Cheng, Bowen, et al. "Boundary IoU: Improving object-centric image segmentation evaluation." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
Abstract
우리는 boundary quailty에 초첨을 둔 새로운 segmentation 평가 지표, Boundary IoU를 제시한다. 우리는 다양한 에러 타입과 객체 크기에 대해 철저한 분석을 실시했고, Boundary IoU가 Standard Mask IoU에 비해 큰 객체의 경계 에러에 더 민감하고, 작은 객체의 에러에 대해 over-penalize 하지 않았다. 새로운 평가 지표는 다양한 prediction / gt 쌍과 크기에 따른 균형잡힌 반응성(??) 등의 우수한 특성을 보인다. 이는, segmentation 평가에서 다른 boundary-focused measure(Trimap IoU, F-measure → 팔로우업 해야겠다. ) 보다 더 적합하다. boundary iou에
기반하여, 우리는 instance와 panoptic segmentation 과제에서 standard 평가방법인 Boundary AP, Boundary PQ 지표를 업데이트 했다. 우리의 실험결과를 보면, 새로운 평가 지표가 현재의 mask-iou 기반의 평가 지표에서 일반적으로 무시되는 boundary quality를 향상시킨다. 우리는 새로운 boundary-sensitive 평가 지표가 boundary quality를 향상시키는 segmentation methods에 빠른 발전을 가져올 것으로 기대한다.
1. Introduction
공통 과제 framework는, 표준화된 과제, 데이터셋, 평가 지표는 연구 진행 상황을 추적하고, 향상된 결과를 내기 위해 사용된다. 예를 들어, pixel level binary mask로 세부 객체를 구분하는 알고리즘을 요구하는 instance segmentation에 대해 연구하는 사람들은 COCO dataset에 대해 AP를 향상시켜왔다. (2015년에서 2019년까지 상대적으로 86% 향상)
하지만, 이러한 과정은 모든 모델 오류에 대해 동등하지 않다. 왜냐하면, 다른 평가 지표는 다른 에러 타입에서 민감하거나 무감각하기 때문이다. 만약, 평가지표가 공통 과제 framework에 장시간동안 사용된다면, 해당 sub-field에서 이 metric의 민감한 유형의 에러를 빠르게 개선시킨다. 다른 유형의 오류를 개선하는 방향은 더 느리게 진전하며, 그러한 개선은 정량화하기 어렵다.
이러한 현상은 instance segmentation에서도 발생하는데, AP(성능)을 높인 다수의 연구는 boundary quality에 대한 언급이 거의 없다.
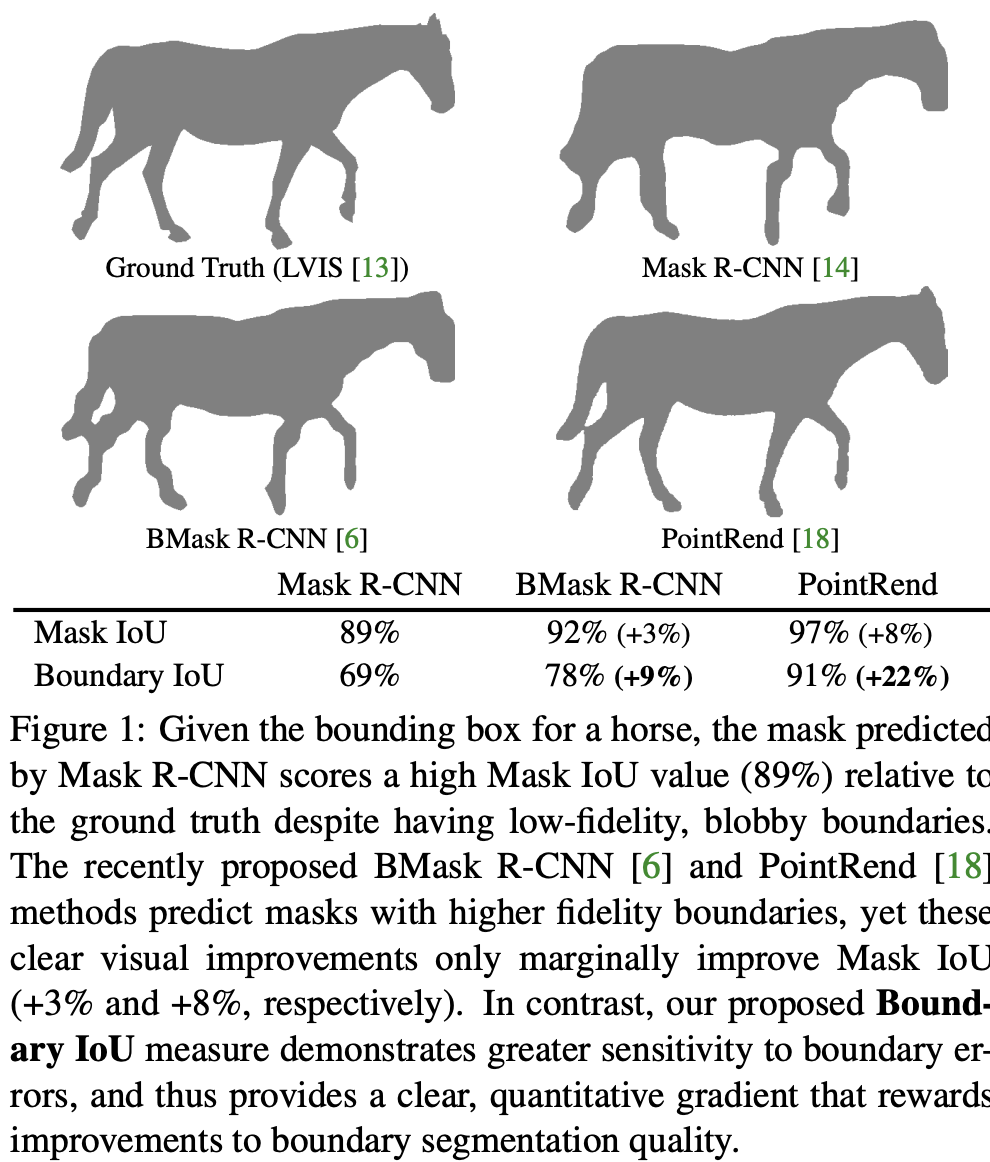
mask boundary quality는 image segmentation에 중요한 부분으로, 정확한 object segmentation은 다른 하류 분야에 직접적으로 도움이 된다. 하지만, 일반적으로 사용되는 Mask-RCNN 기반의 방법론은 저 품질의 blobby mask(덩어리 마스크)를 예측하는 것으로 알려져있다 (Figure 1 참고). 관찰 결과는 현재의 평가 방법이 객체 경계 근처의 mask error를 예측하는 것에 대해 (민감도?) 한계가 있음을 시사한다.
