CHATGPT - 인공지능 기술
https://chat.openai.com/chat
# nvCrawler_blog.py : 네이버 블로그 크롤링
import os,sys
import urllib.request
import datetime, time
import json
client_id ="TY0XEecDCcFWi33nL8uC"
client_secret="5U0WY4HGc7"
# [CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
# [CODE 2]
def getNaverSearch(node, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % node
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
# [CODE 3]
def getPostData(post, jsonResult, cnt):
title = post['title']
link = post['link']
description = post['description']
bloggername = post['bloggername']
pDate = post['postdate']
jsonResult.append({'cnt': cnt, 'title': title, 'description': description,
'link': link, 'pDate': pDate, 'blogger': bloggername})
# [CODE 4]
def main():
node = 'blog'
srcText = input('검색어를 입력하세요 : ')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) #[CODE 2]
total = jsonResponse['total']
while((jsonResponse != None) and (jsonResponse['display'] !=0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post,jsonResult,cnt) #[CODE 3 ]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) #[CODE 2]
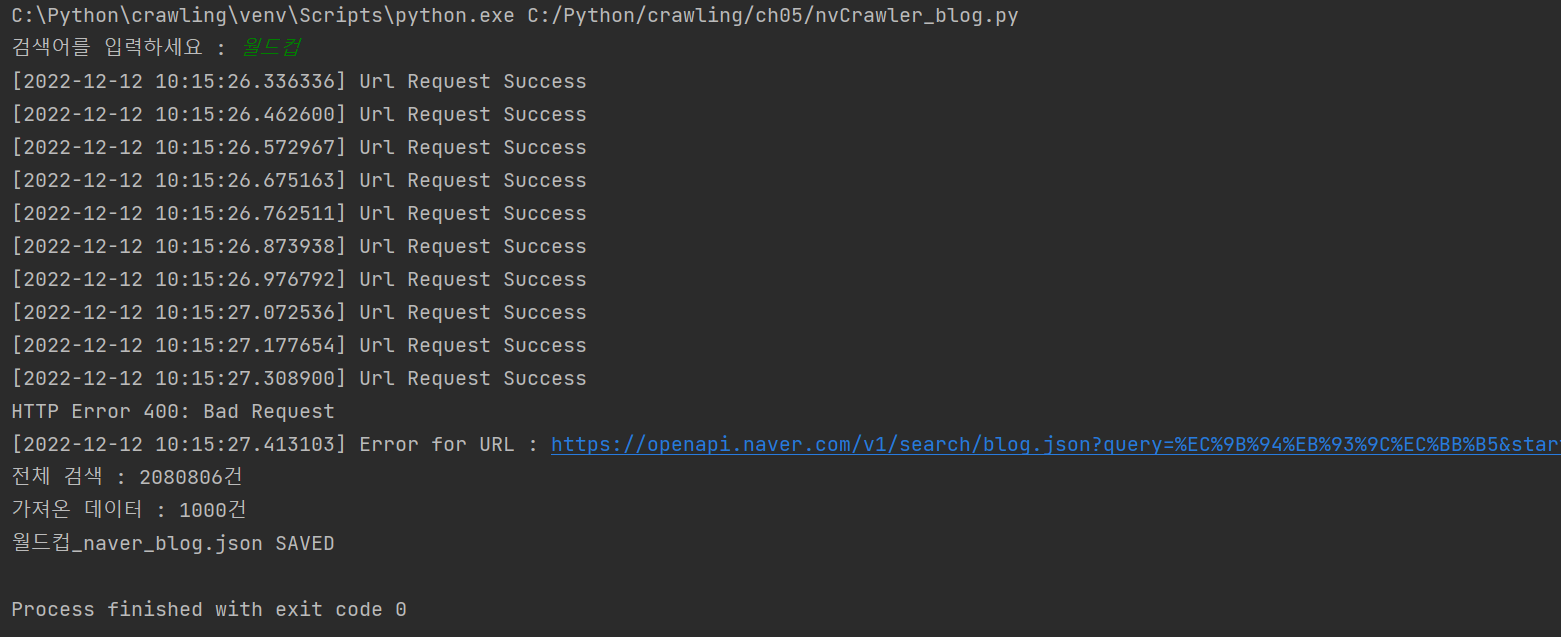
print('전체 검색 : %d건' %total)
with open('./data/%s_naver_%s.json' % (srcText,node),'w',encoding='utf-8') as outfile :
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
# indent : 들여쓰기
outfile.write(jsonFile)
print('가져온 데이터 : %d건' %cnt)
print('%s_naver_%s.json SAVED' % (srcText,node))
if __name__ == '__main__' :
main()
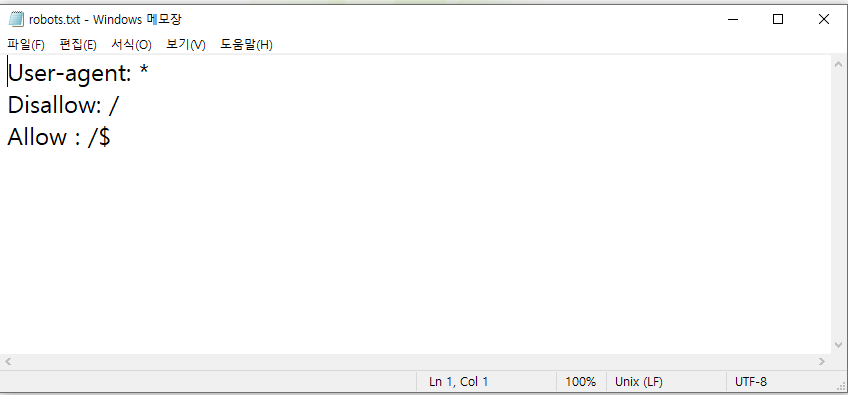
robots.txt
할리스커피 크롤링

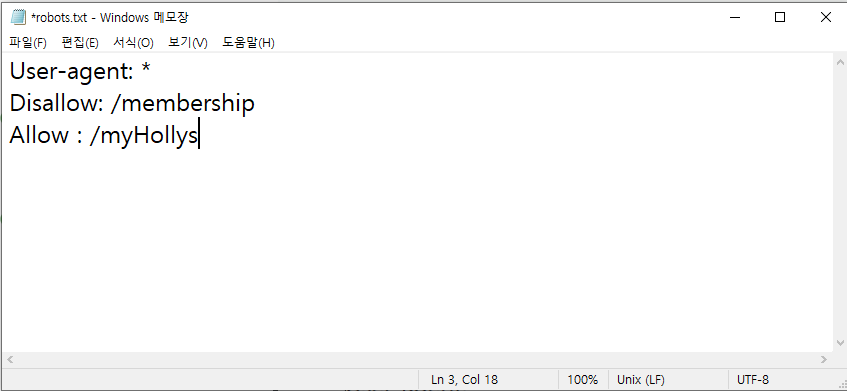
#nvCrawler.py
import os,sys
import urllib.request
import datetime, time
import json
client_id ="--------"
client_secret="-----"
# [CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
# [CODE 2] : 네이버 뉴스를 반환하고 json 형식으로 반환
def getNaverSearch(node, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % node
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
# [CODE 3] : json data를 list 타입으로 변환
def getPostData(post, jsonResult, cnt):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({'cnt': cnt, 'title': title, 'description': description,
'org_link': org_link, 'link': org_link, 'pDate': pDate})
