
지난 팀원들간 코어 시간을 보내며 궁금했던 점을 정리해보았다.
Question
Q1. 버퍼 오버 플로우와 스택 가드(스택 카나리)
- 스택 가드(Stack Guard)는 스택 카나리(Stack Canary)라는 기술을 이용해 버퍼 오버플로우 공격을 방어하는 대표적인 보호 기법입니다.
'스택 가드'는 이 기술의 초기 구현체 이름이었고, 지금은 '스택 카나리'가 이 기술 자체를 가리키는 일반적인 용어로 더 널리 쓰입니다.
핵심 아이디어: '카나리아' 새 🐦
이 기술의 이름은 과거 광부들이 유독가스를 탐지하기 위해 탄광에 카나리아 새를 데리고 들어간 것에서 유래했습니다. 카나리아는 사람보다 유독가스에 민감해서, 만약 새가 죽으면 광부들은 위험을 감지하고 즉시 대피했습니다.
스택 가드(스택 카나리)의 작동 방식
스택 가드는 컴파일러가 프로그램을 만들 때, 함수가 시작되고 끝나는 지점에 특별한 코드를 추가하여 작동합니다.
1. 함수 시작: 카나리아 값 삽입
함수가 호출되면, 지역 변수(버퍼)와 반환 주소(Return Address)라는 매우 중요한 데이터 사이에 '카나리'라고 불리는 무작위 값을 몰래 숨겨둡니다.
스택 메모리 구조
반환 주소 (공격자의 최종 목표)
카나리 값 (비밀 감시병) ⬅️ 여기에 숨겨둠
버퍼 (공격 경로)
2. 버퍼 오버플로우 발생
해커가 버퍼의 크기를 초과하는 악의적인 데이터를 보내면, 이 데이터는 버퍼를 넘어 주변 메모리를 덮어쓰기 시작합니다. 이때 공격자가 최종 목표인 '반환 주소'에 도달하기 전에 반드시 '카나리' 값을 먼저 덮어쓰게 됩니다.
3. 함수 종료 직전: 카나리아 값 검사
함수가 종료되어 원래 위치로 돌아가기 직전, 컴파일러가 추가해 둔 코드가 스택에 저장된 카나리 값이 원래의 값과 일치하는지 검사합니다.
4. 결과
- 일치하는 경우 (공격 없음): 카나리 값이 변하지 않았으므로, 메모리가 안전하다고 판단하고 함수를 정상적으로 종료합니다.
- 불일치하는 경우 (공격 감지): 카나리 값이 변경된 것을 보고 "스택이 공격받았다(Stack Smashing Detected)!"고 판단합니다. 프로그램은 즉시 실행을 강제 종료시킵니다.
Q2. 스택 오버 플로우
스택 오버플로우(Stack Overflow)는 한정된 크기의 접시 보관통(스택 메모리)에 너무 많은 접시(함수 호출 정보)를 쌓아 더 이상 공간이 없을 때 발생하는 에러입니다. 이는 주로 재귀 함수(Recursive function)를 잘못 사용했을 때 발생하며, 프로그램이 비정상적으로 종료되는 원인이 됩니다.
스택은 무슨 역할을 할까
컴퓨터 메모리에는 스택(Stack)이라는 특별한 영역이 있습니다. 이 공간은 함수의 호출을 관리하기 위해 사용됩니다.
- 함수 호출: 프로그램이 함수를 호출하면, 그 함수의 지역 변수, 매개변수, 그리고 함수가 끝난 뒤 돌아갈 위치(반환 주소) 정보가 담긴 '스택 프레임(Stack Frame)'이라는 묶음이 스택의 맨 위에 쌓입니다. (새 접시를 쌓는 것)
- 함수 반환: 함수가 종료되면, 맨 위에 있던 스택 프레임이 제거됩니다. (맨 위 접시를 치우는 것)
왜 발생할까요? (가장 흔한 원인)
스택 메모리의 크기는 한정되어 있습니다. 스택 오버플로우는 이 한정된 공간이 가득 찰 때까지 스택 프레임이 계속 쌓일 때 발생합니다.
가장 흔한 원인은 '무한 재귀' 또는 '너무 깊은 재귀'입니다.
재귀 함수는 자기 자신을 계속해서 호출하는데, 호출이 멈추는 지점(탈출 조건, base case)이 없으면 함수가 끝나지 않고 무한정 스택 프레임을 쌓게 됩니다.
