
1.1 정보는 비트와 컨텍스트로 이루어진다.
파일은 텍스트 파일과 이진 파일로 나뉘며 모두 0과1로 저장이 된다. 그럼 운영체제 입장에서는 어떻게 판단할까?
운영체제는 파일의 확장자와 파일 시그니처(매직 넘버), 두 가지 단서를 통해 텍스트 파일과 이진 파일을 판단하고 구분합니다. 컴퓨터 자체는 파일을 열기 전까지 그 내용이 무엇인지 알지 못합니다.
## 파일 확장자 (File Extension) 🏷️
가장 일반적인 방법으로, 운영체제는 파일 이름 끝에 붙는 확장자를 보고 어떤 종류의 파일인지 추측합니다.
report.txt:.txt확장자를 보고 '아, 이건 텍스트 파일이구나. 메모장으로 열어야겠다.'라고 판단합니다.photo.jpg:.jpg를 보고 '이건 이미지 파일(이진 파일)이네. 이미지 뷰어를 연결해야지.'라고 판단합니다.
하지만 이것은 단순한 약속이라서, 사용자가 이미지 파일의 확장자를 .txt로 강제로 바꾸면 운영체제는 속아서 메모장으로 열려고 시도하고 결과적으로 깨진 글자가 보이게 됩니다.
## 파일 시그니처 (File Signature) 🔍
프로그램이 파일을 열 때, 파일 종류를 더 확실하게 확인하기 위해 사용하는 방법입니다. 많은 이진 파일들은 파일의 가장 맨 앞에 자신이 어떤 종류의 파일인지 알려주는 고유한 데이터(마치 신분증처럼)를 가지고 있습니다. 이를 파일 시그니처 또는 매직 넘버(Magic Number)라고 부릅니다.
- JPEG 이미지 파일: 항상
FF D8 FF E0라는 16진수 값으로 시작합니다. 이미지 뷰어는 파일을 열 때 맨 앞의 이 값을 확인하고 "아, JPG 파일이 맞구나!"라고 확신한 뒤 이미지 데이터를 해석하기 시작합니다. - PDF 문서 파일:
%PDF의 ASCII 값인25 50 44 46으로 시작합니다.
반면, 순수한 텍스트 파일은 이런 특별한 시작 값이 없습니다.
결론적으로, 운영체제는 먼저 확장자로 파일을 대략적으로 추측하고, 해당 파일을 여는 프로그램이 파일 시그니처를 통해 파일 종류를 최종적으로 확인하여 그에 맞는 규칙으로 데이터를 해석하는 것입니다.
데이터가 문자로 보이는 과정 🖥️➡️👨💻
- 근본 데이터 (저장)
- 컴퓨터 하드디스크에는
hello.txt파일이01001000 01100101 ...와 같은 이진수(0과 1)의 나열로 저장되어 있습니다. - 이 데이터를 사람이 분석하기 위해 헥스 에디터로 열면
48 65 6C 6C 6F와 같은 16진수로 보입니다. (이진 파일도 이 단계까지는 동일합니다.)
- 컴퓨터 하드디스크에는
- 사용자의 행동
- 사용자가
hello.txt파일을 더블클릭합니다.
- 사용자가
- 운영체제(OS)의 역할
- 운영체제는
.txt확장자를 보고 "아, 이건 텍스트 파일이구나. 기본 텍스트 편집기(메모장 등)로 열어줘야겠다"라고 판단합니다.
- 운영체제는
- 텍스트 편집기의 역할 (핵심!)
- 실행된 텍스트 편집기는 파일의 데이터를 읽습니다 (
48,65,6C...). - 그리고 이 숫자들을 '문자 인코딩(Character Encoding)' 규칙에 따라 번역(매핑)하기 시작합니다. 사용자가 언급한 아스키(ASCII)가 바로 이 규칙의 한 종류입니다.
- 번역 예시 (ASCII 규칙):
48→ 'H'65→ 'e'6C→ 'l'6C→ 'l'6F→ 'o'
- 실행된 텍스트 편집기는 파일의 데이터를 읽습니다 (
- 최종 결과 (표시)
- 텍스트 편집기는 이렇게 번역된 문자 'H', 'e', 'l', 'l', 'o'를 합쳐서 우리 눈에 익숙한 "Hello"라는 단어로 화면에 보여줍니다.
