고객 만족 예측 분류 실습
내가 분류 기법 중 XGBoost와 LighGBM 모델을 이용하여 실습을 진행했던 데이터 셋을 IBM Watson Studio의 AutoAI에 적용시켜보고자 한다.
사용할 데이터 : Kaggle 산탄데르 고객 만족 데이터셋
여기서 train.csv 파일을 다운받는다.
해당 데이터 셋은 산탄데르 은행이 캐글에 경연을 의뢰한 데이터로서 370개의 피처 이름은 모두 익명 처리돼 이름만을 가지고 어떤 속성인지는 추정 할 수 없다. 클래스 레이블 명은 TARGET이며, 이 값이 1이면 불만을 가진 고객, 0이면 만족한 고객이다.
불만족 고객의 비율은 4% 밖에 되지 않는다.
💡내가 실습했던 과정
1.데이터 전처리
어떤 칼럼은 최솟값이 -999999로, 다른 값에 비해 편차가 매우 심해서 나는 가장 데이터 갯수가 많은 2로 변환했었다.
2.하이퍼 파라미터 튜닝
두 모델 모두 GridSearchCV를 이용하여 최적 파라미터를 찾고 모델에 적용하여 학습시켰다.
최종 ROC AUC는 XGBoost일때 0.8456, LighGBM일때 0.8442로 도출되었다.
Watson Studio의 AutoAI는 더 개선된 결과를 도출할 수 있을까?
튜토리얼
- IBM korea의 Watson Studio