// 무한 재귀를 일으키는 함수 예시
void overflow_function() {
// 탈출 조건 없이 자기 자신을 계속 호출한다.
overflow_function();
}
int main() {
overflow_function(); // 이 함수를 실행하면 스택 오버플로우 발생
return 0;
}위 코드에서 overflow_function()이 호출될 때마다 스택에 프레임이 쌓이고, 이 함수는 자기 자신을 또 호출하여 프레임을 계속 쌓습니다. 결국 스택에 할당된 메모리 공간을 모두 소진하면, 운영체제는 프로그램을 강제로 종료시키며 "Stack Overflow" 에러를 발생시킵니다.
버퍼 오버플로우와는 어떻게 다른가요? 💥
두 용어는 비슷해 보이지만 완전히 다른 문제입니다.
- 버퍼 오버플로우: 접시 하나(버퍼)에 음식을 너무 많이 담아, 음식이 넘쳐서 옆에 있던 컵(다른 데이터/반환 주소)을 덮치는 상황입니다. 이는 주로 보안 취약점으로 이어집니다.
- 스택 오버플로우: 접시 보관통 전체(스택)가 너무 많은 접시(함수 호출)로 가득 차서, 더 이상 새 접시를 넣을 공간이 없는 상황입니다. 이는 주로 프로그램 로직 에러로 인한 자원 고갈 문제입니다.
비교 요약
| 구분 | 버퍼 오버플로우 (Buffer Overflow) | 스택 오버플로우 (Stack Overflow) |
|---|---|---|
| 원인 | 하나의 버퍼에 정해진 크기보다 큰 데이터를 복사 | 너무 많은 함수 호출로 스택 공간 전체를 소진 |
| 결과 | 메모리 변조, 악성 코드 실행 가능 | 프로그램 비정상 종료 (Crash) |
| 종류 | 보안 취약점 | 런타임 에러 |
Q3. 자바, 파이썬이나 내부에서 C언어를 사용한다면 어떤식으로 컴파일이 시스템이 동작하는지
미리 컴파일된 C언어들이 내부에 존재하며 필요시 해당 부분이 실행된다.
Q4. 컴파일시 확장자
.c: C 소스 코드 파일
사람이 C언어 문법에 맞게 작성한 원본 텍스트 파일이에요. 프로그래머가 편집기에서 직접 코드를 작성하고 저장하는 바로 그 파일이죠.
.i: 전처리된 C 소스 코드 파일
#include나 #define 같은 전처리 지시문이 모두 처리된 후의 깨끗한 C 소스 코드 파일이에요. 여전히 사람이 읽을 수 있는 텍스트 형태죠. 예를 들어, #include <stdio.h>가 있다면 그 자리에 stdio.h 파일의 내용 전체가 복사되어 들어가요.
.s: 어셈블리어 파일
컴파일러가 .i 파일을 번역하여 만든 어셈블리어 코드 파일이에요. 기계어와 일대일로 대응되지만, 아직 사람이 읽을 수 있는 텍스트 형태를 유지하고 있어요. (예: mov, add, jmp)
.o: 오브젝트 파일
어셈블러가 어셈블리어 파일(.s)을 실제 컴퓨터가 이해할 수 있는 0과 1의 기계어로 번역한 이진 파일이에요. 이 파일은 완전한 프로그램이 아니라, printf 같은 외부 함수의 연결 정보가 빠져있는 미완성된 코드 조각이죠.
Q5. 여러 파일 시그니처
이미지 파일 (Image Files) 🖼️
- JPEG:
FF D8 FF E0또는FF D8 FF DB - PNG:
89 50 4E 47(.PNG의 ASCII 값) - GIF:
47 49 46 38(GIF8의 ASCII 값) - BMP:
42 4D(BM의 ASCII 값)
문서 파일 (Document Files) 📄
- PDF:
25 50 44 46(%PDF의 ASCII 값) - Microsoft Office (docx, pptx, xlsx):
50 4B 03 04(압축 파일(PKZip) 형식이라서 압축 파일 시그니처와 동일합니다.) - HWP (한글):
D0 CF 11 E0 A1 B1 1A E1
실행 파일 및 아카이브 (Executable & Archive Files) ⚙️
- Windows 실행 파일 (EXE/DLL):
4D 5A(MZ의 ASCII 값) - 리눅스 실행 파일 (ELF):
7F 45 4C 46(.ELF의 ASCII 값) - ZIP:
50 4B 03 04 - RAR:
52 61 72 21(Rar!의 ASCII 값)
Q6. 엔터를 치기전 키보드 내부 버퍼에 저장하는지
키보드 입력 과정
- 키보드 컨트롤러: 키를 누르면, 키보드 내부의 컨트롤러가 해당 키의 고유 코드(스캔 코드)를 생성하여 즉시 컴퓨터의 USB 포트로 보냅니다. 여기에는 아주 작은 임시 버퍼가 있지만, 글자를 쌓아두는 용도는 아닙니다.
