
🧐 분류 알고리즘과 회귀 알고리즘
지도학습 알고리즘은 분류와 회귀로 구분할 수 있다.
분류: 어떤 샘플이 n개의 클래스 중 어디에 속하는지 구하는 문제
회귀: 두 변수 사이의 상관관계를 분석하거나 어떤 숫자를 예측하는 문제
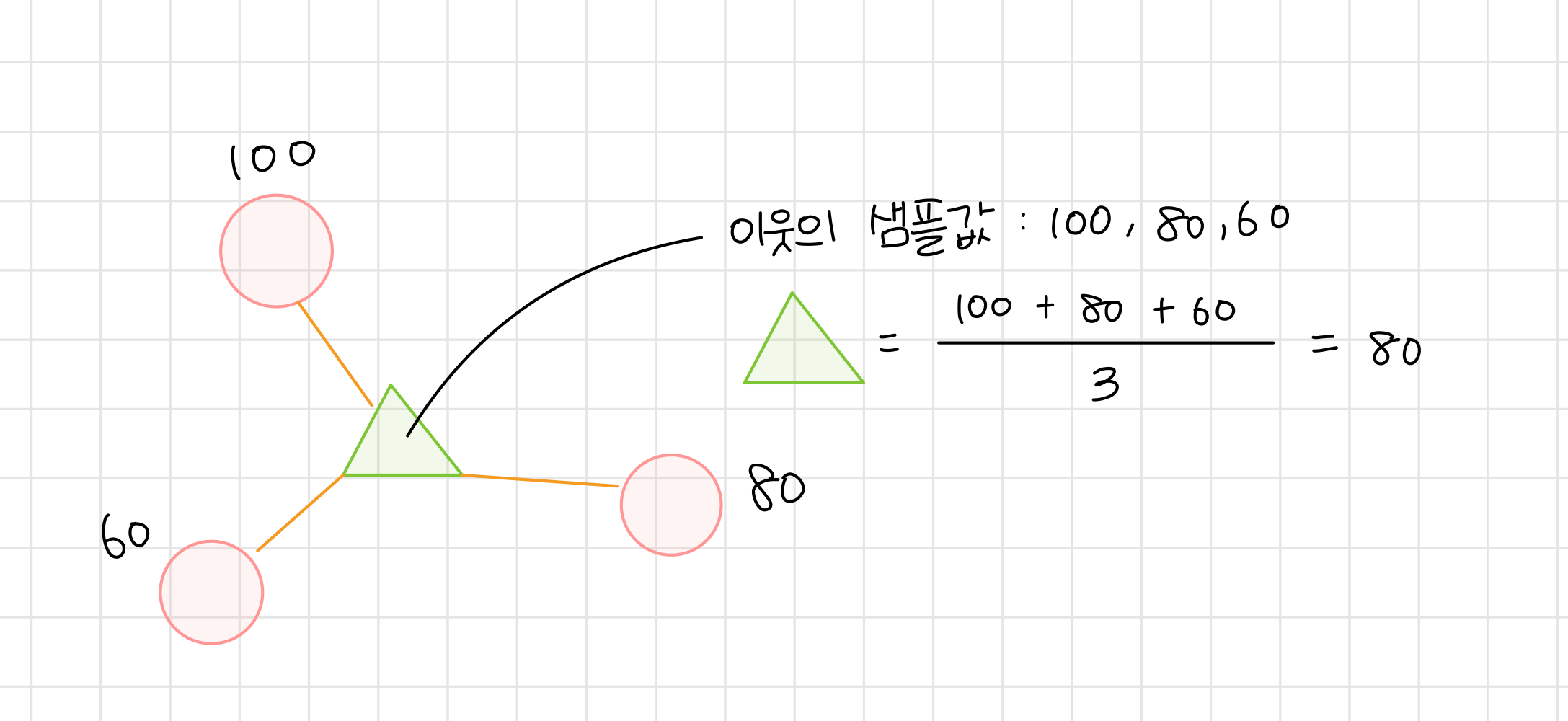
🏘️ K-최근접 이웃 회귀
K-최근접 이웃 분류 알고리즘이 주변 K개의 이웃의 클래스 중 다수의 클래스를 차지하는 알고리즘이었다면, K-최근접 이웃 회귀 알고리즘은 주변 K 개의 이웃의 샘플 값의 평균을 예측값으로 사용하는 알고리즘이다.