만약 튜토리얼을 실행하고 싶다면 아래와 같은 과정을 거치면 된다.
AutoAI학습서 시작하기를 선택하고 필요한 정보를 입력한다.
그러면 튜토리얼을 따라해볼 수 있다.
실행해보기
이제 직접 실행해볼 차례다.
클라우드에서 무료 시작 선택 후 IBM id로 로그인하면 IBM Cloud Pak Data화면이 뜬다.
IBM Cloud Pak Data에서 Create a Service선택한다.
1. 필요 서비스와 프로젝트 생성
1.모두 라이트 플랜으로 세 가지 서비스를 생성한다.
- Watson Studio 서비스 생성
- Machine Learning 서비스 생성
- Object Storage 서비스 생성
2.대시보드로 이동하여 리소스 목록에서 조금 전 생성한 Watson Studio 서비스 → get started클릭
3.New Project 선택
4.보유한 파일을 데이터로 올리기 위해 Create a project from a sample or file 선택
5.Create a project → Create an empty project
6.프로젝트명 작성
💡 project option 는 미체크. 옵션 체크시 생성한 프로젝트는 정의한 다른 사용자(collaborator)만 접근 가능함
7.앞서 생성한 IBM Cloud Object Storage service 선택
2. Watson Service 프로젝트에 Machine Learning 서비스 연결
- 프로젝트의 Setting 탭 이동
- Associated Service 이동
- Add service에서 Watson 선택
- Machine learning 선택
- Add 클릭
- Existing 탭 클릭
- 기존 생성한 Machine learning 서비스 선택
- Select 클릭
3. AutoAI Experiments 수행
- Project의 Asset 탭 이동
- AutoAI experiments 섹션에서 오른쪽 New AutoAI Experiments+ 클릭
- From Blank 선택
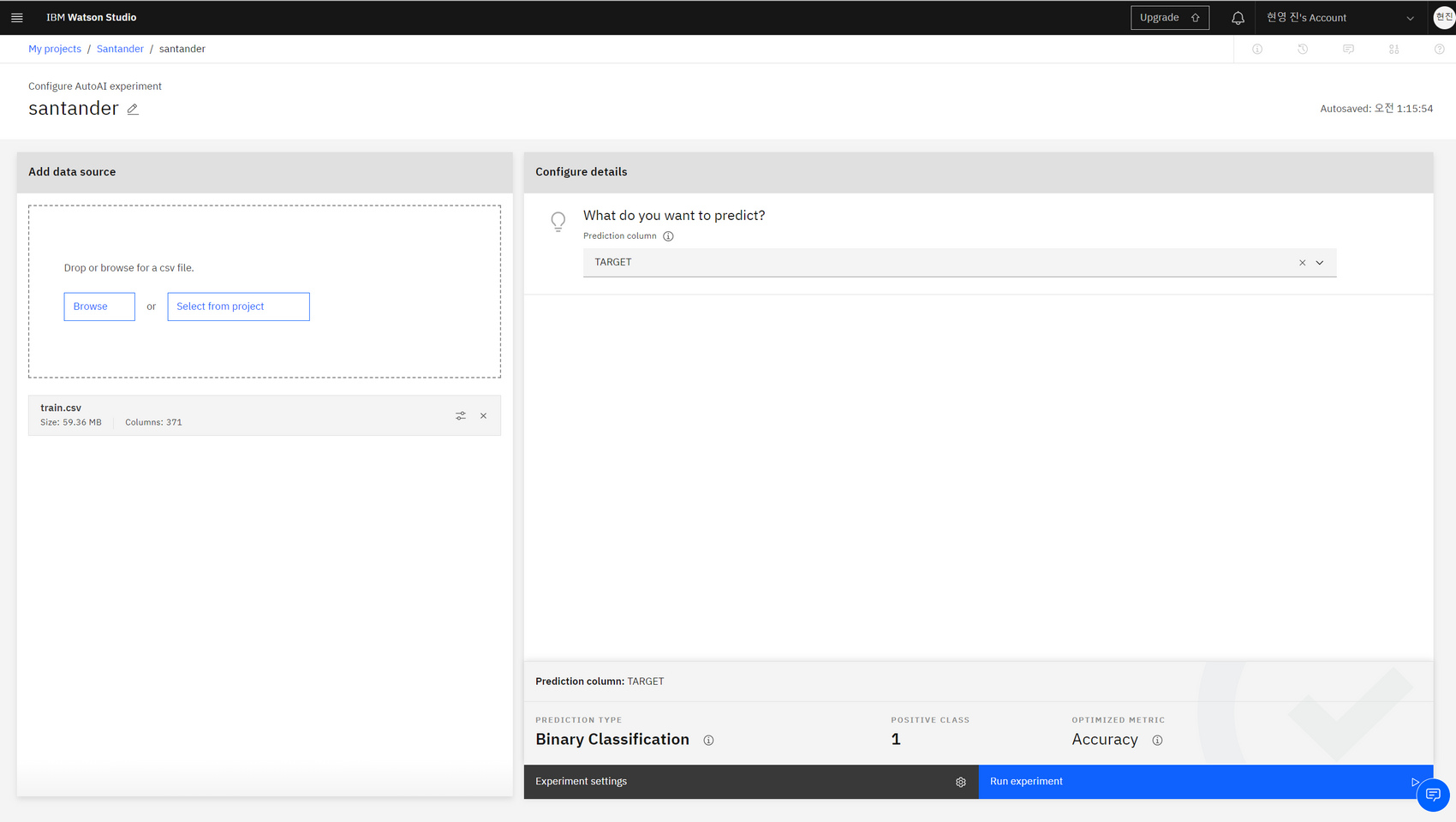
- Asset name 작성 (예)santander
- 학습데이터 업로드를 위해 Browse 선택
- 업로드된 데이터 확인
- 예측속성 선택 : TARGET
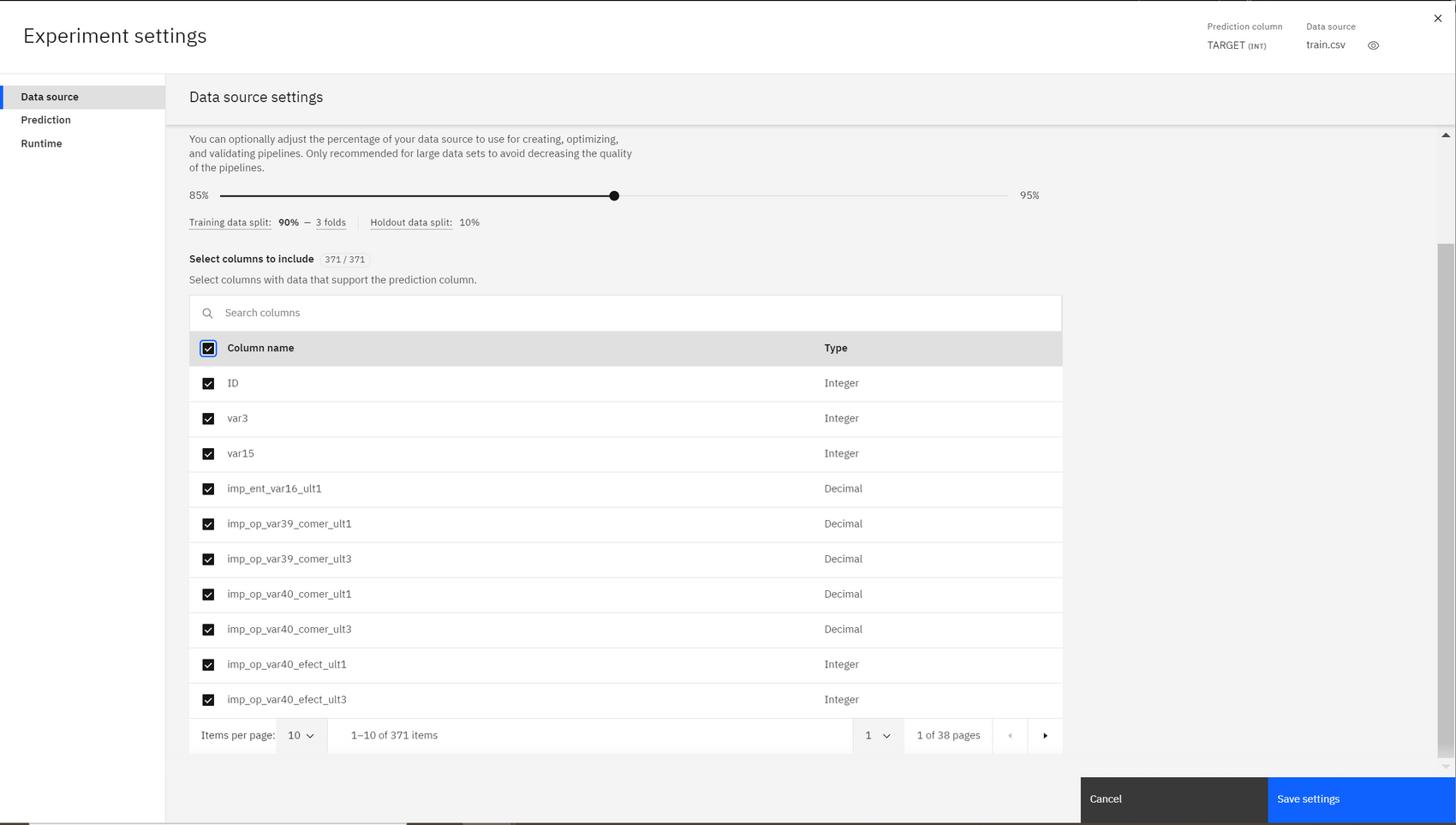
(Experiment settings 선택하여 학습에 필요한 칼럼 정보 확인 혹은 제거할 수 있다.) - Run experiment 클릭
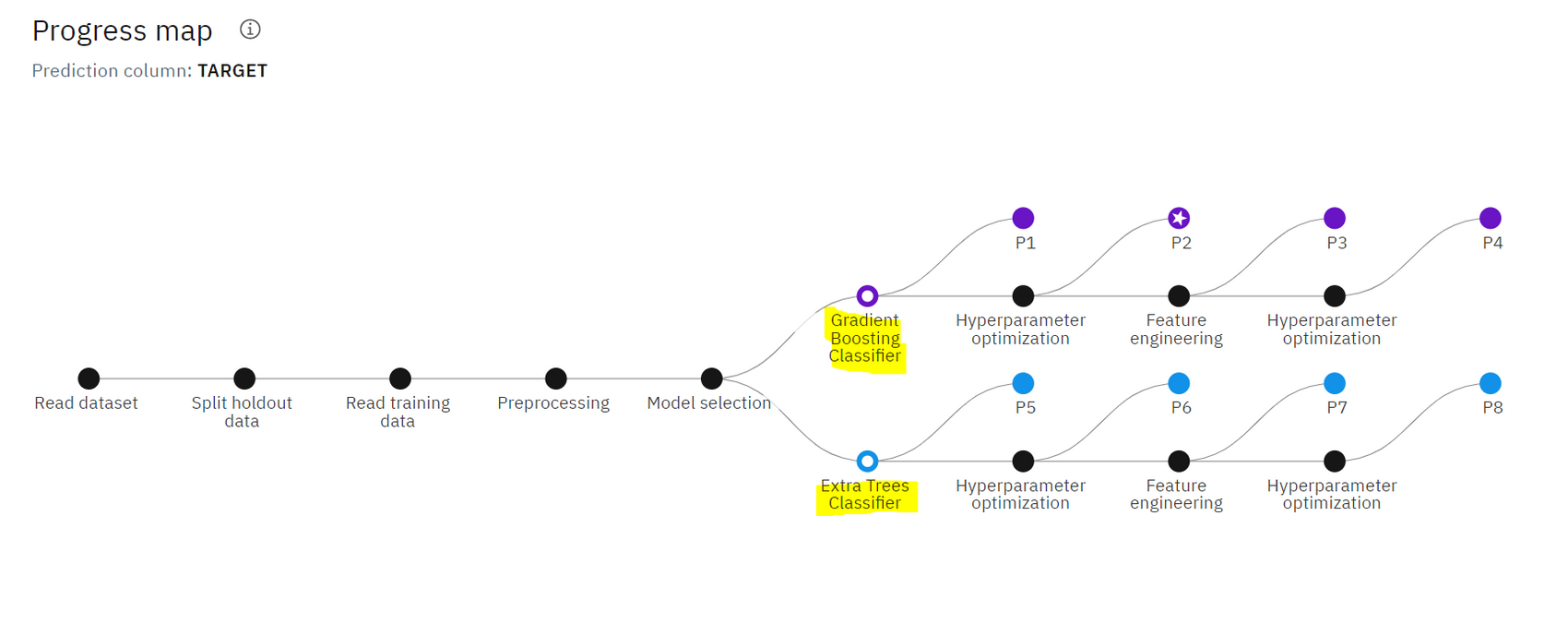
스스로 전처리도 하고, 모델도 select한다.
