
데이터가 부족해..
잡코리아에 있는 데이터가 약 7400개 정도 있었는데 데이터가 더 많이 필요했기 때문에 링커리어도 크롤링해서 자기소개서를 크롤링 해보기로 했다. 방식은 역시 잡코리아와 동일하게 자기소개서를 검색하는 창에서 자기소개서가 있는 창으로 넘어가는 url을 크롤링 한 후 각 url마다 자기소개서를 가져오는 방식으로 진행할 예정이다.
url 크롤링
링커리어는 로그인을 안해도 크롤링을 할 수 있었기 때문에 딱히 로그인을 위한 코드를 작성할 필요가 없었다.
https://linkareer.com/cover-letter/search?page=2&tab=all url 구조를 보니
"page=" 쿼리문만 바꿔주면서 마찬가지로 a태그의 href 속성을 들고오면 되겠다고 생각했다.
from selenium import webdriver
from selenium.webdriver.common.by import By
def url_crawl(driver:webdriver.Chrome):
url_list = []
f=open("C://data/linkcareer_link.txt",'w')
for page in range(1,573): #페이지가 572페이지까지 존재함
url = "https://linkareer.com/cover-letter/search?page="+str(page)+"&tab=all"
driver.get(url)
driver.find_element(By.XPATH,"/html/body/div[1]/div[1]/div/div[4]/div[2]/div/div[3]/div[1]")
driver.implicitly_wait(3)
url_tag = driver.find_elements(By.TAG_NAME,'a')
for tag in url_tag:
url_name = tag.get_attribute('href')
if "cover-letter" in url_name and "search" not in url_name:
# 마찬가지로 잘못된 링크도 같이 크롤링됐기 때문에 자소서 링크만 저장할 수 있도록 했다.
print(url_name)
url_list.append(url_name)
driver.close()
for content in list(set(url_list)): # 중복 제거
f.write(content+"\n")
f.close()자기소개서 가져오기
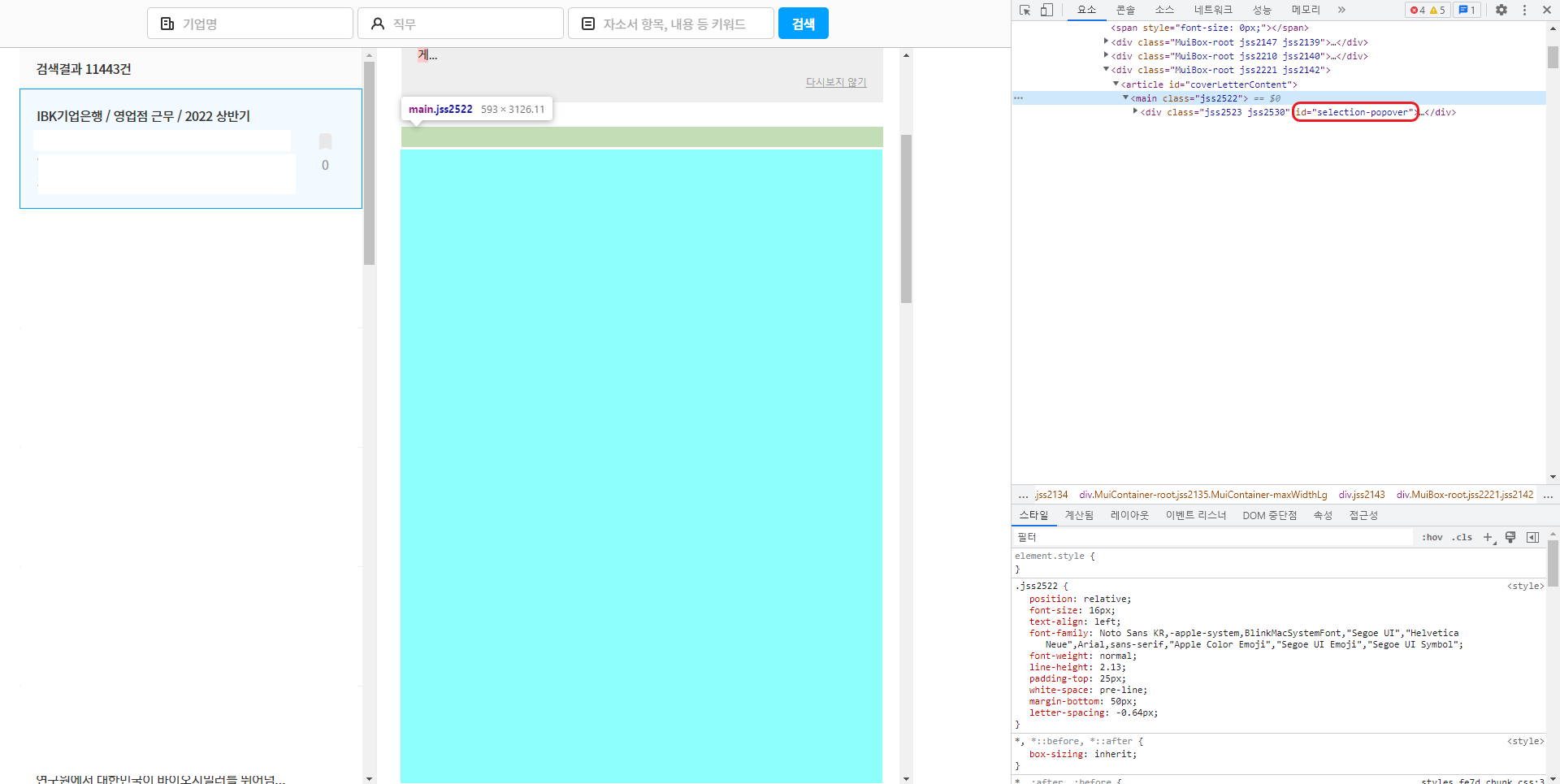
진짜 다행히도 자기소개서가 들어가있는 태그가 id로 구분이 되어있었다. 그냥 id만 가지고 오면 끝이었다. 그안에 태그없이 text로 들어가있었기 때문에 다른 전처리 필요없이 바로 가져오면 됐다.
from selenium import webdriver
from selenium.webdriver.common.by import By
def self_introduction(driver:webdriver.Chrome,url):
person = {}
driver.get(url)
content=driver.find_element(By.ID,"coverLetterContent")
print(content.text)
return person전체코드
잡코리아와 마찬가지로 지원자 정보와 스펙을 같이 가져와야했기 때문에 코드를 추가했다. 그리고 지원자 정보, 스펙, 자기소개서를 각각 key로 하는 person 딕셔너리로 저장해서 dataframe으로 저장하기 쉽도록 자료구조를 설정했다.
# linkareer.py
from selenium import webdriver
