Redis 도입 이유 (Memcached vs Redis vs Ehcache 비교)
서론
다양한 캐싱 솔루션중에 왜 redis를 선택했는지에 대해 써보려고
각각 캐싱 솔루션에 대해 정리해보자!
캐싱의 중요성
캐싱은 자주 사용되는 데이터를 더 빠른 저장소(메모리 등)에 저장하여 조회 속도를 높이고, 시스템 부하를 줄이는 기법이다.
캐싱을 도입하면 성능, 비용, 확장성 측면에서 다양한 이점을 얻을 수 있다.
✅ 성능 향상
- 캐시는 주로 메모리(RAM)에 데이터를 저장하기 때문에, 데이터베이스나 디스크보다 훨씬 빠른 속도로 데이터를 제공 할 수 있다.
- 실제로 nGrinder 부하 테스트를 진행했을때 데이터베이스에서 직접 조회할때보다 Redis에서 조회할때가 약 40% 빠른 성능 차이를 보였다.
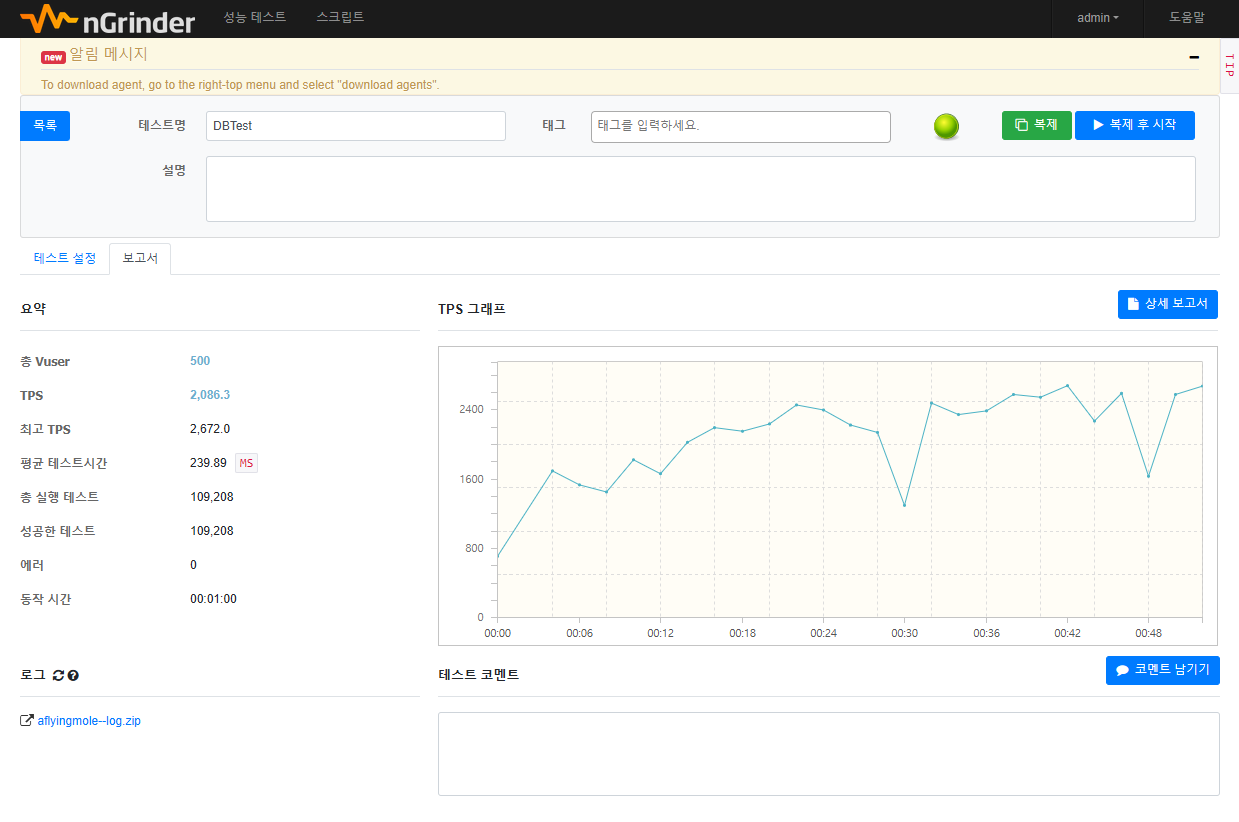
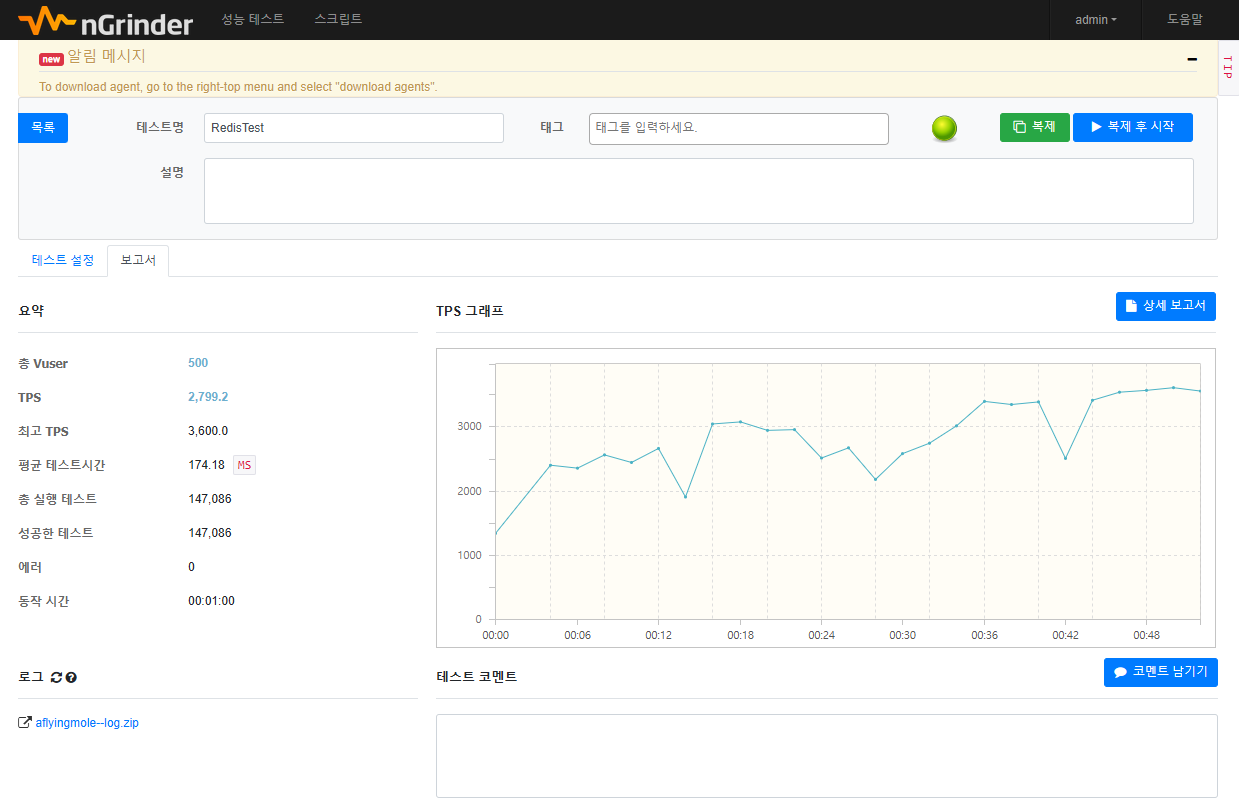
Memcached vs Ehcache vs Redis 비교
1. Memcached
장점
- 단순한 Key-Value 만 저장하기 때문에 가장 빠름
