
우선순위 ★☆☆☆☆
1. 뷰 (View)
(1) view란?
- 작업시 자주 조회하는 데이터들을 쿼리로 뷰를 만들어 놓고 사용
- 테이블에 데이터를 노출시키고 싶지 않을때, 뷰를 사용하여
보여줄 데이터만 뷰로 제공할 수 있다 : 보안에 유리
(2) 뷰의 사용 목적
- 뷰를 만들어 놓으면 복잡한 쿼리를 쉽게 작성 가능
- 원하는 컴럼만 공개하여 원천데이터 테이블 비공개 가능성, 보안에도 유리
(3) 뷰의 특징
- 원천데이터가 변경되면 view 데이터도 자동으로 변경
- 뷰의 검색은 자유로우나, 삽입, 수정, 삭제는 제약이 있다.
- 뷰생성 쿼리에 함수를 사용하면 반드시 alias를 지정
(4) 뷰의 예시

2. 시퀀스 (Sequence)
- 연속적인 번호를 만들어주는 기능
- 순 차적으로 증가하는 순번을 자동으로 반환
- 보통 pk값에 중복값을 방지하기 위해 사용
- 원하는 숫자를 시작값으로 줄 수 있음 (100번 시작 등)
- 숫자를 메김으로써 발생하는 속도 지연을 막아줌
💡 예시
1. 시퀀스 만들기
-- 시퀀스 이름
CREATE SEQUENCE seq_serial_no
INCREMENT BY 1 -- INCREMENT BY : 증가값
START WITH 100 -- START WITH : 시작값
MAXVALUE 110 -- MAXVALUE : 최대값 -- NOmaxvalue : 최대값 x
MINVALUE 99 -- MINVALUE : 최소값
CYCLE -- CYCLE : MAXVALUE에 도달 시 다시 MINVALUE로
-- NOCYCLE (기본값x)
CACHE 2 -- CACHE : 메모리 보관 값 / 신경쓰지말고 아무값이나 넣기
; 2. 시퀀스 넣을 테이블 만들기
CREATE TABLE good(
good_no number(3),
good_name varchar2(10)
);
3. 테이블에 시퀀스 넣기
-- nextval : 시퀀스 늘리기
INSERT INTO good values(seq_serial_no.nextval, '제품14');
-- currval : 현재값으로 숫자 매기기
INSERT INTO good values(seq_serial_no.currval, '제품16');4.현재 시퀀스 확인
SELECT seq_serial_no.currval FROM dual ;
5. 시퀀스 삭제
DROP SEQUENCE se_serial_no;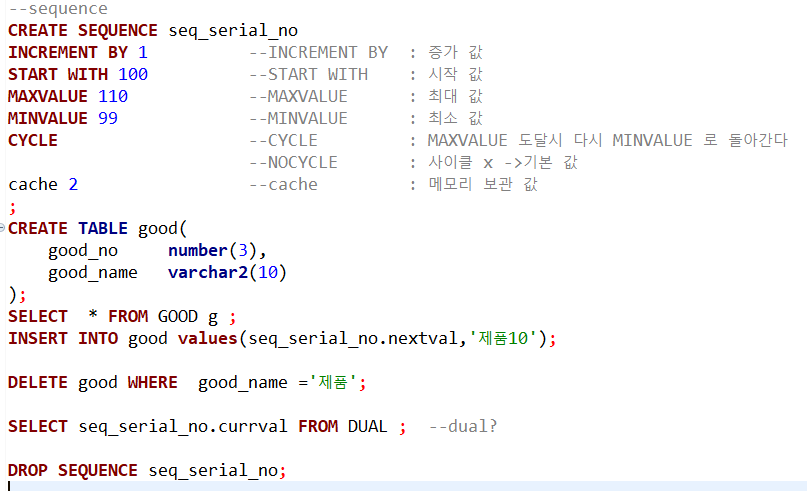
속도 지연을 줄이는 방법
1. COUNT(*) tkdyd
count(*) : 속도가 더빠름
count(salary)
-- 이유 : 오라클이 *로 했을 때는 전체크기로 계산
salary는 해당 컬럼을 찾아서 크기 계산
2. PK로 찾기
3. INDEX 에서 찾기 : 그렇다고 매번 다 index를 걸면 속도 지연
4. 같은 것 찾을 때
1.like 조건 확인하기
2.equal로 찾기
3. Index (많은 정보를 다룰 때)
(1) index란?
