
⛰ 정상
저번 포스트에서 배운 것까지를 "산의 정상에 올랐다" 라고 할 수 있다.
강사님께서 이제 여기서 더 배워나갈지, 아님 하산할지를 정해야 한다고 하셨다.
그걸 구분하기 위해서는 혁신(innovation)과 본질(essence)에 대해 생각해보라고 하셨다.
(혁신 - Relational / 본질 - Database)
✔️ 관계형 데이터베이스의 필요성
 (➡️ 강의의 예제 topic 테이블)
(➡️ 강의의 예제 topic 테이블)
관계형 데이터베이스는 왜 🤷🏻♀️ 필요할까?
위의 예제를 보면 데이터의 중복이 존재한다. (author의 egoing, 그리고 profile의 developer)
이는 개선할 것이 있음의 증거가 된다.
지금은 행이 5개 뿐이라 심각성이 느껴지지 않지만 행이 1억개라고 상상해보자.
그렇다면 데이터의 중복은 여러가지의 문제를 발생시킬 수 있다.
그리고 그 중복되는 수천개의 데이터를 변경해야 하는 상황이 생긴다면?
데이터 하나하나 변경하는 비효율적이고 바보같은 행동은 금물이다.
그렇기 때문에 관계형 데이터베이스가 필요한 것이다.
 이렇게 author라는 id, name, profile을 포함하고 있는 테이블을 따로 생성하고,
이렇게 author라는 id, name, profile을 포함하고 있는 테이블을 따로 생성하고,
Author_id라는 컬럼으로 대체하여 author 테이블에 해당하는 id를 넣어주었다.
➡️ 중복을 완전히 없애주었다. (created는 무시)
그럼 이제 새로운 topic 테이블에서 egoing이라는 이름을 yoon이라고 수정해야 할 때 author 테이블의 id=1의 이름만을 수정하면 된다.
번거로운 작업이 사라졌다. ➡️ 유지보수 편리
더군다나 과거의 topic 테이블에서 egoing이라는 사람은 id=1, 2, 5에 존재했다. 하지만 이들이 모두 같은 사람이라는 것은 알 수 없었다. (동명이인의 가능성)
하지만 id값으로 구분해줌으로써 분명하게 알 수 있게 되었다.
하지만 장점이 있는 만큼 단점도 가지고 있다. ➡️ Trade-off
수정 전의 topic 테이블은 하나의 표에 author, profile까지 담겨있어 데이터를 굉장히 직관적으로 볼 수 있다.
그런데 별도로 테이블을 쪼개놓으니 데이터를 볼 때 그에 해당하는 정보를 모두 조회하기 위해서는 다른 테이블까지 조회해야 한다는 불편함이 존재한다.
🤷🏻♀️: 중복을 허용하지 않으면서도 한번의 조회로 모든 데이터를 볼 수 있는 방법은 없을까?
🙋🏻♀️: MySQL!!