추가 정보: ASCII vs. UTF-8
언급하신 아스키(ASCII)는 아주 기본적인 영문 중심의 규칙입니다. 현대의 컴퓨터는 한글(가나다), 한자(漢字), 이모지(😊) 등 전 세계의 문자를 표현해야 하므로, 아스키를 포함하는 더 확장된 규칙인 UTF-8을 훨씬 더 많이 사용합니다. 하지만 기본적인 원리는 "숫자를 문자로 매핑한다"는 점에서 완전히 동일합니다.
1. C 소스 파일을 '읽는' 과정 🖥️➡️👨💻
- 근본 데이터 (저장)
hello.c파일 역시printf("Hello");같은 내용이 하드디스크에 이진수(0과 1)로 저장됩니다. 헥스 에디터로 보면70 72 69 6E 74 66 ...와 같은 16진수 값으로 보입니다.
- 사용자의 행동
- 프로그래머가
hello.c파일을 더블클릭합니다.
- 프로그래머가
- 운영체제(OS)의 역할
- 운영체제는
.c확장자를 보고 "이건 C 소스 코드 파일이구나. 일반 메모장보다는 코드 에디터(Visual Studio Code 등)로 열어주는 게 좋겠다"라고 판단합니다.
- 운영체제는
- 코드 에디터의 역할 (핵심!)
- 실행된 코드 에디터는 파일의 16진수 데이터(
70,72...)를 읽습니다. - UTF-8 같은 문자 인코딩 규칙에 따라 숫자들을 문자로 번역(매핑)합니다. (
70→'p',72→'r'...)
- 실행된 코드 에디터는 파일의 16진수 데이터(
- 최종 결과 + α (코드 에디터의 특별 기능)
- 에디터는 번역된
printf("Hello");를 화면에 보여줍니다.
- 에디터는 번역된
정리
사람이 읽을 수 있거나 작성한 소스 파일을 모두 텍스트 파일이라고 하며, 사람이 해석할 수 없다면 이진파일이다.
텍스트 파일이든 이진파일이든 컴퓨터 내부적으로 모두 0과 1로 저장되며 8비트(바이트) 단위로 묶인다.
만약 텍스트 파일이라면 에디터나 텍스트 편집기에서 아스키 코드나 UTF-8과 같은 문자 인코딩 규칙에 따라 바이트를 문자로 매핑한 후 사용자에게 문자로 보여준다.
에디터나 텍스트 편집기 등 어떤 프로그램으로 소스 파일을 열지 판단하는 것은 운영체제이다.
이때 운영체제는 확장자를 보고 어떤 프로그램으로 소스파일을 열지 판단하게 된다.
1.2 프로그램이 다른 프로그램에 의해 번역되는 과정
hello.c와 같이 사람이 읽고 이해할 수 있는 프로그래밍 언어를 고급 언어(high-level language)라고 합니다. 하지만 컴퓨터(CPU)는 이런 고급 언어를 직접 이해하지 못합니다. 따라서 컴퓨터에서 프로그램을 실행하려면, 사람이 작성한 C 코드를 컴퓨터가 이해할 수 있는 저수준의 기계어(low-level machine-language) 명령어로 번역해야 합니다.
이러한 번역 과정 전체를 컴파일 시스템(compilation system)이 담당하며, gcc 같은 컴파일러 명령어를 통해 한 번에 실행됩니다. 이 시스템은 크게 네 단계로 구성됩니다.
hello.c (텍스트) ➡️ 전처리기 ➡️ hello.i (텍스트) ➡️ 컴파일러 ➡️ hello.s (텍스트) ➡️ 어셈블러 ➡️ hello.o (이진) ➡️ 링커 ➡️ hello (이진)
1. 전처리 단계 (Preprocessing phase)
- 담당 프로그램: 전처리기 (preprocessor,
cpp) - 입력: 원본 C 소스 코드 (
hello.c- 텍스트 파일) - 처리 내용: 소스 코드에서
#으로 시작하는 지시어를 처리합니다. 예를 들어,hello.c의#include <stdio.h>지시어는 시스템 헤더 파일인stdio.h의 내용을 통째로 복사해서 소스 코드에 붙여넣으라는 의미입니다. - 출력: 수정된 C 소스 코드 (
hello.i- 텍스트 파일)
2. 컴파일 단계 (Compilation phase)
- 담당 프로그램: 컴파일러 (compiler,
cc1) - 입력: 전처리된 C 소스 코드 (
hello.i- 텍스트 파일) - 처리 내용: C 코드를 저수준의 어셈블리어 프로그램으로 번역합니다. 어셈블리어는 기계어 명령어를 사람이 읽을 수 있는 문자 형태로 표현한 언어입니다. C언어든, Fortran이든 서로 다른 고급 언어 컴파일러들이 동일한 어셈블리어를 결과물로 만들 수 있어 중간 언어로서 유용합니다.
