
❓문제 정의
이전에 만든 KNN 모델이 길이 25cm, 무게 150g인 도미를 자꾸 빙어로 분류한다.
이 문제를 해결해야 한다!
문제 상황 확인
위 문제가 진짜인지 확인해보기 위해 다시 데이터를 준비한다.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]앞에서와 마찬가지로 도미 데이터 35개, 빙어데이터 14개의 데이터 셋이다.
데이터를 넘파이 배열로 만들면 좀 더 쉽게 데이터를 가공할 수 있고 데이터가 클수록 리스트에 비해 더 효율적이다.
numpy 사용을 위해 임포트한다.
import numpy as np위에 리스트는 생선의 길이 데이터와 무게 데이터가 각각 선언되어 있기 때문에 모델에 학습을 시기키 위해서는 두 리스트를 연결해 주어야 한다.
리스트를 연결하는 방법: column_stack(), concatenate()
두 함수 모두 매개변수로 연결하고자 하는 리스트를 튜플 형태로 묶어서 전달한다.
튜플은 리스트와 같이 데이터를 묶는 자료구조를 말하지만 리스트가 [ ]로 데이터를 묶는 반면 튜플은 ()로 데이터를 묶는다. 또한 리스트와 달리 튜플은 선언 이후 수정할 수 없다.column_stack()
리스트를 일렬로 세워 연결한다. n개의 리스트를 연결하면 n차원 넘파이 배열이 된다.
concatenate()
리스트를 그대로 연결하는 함수이다. 배열의 차원이 증가하지 않는다. 1차원 넘파이 배열이 된다.
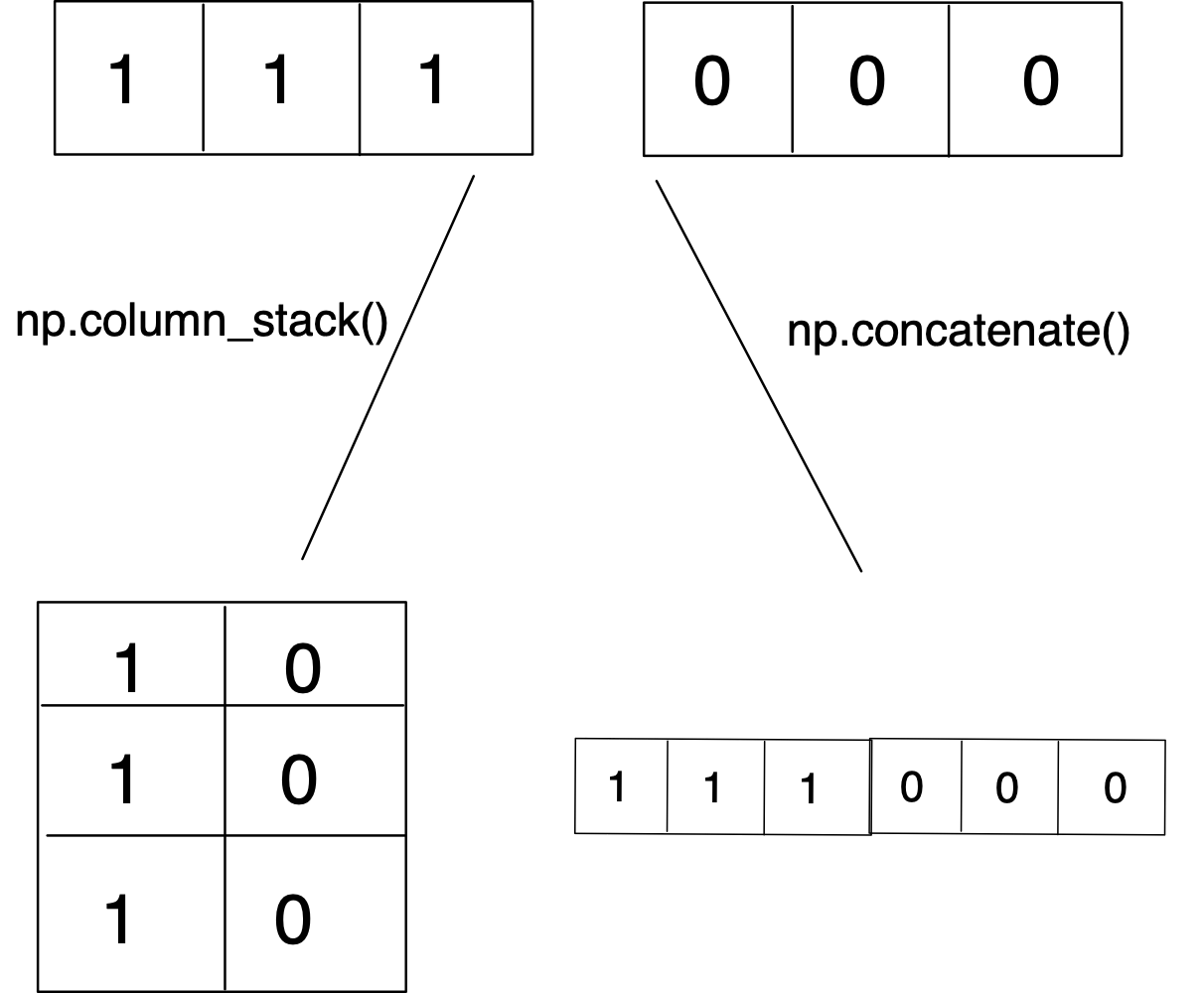
길이 리스트와와 무게 리스트를 연결하여 하나의 데이터로 나타내자.
