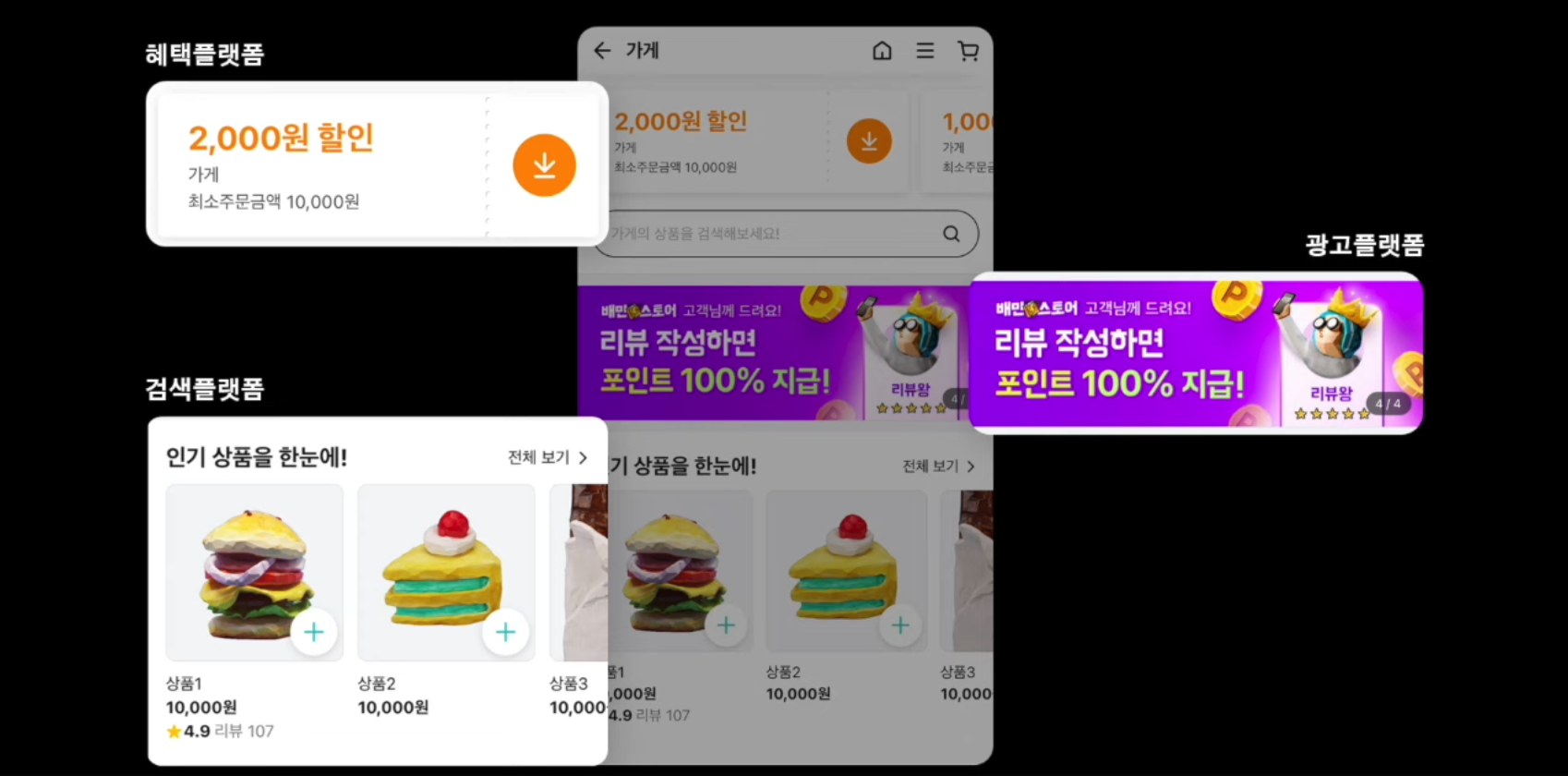
실시간으로 호출되는 외부 API 수의 증가
-
Blocking 방식을 사용했을 때 , 통신 중간의 thread를 점유하게 되고,
Non-Blocking 방식으로 호출하게 되면 Thread를 점유하지 않고 그 시간에 다른 작업에 Thread를 줄 수 있다. -
병렬적으로 호출하게 되면 응답시간을 단축할 수 있게 된다.