from selenium.webdriver.common.by import By
def url_crawl(driver:webdriver.Chrome):
url_list = []
f=open("C://data/linkcareer_link.txt",'w')
for page in range(1,573):
url = "https://linkareer.com/cover-letter/search?page="+str(page)+"&tab=all"
driver.get(url)
driver.find_element(By.XPATH,"/html/body/div[1]/div[1]/div/div[4]/div[2]/div/div[3]/div[1]")
driver.implicitly_wait(3)
url_tag = driver.find_elements(By.TAG_NAME,'a')
for tag in url_tag:
url_name = tag.get_attribute('href')
if "cover-letter" in url_name and "search" not in url_name:
print(url_name)
url_list.append(url_name)
driver.close()
for content in list(set(url_list)):
f.write(content+"\n")
f.close()
def self_introduction(driver:webdriver.Chrome,url):
person = {}
driver.get(url)
info = driver.find_element(By.XPATH,'//*[@id="__next"]/div[1]/div[4]/div/div[2]/div[1]/div[1]/div/div/div[2]/h1')
specification=driver.find_element(By.XPATH,'//*[@id="__next"]/div[1]/div[4]/div/div[2]/div[1]/div[1]/div/div/div[3]/p')
content=driver.find_element(By.ID,"coverLetterContent")
person['info'] = info.text # 지원자 정보
person['specification'] = specification.text # 지원자 스펙
person['self_intro'] = content.text # 지원자 자소서
print(person)
return person# linkareer_total.py
from selenium import webdriver
from selenium.webdriver.common.by import By
import linkareer
url="C://data/linkareer_link.txt"
driver = webdriver.Chrome("C:/Program Files/chromedriver/chromedriver")
# linkcareer.url_crawl(driver=driver)
f=open(url,'r')
while True: # 11437
txt_link = f.readline()
if txt_link=="":
break
person = linkcareer.self_introduction(driver=driver,url=txt_link)
driver.close()
f.close()만약에 데이터가 그렇게 많이 필요없다면 링커리어에서 크롤링하는게 더 편하고 데이터 양이 많아서 굳이 하나만 크롤링하라고 하면 링커리어를 할 것 같다

소개를 어떻게 한줄로 해요..