return
# [CODE 0]
def main():
node = 'news' # 크롤링 할 대상
srcText = input('검색어를 입력하세요: ')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) # [CODE 2]
total = jsonResponse['total']
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post, jsonResult, cnt) # [CODE 3]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) # [CODE 2]
print('전체 검색 : %d 건' % total)
# json타입으로 진행
with open('./data/%s_naver_%s.json' % (srcText,node),'w',encoding='utf-8') as outfile :
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
print("가져온 데이터 : %d건" % (cnt))
print('%s_naver_%s.json SAVED' % (srcText,node))
if __name__ == '__main__' :
main()
다 깨졌지만 출력이 되었다
selenium 패키지 설치
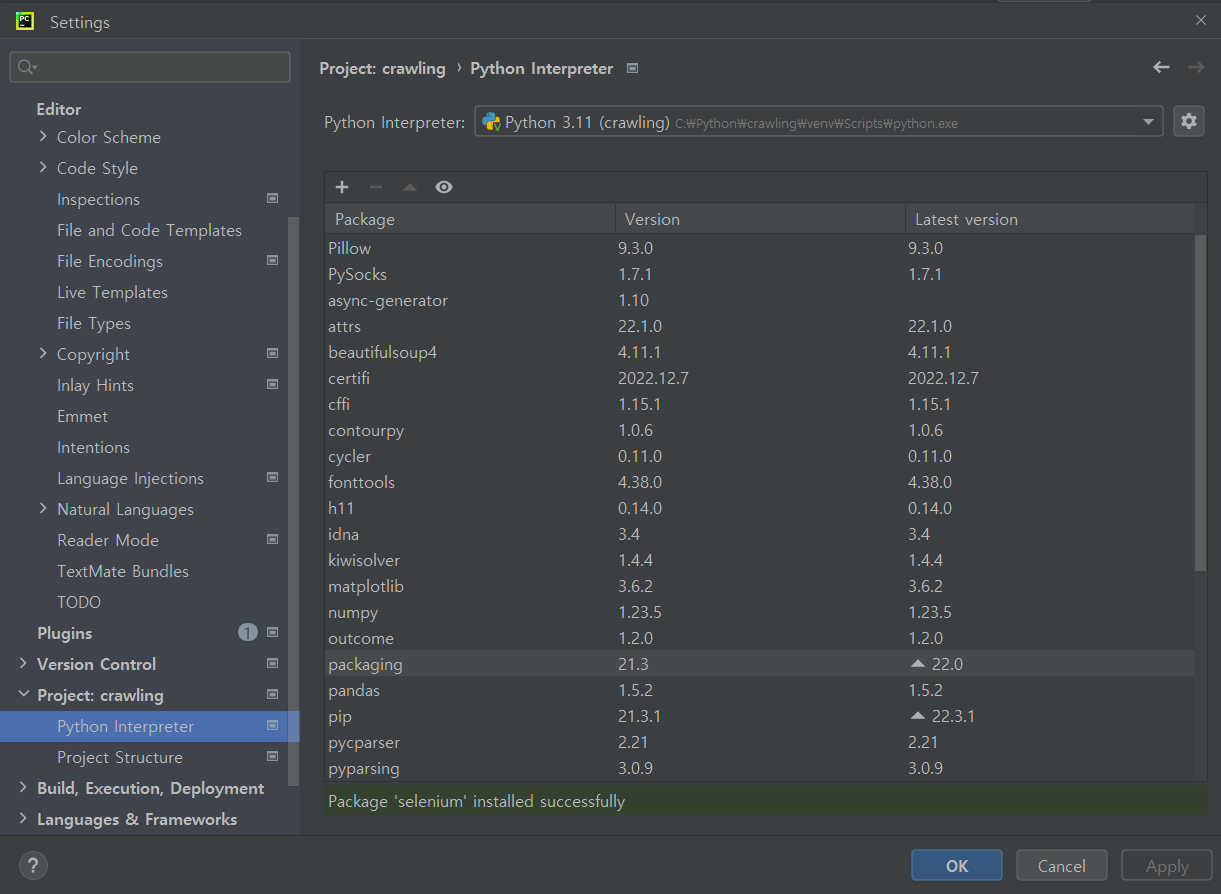

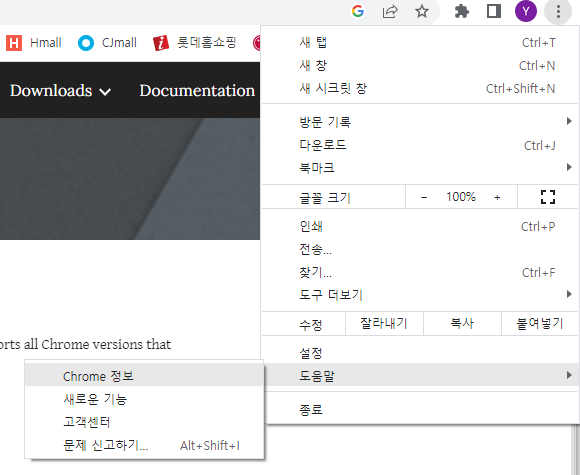
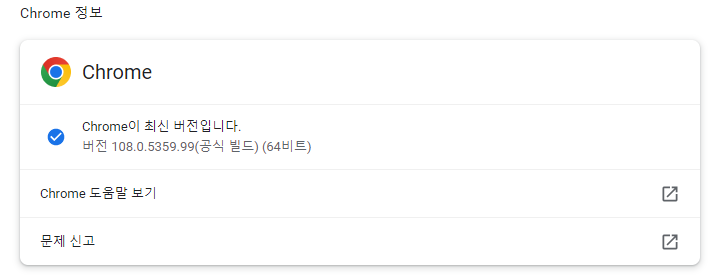
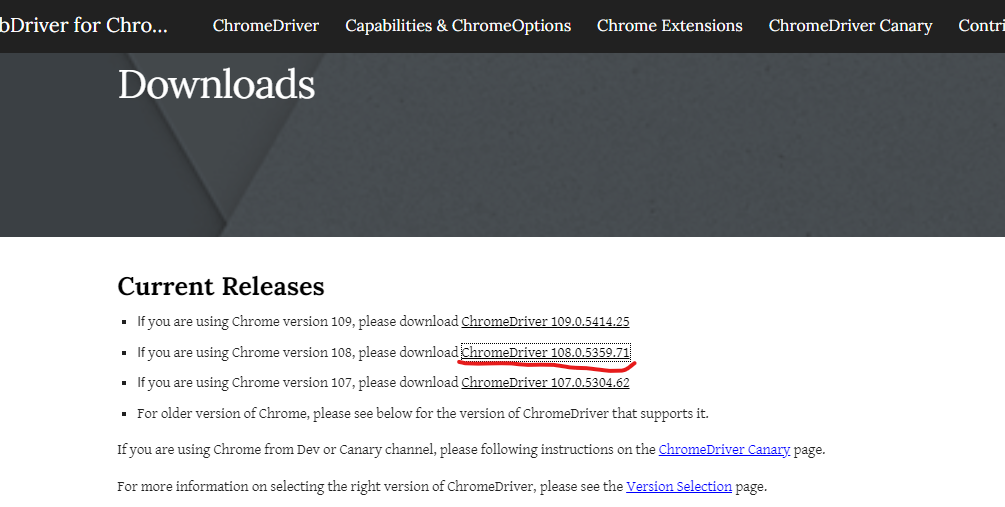

버전에 맞는 걸 다운로드한다

ctrl u->소스바로 보기

커피빈 위치자료 가져오기
# ch06 ex4.py : 커피빈 매장찾기 (동적 웹크롤링)
import time
from bs4 import BeautifulSoup as bs
import urllib.request
import pandas as pd
import datetime
from selenium import webdriver
# [CODE 1]
def coffeeBean_store(result):
