
😱 K-최근접 이웃 회귀의 한계
K-최근접 이웃 회귀의 원리는 주변 K개의 이웃 샘플의 샘플 값을 평균을 내어 예측값을 도출하는 것이다.
따라서 훈련 세트보다 작거나 큰값, 즉 훈련세트의 범위를 크게 벗어나는 샘플 또한 가장 가까운 K개의 샘플의 평균을 내어 예측값을 도출해 버리기 때문에 예측에 한계가 있다.
아래의 예시를 통해 더 자세하게 설명하도록 한다.
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
print(perch_length)
print(perch_weight)
이전 목표와 마찬가지로 여전히 농어의 길이 데이터를 이용하여 농어의 무게를 예측할 것이므로 농어의 길이와 무게 데이터를 준비한다.
즉, x: 농어의 길이, y: 농어의 무게
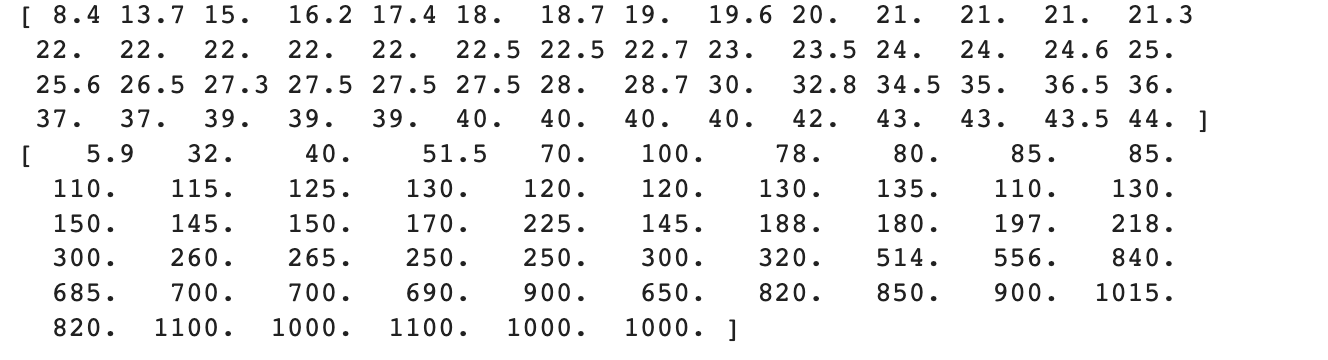
이 때, x 값으로 사용할 농어 길이 데이터의 범위를 살펴보자.
print(np.min(perch_length), np.max(perch_length))
현재 가지고 있는 농어의 길이 데이터의 범위는 최소 8.4cm, 최대 44.0cm이다.
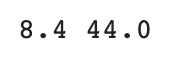
이 데이터를 가지고 모델을 훈련시킨다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
train_input = train_input.reshape(-1,1)
test_input = test_input.reshape(-1,1)
#print(train_input, test_input)
print(train_input.shape, test_input.shape)
잊지 말자 sklearn 모델의 input 데이터는 무조건 이차원 배열이어야 한다.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
knr.fit(train_input, train_target)위와 같이 훈련 시킨 모델을 통해 길이가 훈련세트의 범위를 벗어나는 50cm인 농어의 무게를 예측해 보도록 한다.
