Reference
📢본 게시글은 IBM Advocate팀 유튜브 강의영상을 보고 작성되었음을 밝힙니다!
👉자료 출처
API란?
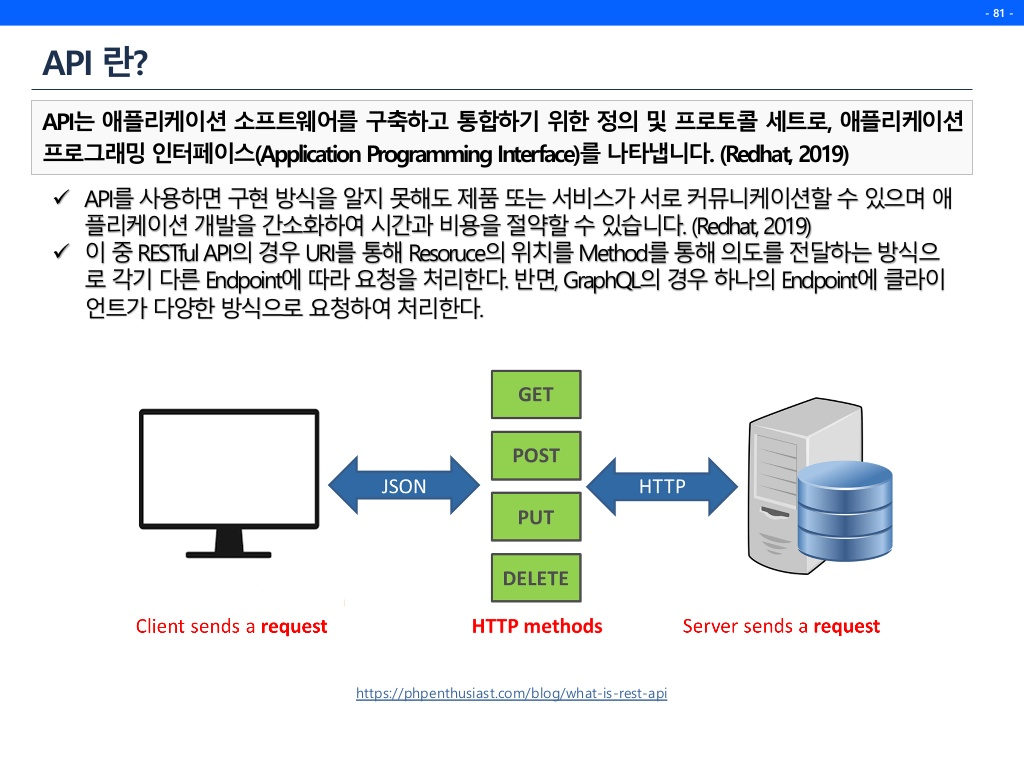
즉, client와 server간에 상호작용인 것이다.
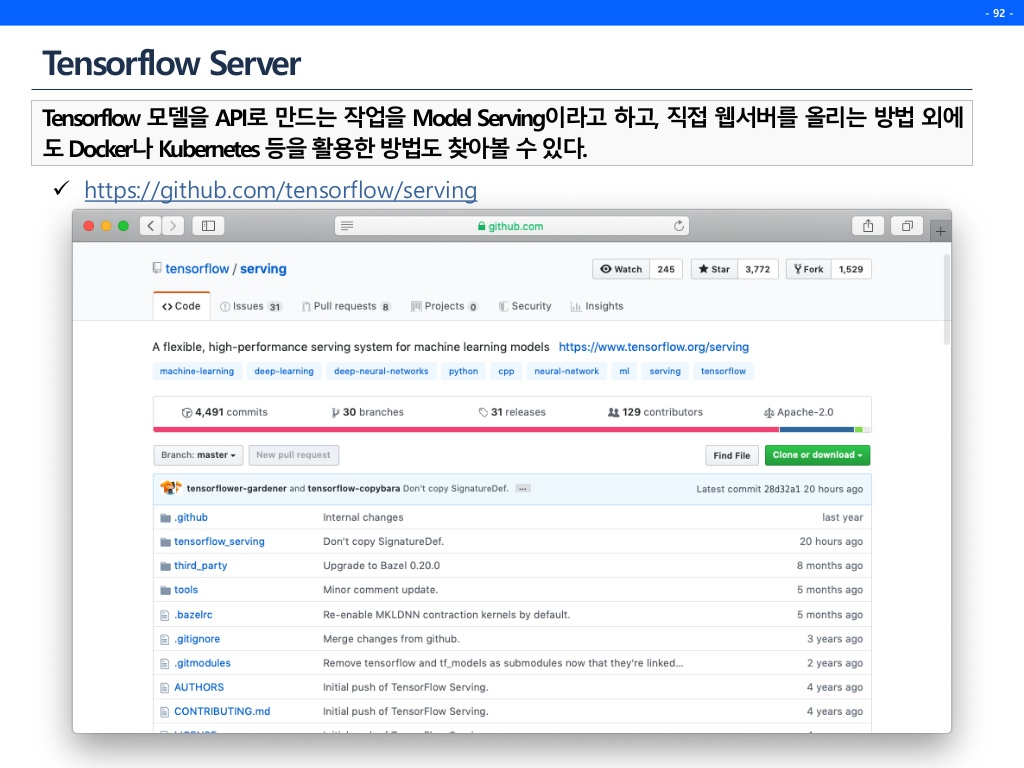
Flask API
Flask로 model serving하는 방법에 대해 알아볼 것이다.