- 출력: 어셈블리어 프로그램 (
hello.s- 텍스트 파일)
3. 어셈블리 단계 (Assembly phase)
- 담당 프로그램: 어셈블러 (assembler,
as) - 입력: 어셈블리어 프로그램 (
hello.s- 텍스트 파일) - 처리 내용: 어셈블리어를 실제 컴퓨터가 알아듣는 기계어 명령어(0과 1)로 번역합니다. 이 기계어를 재배치 가능 목적 프로그램(relocatable object program)이라는 형태로 묶습니다.
- 출력: 목적 파일 (
hello.o- 이진 파일). 이 파일부터는 텍스트 편집기로 열면 의미를 알 수 없는 외계어처럼 보입니다.
4. 링킹 단계 (Linking phase)
- 담당 프로그램: 링커 (linker,
ld) - 입력: 목적 파일 (
hello.o) 및 라이브러리 파일 (printf.o등) - 처리 내용: 우리 코드에서 사용한
printf함수는stdio.h에 선언만 되어있고, 실제 기계어 코드는 별도의 라이브러리 파일에 존재합니다. 링커는hello.o와printf함수의 코드가 담긴 파일을 하나로 합쳐서 완전한 실행 파일을 만듭니다. - 출력: 최종 실행 가능 목적 프로그램 (
hello- 이진 파일). 사용자가 터미널에서 실행하는 바로 그 파일입니다.
1.3 컴파일 시스템의 작동 원리를 알아야 하는 이유 🧠
단순한 프로그램의 경우 컴파일러가 알아서 정확하고 효율적인 코드를 만들어 줍니다. 하지만 프로그래머가 컴파일 시스템의 작동 원리를 이해해야 하는 중요한 이유는 크게 세 가지입니다.
1. 프로그램 성능 최적화 🚀
최신 컴파일러는 매우 정교해서 보통 좋은 품질의 코드를 생성합니다. 하지만 C 코드를 작성할 때 더 나은 결정을 내리려면, 기계어 코드와 컴파일러가 C 언어의 여러 구문을 어떻게 기계어로 번역하는지에 대한 기본적인 이해가 필요합니다. 예를 들면 다음과 같은 질문에 답할 수 있게 됩니다.
switch문이 항상if-else문보다 효율적일까?- 함수를 한 번 호출할 때 발생하는 비용(오버헤드)은 얼마나 될까?
while루프가for루프보다 더 효율적일까?- 포인터 참조가 배열 인덱싱보다 더 효율적일까?
- 반복문에서 참조로 전달된 인수에 값을 더하는 것보다 지역 변수에 더할 때 왜 훨씬 더 빨라질까?
- 산술 표현식에서 괄호의 순서만 바꿨는데 어떻게 함수가 더 빨리 실행될 수 있을까?
이러한 이해는 C 코드를 약간만 수정하여 컴파일러가 더 나은 코드를 생성하도록 도와 프로그램의 성능을 크게 향상시킬 수 있습니다.
2. 링킹 오류 이해하기 🔗
프로그래밍을 하면서 마주치는 가장 혼란스러운 오류 중 상당수는 링커(Linker)와 관련이 있습니다. 특히 대규모 소프트웨어를 만들 때 이런 오류는 더욱 복잡해집니다. 컴파일 원리를 이해하면 다음과 같은 질문에 답할 수 있습니다.
- 링커가 "참조를 확인할 수 없습니다(cannot resolve a reference)"라고 보고하는 것은 무슨 의미일까?
- 정적(static) 변수와 전역(global) 변수의 차이점은 무엇일까?
- 서로 다른 C 파일에 동일한 이름의 전역 변수를 정의하면 어떻게 될까?
- 정적 라이브러리와 동적 라이브러리의 차이점은 무엇일까?