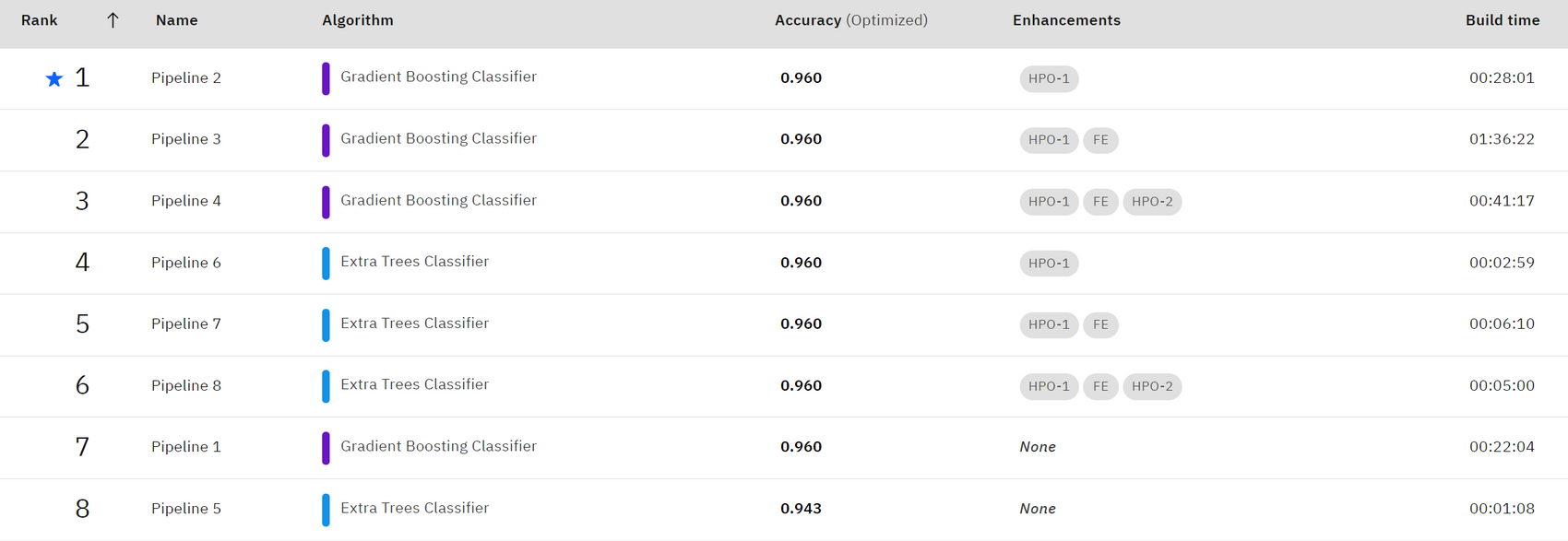
어떤 모델을 선택할지 궁금했는데, Gradient Boosting Classifier와 Extra Tress Classifier를 선택하였다. 같은 Boosting을 사용하는 걸 확인하니, 흥미로웠다.
학습완료 후 각 파이프라인의 랭킹과 정확도를 확인할 수 있다. 0.96으로 매우 높은 정확도가 도출되었다.
데이터 변환이후 모델 정확도 측정, 하이퍼 파라미터 최적화 이후 모델 정확도 측정, 피쳐 엔지니어링이 적용된 후의 모델 정확도 측정, 피쳐 엔지니어링+하이퍼파라미터 최적화 적용된 모델 정확도 측정의 총 4단계의 정확도 결과가 제공된다.
데이터 소스에 따라 후보 알고리즘은 1개 이상이 될 수도 있다고 한다.