fish_data = np.column_stack((fish_length, fish_weight))
print(fish_data[:5])
길이 데이터와 무게 데이터가 이차원 배열로 합쳐진 것을 볼 수 있다.

타깃데이터 또한 넘파이 배열로 만든다.
np.zeros()와 np.ones()를 이용하면 0과 1로 채워진 배열을 쉽게 만들 수 있다.
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
print(fish_target)
train_test_split
사이킷런 라이브러리의 train_test_split()을 이용하면 직접 데이터를 섞지 않아도 원하는 비율대로 훈련 세트와 테스트 세트를 랜덤 샘플링 할 수 있다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state=42)
#실습은 동일한 결과를 얻기 위해 random_state=42를 이용하여 항상 같은 결과가 나오도록 한다훈련 세트와 테스트 세트가 잘 나누어졌는지 확인해보자.
print(train_input.shape, test_input.shape)
print(train_target.shape, test_target.shape)
train_test_split()은 기본적으로 train set:test set 비율을 3:1 정도로 맞춰준다.
shape를 이용하여 데이터의 크기를 출력해보면 36:13으로 약 3:1 비율인 것을 알 수 있다.

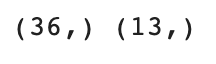
그렇다면 train set과 test set에 샘플링 편향은 일어나지 않았는지 확인해보자.
print(test_target)