- 명령줄에 라이브러리를 나열하는 순서가 왜 중요할까?
- 가장 무서운 것은, 왜 어떤 링킹 관련 오류는 프로그램을 실행할 때까지 나타나지 않을까?
3. 보안 허점 방지하기 🛡️
오랫동안 네트워크 및 인터넷 서버의 수많은 보안 허점은 버퍼 오버플로우(buffer overflow) 취약점 때문에 발생했습니다. 이 문제는 많은 프로그래머들이 신뢰할 수 없는 외부로부터 들어오는 데이터의 양과 형식을 신중하게 제한해야 할 필요성을 이해하지 못하기 때문에 발생합니다.
안전한 프로그래밍을 배우는 첫걸음은 데이터와 제어 정보가 프로그램 스택(stack)에 어떻게 저장되는지 이해하는 것입니다. 스택의 원리와 버퍼 오버플로우 취약점을 이해하면 이러한 공격의 위협을 줄이는 코드를 작성할 수 있습니다.
1.4 프로세서가 메모리에 저장된 명령어를 읽고 해석하는 과정
컴파일 시스템에 의해 hello.c 소스 프로그램은 디스크에 저장된 hello라는 실행 파일로 번역되었습니다. 이 파일을 실행시키기 위해 우리는 셸(shell) 이라는 응용 프로그램에 명령어 ./hello를 입력합니다.
셸은 명령어를 입력받아 수행하는 명령어 해석기입니다. 만약 입력된 명령어가 셸의 내장 명령어가 아니라면, 셸은 그것을 실행 파일의 이름으로 간주하고 해당 프로그램을 실행시킵니다. hello 프로그램은 화면에 메시지를 출력한 뒤 종료되고, 셸은 다시 다음 명령어를 기다립니다.
1.4.1 시스템의 하드웨어 구성
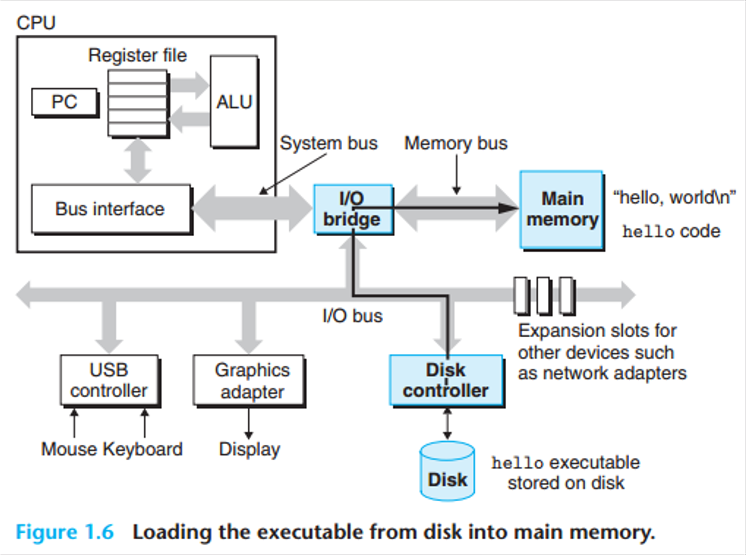
-
버스 (Buses)
시스템 전체에 걸쳐 있는 전기적 통로로, 컴포넌트 간에 정보를 주고받습니다. 버스는 워드(word)라는 고정된 크기의 바이트 덩어리를 전송하도록 설계됩니다. 워드의 크기(4바이트=32비트, 8바이트=64비트)는 시스템의 핵심적인 매개변수입니다. -
입출력 장치 (I/O Devices)
시스템과 외부 세계를 연결하는 장치입니다. 키보드/마우스(입력), 디스플레이(출력), 그리고 데이터와 프로그램을 장기간 저장하는 디스크 드라이브가 있습니다. 실행 파일hello는 처음에 디스크에 저장되어 있습니다. 각 장치는 컨트롤러나 어댑터를 통해 I/O 버스에 연결되어 정보를 교환합니다. -
주기억장치 (Main Memory)
프로세서가 프로그램을 실행하는 동안, 그 프로그램과 데이터를 일시적으로 저장하는 장치입니다. 물리적으로는 DRAM 칩으로 구성되어 있으며, 논리적으로는 0부터 시작하는 고유 주소를 가진 바이트들의 선형 배열로 구성됩니다. -
프로세서 (Processor / CPU)
주기억장치에 저장된 명령어를 해석하고 실행하는 엔진입니다. 핵심에는 프로그램 카운터(Program Counter, PC)라는 레지스터가 있는데, 이는 항상 실행할 다음 명령어의 메모리 주소를 가리킵니다. 프로세서는 PC가 가리키는 명령어를 읽고, 해석하고, 실행한 뒤 PC를 다음 명령어 주소로 업데이트하는 과정을 반복합니다.프로세서가 수행하는 기본적인 작업들은 다음과 같습니다.