- 조회속도를 향상시키기 위한 데이터베이스 검색 기술
- 색인이라는 뜻으로 해당 테이블의 조회결과를 빠르게하기 위해 사용
(2) index의 원리
- 인덱스를 한 개 이상 만들기 가능은 하나 많이 만들면 효율이 떨어짐
- 속도를 빠르게 하기 위해 어떤 컬럼에 인덱스를 넣을지 고민해야 함
- 하지만 dml명령을 사용할 때는 원본 table 물론 index table에도 데이터를 갱신시켜주어야 하기 때문에 update, insert, delete 명령을 쓸 때 속도가 느려진다는 단점이 있다.
index 만들기
1. index를 테이블의 특정 컬럼에 한개 이상 주게되면 index table이 따로 만들어짐
2. 인덱스 컬럼의 로우값과 row id값이 저장
3. 로우값은 정렬된 트리 구조로 저장시켜 두었다가 검색시 좀 더 빠르게 해당 데이터를 찾는 데 도움을 준다.
(3) index 생성이 불필요한 경우
- 데이터가 적은 경우
- 조회보다 삽입, 수정, 삭제 처리가 많은 테이블
-a 테이블에 delete로 삭제 => index는 삭제 x 사용불가 처리
- 자주 삭제하는 테이블에 인덱스처리하면 인덱스안에 저장 정보가 많음
- update를 하면 index는 delete, insert가 같이 일어남으로 시간이 많이 걸림
(4) DML 명령어를 이용했을 경우 취약점
- insert : 두개의 테이블에 동시 insert
- delete : 인덱스에서는 데이터를 사용하지 않음으로 표시하고 지우지 않는다.
- update : 인덱스에는 delete한 후 새로운 데이터를 insert 작업 함
(5) index 생성
- unique index
: 인덱스를 사용한 컬럼이 중복값들을 포함하지 않고 사용할 수 있는 장점이 있다.
create unique index 인덱스명
on 테이블명(컬럼);- non-unique index
: 인덱스를 사용한 컬럼에 중복데이터값을 가질 수 있다.
create index 인덱스명
on 테이블명(컬럼);💡 예시
1.employee 테이블 복사
CREATE TABLE EMPLOYEES4 AS SELECT * FROM EMPLOYEES e ;2.null 값 not null로 변경
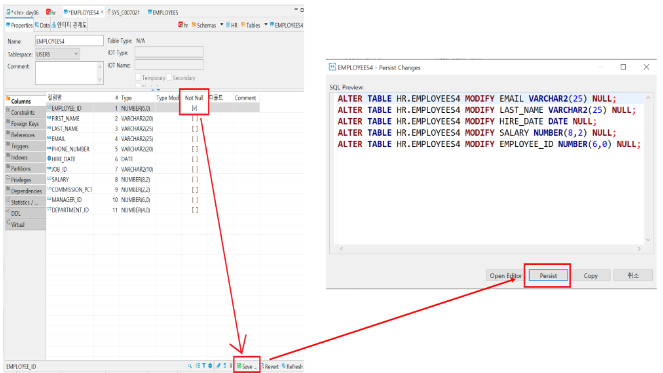
3. unique 인덱스 생성
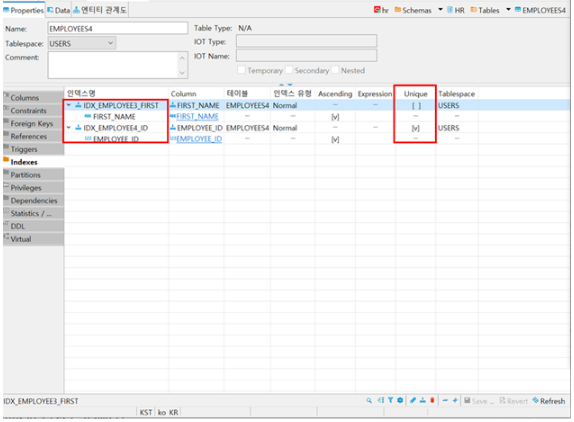
CREATE UNIQUE INDEX idx_employee4_id
ON employees4(employee_id);4. non-unique index 생성
CREATE INDEX idx_employee3_first
ON employees4(first_name);5. 확인

KIC캠퍼스 교육수료 (2023.01~2023.06) - JAVA, JSP, Springboot, DBeaver