⇒ 배민 스토어에서는 전시 서비스에만 도입 하는 것 ,
Batch 성 로직을 사용하는 어드민, 워커에는 도입을 하지 않아 복잡한 로직이 필요없고 단순한 전시 API 단에서 WebFlux를 사용하여 러닝 커브를 상쇄 하고자 함
검증을 위한 질문
1. Spring WebFlux의 도입으로 성능이 개선되거나, 컴퓨팅 자원을 효율적으로 사용할 수 있게 되었는가?
- 이전보다 더 많은 요청을 받았는데도 빨라졌다.
- 데이터를 병렬적으로 가져오는 것이 일상이 되었다.
Mono.zip (
productService.getProductDetail(...),
productService.getProductOption(...),
promotionService.findActivePromotions(...)
). map { (product, shopOptions, promotions) -> ...but 성능, 효율적인 측면에서 변인이 통제된 자료를 만들지는 못함. 다른 조건을 동일하게 맞춘 상태에서 Spring MVC, Spring WebFlux간의 비교를 하지 못함
2. Project Reactor를 통해 배압을 고려해야하는 비즈니스 로직을 손쉽게 작성 할 수 있었는가?
Batch성 로직에서는 프로젝트 리액터의 장점이 잘 살아난다고 판단, 반면 API 로직에서는 ??
들어가기 앞서 배압에 대해 알아보자
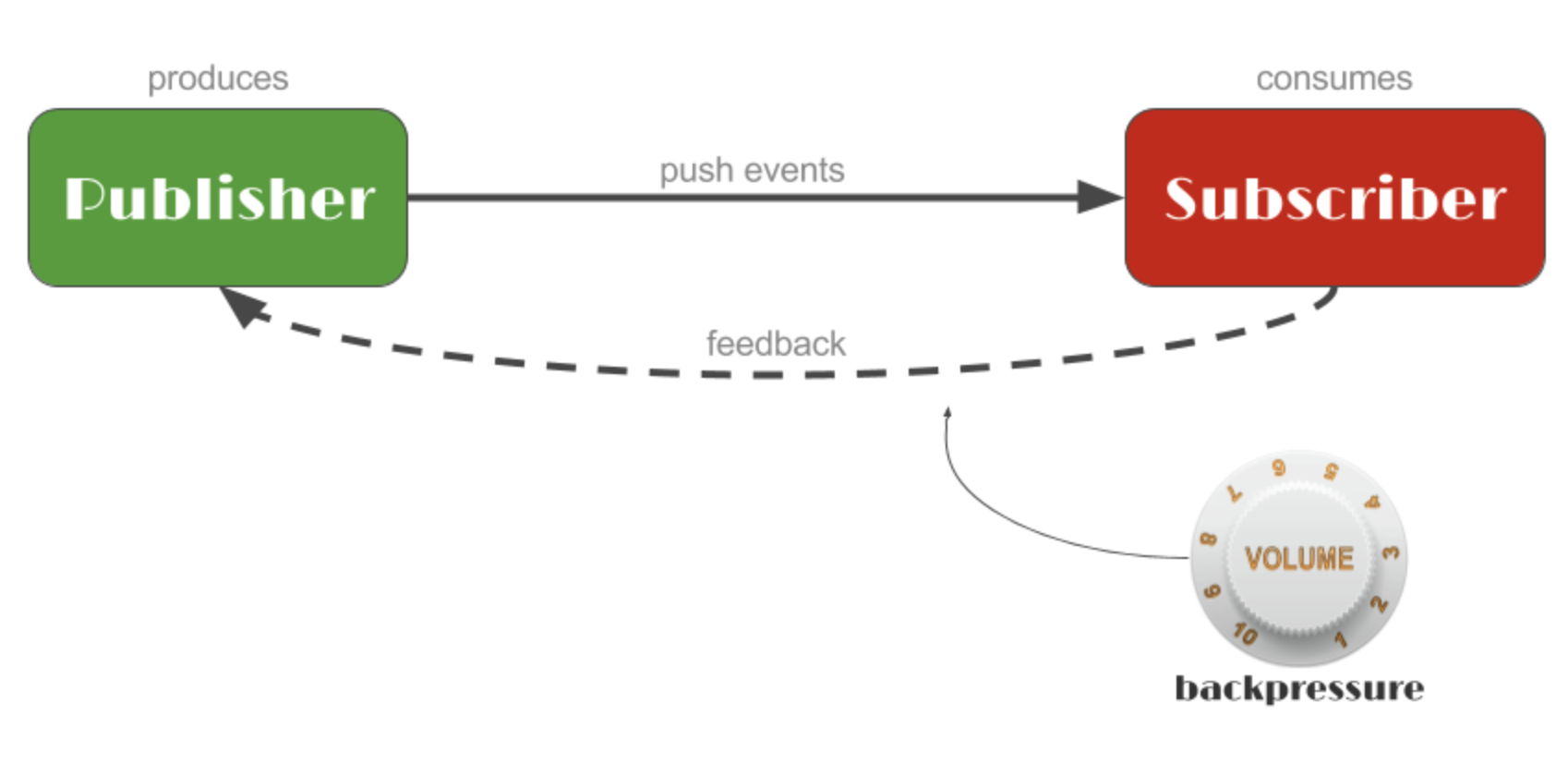
배압이란?
