🌱 들어가기
CPU가 메모리에 접근하는 시간은 CPU 연산 속도보다 느리다
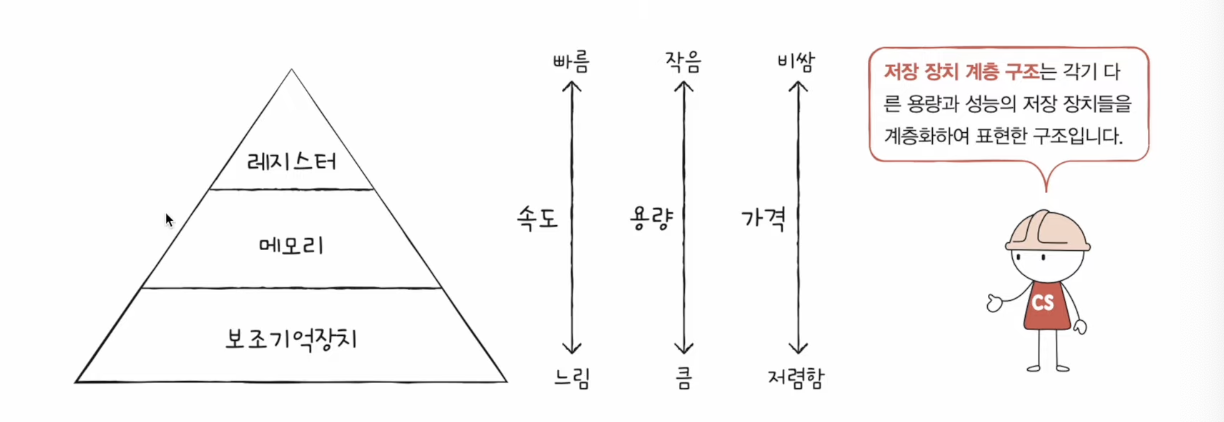
저장장치 계층 구조 (memory hierarchy)
- CPU와 가까운 저장장치는 속도가 빠르고, 멀리 있는 저장장치는 느리다.
- 속도가 빠른 저장장치는 저장용량이 작고, 가격이 비싸다.
레지스터 vs 메모리(RAM) vs USB 메모리
낮은 가격대의 대용량 저장장치를 원한다면 느린 속도는 감수해야 하고, 빠른 속도의 저장 장치를 원한다면 작은 용량과 비싼 가격은 감수해야 한다.
📡 캐시 메모리
-
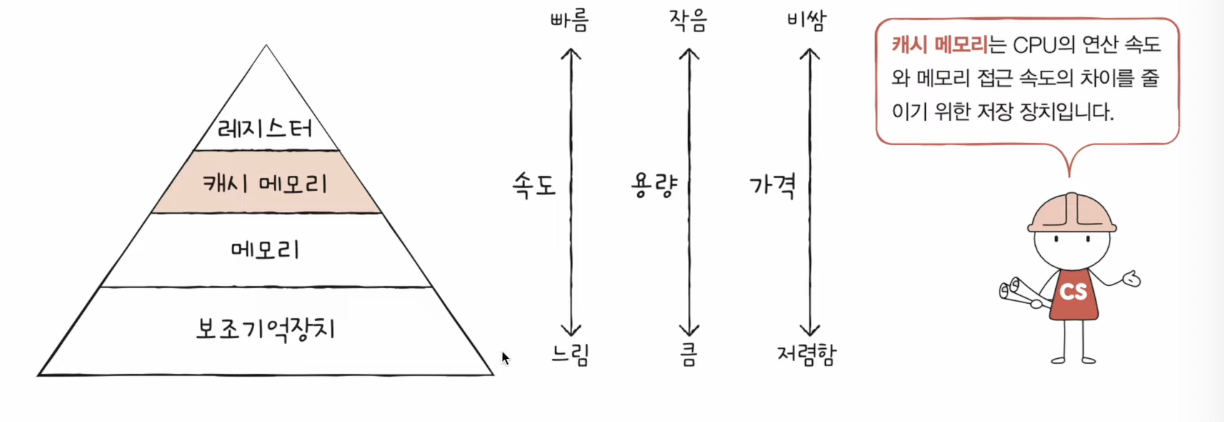
CPU와 메모리 사이에 위치한, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM기반의 연산장치
-
CPU의 연산 속도와 메모리 접근 속도의 차이를 조금이나마 줄이기 위해 탄생
-
CPU가 매번 메모리에 왔다 갔다 하는 건 시간이 오래 걸리니, 메모리에서 CPU가 사용할 일부 데이터를 미리 캐시 메모리로 가지고 와서 쓰자
계층적 캐시 메모리
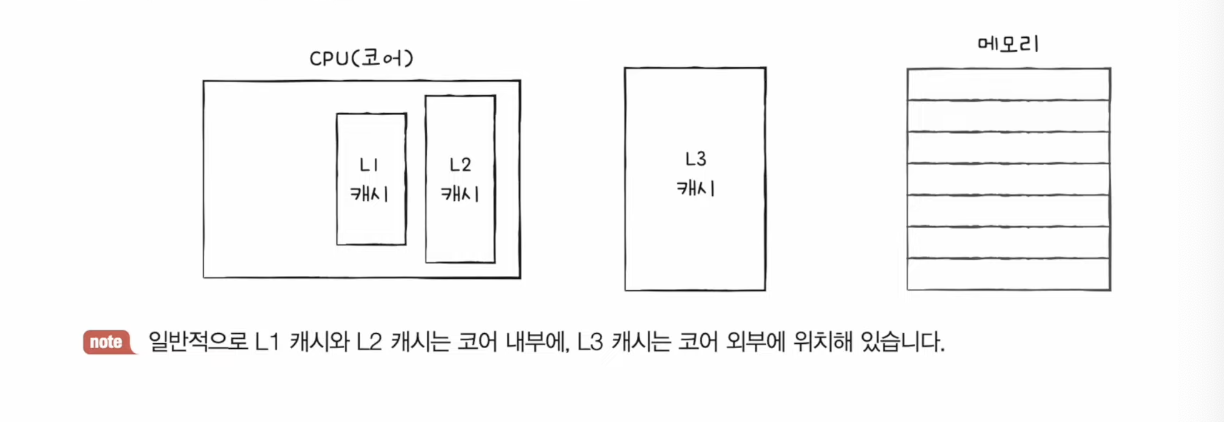
CPU 코어 내부와 CPU 코어 외부에 위치
-
CPU와 메모리 사이에 위치한 캐시메모리
-
캐시메모리 중에서 CPU내부에 있는 캐시메모리도 있지만 레지스터가 더 빠르다.
✅ 참조 지역성의 원리
-
캐시 메모리는 메모리보다 용량이 작다
-
메모리의 모든 내용을 저장 할 수 없고, 일부내용만 저장
-
CPU가 자주 사용할 법한 내용을 예측하여 저장
캐시 적중률
- 예측이 들어맞을 경우 ⇒ 캐시 히트 / 예측이 틀렸을 경우 ⇒ 캐시 미스