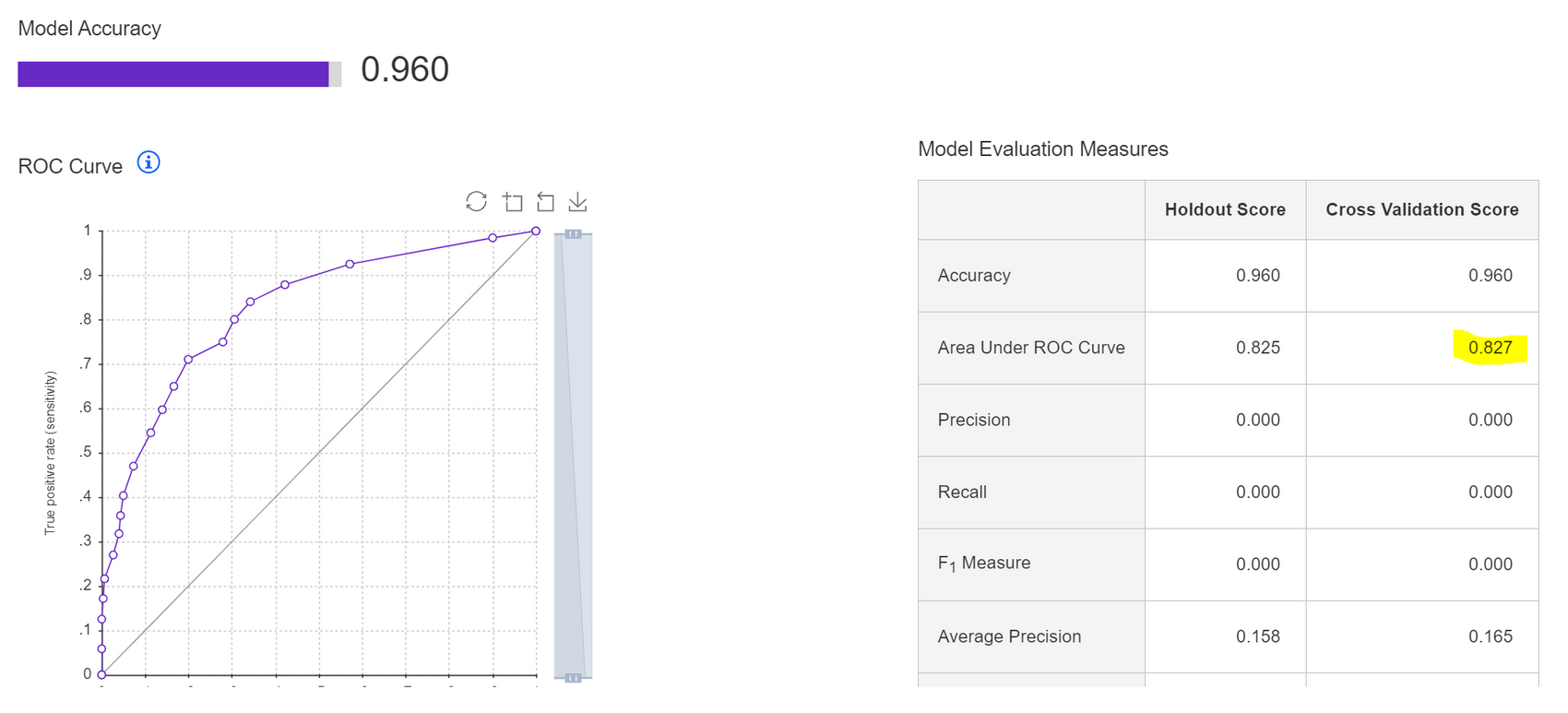
Rank1 의 Pipeline2 결과를 자세히 살펴보았다. 교차 검증 후 ROC AUC는 0.827로, 내가 진행했던 실습 결과인 0.84보다 조금 낮지만 근접하게 도출되었다.
