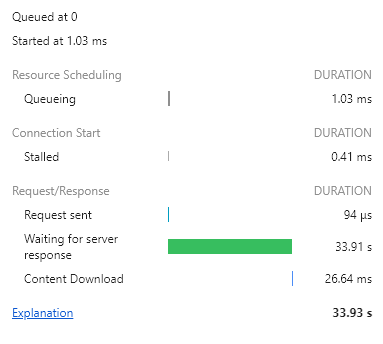
유저가 이상형을 선택하는 페이지에서 이상형을 선택하고 그 이상형 조건에 4개 이상 부합하는 유저를 찾아 추천해주는 이상형 매칭 페이지는 가입된 유저가 별로 없었을 때는 문제가 되지 않았지만 가입된 유저가 많아지니 로딩 시간이 33.91s 로 매우 길어졌다.
그럴 수 밖에 없는게 많은 조건을 가지고 그 조건을 몇 개 이상 부합하는 결과만 뽑아내는 것이기 때문에 쿼리가 아주 복잡했다.. 솔직히 봐도 뭔지 잘 모를만큼
@Query("SELECT u FROM SiteUser u WHERE " +
"u.gender <> :gender AND " +
"(CASE WHEN u.age BETWEEN :#{#idealType.minAge} AND :#{#idealType.maxAge} THEN 1 ELSE 0 END) + " +
"(CASE WHEN u.height BETWEEN :#{#idealType.minHeight} AND :#{#idealType.maxHeight} THEN 1 ELSE 0 END) + " +
"(CASE WHEN :#{#idealType.drinking} = '상관 없음' OR :#{#idealType.drinking} IS NULL OR u.drinking = :#{#idealType.drinking} THEN 1 ELSE 0 END) + " +
"(CASE WHEN :#{#idealType.education} = '상관 없음' OR :#{#idealType.education} IS NULL OR u.education = :#{#idealType.education} THEN 1 ELSE 0 END) + " +
"(CASE WHEN :#{#idealType.smoking} = '상관 없음' OR :#{#idealType.smoking} IS NULL OR u.smoking = :#{#idealType.smoking} THEN 1 ELSE 0 END) + " +
"(CASE WHEN :#{#idealType.religion} = '상관 없음' OR :#{#idealType.religion} IS NULL OR u.religion = :#{#idealType.religion} THEN 1 ELSE 0 END) >= 4")
List<SiteUser> findMatchingUsersByIdealType(@Param("idealType") IdealType idealType, @Param("gender") String gender);이렇게 복잡하게 가져온 리스트를 또 서비스에서 랜덤으로 10개만 추려낸다.
public List<SiteUser> getByIdealType(IdealType idealType, String gender) {
List<SiteUser> users = this.userRepository.findMatchingUsersByIdealType(idealType, gender);
Collections.shuffle(users);
return users.subList(0, Math.min(users.size(), 10));
}최적화를 생각하기 전까지는 솔직히 걸리는 시간같은건 상관없이 기능만 제대로 잘 작동한다면 오케이였지만.. 이제 가입자 수가 늘어났을 때의 과부하를 무시할 수 없다.
그래서 조건을 순차적으로 적용하여 필터링된 결과를 다음 단계로 전달하는 식의 함수를 짜보았다.