이 때 평균은 산술 평균 값이다!
❓ 문제 정의
농어의 길이 데이터를 이용하여 농어의 무게를 예측하자!
농어 무게라는 수치를 예측하는 것이 문제이므로 회귀 알고리즘을 사용하는 것이 적절하다!
💽 데이터 준비
농어의 길이 데이터와 농어의 무게 데이터 56개
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
print(perch_length)
print(perch_weight)
농어의 길이 데이터와 무게 데이터가 모두 일차원 배열 형태로 불러와졌다.

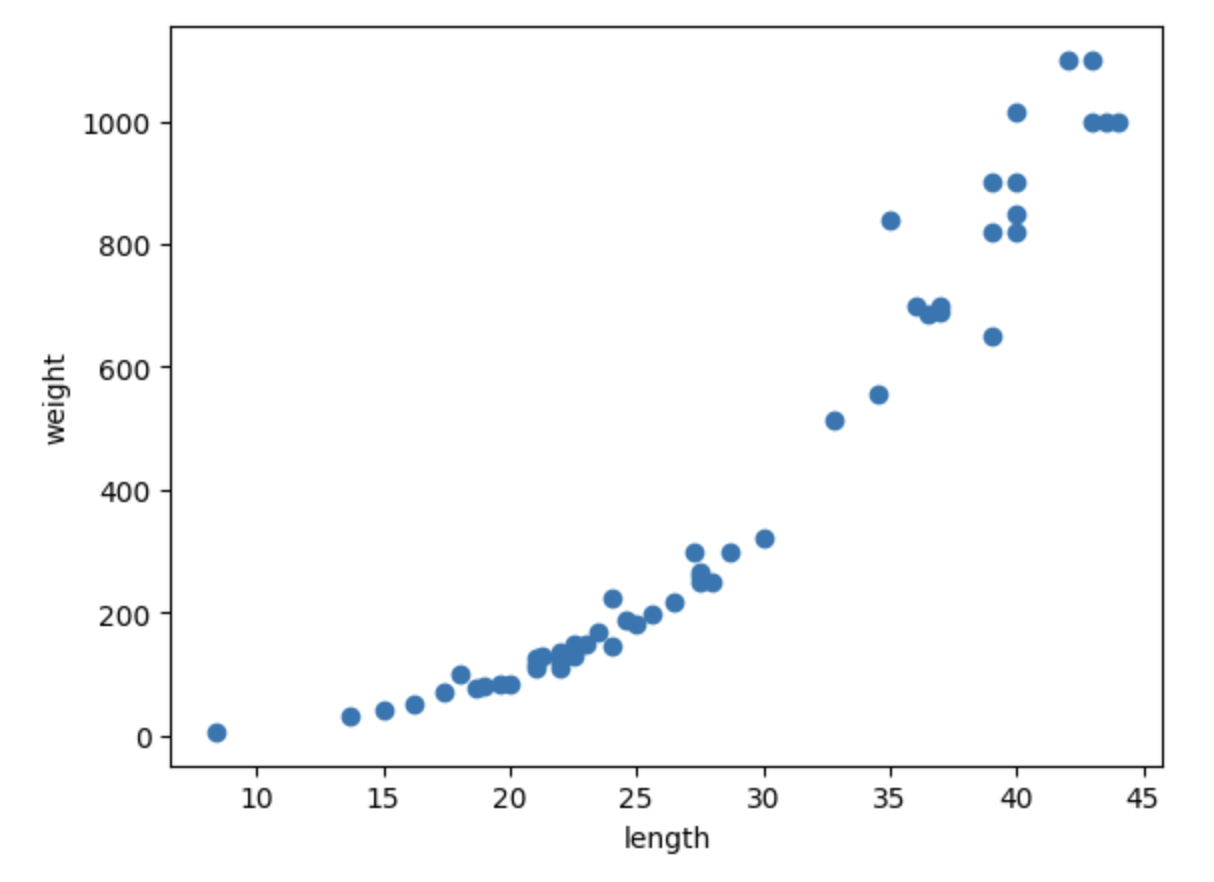
길이와 무게의 관계를 한눈에 보기 위해 산점도를 그려 시각화 한다.