그 이유를 이해하기 위해, 우리는 예측된 mask와 gt mask를 비교하는데 사용되는 AP에서 근본적인 평가 방법인 Mask IoU를 분석하는 것에서 시작한다. Mask IoU는 두 교집합 영역을 합집합 영역으로 나누어서 계산한다. 이러한 방법은 모든 픽셀을 동등하게 다루기 때문에, 큰 객체의 boundary quality에 대해 덜 민감하다. *(*객체 크기가 커질수록 객체의 interior pixel 수는 제곱으로 증가하고, boundary pixel은 그저 선형적으로 증가하기 때문이다.) **본 연구에서, 우리는 모든 스케일(규모)에 대해 boundary quality에 민감한, image segmentation을 위한 평가 방식을 정의하는 것을 목표로 세웠다.
목표를 향해, 우리는 Mask IoU와 같은 표준 segmentation 평가 방식과, Tripmap IoU, F-Measure와 같은 boundary focused 평가 방식을 공부했다. 우리는 각 평가 방식에서 오류 민감도 특징을 연구하기 위해, LVIS 데이터셋의 고 품질 gt mask 위에 다양한 error types을 생성했다. 우리의 분석은 mask iou가 큰 객체에 대해 에러 민감도가 덜 민감하다는 것을 보인다. 덧붙여, 현재 존재하는 boundary-focused 평가 방식이 ‘비대칭성’이거나 ‘작은 변화에 대해 불안정’하다는 한계도 보여주었다.
이러한 통찰력(분석결과)를 기반으로 우리는 새로운 Boundary IoU 평가 지표를 제안한다. Boundary IoU는 간단하고 쉬운 계산이다. 모든 픽셀을 계산하는 대신에, 이는 gt 또는 prediction boundary contours (예측 경계 윤곽)과 대응하는 일정 거리 이내의 mask pixel의 IoU를 계산한다. 우리의 분석은 boundary iou 평가 방식이 큰 객체의 boundary quality를 잘 측정하고, 작은 객체에서도 over-penalize하지 않음을 입증한다. boundary iou와 mask iou를 비교한 모든 일러스트 예제를 figure 1에 있다.
boundary iou는 새로운 task-level(작업 수준)의 평가 지표에 사용가능하다. instance segmentation task에서, 우리는 boundary average precision을 제안한다. panoptic segmentation에서는 boundary panoptic quality 지표를 제안한다.
boundary ap는 이전의 instance segmentation을 위한 boundary focused metrics(e.g., AF)가 FP rate를 무시했던 것과 다르게, instance segmentation의 모든 측정 부분을 평가하며, 동시에 categorization, localization, segmentation quality도 고려한다. 우리는 boundary AP를 3가지의 데이터셋에 대해 테스트 했다: COCO, LVIS, Cityscapes. 최근 instance segmentation 방법의 예측 결과를 활용하여 Boundary AP가 Mask AP보다 잘 개선되었는지 확인한다(개선사항을 잘 추적하는지 ???? 이건 해석이 이상함). 또한, synthetic prediction(합성 예측)을 사용해서 boundary ap가 mask ap 보다 큰 객체의 boundary quality에서 상당히 sensitive하다는 것을 보여준다.
Panoptic Segmentation에서, 우리는 boundary PQ를 COCO와 Cityscapes panoptic dataset에 적용했다. 우리는 새로운 방법론을 synthetic prediction과 테스트하고 이 방법이 기존의 mask iou 기반의 방식보다 더욱 민감하다는 것을 보인다. 마지막으로, 우리는 새로운 평가 지표로 다양한 최신 instance segmentation과 panoptic segmentation 모델의 성능을 평가하여 향후 연구를 위한 비교를 용이하게 한다.
이러한 새로운 평가방법은 mask iou 기반의 평가 방법에서 일반적으로 무시됐던 boundary quality를 향상시켰다. 우리는 이 새로운 boundary-sensitive 평가방법의 채택이 boundary quality를 좋게 만드는 segmentation model을 빠르게 발전시키는 것을 가능케 할 것이라 기대한다.
2. Related Work and Preliminaries
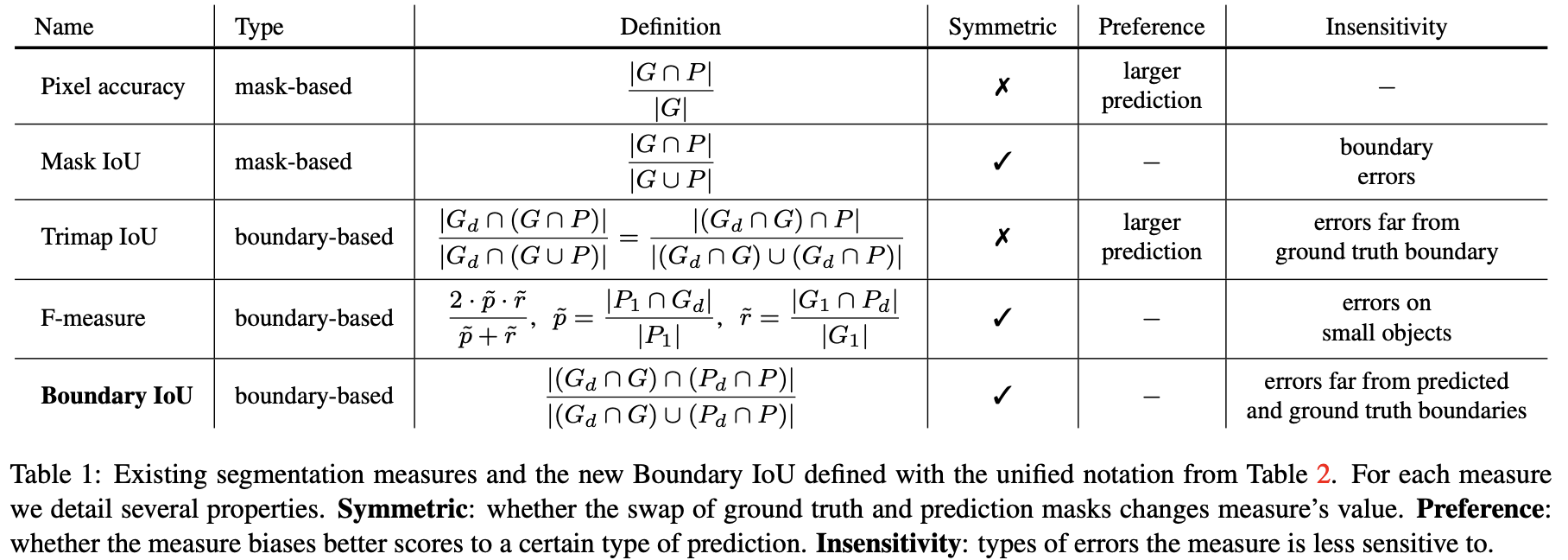

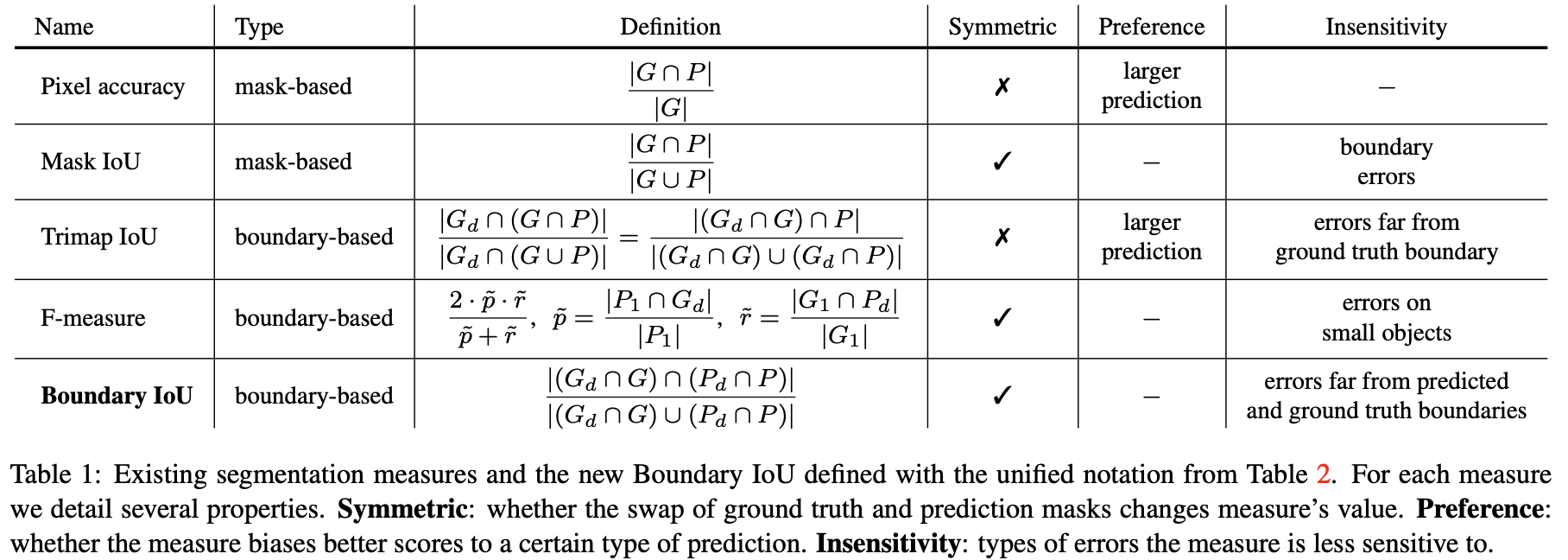