13개의 테스트 세트에서 도미(1)가 10개 빙어(0)가 3개 추출된 것을 확인할 수 있다. 모집단에서 도미:빙어가 35:14로 약 2.5:1이었던 것을 감안하면 약간의 샘플링 편향이 나타났다고 볼 수 있다.
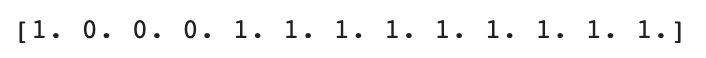
stratify 매개변수로 타깃 데이터를 전달하면 타깃 데이터의 클래스 비율에 맞게 훈련 세트와 테스트 세트를 나눠준다.
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify=fish_target, random_state=42)
print(test_target)
fish_target의 비율대로 훈련 세트와 테스트 세트를 나눈다.
도미(1):빙어(0)가 9:4로 약 2.25:1의 비율로 모집단의 비율이 2.5:1과 비슷해졌다.

위의 데이터로 전과 같이 모델 학습을 진행한다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
모델 정확도가 1이므로 길이 25cm, 무게 150g인 도미 또한 도미로 예측할 것이라고 기대할 수 있다.

print(kn.predict([[25,150]]))
문제 발생: 도미를 빙어라고 예측한다!

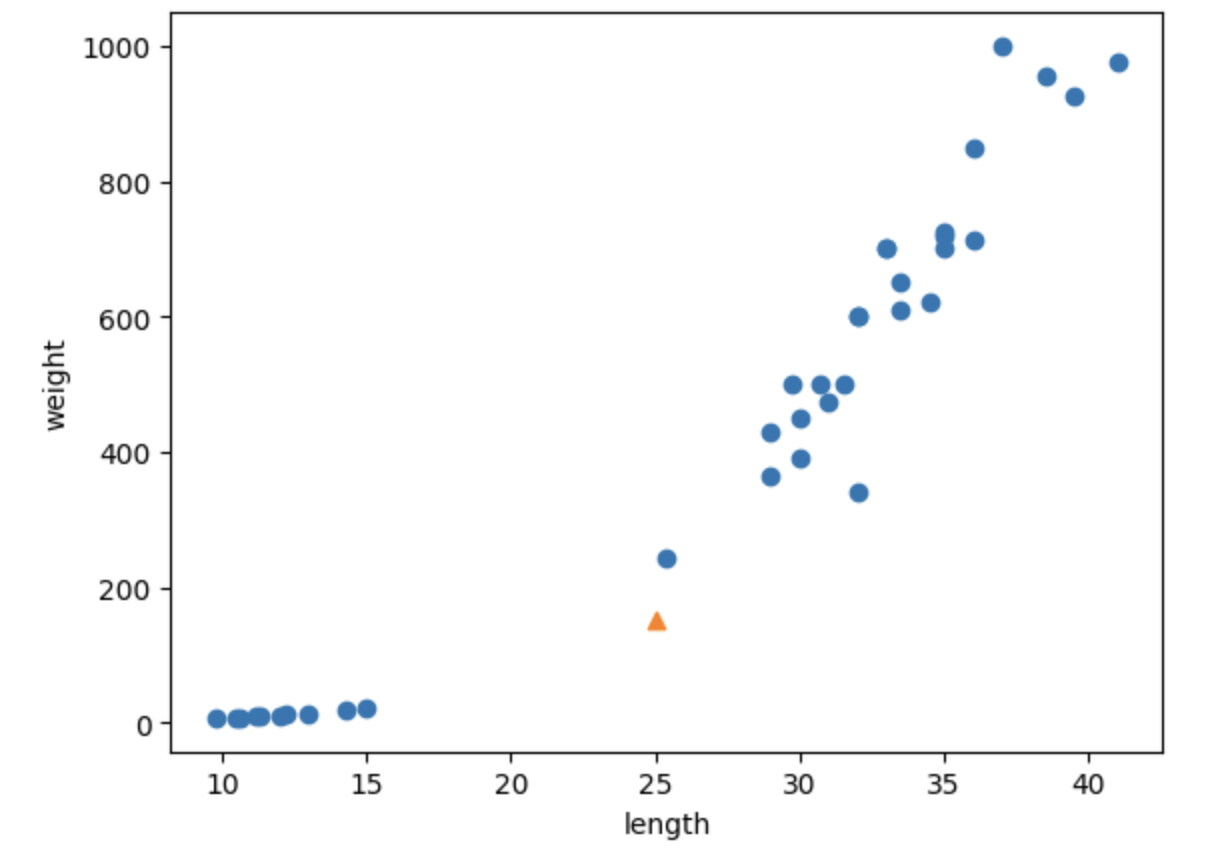
길이 25cm, 무게 150g인 생선이 산점도에서 어디에 분포하는지, 정말 빙어로 예측하는 것이 타당한지 알아보자.
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0],train_input[:,1])
plt.scatter(25,150,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
분포상 도미로 분류하는 것이 더 타당하다.
