Parquet(파케이) 파일 형식
이번에 데이터분석 과제를 하면서 parquet형식의 데이터를 처음 접해봤는데 아무래도 처음 접하는 파일 형식이다보니 좀 더 알고 싶어 관련 포스팅을 하기로 결정⭐
1.파케이(parquet)란?
파케이(parquet)란 하둡에서 칼럼방식으로 저장하는 저장 포멧을 말한다.
하둡이란??
-하둡은 분산 환경에서 빅데이터를 저장하고 처리할 수 있는 자바 기반의 오픈 소스 프레임 워크로, 여러대의 컴퓨터 클러스터에 각각 존재하는 대규모 데이터세트를 분산 처리 할 수 있게 해주는 프레임워크이다.
-하둡은 수천 대의 분산된 장비에 대용량 파일을 저장할 수 있는 기능을 제공하는 1)분산파일 시스템(HDFS)과 2)저장된 분산 파일을 분산된 서버의 CPU와 메모리 자원을 이용하여 빠르게 분석하는 맵리듀스 플랫폼(MapReduce)으로 구성되어 있다.
➡️ 이러한 하둡을 통해 기존의 데이터를 분석하고 저장하는 방식에서 필요했던 많은 비용과 시간을 단축시킬 수 있게 되었다.
파케이는 하둡 생태계에 속한 프로젝트에서 칼럼방식으로 데이터를 효율적으로 저장하여 처리 성능을 비약적으로 향상시킬 수 있다.
파케이는 열(Column)기반 압축을 하고 있는데, 이는 컬럼의 데이터가 연속된 구조로 저장되어 있음을 뜻한다.
아래의 사진은 열 기반 압축 방식과 행 기반 압축 방식의 차이를 직관적으로 보여주고 있다.
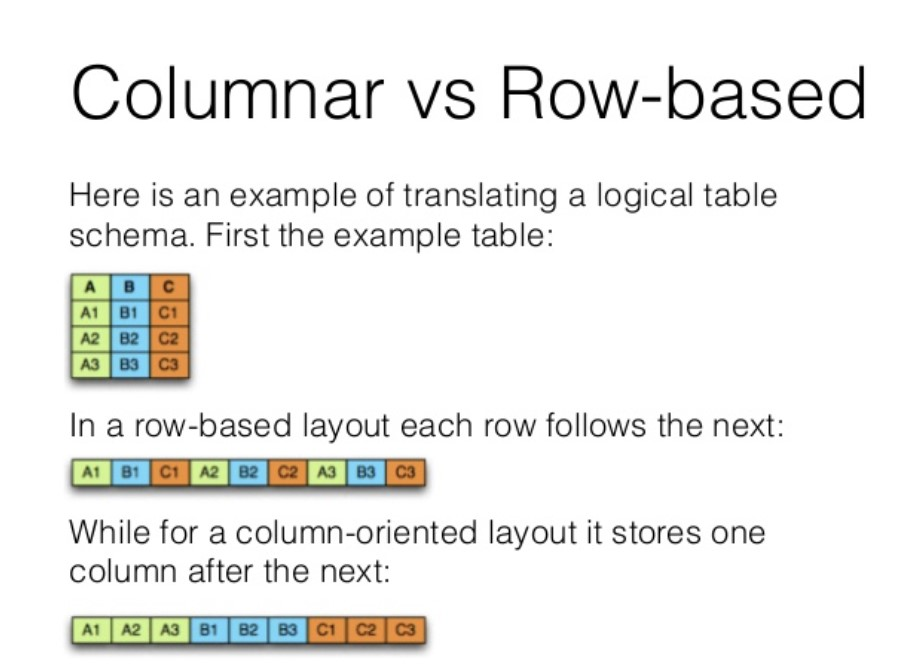
열을 기반으로 데이터를 처리하면 행 기반으로 압축했을 때에 비해 데이터의 압축률이 더 높고, 필요한 열의 데이터만 읽어서 처리하는 것이 가능하기 때문에 데이터 처리에 들어가는 비용을 절약할 수 있다. 컬럼단위로 압축하게 되면 파일의 크기도 작아지기 때문에 용량을 덜 차지한다는 장점도 있다.
2. 파케이(Parquet)내부 구조
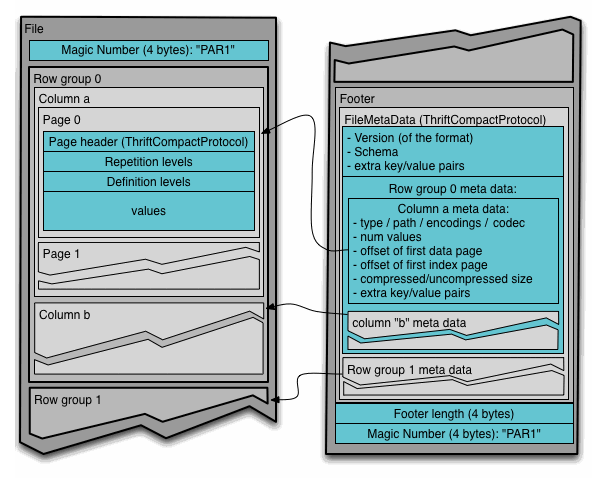
위의 사진은 Parquet File Structure로 검색했을 때 대표적으로 나오는 사진이다.
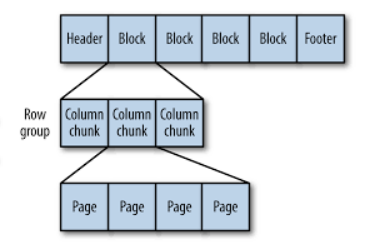
사진에서 볼 수 있듯이, 파케이 파일은 헤더, 하나 이상의 블록, 꼬리말 순으로 구성된다. 파케이 파일의 각 블록은 행 그룹을 저장하며, 행 그룹은 행에 대한 컬럼 데이터를 포함한 컬럼 청크로 되어있다. 또 각 컬럼 청크의 데이터는 페이지에 기록된다. 이때 각 페이지는 동일한 컬럼의 값만 포함하고 있기 때문에, 페이지를 압축할 때 매우 유리하다.
2.1 파케이 불러오기
주피터/코랩 상에서 파케이 파일을 불러오는 방법은 다음과 같다.
df = pd.read_parquet('해당 parquet파일 경로')3. Refrences
https://amazelimi.tistory.com/entry/Parquet%EC%97%90-%EB%8C%80%ED%95%B4-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
https://pearlluck.tistory.com/561
https://m.blog.naver.com/acornedu/222069158703