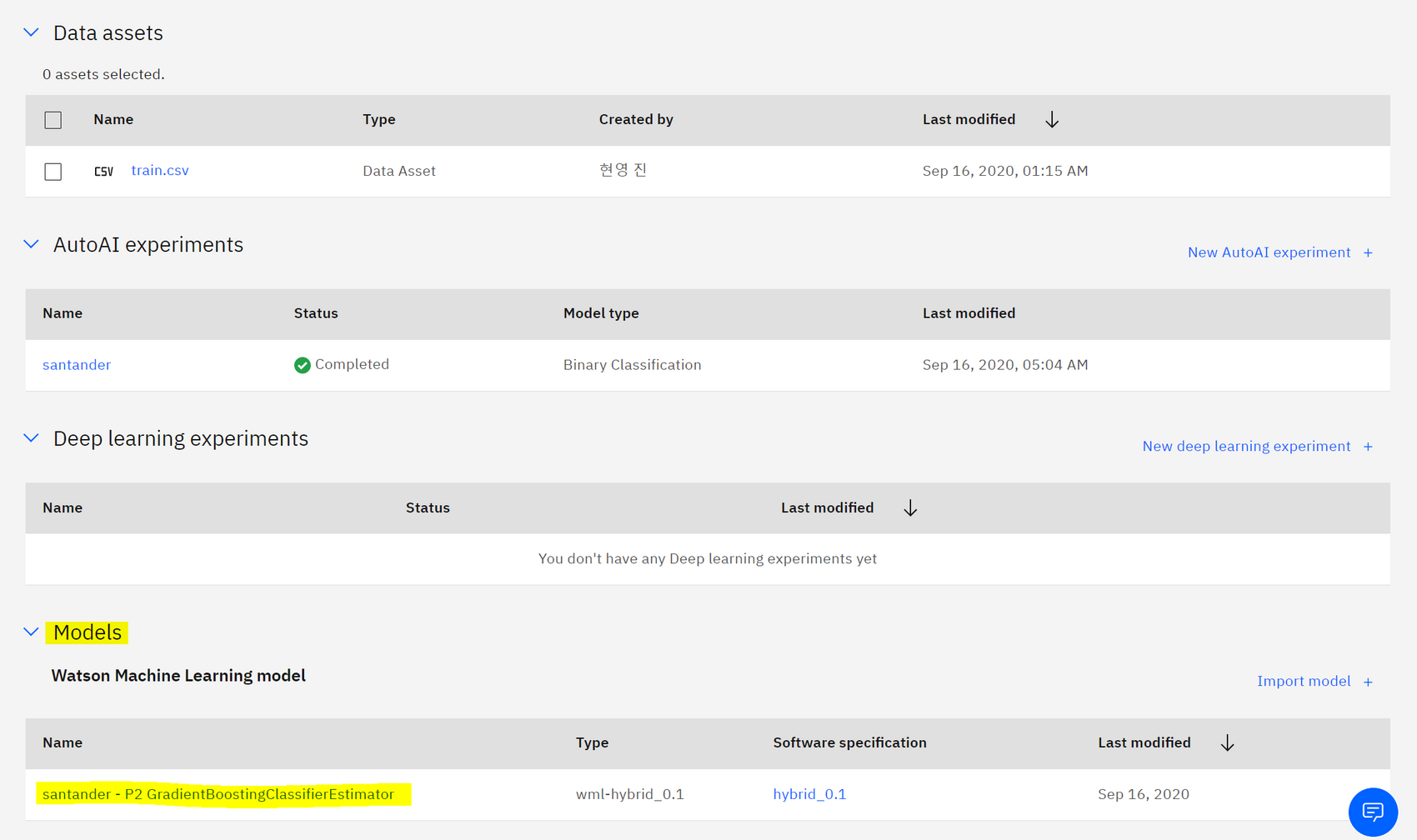
Save As → model 로 확정한 단계의 모델을 저장한다.
4. AutoAI Experiments 생성된 저장 모델 배포하기
1.프로젝트 첫 화면으로 이동

2.Deployment spaces에서 오른쪽 상단 Add to space선택 후 deploy라는 이름으로 생성