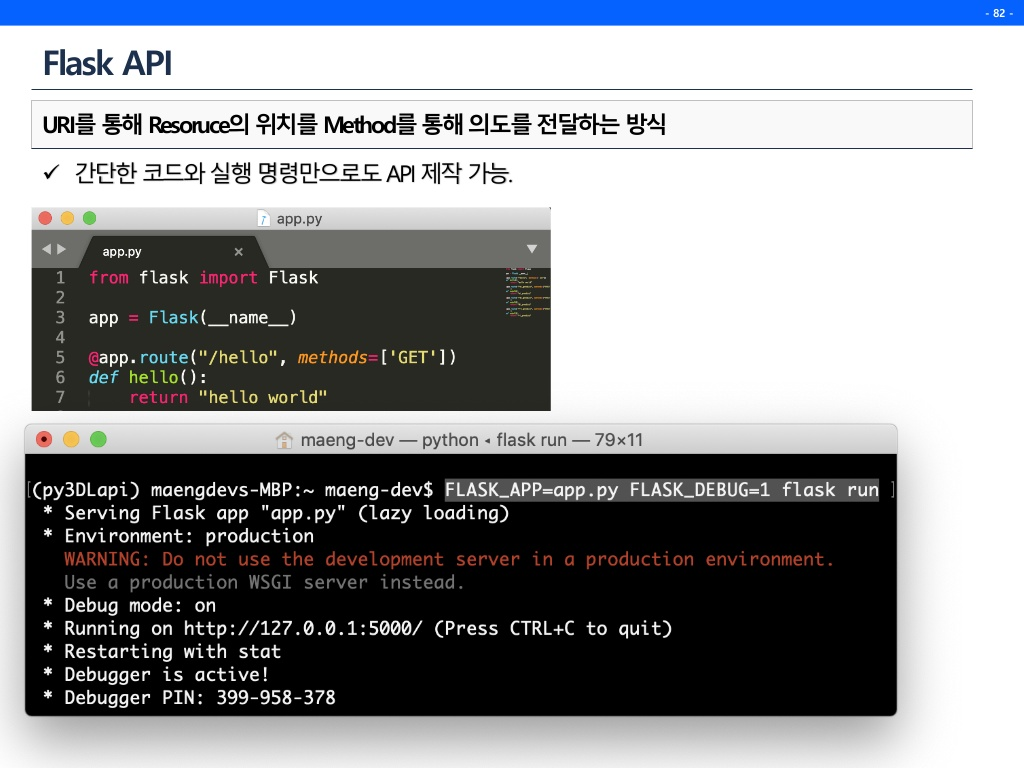
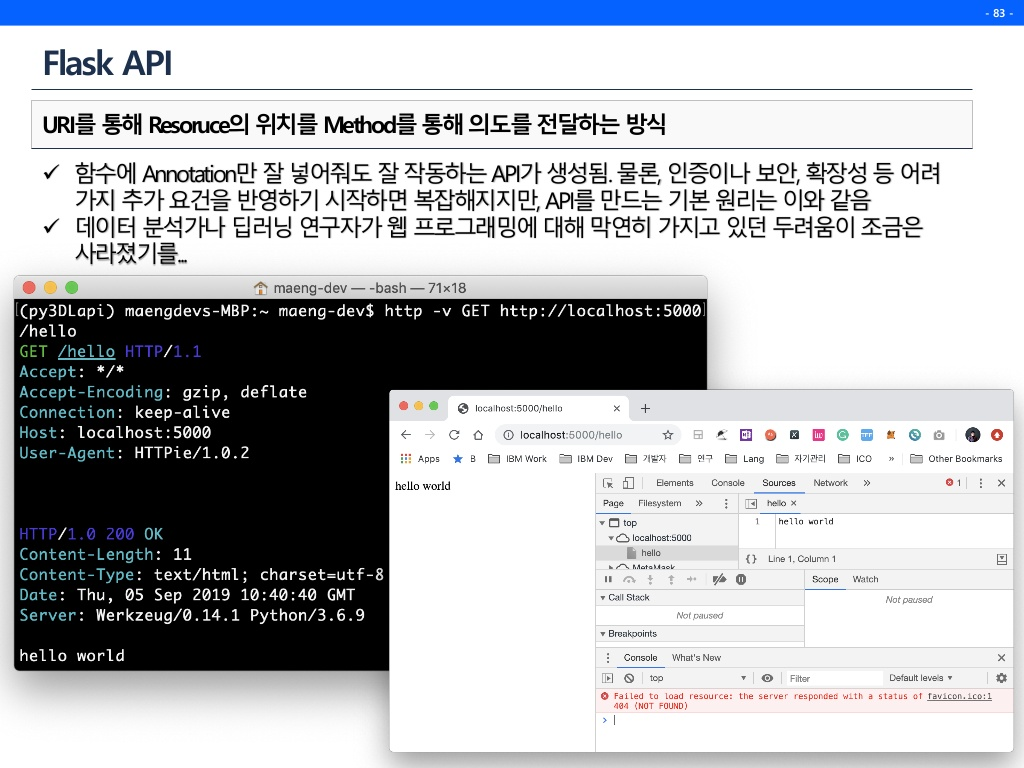

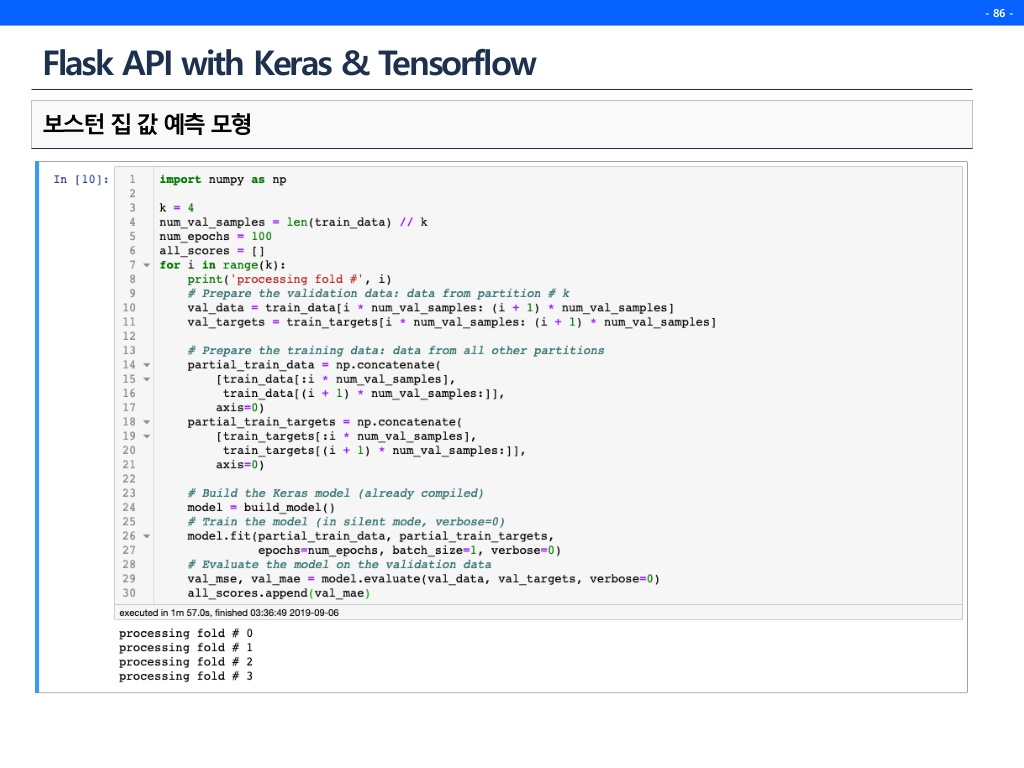
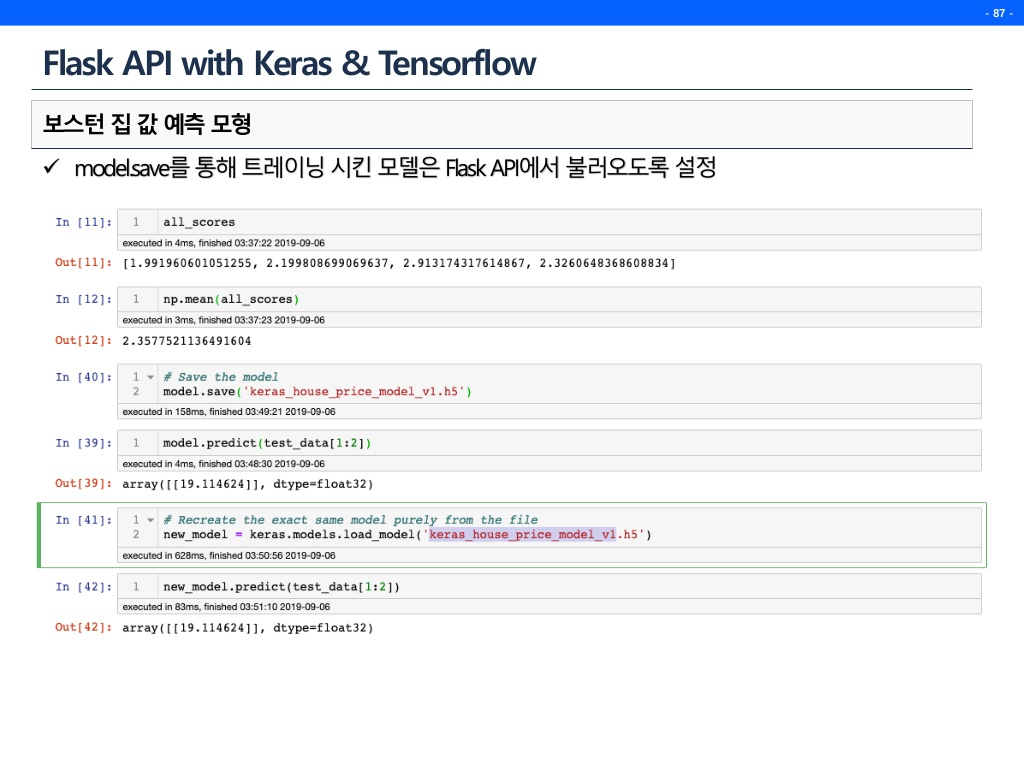
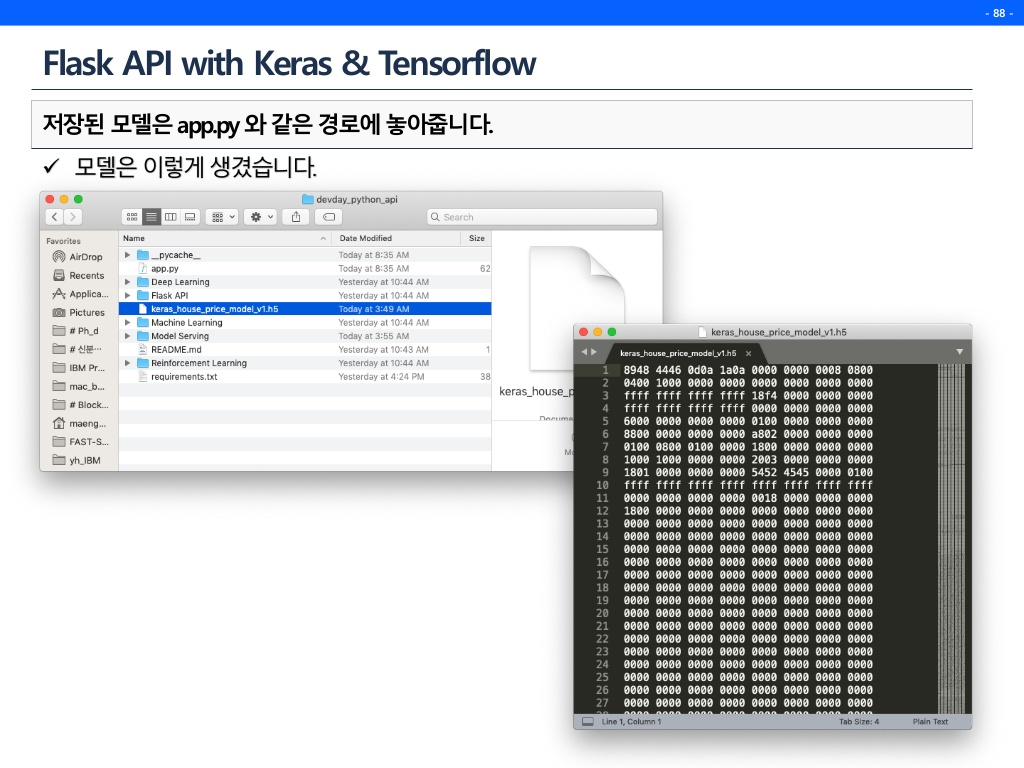
