'가상 면접 사례로 배우는 대규모 시스템 설계 기초 1 - 뉴스 피드 시스템 구현'을 참고하여 '아이바' 프로젝트에 맞춰 설계해보았습니다.
아래 이미지는 책에서 나온 최종 시스템 설계도입니다.
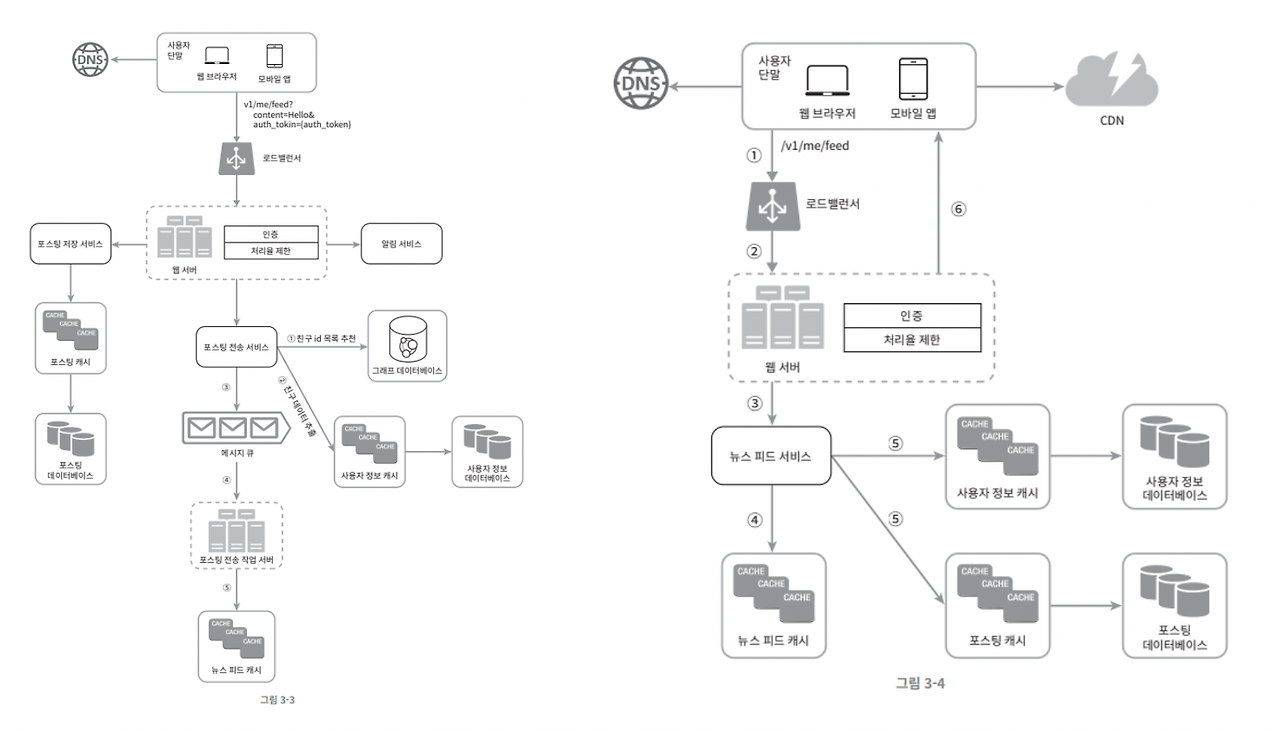
- 피드발행[그림3-3]
- 뉴스 피드 가져오기[그림3-4]
위 설계도는 “팔로우 기반 개인 피드”이지만, 아이바는 “팔로우 없는 전역 최신 피드”를 기준으로 합니다.
그래서 포스팅 전송 서비스의 fan-out 파이프라인이 별도로 존재하지 않습니다.
또한 사용자 정보는 user-service에서 별도로 가져와야 해서 Redis 캐시 및 gRPC 기술을 사용하였습니다.
