
왜..?
사실 자기소개서를 크롤링할 일이 거의 없을거 같긴 한데, 아무튼 나는 프로젝트에 사용될 데이터가 자기소개서라 일단 최대한 데이터를 가지고 와야 했기 때문에 잡코리아와 링커리어와 같은 사이트에서 합격자소서를 크롤링 해보기로 했다. 사실 다른 사이트도 이런 방식으로 크롤링을 많이 하기 때문에 알아두면 좋을 것 같다.
url 크롤링
일단 처음으로 든 생각은 자기소개서를 검색하는 창과 자기소개서가 있는 창이 다른지에 대한 유무였다. 네이버처럼 창이 같은데 이벤트로 인해서 새로 태그가 생기는 경우가 있기 때문에 이 경우에는 크롤링 방식을 완전 다르게 해야되기 때문이다. 다행히도 자기소개서를 검색하는 창과 있는창의 url이 달랐다.

그래서 일단 각 자기소개서 정보가 있는 url을 가져와보기로 했다. 그러기 위해서는 각 페이지에 있는 자소서 li 태그를 찾아서 거기 안에 있는 a태그의 href 정보를 가져오는게 제일 편했다. 페이지의 끝을 한번 보니 368페이지가 마지막이었기 때문에 for문으로 모든 태그를 들고와서 배열에 링크를 넣어주는 작업을 진행했다.
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome("C:/Program Files/chromedriver/chromedriver")
for i in range(1,369):
driver.get("https://www.jobkorea.co.kr/starter/passassay?schTxt=&Page="+str(i))
# page에 따른 경로
paper_list = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[5]/ul")
# 자기소개서 목록을 담아놓은 태그
driver.implicitly_wait(3)
urls = paper_list.find_elements(By.TAG_NAME,'a') # 거기에서 a태그만 가져온다
for url in urls:
if 'selfintroduction' in url.get_attribute('href'):
#가끔씩 이상한 경로가 섞여들어와서 제외하고 진행했다.
pass
else:
array.append(url.get_attribute('href')) # href안에 있는 경로를 array에 추가해준다.
array = list(set(array))
for content in array: # array를 파일에 저장해준다
