
6.1.2 디스크 저장 장치 (Disk Storage)
디스크는 엄청난 양의 데이터를 저장하는 핵심적인 저장 장치입니다. RAM 기반 메모리가 수백~수천 메가바이트(MB)인 것에 비해, 디스크는 수백~수천 기가바이트(GB) 또는 그 이상의 데이터를 저장할 수 있습니다.
하지만 디스크에서 정보를 읽는 데는 밀리초(ms) 단위의 시간이 걸리는데, 이는 DRAM보다 약 10만 배, SRAM보다는 약 100만 배 더 느린 속도입니다.
디스크 저장 장치 - 디스크 구조 (Disk Geometry)
디스크는 엄청난 양의 데이터를 저장하는 핵심적인 장치입니다. (여기서 설명하는 디스크는 전통적인 회전식 하드 디스크 드라이브(HDD)입니다.)
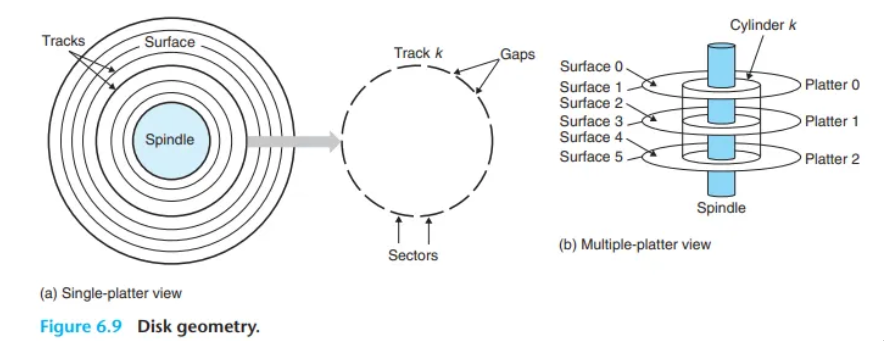
1. 디스크의 기본 구성 요소
- 플래터 (Platter): 자기 기록 물질로 코팅된 원형 판입니다. 각 플래터는 양면(surface)을 가지고 있으며, 중앙의 스핀들(spindle)을 축으로 하여 5,400 ~ 15,000 RPM의 고정된 속도로 회전합니다.
- 디스크 드라이브: 하나 이상의 플래터가 밀봉된 컨테이너 안에 쌓여있는 전체 조립품을 의미합니다.
2. 데이터 저장 구조
- 트랙 (Track): 각 플래터 표면에 있는 동심원 모양의 링입니다. 데이터는 이 트랙을 따라 기록됩니다. (마치 운동장의 달리기 트랙과 같습니다.)
- 섹터 (Sector): 각 트랙은 섹터라는 여러 개의 작은 조각으로 나뉩니다. 섹터는 디스크에 데이터를 기록하는 가장 기본적인 단위이며, 보통 512바이트의 데이터를 저장합니다.
- 갭 (Gap): 섹터와 섹터 사이의 빈 공간으로, 데이터가 저장되지 않고 섹터를 식별하기 위한 정보 등이 기록됩니다.
3. 실린더 (Cylinder)
여러 개의 플래터로 구성된 디스크에서, 모든 플래터의 같은 위치에 있는 트랙들의 집합을 실린더라고 합니다. 예를 들어, 3개의 플래터(6개의 표면)가 있는 디스크에서, 5번 실린더는 6개 표면의 모든 5번 트랙들을 모아놓은 것입니다.
Q. Sector의 크기가 512 byte인 이유는?
섹터 크기를 512바이트로 정한 것은 역사적인 이유와 기술적인 효율성 사이의 '합리적인 절충안'이었기 때문입니다.
1. 초창기 컴퓨터의 메모리(RAM) 한계
하드디스크가 처음 등장했을 때, 컴퓨터의 RAM 용량은 지금과 비교할 수 없을 정도로 작았습니다 (수십~수백 KB 수준).