- 운영체제 커널: 인터럽트를 통해 신호를 받은 커널은 이 스캔 코드를 실제 문자(예: 'a')로 변환합니다.
- 키보드 버퍼: 커널은 이 변환된 문자를 자신이 관리하는 키보드 버퍼에 차곡차곡 쌓아둡니다. 셸(명령 프롬프트)과 같은 현재 활성화된 프로그램은 이 버퍼를 계속 지켜보고 있습니다.
- 엔터 입력: 엔터 키를 누르면, 셸 프로그램은 "아, 이제 사용자의 입력이 끝났구나"라고 인지하고, 운영체제의 키보드 버퍼에 쌓여있던 전체 문자열을 가져가서 명령어로 해석하고 실행합니다.
실시간 신호 전달 과정
- 키 누름 (즉시): 사용자가 키보드의 'A' 키를 누릅니다.
- 컨트롤러의 신호 생성 (즉시): 키보드 내부의 컨트롤러는 'A' 키에 해당하는 스캔 코드(scan code)를 생성합니다. 컨트롤러의 아주 작은 내부 버퍼는 이 신호를 컴퓨터로 보내기 위해 아주 잠깐만 사용될 뿐, 데이터를 저장하지 않습니다.
- 인터럽트 발생 (즉시): 생성된 스캔 코드는 전기 신호로 즉시 컴퓨터에 전달되고, CPU에 인터럽트를 발생시킵니다.
- 커널의 데이터 저장 (즉시): 인터럽트를 받은 커널은 키보드 드라이버를 통해 스캔 코드를 'A'라는 문자로 해석하고, 이 문자를 커널의 키보드 버퍼에 저장(추가)합니다.
이 모든 과정은 사람이 인지할 수 없을 정도로 빠르게, 거의 실시간으로 일어납니다. 따라서 컨트롤러의 데이터가 커널로 '가는 시점'은 키를 누르는 바로 그 순간이라고 생각하시면 됩니다.
키보드 입력과 DMA
DMA는 대량의 데이터를 빠르게 전송하여 CPU의 부담을 줄일 때 의미가 있습니다.
키보드 입력은 다음과 같은 특징 때문에 DMA를 사용할 필요가 없습니다.
- 데이터 양이 매우 적음: 키를 한 번 누를 때 발생하는 데이터는 고작 몇 바이트에 불과합니다. 이 정도의 작은 데이터를 옮기기 위해 DMA를 설정하고 실행하는 것은 오히려 더 비효율적입니다.
- CPU 부담이 거의 없음: 키 입력 시 발생하는 인터럽트는 CPU가 처리하는 데 아주 짧은 시간만 소요되므로, 굳이 DMA를 사용할 실익이 없습니다.
결론적으로, DMA는 디스크, 네트워크 카드, 그래픽 카드처럼 한 번에 수백 KB 이상의 큰 데이터를 옮기는 작업에 사용되고, 키보드처럼 데이터 양이 적고 빈번한 입력은 CPU가 인터럽트를 통해 직접 처리하는 것이 훨씬 효율적입니다.
1.7 운영체제는 하드웨어를 관리한다.
hello 프로그램이 실행되고 메시지를 출력할 때, 프로그램이 직접 키보드, 디스플레이, 디스크 같은 하드웨어를 제어한 것이 아니라 운영체제(Operating System, OS)가 제공하는 서비스를 이용했습니다.
운영체제는 응용 프로그램과 하드웨어 사이에 위치하는 소프트웨어 계층으로 생각할 수 있습니다. 응용 프로그램이 하드웨어를 조작하려는 모든 시도는 반드시 운영체제를 거쳐야 합니다.
운영체제의 주요 목적은 두 가지입니다.
- 하드웨어 보호: 잘못된 프로그램이 하드웨어를 오용하여 시스템 전체를 망가뜨리는 것을 방지합니다.
- 단순하고 통일된 사용법 제공: 복잡하고 제각각인 하드웨어 장치들을 응용 프로그램이 간단하고 일관된 방식으로 사용할 수 있게 해줍니다.
운영체제는 이 두 가지 목표를 달성하기 위해 프로세스(Process), 가상 메모리(Virtual Memory), 파일(File)이라는 세 가지 핵심적인 추상화(Abstraction) 개념을 사용합니다.