f.write(content+'\n') 로그인 코드 작성
이제 url을 가지고왔으니 그 url내에 있는 자기소개서 태그를 찾아서 저장만 해주면 된다. 그런데 url에 들어가서 드래그를 조금 해보니 로그인을 해야지 볼 수 있다는 창이 뜨면서 로그인 modal이 떠버리는 것이었다.
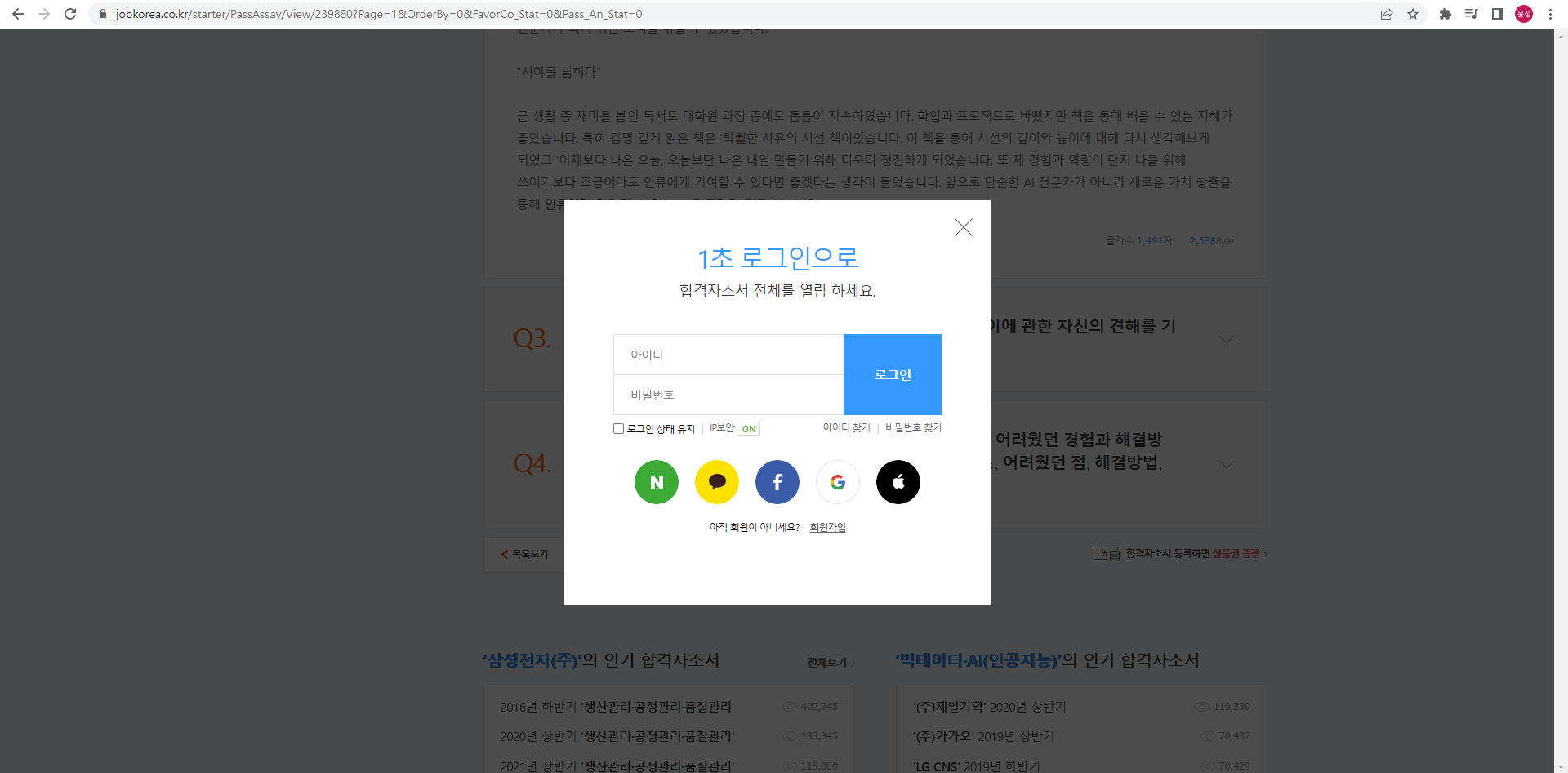
이거 때문에 문항이 많은 자기소개서는 전부 크롤링이 안되고 오류가 떠버리는 상황이 발생했다. 그래서 처음에 크롤링을 하기전에 chromedriver에 로그인을 먼저 해놓고 크롤링을 해야겠다는 생각이 들었다. 그렇게 할려면 일단 로그인을 자동으로 해주는 코드를 작성해야했다.
from selenium import webdriver
from selenium.webdriver.common.by import By
def login_protocol(driver:webdriver.Chrome):
# 로그인해야지 로그인창때문에 크롤링 멈추는거 막을 수 있음
driver.get("https://www.jobkorea.co.kr/")
driver.find_element(By.XPATH,"/html/body/div[5]/div/div[1]/div[1]/ul/li[1]/button").click()
# 로그인하기 버튼 누르기
driver.find_element(By.ID,"lb_id").send_keys("id 입력하면됨")
driver.find_element(By.ID,"lb_pw").send_keys("pw 입력하면됨")
driver.find_element(By.XPATH,"/html/body/div[5]/div/div[1]/div[1]/ul/li[1]/div/form/fieldset/div[1]/button").click()
# 로그인 버튼 누르기
driver.implicitly_wait(3)
driver.find_element(By.ID,"closeIncompleteResume")
# 나는 잡코리아에 자소서를 다 안썼기 때문에 이 모달이 로그인할때마다 떠서 그냥 모달 꺼주는 용도임
driver.implicitly_wait(3)
print("login success")코드는 그렇게 어렵지 않다 태그 구조가 고정이었기 때문에 그냥 XPATH를 이용해서 크롤링했다.
자기소개서 가져오기
드디어 자기소개서만 가지고 오면 된다. 특이하게 잡코리아는 질문 태그는 dd, 답변 태그는 df로 태그 이름을 커스텀해놨다.