디스크에서 데이터를 읽고 쓰려면, 최소한 섹터 하나만큼의 데이터를 담을 수 있는 버퍼가 RAM에 필요했습니다. 512바이트는 당시의 RAM 용량을 고려했을 때, 부담스럽지 않으면서도 한 번에 적당한 양의 데이터를 처리할 수 있는 실용적인 크기였습니다. 만약 섹터 크기가 4KB였다면, 버퍼만으로도 RAM의 상당 부분을 차지해버리는 문제가 있었습니다.
2. 효율성과 오버헤드의 균형
- 섹터가 너무 작으면?: 각 섹터 사이에는 데이터를 저장하지 못하는 갭(gap)과 주소 정보를 담는 공간이 필요합니다. 섹터가 너무 작으면 이 갭의 비율이 늘어나, 디스크 전체의 저장 효율(공간 활용도)이 떨어집니다.
- 섹터가 너무 크면?: 1KB짜리 작은 파일을 저장해도 4KB의 큰 섹터 하나를 통째로 차지하게 되어 공간 낭비(내부 단편화)가 심해집니다. 또한, 섹터에 물리적인 오류가 하나라도 발생하면 손실되는 데이터의 양이 너무 커집니다.
512바이트는 이 두 가지 문제 사이에서 적절한 균형을 맞춘 크기였습니다.
현대의 변화: 4KB 섹터 (Advanced Format)
오랫동안 512바이트가 표준으로 사용되었지만, 하드디스크의 용량이 테라바이트(TB)급으로 커지면서 512바이트 단위는 비효율적이게 되었습니다. 그래서 최신 하드디스크와 SSD는 4KB(4096바이트) 섹터를 사용하는 어드밴스드 포맷(Advanced Format)으로 전환되고 있습니다.
디스크 용량 (Disk Capacity)
디스크에 기록될 수 있는 최대 비트의 수를 최대 용량 또는 간단히 용량(Capacity)이라고 합니다. 디스크 용량은 다음과 같은 기술적 요인에 의해 결정됩니다.
- 기록 밀도 (Recording Density): 트랙의 1인치 길이에 얼마나 많은 비트를 기록할 수 있는지.
- 트랙 밀도 (Track Density): 플래터의 반지름 1인치에 얼마나 많은 트랙을 만들 수 있는지.
- 면적 밀도 (Areal Density): 기록 밀도와 트랙 밀도의 곱.
디스크 제조사들은 면적 밀도를 높여 용량을 늘리기 위해 노력하며, 이는 2년마다 두 배씩 증가해 왔습니다.
디스크 용량 계산
초기 디스크는 모든 트랙에 동일한 수의 섹터를 할당했지만, 이는 바깥쪽 트랙의 공간을 낭비하는 결과를 낳았습니다. 현대의 고용량 디스크는 다중 구역 기록(multiple zone recording)이라는 기술을 사용합니다. 이는 디스크를 여러 구역(zone)으로 나누고, 바깥쪽 구역의 트랙에 더 많은 섹터를 할당하여 공간 효율을 높이는 방식입니다.
디스크의 용량은 다음 공식으로 계산됩니다.
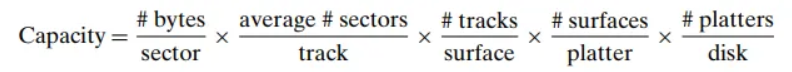
용량 = (섹터 당 바이트 수) × (트랙 당 평균 섹터 수) × (표면 당 트랙 수) × (플래터 당 표면 수) × (디스크 당 플래터 수)
예시:
- 플래터 5개 (표면 10개)
- 섹터 당 512 바이트
- 표면 당 20,000 트랙
- 트랙 당 평균 300 섹터

용량 = (512 바이트/섹터) × (300 섹터/트랙) × (20,000 트랙/표면) × (2 표면/플래터) × (5 플래터/디스크)
= 30,720,000,000 바이트
= 30.72 GB
(참고: 디스크 제조사는 용량을 계산할 때 1GB = 109 바이트를 기준으로 사용합니다.)