semantic, instance 또는 panoptic segmentation과 같은 image segmentation 과제는 시스템으로부터 예측된 segmentation mask와 annotator로부터 제공된 gt mask를 비교하는 것으로 평가된다. 이를 위한 현대의 평가 방식은 gt object shape : G와 고정 해상도의 이진 마스크로 제공되는 prediction shape : P 사이의 일관성을 측정하는 segmentation quality에 기반한다. 우리는 가장 많이 사용되는 segmentation quality 평가 방식과 새로운 boundary IoU 평가 방식을 Table 1에서 정의하고, Table 2에서 표기법을 이용해 보여준다. 우리는 평가 방식을 mask-와 boundary-based 유형으로 나누고, 이들의 차이점을 다음에 의논한다.
Mask-based segmentation measures
mask-based segmentation 평가지표는 객체 mask의 모든 픽셀을 고려한다. 2007년 첫 PASCAL VOC semantic segmentation track에서는 prediction을 평가하기 위해서 Pixel Accuracy를 사용했다. 각 class마다 올바르게 레이블이 지정된 비율을 계산한다. Pixel Accuracy는 대칭적이지 않고, 예측 마스크가 gt 마스크보다 큰 경우에 편향되어있다. 이후, PASCAL VOC는 평가를 Mak IoU 평가 지표로 변환했다.
Mask IoU segmentation의 일관성 측정은(?) 예측과 gt의 교집합 픽셀 수를 그들의 합집합으로 나누었다(Table 1). 이 측정방식은 가장 인기있는 semantic, instance, panoptic segmentation 과제와 데이터셋에 널리 사용된다. Pixel Accuracy와 다르게 Mask IoU는 대칭적이지만, 본 논문에서 보여줄 것처럼, 이는 객체 크기에 따른 boundary quality에 대해 균형 잡힌 반응(?)을 보이지 않는다.
Boundary-based segmentation measures
boundary-based segmentation 평가지표는 예측된 마스크와 실제 마스크 사이의 contour alignment(윤곽 정렬??)을 측정하여 segmentation quality를 평가한다. mask-based 평가 방식과 다르게, 이러한 평가 방식은 boundary에 직접적 또는 가까이에 놓여있는 픽셀만 계산한다.
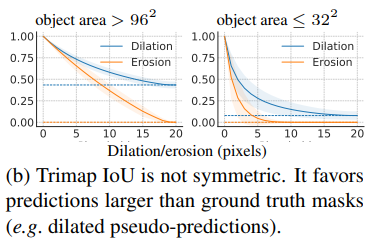
Tripmap IoU는 boundary-based segmentation 평가지표로, 실제 마스크 윤곽으로부터 픽셀 거리 d 내의 픽셀에서 IoU를 계산한다 (Table 1 참고). Mask IoU와 달리, Trimap IoU는 윤곽 주변의 픽셀에 대해서만 IoU를 계산하기 때문에, Tripmap Iou는 객체 크기에 따라(고려하여), (비교가능한?) pixel error에 대해 반응한다. 하지만, Mask IoU와 다르게, 이 평가 방식은 대칭적이지 못하고, gt 마스크보다 큰 예측 마스크를 선호한다. 게다가, 이 측정치는 gt 윤곽 주변의 밴드 외에 나타나는 prediction error에 대해서는 무시한다.
F-measures는 원래 edge detection으로 제안되었지만, segmentation quality를 측정하는 데에도 사용된다. F-measure = 로 정의되고, 여기서 p와 r은 각각 precision(정밀도)와 recall(재현율)을 의미한다. 원래의 정의에서, p와 r은 이분법적인 매칭(?)을 통해 경계 픽셀과 pixel distance threshold 내에서 예측과 실제 윤곽 픽셀을 매칭하여 계산된다. 하지만, 매칭과정은 고행상도 마스크와 큰 데이터셋에서 계산 비용이 높다. 때문에, 여러 논문[8, 28]에서 정밀도와 재현율을 계산하기 위해 중복 매칭을 허용하는 근사 방법을 제안했다(로 표기). 이 경우에서, 는 예측 윤곽으로부터 거리 d 내에 있는 픽셀의 비율을 계산하고, 반면 는 gt 윤곽 픽셀에 대해 유사한 비율을 계산한다(Table 1 참고). 논문의 나머지 부분에서는 F-measure의 근사식을 사용한다. 이 측정치는 대칭적이고, 모호성으로 인해 발생할 수 있는 작은 contour misalignment를 용인하지만, 객체 크기가 d와 유사한 경우에는 중요한 오류를 무시한다. 예를 들어, 이는 COCO와 같은 데이터셋에서 자주 발견되는 작은 객체와 적절한 d값으로부터 발생한다.