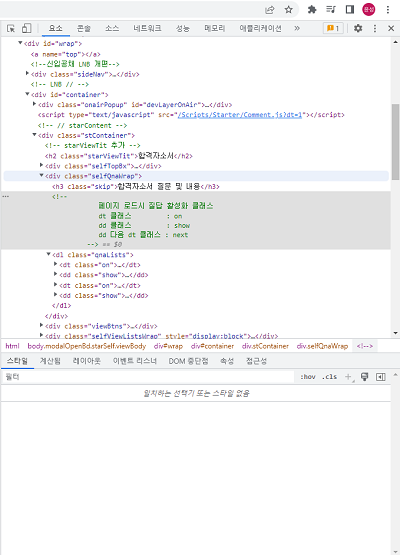
그리고 또 신기한거는 질문에 클릭을 하면 답변 태그가 펼쳐지는 구조인데 펼쳐질때와 안펼쳐질 때의 클래스 이름이 달라졌다.
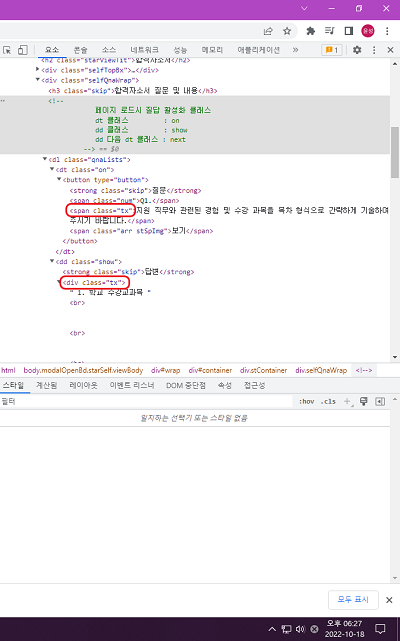
그래서 안펼쳐져 있는 경우에는 .text가 아무것도 나오지 않을테니깐 그 경우에만 질문 태그를 눌러주고 다시 크롤링하는 방식으로 진행할려고 했다.
paper = driver.find_element(By.CLASS_NAME,"qnaLists")
driver.implicitly_wait(3)
questions = paper.find_elements(By.TAG_NAME,'dt')
# 질문 목록에 있는 태그 다 들고오기
driver.implicitly_wait(3)
# next on -> tx
# show -> tx
print("question")
for index in questions:
question = index.find_element(By.CLASS_NAME,'tx')
if question.text=="": #태그가 펼쳐지지 않아서 크롤링이 안되는 경우
index.find_element(By.TAG_NAME,'button').click() # 펼쳐준다
question = index.find_element(By.CLASS_NAME,'tx') # 다시 크롤링
print(question.text)
else:
print(question.text) # 이미 펼쳐져 있는 경우
driver.implicitly_wait(3)
answers = paper.find_elements(By.TAG_NAME,'dd')
driver.implicitly_wait(3)
print('answer')
for index in range(len(answers)):
answer =answers[index].find_element(By.CLASS_NAME,'tx')
if answer.text == "": #태그가 펼쳐지지 않아서 크롤링이 안되는 경우
questions[index].find_element(By.TAG_NAME,'button').click() # 펼쳐준다
answer =answers[index].find_element(By.CLASS_NAME,'tx') # 다시 크롤링
print(answer.text) # 이미 펼쳐져 있는 경우전체코드
전체코드는 자기소개서뿐만 아니라 지원자가 낸 회사, 지원자 스펙까지 크롤링 해온 코드이다.