디스크 동작 (Disk Operation)
1. 디스크의 물리적 동작
디스크는 액추에이터 암(actuator arm) 끝에 달린 읽기/쓰기 헤드(read/write head)를 사용하여 자기 표면에 저장된 비트를 읽고 씁니다.
- 탐색 (Seek): 드라이브는 암을 앞뒤로 움직여 헤드를 원하는 트랙 위에 위치시킵니다. 이 기계적인 움직임을 '탐색(seek)'이라고 합니다.
- 회전 (Rotation): 헤드가 트랙 위에 위치하면, 플래터가 회전하여 원하는 섹터의 첫 부분이 헤드 아래를 지나갈 때까지 기다립니다.
- 읽기/쓰기: 헤드는 자기 표면을 스치듯이 지나가면서 비트의 값을 감지(읽기)하거나 변경(쓰기)합니다.
여러 개의 플래터가 있는 디스크는 각 표면마다 별도의 헤드를 가지며, 모든 헤드는 한 몸처럼 움직여 항상 동일한 실린더 위에 위치합니다.
Q. HDD는 섹터의 데이터를 이진수로 읽어서 디스크 컨트롤러에 있는 버퍼에 저장하는 걸까?
디스크 컨트롤러 버퍼에 저장: 이 전기 신호는 디스크 드라이브 기판에 있는 디스크 컨트롤러로 전송되고, 컨트롤러는 이 데이터를 자신의 내부 버퍼(작은 메모리 칩)에 섹터(sector) 단위로 (예: 512바이트 또는 4KB) 임시 저장합니다.
이 버퍼에 데이터가 다 채워지면, 디스크 컨트롤러는 비로소 CPU에게 "요청한 데이터 준비 끝났습니다!"라고 인터럽트 신호를 보내고, 그 다음 단계에서 이 버퍼의 데이터가 DMA를 통해 컴퓨터의 주기억장치(RAM)로 전송되는 것입니다.
디스크 컨트롤러 버퍼에 데이터가 저장되면 인터럽트 발생 → CPU는 DMA에게 데이터 옮겨달라고 요청 → DMA는 커널 영역의 버퍼에 데이터 복사 → DMA의 인터럽트 → 사용자 공간으로 데이터 복사 → blocked 되어있던 프로세스를 ready 상태로 변경 → 운영체제의 스케줄러가 이제 실행할 차례라고 판단하면, 해당 프로그램은 잠들었던 read() 함수 호출 바로 다음부터 재개.
Q. 데이터를 읽을 때 펌웨어에 있는 로직이 디스크 컨트롤러 버퍼에 데이터를 복사시키는걸까?
CPU(운영체제)가 디스크 컨트롤러에게 "데이터를 읽어라"는 명령을 보내면, 디스크 컨트롤러가 자신의 펌웨어에 내장된 로직을 실행하여 데이터를 읽고 자신의 버퍼에 저장합니다.
실제 동작 순서
- CPU의 명령: CPU는 운영체제의 디스크 드라이버 코드를 실행하여, 디스크 컨트롤러에게 "몇 번 트랙, 몇 번 섹터의 데이터를 읽어라"는 고수준의 명령을 보냅니다.
- 컨트롤러의 펌웨어 실행: 디스크 컨트롤러는 이 명령을 받습니다. 컨트롤러 내부에 있는 작은 프로세서가 자신의 ROM(펌웨어)에 저장된 프로그램을 실행하기 시작합니다.
- 펌웨어의 역할: 이 펌웨어에는 '헤드를 움직이는 방법', '플래터 회전을 기다리는 방법', '자기 신호를 0과 1로 바꾸는 방법' 등의 매우 구체적인 로직이 들어있습니다. 펌웨어는 이 로직에 따라 디스크의 물리적인 부품들을 제어하여 데이터를 읽습니다.
- 버퍼에 저장: 펌웨어의 지시에 따라 읽어진 데이터는 디스크 컨트롤러 기판 위에 있는 내부 버퍼(RAM 칩)에 저장됩니다.
