하둡이란 대용량 데이터를 분산처리할 수 있는 자바 기반의 오픈소스 프레임워크입니다.
따라서 우분투에 하둡을 설치하기 전에 자바를 먼저 설치해줘야 됩니다.
자바설치
- 먼저 apt-get을 업데이트 시켜줍니다.
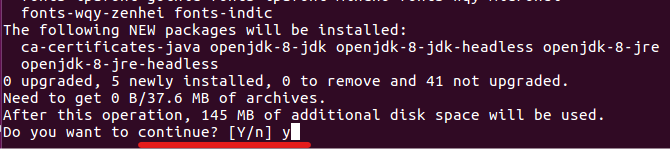
sudo apt-get update - 자바 OpenJDK8버전을 설치해줍니다.
중간에 Do you want to continue?가 나오면 Y를 입력해주시고 enter를 쳐주세요.sudo apt-get install openjdk-8-jdk
-
자바가 설치된걸 확인해주세요.
java -version

하둡설치
1. Openssh Server, push 설치
1) Openssh Server와 push를 설치합니다.
-
하둡이 클러스터에 접속할 때 SSH를 통해 터미널을 이용하여 관리및 작업을 수행 할 수 있습니다.
-
PDSH를 설치하면 클러스터의 각 노드에 동시에 명령을 내려 수행할 수 있습니다.
-
따라서 하둡 설치 및 관리를 위해서 SSH 서버가 필요하고 pdsh를 설치하면 클러스터 노드 간의 효율적이 명령 실행이 가능해지기에 패키지 설치를 합니다.
sudo apt-get install openssh-server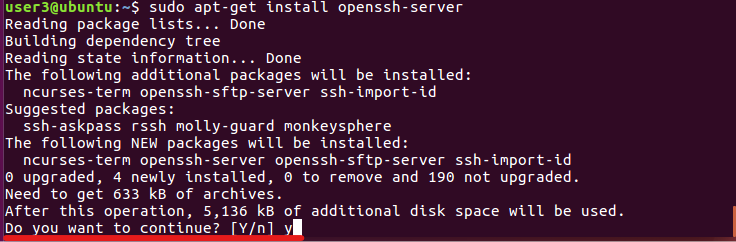
sudo apt-get install pdsh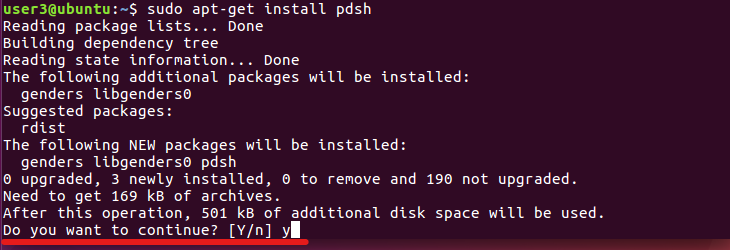
2) SSH 공개키와 개인키를 생성합니다.
- ssh-keygen : SSH 키 생성 및 관리를 위한 유틸리티
- -t rsa : RSA 알고리즘을 사용하여 키 생성
- -P '' : 비밀번호를 설정하지 않고 생성
- -f ~/.ssh/id_rsa : 생성할 키 파일의 이름과 경로를 지정
- ~/.ssh 디렉토리에 'id_rsa'(개인키)와 'id_rsa.pub'(공개키)파일이 생성
- SSH 키를 통해 원격 접속이나 파일 전송 등에서 비밀번호 입력 없이 보연 연결을 제공하는데 사용됩니다.
ssh-keygen –t rsa –P ‘’ -f ~/.ssh/id_rsa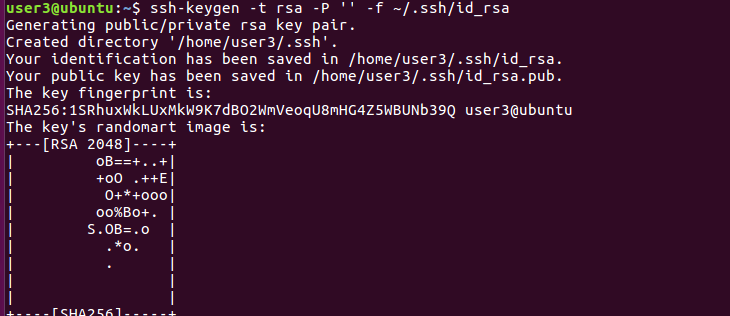
3) SSH 키 접속
-
cat : 파일의 내용을 출력하는 명령어
-
'>>' : 리다이렉션 연산자, 오른쪽의 파일에 데이터 추가
-
chmod : 파일 권한을 변경하는 명령어
-
0600 : 'authorized_keys'의 파일의 새로운 권한을 나타내는 숫자로 첫번째 자리는 소유자 권한, 두 번째 자리는 그룹 권한, 세 번째 자리는 다른 사용자권한. 즉 소유자에게 읽기와 쓰기 권한만 주고, 그룹과 다른 사용자에게는 권한을 주지 않음을 의미
-
ssh localhost : 로컬 머신으로 SSH 접속을 시도하는 명령어
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys ssh localhost -
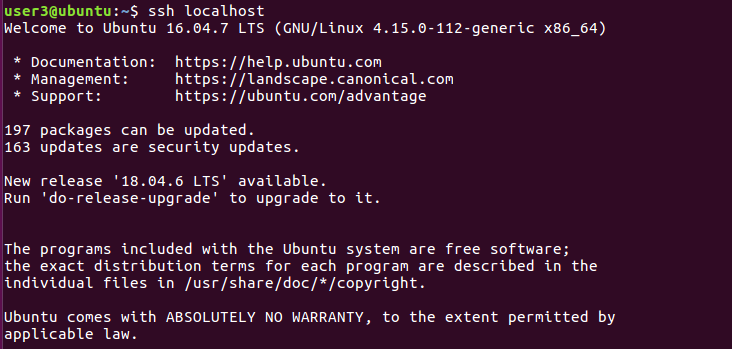
특정 호스트에 최초 SSH 접속 시 아래처럼 RSA key fingerprint로 접속 여부(yes/no)를 확인합니다. yes를 입력하면 접속이 가능합니다.