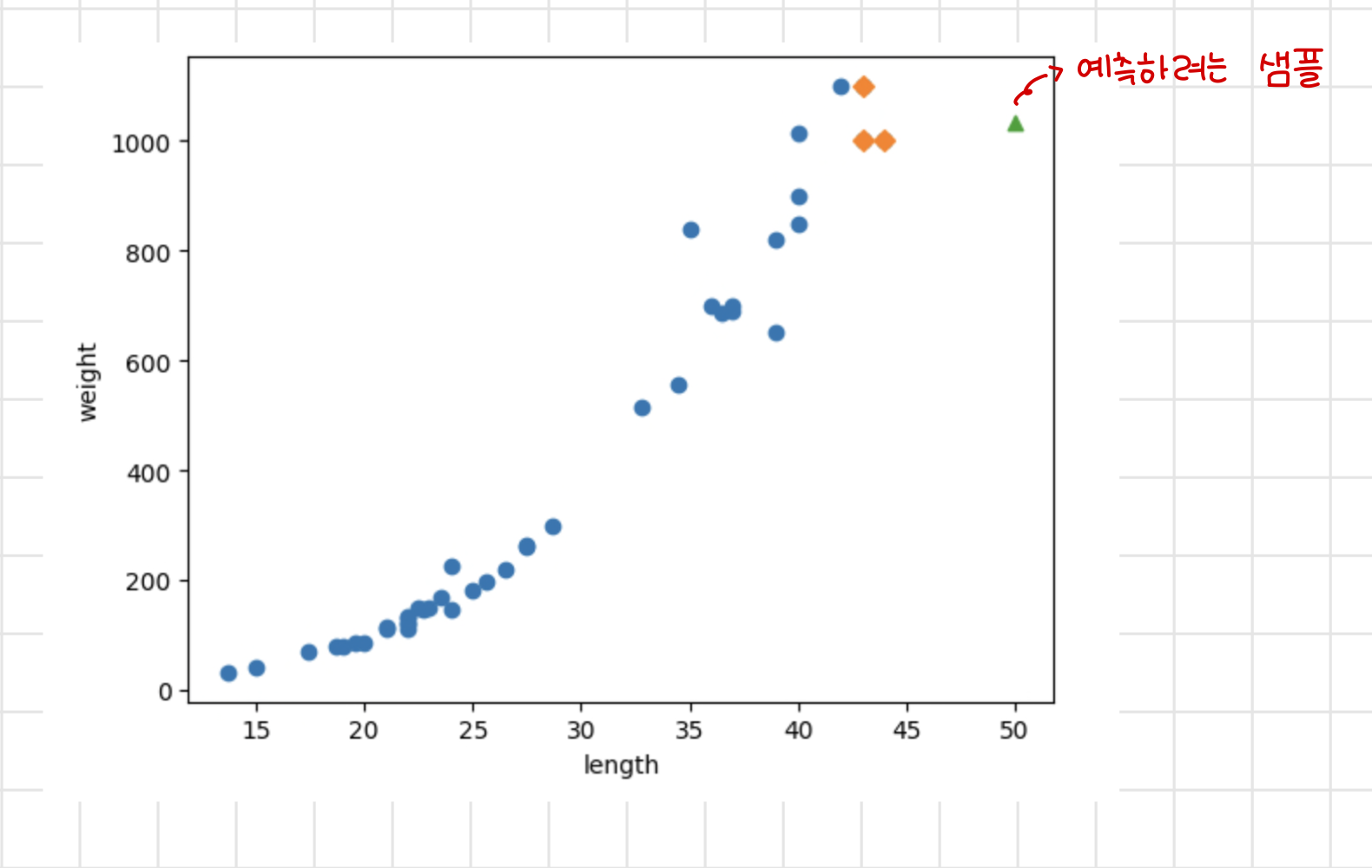
print(knr.predict([[50]]))
모델은 해당 농어가 약 1033g일 것이라고 예측했다.
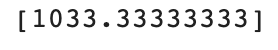
그런데 실제 50cm 농어의 무게는 훨씬 더 크다고 한다!
어떻게 된 일인지 산점도로 그려보도록 하자.
import matplotlib.pyplot as plt
#50cm의 농어의 이웃 구하기
distances, indexes = knr.kneighbors([[50]])
#산점도 그리기
plt.scatter(train_input, train_target) #훈련 세트
plt.scatter(train_input[indexes], train_target[indexes], marker='D') #이웃
plt.scatter(50, 1033, marker='^') #길이 50cm 농어
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
그래프의 경향 상 농어의 길이가 증가할수록 무게 또한 같이 증가해야하는데
길이가 50cm인 농어의 무게가 길이 40~45cm의 농어 무게와 비슷하다고 예측해 버린 것을 알 수 있다.
print(np.mean(train_target[indexes]))
print(np.mean(train_input[indexes]))
위 모델은 50cm 농어의 이웃으로 50cm보다 작은 크기의 농어들을 선택했고 이들의 무게 평균을 예측값으로 출력했다.
이웃들의 무게 평균은 약 43cm로 50cm보다 훨씬 작은 것을 알 수 있다.

즉, K-최근접 이웃 회귀 알고리즘은 훈련 세트의 범위를 벗어나는 샘플에 대한 예측이 어렵다.