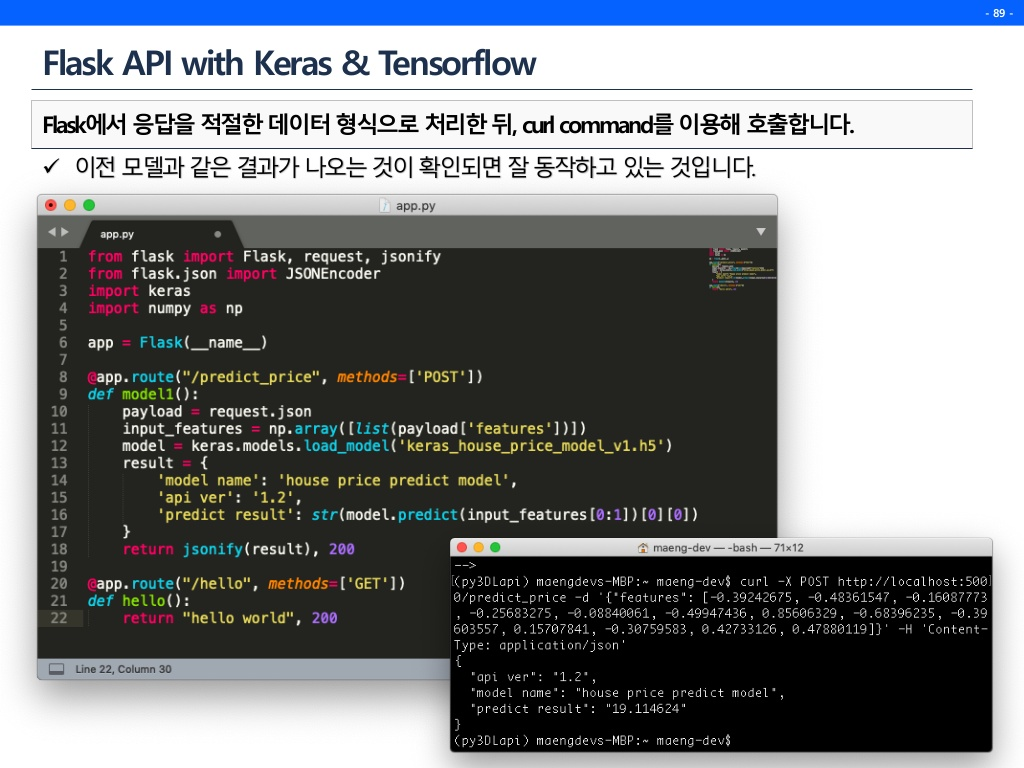
보통 예측 결과를 내고, 성능을 확인한 뒤 끝내는 경우가 대부분이다.(여기서 많이 뜨끔했다.) 하지만 모델 파일을 만들고 그 모델로 API를 만든다면 후에는 코드 몇줄만 추가하면 자유자재로 그 모델을 계속 호출하여 사용할 수 있다.
Pickle
sk learn 같은 경우는 모델을 저장하는 기능을 별도로 가지고 있지 않다. 따라서 python은 자체적으로 내장하고있는 pickle이라는 기능을 사용한다.