-
Load: 주기억장치에서 레지스터로 데이터(바이트 또는 워드)를 복사합니다.
-
Store: 레지스터에서 주기억장치로 데이터를 복사합니다.
-
Operate: 두 레지스터의 값을 산술논리연산장치(ALU)로 복사해 연산을 수행하고, 결과를 다시 레지스터에 저장합니다.
-
Jump: 명령어에 포함된 주소로 프로그램 카운터(PC)의 값을 변경하여 실행 흐름을 바꿉니다.
-
파일 읽기는 어떻게 진행될까?
C언어에서 파일 읽기 메서드를 호출하면 내부적으로 시스템 콜을 호출한다. 시스템 콜을 소프트웨어 인터럽트이기 때문에 CPU는 하던 일을 멈추고 인터럽트 벡터를 확인하고 알맞은 인터럽트 처리 루틴을 실행하게 된다. CPU는 인터럽트 처리 루틴 내부의 입출력 드라이버 코드를 실행하게 된다. 이때 드라이버에는 입출력 컨트롤러에게 명령을 내리는 코드가 작성되어 있으며 이를 통해 입출력 컨트롤러를 제어한다. 이때 CPU는 명령만 내리고 본인의 일을 다시 진행한다.(CPU 사용률을 높이는 것이 좋기 때문) 입출력 컨트롤러는 디스크 헤더를 움직이며 데이터를 읽는다. 읽은 데이터는 디바이스 컨트롤러 내부 버퍼에 모아둔다. 이때 DMA와 소통하며 DMA는 내부 버퍼의 데이터를 메모리로 옮긴다.DMA를 통해 모든 데이터가 메모리에 올라가게 되면 이 때 한번 인터럽트를 발생시켜 CPU에게 완료 신호를 보낸다.→ DMA를 사용하는 이유는 컨트롤러 내부 버퍼에 데이터가 쌓일때마다 인터럽트를 발생시키면 CPU의 효율이 떨어지기 때문이다.
