1.Oracle data type
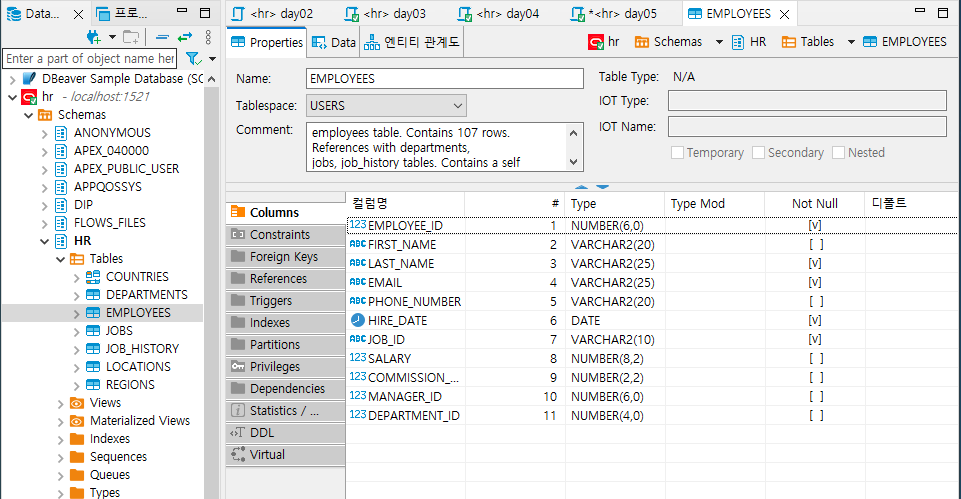
(1) 데이터 타입
- 데이터 타입 : 컬럼이 저장되는 데이터 유형
- 기본 데이터 타입 : 문자형, 실수, 소수, 자료형 등 여러 데이터를 식별
(2) 문자 데이터 타입

- char 보다는 vachar2
- vachar2는 가변길이로 저장된다.
- 길이값은 본인 선택
[가변길이]
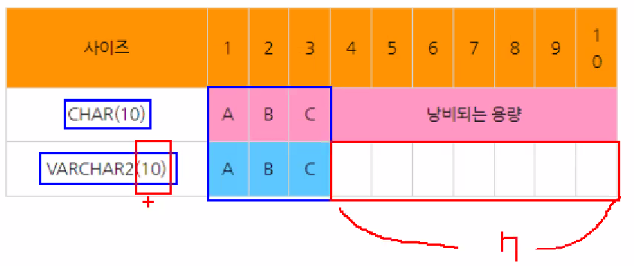
-> VACHAR2 은 메모리를 효율적으로 사용할 수 있음
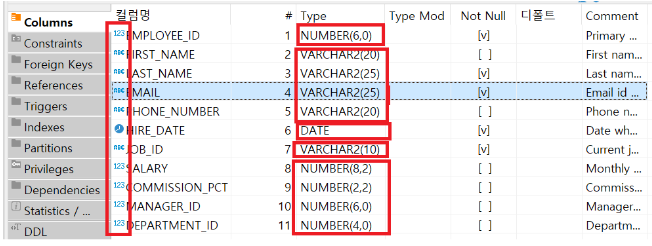
(3) 숫자형 데이터 타입

- 대부분 NUMBER형을 사용한다.
- P는 소수점을 포함한 전체 자릿수를 의미하고, S는 소수점 자릿수를 의미한다.
- NUMBER는 가변 숫자 이므로 P와 S를 입려하지 않으면 저장 데이터의 크기에 맞게 자동으로 조절 된다.
[연습]
[입력값] [타입] [저장되는 값]
__________________________________________________________________________
123.89 NUMBER 123.89
123.89 NUMBER(3) 124 (자연스럽게 반올림)
123.89 NUMBER(3,2) 오류
123.89 NUMBER(4,2) 오류
123.89 NUMBER(5,2) 123.89
123.89 NUMBER(6,1) 123.9
(4) 날짜 데이터 타입