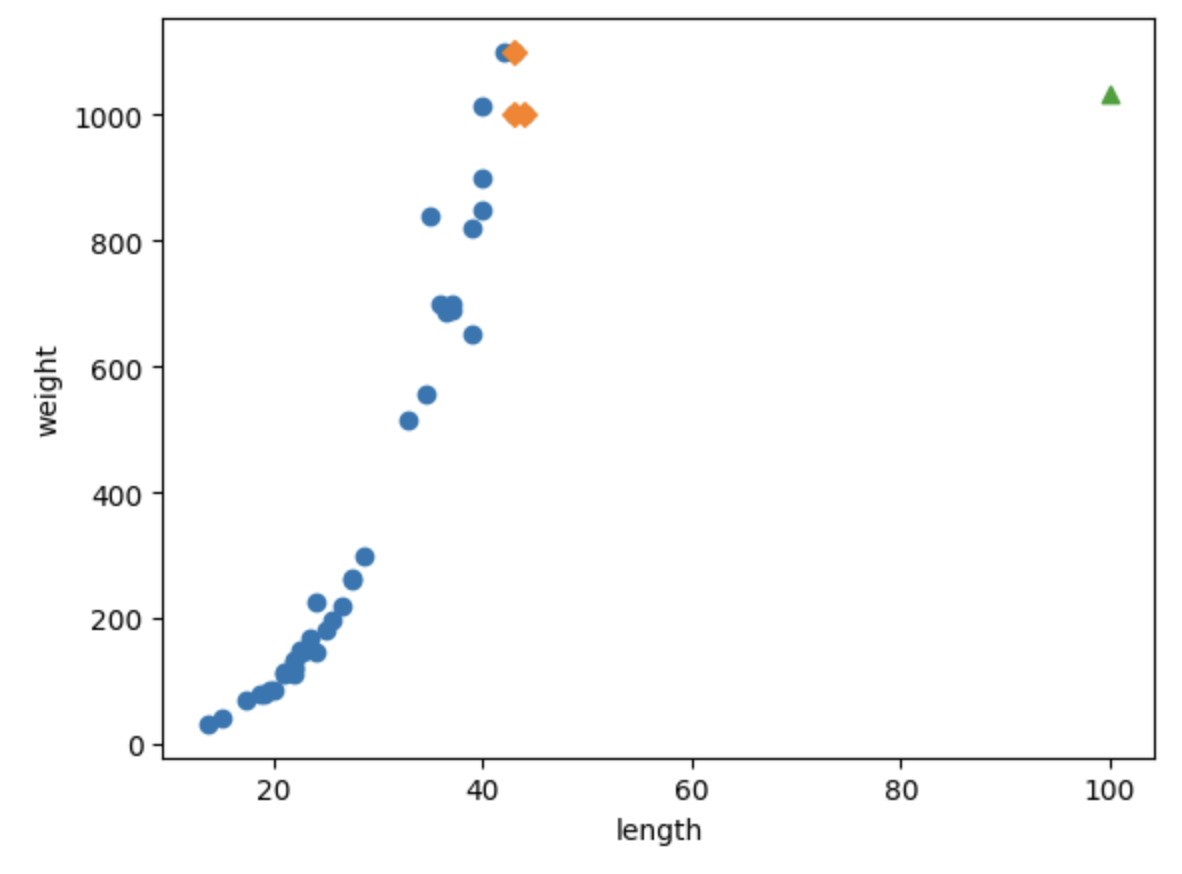
print(knr.predict([[100]]))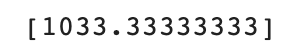
# 100cm 농어의 이웃을 구합니다
distance, indexes = knr.kneighbors([[100]])
# 산점도 그리기
plt.scatter(train_input, train_target) #훈련세트 산점도
plt.scatter(train_input[indexes], train_target[indexes], marker='D') #이웃 샘플
plt.scatter(100, 1033, marker='^') #길이 100cm 농어
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
아무리 큰 샘플을 넣어도 훈련 세트의 범위를 넘어가면 이웃이 변하지 않기 때문에 항상 같은 평균 값을 내놓는다.
📏 선형 회귀(Linear Regression)
K-최근접 이웃 회귀 방법론으로는 농어의 무게를 잘 예측할 수 없으므로 방법론을 바꾸기로 한다.
선형 회귀는 데이터들을 가장 잘 나타내주는 선(방정식)을 찾는 알고리즘이다.
이 때 찾은 방정식은 해당 데이터의 경향성을 가장 잘 보여줄 수 있는 선을 의미한다.
우선 일차 방정식(직선)을 통해 데이터를 나타내 보기로 한다.