이 과정이 끝나면, 컨트롤러는 CPU에게 인터럽트 신호를 보내는 것입니다.
2. 디스크 접근 시간 (Access Time)
디스크의 특정 섹터에 접근하는 시간은 크게 세 가지 요소로 구성됩니다.
- 탐색 시간 (Seek Time): 헤드를 원하는 트랙까지 이동시키는 데 걸리는 시간입니다. 현대 드라이브의 평균 탐색 시간(Tavg seek)은 보통 3 ~ 9 ms 정도입니다.
- 회전 지연 시간 (Rotational Latency): 헤드가 트랙에 도착한 후, 원하는 섹터가 헤드 아래로 회전해 올 때까지 기다리는 시간입니다.
- 최대 회전 지연 시간: 플래터가 한 바퀴 완전히 도는 데 걸리는 시간.
- 최대 회전 지연 시간: 플래터가 한 바퀴 완전히 도는 데 걸리는 시간.
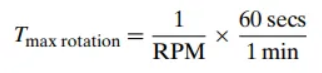
- **평균 회전 지연 시간**: 최대 회전 지연 시간의 절반.- 전송 시간 (Transfer Time): 원하는 섹터의 내용을 실제로 읽거나 쓰는 데 걸리는 시간입니다.
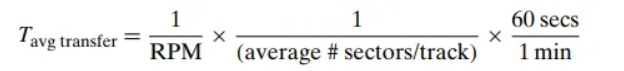
평균 디스크 접근 시간은 이 세 가지 시간의 합입니다.
Taccess=Tavg seek+Tavg rotation+Tavg "transfer

결론
- 디스크 접근 시간은 탐색 시간과 회전 지연 시간이 대부분을 차지합니다. 일단 섹터의 첫 바이트에 접근하면, 나머지 바이트를 읽는 시간은 거의 공짜에 가깝습니다.
- 디스크 접근 시간(약 10ms)은 DRAM(약 4,000ns)보다 수천 배, SRAM(약 256ns)보다는 수만 배 더 느립니다.
논리적 디스크 블록 (Logical Disk Blocks)
현대 디스크의 물리적 구조(여러 표면, 다중 구역 등)는 매우 복잡합니다. 이러한 복잡성을 운영체제(OS)로부터 숨기기 위해, 현대 디스크는 자신의 구조를 섹터 크기의 논리 블록(logical blocks들이 순차적으로 나열된 간단한 형태로 보여줍니다.
1. 핵심 아이디어: 추상화
디스크는 운영체제에게 자신을 0, 1, 2, ..., B-1번까지 번호가 매겨진 하나의 긴 배열처럼 보이게 합니다. 운영체제는 복잡한 물리적 구조를 신경 쓸 필요 없이, "12345번 블록의 데이터를 달라"고 간단하게 요청하기만 하면 됩니다.
2. 디스크 컨트롤러의 역할: 번역기
디스크 패키지에 내장된 디스크 컨트롤러라는 작은 하드웨어/펌웨어 장치가 논리 블록 번호와 실제 물리적 디스크 섹터 사이의 매핑(mapping)을 관리합니다.
- 동작 과정:
- OS의 요청: 운영체제가 디스크 컨트롤러에게 "논리 블록 12345번을 읽어라"는 명령을 보냅니다.
- 컨트롤러의 번역: 컨트롤러의 펌웨어는 내부의 매핑 테이블을 빠르게 조회하여, 논리 블록 12345번이 실제로는 (표면 2, 트랙 500, 섹터 15) 와 같은 물리적 위치에 해당한다는 것을 알아냅니다.
- 물리적 동작: 컨트롤러의 하드웨어는 이 물리 주소에 따라 헤드를 해당 실린더로 이동시키고(탐색), 섹터가 헤드 아래로 지나갈 때까지 기다린 뒤(회전), 데이터를 읽어 자신의 작은 버퍼에 담아 최종적으로 주기억장치로 복사합니다.