우선 실습을 위해 만들어놓은 테이블을 조금 수정하고 복사하고 정리해놓을 것이다.
현재 데이터 상태

저번 게시물에서 CRUD 수행을 위해 삭제했던 행을 하나 추가하도록 하겠다.
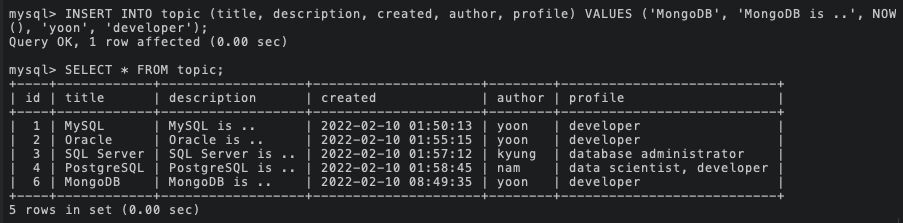
그리고 이 데이터를 테이블을 쪼개기 전 남겨두기 위하여 topic_backup이라는 이름으로 테이블 구조와 데이터를 복사해준다.
CREATE TABLE [복사해 생성될 테이블] LIKE [복사될 테이블];
: 테이블 구조 복사INSERT INTO [붙여넣기 될 테이블] SELECT * FROM [복사할 테이블];
: 전체 데이터 복사
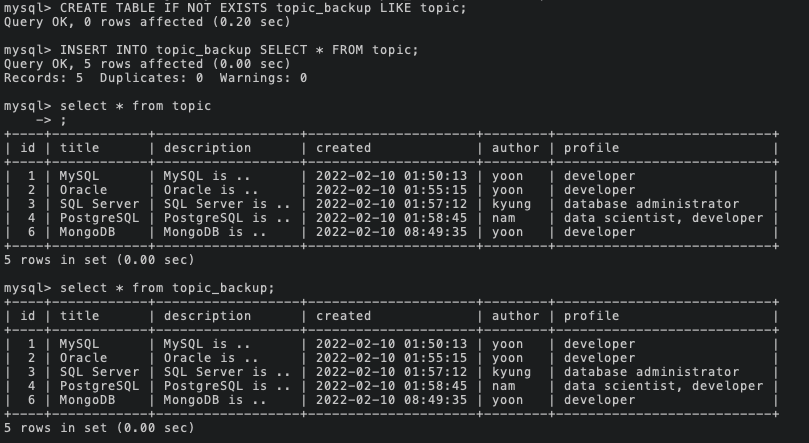 이렇게 복사에 성공하였다.
이렇게 복사에 성공하였다.
그리고 이제 author 테이블을 생성하고, topic 테이블을 수정하자.
저번 게시글에서 배웠던 내용을 활용하여 author 테이블을 생성하였다.
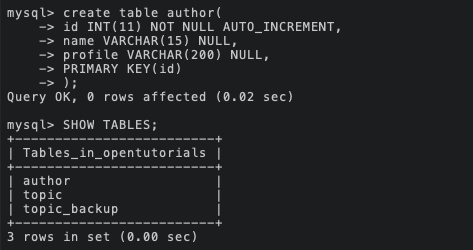
그리고 데이터를 각각 생성해 채워주었다.
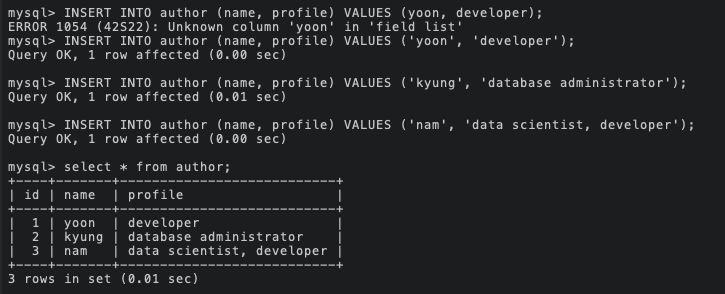
이제 author 테이블의 준비는 끝났고, topic 테이블을 수정한다.
ALTER TABLE [테이블명] DROP [컬럼명];
: topic 테이블에서 profile 컬럼 삭제
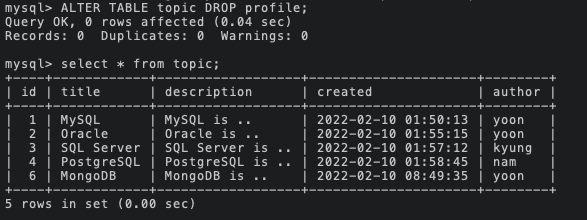
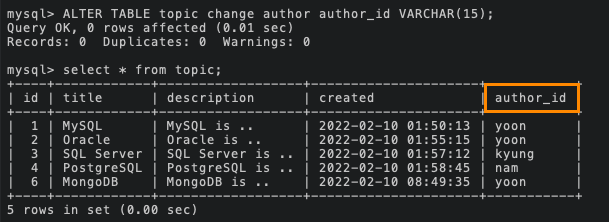
ALTER TABLE [테이블명] CHANGE [기존 컬럼명] [변경할 컬럼명] [기존 자료형];
: 컬럼명 변경
이때, 마지막에 기존 자료형까지 기입해주어야 한다.
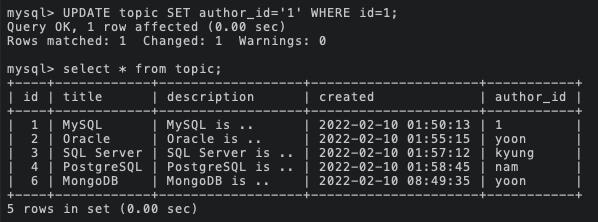
그리고 저번 게시글 UPDATE 부분을 참고하여 이렇게 데이터를 수정해주었다. 나머지 4개의 데이터도 수정해줄 것이다.
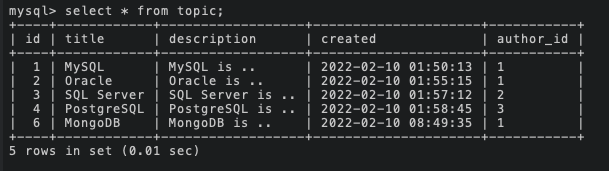
테이블 준비 끝!
LEFT JOIN
SELECT * FROM [테이블명] LEFT JOIN [조인할 테이블명] ON [테이블명].[컬럼명] = [테이블명].[컬럼명];
: 이렇게 topic의 author_id와 author의 id 값으로 LEFT JOIN 하여 원하던대로 데이터를 한 눈에 볼 수 있게 되었다.
(ON 뒤에는 기준이 옴)