1.4.2 hello 프로그램 실행 과정
- 명령어 입력
사용자가 키보드로./hello를 입력하면, 셸 프로그램은 이 문자들을 레지스터를 거쳐 주기억장치에 저장합니다.
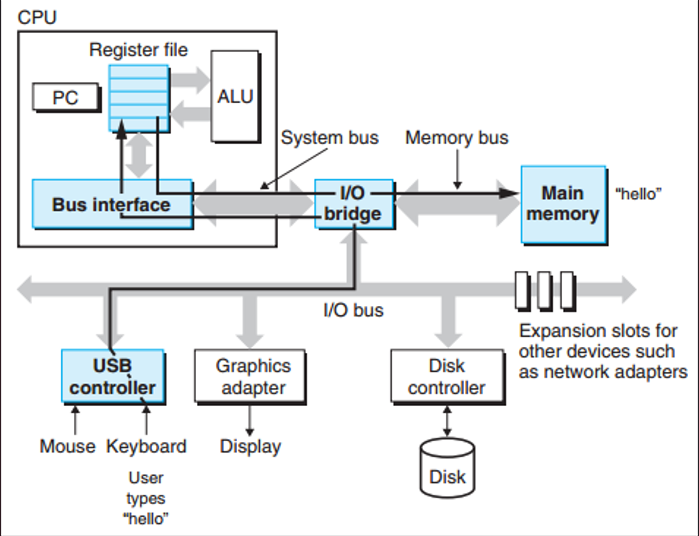
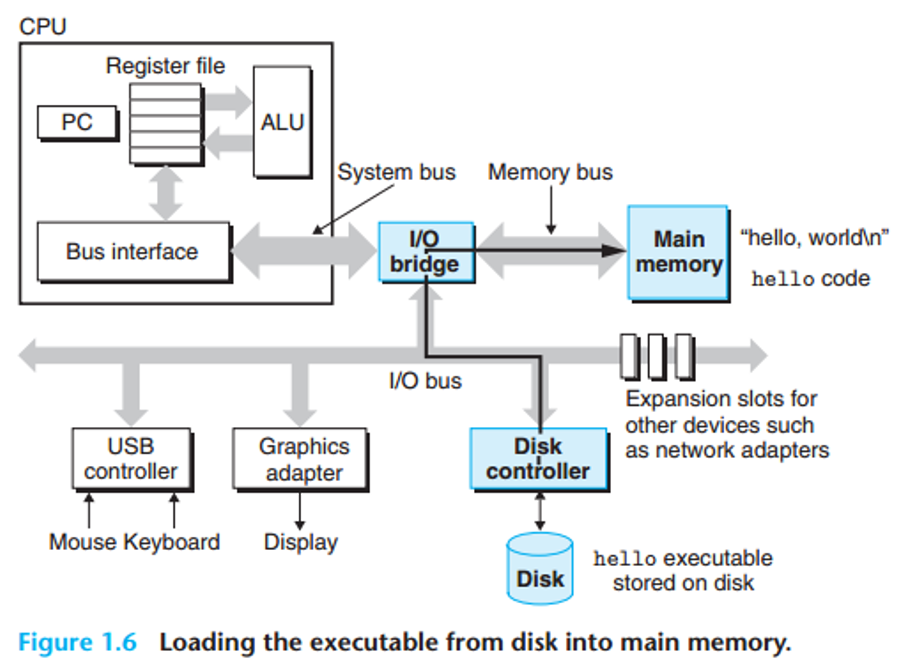
- 프로그램 로딩 (Loading)
사용자가 엔터 키를 누르면, 셸은 디스크에 저장된hello실행 파일을 주기억장치로 로딩합니다. 이 과정에서hello프로그램의 기계어 코드와"hello, world\n"라는 데이터가 주기억장치로 복사됩니다. 이 데이터는 DMA(Direct Memory Access) 기술을 통해 프로세서를 거치지 않고 디스크에서 주기억장치로 직접 전송되어 효율을 높입니다.
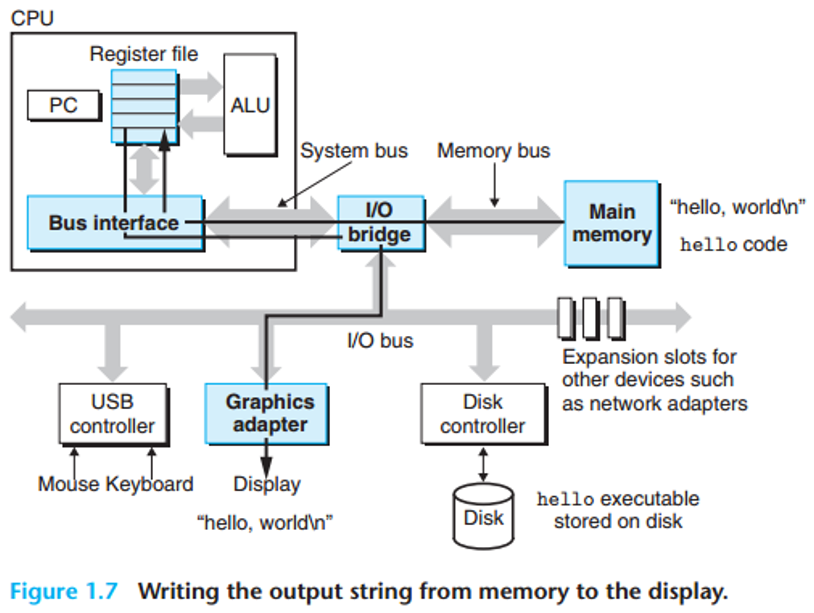
- 실행 및 출력
로딩이 완료되면, CPU는hello프로그램의main함수에 있는 기계어 명령들을 실행하기 시작합니다. 이 명령어들은 주기억장치에 있는"hello, world\n"문자열을 레지스터로, 그리고 레지스터에서 디스플레이 장치로 복사하여 최종적으로 화면에 출력합니다.