[Aiva community-service 요약]
- 피드 목록은 Redis Sorted Set(ZSET), 게시글 본문은 Redis Hash, TTL 24시간
- 작성자 정보(닉네임/아바타 등)도 헤더에서 받아 캐시
- 최신 피드 조회: ZSET에서 커서 기반 페이지네이션 → Post Hash 다건 조회 → 작성자 정보 캐시 조합
- 교차 서비스 조회: user-service는 gRPC로 동기 통신
- 알림: 댓글/대댓글/좋아요 이벤트를 Kafka 토픽에 퍼블리시 → notification-service가 컨슘 후 FCM 발송
1. 피드 발행
레디스 데이터/키 설계 요약
- 피드 인덱스(ZSET):
feed:global
score = createdAt(epochMillis), member = postId - 게시글 본문(HASH):
post:{postId}
title, content, authorId, createdAt, likeCount ... - 작성자 정보 캐시(HASH):
user:{authorId}:profile
nickname, avatarUrl, ...
흐름
- Community에 글 작성 요청 수신
- DB 트랜잭션: 게시글 영속화(MySQL)
- 캐시 반영(TTL 24h)
- HSET
post:{id}... (본문 저장) - ZADD
feed:global score=now member=postId(최신순 인덱스 갱신) - HSET
user:{authorId}:profile(작성자 정보 캐시)
Redis 키 설계 이유
-
ZSET(
feed:global)- 점수(score)에
createdAt(epochMillis)를 쓰면 최신순 정렬이 자동이고, 커서 기반 페이지네이션에서O(logN + M)로 안정적입니다. - 목록에는 postId만 넣어 정렬/페이지네이션과 본문 캐시를 관심사 분리 → 메모리 사용량 절감, 갱신 충돌 감소.
- 팔로우가 없는 전역 피드라 “사용자별 피드 상자”가 불필요해 키 수가 적고 단순합니다.
- 참고: Redis SortedSet
- 점수(score)에
-
HASH(
post:{postId})- 필드 단위 접근/갱신이 쉽고 명확합니다(예:
HINCRBY likeCount). - 본문/메타 일부만 읽어도 되어 네트워크/CPU 낭비 최소화.
- 포스트 스키마가 변해도 필드 추가로 유연하게 진화 가능.
- 필드 단위 접근/갱신이 쉽고 명확합니다(예:
-
작성자 프로필 HASH(
user:{authorId}:profile)- 헤더의 사용자 정보를 기본으로 캐시에 저장
- 사용자 정보 수정시 해당 캐시 내용 업데이트 필요
TTL 시간(24H)
- 사용 패턴 가정: 전역 최신 피드는 ‘하루 단위’ 소비가 강함 → “전일 최신” 컨셉과 정합.
- 신선도 vs 비용: 너무 짧으면 미스/DB 부하↑, 너무 길면 스테일·메모리↑. 24h는 합리적 시작값.
- 운영 조정(히트율 보며 튜닝)
- 히트율↑·메모리 여유→ 늘림(예: 36h)
- 미스↑·DB 과열→ 늘림 (DB 보호)
- 메모리 압박·스테일 이슈→ 줄임(예: 12h)
2. 피드 목록 조회
커서 기반 페이지네이션 설계
페이지네이션 비교
| 구분 | Offset 기반 | Cursor 기반 |
|---|---|---|
| 기본 원리 | 건너뛸 개수 지정 (OFFSET) | 특정 지점 이후 조회 (WHERE) |
| 파라미터 | ?page=3&limit=20 | ?cursor=eyJpZCI6MTIzfQ&limit=20 |
| SQL 예시 | LIMIT 20 OFFSET 40 | WHERE id < 123 LIMIT 20 |
| 시간 복잡도 | O(N + M) - N은 offset 값 | O(log N + M) - 인덱스 활용 |
| 메모리 사용 | offset만큼 메모리 필요 | 일정한 메모리 사용 |
| 무한 스크롤 | 비효율적 | 최적화됨 |
성능 벤치마크 (100만 레코드 기준)
| 페이지 | Offset 응답시간 | Cursor 응답시간 | 성능 차이 |
|---|---|---|---|
| 1 | 5ms | 5ms | 동일 |
| 10 | 8ms | 5ms | 1.6배 |
| 100 | 50ms | 6ms | 8.3배 |
| 1,000 | 380ms | 6ms | 63배 |
| 10,000 | 3,500ms | 7ms | 500배 |
| 50,000 | 17,000ms | 7ms | 2,428배 |
-> 소셜피드 같은 경우 커서 기반으로 페이지네이션을 구현한다.