그렇다면 모델이 판단한 [25,150] 샘플의 이웃을 알아보자.
kneighbors()를 이용하여 분류하고 싶은 샘플의 이웃에 대한 정보를 얻을 수 있다.
즉, 이웃과의 거리와 이웃 샘플의 인덱스를 반환해준다.
KNN 객체의 n_neighbors의 기본값이 5이므로 기본적으로 5개의 이웃에 대한 정보를 반환한다.
distances, indexes = kn.kneighbors([[25,150]]) #데이터는 이차원 배열로!
print(distances, indexes)
[25,150] 샘플과 가장 가까운 5개의 샘플까지의 거리가 distances 변수에, 그 샘플들의 인덱스가 indexes 변수에 저장되었다.

산점도에 나타내서 이웃 샘플들이 정확히 어디 있는지 알아보자.
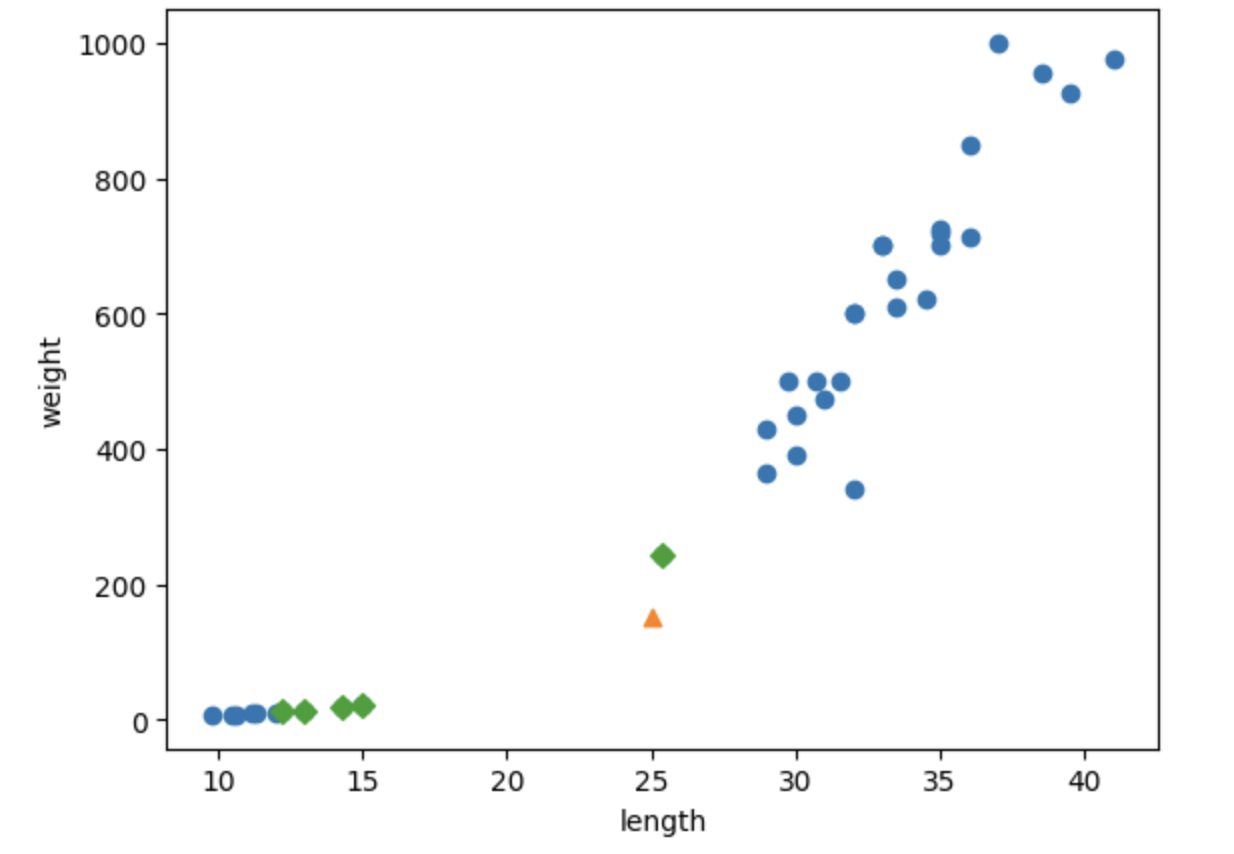
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25,150,marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1],marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
이웃샘플 5개 중 4개가 빙어로 확인되었다.
print(train_input[indexes])
print(train_target[indexes])
아무리 봐도 주변 샘플 5개 중 4개가 빙어다.
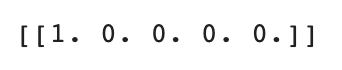
길이를 다시 보자.
print(distances)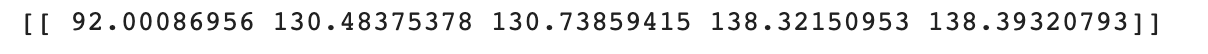
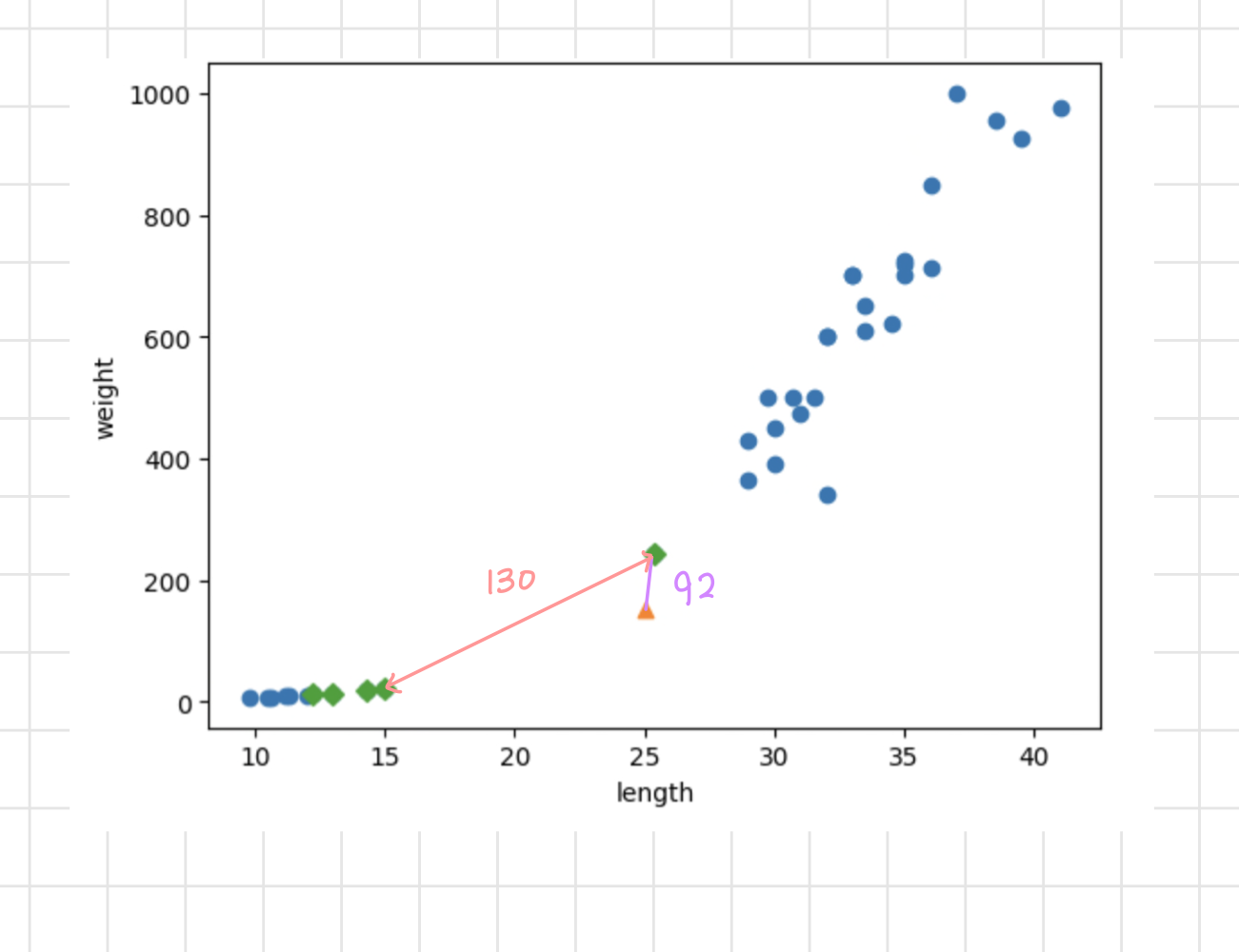
현재 길이에 따르면 길이와 비율이 좀 이상함을 알 수 있다...!