# jobkorea.py
from selenium import webdriver
from selenium.webdriver.common.by import By
def link_crawl(driver:webdriver.Chrome):
array= []
f = open("C://data/jobkorea_link.txt",'w')
for i in range(1,369):
driver.get("https://www.jobkorea.co.kr/starter/passassay?schTxt=&Page="+str(i))
paper_list = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[5]/ul")
driver.implicitly_wait(3)
urls = paper_list.find_elements(By.TAG_NAME,'a')
for url in urls:
if 'selfintroduction' in url.get_attribute('href'):
pass
else:
array.append(url.get_attribute('href'))
array = list(set(array))
for content in array:
f.write(content+'\n')
f.close()
def login_protocol(driver:webdriver.Chrome): # 로그인해야지 로그인창때문에 크롤링 멈추는거 막을 수 있음
driver.get("https://www.jobkorea.co.kr/")
driver.find_element(By.XPATH,"/html/body/div[5]/div/div[1]/div[1]/ul/li[1]/button").click()
driver.find_element(By.ID,"lb_id").send_keys("id")
driver.find_element(By.ID,"lb_pw").send_keys("pw")
driver.find_element(By.XPATH,"/html/body/div[5]/div/div[1]/div[1]/ul/li[1]/div/form/fieldset/div[1]/button").click()
driver.implicitly_wait(3)
driver.find_element(By.ID,"closeIncompleteResume")
driver.implicitly_wait(3)
print("login success")
def self_introduction_crawl(driver:webdriver.Chrome,file_url):
print("current URL : "+ file_url)
driver.get(file_url)
user_info = driver.find_element(By.XPATH,'//*[@id="container"]/div[2]/div[1]/div[1]/h2')
company = user_info.find_element(By.TAG_NAME,'a')
print(company.text) # 지원회사
season= user_info.find_element(By.TAG_NAME,'em')
print(season.text) # 지원시기
specification=driver.find_element(By.CLASS_NAME,'specLists')
spec_array = specification.text.split('\n')
print(spec_array[:-2]) #스펙
paper = driver.find_element(By.CLASS_NAME,"qnaLists")
questions = paper.find_elements(By.TAG_NAME,'dt')
print("question")
for index in questions:
question = index.find_element(By.CLASS_NAME,'tx')
if question.text=="":
index.find_element(By.TAG_NAME,'button').click()
question = index.find_element(By.CLASS_NAME,'tx')
print(question.text)
else:
print(question.text) # 자소서 질문 모아놓은 리스트
driver.implicitly_wait(3)
answers = paper.find_elements(By.TAG_NAME,'dd')
driver.implicitly_wait(3)
print('answer')
for index in range(len(answers)):
answer =answers[index].find_element(By.CLASS_NAME,'tx')
if answer.text == "":
questions[index].find_element(By.TAG_NAME,'button').click()
answer =answers[index].find_element(By.CLASS_NAME,'tx')
print(answer.text) # 자소서 답변 모아놓은 리스트# jobkorea_protocol.py
import jobkorea
from selenium import webdriver
from selenium.webdriver.common.by import By
file = open('C://data/jobkorea_link.txt','r')
driver = webdriver.Chrome("C:/Program Files/chromedriver/chromedriver")
jobkorea.login_protocol(driver=driver)
while True: # 7354개
file_url = file.readline()
if file_url == "":
break
jobkorea.self_introduction_crawl(driver=driver,file_url=file_url)느낀점
크롤링을 할때는 최대한 패턴을 찾아서 작게 과정을 쪼개서 진행하는게 조금 느릴수도 있겠지만 코드를 작성하는데 훨씬 효율적이고 빠르다는 것을 깨달았다. 이런 방식으로 크롤링을 자주 구현하니 알아두면 좋을 듯하다.

6개의 댓글

크롤링에 입문하면서 딱 이런 내용이 필요했는데 감사합니다 ㅠㅠ
너무 기초적인 질문일 거 같아 죄송한데 혹시 Message: no such element: Unable to locate element: {"method":"xpath","selector":"//*[@id="container"]/div[2]/div[1]/div[1]/h2"}라는 에러가 뜨는데, 사용자별(혹은 크롬 버전별)로 구조가 조금씩 달라서 이런 일이 발생할 수도 있나요?
좋은 글 올려 주셔서 감사합니다. 좋은 하루 되세요 :)
좋은 글 정말 감사합니다! 그런데 오늘 실행해 봤더니, driver.close() 방식으로 닫히지 않는 창이 하나 떠서 크롤링하지 못하고 있습니다.... 혹시 해결법 아시는지 궁금합니다!