'나는 텐서플로우만 서빙하겠어!' 라고한다면, Docker를 이용하면 된다.
IBM
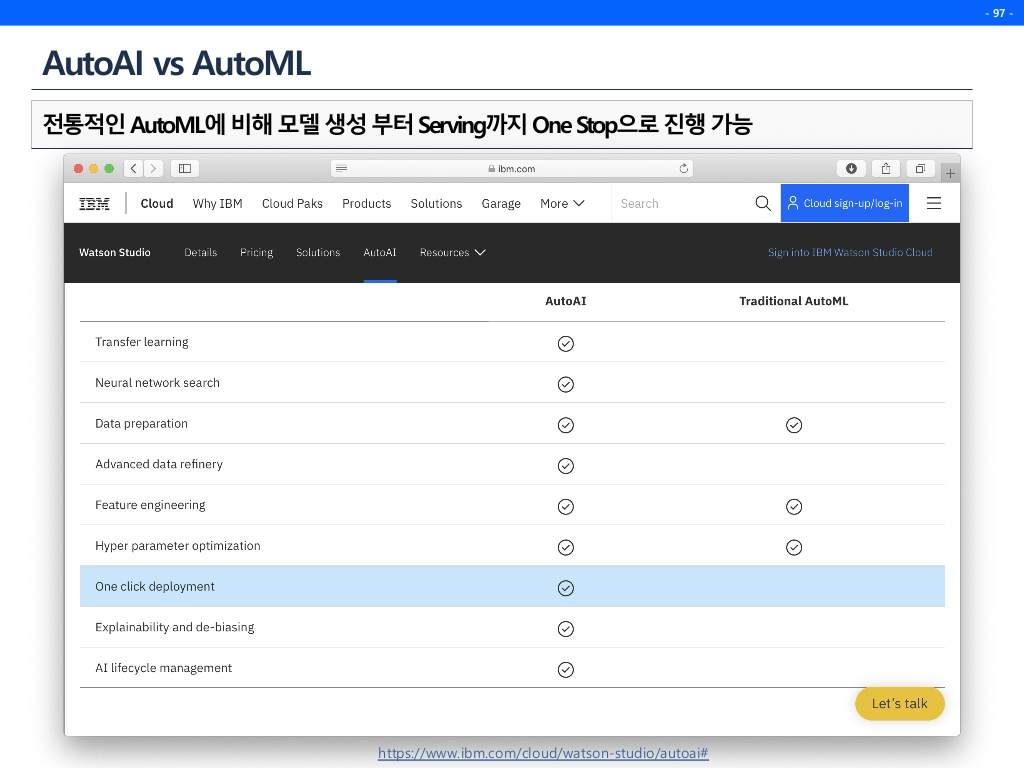
AutoAI with Watson

특히 아래 이미지에서 'One click deployment'란, 내가 데이터를 올리면 가장 최적화된 모델을 통해서 API로 자동으로 결과까지 뽑아주는 것이다.