이유는 x축과 y축 두 축의 스케일이 다르기 때문인데,
x축의 스케일이 10~40인 반면 y축의 스케일은 0~1000인 것을 볼 수 있다.
따라서 유클리드 거리(점과 점 사이의 거리)로 이웃간 거리를 측정하는 KNN 방식에서 y축의 민감도가 매우 커지게 된다.
무슨 말인지 이해가 안된다면 두 축의 스케일을 맞춰보면 더 쉽게 이해할 수 있다.
xlim()을 이용하여 x축의 스케일 또한 0~1000으로 바꿔보자.
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25,150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.xlim(0,1000)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()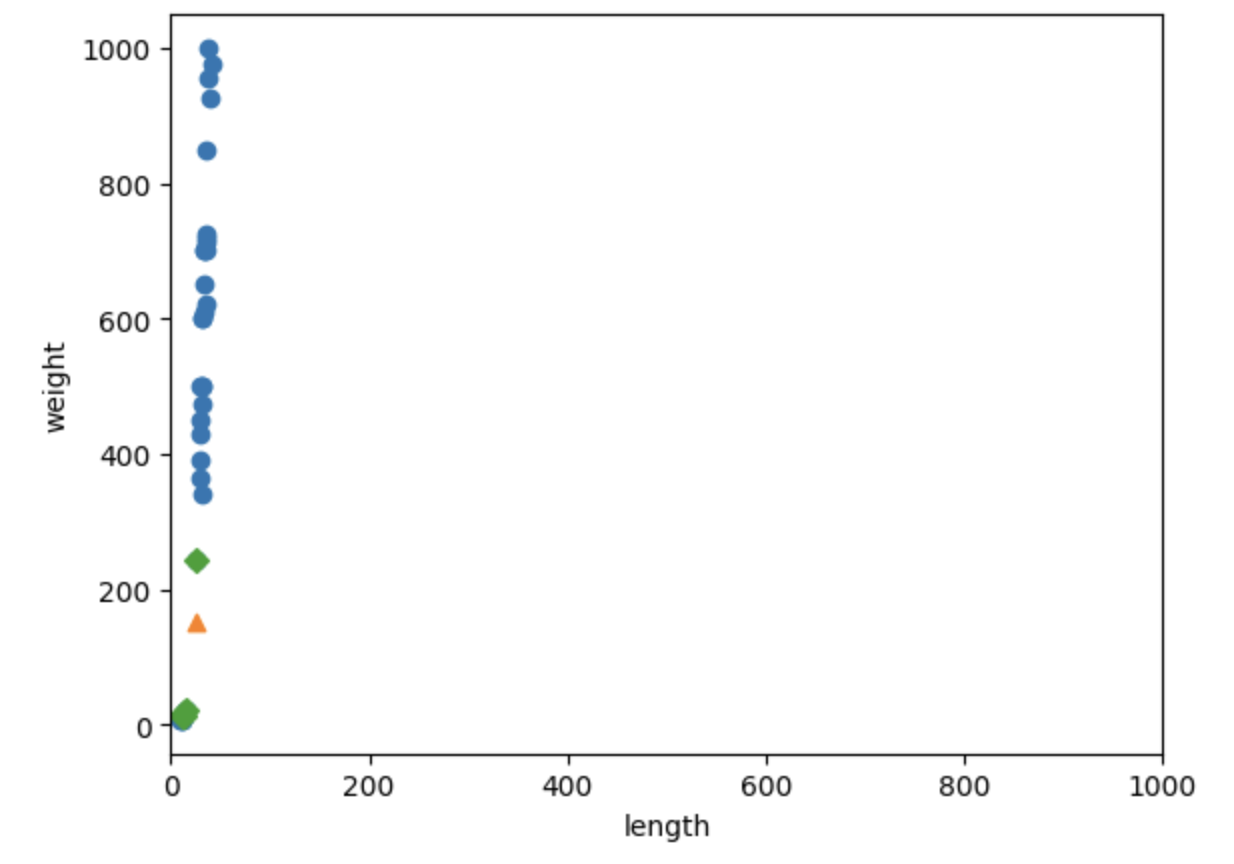
이런 데이터로 KNN 모델을 학습시키면 사실상 길이는 무시하고 무게만 고려한 모델이 된다.