일차 방정식의 형태는
형태이므로 우리가 찾으려는 방정식은 다음과 같다.

위 수식에서 a와 b는 알고리즘이 찾아낼 값으로 이러한 값을 모델 파라미터(model parameter)라고 한다.
반대로 내가 입력해 주어야 하는 파라미터라면 하이퍼 파라미터(hyper parameter)라고 한다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
#모델 훈련
lr.fit(train_input, train_target)
#50cm 농어 무게 예측
print(lr.predict([[50]]))
일차원 방정식을 학습한 모델은 50cm 농어 무게를 약 1241.8g으로 예측했다.
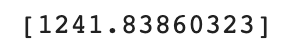
어떻게 해당 값을 출력했는지는 모델 파라미터를 확인하면 된다.
print(lr.coef_, lr.intercept_)
coef_는 계수(coefficient)라고 하기도 하고 가중치(weight)라고 하기도 한다.
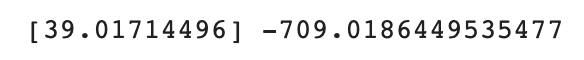
즉, 모델이 찾은 방정식은 다음과 같다.

시각화를 해보자
# 훈련 세트의 산점도 그리기
plt.scatter(train_input, train_target)
# 15~50까지 1차 방정식 그리기
plt.plot([15,50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
# 50cm 농어 데이터
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
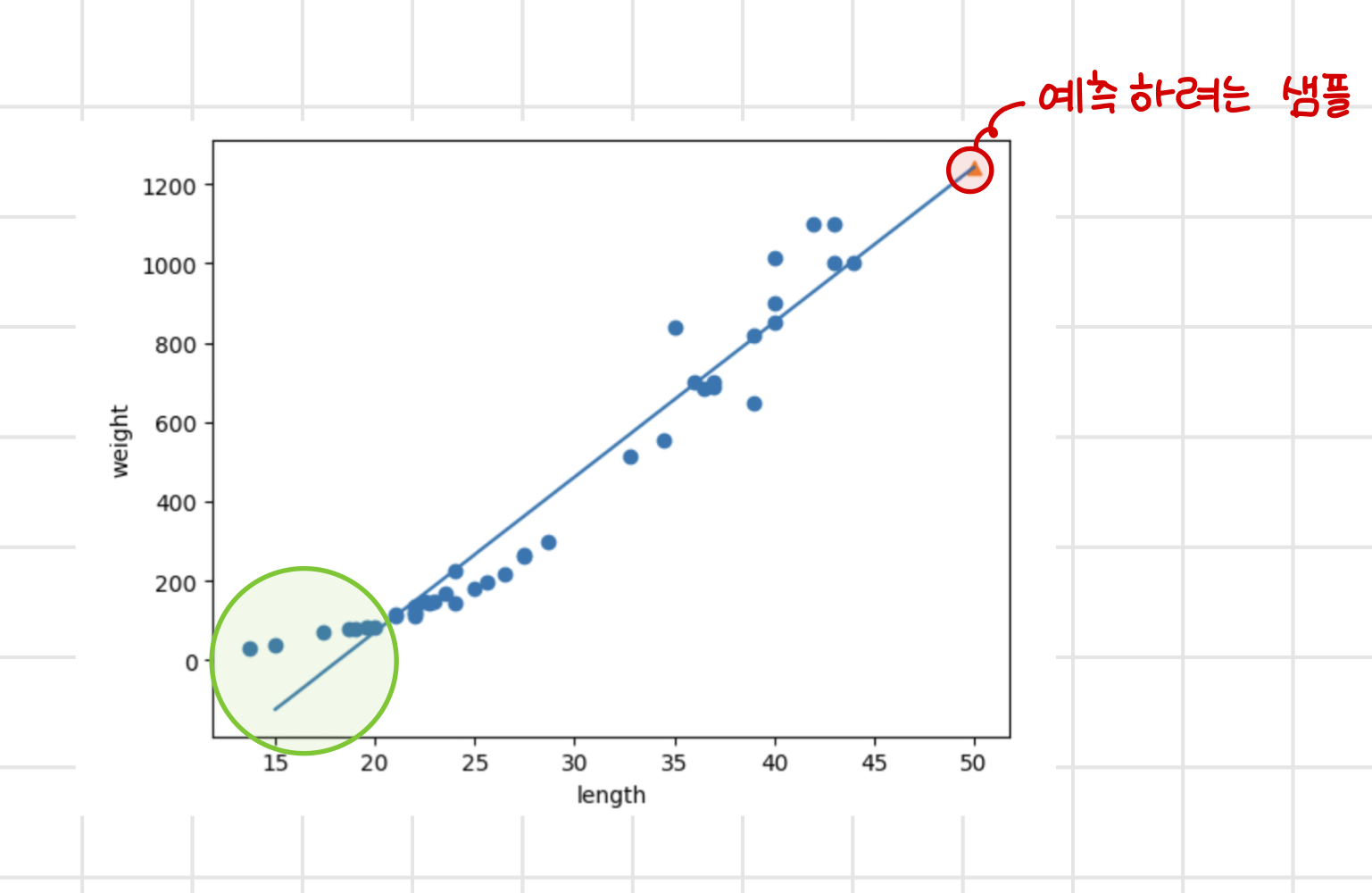
plt.show()
그래프로 나타내 보면 예측하고자 했던 50cm 농어 샘플이 일차 방정식 직선 위에 있는 값인 것을 확인할 수 있다.