3.Models 섹션에서 저장된 모델 확인 후 Promote to deployment space → 생성한 'deploy'선택
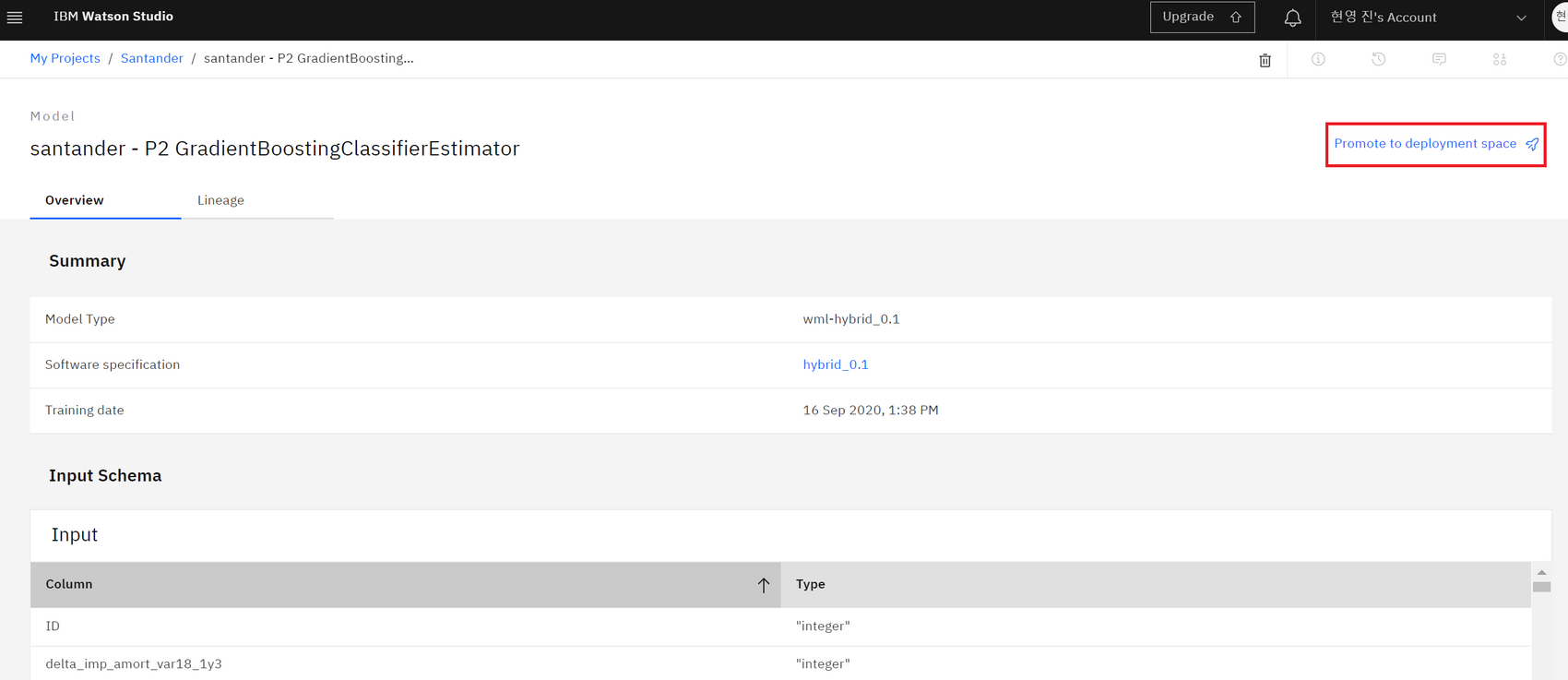
4.deploy로 들어가보면 모델이 들어와 있음 → 거기서 비행기 모양 Deploy선택
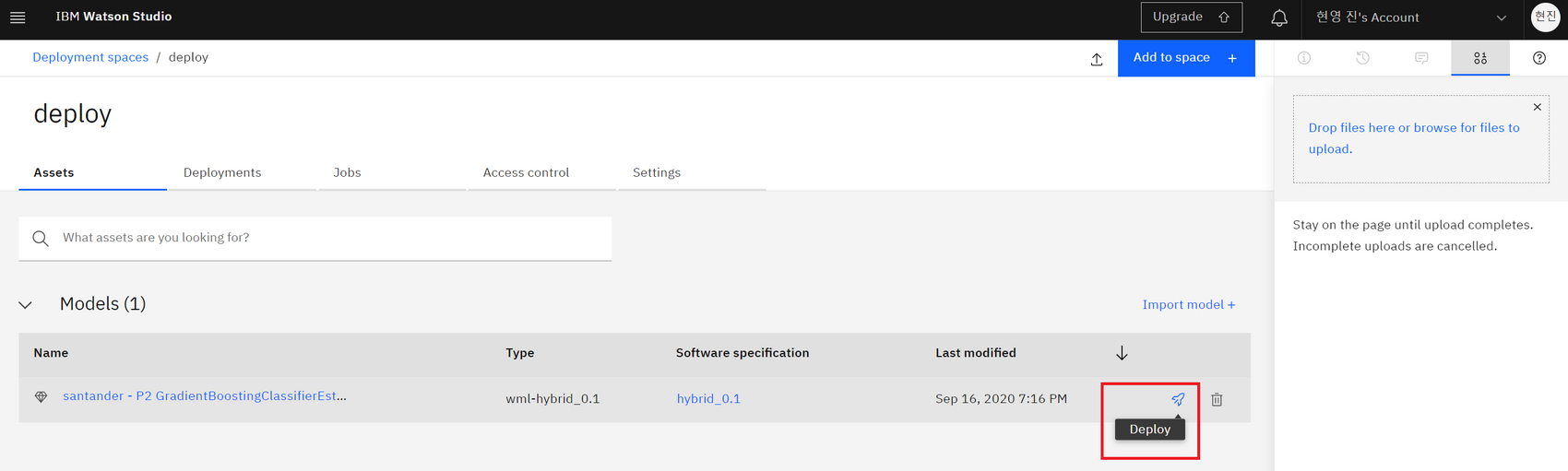
5.원하는 배포 타입 선택, Deployment명 작성 및 Create