🔨 해결방법: 데이터 전처리_표준화
모델 학습 시 길이와 무게를 모두 고려하고 싶다면 두 속성의 스케일을 맞춰주어야 한다.
가장 흔히 사용하는 방법은 표준점수(z점수)를 이용하는 것이다.
z = (x - 평균) / 표준편차로 계산하며 x가 평균으로부터 표준편차의 몇 배만큼 떨어져 있는가를 의미한다.
그렇다면 우선 평균과 표준편차를 먼저 구하기로 하자.
numpy 함수로 쉽게 구할 수 있다.
mean = np.mean(train_input, axis=0) #axis=0: 열 별 통계!
std = np.std(train_input, axis=0)
print(mean, std)
axis=0 매개변수를 이용하여 길이와 무게에 대하여 각각 평균과 표준편차를 구했다.
무게에 대한 표준편차가 매우 큰 것을 알 수 있다.
사실 무게 표준편차 구해보고 바로 표준화 작업이 필요하다는 것을 알 수도 있다.
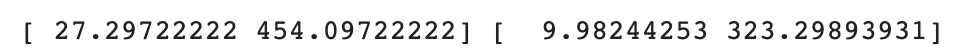
평균과 표준편차를 이용하여 표준 점수를 계산한다.
train_scaled = (train_input - mean) / std
print(train_scaled)
바뀐 분포를 한눈에 보기 위하여 산포도를 그려보자.
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(25,150,marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()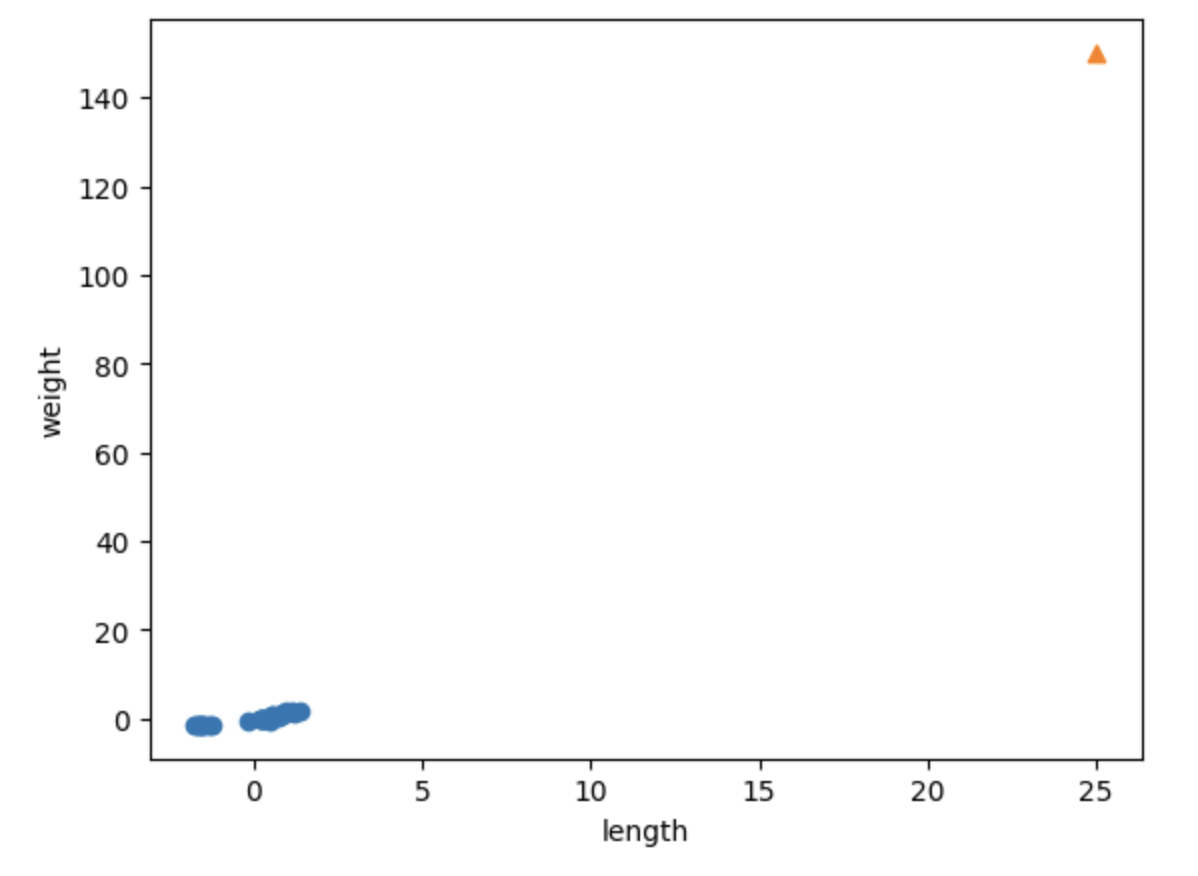
훈련 세트를 표준화 했다면 다른 샘플 모두 같은 기준을 따르도록 표준화시켜줘야 한다.
