성별이 다른 유저를 랜덤으로 3명만 추천해주는 페이지에서 유저를 가져올 때 먼저 JpaRepository에서 성별이 다른 유저를 모두 가져온 후 UserService에서 그 리스트를 섞어 3명을 뽑아오도록 함수를 작성했었다.
public List<SiteUser> getRandomList(String gender) {
List<SiteUser> userList = this.userRepository.findByGenderNot(gender);
Collections.shuffle(userList);
return userList.size() > 3 ? userList.subList(0, 3) : userList;
}랜덤으로 몇명의 유저만 가져오는 방법을 검색했을 때 쿼리문을 직접 작성하는 것보다 이렇게 하는 방식이 성능적으로 더 나을 거라고 봤던 것 같은데..
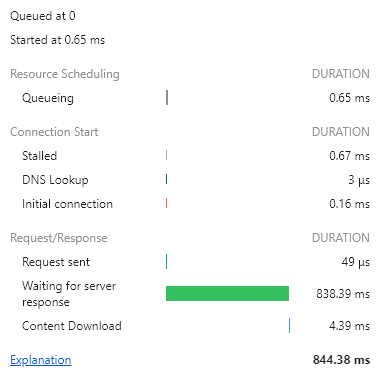
서버에서 데이터를 가져오는 시간이 꽤 오래 걸렸다.
그래서 이번에는 서비스에서 유저 리스트를 반환하는 방식이 아닌 처음부터 쿼리문을 통해 랜덤으로 3명을 가져오는 방법으로 바꿔보기로 했다.
@Query(value = "SELECT * FROM site_user WHERE gender != :gender ORDER BY preference DESC, RAND() LIMIT 10", nativeQuery = true)
List<SiteUser> findByGenderNotRandom(@Param("gender") String gender);'RAND()' 함수를 사용하기 위해서 네이티브 SQL 쿼리를 사용한다는 의미인 nativeQuery = true 를 함께 적어주었다.
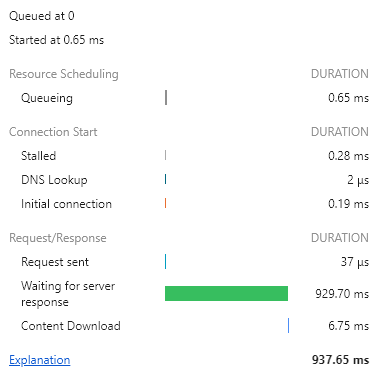
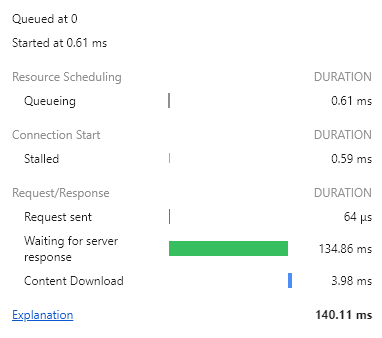
이렇게 쿼리로 처음부터 랜덤으로 3명의 데이터를 가져왔을 때의 시간을 보면
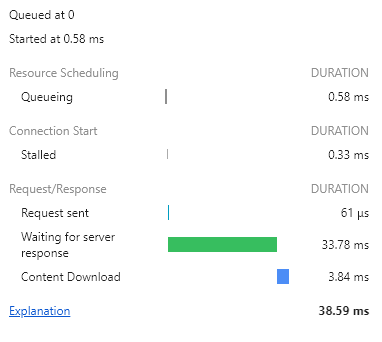
서버에서 걸리는 시간이 929.70ms -> 33.78ms로 단축된 것을 볼 수 있다.
로컬 서버에서 처음에 테스트를 진행했을 때는 가입된 유저가 별로 없어서 두 방식의 차이가 크게 없었다. 하지만 유저 더미데이터를 5만개 정도 추가했을 때는 차이가 확연하게 드러났다.
쿼리에서 랜덤으로 뽑아올 때
- DB에서 필요한 만큼만의 데이터를 불러와 불러온 결과가 작다면 네트워크 지연과 메모리 사용량 감소.
- 'RAND()' 함수는 모든 행에 대한 랜덤 값을 생성하고 그 결과를 정렬해야 하기 때문에 대규모 테이블에서는 성능 저하를 일으킬 수 있음.