우리는 길이 데이터를 통해 무게를 예측할 것이므로 길이를 x, 무게를 y로 설정한다.
import matplotlib.pyplot as plt
plt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
길이가 증가함에 따라 무게가 증가하고 있음을 알 수 있다.
모델에 학습시켜주어야 하므로 훈련 세트와 테스트 세트를 나눈다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
print(train_input.shape, test_input.shape)
print(train_target.shape, test_target.shape)
perch_length가 일차원 배열이었으므로 train_input, test_input 또한 일차원 배열이 되었다.
그러나 sklearn 모델에 학습시킬 때에 input 데이터는 무조건 이차원 배열이어야 한다!!
따라서 현재 train_input, test_input을 그대로 사용할 수 없으므로 이차원 배열 형태로 바꿔주어야 한다.
reshape() 메서드
넘파이 배열의 크기를 바꿔주는 메서드이다.
원본 배열의 원소 개수와 크기를 바꾼 배열의 원소의 수가 같지 않으면 오류가 나니 조심해야 한다.
test_array = np.array([1,2,3,4])
print(test_array)
print(test_array.shape)
test_array는 일차원 배열이다.
파이썬에서 일차원 배열은 원소가 1개인 튜플로 나타내므로 shape의 결과가 위와 같이 나온다.
참고로 이차원 배열의 shape는 (행,열) 형태의 튜플이다.
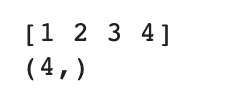
test_array = test_array.reshape(2,2)
print(test_array)
print(test_array.shape)
reshape() 메서드를 이용하여 2행 2열짜리 이차원 배열로 배열의 크기를 바꿔주었다.
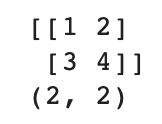
이차원 배열은 리스트 안에 리스트가 있는 형태라고 생각할 수 있다.
만약 (행, 열)이 잘 와닿지 않는다면 열 부분을 안쪽 리스트의 원소 개수라고 생각하면 편하다.
배열의 크기를 자동으로 지정하는 방법은 행 또는 열 중 하나를 -1을 사용하는 것이다.
크기에 -1을 지정하면 자동으로 원소의 수를 계산하여 바꿔준다.
train_input = train_input.reshape(-1,1)
test_input = test_input.reshape(-1,1)
print(train_input.shape, test_input.shape)
우리는 안쪽 리스트에 원소가 한개만 들어가면 되므로 열을 1로 지정한다.
행을 -1로 지정하면 행의 수를 파악할 필요 없이 자동으로 행의 개수를 계산하여 넣어준다.
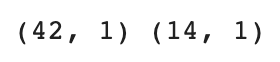
🤖 모델 학습
K-최근접 이웃 회귀 알고리즘을 사용하여 모델을 훈련한다.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
print(knr.score(test_input, test_target))
테스트 세트의 점수가 99.2점이 나왔다.
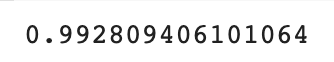
결정계수(R²)
위에서 설명한 점수는 사실 결정계수(coefficient of determination) 또는 R²(R square)라고 한다.