이러한 추상화 덕분에, 운영체제는 디스크의 복잡한 물리적 구조가 어떻게 생겼는지 알 필요 없이, 단순한 논리 블록 번호만으로 디스크와 효율적으로 통신할 수 있습니다.
Q. 컨트롤러 내부에 매핑 테이블은 어디에 있을까?
매핑 테이블은 디스크 컨트롤러의 펌웨어(firmware) 안에, 즉 하드디스크(HDD)나 SSD에 붙어있는 회로 기판의 ROM 또는 플래시 메모리 칩 안에 저장되어 있습니다.
Q. 운영체제가 12345번 블럭 데이터를 달라고 하는데 그럼 어떤 요청이 들어왔을 때 운영체제는 어디 블럭에 어떤 데이터가 들어가 있는지 이미 알고 있는걸까?
아니요, 운영체제는 처음부터 어떤 데이터가 어디에 있는지 알지 못합니다. 대신, 파일 시스템(File System)이라는 관리 체계를 통해 그 정보를 조회하여 알아냅니다.
응용 프로그램은 '논리 블록 12345번'처럼 저수준으로 요청하지 않습니다. 대신 'my_file.txt' 파일의 5000번째 바이트부터 1024바이트를 읽어달라' 와 같이 파일 이름과 오프셋을 사용하여 요청합니다.
운영체제의 역할은 이 고수준의 파일 기반 요청을, 디스크 컨트롤러가 이해할 수 있는 저수준의 논리 블록 번호로 변환하는 것입니다.
파일 시스템의 주소 변환 과정
- 경로 탐색 (Path Traversal): 운영체제는 파일 경로(예:
/home/user/my_file.txt)를 따라 각 디렉터리(directory)를 탐색합니다. 각 디렉터리는 파일 이름과 해당 파일의 'inode 번호'를 연결하는 목록을 가지고 있습니다. - inode 조회 (Inode Lookup): 파일 이름
my_file.txt에 해당하는 inode를 찾습니다. inode는 파일의 모든 메타데이터(metadata)를 담고 있는 핵심 데이터 구조입니다. 여기에는 파일 크기, 소유자, 권한, 그리고 가장 중요한 '이 파일이 어떤 논리 블록들로 구성되어 있는지'에 대한 정보(포인터 목록)가 포함됩니다.
Q. inode 번호가 무엇이고 inode는 어디에 저장되어 있는걸까?
Inode 번호 (Inode Number)
파일 이름은 사람이 알아보기 쉽게 언제든 바꿀 수 있지만, inode 번호는 파일이 생성될 때 부여되어 삭제될 때까지 절대 변하지 않는 고유한 식별자입니다.
- 디렉터리: 디렉터리는 단순히 '파일 이름'과 'inode 번호'의 연결 목록을 가지고 있습니다. "컴퓨터 구조"라는 파일의 inode 번호는
12345라고 기록해두는 식이죠.
Inode의 내용과 저장 위치
Inode는 파일의 이름과 실제 데이터를 제외한 모든 정보를 담고 있습니다.
- 파일 종류: 일반 파일인지, 디렉터리인지.
- 소유자 및 권한: 누가 소유하고 있고, 읽기/쓰기/실행 권한은 어떻게 되는지.
- 파일 크기: 파일의 총 바이트 크기.
- 시간 정보: 생성 시간, 마지막 수정 시간, 마지막 접근 시간.
- 데이터 블록 포인터 (⭐ 가장 중요): 파일의 실제 데이터가 하드디스크의 어떤 논리 블록들에 저장되어 있는지에 대한 포인터 목록.
저장 위치: Inode들은 파일 시스템을 처음 만들 때(포맷할 때) 디스크의 특정 영역에 미리 할당된 'Inode 테이블'이라는 곳에 모두 모여 저장됩니다.
Q. Inode들이 테이블 형태로 저장되어 있는 걸까?
Inode들은 디스크의 특정 영역에 'Inode 테이블'이라는 거대한 배열(테이블) 형태로 미리 만들어져 순서대로 저장되어 있습니다.