서비스에서 랜덤으로 가져올 때
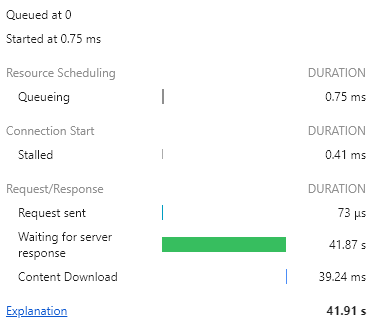
- 서비스에서 랜덤으로 가져올 대는 'RAND()' 함수를 쓰지 않아 데이터베이스 서버의 부하가 덜하고 대규모 데이터셋에서 SQL 쿼리 성능 저하를 피할 수 있음.
- 하지만 DB에서 모든 유저 데이터를 불러와 처리하기 때문에 현재처럼 유저의 데이터가 많아지면 메모리 사용량이 증가하고 데이터를 전송하는데 많은 시간이 걸림.
-> 데이터가 너무 많지 않고 쿼리 최적화에 한계가 있는 경우에 사용하기 좋음.
두 방식 중 어떤 방식으로 사용해야 성능이 좋을 지는 사용 사례에 따라 달라지겠지만 현재 상황으로서는 결과의 크기가 작고 'RAND()' 함수로 인한 성능 저하가 크지 않기 때문에 쿼리를 사용하는 것이 더 효율적이다.
결과 값이 클 때 두 방식의 로딩 속도 차이 (1만명의 유저 랜덤으로 가져오기)
-
쿼리 사용

결과 값이 커지니까 이상하게 쿼리로 불러올 때 처음에 이렇게 fail이 뜬다.
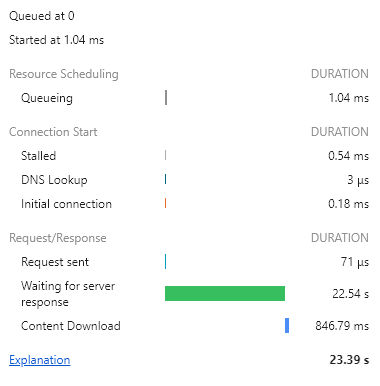
-
서비스 사용
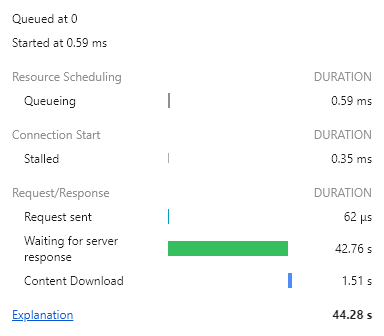
왜.. 결과값이 커도 서비스가 더 오래 걸리지;;
좀 더 극단적으로 커야 결과 차이가 보일 듯해서 5만명으로 늘림.
결과 값이 클 때 두 방식의 로딩 속도 차이 (5만명의 유저 랜덤으로 가져오기)
-
쿼리 사용
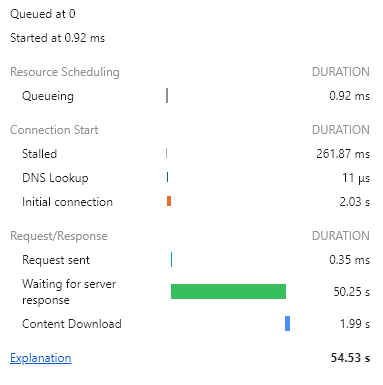
과부하가 많이 오는 듯.. 로딩 되고 나서 몇초동안 화면 클릭도 잘 안된다. -
서비스 사용
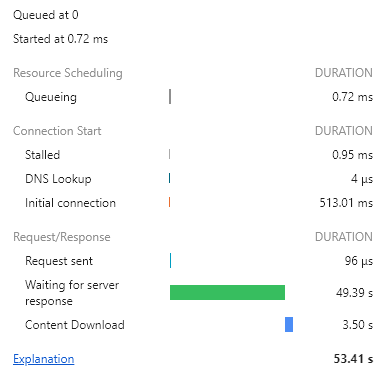
마찬가지로 몇초동안 화면이 많이 버벅인다.
결과값이 5만이 되어서야 둘이 얼추 비슷해졌는데 정말 극단적으로 결과값이 많은게 아니라면 쿼리문을 사용하는 것이 좋을 것 같다.