Tripmap과 F-measures는 ad -hoc fashion(”특정한 목적을 위한”)의 semantic segmentation 과업에서 boundary quality를 계산하기 위해 자주 사용된다. 예를들어, Tripmap IoU는 boundary quality를 향상시키기 위한 extra 평가 지펴로 사용된다. 하지만, 이는 대부분의 segmentation method에서 사용되지 않는다. 다음의 섹션에서 우리는 두개의 평가 방식에 대해 디테일하게 공부하고, 다른 에러 타입과 객체 사이즈에서 나오는 결과를 분석할 것이다.
3. Sensitivity Analysis
section 4와 5에서 우리는 여러 mask 일관성 평가 지표를 비교함으로서 측정치의 값이 다른 크기의 오류에 어떻게 변하는지 관찰할 것이다. 우리는 이러한 변화를 관찰하고 해석함으로서 평가 지표의 동작에 관해 결론을 이끌어 낼 것이다. 이러한 방법론을 “sensitivity analysis (민감도 분석)” 이라고 한다.
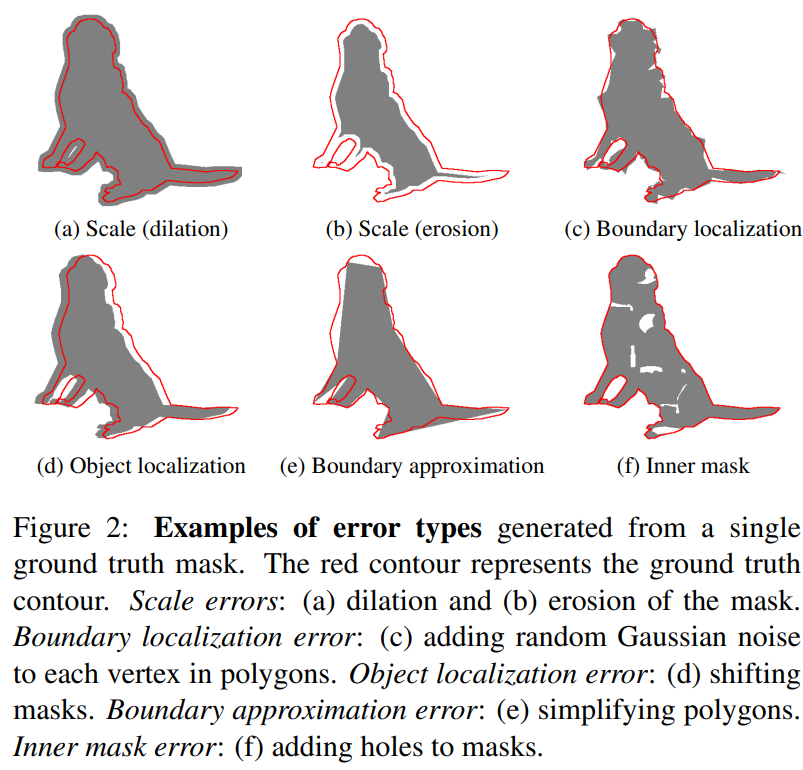
체계적인 분석을 위해, 우리는 gt annotaion에서 유사(가짜) 예측(pseudo-prediction)을 생성하여 다양한 마스크 크기에 걸친 segmentation error set를 시뮬레이션한다. 이러한 접근법은 분석에 사용된 오류의 유형과 심각도를 명확하게 제어할 수 있도록 한다. 게다가, 유사 예측의 사용은 segmentation model에 특정 편향을 피해, 분석 결과를 보다 견고하고 일반적으로 만들 수 있다. 이 접근 방식의 잠재적인 한계는 시뮬레이션 에러가 실제 모델에서 생성되는 에러를 완벽히 대변하지 못한다는 것이다. 우리는 이러한 한계점을 극복하기 위해 다양한 에러 타입 세트를 사용했다. Figure2는 우리가 생각한 error type을 묘사한 것이다.
- scale error : gt mask에서 침식 / 팽창을 적용했다. 에러 심각도는 형태학적 작업(?morphological operation) 의 커널 반경(kernel radius)에서 제어된다.
- boundary localization error : gt mask에서 표현되는 다각형의 각 정점(vertex)에 랜덤 가우시안 노이즈를 추가했다. 에러 심각도는 가우시안 노이즈의 standard deviation(std, 표준편차)에 의해 제어된다.
- object localization error : gt mask는 random offsets에 의해 이동된다. 에러 심각도는 이동(shift)의 픽셀 길이에 의해 제어된다.
- boundary approximation error : Shapely에서 simplify 함수는 gt mask에서 표현되는 다각형의 vertices(정점)을 제거한다. 이때, 원래의 다각형과 최대한 비슷하게 다각형을 간소화한다. 에러 심각도는 simplify 함수의 error tolerance 파라미터에 의해 조정된다.
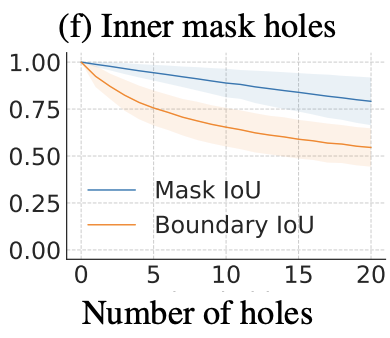
- Inner mask error : gt mask에 랜덤 모양의 구멍이 추가된다. 에러 심각도는 추가되는 구멍의 개수에 의해 조정된다. 이런 오류 유형은 현대적인 segmentation 접근 방식에는 흔하지 않지만, 내부 마스크 오류를 평가하기 위해서 추가되었다.
Implementation details (구현 세부 사항)
분석을 위해, LVIS v0.5 검증 세트에서 instance mask를 무작위로 샘플링한다. 이 데이터셋은 고 품질의 annotation에 의해 선택되었다. 이러한 마스크를 사용하여, 각 segmentation error type에 대해 오류 심각도를 조정하면서 다수의 유사 예측 세트를 만든다. segmentation measure를 분석하기 위해, 우리는 주어진 에러 타입에서 특정한 심각도를 표현하는 유사 예측 세트의 평균과 표준편차를 보고한다. 또한, 다양한 object sizes에 대해 segmentation 평가 방식을 비교한다. 이를 위해 특정 마스크 영역 내의 gt를 사용하여 별도의 유사 예측을 생성한다. 픽셀 거리 파라미터 d를 사용하는 모든 boundary-based 평가 방식은 공정한 비교를 위해, d를 이미지 대각선의 2%로 설정한다.