만약 yes를 쳤을 때 이러한 오류가 생긴다면?

SSH 접속을 위한 방화벽 해제를 해줍니다.
기본적으로 SSH 포트는 22번입니다.
sudo ufw allow 22
방화벽이 해제 되었는지 확인합니다.
inactive가 나오면 방화벽 해제 완료 !
다시 ssh localhost를 쳐주세요
sudo ufw status

2 하둡
1. 하둡 설치
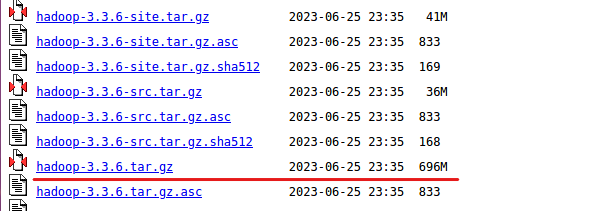
1) 하둡 홈페이지에서 하둡 파일 url을 가져와줍니다.
- 하둡 홈페이지에서 다운로드 칸 들어가기
- Apache 들어가기
- 알맞는 하둡 버전 찾아서 들어가기 (전 가장 최신 버전을 다운받았습니다.)
- hadoop-3.3.6.tar.gz 파일 우클릭 후 Copy Link Location 클릭




2) 하둡 파일 터미널에 설치
-
다시 터미널로 돌아와 아까 복사했던 경로를 붙여넣기
-
다운받는 시간이 꽤 길음
-
우분투 터미널에서 붙여넣기 키: CTRL + SHIFT + V
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz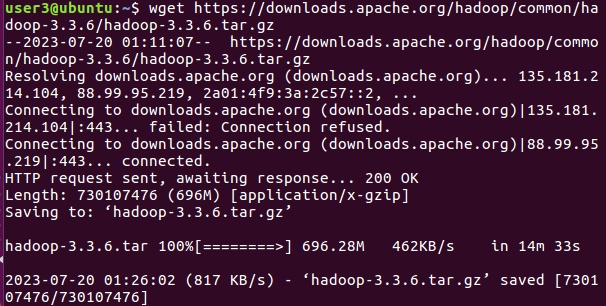
-
압축 풀어주기
tar -xzvf hadoop-3.3.6.tar.gz -
설치 확인
ls
3) 하둡 파일 이동
mv hadoop-3.3.6 /home/계정이름/hadoop 2. 하둡 경로 설정
1) 환경 변수 설정창 진입
sudo vi ~/.bashrcvi 단축키
입력모드 > i (현재 커서부터 시작)
입력모드 > a (다음 커서부터 시작)
입력모드에서 명령모드로 전환 > Esc
파일 저장 > :W
파일 나가기 > :q
파일 저장후 나가기 > :wq
파일 저장하지 않고 나가기 > :q!
한줄 지우기 > dd
한글자 지우기 > x
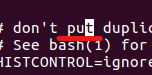
전으로 되돌리기 > u처음 파일로 들어가면 명령모드로 되어 있습니다
커서위치는 윈도우와 다르니 적응해야 됩니다
위 사진에서 'x'로 한글자를 지우면 u가 아닌 t가 지워집니다.
2) 하둡 경로 추가
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export HADOOP_HOME="/home/계정이름/hadoop"
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_CLASSPATH=$(hadoop classpath)3) 변경 적용
source ~/.bashrc4) 자바 경로 설정(env.sh)
- 주석처리 되있는 JAVA_HOME 에 경로를 입력해주시고 저장해줍니다.
sudo vi $HADOOP_HOME/etc/hadoop/hadoop-env.shJAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/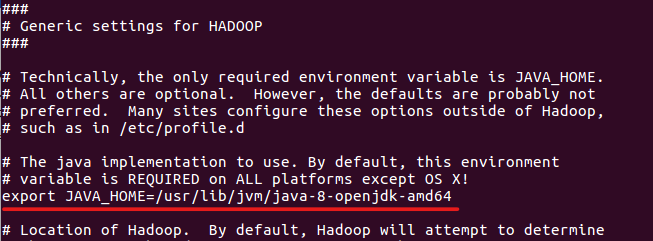