coffeeBean_URL = 'https://www.coffeebeankorea.com/store/store.asp'
wd =webdriver. Chrome('./WebDriver/chromedriver.exe')
for i in range(1, 370): #233 -> 234 매장 수 만큼 반복
wd.get(coffeeBean_URL)
time.sleep(1) # 웹페이지 연결할 동안 1초 대기
try:
wd.execute_script('storePop2(%d)'%i)
time.sleep(1) #스크립트 실행 동안 1초 대기
html = wd.page_source
soupCB = bs(html, 'html.parser')
store_name_h2 = soupCB.select('div.store_txt > h2')
store_name = store_name_h2[0].string
# print('%d : %s' %(i,store_name))
store_info = soupCB.select('div.store_txt > table.store_table > tbody >tr>td')
store_address_list = list(store_info[2])
# print(store_address_list)
store_address = store_address_list[0]
store_phone = store_info[3].string
result.append([store_name] + [store_address] + [store_phone])
except:
continue
return
# [CODE 0]
def main():
result = []
print('CoffeeBean store crawling---')
coffeeBean_store(result)
cb_tbl = pd.DataFrame(result, columns=('store', 'address', 'phone'))
cb_tbl.to_csv('./data/CoffeeBean.csv', encoding='cp949', mode='w', index=True)
print('완료')
if __name__ == '__main__':
main()