페이지네이션의 기준(정렬 키)은 “항상 동일”해야 합니다.
아이바에선 createdAt DESC, id DESC(= 최신순 + 동점 보조키)로 통일하고,
- 24h 캐시 구간은 Redis ZSET 커서로,
- 그 아래(오래된 구간)는 DB Keyset Pagination(= 커서 기반)으로 자연스럽게 넘겨 받으면 됩니다.
1. 기준 정렬(커서) 통일
- 커서 형태:
(lastCreatedAtEpochMs, lastPostId) - 정렬:
ORDER BY created_at DESC, id DESC - 조건:
(created_at < :lastCreatedAt) OR (created_at = :lastCreatedAt AND id < :lastId)
이렇게 하면 캐시 → DB로 넘어가도 커서의 의미가 동일해서 끊김 없이 다음 페이지를 이어감
2. 캐시 → DB “컷오버(cutover)” 규칙
-
cutoff = now - 24h -
각 페이지를 만들 때:
- ZSET에서
score(=createdAt)가> cutoff인 아이템만 커서 기준으로 가져옴(예: 최대limit개). - 가져온 개수가
limit보다 부족하면, 남은 개수만큼 DB Keyset으로 추가로 채움.- DB 조회의 시작 경계는:
- 캐시에서 마지막으로 가져온
(lastScore, lastId)가 있으면 그걸 사용 - 없다면
cutoff를 시작점으로 사용
- 캐시에서 마지막으로 가져온
- DB 조회의 시작 경계는:
- ZSET에서
즉, “페이지 하나”는 캐시 결과 + DB 결과가 합쳐질 수 있습니다. 커서는 항상 “마지막으로 반환한 항목의
(score,id)”로 갱신
3. Redis 쿼리 예시(커서 기반)
# 첫 페이지
ZREVRANGEBYSCORE feed:global +inf -inf LIMIT 0 :limit
# 다음 페이지
# (lastScore, lastId) 커서가 있을 때: score는 open range, 동점은 앱에서 postId로 필터
ZREVRANGEBYSCORE feed:global ( :lastScore -inf LIMIT 0 :limit※ 동점 처리: 동일 score가 많은 경우, 여유분을 조금 더 가져와서
(score < lastScore) OR (score = lastScore AND postId < lastId)로 애플리케이션에서 필터.
4. DB Keyset Pagination 쿼리
-- 인덱스
CREATE INDEX idx_posts_created_id ON posts (created_at DESC, id DESC);
-- 다음 페이지 조회
SELECT id, title, content, author_id, created_at, like_count
FROM posts
WHERE
(created_at < :lastCreatedAt)
OR (created_at = :lastCreatedAt AND id < :lastId)
ORDER BY created_at DESC, id DESC
LIMIT :limit;- 첫 DB 페이지라면
:lastCreatedAt = :cutoff,:lastId = 'MAX'같은 형태로 시작. - 응답 마지막 레코드의
(created_at, id)를 다음 커서로 적용.
gRPC를 통한 작성자 정보 조회
피드 발행 시 작성자 프로필을 user:{authorId}:profile에 캐시(기본 TTL 24h) 해둡니다.
하지만 TTL이 만료되었거나 캐시에 없는 경우, user-service에서 작성자 정보를 gRPC로 조회해 결합합니다.
핵심 흐름은 아래와 같습니다.
- 피드 목록에서 수집한
authorId들을 중복 제거 - 캐시에서 우선 조회 → 존재하는 것은 즉시 사용
- 캐시 미스 난 ID만 묶어서 gRPC 벌크 호출(지연/호출 수 최소화)
선택 이유: 작성자 정보는 재사용률이 높고(여러 게시글에 반복 등장), gRPC는 낮은 지연·작은 페이로드·타입 안정성으로 비용 대비 효용이 큽니다.