4. Analysis of Existing Segmentation Measures
먼저, 우리는 이론(Theoretical) 및 경험적 관점에서 표준 Mask IoU segmentation 일관성 측정을 분석한다. 그 후, 우리는 두가지 대안 - Trimap IoU와 F-measure boundary-based 평가지표 에 대해 공부한다.
4.1. Mask IoU - Theoretical Analysis
Mask IoU는 객체 영역에 대해 크기 불변적(?)이다. 고정된 Mask IoU 값에 대해 더 큰 객체는 더 많은 오류 픽셀을 갖게 되고, 잘못된 픽셀 수의 변화는 객체 영역의 변화에 비례하여 증가한다. 하지만, 일반적인 객체를 확대할 때, 내부 픽셀 개수는 제곱으로 증가하는 반면, 경계의 픽셀은 linear(선형적으로) 증가한다. 서로 다른 점근적 성장률은 Mask IoU가 큰 객체의 윤곽 길이 당 잘못 분류된 픽셀 수를 더 많이 허용할 수 있게 한다.
4.1. Mask IoU - Empirical Analysis

→ LVIS 데이터에 대해 독립적으로 두번 annotation 결과
→ 왼쪽, 냉장고는 오른쪽의 날개보다 100배 더 큰 영역을 가지고 있지만, 동일한 해상도의 잘린 부분에서 annotation 불일치는 시각적으로 유사
→ 이 예제는 gt의 boundary quality가 객체 크기와 독립적임을 확인하는 것
→ 하지만, Mask IoU는 냉장고에 0.97, 날개에 0.81을 부여, 이는 큰 객체에 대한 편향이기 때문
→ 반면, Boundary IoU는 냉장고에 0.87, 날개에 0.81을 부여해 경계 품질 평가에 적합
이 특성은 gt annotation(i.e., intrinsic annotation ambiguity)에서 boundary localization error가 객체 크기와 함께 증가한다는 가정과 일치한다. 그러나, multi-region segmentation의 고전적인 연구는 서로 다른 주석자가 라벨링한 동일한 객체에 대해 두 윤곽 사이의 pixel distance는 객체의 크기와 관계 없이 이미지 대각선의 1 %를 초과하지 않는다. 우리는 이 관찰을 LVIS 데이터셋의 일부 이미지에 대해 제공된 이중 주석을 통해 확인한다. Figure 3에서, 우리는 큰 크기 차이가 있는 랜덤 객체 쌍을 제시한다. 한 객체는 100배 크지만, 동일한 해상도를 가지는 잘린 부분(cropped part) 내에서 윤곽의 불일치는 두 객체 사이에서 유사하다. 관찰 결과는 경계 모호성이 객체 영역과 독립적이고, 고정되어있는 것으로 보인다. 이는 윤곽을 그릴 때(annotation 딸 때), 확대 기능이 포함된 annotation 도구의 결과일 수 있다.
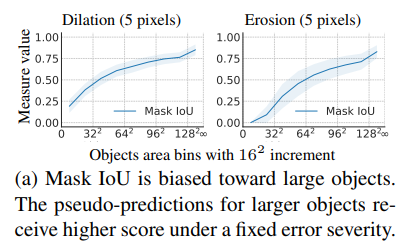
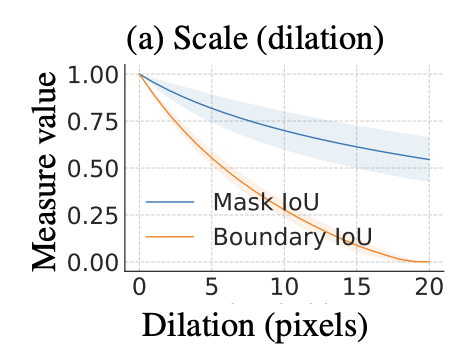
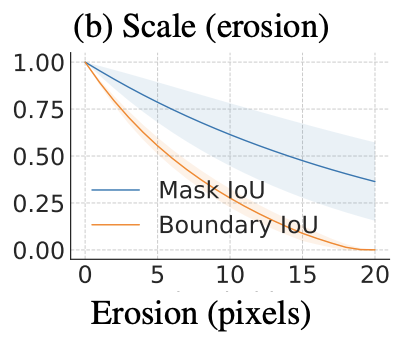
시뮬레이션된 스케일 오류를 사용하여 (section 3 참고) 우리는 Mask IoU가 큰 객체에 대해 편향되어 있음을 확인했다. 일정한 픽셀수로 gt mask를 팽창/침식 시키는 것은 작은 객체에서 Mask IoU가 상당히 낮아지지만, 객체 영역이 커질 수록 Mask IoU는 증가했다(Figure 4a 참고). Mask IoU가 큰 객체의 경계 오류에 민감하지 않은 사실은 AP나 PQ와 같은 평가 지표에서 Mask IoU의 최저 threshold를 증가시킴으로서 단순히 해결할 수 없다. 이러한 변화(threshold 증가)는 편향에 대한 치료법이 아니고, 작은 객체에 대해 over-penalization을 유도할 수 있다.
4.2. Boundary-Based Measures - Intro
다음으로, 우리는 boundary-based 평가 지표인 Trimap IoU와 F-measure에 대해 분석한다. 이러한 평가 방식은 객체 경계로부터 distance 내부의 픽셀에 초점이 맞춰져 있다. 파라미터 d는 일반적으로 데이터셋이나 image level에 따라 고정되어있다. 결과적으로, 이러한 측정치는 객체의 크기와 관계 없이 boundary localization error를 독립적으로 처리한다. gt segmentation data의 자연적 특성(???)과 일치시켜, 이러한 boundary-based 평가 방법은 객체 크기에 걸쳐 boundary quality를 평가하는데 적합하다.
4.3. Boundary-Based Measures - F-Measures
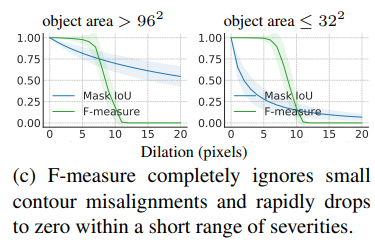
F-Measures는 예측된 값과 gt 경계의 픽셀이 threshold 내에 있으면 매칭한다. 따라서, 이는 모호성으로 인해 발생할 수 있는 작은 윤곽 불일치를 무시한다. 모호성에 대한 강건함은 원칙적으로 좋지만, Figure 4c에서 관찰할 수 있듯이 F-Measures는 오류 심각도가 약간 변할 때 거의 이산적으로, 즉 1에서 0으로 급격히 전환될 수 있다. 뾰족한 response curves는 높은 분산을 가진 task metrics을 유도할 수 있다. 비교적, Mask IoU는 더욱 연속적이다. 또한, d가 작은 객체에 비해 클 경우, F-Measures는 완벽한 점수에 상당한 에러를 부여한다.
