compile?
주어진 언어로 작성된 컴퓨터 프로그램을 다른 언어의 동등한 프로그램으로 변환하는 프로세스이다.
보통 high-level 프로그래밍 언어를 실행 프로그램으로 만들기 위한 lower level언어(어셈블리어,기계어)로 바꾸는데 사용한다.
원래의 문서(high-level)를 소스 코드 혹은 원시 코드라고 부름
출력된 문서(low-level)를 목적 코드라고 부름
Compiler의 조건
-
옮김의 과정에서 프로그램의 뜻이 보존되어야 함
즉, 입력받은 프로그램의 의미를 충실히 따라야함
-
입력으로 들어온 프로그램을 실용적으로 개선해야 함
컴파일 과정
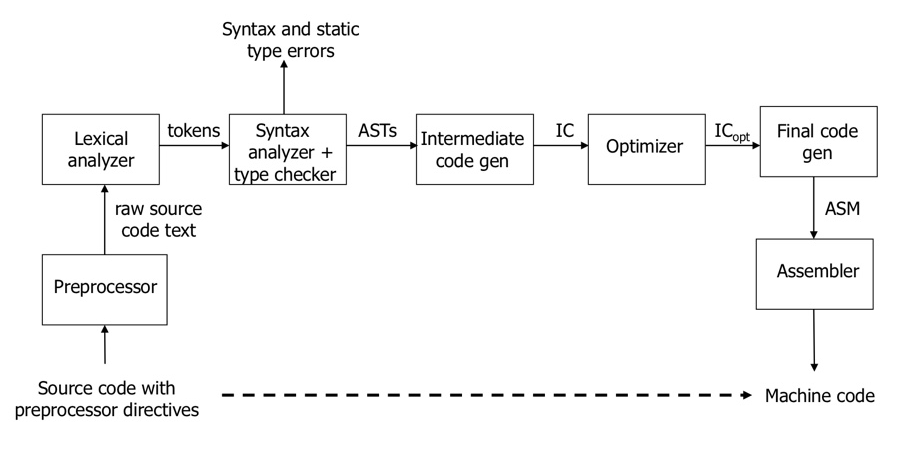
컴파일러의 첫 번째 단계는 소스 코드를 정규 문법 (regular grammar)에 따라 토큰 (token)으로 분류하는 어휘 분석 또는 스캐닝 (scanning)이다.
💡 예를 들어, “Hello world"라는 문장에서 'H', 'e', 'l', 'l', 'o'을 따로 놓으면 어떠한 의미도 없지만, "Hello"라는 하나의 조각으로 보면 의미를 갖게 된다.
용어 정리
-
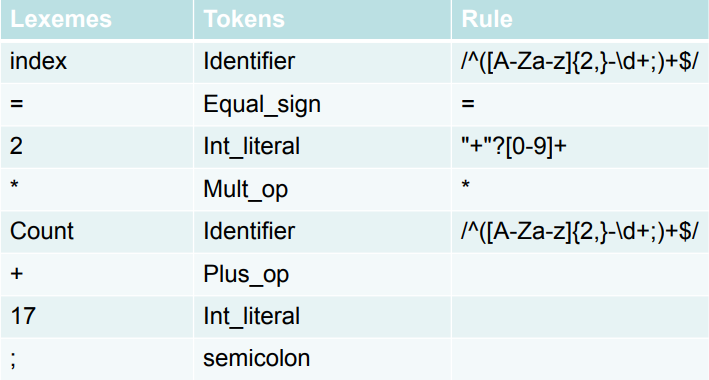
lexeme(어휘 항목) : 소스 코드에 존재하는 의미있는 문자열, 식별자, 숫자. 키워드 등을 의미
→ 문법상의 최소한의 단위(token에 있는 category에 상응하는 charactor들의 sequence)
-
token(토큰): token이름과 속성값으로 구성되는 데이터쌍으로써, 각 token은 token의 pattern에 부합하는 lexeme를 갖는다.