캐시 히트 - CPU가 캐시 메모리에 저장된 값을 활용한 경우
캐시 미스 - CPU가 메모리에 접근해야 하는 경우 ( 성능 하락 ! )
-
캐시 적중률 = 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
-
최근 CPU의 적중률은 최소 80% 이상이다
-
캐시 미스
- Cold Miss : 해당 메모리 주소를 처음 불러서 나는 미스
- Conflict Miss : 캐시 메모리에 A와 B 데이터를 저장해야 하는데, A와 B가 같은 캐시 메모리 주소에 할당되어 있어서 나는 미스
- Capacity Miss : 캐시 메모리의 공간이 부족해서 나는 미스
캐시 적중률을 높여야 한다!
== CPU가 사용할 법한 데이터를 예측해야 한다. ⇒ 참조 지역성의 원리
참조 지역성의 원리
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다. ( 시간 지역성 )
- for나 while 같은 반복문에 사용하는 조건 변수처럼 한번 참조된 데이터는 잠시후 또 참조될 사능성이 높다.
- CPU는 접근한 메모리 공간 근처에 접근하려는 경향이 있다. ( 공간 지역성 )
- A[0], A[1] 과 같은 연속 접근 시, 참조된 데이터 근처에 있는 데이터가 잠시후 또 사용될 가능성이 높다.
블록 사이즈가 커지면 캐시의 Hit율도 올라간다. 그렇다고 해서 무작정 블록 사이즈를 키우는 것만으로는 그 효율성을 높일 수는 없다. 이에 따라 몇 가지 요소를 고려하여 설계해야 한다. 설계의 목표는 Hit율을 높이고 최소의 시간에 데이터를 전달 하는 것이다. Hit 실패시에 다음 동작을 처리하는데 있어서 시간을 최소화하는 것이 중요하며 데이터의 일관성 유지해서 이에 따른 오버헤드 최소화해야 한다.
🔗 참조한 사이트