MSA에서의 서비스 간 통신 선택지와 트레이드오프
| 방식 | 장점 | 단점 | 아이바 적용 포인트 |
|---|---|---|---|
| REST (HTTP/JSON) | 범용성 높고 디버깅 용이, 브라우저 친화 | 페이로드 큼, 스키마/버전 관리 느슨 | 외부/공개 API, 관리자 툴 등에 적합 |
| gRPC | 고성능(HTTP/2, 바이너리), 타입 안정성(Proto), 스트리밍, 멀티플렉싱 | 브라우저 직접 호출 어려움, 디버깅 난이도↑ | 내부 마이크로서비스 간 조회(작성자 프로필, 벌크 조회)에 채택 |
| GraphQL | 단일 엔드포인트, 정확한 필드만 조회(over/under-fetch 해결) | 캐싱/권한/N+1 관리 복잡 | BFF나 복합 조회에 고려 가능(현 단계 미도입) |
| 메시지 큐 (Kafka 등) | 비동기, 느슨한 결합, 버퍼링/재시도 | 즉시성 부족, 운영 복잡도↑ | 알림/이벤트 전송에 채택(댓글/좋아요 등) |
3. 알림 발송
댓글/대댓글/좋아요 이벤트를 본요청 경로에서 분리하여, Kafka → notification-service → FCM 파이프라인으로 비동기 처리합니다.
전체 흐름
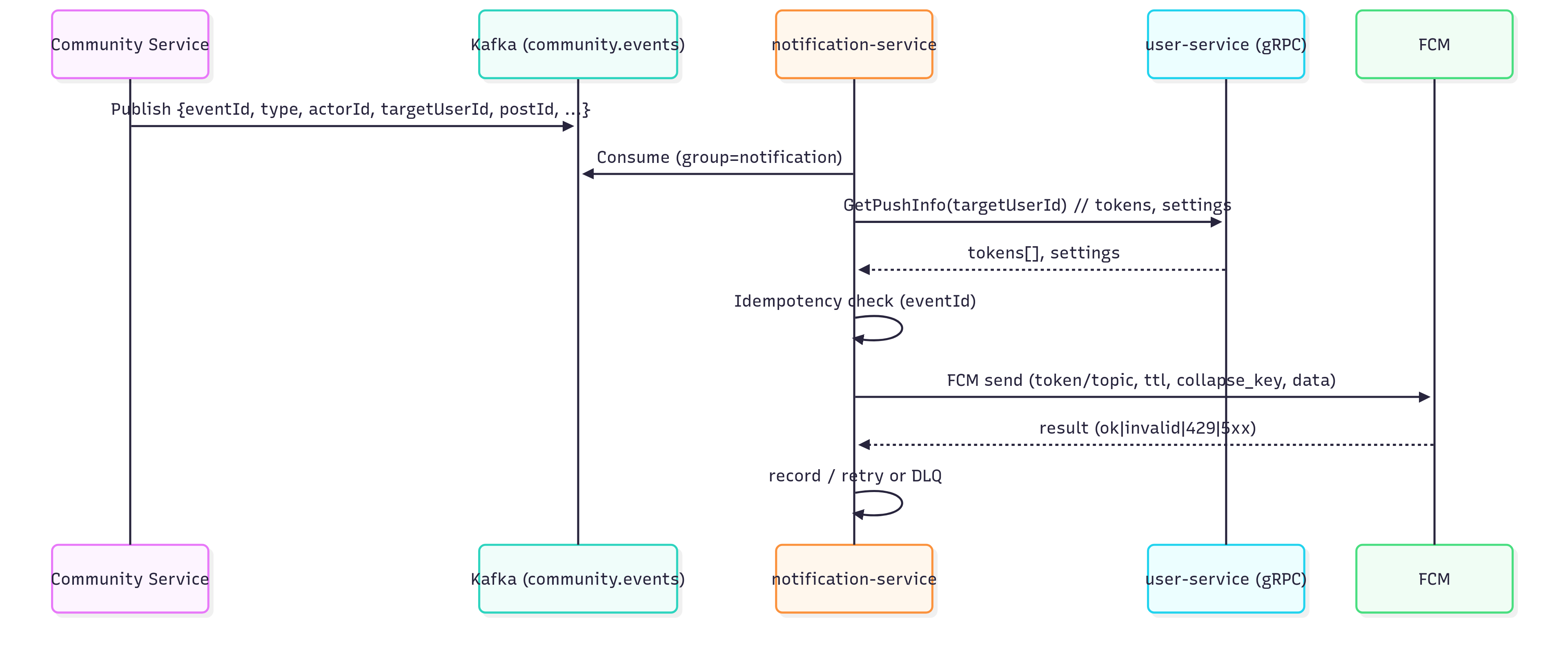
이벤트 스키마 & 토픽
- 토픽:
community.events(파티션 N, 압축 on) - 파티셔닝 키:
targetUserId(동일 사용자 알림 순서 보장/스로틀 유리) - 소비 모델: at-least-once → 멱등 처리 필수
{
"eventId": "uuid-...", // 멱등키(필수)
"type": "COMMENT|REPLY|LIKE",
"actorId": "user-123",
"targetUserId": "user-999",
"postId": "post-456",
"commentId": "c-789", // (선택)
"createdAt": 1695972100123
}notification-service 소비 로직
- 멱등 체크:
eventId가 이미 처리되었으면 즉시 스킵 - 수신 가능 여부: user-service gRPC로 토큰/알림 설정 조회 → 거부/야간 차단이면 종료
- FCM 전송: 토큰 단위 전송(배치/병렬), 결과 수집
- 결과 처리:
- 재시도 대상(429/5xx/네트워크): 지수 백오프 + 지터로 재시도
- 영구 실패(잘못된 토큰 등): 토큰 폐기 + 기록
- N회 실패: DLQ 이동
- 멱등키 기록: 성공/영구 실패 모두
eventId저장(중복 방지)