✔️ JOIN - 관계형 데이터베이스의 🌼
우선 위에서 LEFT JOIN으로 테이블은 구성해 보았으나,,
영 author_id와 id는 꼴보기가 싫다.
SELECT [보고싶은 컬럼명들을 ,로 구분하여 나열] FROM [테이블명] LEFT JOIN [조인할 테이블명] ON [테이블명].[컬럼명] = [테이블명].[컬럼명];
: 보고싶은 컬럼만 선별해 LEFT JOIN
이때, id는 topic에도, author에도 존재하므로 topic.id와 같이 명시해주어야 한다.

아 뭔가 아쉽다, 저 id가 topic의 id인지,, author의 id인지 모르겠다,, 면?
SELECT topic.id AS topic_id, ...(생략);
: 이렇게 AS를 활용해 명시하고 싶은 컬럼명을 적어준다.

이렇게 테이블을 분리한 이유는 이뿐만이 아니다.
추후 댓글에 관련된 comment라는 테이블이 생겼고, topic 테이블의 yoon의 profile을 수정해야 한다면
이는 topic만의 문제가 아니라 comment 테이블 또한 수정해줘야 하는 대공사이다.
관계형 테이블은 이를 보완한다.
✔️ 인터넷과 데이터베이스
인터넷이 동작하기 위해서는 컴퓨터는 최소한이면서 최대한 몇대가 필요할까?
🙋🏻♀️: 바로 두 대이다.
인터넷은 간단하게 말해 컴퓨터들 간의 사회이다.
컴퓨터들끼리 데이터를 요청하고, 응답할 수 있게 된 것이다.
우선, server, client는 인터넷을 이해하는 핵심 열쇠이다.
 이런식으로 정보를 요청하고 응답해준다.
이런식으로 정보를 요청하고 응답해준다.
MySQL을 설치하면 두 개의 프로그램을 동시에 설치해야 한다.
하나는 database client, 하나는 database server이다.

database server에는 실제로 데이터가 저장되고,
database client는 이를 통해 서버에 접속할 수 있는 역할을 수행한다.
database server를 직접 다루는 것처럼 보였지만 어떤 형태로든 database client를 반드시 거쳐 사용할 수 있었다.
그렇다면 database client는 도대체 뭐였는지?
바로 mysql -uroot 이렇게 접속하여 사용하였던 바로 이 프로그램이 database client 중 하나였다.
접속하면 MySQL Monitor라고 나오는데 이는 명령어를 통해 database server를 제어하는 프로그램이다.
또 다른 database client는 MySQL workbench이다.
포스트에서는 이것을 사용하진 않았지만 조금 더 그래픽한 화면으로 사용할 수 있다. (마치 엑셀처럼)
