
🛑 잠깐, 이전 코드에서 이상한 점 없음?
from sklearn.neighbors import KNeighborsClassifier
# 객체 만들기: 이 객체 훈련시킬거임!
kn = KNeighborsClassifier()
#모델 훈련
kn.fit(fish_data, fish_target)
#모델 평가
kn.score(fish_data, fish_target)훈련할 때 사용한 데이터와 평가할 때 사용한 데이터가 같은 데이터네?
어쩐지 모델 정확도가 100%더라!!
❓ 엥 모델 정확도가 100%면 좋은거 아님?
우리가 만든 모델은 도미 데이터와 빙어 데이터를 구분하는 문제였음!
즉, 정답지가 있는 지도학습(supervised learning)이었다는 뜻!
지도학습과 비지도학습을 모른다면?
위에 예시처럼 훈련할 때와 테스트할 때 같은 같은 데이터를 쓴다면, 정답지를 주고 시험을 본 것과 마찬가지!
즉, 모델의 성능으로 올바르게 평가할 수 없다
📍 해결방법: 데이터 분할
✅ 훈련 세트와 테스트 세트
모델의 정확한 성능 평가를 위하여 데이터를 훈련 세트(train set)와 테스트 세트(test set)로 나누는 것을 말한다.
모델 학습을 시킬 때 훈련 세트를 사용하고, 모델의 성능을 평가할 때는 모델이 처음 보는 데이터인 테스트 세트를 사용하여 성능 평가를 진행한다!
데이터를 분할할 때에는 bias를 피하기 위해 랜덤 샘플링(random sampling)을 진행한다
🤔 나는 검정 세트도 들어봤는데
검정 세트란 validation set라고도 말하는데 모델을 테스트하기 전에 점검하는 데이터라고 생각하면 된다.
모델 훈련할 때 사용하지 않는다는 점에서 train set와 비슷하지만, validataion set는 테스트 전에 모델 튜닝(tuning) 시 사용한다는 점에서 차이가 있다.
💾 그렇다면 다시 데이터를 불러오자(데이터 수집)
# 리스트 형태로 데이터 불러오기
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
# 각 리스트의 길이 출력
print(len(fish_length), len(fish_weight))출력
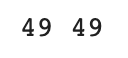
해석
- 데이터의 크기는 49개이다.
- 길이 데이터와 무게 데이터의 개수가 같은 것으로 보아 누락값 없이 제대로 입력했다.
⚙️ 데이터 준비
fish_data 이차원 배열 형태로 변환
👩🏫 잠깐, 왜 이차원 배열 형태로 변환한다고 했었지?
사이킷런(scikit-learn) 라이브러리는 입력(input) 데이터 형태가 2차원 배열이라서!
# 길이 데이터와 무게 데이터를 2차원 배열 형태로 만들기
fish_data = [[l,w] for l,w in zip(fish_length, fish_weight)]
print(fish_data)출력
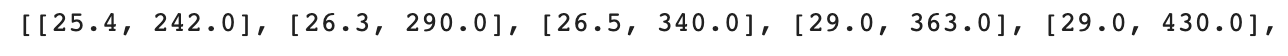
tip
이차원 배열은 배열 안에 배열이 있는 형태라고 생각하면 쉽다!
정답 데이터 만들기
# 정답 데이터 만들기
fish_target = [1] * 35 + [0] * 14train set과 test set 나누기
# 훈련 세트로 35개의 샘플 사용
train_input = fish_data[:35]
train_target = fish_target[:35]
# 테스트 세트로 14개의 샘플 사용
test_input = fish_data[35:]
test_target = fish_target[35:]인덱스의 의미
- [:n] 0번째 인덱스부터 n-1번째 인덱스까지 즉 n개의 요소 슬라이싱(slicing)
- [n:] n번째 인덱스부터 리스트의 끝까지 슬라이싱
🤖 기계학습
객체 만들기
저번 예시와 마찬가지로 KNN 알고리즘 사용!
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()모델 훈련
만들어뒀던 훈련 세트를 학습에 사용!
kn = kn.fit(train_input, train_target)모델 평가
만들어뒀던 테스트 세트를 학습에 사용!
kn.score(test_input, test_target)
해석
- 정확도 0% 모델 탄생...!