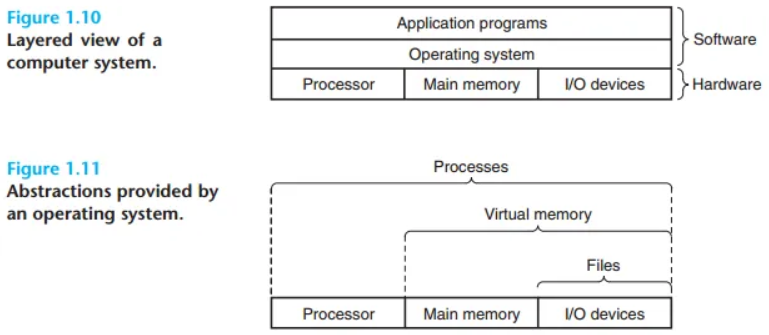
1.7.1. 프로세스 (Process)
현대 시스템에서 hello 같은 프로그램이 실행될 때, 운영체제는 마치 시스템에 이 프로그램 하나만 실행되고 있는 것 같은 착각을 제공합니다. 프로그램은 프로세서, 주기억장치, 입출력 장치를 독점적으로 사용하는 것처럼 보입니다.
이러한 환상은 컴퓨터 과학의 가장 중요한 개념 중 하나인 프로세스를 통해 제공됩니다.
- 프로세스란?: 실행 중인 프로그램을 운영체제가 추상화한 개념입니다.
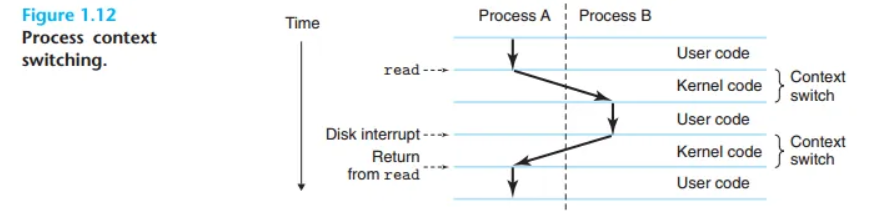
- 동시성 (Concurrency): 하나의 시스템에서 여러 프로세스가 동시에 실행될 수 있으며, 각 프로세스는 하드웨어를 독점하는 것처럼 보입니다. 실제로는 하나의 CPU가 여러 프로세스 사이를 매우 빠르게 전환하며 실행하기 때문에 동시에 실행되는 것처럼 보이는 것입니다. 이 전환 기술을 문맥 교환(Context Switch)이라고 합니다.
- 문맥 (Context): 프로세스가 실행되는 데 필요한 모든 상태 정보(예: 프로그램 카운터(PC)의 현재 값, 레지스터 값, 주기억장치 내용 등)를 의미합니다. 운영체제는 한 프로세스에서 다른 프로세스로 제어권을 넘길 때, 현재 프로세스의 문맥을 저장하고 새 프로세스의 문맥을 복원합니다.
- 커널 (Kernel): 운영체제의 핵심 부분으로, 항상 메모리에 상주하며 프로세스 관리와 같은 시스템의 모든 것을 관리합니다. 응용 프로그램이 파일 읽기/쓰기 등 커널의 도움이 필요할 때 시스템 콜(System Call)을 통해 커널에 제어권을 넘깁니다.
- 같은 프로세스 두 개를 생성하면 코드, 데이터 영역은 같을텐데 어떻게 관리할까? 운영체제는 메모리를 효율적으로 사용하기 위해 코드(Code) 영역은 공유하고, 데이터(Data) 영역은 복사해서 관리합니다. 이때 '쓰기 시 복사(Copy-on-Write)'라는 아주 똑똑한 기술이 사용됩니다.
코드 영역 (.text): 읽기 전용으로 '공유'
프로그램의 실행 명령어들이 담긴 코드 영역은 실행 중에 내용이 바뀌지 않는 읽기 전용(Read-only)입니다. 따라서 같은 프로그램을 실행하는 여러 프로세스가 이 영역을 각자 메모리에 둘 필요가 없습니다.
- 관리 방식:
- 운영체제는 프로그램이 처음 실행될 때, 코드 영역을 물리적 메모리(RAM)에 단 한 번만 올립니다.
- 이후 같은 프로그램으로 두 번째, 세 번째 프로세스가 생성되면, 운영체제는 코드를 또 로드하지 않습니다. 대신, 새로 생성된 프로세스의 가상 메모리 주소를 이미 올라와 있는 동일한 물리 메모리 주소에 연결(mapping)시켜 줍니다.
데이터 영역 (.data, .bss): '쓰기 시 복사(Copy-on-Write)'
전역 변수나 정적 변수 등이 담긴 데이터 영역은 프로세스마다 고유한 값을 가질 수 있으므로 독립적으로 관리되어야 합니다. 하지만 프로세스를 생성할 때마다 모든 데이터 영역을 무조건 복사하는 것은 비효율적일 수 있습니다.
