DB 정규화
서론
프로젝트를 진행하면서 데이터 베이스 정규화의 중요성에 대해서 깨닫게 되었다. 지난 프로젝트에서는 정규화 없이 하나의 테이블에 여러가지 데이터가 들어가있어 중복이 발생하고 데이터 조회 성능이 좋지 않았다. 이런 문제점들을 해결하기 위해 정규화라는 과정을 공부하고 적용해보자.
DB 정규화란
관계형 데이터베이스에서 데이터를 효율적으로 저장하고 관리 하기 위해 데이터를 여러 테이블로 분리하고, 중복을 최소화 하는 과정이다.
정규화의 장 단점
정규화의 장점
- 데이터 중복 제거
- 동일한 데이터가 여러 곳에 저장되지 않으므로 저장 공간을 절약할 수 있다.
- 중복된 데이터를 수정할 때 일관성 문제가 발생하는 것을 방지할 수 있다.
- 데이터 무결성 유지
- 정규화를 통해 데이터가 논리적으로 정리되면 삽입, 수정, 삭제 시 데이터 불일치 문제가 줄어든다.
정규화의 단점
- join 연산 증가
- 데이터를 여러 테이블로 분할하여 저장하기 때문에 조회할때 여러 테이블을 조인해야 할 수 있음.
- 설계 복잡성 증가
- 정규화를 통해 테이블의 수가 많아지고 이들간의 관계를 설계하는 과정이 까다로워진다.
- 읽기 성능 저하
- 읽기 성능이 중요한 시스템에서 지나치게 정규화된 데이터베이스는 다수의 조인을 필요로 하여 성능이 떨어질 수 있음.
(※ 인덱스를 사용하면 성능 저하를 최소화 할수도 있다)
- 읽기 성능이 중요한 시스템에서 지나치게 정규화된 데이터베이스는 다수의 조인을 필요로 하여 성능이 떨어질 수 있음.
제1 정규화
제1 정규화는 한 칼럼 안에는 하나의 데이터만 넣어야 한다.
| 주문번호 | 고객명 | 상품명 | 수량 |
|---|---|---|---|
| 1001 | 김철수 | 노트북, 마우스 | 1, 2 |
| 1002 | 이영희 | 키보드, 모니터 | 1, 1 |
위 테이블과 같이 상품명 칼럼에 두가지 데이터를 가지고 있다면
| 주문번호 | 고객명 | 상품명 | 수량 |
|---|---|---|---|
| 1001 | 김철수 | 노트북 | 1 |
| 1001 | 김철수 | 마우스 | 2 |
| 1002 | 이영희 | 키보드 | 1 |
| 1002 | 이영희 | 모니터 | 1 |
이처럼 나눠서 데이터를 저장하는것이 제1 정규화이다.
제2 정규화
제2 정규화는 앞서 설명한 제1 정규화를 만족한 상태에서,기본키의 일부가 특정 속성을 결정하면 안된다.
즉 부분 함수 종속성을 제거해야하는데 기본키가 여러 칼럼으로 이루어진 복합키 일때, 그중 일부(한 칼럼)에만 종속된 속성을(부분 함수 종속)을 제거해야 하는것이다.
예시를 통해서 이해를 해보자.
| 학생ID | 학생이름 | 과목ID | 과목명 | 성적 |
|---|---|---|---|---|
| 1 | 홍길동 | 101 | 수학 | A |
| 1 | 홍길동 | 102 | 영어 | B |
위 테이블에서 학생이름은 학생ID에만 의존하고, 과목명은 과목ID에만 의존한다.
따라서 학생ID와 과목ID로 구성된 복합키에 완전히 종속되지 않는다.
이를 분리해서 제2정규화를 만족시켜 보자.
학생 테이블
| 학생ID | 학생이름 |
|---|---|
| 1 | 홍길동 |
과목 테이블
| 과목ID | 과목명 |
|---|---|
| 101 | 수학 |
| 102 | 영어 |
성적 테이블
| 학생ID | 과목ID | 성적 |
|---|---|---|
| 1 | 101 | A |
| 1 | 102 | B |
이렇게하면 부분 함수 종속을 제거하고 제2 정규화가 완성된다.
제3 정규화
제3 정규화는 제2를 만족한 상태에서 기본키에 직접 의존하지 않는 속성들은 별도의 테이블로 분리해야한다.
즉 이행적 종속을 제거해야 한다.
이행적 종속이란 A -> B -> C와 같은 관계에서 A가 C를 간접적으로 결정하는 경우를 뜻한다.
(A가 B를 결정하고 B가C를 결정하면, A가C를 결정하는 관계)
쉽게말해서 기본키에 직접의존하지 않은 속성을 제거해야 한다.
예시를 통해서 이해를 해보자.
| 학생ID | 학생이름 | 학과코드 | 학과명 |
|---|---|---|---|
| 1 | 홍길동 | CS | 컴퓨터공학 |
| 2 | 이순신 | ME | 기계공학 |
| 3 | 김유신 | CS | 컴퓨터공학 |
기본키는 학생ID이고 학과코드는 학생 ID를 통해 알 수 있다.
학과명은 학과코드를 통해서 알수 있다.