그러나 해당 직선의 경우 그래프의 왼쪽 하단을 보면 알 수 있듯이 농어의 길이가 더 작아진다면 농어의 무게를 음수로 예측할 수 있다.
또한 산점도를 통해 확인한 데이터의 경향성이 일차방정식 보다는 이차 방정식 형태에 가깝다는 것을 알 수 있다.
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))
또한 위 모델은 훈련 세트 점수와 테스트 세트 점수 둘 다 별로 높지 않은 전체적인 과소적합을 보이고 있다!

과소적합 문제를 해결하기 위해 조금 더 복잡한 모델을 만들어 보기로 한다.
다항회귀(Polynomial Regression)
위에서 설명한 대로 데이터가 이차 방정식 형태에 더 가깝기 때문에 모델에게 다음과 같은 형태의 방정식을 찾도록 만드려고 한다.
우리가 사용하고 있는 값은 길이이기 때문에 최종적으로 모델이 찾아야 하는 방정식은 다음과 같아진다.

그런데 우리에겐 농어 길이 제곱 항이 없으므로 임의로 해당 항을 만들어 주어야 한다.
train_poly = np.column_stack((train_input**2, train_input))
test_poly = np.column_stack((test_input**2, test_input))
print(train_poly[:5])
임의로 길이의 제곱 항을 만들어 이차원 배열로 만들어 준 것을 확인할 수 있다.

print(train_poly.shape, test_poly.shape)
앞의 일차 방정식을 찾을 때와 마찬가지로 LinearRegression() 모델에 학습시킨다.
훈련 데이터에 이차항을 추가해 줬으므로 예측 샘플을 입력할 때에도 이차항을 입력해 주어야 한다.
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2,50]]))
일차 방정식을 통해 찾은 예측값보다 더 큰 값을 예측했다.
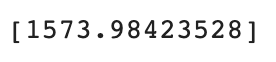
모델 파라미터를 확인해보자.
print(lr.coef_, lr.intercept_)
coefficient가 2개이므로 배열로 출력된다.
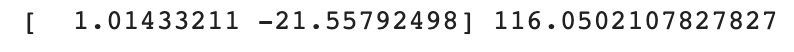
위 결과에 따르면 모델이 찾은 이차 방정식은 다음과 같다.
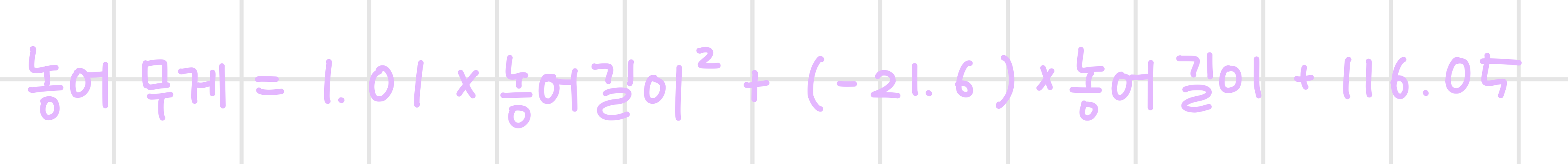
마찬가지로 모델이 찾은 값들을 한번에 시각화하면 다음과 같다.