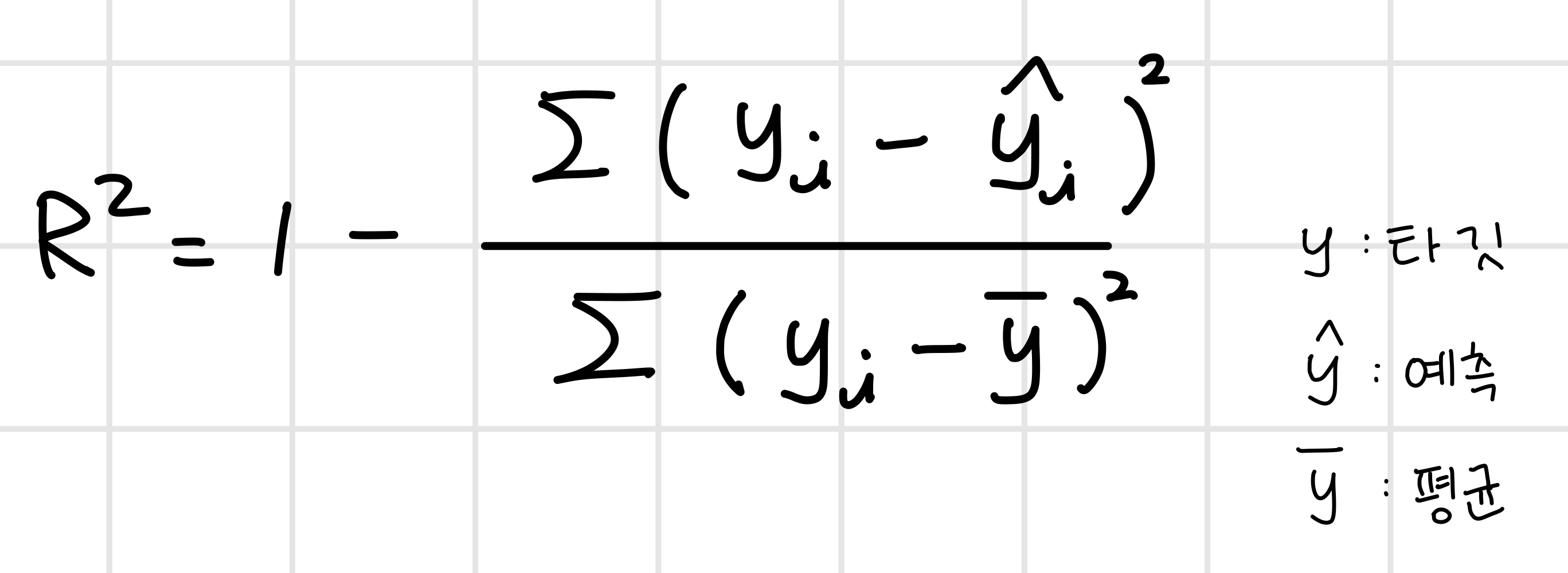
우리의 목표는 예측값이 실제 타깃과 최대한 근사하는 것이기 때문에 예측이 정확할수록 분자가 0이 되어 R²이 1에 가까워 진다.
그런데 만약 예측 값이 타깃의 평균 정도를 예측한다면(이렇게 되면 예측을 하는 의미가 없다!) R²이 0에 가까워 진다.
평균 절대 오차(mae)
모델의 성능을 평가하는 다른 방법으로는 mae가 있는데, 오차의 절댓값의 평균을 의미한다.
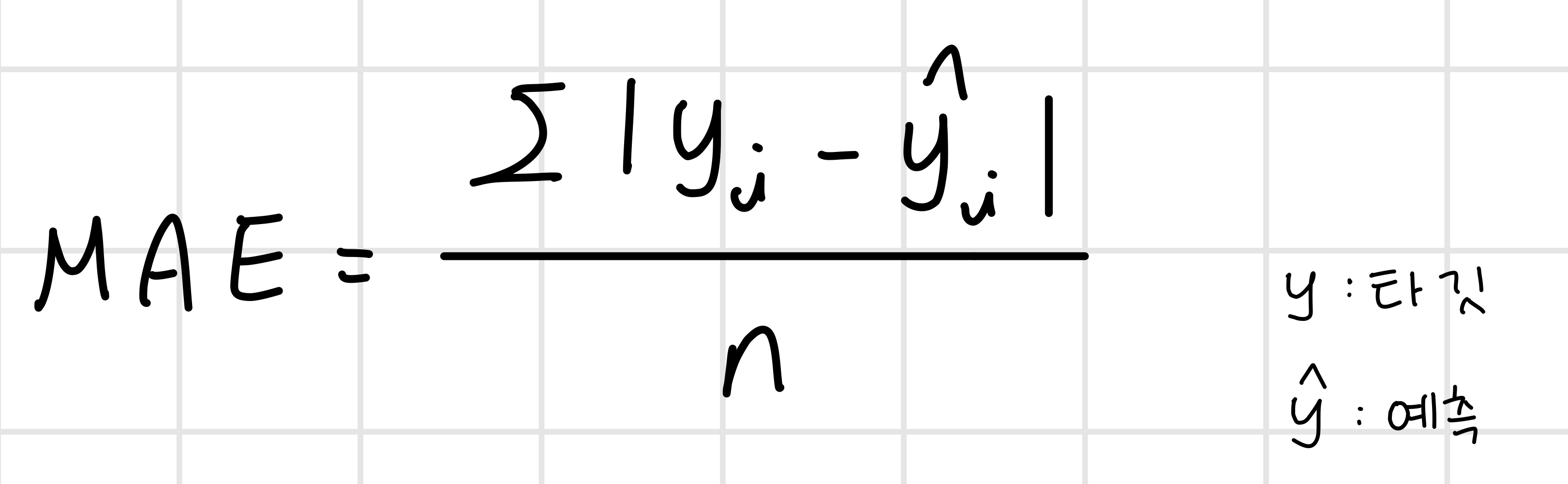
장점으로는 좀 더 직관적이라는 점이 있지만 절댓값을 사용하다보니 예측값이 실제보다 큰지/작은지는 알 수 없다는 단점이 있다.