4.4. Discussion
위에서 소개된 한계를 고려할 때, Trimap IoU나 F-Measures 모두 주된 segmentation consistency 평가 지표인 Mask IoU를 대체할 수 없다고 결론 내렸다. (→ 기존의 경계 평가 지표는 작은 객체에 대해 지나치게 페널티를 주거나 무시하기 때문) 동시에 Mask IoU는 boundary segmentation의 개선을 저해하는 방식으로, 큰 객체에 대해 편향되어 있다. 다음으로, 우리는 이전에 언급한 한계를 갖지 않고, boundary-quality segmentation에 대한 새로운 평가 방식인 Boundary IoU를 제안한다.
5. Boundary IoU

이 섹션에서는 새로운 segmentation 평가 방법을 제안하고, 시뮬레이션 error set 를 사용하여 기존의 일관성 측정치와 비교한다. 새로운 측정치는 Mask IoU보다 큰 객체에 대한 편향이 약해야 한다. 게다가, Mask IoU와 유사하게 작은 객체의 오류에 대해 지나치게 페널티를 주거나, 무시하지 않는 측정치를 목표로 한다.
이러한 원칙에 따라, 우리는 Boundary IoU segmentation 일관성 평가지표를 제안한다. 이 새로운 평가 지표는 간단하면서도 위에서 묘사한 요소를 만족한다. 두 개의 마스크 G, P가 주어졌을 때, Boundary IoU는 각 윤곽(contour)으로부터 d만큼의 거리에 포함된 (원래의) 마스크 픽셀 집합을 계산하고, 두 개의 세트에 대해 IoU를 계산한다(Figure 5). 표기법을 이용해 Table2 (밑 수식) 처럼 표현된다.
와 는 각각 실제 윤곽과 예측 경계로부터 d 픽셀 거리 이내의 픽셀 집합들이다. 새로운 평가 지표는 경계로부터 픽셀 거리 d 이내에 있는 마스크 픽셀만에 대해서 평가한다. 직접적으로 경계영역 와 에 대해 IoU를 계산하는 것은 경계로부터 거리 d 안에 있는 모든 픽셀을 고려함으로서 smoothing되어 뾰족한 경계 (sharp contour)에 대한 정보가 손실된다. (단점?)
Boundary IoU의 contour parameter 는 평가 지표의 민감도를 제어한다. prediction과 gt 마스크의 모든 픽셀을 포함할만큼 가 충분히 크다면, Boundary IoU는 Mask IoU와 동등하게 된다. Bounday IoU의 파라미터 가 내부 마스크 픽셀을 무시할만큼 작다면, 큰 객체에서 Mask IoU보다 boundary quality에 대해 민감해지게 된다. 작은 객체일 경우, Boundary IoU는 파라미터 에 따라 Mask IoU와 매우 비슷하다. 또한, 내부 픽셀 수를 경계 근처의 픽셀수와 비교할 수 있기 때문에, 작은 객체에 대해 over-penalizing하는 것을 예방할 수 있다.
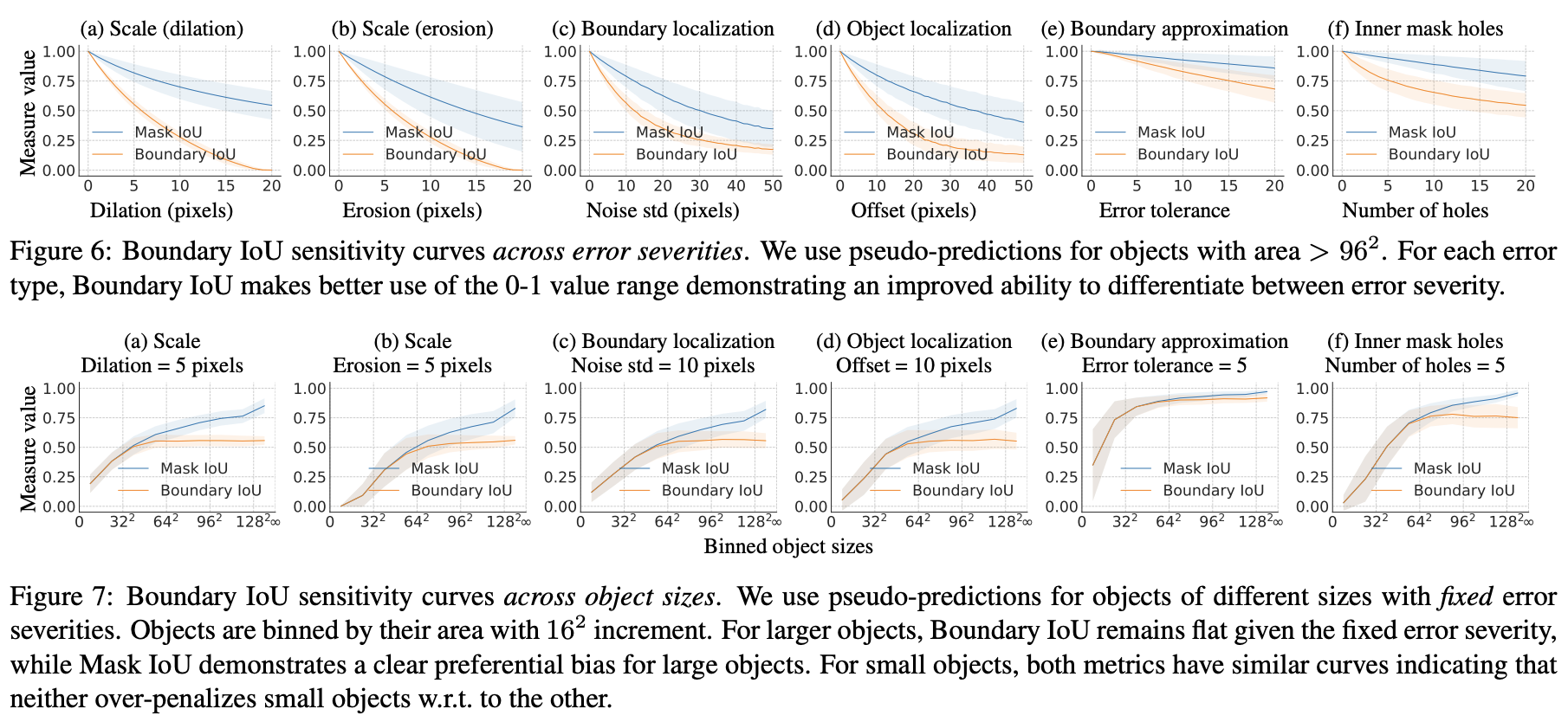
Figure 6과 Figure 7에서 Boundary IoU에 대한 우리의 분석을 포함한다. 분석 결과, 모든 에러 타입의 큰 객체에 대해 Boundary IoU가 Mask IoU가 덜 편향된 결과를 보인다(Figure 6). 오류 심각성을 고정한 채로 객체 크기를 변화시키면(Figure 7), 작은 객체에서는 모든 오류 유형에 대해 over-penalizing하지 않으면서, Mask IoU와 동일하게 작동한다. 큰 객체의 경우, Boundary IoU는 Mask IoU보다 편향이 감소되었고, 고정된 오류 심각성을 가지고 객체의 크기가 증가했을 때 측정치(Boundary IoU)가 (Mask IoU에 비해 )천천히 증가되었다.