- 분산 저장 지원으로 수평 확장 가능
- 다중 스레드 지원
단점
- 데이터 구조가 단순한 (Key-Value만 지원함)
- 데이터 영속성 없음, 재시작 시 데이터 유실
- TTL이 지나도 즉시 삭제되지 않고 조회될 때 삭제됨
2. Ehcache
장점
- 디스크 저장 가능
- java 애플리케이션과 통합 용이(spring, Hibernate 등 과 잘맞음)
- L1(메모리) + L2(디스크) 캐싱 구조 지원
단점
- 분산 캐시 지원이 약함 주로 단일 서버에서 사용
- java 이외 다른 언어 에서 사용 어려움
- L1 + L2 캐싱을 사용하므로 데이터가 디스크에 저장될 경우 상대적으로 느림
3. Redis
장점
- 다양한 데이터 구조 지원(List, Set, Hash, Sorted Set 등)
- TTL이 지나면 자동 삭제(백그라운드에서 관리)
- 영속성 지원 (RDB, AOF)
- 수평 확장 (클러스터링) 가능
- 추가적인 기능이 많음 (Pub/Sub 등)
단점
- 단일 스레드 사용 (멀티 스레드를 지원하지 않음)
- 상대적으로 메모리 사용량이 높을 수 있음(다양한 자료구조, 영속성 등...)