- 관리 방식 (쓰기 시 복사, COW):
- 초기에는 공유: 프로세스를 새로 생성(예:
fork()시스템 콜)하면, 운영체제는 일단 데이터 영역을 복사하지 않고 부모 프로세스의 데이터 영역을 함께 가리키도록 합니다. 단, 이 공유된 페이지를 '읽기 전용'으로 표시해 둡니다. - '쓰기' 시도: 둘 중 어떤 프로세스라도 이 공유된 데이터 영역에 값을 쓰려고(수정하려고) 시도하면, CPU는 '읽기 전용' 페이지에 쓰려 했다는 것을 감지하고 페이지 폴트(Page Fault)라는 예외를 발생시켜 운영체제에 알립니다.
- '복사' 실행: 운영체제는 이 페이지 폴트가 '쓰기 시 복사' 때문이라는 것을 확인하고, 그제서야 해당 데이터 페이지를 새로운 물리 메모리 공간에 복사합니다.
- 연결 변경: 그리고 쓰기를 시도했던 프로세스의 가상 메모리 주소를 이 새로 복사된 페이지에 연결하고, 이 페이지를 '쓰기 가능'으로 변경합니다.
- 이제 두 프로세스는 서로 독립된 데이터 영역을 가지게 되며, 각자 자유롭게 값을 수정할 수 있습니다.
요약
| 구분 | 코드 영역 (.text) | 데이터 영역 (.data) |
|---|---|---|
| 관리 방식 | 공유 (Sharing) | 쓰기 시 복사 (Copy-on-Write) |
| 이유 | 내용이 변하지 않으므로, 메모리 절약을 위해 | 프로세스별로 내용이 바뀔 수 있으므로, 독립성을 보장하기 위해 |
| 비유 | 도서관 참고서적 (모두가 함께 봄) | 공용 양식 파일 (수정 시 사본 생성) |
- 페이지 폴트(Page Fault)란?
페이지 폴트(Page Fault)란 프로그램이 사용하려는 데이터가 물리 메모리(RAM)에 없어 CPU가 실행을 중단하고 운영체제에 도움을 요청하는 일종의 인터럽트입니다. 이는 오류가 아니라, 가상 메모리 시스템이 작동하기 위한 정상적인 과정 중 하나입니다.
페이지 폴트의 역할과 과정
가상 메모리 시스템에서 모든 데이터가 항상 RAM에 올라와 있는 것은 비효율적입니다. 따라서 운영체제는 당장 필요하지 않은 데이터는 디스크에 내려놓고, RAM에는 자주 쓰는 데이터만 올려놓습니다.
비유: 도서관에서 공부하기 📖
- 물리 메모리(RAM): 내 책상 (작지만 빠름)
- 디스크: 도서관 서가 (크지만 느림)
- CPU: 나 자신
- 페이지 폴트: 책상에 없는 책을 찾으러 도서관에 가는 행위
페이지 폴트가 발생하는 과정은 다음과 같습니다.
- 접근 시도: CPU(나)가 특정 데이터(책의 특정 페이지)를 읽으려고 메모리에 접근합니다.
- 페이지 폴트 발생: 하지만 해당 데이터는 현재 물리 메모리(책상)에 없습니다. 이때 CPU는 페이지 폴트라는 하드웨어 인터럽트를 발생시키고 실행을 멈춥니다.
- 운영체제의 개입: 인터럽트를 받은 운영체제(사서)가 상황을 파악합니다.
- 유효한 접근: "이 데이터는 디스크(도서관 서가)에 있으니 가져와야겠다"고 판단합니다.
- 무효한 접근: 만약 접근 권한이 없는 메모리 영역에 접근한 것이라면, 프로그램에 오류(Segmentation Fault)를 내고 강제 종료시킵니다.
- 데이터 로딩: 운영체제는 디스크에서 해당 데이터를 찾아 비어있는 물리 메모리 공간에 로드합니다. (사서가 도서관 서가에서 책을 찾아 내 책상에 가져다줍니다.)
- 작업 재개: 데이터 로딩이 끝나면, 운영체제는 멈췄던 프로그램을 다시 실행시킵니다. 이제 CPU는 아무 일 없었다는 듯이 RAM에 올라온 데이터를 정상적으로 사용할 수 있습니다.
1.7.2. 스레드 (Threads)
하나의 프로세스는 전통적으로 하나의 실행 흐름을 갖지만, 현대 시스템에서는 스레드(Thread)라는 여러 개의 실행 단위로 구성될 수 있습니다. 한 프로세스 내의 스레드들은 코드와 전역 데이터를 공유하며, 프로세스보다 더 효율적으로 동작하기 때문에 동시성 프로그래밍에서 매우 중요합니다.