- 일반적으로는 날짜 데이터 타입은 DATE 타입이다.
(5) LOB 데이터 타입 => ORACLE

- 서버에 DB만 대용량 올라가는 데 DB를 건든다는 건 큰일 -> 데이터타입만 바꿔주고 커뮤니케이션
- LOB란, Large Object의 약자로 대용량 데이터를 처리할 수 있는 데이터 타입이다.
2. 명령어
(1) 테이블 명령어DDL (Data Definition Language)
- 새로운 명령어
- 데이터의 구조를 정의하기 위한 테이블 생성, 삭제와 같은 명령어
create : 테이블 생성
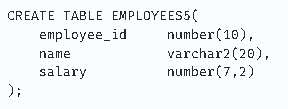
drop : 테이블 삭제

alter : 테이블 수정

truncate : 테이블에 있는 모든 데이터 삭제
- 데이터를 삭제하거나 암호화 시키면 데이터 흔적 보관가능
- 기능 테스트를 위한 쓰레기 데이터들이 많음 지울때 사용하면 좋음
(2) 데이터 조작어 (DATA Manipulaion Language)
- 데이터 조회 및 변형을 위한 명령어
select : 데이터 조회
insert : 데이터 입력
insert into 테이블명 values(값1,값2,...) -> 전체 컬럼 insert into 테이블명 (컬럼1, 컬럼2 ,...)values(값1,값2,...) -> 특정 컬럽

update : 데이터 수정
update 테이블명 set 컬럼1 = 값1,컬럼2 = 값2, ... where 조건..;

delete : 데이터 삭제
delete 테이블명 where 조건;

(3) drop vs truncate vs delete
① drop
drop table 테이블명;- 존재 자체가 삭제
- 로그를 안 남김
② truncate
- 데이터만 통 삭제
- truncate는 테이블이 삭제x -> 레코드들을 제고하는 명령어
- 테이블을 drop 했다가, create 하는 작업
- 모든 행을 삭제하는 데는 가장 효율적이고 빠른 작업
- 로그를 안 남김
③ delete
- delete는 조건에 해당하는 것만 지울수도 있고 전체를 지울 수도 있는 이유가 한 줄 한 줄 삭제하기 때문 : 시간이 오래걸림
- 로그를 남김
(4) commit 과 rollback
① commit
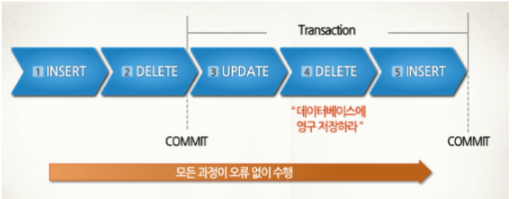
- 모든 작업을 정상적으로 처리하겠다고 확정하는 명령어
- 트랜잭션의 처리 과정을 데이터베이스에 반영하기 위해서 변경된 내용을 모두 영구 저장한다.
- commit을 수행하면, 하나의 트랜잭션 과정을 종료하게 된다.
- transaction 작업내용을 실제 db에 저장
- 모든 사용자가 변경한 데이터의 결과를 볼 수 있다.
- (select, insert, update, delete) -> 영구적으로 저장
<오토커밋 - 기본값>
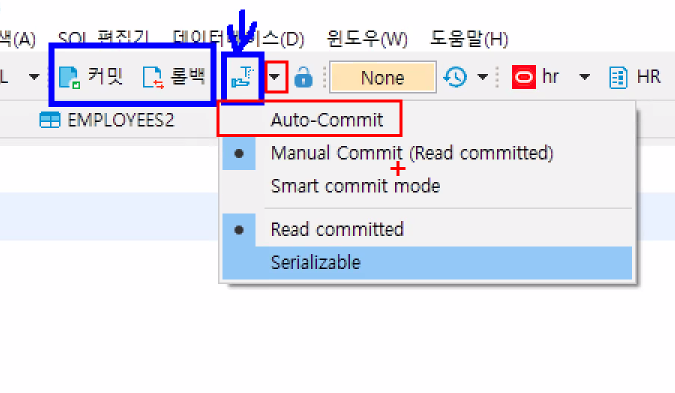