1.5 캐시 메모리가 중요한 이유
컴퓨터 시스템은 생각보다 많은 시간을 한 장치에서 다른 장치로 정보를 옮기는 데 사용합니다. 디스크에 있던 프로그램 코드는 실행될 때 주기억장치로 복사되고, CPU가 이를 실행할 때는 다시 주기억장치에서 CPU 내부로 복사됩니다. 이러한 데이터 복사 작업은 프로그램의 실제 작업을 느리게 만드는 오버헤드(overhead) 이므로, 시스템 설계자들의 주요 목표는 이 복사 속도를 최대한 빠르게 만드는 것입니다.
1. 저장 장치의 딜레마: 속도 vs. 용량/비용
물리 법칙 때문에 저장 장치는 다음과 같은 특징을 가집니다.
- 크고(용량이 큰) 장치는 작고 빠른 장치보다 느리다.
- 빠른 장치는 느린 장치보다 훨씬 비싸다.
예를 들어, 디스크는 주기억장치(RAM)보다 용량이 1,000배 더 클 수 있지만, 데이터 접근 속도는 10,000,000배나 느릴 수 있습니다. 반대로, CPU 내부의 레지스터는 주기억장치보다 용량은 수십억 분의 일에 불과하지만, 접근 속도는 거의 100배나 빠릅니다.
문제는 기술이 발전할수록 CPU의 속도는 매우 빠르게 향상되는 반면, 주기억장치의 속도는 그만큼 따라오지 못해 '프로세서-메모리 격차(processor-memory gap)'가 점점 더 벌어진다는 것입니다.
2. 해결책: 캐시 메모리 (Cache Memory)
이러한 속도 격차 문제를 해결하기 위해, 시스템 설계자들은 CPU와 주기억장치 사이에 캐시 메모리(Cache Memory)라는 작고 더 빠른 저장 장치를 둡니다. 캐시는 CPU가 가까운 미래에 필요로 할 것 같은 데이터를 미리 갖다 놓는 임시 저장소 역할을 합니다.
- 캐시 계층 (Cache Hierarchy):
- L1 캐시: CPU 칩 내부에 있으며, 용량은 수십 KB로 작지만 속도는 레지스터만큼 빠릅니다.
- L2 캐시: CPU와 특별한 버스로 연결되며, 용량은 수백 KB에서 수 MB로 더 큽니다. L1 캐시보다 약 5배 정도 느리지만, 여전히 주기억장치보다는 5~10배 빠릅니다.
- L3 캐시: 최신 고성능 시스템에는 더 큰 용량의 L3 캐시가 있기도 합니다.
3. 캐시의 작동 원리: 지역성 (Locality)
캐시가 효과적으로 동작하는 이유는 프로그램이 '지역성(Locality)'이라는 경향을 갖기 때문입니다. 지역성이란 프로그램이 특정 영역의 데이터나 코드를 반복적으로 접근하는 경향을 의미합니다.
캐시는 이러한 지역성의 원리를 이용해, 자주 사용될 것 같은 데이터를 미리 자신에게 복사해 둡니다. 덕분에 CPU는 대부분의 데이터 요청을 느린 주기억장치까지 갈 필요 없이, 바로 옆에 있는 빠른 캐시에서 처리하여 시스템 전체의 성능을 높일 수 있습니다.
- 공간 지역성 : 하나의 데이터에 접근했을 때, 그 근처에 있는 데이터에 곧이어 접근할 가능성이 높은 경향
- 시간 지역성 : 최근에 접근한 데이터에 곧 다시 접근할 가능성이 높은 경향
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += data[i]; // 변수 sum은 반복될 때마다 계속해서 접근됨
}4. 프로그래머에게 중요한 이유
이 책의 가장 중요한 교훈 중 하나는, 캐시 메모리의 존재를 아는 프로그래머는 이를 활용하여 프로그램의 성능을 수십 배까지 향상시킬 수 있다는 것입니다. 캐시의 동작 원리를 이해하면, 캐시가 더 효율적으로 작동하도록 코드를 작성할 수 있기 때문입니다.
1.6 저장장치들은 계층 구조를 이룬다.
컴퓨터의 저장 장치들은 속도, 용량, 비용에 따라 피라미드 형태의 '메모리 계층 구조(Memory Hierarchy)'를 이룹니다. 이 구조의 맨 위로 갈수록 장치는 더 빠르고, 용량이 작고, 바이트당 비용이 비싸집니다. 반대로 아래로 내려갈수록 느리고, 용량이 크고, 비용이 저렴해집니다.
