U-Net
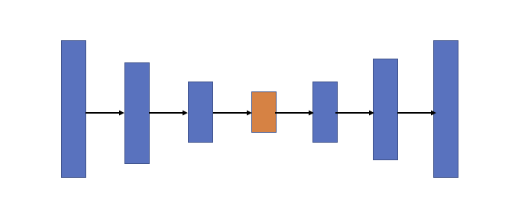
U-Net이란
: U-Net은 오토인코더와 같은 인코더-디코더 기반 모델
-
오토인코더란?
💡 오토인코더? : 입력을 출력으로 복사하는 신경망 (딥러닝에서의 비지도 학습) → 네트워크에 여러가지 방법으로 제약을 줌으로써 어려운 신경망으로 만든다.-
오토인코더는 잠재 표현의 크기를 제한하거나(은닉층 뉴런의 수를 입력층 뉴런 수보다 작게 하는 방법) 입력값에 잡음을 추가하고 원본 입력값을 복원하도록 하는 등의 네트워크 훈련 방법을 사용해 데이터를 효율적으로 표현하는 방법(패턴이 있는 데이터)을 배운다. (어려운 신경망으로 만든다.)
→ 그 중 차원을 줄이는 방법
: 입력층보다 적은 수의 뉴런을 가진 은닉층을 중간에 넣어 줌으로써 차원을 줄인다. 이때 학습을 톻해 소실된 데이터를 복원하는데 이 과정을 통해 입력 데이터의 특징을 효율적으로 응축한 새로운 출력이 나오는 원리를 따른다.⇒ 입력보다 훨씬 더 낮은 차원을 갖기 때문에 차원 축소와 시각화에 유용하게 사용된다. 입력이 저차원으로 표현되는 인코더구조를 Undercomplete Autoencoder라고 한다.
-
인코더-디코더 기반 모델의 문제
- 인코더-디코더 기반 모델은 보통 인코딩 단계에서 입력 이미지의 특징을 포착할 수 있도록 채널의 수를 늘리면서 차원을 축소해 나가고, 디코딩 단계에서는 저차원으로 인코딩 된 정보만 이용해 채널 수를 줄이고 차원을 늘려 고차원의 이미지를 복원한다.
- BUT 인코딩 단계에서 차원 축소를 거치면서 이미지 객체에 대한 자세한 위치 정보를 잃어 디코딩 단계에서도 저차원의 정보만을 이용하기 때문에 위치 정보 손실을 회복하지 못한다.
➡️ U-Net은 인코더-디코터 구조의 이런 정보 손실 회복 불가 문제를 해결하기 위해 고안된 모델
U-Net의 구조
- U-Net의 기본 아이디어 : 저차원 뿐만 아니라 고차원 정보도 이용해 이미지의 특징을 추출 + 정학환 위치 파악도 가능하게 하자 !
→ 이를 위해 인코딩 단계의 각 레이어에서 얻은 특징을 디코딩 단계의 각 레이어에 합치는 방법을 사용
⇒ 이때 인코더 레이어와 디코더 레이어를 직접 연결하는 방법을 스킵 연결(skip connection)이라고 한다.
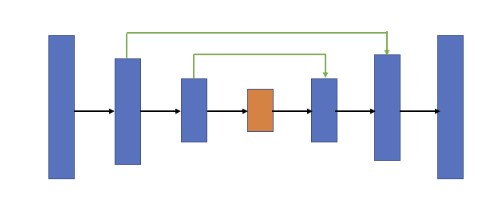
- 논문에서는 신경망 구조를 skip connection을 평행하게 두고 가운데를 기준으로 좌우가 대칭이 되도록 레이어 배치, 모델 이름 그대로 U자 형태로 만들었다.