-
Reactvice Streams 에서 배압은 스트림 요소의 전송을 조절하는 방법 ,즉 처리량을 조절하는 메커니즘
-
데이터의 생산 속도와 소비 속도간의 불일치를 관리하기 위해 사용
Publisher : 데이터의 생산을 담당 (Subscriber가 구독하기전까지 아무런 일도 하지 않음)
Subscriber : 데이터의 소비를 담당
배압 = Subscriber가 Publisher 에게 데이터 전송 속도를 줄여달라고 신호를 보내는 과정
흐름제어 -> Publisher는 Subscriber가 등록되는 시점부터 데이터를 계속 push 한다.
피드백 -> Subscriber 데이터가 지나치게 쌓여서 감당할 수 없는 현상을 제거하기 위해 피드백을 보낸다.
이 피드백을 관장하는 요소가 Back-Prussure , 배압이다.
Flux<String> dataStream = Flux.range(1, 100)
.map(i -> {
// 데이터 처리 로직
return "Item " + i;
});
dataStream.onBackpressureBuffer(10) // 버퍼 사이즈 설정
.subscribe(item -> {
// 데이터 소비 로직
System.out.println("Processing " + item);
});-
onBackpressureBuffer(10)는 데이터가 버퍼에 최대 10개까지 쌓이도록 설정 -
데이터가 버퍼를 초과하면,
Publisher는 추가 데이터를 멈추고,Subscriber가 버퍼에서 데이터를 처리할 때까지 기다리자.
API 로직에서 배압이 중요할까?
-
같은 API는 여러번 호출하지 않는다. 다양한 외부 API 들을 통상적으로 1-2번 호출하여 Mono 형태의 결과를 조합한다.
-
외부 API 에서 필요한 데이터를 스트리밍 형식으로 제공해 주지 않는다.
-
실시간 호출 API 에서 대량의 데이터를 순차적으로 읽어올 일도 없다.
오히려 Batch 로직에서 배압이 중요하지 않을까?