Comparison with Trimap IoU.
새로운 평가 지표는 Trimap IoU와 매우 비슷해 보인다(Table 1 참고). 하지만, Trimap IoU와 달리 Boundary IoU는 예측과 gt 모두에 대해 경계 근처의 픽셀을 고려한다. 이런 간단한 변경은 Trimap IoU의 두 주된 한계에서 해결책이된다. 새로운 평가 지표는 대칭적이고, gt 경계로부터 떨어져있는 에러에 대해 페널티를 준다. (Figure 6(a), (b), (f) → 이 피규어가 왜 위의 내용을 대변하는거지 ??? )
Comparison with F-measures.
F-measure는 예측 마스크와 gt 마스크의 경계에 대해 hard matching을 진행한다. contour pixel 간의 거리가 이내라면, precision과 recall 값이 완벽하지만, 거리가 d를 초과하면 모든 경우에 대해서 매칭되지 않는다. 반대로, Boundary IoU는 부드럽게 일관성을 측정한다(음 … 근데 애는 sharp 한 정보는 손실되지 않나. ). 두 경계가 완벽하게 겹치면 IoU는 1.0이 되고, 두 윤곽이 분리되면 IoU는 점진적으로 감소한다. 부록에서(→아카이브 찾아봐야 할 듯), 우리는 Boundary IoU와 파라미터 d를 다양한 값으로 설정한 후 평균을 내어 부드러운 일반화(?soft generalization?)가 된 F-measures를 비교한다. 우리의 분석은 작은 객체에 대해 Mask IoU와 Boundary IoU를 비교했을 때, under-penalize(오류를 과도하게 페널티 주지 않는 것)하는 것을 보인다.
The pixel distance parameter .
만약 Boundary IoU의 d가 충분히 크다면, Mask IoU와 동등하다. 반면에, 가 너무 작으면 경계에서 발생할 수 있는 모호함을 무시하고, 가장 작은 오류에도 엄격하게 페널티를 준다. 경계에서 발생할 수 있는 모호함을 과도하게 페널티 주지 않는 d를 구하기 위해, 두 명의 전문 annotator가 같은 객체에 대해 독립적으로 경계를 그린 경우에 대해 Boundary IoU를 사용해 일관성을 측정한다. LVIS의 창작자들은 COCO 및 ADE20k 데이터셋의 이미지에 대해 이러한 전문 주석가를 수집했다. 두 데이터셋 모두 유사한 해상도의 이미지를 가지고 있으며, 이미지 대각선의 2%에 해당하는 (평균 15픽셀 거리) 에서 두 전문가의 annotation간 중간 Boundary IoU가 0.9를 초과한다는 것을 발견했다. 해상도가 높고 annotation 품질이 우수한 Cityscape의 경우 데이터셋에 대해 동일한 픽셀 거리를 사용하는 것을 제안한다. 우리는 를 이미지 대각선의 0.5%로 설정했다.
다른 데이터셋의 경우, 픽셀 거리 를 설정하기 위해, 두 가지 방법을 고려한다.
- annotation consistency는 의 하한으로 설정한다.
- 현재 방법의 성능을 기반으로 d를 선택하고, 성능이 향상됨에 따라 값을 줄인다.
Limitations of Boundary IoU
새로운 평가방법은 예측된 경계로부터 d 픽셀 이상 떨어진 마스크 픽셀을 평가하지 않는다. 따라서, 일치하지 않은 마스크에 대해 완벽한 점수를 부여할 수 없다. 예를 들어, Boundary IoU는 디스크 모양(disc shape)과 같은 center와 outer radius (외부 반지름? )을 갖고 있는 반지 모양(ring shape)의 마스크와 완벽한 점수를(?) 부여할 수 있다. 또한, inner radius(내부 반지름)이 외부에 반지름에 비해 정확히 픽셀만큼 작은 경우에도 완벽한 점수를 부여한다(부록에서 보여줌). 이 두마스크에 대해 디스크 모양 마스크에 매칭되지 않은 모든 픽셀은 경계로부터 d 픽셀만큼 떨어져있다. 이러한 경우에 페널티를 주기 위해서, 우리는 Mask IoU와 Boundary IoU를 간단히 조합하여 그 중 최솟값을 취한다. 실제 경우와 시뮬레이션된 예측 결과에서, Boundary IoU가 대부분의 경우에서(99.9) Mask IoU보다 작거나 같음을 발견했으며, 정확한 경계를 가진 예측이 객체의 interior part를 놓칠 경우 불평등이 발생했다. (toy example 존재)
6. Applications
instance 및 panoptic segmentation 작업에서 가장 일반적인 평가 방법은 AP / Mask AP 또는 PQ / Mask PQ 이다. 두 평가지표는 Mask IoU를 사용하며, 이는 이전에 언급한 큰 객체에 대한 편향과 boundary quality에 대한 무감각이 존재한다.
우리는 이러한 작업에 대한 평가지표를 이전 섹션에 언급된 것처럼 min(Mask IoU, Boundary IoU)로 Mask IoU로 대체한다. 우리는 이 새로운 평가 지표를 Boundary AP와 Boundary PQ라고 이름 붙인다. 이 변경은 구현하기 쉽고, 새로운 평가 지표가 boundary quality에 더 민감하면서도, 다른 유형의 예측에서도 잘 작동하는 것을 입증하였다.
우리는 새로운 평가 지표의 채택이 segmentation에서 boundary quality를 빠르게 개선시키는 것을 가능케 할 것으로 생각한다. 우리는 instance segmentation에 대한 우리의 결과를 본문에 제시하고, Boundary PQ에 대한 분석은 부록에 붙인다.
Boundary AP for instance segmentation
instance segmentation 작업의 목표는 각 객체에 대해 pixel-level의 마스크를 묘사하는 것이다. 이 작업에 대한 평가 메트릭은 categorization, localization, segmentation quality를 동시에 평가한다. 다른 평가 방법을 비교하기 위해서, 우리는 합성 예측과 실제 instance segmentation model을 사용하여 실험을 수행한다. 합성 예측은 segmentation quality를 독립적으로 평가할 수 있도록 해주는 반면, 실제 예측은 Boundary AP가 instance segmentation 작업의 모든 측면을 추적(?)하는 통찰력을 제공한다.