- 맞춘 데이터가 하나도 없다!
🎈 샘플링 편향(sampling bias)
# 훈련 세트로 35개의 샘플 사용
train_input = fish_data[:35]
train_target = fish_target[:35]
# 테스트 세트로 14개의 샘플 사용
test_input = fish_data[35:]
test_target = fish_target[35:]이렇게 데이터를 분할하게 되면 훈련 세트에는 빙어 데이터가 하나도 들어가있지 않게 된다!!!!
이렇게 데이터가 치우쳐있는 경우를 샘플링 편향이라고 한다.
데이터를 분할할 때에는 랜덤 샘플링(random sampling)해야한다는 사실을 잊지 말자!!
⚒️ 다시 데이터 준비
input 데이터와 traget 데이터 준비
〰️ 넘파이(numpy)
넘파이는 파이썬에서 여러 수치계산에 용이하게 사용할 수 있는 라이브러리이다.
단순 계산 뿐만 아니라 벡터 연산, 행렬 연산 등 다양한 연산을 지원한다.
리스트를 넘파이 배열로 쉽게 변환할 수 있다.
넘파이 임포트
numpy는 보통 np로 줄여서 사용한다.
import numpy as np리스트를 넘파이 배열로 바꾸기
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)💣 array() 함수
파이썬 리스트를 넘파이 배열로 변환하는 함수.
np.array(파이썬 리스트) 형태로 사용한다.
print(input_arr)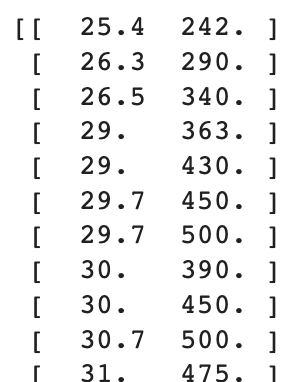
파이썬 리스트와 출력되는 형태 비교!
넘파이 배열은 2차원 형태로 출력된다!
2차원 배열도 일렬로 주르륵 출력되는 파이썬 리스트와의 차이점이다.
데이터 형태 파악
🧰 shape
넘파이 배열의 크기를 알려준다
(행,열) 형태로 출력된다.
즉, (샘플수,칼럼수)라고 할 수 있다.
print(input_arr.shape)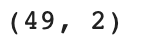
해석
- 49개의 샘플, 2개의 특성
다시 train set과 test set 나누기
input_arr와 target_arr를 직접 랜덤으로 섞어버리면 어떤 데이터의 정답이었는지 같이 섞이게 된다.
따라서 인덱스 배열을 따로 만든 후 인덱스 배열을 섞기로 한다.
np.random.seed(42) # 결과가 일정하도록
index = np.arange(49)
np.random.shuffle(index)
print(index)💡 arange(N) 함수
N은 정수이다. arange() 함수는 0부터 N-1까지 1씩 증가하는 정수 배열을 만든다.

해석
- np.random.shuffle() 함수를 통해 인덱스를 램덤하게 섞었다.
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
print(train_input[0])램덤하게 섞인 상태의 index 배열에서 0~34번째에 있는 요소를 input_arr와 target_arr의 인덱스로 사용!
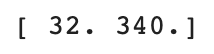
해석
위 출력 결과는 index[0]의 값이 13이므로 input_arr[13]의 샘플이다!
# x축은 길이 y축은 무게로 데이터 분포 확인하기
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(test_input[:,0], test_input[:,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()코드 해석: train_input[:,0]
train_input은 (길이,무게) 형식의 2차원 배열이다.
train_input의 모든 원소 중 첫번째 요소인 길이를 의미하는 것이다.