<오토커밋 - 수동값>
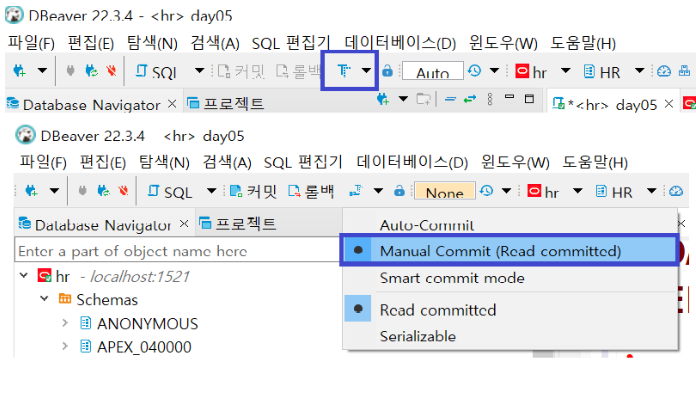
② rollback
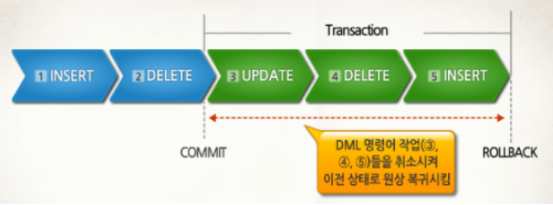
-작업 중 문제가 발생했을 때, transaction의 처리 과정에서 변경사항을 취소하고, 트랜잭션과정을 종료시킨다.
-
transaction으로 인한 하나의 묶음처리가 시작되기 이전의 상태로 되돌린다.
-
이전 commit한 곳까지만 복구 가능
-
transaction 작업 중 하나라도 문제가 발생하면, 모든 작업을 취소해야 하기 때문에 하나의 논리적인 작업 단위로 구성해 놓아야 한다.
-
문제가 발생하면 논리적인 작업의 단위를 모두 취소해 버리면 되기 때문이다.
-
drop, truncet : 무조건 자동 commit 롤백 안됨
-
delete : 수동 commit 가능 롤백 가능
명령어의 장점 : commit 과 롤백의 이유
- 데이터 무결성이 보장된다.( 삭제되어선 안되는 데이터가 삭제되거나 인서트 하면 안되는데 인서트 -> 값을 해침)
- 논리적으로 연관된 작업을 그룹화할 수 있다.
자동 rollback 되는 경우
- 비정상적인 종료 (갑자기 pc 꺼짐)
자동 commit 되는 경우
- DDL문 (create, alter, drop, truncate)
- DCL문 (grant, revoke) 사용 권한
- insert, update, delete작업 후 commit하지 않고 오라클을 정상종료 시에 commit명령어 입력하지 않아도 정상 commit 후 오라클 종료(물어보지 않고 자동으로)
3. 기본키와 외래키
(1) 컬럼속성(무결성 제약조건)
- 무결성 제약 조건의 예
"null값이 오면 안된다는 조건, employee id값은 중복값이 할당되지 않는다."
not null : 널값이 입력되지 못하게 하는 조건