new = ([25,150] - mean) / std
print(new)
훈련 세트와 같은 기준에 맞춰 표준화 작업
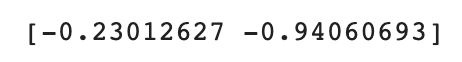
그 후 샘플의 위치를 파악하기 위해 산포도를 그린다.
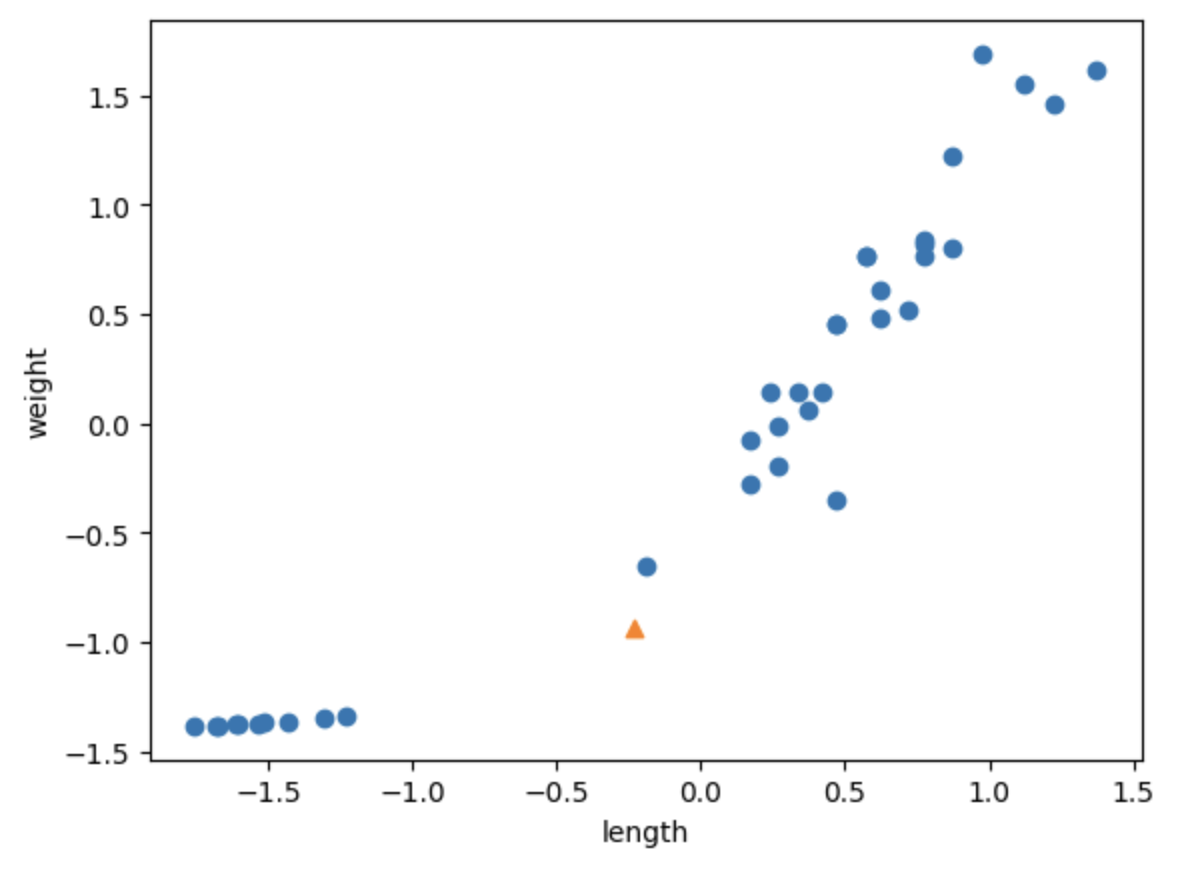
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
x축의 스케일과 y축의 스케일이 같아진 것을 확인할 수 있다.