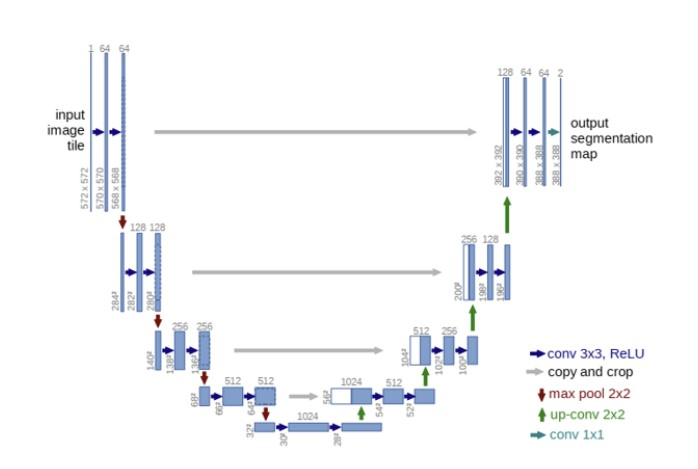
- U-Net은 인코더(축소경로)와 디코더(확장경로)로 구성되며, 두 구조는 대칭적이다.
- 인코더와 디코더를 연결하는 부분을 ‘브릿지’라고 하며, 인코더와 디코더에서는 모두 3*3 convolution을 사용.
Details
Encoder
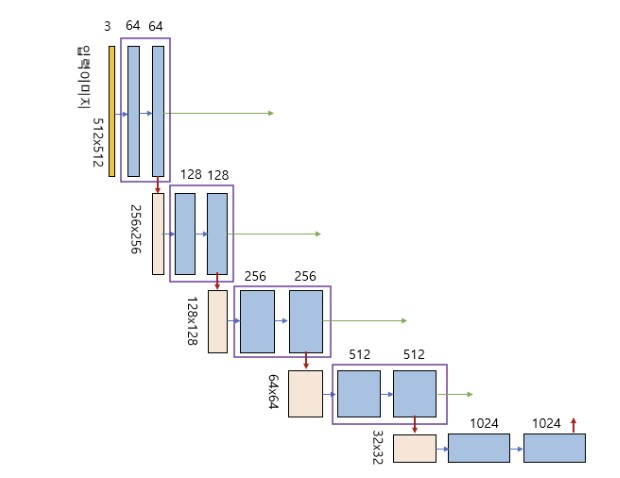
- 그림의 세로 방향 숫자는 맵(map)의 차원을 표시, 가로 방향 숫자는 채널 수를 표시.
ex) 입력이미지 = 5125123 → RGB 3개 채널을 갖고 크기가 512*512인 이미지 - 파란색 박스가 인코더의 각 단계마다 반복적으로 나타남
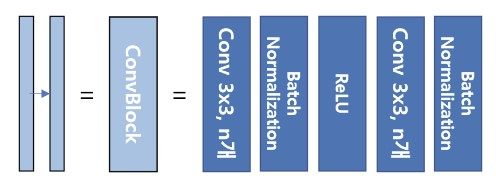
→ 이 박스는 33 convolution, Batch Normalization, ReLU 활성화 함수가 차례로 배치된 것을 나타낸다.
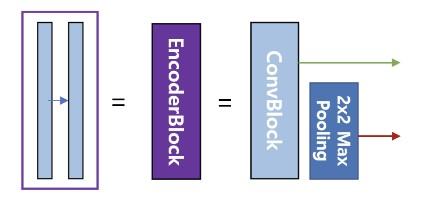
- 이 박스에서 나오는 출력이 2개인데, 한개의 출력은 U-Net의 디코더로 복사하기 위한 연결선, 또 하나의 출력은 22max pooling으로 다운 샘플링하여 인코더의 다음 단계로 내보내는 빨간색 화살선,
Decoder
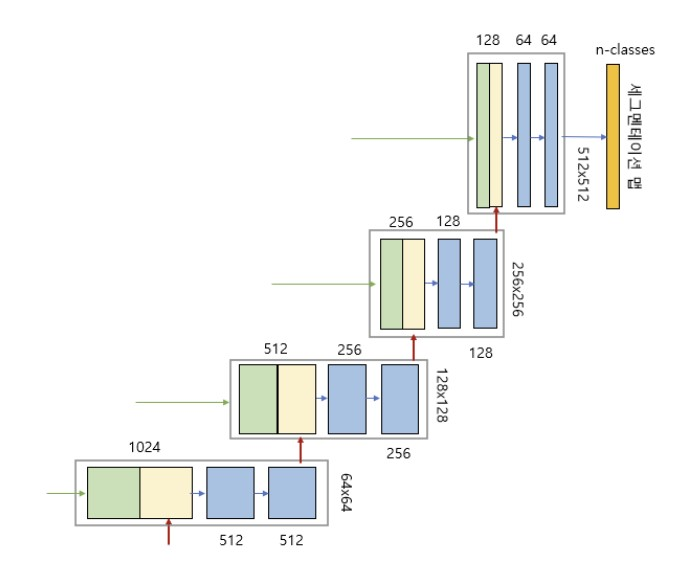
- 파란색 박스 2개 = 인코더의 ConvBlock과 동일
- 녹색 박스 : skip connection을 통해 인코더에 있는 맵을 복사한 것.