따라서 학생ID -> 학과코드 -> 학과명 관계가 존재하게된다. 결국 학생ID는 학과명을 간접적으로 결정하게 되므로 이행적 종속이 발생한다.
학생 테이블
| 학생ID | 학생이름 | 학과코드 |
|---|---|---|
| 1 | 홍길동 | CS |
| 2 | 이순신 | ME |
| 3 | 김유신 | CS |
학과 테이블
| 학과코드 | 학과명 |
|---|---|
| CS | 컴퓨터공학 |
| ME | 기계공학 |
이를 해결하기 위해 학생 테이블과 학과 테이블을 분리하여 학생ID -> 학과명의 이행적 종속을 제거하여 제3 정규화를 완성했다.
비정규화
지금까지는 정규화에 대해서 알아보았다. 그런데 무조건 정규화를 하는 것이 좋은 것은 아니다.
정규화를 하면 데이터의 중복을 최소화하고, 무결성을 보장할 수 있다는 장점이 있지만, 성능에 문제가 생길 수 있다.
특히, 데이터를 조회할 때 여러 테이블을 JOIN해야 한다면 성능이 저하될 수 있다.
이처럼 정규화의 단점을 보완하기 위해 등장한것이 비정규화이다.
비정규화란 의도적으로 정규화를 깨고 일부러 중복을 허용하거나 테이블을 합치는 과정이다.
정규화 vs 비정규화 언제 선택해야 할까 ?
| 구분 | 정규화 | 비정규화 |
|---|---|---|
| 목적 | 데이터 무결성 및 일관성 유지 | 성능 최적화 (특히 조회 성능 향상) |
| 적합한 경우 | - 데이터 무결성이 중요한 시스템 - 트랜잭션이 빈번한 시스템 - 데이터 관리가 중요한 시스템 | - 대량 데이터 처리 시 성능 문제가 있을 경우 - 지나치게 많은 JOIN이 필요한 시스템 |
| 사용 예시 | - 은행 시스템 - 온라인 쇼핑몰 주문 시스템 - 회계 시스템 | - 대규모 분석 시스템 - 로그 분석 시스템 - 보고서 시스템 |
즉, 정규화와 비정규화는 목적에 따라 적절히 조합해야 한다!
- 데이터 일관성이 중요한 경우 → 정규화
- 빠른 조회 성능이 필요한 경우 → 비정규화
내가 사용한 정규화 피드백
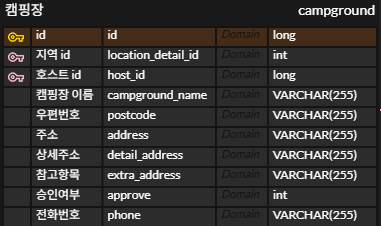 진행 했던 프로젝트중 캠핑장 테이블이 있었다. 현재 campground 테이블은 주소 관련 칼럼들이 포함되어있다.
진행 했던 프로젝트중 캠핑장 테이블이 있었다. 현재 campground 테이블은 주소 관련 칼럼들이 포함되어있다.
postcode, address, detail_address, extra_address는 주소 관련 속성들이며, 이 칼럼들은 서로 의존 관계를 형성 할수 있으므로 부분 종속 속성을 제거해야 한다.
리펙토링
- 새로운
address테이블 생성:postcode,address,detail_address,extra_address를address테이블로 분리하여 저장합니다.campground테이블에는address_id를 외래키로 추가한다.
- 변경된
campground테이블:campground테이블에서 주소와 관련된 컬럼들을 제거하고, 대신address_id컬럼을 추가하여address테이블과 연결한다.
address 테이블
| 컬럼명 | 데이터 타입 | 설명 |
|---|---|---|
address_id | BIGINT NOT NULL | 주소의 고유 ID (PK) |
postcode | VARCHAR(255) | 우편번호 |
address | VARCHAR(255) | 기본 주소 |
detail_address | VARCHAR(255) | 상세 주소 |
extra_address | VARCHAR(255) | 추가 주소 |
campground 테이블
| 컬럼명 | 데이터 타입 | 설명 |
|---|---|---|
id | BIGINT NOT NULL | 캠핑장의 고유 ID (PK) |
location_detail_id | INT NOT NULL | 위치 상세 ID |
host_id | BIGINT NOT NULL | 호스트(관리자) ID |
campground_name | VARCHAR(255) NOT NULL | 캠핑장 이름 |
approve | INT NULL | 승인 여부 |
phone | VARCHAR(255) NULL | 전화번호 |
address_id | BIGINT NOT NULL | 주소 정보 참조 (FK → address) |
이렇게 하면 campground에서 부분 종속 속성을 제거 할 수 있다.
대신 address_id라는 외래키를 추가하였고 각 캠핑장은 address 테이블의 특정 주소를 참조하게 된다.
address 테이블은 주소관련 정보를 보유하고 있으며, 캠핑장의 주소를 독립적으로 관리 할 수 있게 되었다.
결론
무조건 정규화를 하는것만이 데이터베이스의 성능을 결정 지을 수는 없다. 상황에 맞는 기술 선택이 이번 글에서도 녹아있는것 같다.
앞으로 ERD를 작성할 때에는 프로젝트의 주제에 따라 적절한 정규화 방법을 사용해서 데이터 베이스 성능을 높이도록 하고 싶다.