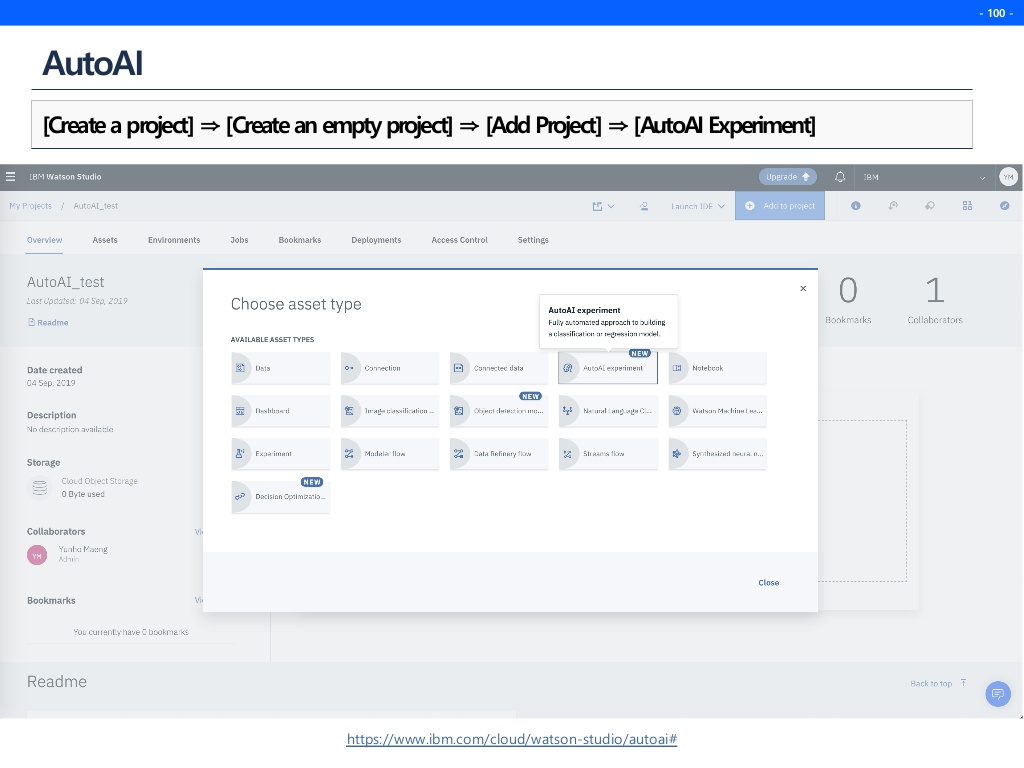
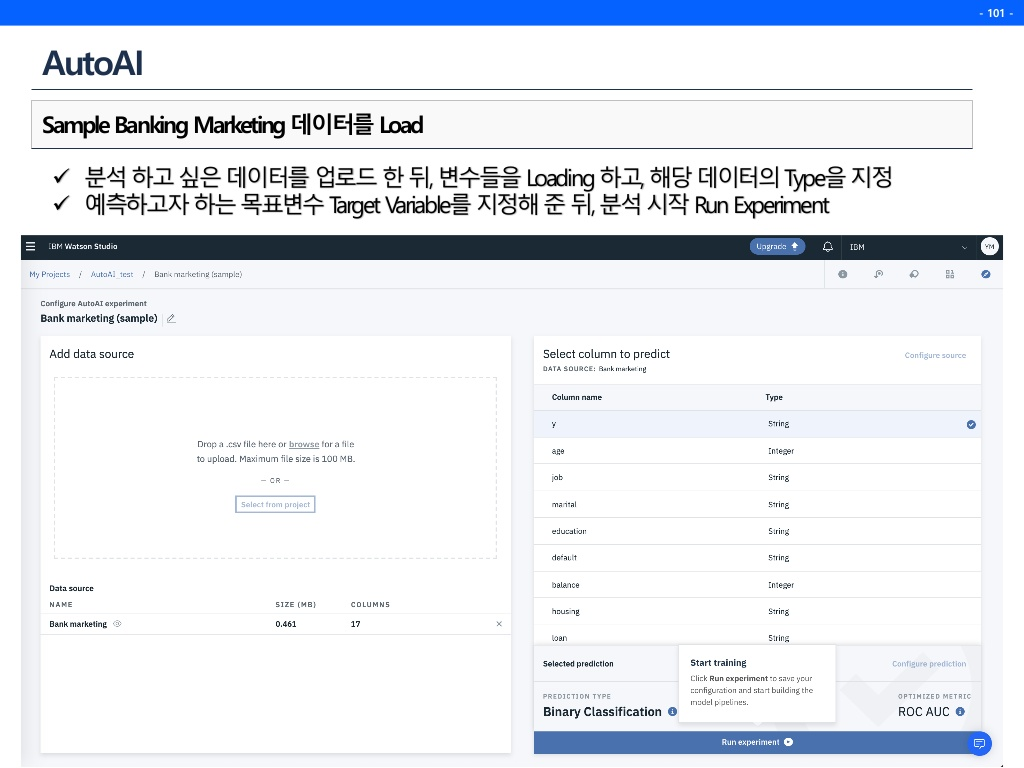
한가지 주의할 점은 autoAI가 지도학습 또는 비지도학습을 수행하려면 데이터의 target변수를 알려줘야 한다는 것이다. 아래 그림에서 ☑️체크표시가 목표변수를 체크하는 표시이다. 또한 그것이 연속형인지, 순서형인지, 범주형인지 지정해주면 돌기 시작한다.