내 프로젝트에서 Redis를 선택한 이유
1. 다양한 자료 구조 지원
실시간 협업 문서 편집기 프로젝트에서는 여러 사용자가 동시에 문서를 편집할 수 있기 때문에, 실시간 데이터 처리가 빠르고, 효율적인 캐싱 솔루션이 필요했다. 그중 Redis를 고른 이유는 다음과 같다.
첫번째 Memcached, Ehcache는 Key-Value 저장 방식만 지원하는 반면, Redis는 Hash, List, Set, Sorted Set등 다양한 자료구조를 제공한다.
내 프로젝트에서는 Hash 자료구조(HashOperation) 사용하여 데이터를 저장했는데 만약 Memcached나 Ehcache를 사용했다면 Key-Value 저장 방식만 지원하기 때문에 Hash를 쓰려면 직렬화된 JSON/String 형태로 저장해야한다. 이렇게 사용하게 되면 조회, 수정시 전체 데이터를 파싱해야하는 비효율이 발생한다. 반면 Redis는 Hash자료구조를 지원하기 때문에 특정 데이터를 직접 조회하거나 수정이 가능하다. 결과적으로 Memcached와 Ehcache는 시간복잡도를 O(n)이고, Redis는 O(1)이기 때문에 협업 문서 편집기 프로젝트 에서는 Redis가 적합하다고 생각했다.
2. TTL(Time To Live)
내 프로젝트에서는 이메일 인증을 통한 회원가입 기능을 지원한다. 이메일 인증 코드는 짧은 시간 동안만 유지하면 되는 데이터라고 판단하여 캐싱을 하기로 결정했다. 그중 TTL 기능을 사용하여 데이터의 생명주기 관리를 편리하게 하였다.
세 가지 솔루션 모두 TTL 기능을 지원하지만, Redis를 고른 이유는 다음과 같다.
첫번째. Memcached는 TTL이 지나더라도 백그라운드에서 즉시 삭제하지 않으며, 조회 요청이 발생할 때 만료된 데이터를 제거한다. 하지만 Redis에는 백그라운드에서 만료된 데이터를 자동으로 삭제를 하기때문에 남아 있지않는다.
두번째. Ehcache는 TTL 설정을 캐시 영역 단위로 적용해야 한다. 즉, 개별 데이터에 대해 TTL을 설정할 수 없기 때문에 개별적인 데이터에 대해서는 TTL 설정이 어렵다. 반면, Redis는 각각의 Key별로 TTL을 설정할 수 있어, 세부적인 데이터 관리가 용이하다. (버전 업 이후로 개별 데이터 마다 TTL지정이 가능해졌다..)
결론
여러가지 캐싱 솔루션에 대해서 공부해보고 내 프로젝트에 맞는 기술을 선택해 보았다. 향후에 Redis의 Stream를 활용해서 문서 변경이력을 저장하고 특정 시점으로 되돌리는 버전 롤백 기능을 구현해보고싶다.