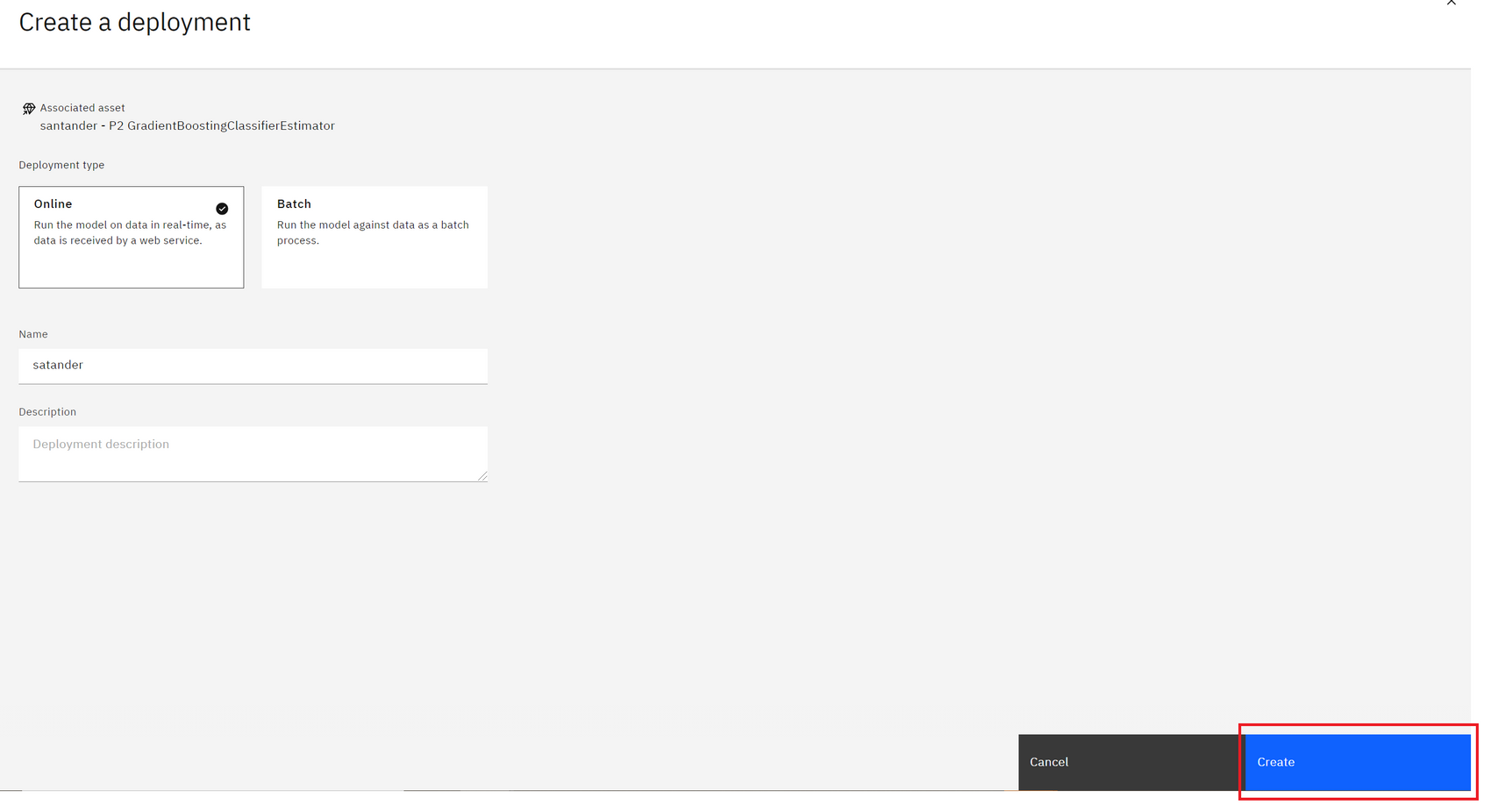
🚀 AutoAI.. 한 번 편리함을 느끼면 빠져나올 수 없다..!🌌
- 데이터 준비
- 모델 개발
- 피쳐 엔지니어링
- 하이퍼 파라미터 최적화
이 모든걸 자동화하는 통합형 UI인데다가, 준비가 완료되면 배치할 서비스를 저장하고 선택하는 원클릭 배치까지..! 신세계를 경험했던 실습이었다고 한다✨