from sklearn.metrics import mean_absolute_error
# 테스트 세트에 대한 예측
test_prediction = knr.predict(test_input)
# 테스트 세트에 대한 평균 절댓값 오차를 계산
mae = mean_absolute_error(test_target, test_prediction)
print(mae)
mae값에 따라 예측값이 평균적으로 실제 값과 약 19g정도 차이가 남을 알 수 있다.
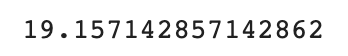
과대적합과 과소적합
과대적합(overfitting)
훈련 세트 점수 >>> 테스트 세트 점수인 경우 과대적합 되었다고 말한다.
즉, 학습 데이터 셋에 지나치게 최적화 되어 오히려 새로운 데이터에 대한 예측을 잘 못하는 경우를 의미한다.
원인과 해결 방안은 다음과 같다
- 훈련 데이터가 충분하지 못한 경우(주된 원인): 훈련 데이터 추가
- 데이터 셋 내 분산이 크거나 노이즈가 심한 경우: 데이터 전처리를 통해 훈련에 적합한 데이터셋 만들기
- 모델의 복잡도가 큰 경우: 가중치를 제한하는 규제를 적용하여 모델의 복잡도 낮추기
- 과도하게 큰 epoch로 학습을 진행한 경우: 조기종료를 통해 모델이 적당히 학습하도록 하기
과소적합(unerfitting)
훈련 세트 점수 < 테스트 세트 점수 또는 훈련 세트 점수와 테스트 세트 점수 모두 낮은 경우 과소적합 되었다고 한다.
모델이 너무 단순하여 훈련 세트에 대한 훈련이 제대로 되지 않아 훈련 세트의 구조나 패턴 조차 파악하지 못한 경우를 의미한다.
원인과 해결 방안은 다음과 같다.
- 모델 복잡도가 낮은 경우: 조금 더 복잡한 모델 사용
- 모델에 너무 많은 규제가 적용된 경우: 규제를 줄임
- 충분하지 못한 epoch로 학습하는 경우: epoch를 조정하여 모델이 충분히 학습할 수 있도록 조정
print(knr.score(test_input, test_target))
print(knr.score(train_input, train_target))
훈련 세트 점수가 테스트 세트 점수보다 낮으므로 위 모델은 과속적합되었다고 할 수 있다.
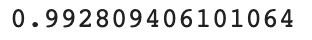
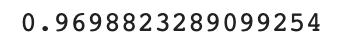
과소 적합 해결
과소적합을 해결하기 위하여 조금 더 복잡한 모델을 사용해 보기로 한다.
K-최근접 이웃 알고리즘 모델을 더욱 복잡하게 만드는 것은 K를 줄이는 것이다.
K를 줄이면 조금 더 국지적인 패턴에 민감해 진다.
# k를 줄여 국지적인 패턴에 민감한 복잡한 모델을 만들자
knr.n_neighbors = 3
knr.fit(train_input, train_target)
print(knr.score(train_input, train_target))
R² 값이 96에서 98점으로 점수가 높아진 것을 확인할 수 있다.
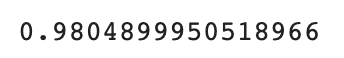
print(knr.score(test_input, test_target))
이제 훈련 세트 점수보다 테스트 세트의 점수가 낮아졌으므로 과소적합 문제가 해결되었다고 볼 수 있다.
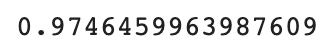
📚 Reference
혼자 공부하는 머신러닝+딥러닝, 박해선, 한빛미디어