1.7.3. 가상 메모리 (Virtual Memory)
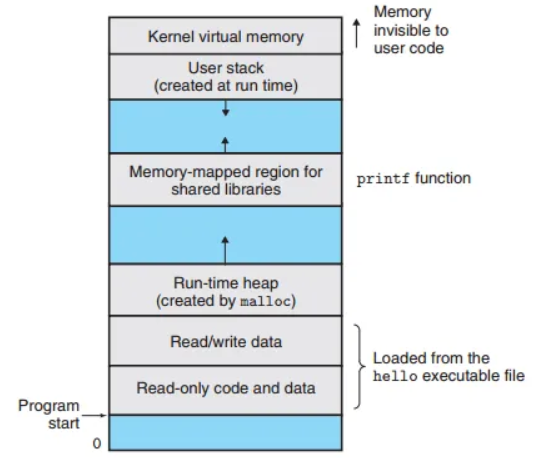
가상 메모리는 각 프로세스가 주기억장치(RAM) 전체를 독점적으로 사용하는 것 같은 환상을 제공하는 추상화 개념입니다. 각 프로세스는 가상 주소 공간(Virtual Address Space)이라는 동일하고 독립적인 메모리 구조를 갖게 됩니다.
실제로는 디스크에 각 프로세스의 메모리 내용을 저장해두고, 주기억장치를 디스크의 캐시처럼 사용하여 이런 환상을 만들어냅니다. 가상 주소 공간은 다음과 같이 여러 영역으로 나뉩니다.
- 프로그램 코드 및 데이터: 실행 파일로부터 로드된 기계어 코드와 전역 변수들이 저장됩니다.
- 힙 (Heap): 프로그램 실행 중에
malloc이나free함수 호출을 통해 동적으로 크기가 변하는 메모리 영역입니다. - 공유 라이브러리: C 표준 라이브러리처럼 여러 프로세스가 공유하는 코드와 데이터가 위치합니다.
- 스택 (Stack): 함수 호출 시 사용되는 영역으로, 함수를 호출할 때마다 커지고 함수에서 반환될 때마다 작아집니다.
- 커널 가상 메모리: 운영체제 커널을 위한 공간으로, 응용 프로그램은 접근할 수 없습니다.
1.7.4. 파일 (Files)
파일은 단순히 바이트(byte)의 연속입니다. 디스크, 키보드, 디스플레이, 네트워크 등 모든 입출력(I/O) 장치는 파일이라는 개념으로 모델링됩니다. 시스템의 모든 입출력은 파일을 읽고 쓰는 방식으로 수행됩니다.
이 단순한 '파일'이라는 개념은 응용 프로그램에게 모든 종류의 입출력 장치를 통일된 방식으로 바라볼 수 있게 해주는 매우 강력한 추상화입니다. 예를 들어, 프로그래머는 디스크 기술의 종류와 상관없이 동일한 방식으로 파일에 접근하는 코드를 작성할 수 있습니다.
1.8 시스템은 네트워크를 이용해 다른 시스템과 통신한다.
지금까지 시스템을 독립된 하드웨어와 소프트웨어의 집합으로 다루었지만, 실제 현대 시스템들은 네트워크를 통해 다른 시스템들과 연결되어 있습니다.
개별 시스템의 관점에서 보면 네트워크는 또 하나의 입출력(I/O) 장치로 볼 수 있습니다. 시스템이 주기억장치에서 네트워크 어댑터로 데이터를 복사하면, 그 데이터는 로컬 디스크가 아닌 네트워크를 통해 다른 컴퓨터로 흘러갑니다. 반대로 다른 컴퓨터에서 보낸 데이터를 읽어 자신의 주기억장치로 복사할 수도 있습니다.
인터넷과 같은 글로벌 네트워크의 출현으로, 컴퓨터 간에 정보를 복사하는 것은 시스템의 가장 중요한 용도 중 하나가 되었습니다. 이메일, 웹, FTP 등 우리에게 익숙한 응용 프로그램들은 모두 네트워크를 통해 정보를 복사하는 능력에 기반하고 있습니다.
네트워크를 통해 원격으로 hello 프로그램 실행하기
우리가 사용했던 hello 예제를 원격 컴퓨터에서 실행하기 위해 텔넷(telnet)과 같은 네트워크 응용 프로그램을 사용할 수 있습니다.
로컬 컴퓨터의 텔넷 클라이언트(client)를 사용하여 원격 컴퓨터의 텔넷 서버(server)에 접속했다고 가정해 봅시다. 원격 컴퓨터에 로그인하고 셸을 실행하면, 원격 셸은 명령어 입력을 기다립니다. 여기서부터 hello 프로그램을 원격으로 실행하는 과정은 다음 5단계로 이루어집니다.
- 입력: 사용자가 로컬 컴퓨터에서
hello라는 문자열을 입력하고 엔터 키를 누릅니다. - 클라이언트 → 서버: 텔넷 클라이언트는 이 문자열을 네트워크를 통해 원격 텔넷 서버로 전송합니다.