-
pattern(패턴) : token이 lexeme를 서술하는 규칙으로써, 정규문법에 따라 표현된다.
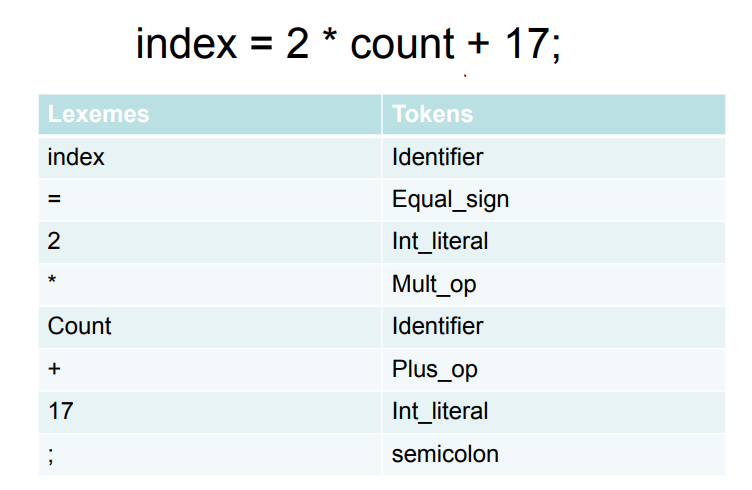
lexeme는 token의 예시라고 생각하면 되고,
token은 카테고리라고 생각하면 된다. 그리고 lexeme와 token을 잇는 규칙이 pattern이다
->pattern = lexeme(index,indentifier)
예시
아래의 그림의 코드가 있다고 생각해보자
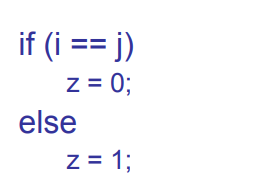
소스 코드상으로는 저렇게 보이는 코드지만,\tif(i==j)\n\t\tz=0;\n\teles\n\t\tz=1; 이런 식으로 이루어져있다. 여기서 우리가 해야할 일은 특정한 문법으로 나누어줘야 하는 것이다.
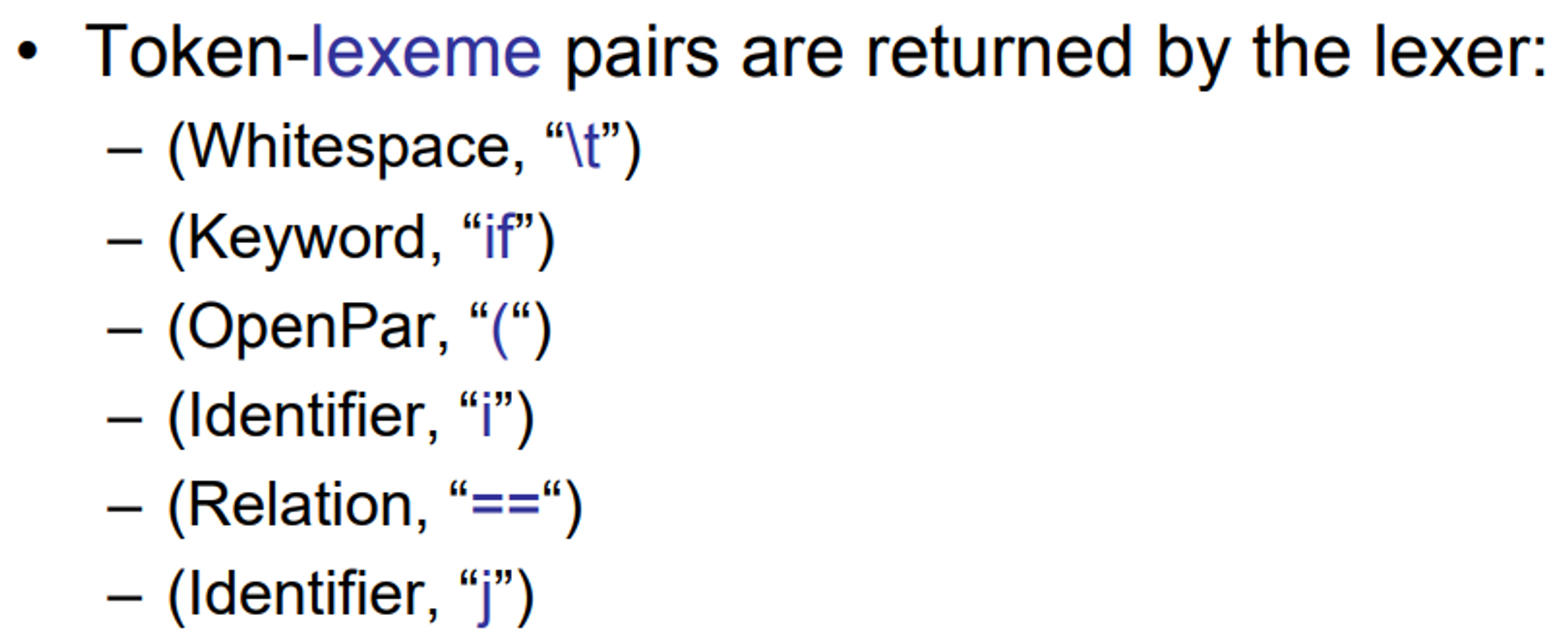
이런 패턴이 존재한다면 위의 식을 패턴에 맞게 나타낼 수 있다. 이러한 작업을 하기 위해서 token-lexeme 패턴이 필요한 것이다.