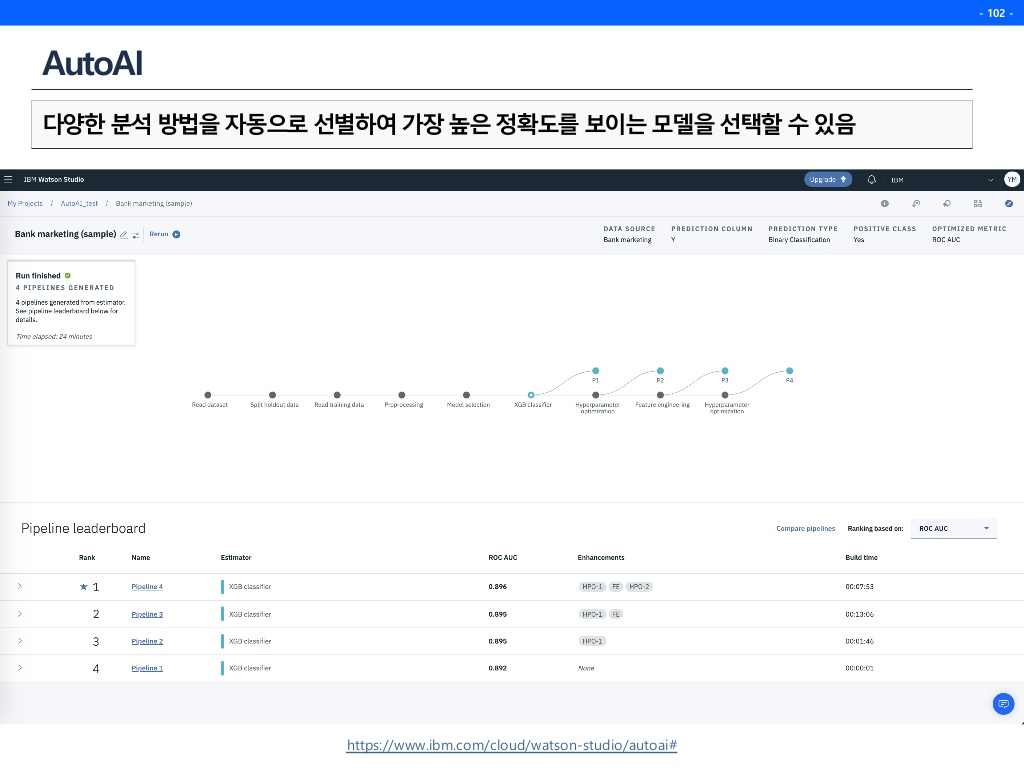
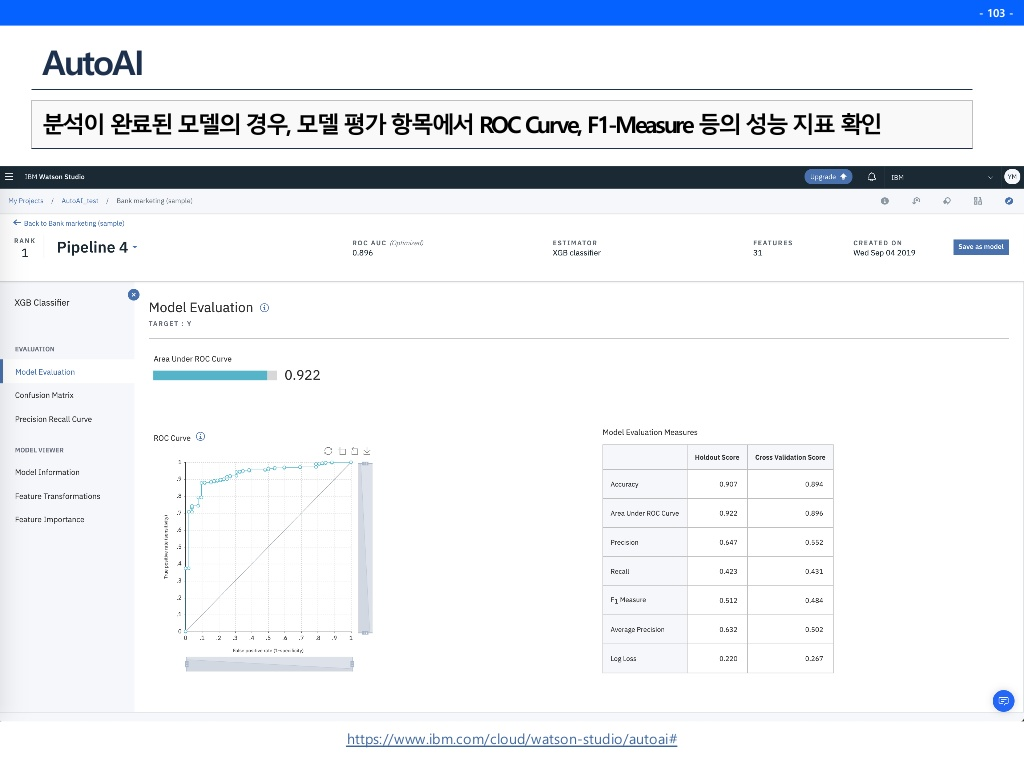
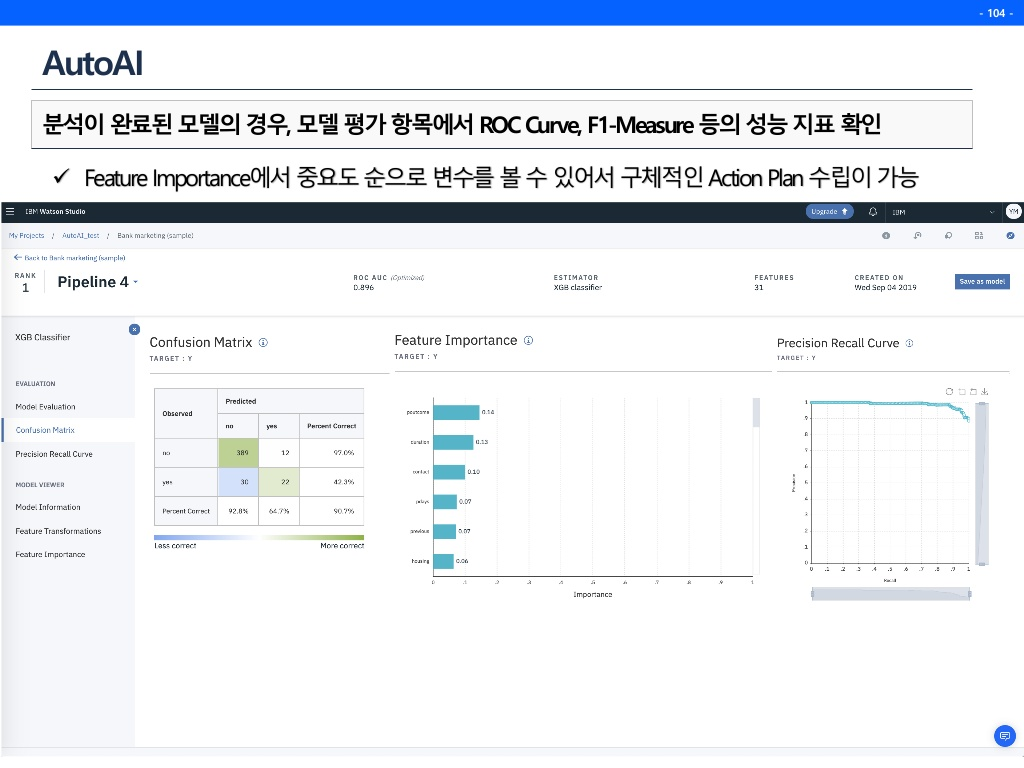
아래의 버튼을 누르면 한방에 API가 나온것을 확인 가능하다. 