
즐🙂겁😋다🤗푸🤐항😧항
DAG에 대해 알아보고, Airflow를 이용해 크롤링 자동화 task를 담은 DAG을 살펴보자.
DAGs(Directed Acyclic Graph)
DAG은 task간의 의존성과 관계를 하기 위해 task를 묶는 Airflow의 핵심 개념이다.
는 Airflow 공식 문서를 번역한 것이고, 쉽게 설명하면 다음과 같다. Airflow에서 파이프라인을 정의하기 위해 사용되는 것이라 보면 된다. DAG는 Directed Acyclic Graph의 약자로, 방향성이 있는 비순환 그래프이다. 아래 그림을 보면 이해가 쉬울 것이다.
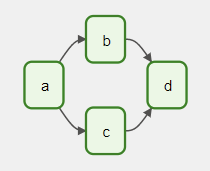
위 그림에서 각각의 사각형은 task를 의미한다. 즉, task들은 화살표로 이어져 있는데, 이 화살표는 task들 사이에 의존성이 존재함을 의미한다.
DAG은 간단히 파이썬 코드로 작성할 수 있다.
DAG 폴더
DAG을 작성한 파이썬 파일들은 $AIRFLOW_HOME/dags 디렉토리에 저장하는 것을 기본으로 한다. DAG 파일 디렉토리를 변경하고 싶다면 airflow.cfg에서 수정할 수 있다.
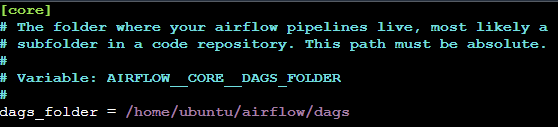
DAG 작성
아래 코드는 이 게시물을 베이스로 추가 작성하였다.
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from crawling_dev import *
def upload_to_s3():
date = datetime.datetime.now().strftime("%Y%m%d")
hook = S3Hook("de-airflow")
filename = f'/home/ubuntu/airflow/data/dev-crawler-{date}.csv'
key = f'data/dev-crawler-{date}.csv'
bucket_name = 'de-project-airflow'
hook.load_file(filename=filename, key=key, bucket_name=bucket_name)
with DAG (
dag_id = "de-project-dev-event",
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
"depends_on_past": False,
"email": ["your_email@gmail.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=30)
},
description="de-project-dev-event",
schedule_interval=timedelta(minutes=50),
start_date=datetime.datetime(2023, 11, 26),
tags=["dev-event"],
) as dag:
start = BashOperator(
task_id="start",
bash_command="echo 'start!'",
)
info = PythonOperator(
task_id = 'get_info',
python_callable = crawling
)
upload = PythonOperator(
task_id='upload',
python_callable = upload_to_s3,
trigger_rule = TriggerRule.NONE_FAILED
)
complete = BashOperator(
task_id = 'complete_bash',
depends_on_past = False,
bash_command = 'echo "complete"',
trigger_rule = TriggerRule.NONE_FAILED
)
start >> info >> upload >> complete코드를 하나씩 뜯어보자.
패키지 불러오기
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
from airflow.providers.amazon.aws.hooks.s3 import S3Hookdatetime: 날짜와 시간 계산 지원DAG: DAG을 구성BashOperator: Airflow에서 쉘 스크립트나 명령어를 실행하는 작업 정의PythonOperator: Airflow에서 Python 함수를 실행하는 작업 정의TriggerRule: task 실행 규칙 지정 (trigger rule 목록 보러가기)S3Hook: python으로 Amazon S3에 접근 (나중에 별도로 다룰 예정..)