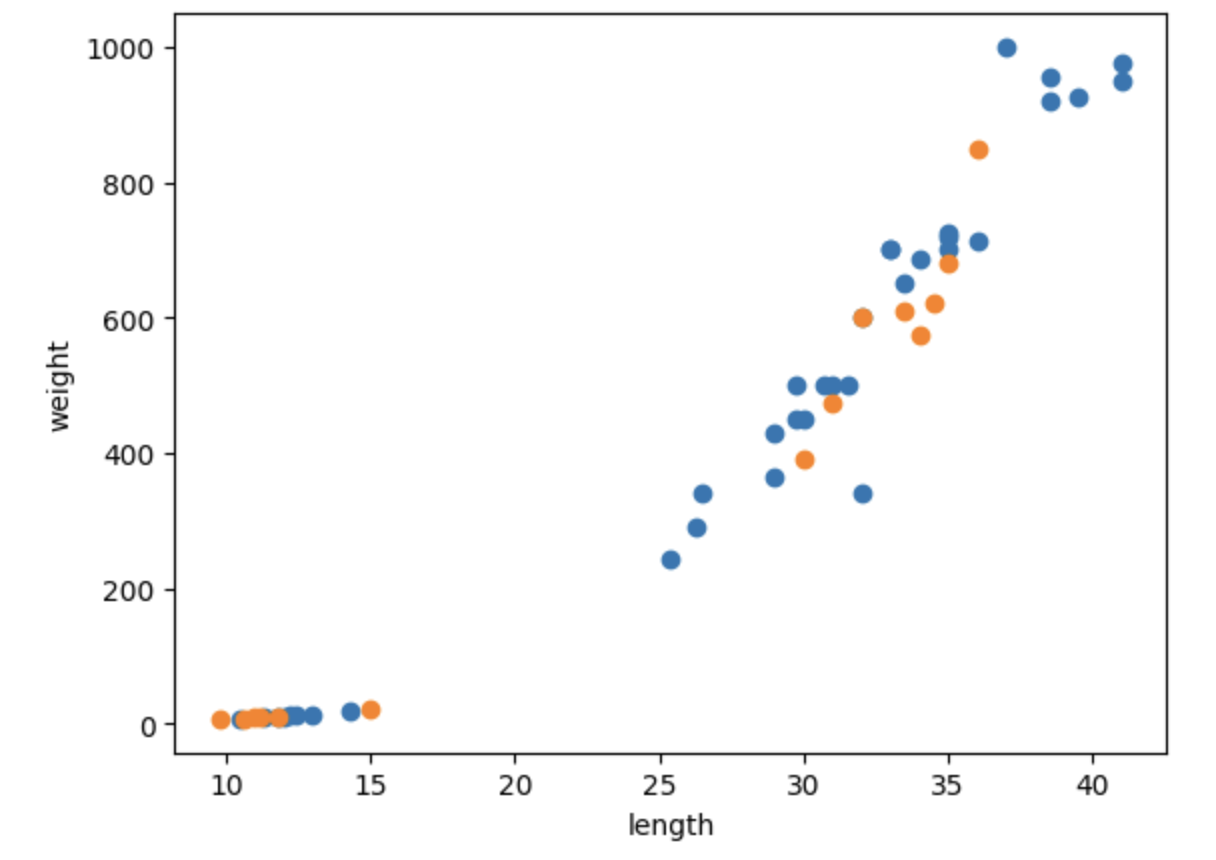
그래프 해석
훈련 세트와 테스트 세트에 도미와 빙어가 적절히 섞였다고 볼 수 있다.
🩺 다시 기계 학습
kn = kn.fit(train_input, train_target)
kn.score(test_input, test_target)출력

해석
- 훈련 세트와와 테스트 세트를 구분하여 모델 평가 진행함
- 모델 정확도 100%
테스트 세트의 예측 결과
kn.predict(test_input)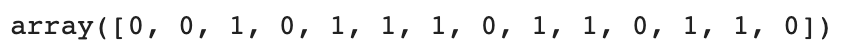
실제 정답(test_target)과 비교하기
test_target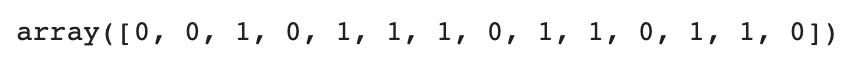
해석
- 예측 결과와 test_target이 일치하는 것을 알 수 있다.
- 즉, 모델의 정확도 100%
📚 Reference
혼자 공부하는 머신러닝+딥러닝, 박해선, 한빛미디어
