
3주 차 📢
파이썬이란?
파이썬은 배우기 쉽고, 강력한 프로그래밍 언어입니다. 효율적인 자료 구조들과 객체 지향 프로그래밍에 대해 간단하고도 효과적인 접근법을 제공합니다. 우아한 문법과 동적 타이핑(typing)은, 인터프리터 적인 특징들과 더불어, 대부분 플랫폼과 다양한 문제 영역에서 스크립트 작성과 빠른 응용 프로그램 개발에 이상적인 환경을 제공합니다.
예제 💻
- Python 코드 예제
def oddeven(num):
if num % 2 == 0:
return True
else:
return False
result = oddeven(20)
- Javsscript 코드 예제
function solution(num) {
var answer = '';
if(num % 2 == 0){
return 'Even';
}else {
return 'Odd';
}
return answer;
}
파이썬이 코드문은 간단하고 직관적인 언어인 것을 볼 수 있다!
웹스크래핑(크롤링)
크롤링 기본 세팅 💻
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################
- 항상 정확하지는 않으나, 크롬 개발자도구를 참고할 수도 있습니다.
-
원하는 부분에서 마우스 오른쪽 클릭 → 검사
-
원하는 태그에서 마우스 오른쪽 클릭
-
Copy → Copy selector로 선택자를 복사할 수 있음
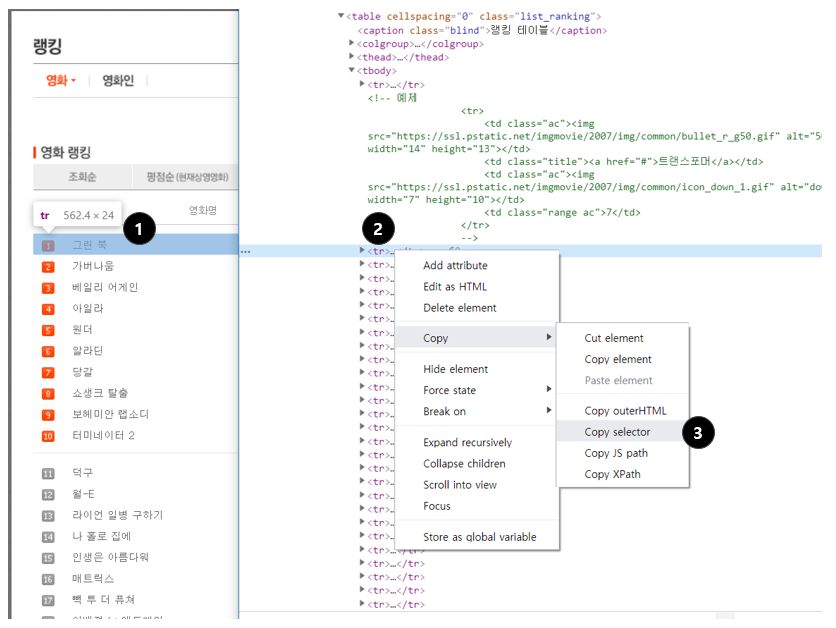
-
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text)
DB 란?
Database에는, 크게 두 가지 종류가 있습니다.

👉 RDBMS(SQL)
행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사합니다. 데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 어려울 것입니다. 그러나, 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이할 수 있습니다.
ex) MS-SQL, My-SQL 등
👉 No-SQL
딕셔너리 형태로 데이터를 저장해두는 DB입니다. 고로 데이터 하나 하나 마다 같은 값들을 가질 필요가 없게 됩니다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있습니다.
ex) MongoDB
요새는 Cloud 형태로 제공해주는 곳들이 많다! 그래서 최신 클라우드 서비스인 mongoDB Atlas를 사용해본다고 한다
- pymongo 기본 코드
from pymongo import MongoClient
client = MongoClient('여기에 URL 입력')
db = client.dbsparta- pymongo 코드 요약
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})- 웹스크래핑 결과 저장하기
예제 💻
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.55vah.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = a_tag.text # a 태그 사이의 텍스트를 가져오기
star = movie.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
doc = {
'rank': rank,
'title': title,
'star': star
}
db.movies.insert_one(doc)퀴즈 💻
- 가버나움'의 평점과 같은 평점의 영화 제목들을 가져오기
헷갈렸던 퀴즈 문제임!!!!
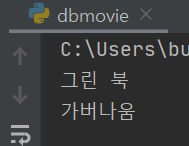
movie = db.movies.find_one({'title':'가버나움'})
star = movie['star']
movies = list(db.movies.find({'star':star}))
for movie in movies:
print(movie['title'])숙제 💻
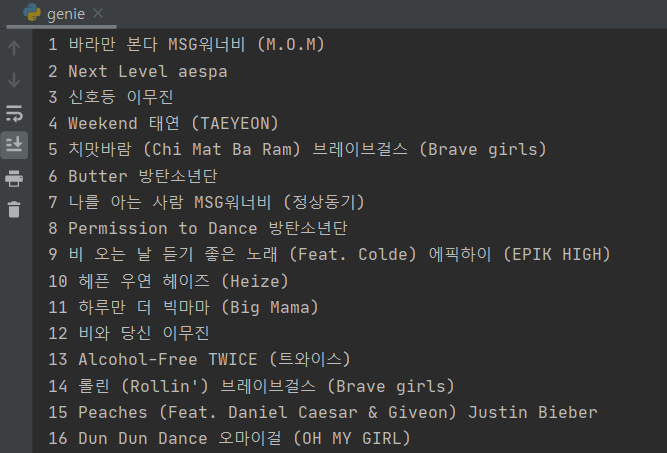
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
genies = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for genie in genies:
title = genie.select_one('td.info > a.title.ellipsis').text.strip().strip("19금").lstrip()
rank = genie.select_one(' td.number').text[0:2].strip()
artist = genie.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)여기서❗title에서 .text.strip()만 하게 되면 15번의 저스틴비버 peaches 옆에 19금이라는 문자열이 떠서 자꾸 빈칸이 생성이 된다.
.strip("19금")문자열을 제외하고.lstrip()를 사용하여 왼쪽의 여백을 제외하니 제대로 출력이 되었다.
알듯 말듯 하다😐