3.하둡 파일 수정
1) core-site.xml 파일 수정을 해줍니다
- hadoop.tmp.dir : hadoop 프레임워크에서 임시 파일 및 디렉토리를 저장하는 경로 설정
- fs.default.name : hadoop의 파일시스템의 기본 위치를 설정
sudo vi $HADOOP_HOME/etc/hadoop/core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/계정이름/hadoop_tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>2) hdfs-site.xml 파일 수정을 해줍니다
- dfs.replication : HDFS에서 데이터의 복제 수 설정
sudo vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>3) mapred-site.xml 파일 수정을 해줍니다
- mapreduce.framework.name : 맵리듀스 작업 실행하는 데 사용할 프레임워크
- yarn.app.mapreduce.am.env : YARN 맵리듀스 어드민 환경변수
- mapreduce.map.env :맵리듀스 job의 map task가 실행될 때 사용되는 환경 변수
- mapreduce.reduce.env : 맵리듀스 job의 reduce task 실핼될 때 사용되는 환경 변수
sudo vi $HADOOP_HOME/etc/hadoop/mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>4) yarn-site.xml 파일 수정을 해줍니다
- yarn.nodemanager.aux-services : YARN에서 실행되는 보조 서비스 설정
- yarn.nodemanager.aux-services.mapreduce.shuffle.class : YARN의 보조서비스인 맵리듀스 셔플링을 처리하는 클래스를 지정
sudo vi $HADOOP_HOME/etc/hadoop/yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>4. 하둡 실행
1) namenode 초기화를 해줍니다.
hdfs namenode -format2) pdsh "ssh" 기본 설정을 변경해줍니다.
echo "ssh" | sudo tee /etc/pdsh/rcmd_default3) hadoop 실행 해줍니다.
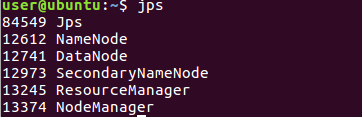
start-all.sh4) jps로 하둡이 돌아가는지 확인해줍니다.
jps- 밑에 그림과 같이 뜨면 하둡이 성공적으로 설치 되었습니다.
참고한 블로그입니다.
https://domdom.tistory.com/524
https://minutemaid.tistory.com/88

많은 도움이 되었습니다, 감사합니다.