- 노란색 박스 : 디코더의 하위 단계에서 transposed revolution을 통해 맵의 차원을 두배로 늘리면서 채널 수는 반절로 줄인 것.
⇒ 두 개의 맵을 서로 합쳐 저차원 이미지 정보뿐만 아니라 고차원 정보도 이용가능 - 그림의 맨 상단 오른쪽 부분 : U-Net의 출력으로, 1*1 convolution으로 feature map을 처리해 입력 이미지의 각 픽셀을 분류하는 segmentation map을 생성한다.
→ 이때 컨볼루션 필터의 개수 = 분류할 카테고리 개수이며 활성화 함수로는 카테고리 수에 따라 카테고리 수가 1개면 sigmoid함수, 여러 개면 softmax함수를 사용한다.
코드 구현
# U-Net model
# coded by st.watermelon
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Conv2DTranspose
from tensorflow.keras.layers import Activation, BatchNormalization, Concatenate
""" Conv Block """
class ConvBlock(tf.keras.layers.Layer):
def __init__(self, n_filters):
super(ConvBlock, self).__init__()
self.conv1 = Conv2D(n_filters, 3, padding='same')
self.conv2 = Conv2D(n_filters, 3, padding='same')
self.bn1 = BatchNormalization()
self.bn2 = BatchNormalization()
self.activation = Activation('relu')
def call(self, inputs):
x = self.conv1(inputs)
x = self.bn1(x)
x = self.activation(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.activation(x)
return x
""" Encoder Block """
class EncoderBlock(tf.keras.layers.Layer):
def __init__(self, n_filters):
super(EncoderBlock, self).__init__()
self.conv_blk = ConvBlock(n_filters)
self.pool = MaxPooling2D((2,2))
def call(self, inputs):
x = self.conv_blk(inputs)
p = self.pool(x)
return x, p
""" Decoder Block """
class DecoderBlock(tf.keras.layers.Layer):
def __init__(self, n_filters):
super(DecoderBlock, self).__init__()
self.up = Conv2DTranspose(n_filters, (2,2), strides=2, padding='same')
self.conv_blk = ConvBlock(n_filters)
def call(self, inputs, skip):
x = self.up(inputs)
x = Concatenate()([x, skip])
x = self.conv_blk(x)
return x
""" U-Net Model """
class UNET(tf.keras.Model):
def __init__(self, n_classes):
super(UNET, self).__init__()
# Encoder
self.e1 = EncoderBlock(64)
self.e2 = EncoderBlock(128)
self.e3 = EncoderBlock(256)
self.e4 = EncoderBlock(512)
# Bridge
self.b = ConvBlock(1024)
# Decoder
self.d1 = DecoderBlock(512)
self.d2 = DecoderBlock(256)
self.d3 = DecoderBlock(128)
self.d4 = DecoderBlock(64)
# Outputs
if n_classes == 1:
activation = 'sigmoid'
else:
activation = 'softmax'
self.outputs = Conv2D(n_classes, 1, padding='same', activation=activation)
def call(self, inputs):
s1, p1 = self.e1(inputs)
s2, p2 = self.e2(p1)
s3, p3 = self.e3(p2)
s4, p4 = self.e4(p3)
b = self.b(p4)
d1 = self.d1(b, s4)
d2 = self.d2(d1, s3)
d3 = self.d3(d2, s2)
d4 = self.d4(d3, s1)
outputs = self.outputs(d4)
return outputs
나는야