KeyBERT
모델 소개
KeyBERT는 키워드 추출 방법중 하나로 텍스트 임베딩 단계에서 BERT를 사용한다.
* BERT
- 버트(BERT)는 2018년 구글이 공개한 레이블이 없는 텍스트 데이터(ex: 위키피디아, BookCorpus)로 사전 훈련된 모델로 트랜스포머를 이용해 구현되었다.
- 버트는 언어 표현을 사전 학습시키는 방법으로 자연어를 이해하기 위한 양방향 학습 모델을 모두 지원하는 알고리즘이다.
KeyBERT 원리
keyBERT는 다음과 같은 원리를 따른다.
1. BERT를 이용해 문서 레벨에서의 주제 파악
2. N-gram(키워드 및 식)을 위해 단어 임베딩
3. 코사인 유사도 계산을 통해 어떤 N-gram 혹은 단어가 문서와 가장 유사한지 탐구
4. 가장 유사한 단어들을 키워드로 분류
코드 구현
-
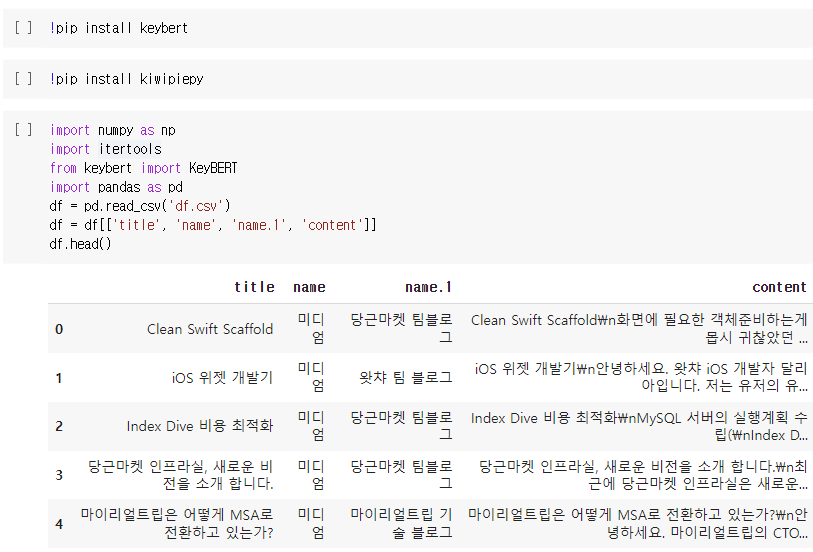
keyBERT와 한글 명사추출을 위해 kiwipiepy설치 후 데이터 불러오기
-
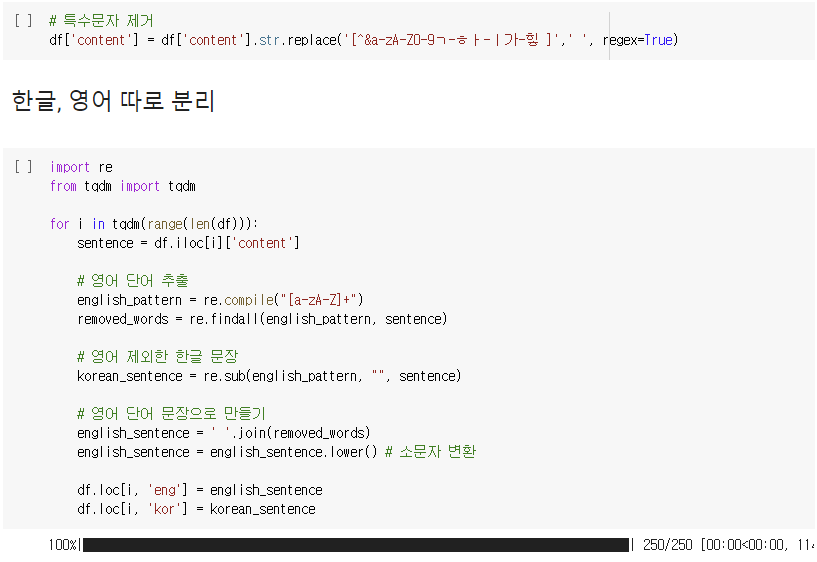
데이터프레임 특수문자 제거 후 한글과 영어 따로 분리
-
한글 데이터의 키워드 추출에 앞서 불용어를 정의해주고 필요 라이브러리를 임포트 한다.

-
한글 명사 추출 및 키워드를 추출해 상위 5개 키워드를 아래와 같이 데이터프레임에 저장
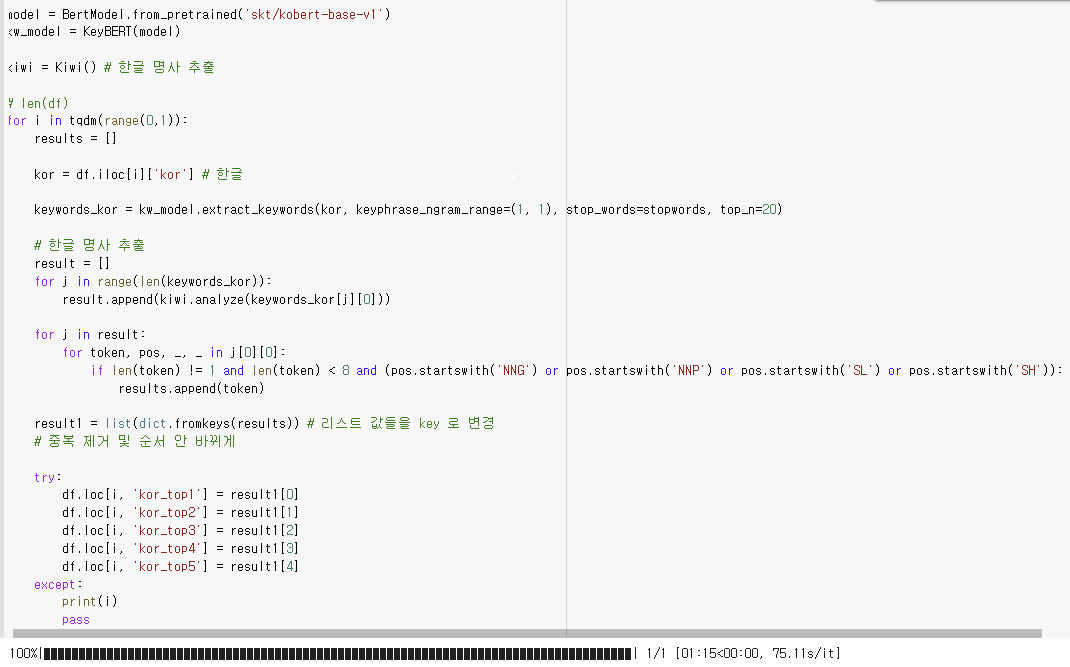

-
다음과 같이 결과가 잘 나온 것을 볼 수 있다.


나는야