함수 구성
task는 Airflow에서 지원하는 여러 Operator를 이용해 정의할 수 있다.
def upload_to_s3():
date = datetime.datetime.now().strftime("%Y%m%d")
hook = S3Hook("de-airflow")
filename = f'/home/ubuntu/airflow/data/dev-crawler-{date}.csv'
key = f'data/dev-crawler-{date}.csv'
bucket_name = 'de-project-airflow'
hook.load_file(filename=filename, key=key, bucket_name=bucket_name)S3에 관해선 나중에 자세히 다룰 것이기 때문에 여기선 넘어가겠다. 단순하게 크롤링한 데이터를 csv 파일로 저장해 S3에 적재하겠다는 의미로 이해하면 된다. 크롤링 코드 바로가기
task 및 DAG 구성
with DAG (
dag_id = "de-project-dev-event",
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
"depends_on_past": False,
"email": ["your_email@gmail.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=30)
},
description="de-project-dev-event",
schedule_interval=timedelta(minutes=50),
start_date=datetime.datetime(2023, 11, 26),
tags=["dev-event"],
) as dag:
start = BashOperator(
task_id="start",
bash_command="echo 'start!'",
)
info = PythonOperator(
task_id = 'get_info',
python_callable = crawling
)
upload = PythonOperator(
task_id='upload',
python_callable = upload_to_s3,
trigger_rule = TriggerRule.NONE_FAILED
)
complete = BashOperator(
task_id = 'complete_bash',
depends_on_past = False,
bash_command = 'echo "complete"',
trigger_rule = TriggerRule.NONE_FAILED
)BashOperator: bash shell 명령을 사용할 수 있는 operator- start 태스크는 bash로
echo "hello"라는 커맨드를 실행한다. - complete 태스크는 bash로
echo "complete"라는 커맨드를 실행한다.
- start 태스크는 bash로
PythonOperator: 파이썬으로 작성된 코드를 사용할 수 있는 operator- python_callable 인자에다 파이썬 함수를 적용해주면 된다.
- 더 디테일 dag 설정을 알고 싶다면 공식 문서를 참고하자.
task 의존성 정의
start >> info >> upload >> completeoperator로 만든 task들의 의존성을 설정한다. 여기에서는 branch 없이 매우 단순하게 task의 관계를 정의했지만, BranchPythonOperator를 이용해 분기 경로를 설정할 수도 있다.
DAG 실행
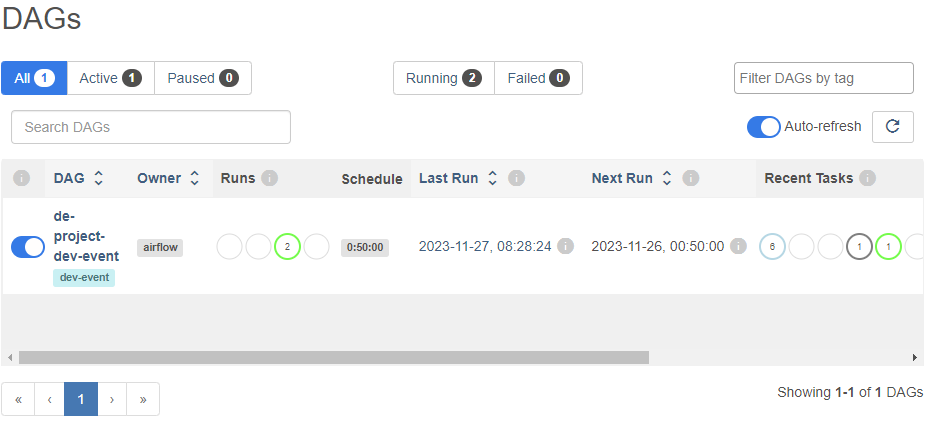
$AIRFLOW_HOME/dags에 dag을 구성한 파이썬 파일을 올려두고, airflow dags list 명령을 입력해본다. 오류가 없다면 아래와 같이 dag의 정보가 화면에 나타날 것이다.

scheduler를 실행시키고 airflow 웹서버에 접속해보면 dags 디렉토리에 올려둔 dag이 올라가 있을 것이다.
다음 게시글에서는 Amazon S3에 관해 자세히 설명해보겠다.