아래의 Code Snippets는 python코드로 어떻게 호출할 수 있는지를 보여주고있다.
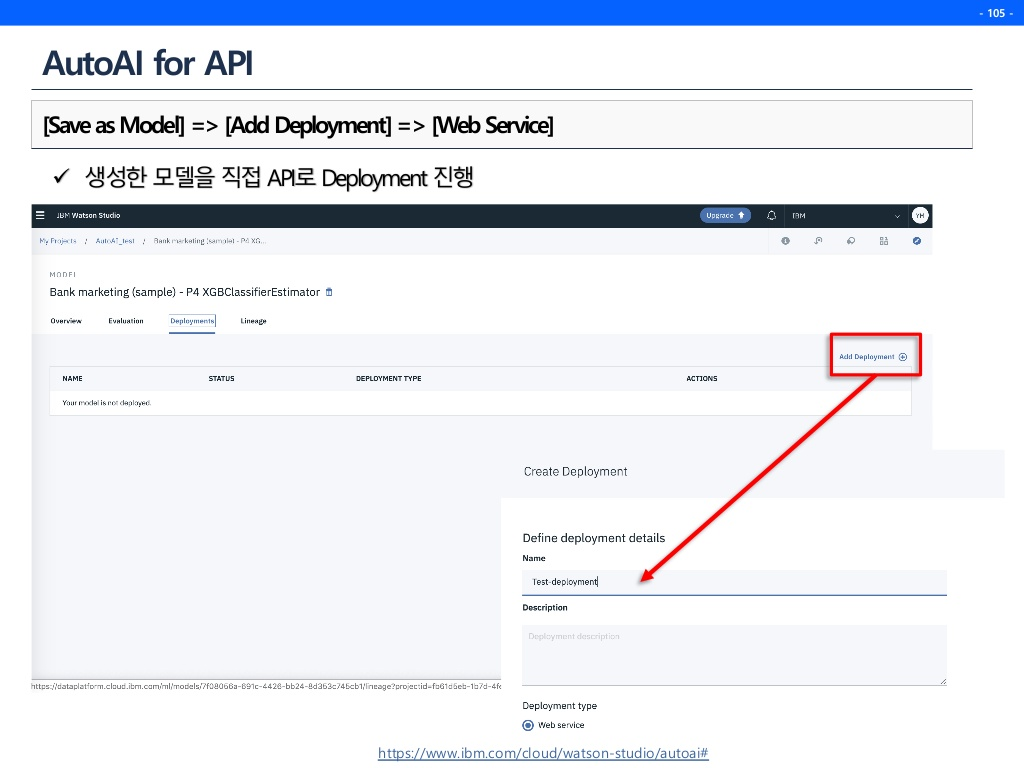
내가 데이터만 잘 올리면 모델 생성, 분석, API생성까지 A to Z를 수행해주는 것이다. 앞으로의 데이터 분석의 방향은 이러할 것이다!