핵심 원리: 모든 계층은 다음 계층의 '캐시'다
메모리 계층 구조의 가장 중요한 아이디어는 한 계층의 저장 장치가 바로 아래 계층의 저장 장치를 위한 '캐시' 역할을 한다는 것입니다.
- 레지스터 파일은 L1 캐시를 위한 캐시입니다.
- L1 캐시는 L2 캐시를 위한 캐시입니다.
- L2 캐시는 L3 캐시를 위한 캐시입니다.
- L3 캐시는 주기억장치를 위한 캐시입니다.
- 주기억장치는 디스크를 위한 캐시입니다.
- 로컬 디스크는 네트워크 상의 다른 컴퓨터 디스크를 위한 캐시가 될 수도 있습니다.
컴퓨터는 이 계층 구조와 지역성(Locality) 원리를 이용하여, 마치 거대한 용량의 메모리를 매우 빠른 속도로 사용하는 것과 같은 효과를 얻습니다. CPU가 데이터를 요청하면, 시스템은 가장 빠른 L1 캐시부터 확인하고, 데이터가 없으면 L2, L3, 주기억장치 순서로 점점 더 느린 장치를 확인합니다.
정렬
Bubble Sort
inputs = [1, 6, 4, 3, 7, 8, 9]
n = len(inputs)
def bubblesort():
for i in range(n - 1):
for j in range(n - 1, i, -1):
if inputs[j] < inputs[j - 1]:
inputs[j], inputs[j - 1] = inputs[j - 1], inputs[j]
def bubblesort_improve_1():
for i in range(n - 1):
exchange_count = 0
for j in range(n - 1, i, -1):
if inputs[j] < inputs[j - 1]:
inputs[j], inputs[j - 1] = inputs[j - 1], inputs[j];
exchange_count += 1
if exchange_count == 0:
break
def bubblesort_improve_2():
k = 0
while k < n - 1:
last = n - 1
for j in range(n - 1, k, -1):
if inputs[j] < inputs[j - 1]:
inputs[j], inputs[j - 1] = inputs[j - 1], inputs[j];
last = j
k = last
def double_direction_bubble_sort():
left = 0
right = n - 1
last = right
while left < right:
for j in range(right, left, -1):
if inputs[j - 1] > inputs[j]:
inputs[j - 1], inputs[j] = inputs[j], inputs[j - 1]
last = j
left = last
for k in range(left, right):
if inputs[k] > inputs[k + 1]:
inputs[k], inputs[k + 1] = inputs[k + 1], inputs[k]
last = k
right = last
print(inputs)Insertion Sort
inputs = [1, 6, 4, 3, 7, 8, 9]
n = len(inputs)
for i in range(1, n):
j = i
temp = inputs[i]
while j > 0 and inputs[j-1] > temp:
inputs[j] = inputs[j-1]
j -= 1
inputs[j] = temp
print(inputs)Selection Sort
inputs = [1, 6, 4, 3, 7, 8, 9]
n = len(inputs)
for i in range(n-1):
min = i
for j in range(i+1, n):
if inputs[j] < inputs[min]:
min = j
inputs[min], inputs[i] = inputs[i], inputs[min]
print(inputs)Shell Sort
a = [1, 6, 4, 3, 7, 8, 9]
n = len(a)
h = n // 2
while h > 0:
for i in range(h, n):
j = i - h
temp = a[i]
while j >= 0 and a[j] > temp:
a[j+h] = a[j]
j -= h
a[j+h] = temp
h //= 2
print(a)시간 복잡도
데이터마다 best case와 worst case가 존재하며 각 case마다 빅 오, 오메가, 세타를 측정할 수 있다. 이 중 최악의 점근적 표기법을 빅 오 라고 표기하고 최고의 점근적 표기법을 오메가라고 부른다. 다른 말로 하면 점근적 상한(Upper Bound)을 빅 오라고 하고 점근적 하한(Lower Bound)을 오메가라고 부른다.
두 점근적 표기법의 평균?을 세타(Tight bound) 라고 한다.
이때 데이터가 무한히 존재한다고 가정하고 분석하는 것을 점근적 분석이라고 한다.