List<SiteUser> users = userRepository.findByGenderNot(gender);
List<SiteUser> ageFilteredUsers = users.stream()
.filter(u -> Integer.parseInt(u.getAge()) >= idealType.getMinAge() && Integer.parseInt(u.getAge()) <= idealType.getMaxAge())
.collect(Collectors.toList());
List<SiteUser> heightFilteredUsers = ageFilteredUsers.stream()
.filter(u -> Integer.parseInt(u.getHeight()) >= idealType.getMinHeight() && Integer.parseInt(u.getHeight()) <= idealType.getMaxHeight())
.collect(Collectors.toList());
List<SiteUser> drinkingFilteredUsers = heightFilteredUsers;
if (!idealType.getDrinking().equals("상관 없음")) {
drinkingFilteredUsers = heightFilteredUsers.stream()
.filter(u -> Objects.equals(u.getDrinking(), idealType.getDrinking()))
.collect(Collectors.toList());
}
List<SiteUser> educationFilteredUsers = drinkingFilteredUsers;
if (!idealType.getEducation().equals("상관 없음")) {
educationFilteredUsers = drinkingFilteredUsers.stream()
.filter(u -> Objects.equals(u.getEducation(), idealType.getEducation()))
.collect(Collectors.toList());
}
List<SiteUser> smokingFilteredUsers = educationFilteredUsers;
if (!idealType.getSmoking().equals("상관 없음")) {
smokingFilteredUsers = educationFilteredUsers.stream()
.filter(u -> Objects.equals(u.getSmoking(), idealType.getSmoking()))
.collect(Collectors.toList());
}
List<SiteUser> religionFilteredUsers = smokingFilteredUsers;
if (!idealType.getReligion().equals("상관 없음")) {
religionFilteredUsers = smokingFilteredUsers.stream()
.filter(u -> Objects.equals(u.getReligion(), idealType.getReligion()))
.collect(Collectors.toList());
}
Collections.shuffle(religionFilteredUsers);
return religionFilteredUsers.subList(0, Math.min(religionFilteredUsers.size(), 10));음주 습관이나 종교 등을 "상관 없음"으로 설정했을 때는 필터링 없이 모든 데이터가 나와야하기 때문에 조건문을 달아 필터링했다.
이렇게 실행해보았는데
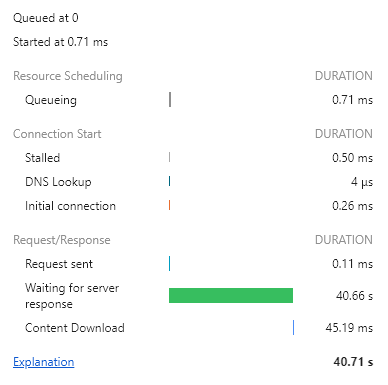
33.91s -> 40.66s 로 오히려 로딩 시간이 늘어났다......
다음 방법으로는 Criteria API를 사용했다.
동적으로 쿼리를 생성해 사용자의 이상형 조건에 맞는 SiteUser 객체들을 데이터베이스에서 검색하고, 그 결과를 무작위로 섞어서 상위 10개의 결과를 반환하는 코드를 작성했다.
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<SiteUser> cq = cb.createQuery(SiteUser.class);
Root<SiteUser> user = cq.from(SiteUser.class);
List<Predicate> predicates = new ArrayList<>();
predicates.add(cb.notEqual(user.get("gender"), gender));
predicates.add(cb.between(user.get("age"), idealType.getMinAge(), idealType.getMaxAge()));
predicates.add(cb.between(user.get("height"), idealType.getMinHeight(), idealType.getMaxHeight()));
if (!"상관없음".equals(idealType.getDrinking())) {
predicates.add(cb.equal(user.get("drinking"), idealType.getDrinking()));
}
if (!"상관없음".equals(idealType.getEducation())) {
predicates.add(cb.equal(user.get("education"), idealType.getEducation()));
}
if (!"상관없음".equals(idealType.getSmoking())) {
predicates.add(cb.equal(user.get("smoking"), idealType.getSmoking()));
}
if (!"상관없음".equals(idealType.getReligion())) {
predicates.add(cb.equal(user.get("religion"), idealType.getReligion()));
}
List<SiteUser> result = entityManager.createQuery(cq).getResultList();
Collections.shuffle(result);
return result.stream().limit(10).collect(Collectors.toList());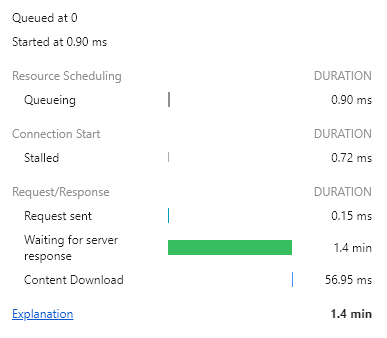
40.66s -> 1.4 min으로 또 로딩 시간이 대폭 증가..ㅠㅠ
그래서 더 이상 서비스를 변경하지 않고 쿼리문에서 다른 매칭 추천 페이지에서 사용했던 'RAND()'와 LIMIT를 사용해보기로 했다.