# 구간별 직선을 그리기 위해 15에서 49까지 정수 배열을 만듭니다
point = np.arange(15,50)
# 훈련 세트의 산점도를 그립니다
plt.scatter(train_input, train_target)
# 15에서 49까지 이차방정식 그래프를 그립니다
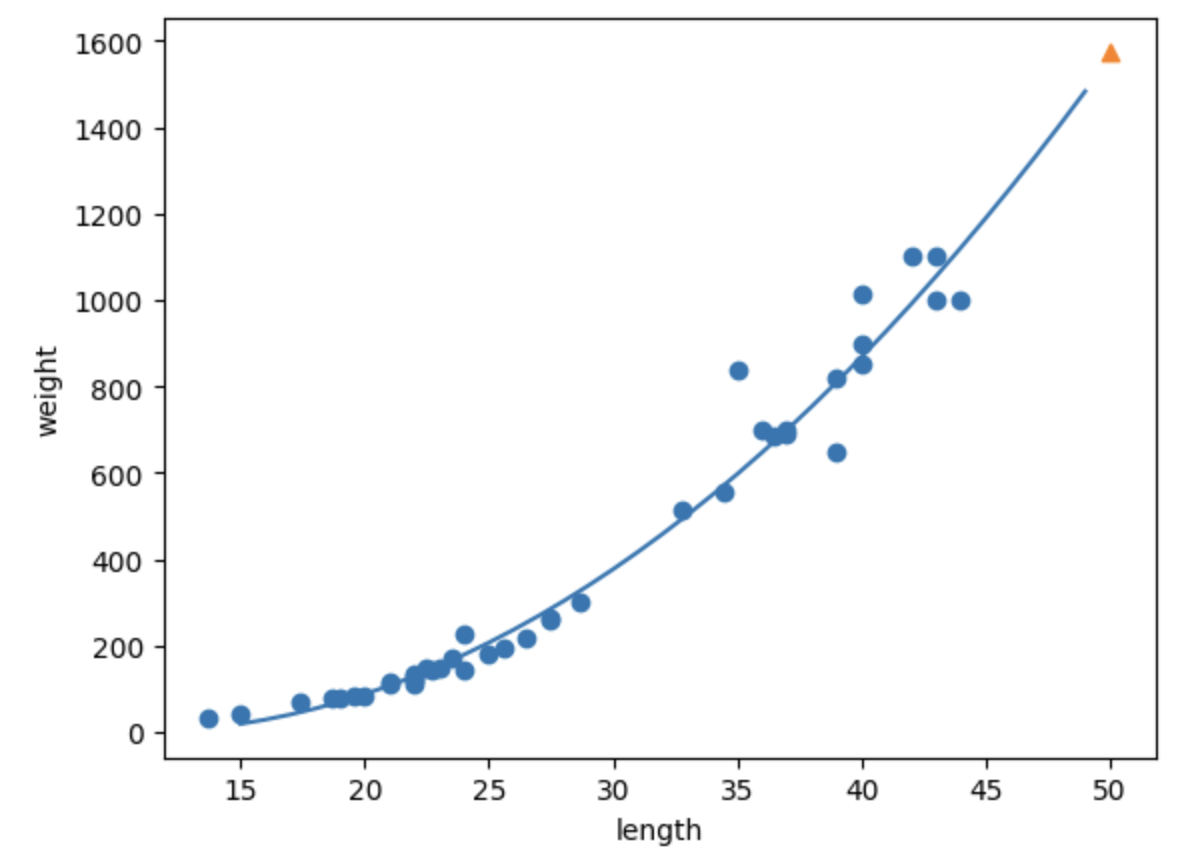
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
# 50cm 농어 데이터
plt.scatter(50, 1574, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
일차 방정식으로 나타냈을 때보다 훨씬 더 그래프의 경향성을 잘 나타내 주고 있는 것을 알 수 있다.
마지막으로 R² 값을 출력하여 모델의 성능을 평가해보도록 하자.
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
회귀 곡선과 데이터 사이의 오차가 줄어들었기 때문에 점수가 많이 올라갔지만 테스트 세트의 점수가 더 높아 과소적합이 남아있는 것을 확인할 수 있다.

다항 회귀도 선형인가요?
선형 회귀는 인 방정식을 찾는 알고리즘이라고 생각하면 된다.
위에서의 항을 , 항을 로 표현해보면
로 나타낼 수 있으므로 다항회귀 또한 선형 회귀라고 할 수 있다.
📚 Reference
혼자 공부하는 머신러닝+딥러닝, 박해선, 한빛미디어