- Batch 서버에서는 Apache Kafka를 통한 이벤트 수신 또는 대량의 상품 데이터를 순차적으로 읽기
fun getProductIds(sellerId: String) Flux<String> {
return getProducts(serllerId, null)
.expand { res ->
res.nextCursor.toMono()
.flatMap { cursor -> getProducts(sellerId, cursor) }
}
.flatMapIterable { it.items }
.map { it.productId }
}-
상품 데이터 전체를 읽는데 커서 기반 페이지네이션으로 읽는 코드
-
다음 페이지를 언제 가져오는가? 처리량에 따라
Project Reactor의 장점은 풍부한 연산자로부터
-
외부 플랫폼 연동에서 요구되는 사항을 손쉽게 구현 할 수 있다
- 1초당 몇 회의 API 호출
- 1초당 몇 개의 데이터로 호출
-
큰 chunk 단위를 1초마다 처리하면서 chunk를 작은 chunk를 쪼개서 처리하는 코드
flux.windowTimeout(
BIFFER_SIZE * REQUEST_PER_SECONDS,
Duration.ofSeconds(1),
/* fairBackpressure = */ true,
)
.delayElements(Duration.ofSecond(1))
.concatMap { window ->
window.buffer(BUFFER_SIZE). flatMap { chunk ->
importer.import(chunk)
}
}⇒ 배민 스토어에서는 앞선 내용을 바탕으로 Batch성 로직에서 오히려 프로젝트를 적응하는 것이 배압의 특성을 잘 적용하는 것임을 알게 됨 project reactor 적용으로 방향 수정
⇒ 서비스에 대한 이해도 높아지면서 기술적 이해도도 높아짐
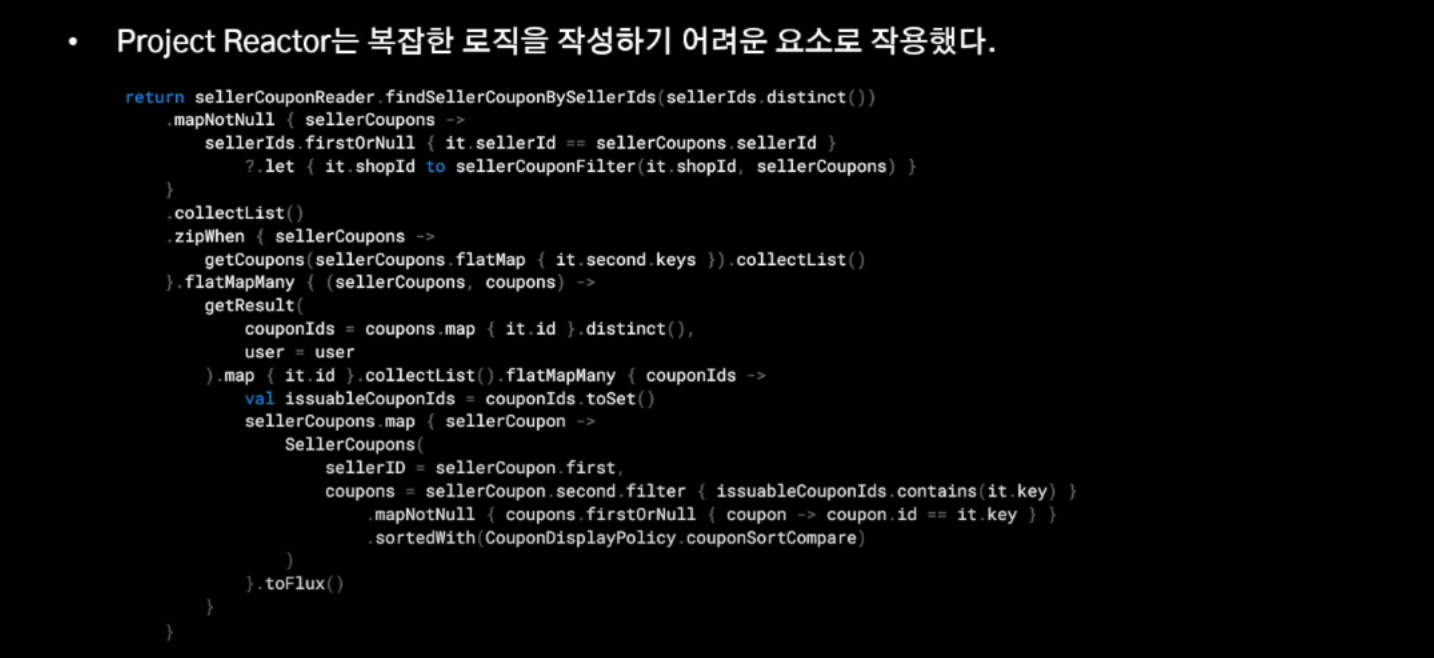
3. Project Reactor의 높은 러닝 커브가 생산성을 저해하지 않을 만한 수준이었는가?
-
이슈를 파악하는 것도 쉽지 않았다고 합니다.
-
팀 내에서 지속적으로 스터디 및 노하우를 공유했지만, 잔존하는 이슈들이 많았고, 생산성을 저해하는 부분을 가시화 하는 것은 어려운 일이라고 말씀해주심