동작 원리
- 공간 확보 (포맷 시): 하드디스크를 처음 포맷할 때, 파일 시스템은 디스크의 일부를 "여기는 Inode들을 저장하는 공간이다"라고 'Inode 테이블'로 지정해 둡니다. 이 공간은 수많은 빈 Inode 슬롯들이 배열처럼 나열된 형태입니다.
- Inode 할당 (파일 생성 시): 새로운 파일을 만들면, 파일 시스템은 Inode 테이블에서 비어있는 슬롯 하나를 찾아 그 파일에 할당하고, 고유한 Inode 번호(배열의 인덱스)를 부여합니다. 그리고 파일의 모든 정보(크기, 권한, 데이터 블록 위치 등)를 이 Inode 슬롯 안에 기록합니다.
- Inode 조회 (파일 접근 시): 운영체제가 파일에 접근할 때, 디렉터리에서 파일의 Inode 번호를 알아낸 뒤, 그 번호를 Inode 테이블의 인덱스로 사용하여 해당 Inode의 위치를 한 번에 찾아내고 파일의 모든 정보를 읽어옵니다.
Q. 파일 당 식별자로 Inode 번호가 정해진다고 했는데 그럼 파일이 많아지면 배열의 크기가 커지는걸까?
Inode 테이블(배열)의 크기는 파일 개수가 많아진다고 해서 실시간으로 커지지 않습니다. 크기는 파일 시스템이 처음 생성될 때(포맷 시) 고정됩니다.
Inode 테이블의 동작 방식
- 고정된 크기 (포맷 시 결정):
하드디스크를ext4와 같은 파일 시스템으로 포맷할 때, 전체 디스크 공간의 일부를 'Inode 테이블 영역'으로 미리 할당합니다. 이때 생성할 수 있는 Inode의 최대 개수가 결정됩니다. 이는 곧 그 파일 시스템에 저장할 수 있는 파일과 디렉터리의 최대 개수가 됩니다. - 파일 생성과 Inode 사용:
새로운 파일을 만들 때마다, 파일 시스템은 이 미리 만들어진 Inode 테이블에서 비어있는 Inode 하나를 가져와 사용합니다.
"파일이 많아지면" 생기는 문제
Inode 테이블의 크기는 고정되어 있으므로, 작은 파일들이 너무 많아져서 준비된 Inode를 모두 소진해버리면 다음과 같은 문제가 발생할 수 있습니다.
"디스크 공간은 수백 GB나 남아있는데, Inode가 부족하여 더 이상 파일을 생성할 수 없습니다."
이것은 매우 드문 경우지만, 아주 작은 파일 수백만 개를 저장하는 특정 서버 환경 등에서 실제로 발생할 수 있는 문제입니다.
동작 순서
- 경로 탐색: 운영체제는
/home/user/my_file.txt경로를 보고, 먼저 루트(/) 디렉터리에서home의 inode 번호를 찾습니다. - Inode 조회:
home의 inode를 읽어, 그 안에서user의 inode 번호를 찾습니다. - 반복: 이 과정을 반복하여
my_file.txt의 inode 번호를 최종적으로 알아냅니다. - 최종 Inode 조회:
my_file.txt의 inode를 열어, 파일의 실제 데이터가 저장된 논리 블록들의 위치를 파악하여 디스크에 접근합니다.
/home/user/my_file.txt 경로 탐색의 정확한 순서
- 루트(
/) 디렉터리 탐색:- 운영체제는 루트 디렉터리의 inode 번호(보통 2번)를 이미 알고 있습니다.
- 루트 inode를 읽어, 루트 디렉터리의 내용이 담긴 데이터 블록의 주소를 알아냅니다.
- 그 데이터 블록을 읽어,
home이라는 이름과 짝지어진 inode 번호를 찾습니다.
home디렉터리 탐색:- 방금 찾은
home의 inode 번호를 이용해, Inode 테이블에서home디렉터리의 inode를 읽습니다. home의 inode에 기록된 데이터 블록 주소를 알아냅니다.- 그 데이터 블록(즉,
home디렉터리의 내용)을 읽어,user라는 이름과 짝지어진 inode 번호를 찾습니다.