즉, 우리가 쓴 코드 한줄한줄에 대해 의미 단위로 끊어주는 역할이라고 생각하면 편하다. 여기서는 문법에 대한 오류는 잡아내지 않는다.(parsing만 해준다.)
정규 표현식
지금까지는 역할이 고정된 문자(keyword)를 정의했다. 하지만 x=2 에서 2가 문자인지 정수인지 어떻게 구분할 수 있을까? 이것을 구분해주기 위해 정규표현식을 사용한다.
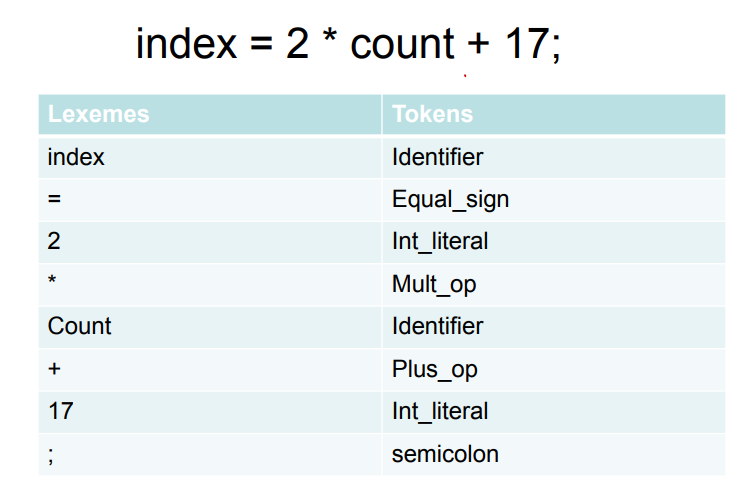
여기서 int_literal과 같이 정수인지 문자인지는 어떻게 구분할까?
정규 표현식은 수학적으로 정의된 기호와 연산을 이용하여 언어를 귀납적으로 정의하기 위한 방법이다. 정규 표현식에서 정의되는 연산은 접합, 클린 클로저, OR이 있으며, 피연산자는 기호의 유한 집합인 알파벳이나 기호가 된다.
말이 어렵게 되어있지만 그냥 우리가 아는 문자열 정규식이랑 동일하다. 정규식안에는 각 lexeme가 가져야하는 규칙이 들어가 있고 그 규칙을 벗어나는 경우에는 에러를 발생시킨다.