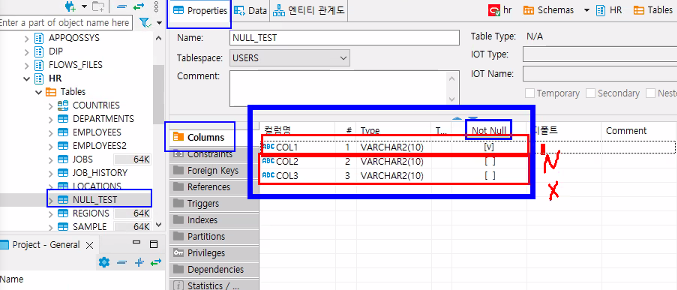
unique : 중복된 값이 입력되지 못하게 하는 조건
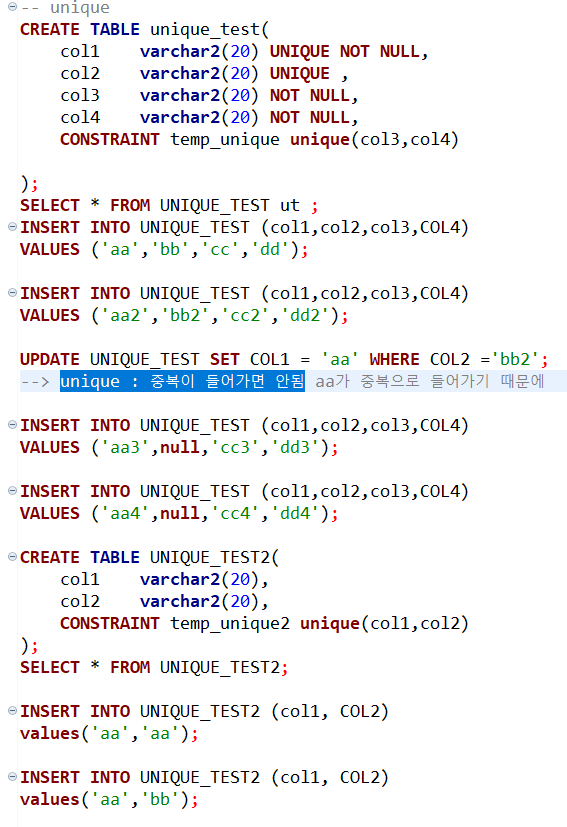
💡 예시 1

💡 예시 2

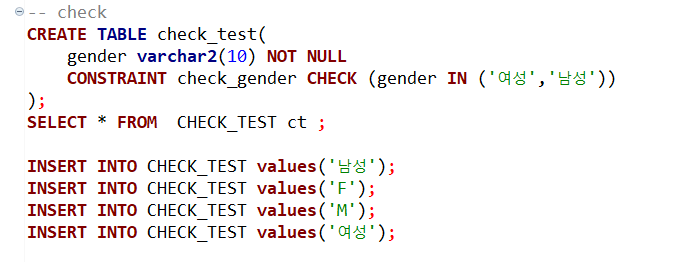
check : 주어진 값만 허용하는 조건
primary key (기본키) : not null + unique + index의 의미
foreign key(외래키) : 다른 테이블의 필드(컬럼)를 참조해서 무결성을 검사하는 조건
(2) 기본키 (primary key)
- 기본키 역시 기본적인 제약조건들은 테이블을 생성할 때 같이 정의한다.
- 테이블당 하나만 정의 가능하다.
- 기본키, 식별자, pk,등으로 불리고 있다.
- not null + unique + index 까지 정의 (아무곳에나 정의하면 안됨)
- index를 사용한다는 것 : 검색 시 시간을 엄청나게 줄여줌
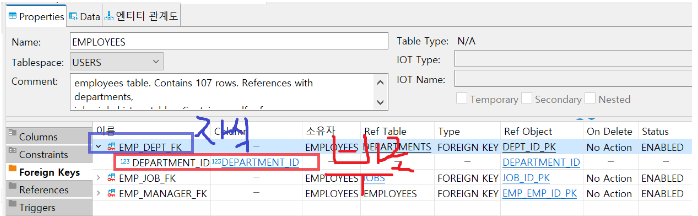
<primary key 확인하기>
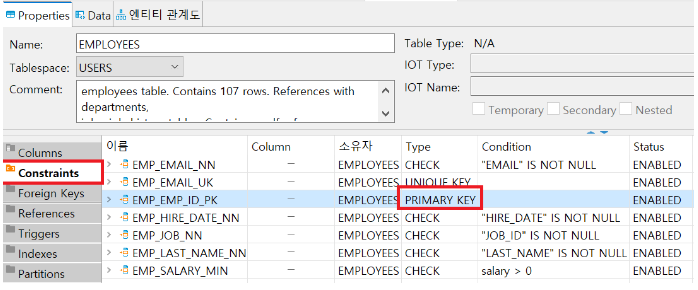
<pk를 선언하는 방법>
3가지