- 방금 찾은
user디렉터리 탐색:- 다시
user의 inode 번호를 이용해,user디렉터리의 inode를 읽습니다. user의 inode에 기록된 데이터 블록 주소를 알아냅니다.- 그 데이터 블록(
user디렉터리의 내용)을 읽어,my_file.txt라는 이름과 짝지어진 inode 번호를 찾습니다.
- 다시
- 최종 파일 접근:
- 이제
my_file.txt의 inode 번호를 알았으므로, 이 inode를 열어 파일의 크기, 권한, 그리고 실제 데이터가 저장된 블록들의 위치를 파악하여 파일에 접근합니다.
- 이제
결론적으로, 디렉터리 역시 inode를 가진 특별한 파일이며, 디렉터리의 inode를 조회해야만 그 디렉터리의 내용(파일/하위 디렉터리 목록)이 어디 저장되어 있는지 알 수 있습니다.
Q. inode가 디스크에 저장되어 있다고 했는데 그럼 운영체제는 매번 하드웨어에 접근해서 inode를 조회하는 걸까?
아니요, 매번 하드웨어(디스크)에 접근하면 너무 느리기 때문에 운영체제는 캐시(Cache)를 사용하여 이 과정을 매우 효율적으로 처리합니다.
파일 경로를 탐색할 때 운영체제는 다음과 같은 순서로 동작합니다.
1. 첫 번째 접근: 디스크 읽기 + 캐시에 저장
프로그램이 /home/user/my_file.txt에 처음 접근한다고 가정해 봅시다.
- 디스크 접근: 운영체제는 먼저 루트(
/) 디렉터리의 내용을 디스크에서 읽어옵니다. - 캐시 저장: 읽어온 루트 디렉터리의 내용(파일 이름과 inode 번호 목록)을 주기억장치(RAM)에 있는 '버퍼 캐시' 또는 '페이지 캐시'라는 특별한 공간에 저장합니다.
- 반복:
home디렉터리,user디렉터리,my_file.txt의 inode를 찾아 디스크에서 읽어올 때마다 그 내용을 모두 캐시에 저장해 둡니다.
2. 두 번째 이후의 접근: 캐시에서 바로 읽기
잠시 후, 다른 프로그램이 다시 /home/user/my_file.txt에 접근하려고 합니다.
- 캐시 확인: 운영체제는 디스크를 먼저 찾아보기 전에, RAM에 있는 버퍼 캐시를 먼저 확인합니다.
- 캐시 히트(Hit)!: 방금 사용했던
/,home,user디렉터리와my_file.txt의 inode 정보가 캐시에 이미 존재합니다. - 즉시 반환: 운영체제는 느린 디스크까지 갈 필요 없이, 매우 빠른 RAM(캐시)에서 inode 정보를 즉시 읽어 작업을 처리합니다.
결론적으로, 운영체제는 자주 사용되거나 최근에 사용된 디렉터리 및 inode 정보를 RAM에 캐싱해 둠으로써, 대부분의 파일 접근을 디스크 I/O 없이 매우 빠르게 처리합니다. 실제 디스크에 접근하는 것은 해당 정보가 캐시에 없을 때(Cache Miss)만 일어나는 상대적으로 드문 작업입니다.
- 오프셋 계산 및 블록 번호 확정: 운영체제는 요청된 오프셋(5000번째 바이트)과 디스크의 블록 크기(예: 4096바이트)를 이용해,
my_file.txt의 5000번째 바이트가 논리 블록 12345번에 해당한다는 것을 inode의 정보를 통해 계산해냅니다.
Q. 오프셋 계산 및 블록 번호 확정 예시
가정
- 디스크 블록 크기: 4096 바이트 (4KB)
- 응용 프로그램의 요청: "
my_file.txt파일의 9000번째 바이트부터 데이터를 읽어달라." my_file.txt의 inode 정보 (일부):- 이 파일은 디스크의 논리 블록 250, 251, 252, ... 번을 순서대로 사용하고 있다.