- 서버 내부 처리: 텔넷 서버는 네트워크로부터 문자열을 받아 원격 셸 프로그램에 전달합니다. 원격 셸은
hello프로그램을 실행하고, 그 결과물(hello, world\n)을 다시 텔넷 서버로 넘겨줍니다. - 서버 → 클라이언트: 텔넷 서버는 전달받은 결과 문자열을 다시 네트워크를 통해 로컬 텔넷 클라이언트로 전송합니다.
- 출력: 텔넷 클라이언트는 전달받은 결과 문자열을 로컬 컴퓨터의 화면에 출력합니다.
이러한 클라이언트와 서버 간의 데이터 교환은 모든 네트워크 응용 프로그램의 전형적인 동작 방식입니다.
1.9 시스템에서 중요한 주제들
시스템은 응용 프로그램을 실행하는 궁극적인 목표를 달성하기 위해 하드웨어와 시스템 소프트웨어가 서로 얽혀 협력하는 집합체입니다.
1.9.1. 암달의 법칙 (Amdahl’s Law)
암달의 법칙은 시스템의 한 부분의 성능을 개선했을 때 전체 시스템 성능에 미치는 영향에 대한 단순하지만 통찰력 있는 관찰입니다. 핵심 아이디어는 특정 부분의 개선 효과가 그 부분이 원래 얼마나 중요했는지(비중)와 얼마나 빨라졌는지(개선율)에 따라 결정된다는 것입니다.
- 수식:
어떤 작업에 Told 시간이 걸리고, 그중 α의 비율을 차지하는 부분의 성능을 k배 향상시켰을 때, 새로운 실행 시간 와 전체 성능 향상률(Speedup) S는 다음과 같습니다.
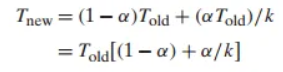
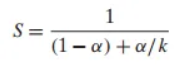
- 예시:
시스템의 60%(α=0.6)를 차지하는 부분의 속도를 3배(k=3) 빠르게 만들었다고 가정해 봅시다. 전체 성능 향상률은 1/((1−0.6)+0.6/3)=1/(0.4+0.2)=1/0.6=1.67배에 그칩니다. - 핵심 통찰:
시스템 전체의 성능을 크게 향상시키려면, 시스템의 아주 큰 부분을 개선해야만 한다는 것입니다. 한 부분을 아무리 극단적으로 개선해도(예: k→∞), 전체 성능 향상률은 를 넘을 수 없습니다. (위 예시에서는 1/0.4=2.5배가 한계입니다.)
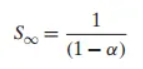
1.9.2. 동시성(Concurrency)과 병렬성(Parallelism)
컴퓨터의 발전은 '더 많은 일을' 그리고 '더 빠르게'라는 두 가지 요구에 의해 주도되어 왔습니다. 이 두 가지는 프로세서가 한 번에 더 많은 일을 처리할 때 향상됩니다.
- 동시성 (Concurrency): 여러 활동이 동시에 진행되는 시스템의 일반적인 개념입니다.
- 병렬성 (Parallelism): 동시성을 활용하여 시스템을 더 빠르게 실행시키는 것을 의미합니다.
병렬성은 시스템의 여러 수준에서 활용될 수 있습니다.
스레드 수준 병렬성 (Thread-Level Parallelism)
여러 프로그램이나 한 프로그램 내의 여러 스레드가 동시에 실행되는 것을 의미합니다.
- 단일 프로세서 시스템 (Uniprocessor system): 하나의 CPU가 여러 작업을 매우 빠르게 전환(Context Switching)하며 동시에 처리되는 것처럼 보이게 합니다.
- 다중 프로세서 시스템 (Multiprocessor system): 여러 개의 CPU를 사용하여 여러 작업을 실제로 동시에 처리합니다.
- 멀티코어 프로세서 (Multi-core processor): 하나의 칩에 여러 개의 CPU(코어)를 통합한 것입니다.
- 하이퍼스레딩 (Hyperthreading): 하나의 코어가 여러 스레드를 동시에 실행하는 것처럼 보이게 하는 기술입니다. 하나의 스레드가 데이터를 기다리는 동안 다른 스레드를 실행하여 CPU 자원의 활용도를 높입니다.
- 하이퍼스레딩 : 하드웨어 스레딩
하이퍼스레딩은 인텔(Intel) CPU에 적용된 하드웨어 스레딩 기술의 상표명입니다.