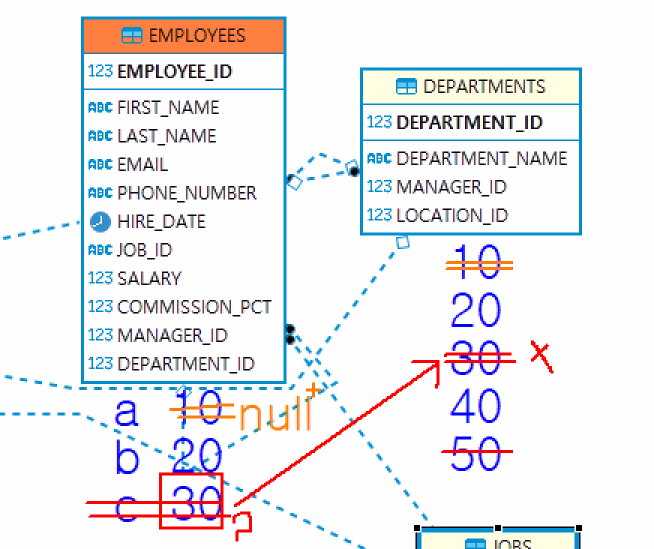
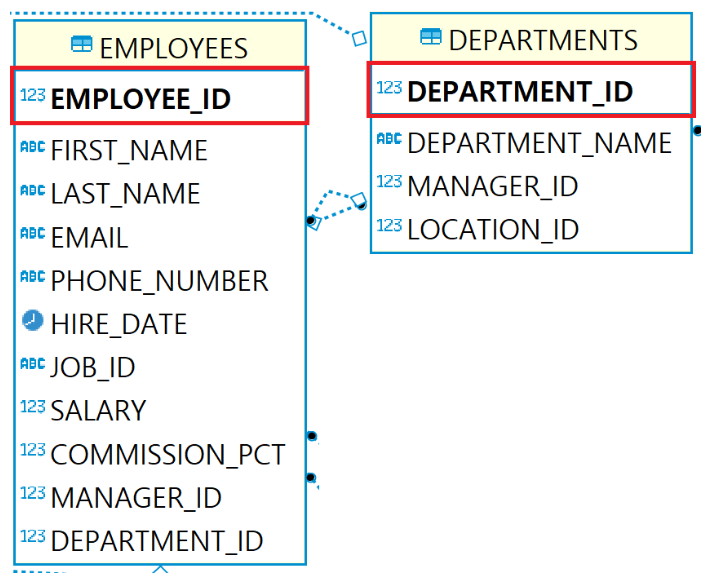
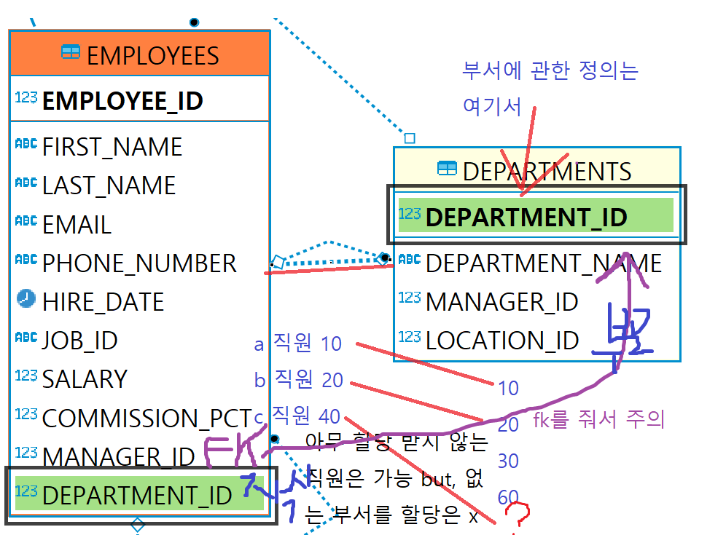
(3) Foreign Key(외래키)
- 외부키, 외래키, 참조키, fk, 외부식별자 등으로 불린다.
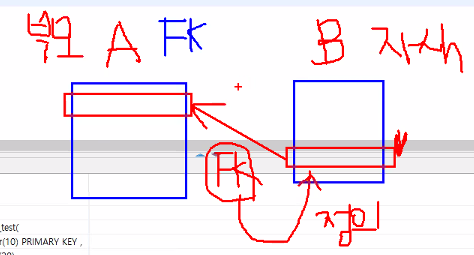
- FK가 정의된 테이블을 자식 테이블이라고 칭한다.
- 테이블 사이 연결고리를 만들어주는 것
- 화살표 방향 (자식-정의) b -> a (부모). 자식이 부모한테 연결고리를 던질 뿐
- 참조되는 테이블 즉 PK(기본키)가 있는 테이블을 부모 테이블이라고 한다.
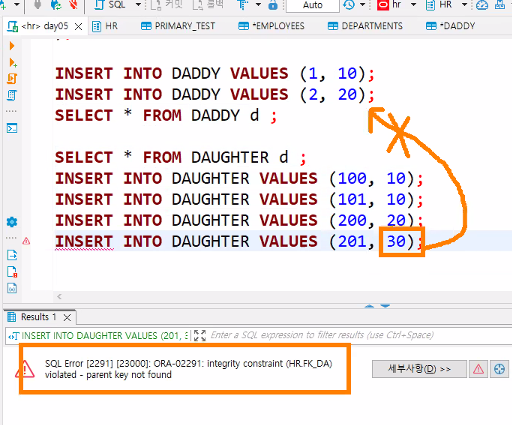
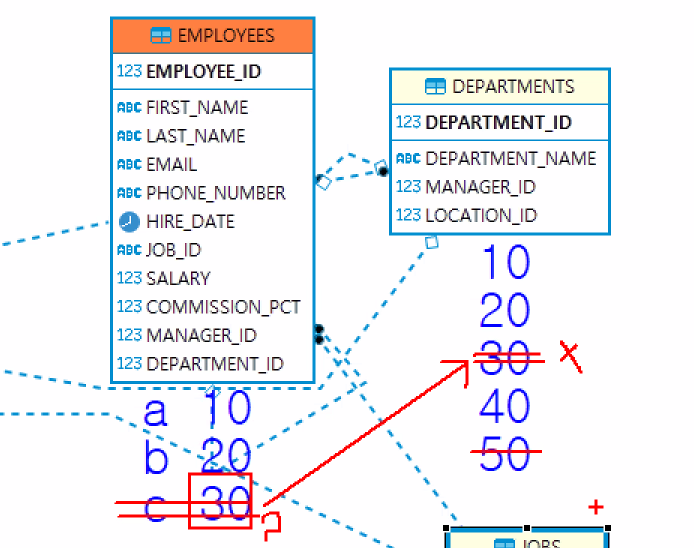
- 부모테이블의 PK컬럼에 존재하는 데이터만 자식 테이블에 입력할 수 있다.
- 부모테이블은 자식의 데이터나 테이블이 삭제된다고 영향을 받지 않는다.
- 참조하는 데이터 컬럼과 데이터 타입이 반드시 일치해야 한다.
- 참조할 수 있는 컬럼은 기본키이거나 unique만 가능하다.
(보통은 Pk랑 엮는다.)
<참고 이미지>
<FOREIGN KEY 선언방법>
① 인라인 방법 : 컬럼을 선언함과 동시에 제약조건 같이 걸어주는 것

② 아웃라인 방식 : 컬럼을 전체 다 선언하고 외래키 선언 ; 대상 컬럼을 지목해주어야 함

<외래키 삭제 옵션>
on delete cascade
- 참조되는 부모 테이블의 행에 대한 delete를 허용한다. 즉, 참조되는 부모테이블 값이 삭제되면 연쇄적으로 자식 테이블 값 역시 삭제된다.
on delete set null
- 참조되는 부모테이블의 해애에 대한 delete를 허용한다. 이건 cascade와 다른데, 부모 테이블의 값이 삭제되면 해당 참조하는 자식테이블의 값들이 null이 된다.