Notebook in Watson Studio
좀더 매뉴얼하게 하고싶다면 cloud상에서 jupyter notebook을 띄울 수 있다.
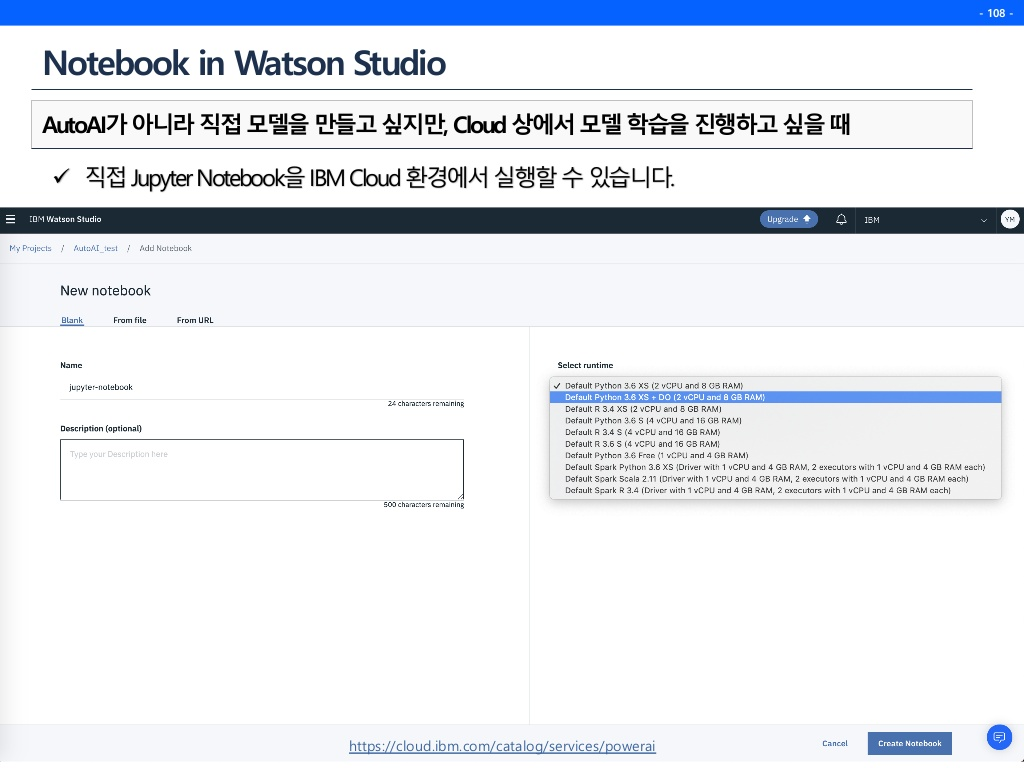
또한 그동안 있었던 예제들을 확인해볼 수 있는데, 대표적으로 챗봇 성능 확인코드가 있다.
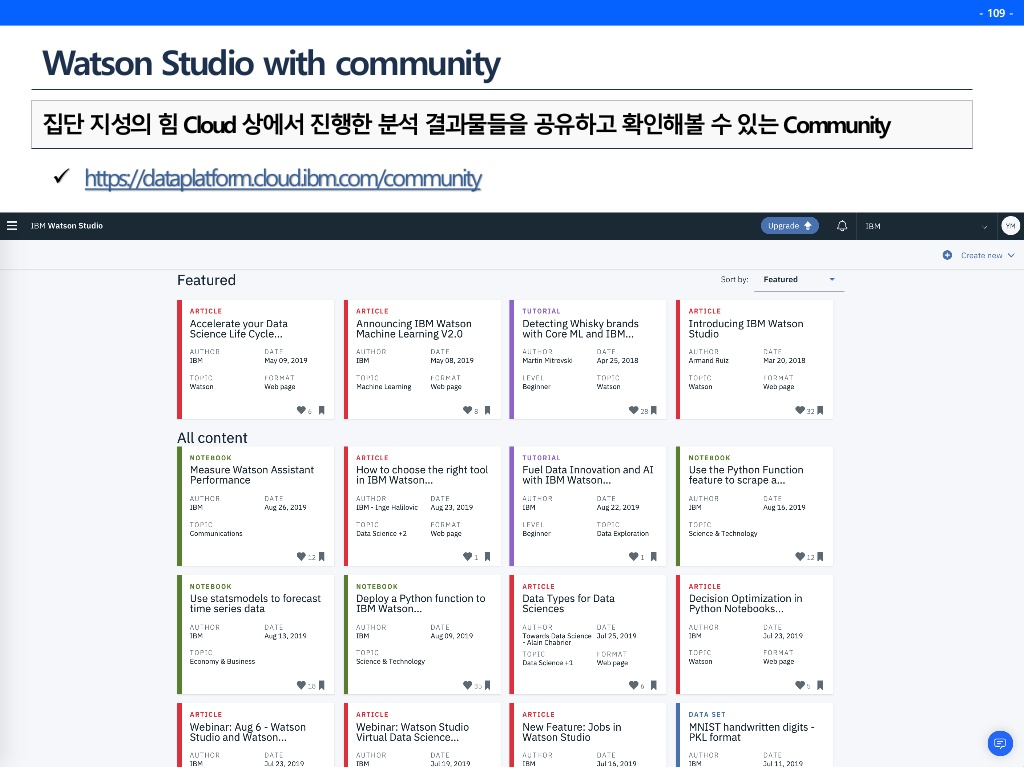
요즘 쓰니는 머신러닝 스터디를 진행중인지라 더욱 흥미롭게 다가왔다. 다음 글에서는 이미 분석 실습을 진행한 데이터를 IBM AutoAI로 돌려보고 비슷한 성능이 나오는지 확인해 볼 것이다.