@Query(value = "SELECT * FROM site_user WHERE " +
"gender <> :gender AND " +
"age BETWEEN :minAge AND :maxAge AND " +
"height BETWEEN :minHeight AND :maxHeight AND " +
"(:drinking = '상관 없음' OR drinking = :drinking) AND " +
"(:education = '상관 없음' OR education = :education) AND " +
"(:smoking = '상관 없음' OR smoking = :smoking) AND " +
"(:religion = '상관 없음' OR religion = :religion) ORDER BY RAND() LIMIT 10", nativeQuery = true)
List<SiteUser> findMatchingUsersByIdealTypeRand(@Param("gender") String gender,
@Param("minAge") int minAge,
@Param("maxAge") int maxAge,
@Param("minHeight") int minHeight,
@Param("maxHeight") int maxHeight,
@Param("drinking") String drinking,
@Param("education") String education,
@Param("smoking") String smoking,
@Param("religion") String religion);이렇게 nativeQuery를 사용하여 쿼리문을 직접 작성해주었다.
인덱싱하면 쿼리의 성능을 향상시킬 수 있다고 해서 인덱싱을 먼저 해주고
CREATE INDEX idx_gender ON site_user (gender);
CREATE INDEX idx_age ON site_user (age);
CREATE INDEX idx_height ON site_user (height);
CREATE INDEX idx_drinking ON site_user (drinking);
CREATE INDEX idx_education ON site_user (education);
CREATE INDEX idx_smoking ON site_user (smoking);
CREATE INDEX idx_religion ON site_user (religion);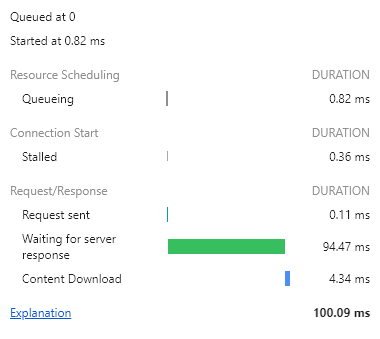
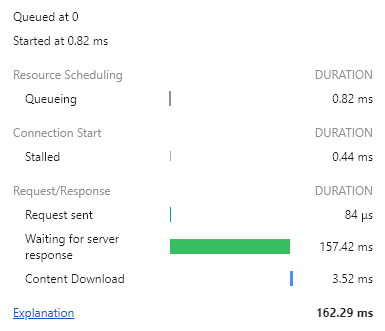
빠를 때는 94.47ms, 살짝 느릴 때는 157.42ms 로 서버에서 걸리는 시간이 매우 매우 많이 줄어들었다.
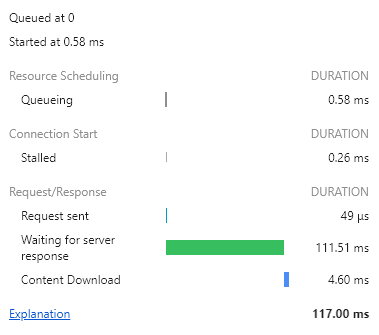
인덱싱을 하기 전과 한 후의 차이가 궁금해서 다시 인덱스를 삭제하고 페이지를 로드해봤다.
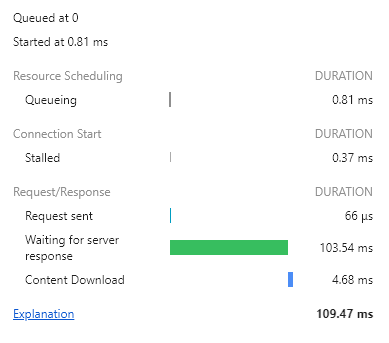
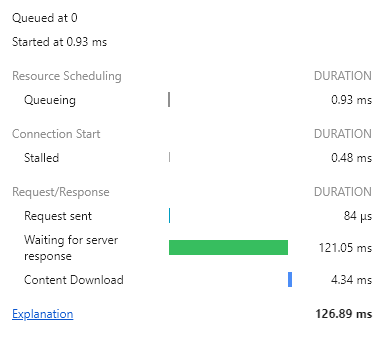
110ms-120ms 정도에서 왔다갔다 하는것같다. 생각보다 하기 전과 한 후의 차이가 별로 없었고 오히려 인덱싱 전이 편차도 더 적어 평균적으로는 더 빠른 것 같다.