우리는 본문에서 다루는 COCO instance segmentation dataset에서 Mask AP와 Boundary AP를 비교한다. 또한, 본 발견은 부록에 있는 Cityscapes와 LVIS와 같은 유사한 실험에서도 지지된다(?) 같다. 모든 데이터셋에 대한 자세한 설명은 부록에서 찾을 수 있으며, 세 개의 데이터셋에 대한 다양한 최근 및 고전적인 모델에 대한 Boundary AP 평가도 함께 제시된다. 이 결과는 향후 방법을 비교하기 위해 참고자료로 사용될 수 있다.
6.1. Evaluation on Synthetic Predictions
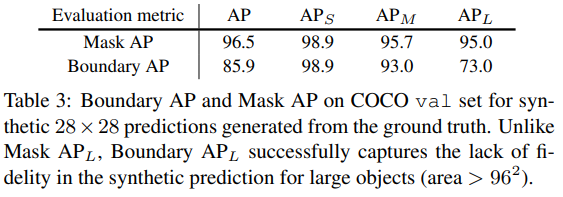
합성 예측을 사용하여 우리는 모델이 가질 수 있는 특정한 편향 없이 instance segmentation의 segmentation quality를 측정한다(? 이게 왜 가능?). 우리는 각 마스크의 유효 해상도를 제한하여 예측을 시뮬레이션한다. 먼저, 우리는 gt mask를 연속값을 가진 28x28 해상도 마스크로 다운스케일한 후, bilinear interpolation을 통해 업스케일링 하고, 마지막으로 binarize한다. 이러한 합성 마스크는 작은 객체에 대해서 실제 gt에 매우 가깝지만, 객체 크기가 커질수록 차이가 커진다. Table 3에서는 COCO에서 정의된 객체 크기 분할에 따라 전체 , , , 를 보고한다. Mask AP는 Mask IoU의 과정을 따르고, 와 간 에러가 커져도 sensitivity는 거의 없다. 반면에, Boundary AP는 큰 객체에 대해 훨씬 낮은 점수를 가지고 차이점을 성공적으로 포착한다. 부록에서, 우리는 합성 예측의 예제와 다른 해상도에 따른 결과가 더 제공되어 있다.
6.2. Evaluation on Real Predictions - Intro
우리는 Boundary AP 연구를 더 수행하기 위해서 존재하는 segmentation 모델의 출력을 사용했다. 특별히 지정하지 않는 한, 제안된 분석에서 categorization과 localization error로부터 segmentation을 분리하기 위해, 우리는 방법론에 대해 gt boxes를 적용하고, 각 box에 랜덤 confidence score를 부여한다. 우리는 다른 것이 명시되지 않는한, ResNet-50을 활용한 Detectron2을 백본으로 사용했다.
6.2. Evaluation on Real Predictions - Mask AP vs. Boundary AP.
Table 4a에서 표준 Mask RCNN에 대한 Mask AP와 Boundary AP를 보인다. Mask RCNN은 큰 객체에 대해 중요한 시각적 결함을 가진 blobby mask(덩어리 마스크)를 생성한다고 알려져 있다(Figure 1). 그럼에도 불구하고, Mask 이 Mask 보다 크다. 반면, 우리는 같은 상황에서 Boundary 이 Boundary$ AP_S$ 보다 작다는 것을 확인했다. 이는 새로운 측정 방법이 대형 객체의 boundary quality에 더 민감함을 뜻한다. 이 결과에서, gt box의 사용은 일반적으로 small object에 대해 일반적으로 큰 categorization, localization error를 제거한다.
6.2. Evaluation on Real Predictions - Segmentation vs. Categorization and Localization
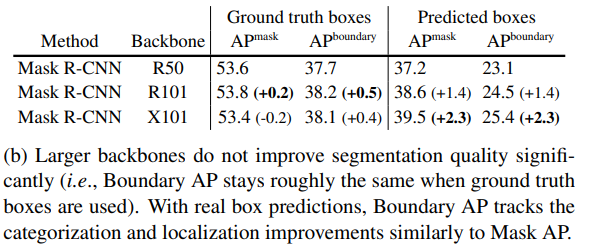
instance segmentation에 대한 일반적인 평가 지표는 segmentation, categorization, localizatoin을 포함한 모든 측면의 개선사항을 추적해야 한다. Table 4b에서 우리는 여러 백본을 사용하여 Mask RCNN을 평가한다. Msak AP와 Boundary AP는 다른 backbone과 함께 사용되어도 크게 변경되지 않으며, 이는 더 강력한 backbone이 segmentation quality에 큰 영향을 미치지 않음을 시사한다. 다음으로, 우리는 각 모델이 그들의 box를 예측하도록 하여 Boundary AP를 평가한다. 우리는 boundary AP가 Mask AP와 유사하게 더 나은 localization과 categorization을 추적할 수 있음을 확인했다.
우리는 Boundary AP가 Table 4c 및 4d에서 이러한 목적을 위해 설계된 방법에 의해 segmentation quality가 개선할 수 있는지 확인했다. 모델별 segmentation quality를 비교하기 위해서, 우리는 각 모델에 gt box를 제공했다.
PointRend는 Mask RCNN과 같이 pixel level의 예측 품질을 향상시키기 위해 개발되었으며, 다양한 해상도의 예측을 제공한다. PointRend는 mask quality가 상당히 향상되었고, mask AP를 통해 측정될 수 있지만, 큰 객체 및 높은 해상도의 PointRend인 경우, Boundary AP 에서 확연히 두드러진다. Table 4c에서 세부사항을 확인해라.
Boundary-preserving Mask RCNN(BMask RCNN)은 직접 boundary supervision loss를 추가하고, 마스크 헤드에서 사용되는 특성 맵의 해상도를 증가시킴으로서 boundary quality를 증가시킨다. Table 4d에서 Boundary AP는 작은 객체에 대해 28 x 28 출력 해상도를 가진 BMask RCNN이 PointRend보다 우수한 성능을 보여주는 반면, 큰 객체에 대해 224 x 224 출력 해상도를 가진 PointRend가 더 선호된다. 이는 주관적 시각적 품질 평가와 일치한다 (Figure 1 참고). 우리는 새로운 Boundary AP 평가 방법이 instance segmentation을 위한 boundary quality 개선에 빠른 발전을 가져올 것이라 기대한다.
7. Conclusion
표준 Mask IoU와는 달리 Boundary IoU segmentation quality 평가 방식은 boundary segmentation quality에 대해 명확하고 양적인(?) 증감을 제공한다. 우리는 새로운 측정 방식이 고도로 정확한 마스크 예측을 위한 분야에 챌린지가 될 것을 기대한다. 덧붙여, Boundary IoU는 instance 및 panoptic segmentation과 같은 복합 과제(?)에 대해 더욱 세분화된 분석을 가능하게 한다. 이러한 측정 방법이 TIDE와 같은 성능 분석 도구에 통합되면 인스턴스 분할 모델의 특정 오류 유형에 대해 더 나은 통찰력을 제공할 수 있다.
전문 번역은 역시 힘이 든다... 그치만 뿌듯함!
정리했던 논문들 싹 다 올려버려야겠다...