하드웨어 스레딩과 하이퍼스레딩
- 하드웨어 스레딩 (Hardware Threading): 하나의 물리적인 CPU 코어(Core)를 운영체제(OS)에게 여러 개의 논리적인 코어(Logical Core)처럼 보이게 만드는 기술의 일반적인 명칭입니다. SMT(Simultaneous Multi-Threading, 동시 멀티스레딩) 라고도 불립니다.
- 하이퍼스레딩 (Hyper-Threading): 인텔이 개발하여 자사의 CPU에 적용한 SMT 기술의 브랜드 이름입니다.
작동 원리
하나의 코어 안에는 연산 장치, 레지스터, 캐시 등 여러 구성 요소가 있습니다. 하이퍼스레딩은 이 중에서 레지스터와 프로그램 카운터(PC)처럼 각 스레드가 독립적으로 사용해야 하는 일부 요소만 복제하고, 산술논리연산장치(ALU)처럼 공유해서 쓸 수 있는 핵심 자원은 하나만 둡니다.
이를 통해 하나의 스레드가 데이터를 기다리는 등 잠시 멈추는 순간에, 다른 스레드가 그 자원을 즉시 사용하여 코어의 자원 활용률을 극대화하고 전체적인 성능을 높이는 원리입니다.
결론적으로, 하이퍼스레딩은 하드웨어 스레딩 기술의 한 종류이며, 가장 널리 알려진 상표명이라고 생각하시면 됩니다.
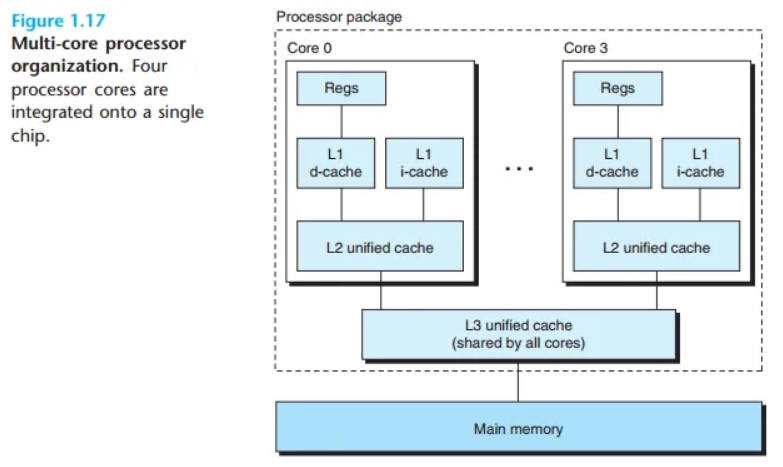
명령어 수준 병렬성 (Instruction-Level Parallelism)
현대 프로세서는 한 번에 여러 개의 명령어를 실행할 수 있습니다.
- 파이프라이닝 (Pipelining): 하나의 명령어를 여러 단계로 나누어, 각 단계가 서로 다른 명령어의 일부를 동시에 처리하는 기술입니다.
- 슈퍼스칼라 프로세서 (Superscalar processor): 매 클럭 사이클 당 1개 이상의 명령어를 처리할 수 있는 고성용 프로세서입니다.
단일 명령어, 다중 데이터 (SIMD) 병렬성
하나의 명령어로 여러 개의 데이터에 대해 동일한 연산을 병렬로 수행하는 방식입니다. 주로 이미지, 사운드, 비디오 데이터 처리 속도를 높이는 데 사용됩니다. (예: 8쌍의 실수를 한 번에 더하는 명령어)
1.9.3. 컴퓨터 시스템에서 추상화의 중요성
- 추상화(Abstraction)는 복잡한 내부 동작을 숨기고 사용자에게 단순하고 일관된 인터페이스를 제공하는 컴퓨터 과학의 가장 중요한 개념 중 하나입니다.
- 프로세서: 명령어 집합 구조(Instruction Set Architecture, ISA)는 실제 복잡한 하드웨어 동작(병렬 처리 등)을 추상화하여, 프로그래머에게는 마치 명령어가 한 번에 하나씩 순차적으로 실행되는 것처럼 보이게 합니다.
- 운영체제:
- 파일(File): 모든 종류의 입출력 장치를 '바이트의 연속'이라는 단순한 개념으로 추상화합니다.
- 가상 메모리(Virtual Memory): 실제 메모리(RAM)와 디스크를 추상화하여, 각 프로세스가 메모리 전체를 독점하는 것처럼 보이게 합니다.
- 프로세스(Process): CPU, 메모리, I/O 장치 등을 모두 추상화하여, 실행 중인 프로그램이 시스템 전체를 독점하는 것처럼 보이게 합니다.
- 가상 머신 (Virtual Machine): 운영체제를 포함한 컴퓨터 전체를 추상화하여, 하나의 컴퓨터에서 여러 다른 종류의 운영체제를 실행할 수 있게 합니다.