🤖 전처리 데이터로 다시 모델 훈련
위와 같이 전처리된 데이터로 다시 모델을 훈련하면 길이와 무게 속성을 모두 반영한 모델을 만들 수 있다.
kn.fit(train_scaled, train_target)테스트 전 테스트 세트 또한 훈련 세트와 같은 기준을 따르도록 표준화 해 주어야 함을 잊지 말자!
test_scaled = (test_input - mean)/std
print(test_scaled)
kn.score(test_scaled, test_target)
모델 정확도가 100% 이므로 길이 25cm, 무게 150g의 생선을 도미로 예측할 것이라고 기대할 수 있다.

print(kn.predict([new]))
샘플 또한 훈련 데이터와 같은 스케일을 따라야하기 때문에 표준화된 데이터인 new를 사용했다.
이제 해당 샘플을 도미로 잘 예측한다.
표준화된 샘플의 이웃에 대한 정보를 다시 보면
distances, indexes = kn.kneighbors([new])
print(distances, indexes)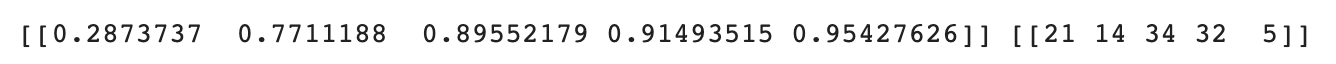
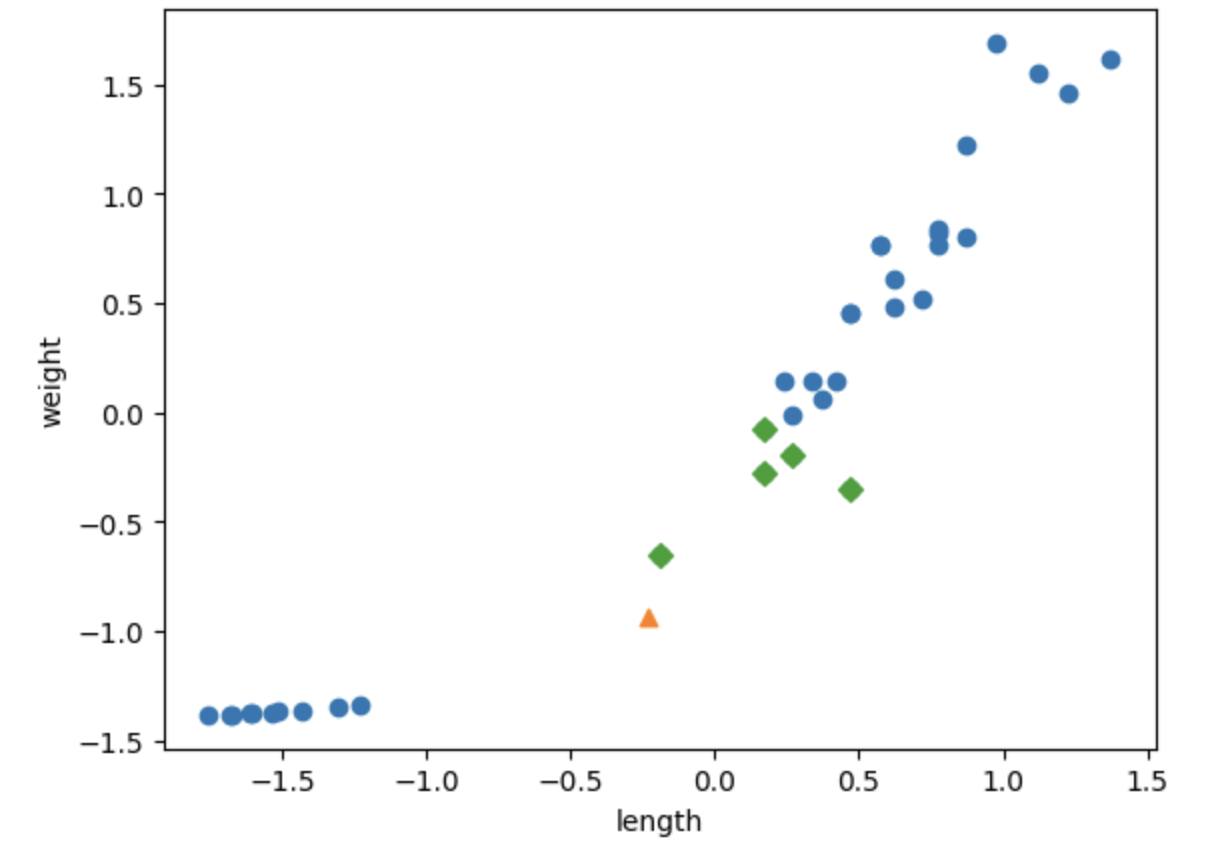
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
이제 [25,150] 샘플의 이웃들을 도미로 잘 파악하고 있음을 알 수 있다.
📚 Reference
혼자 공부하는 머신러닝+딥러닝, 박해선, 한빛미디어