@KafkaListener(topics = ["community.events"], groupId = "notification")
fun handle(e: Event) {
if (idem.exists(e.eventId)) return
val info = userGrpc.getPushInfo(e.targetUserId) // tokens, settings
if (!info.settings.allow(e.type)) { idem.save(e.eventId); return }
val payload = render(e, info.settings.lang)
sendWithRetry(info.tokens, payload) // 429/5xx만 재시도
idem.save(e.eventId) // 최종 기록(성공/영구실패)
}코틀린 비동기 전송(코루틴)
- 경량 동시성으로 수백~수천 전송을 스레드 과증식 없이 처리
withTimeout/retry(backoff+지터)/SupervisorJob로 취소/재시도/격리 제어
suspend fun sendWithRetry(tokens: List<String>, payload: Payload) = coroutineScope {
val sem = Semaphore(50) // 동시 전송 50
tokens.chunked(500).map { batch ->
async {
sem.withPermit { retry(3) { fcm.sendAll(batch, payload) } }
}
}.awaitAll()
}신뢰성 전략 (멱등 · 재시도 · DLQ)
- 멱등성:
eventId에 Unique 보장(테이블/캐시) - 재시도 정책: 429/5xx/일시 네트워크만 재시도(최대 N회, 지수 백오프)
- DLQ: 스키마 오류/참조 무효/최대 재시도 초과 이벤트 격리
- Exactly-once 착각 금지: 현실은 at-least-once → 멱등으로 해결
마무리
이번 글에서는 ‘가상 면접 사례로 배우는 대규모 시스템 설계 – 뉴스 피드’의 아이디어를 참고해, 아이바(Aiva)의 현실 제약(팔로우 없음·전역 최신 피드)을 반영한 커뮤니티 서비스 설계를 정리했습니다.
핵심은 다음과 같습니다.
- 목록/정렬은 ZSET, 본문은 HASH로 관심사 분리
- TTL 24h(히트율/비용 균형)과 커서 기반 페이지네이션(createdAt DESC, id DESC)
- 작성자 정보는 캐시 우선 → gRPC 폴백
- 알림은 Kafka 비동기 처리 + 멱등/재시도/DLQ로 유실·중복·폭주에 강하게
아직 분산환경을 위해 기술적으로 손볼 부분이 많습니다... 나머지 서비스들을 채워가며 계속 디벨롭할 예정입니다..