계산 과정
운영체제(파일 시스템)는 이 요청을 받고 다음과 같이 계산합니다.
1단계: 파일 내 블록 인덱스 계산
요청된 9000번째 바이트가 이 파일의 몇 번째 블록에 위치하는지 계산합니다.
- 계산:
(파일 오프셋) / (블록 크기)9000 / 4096 = 2 (나머지 808)
- 결과: 9000번째 바이트는 파일의 인덱스 2에 해당하는 블록, 즉 3번째 블록에 있다는 것을 알 수 있습니다.
2단계: 논리 블록 번호 조회
파일의 3번째 블록이 디스크의 몇 번 논리 블록에 매핑되어 있는지 inode 정보를 조회합니다.
- 조회:
- 파일의 0번째 블록 → 논리 블록 250
- 파일의 1번째 블록 → 논리 블록 251
- 파일의 2번째 블록 → 논리 블록 252
- 결과: 우리가 찾아야 할 데이터는 논리 블록 252번에 있다는 것을 확정합니다.
3단계: 블록 내 오프셋 계산
이제 논리 블록 252번 안에서 정확히 몇 번째 바이트부터 읽어야 하는지 계산합니다.
- 계산:
(파일 오프셋) % (블록 크기)9000 % 4096 = 808
- 결과: 논리 블록 252번의 808번째 바이트부터 읽기 시작하면 된다는 것을 알 수 있습니다.
최종 명령
이 모든 계산이 끝나면, 운영체제는 디스크 컨트롤러에게 다음과 같이 명령합니다.
- "디스크의 논리 블록 252번을 읽어서 커널 버퍼로 가져와라."
- (데이터가 커널 버퍼로 온 뒤) "그 버퍼의 808번째 위치부터 응용 프로그램이 요청한 만큼의 데이터를 사용자 공간으로 복사해라."
- 디스크에 명령 전달: 이 변환이 끝난 후에야 비로소, 운영체제는 디스크 컨트롤러에게 '논리 블록 12345번을 읽어라'는 저수준 명령을 내립니다.
I/O 장치 연결하기
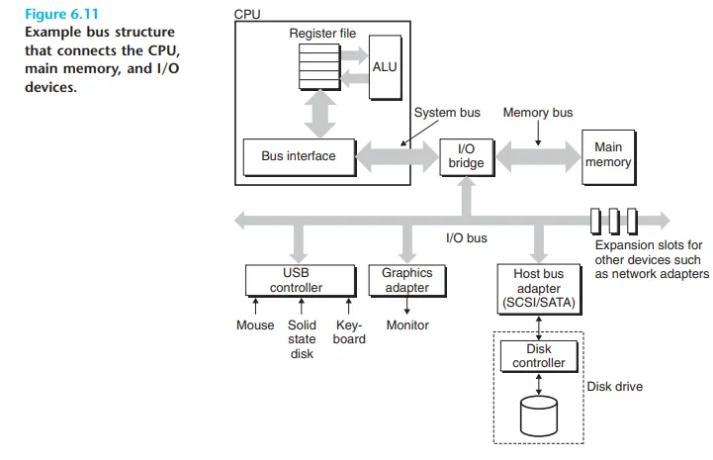
그래픽 카드, 모니터, 마우스, 키보드, 디스크와 같은 입출력(I/O) 장치들은 I/O 버스를 사용하여 CPU 및 주기억장치와 연결됩니다.
- I/O 버스의 특징: CPU에 특화된 시스템 버스나 메모리 버스와 달리, I/O 버스는 CPU 종류에 독립적으로 설계됩니다. 이 덕분에 다양한 종류의 외부 장치들을 연결할 수 있습니다. I/O 버스는 시스템 및 메모리 버스보다 느리지만, 넓은 호환성을 제공합니다.
I/O 버스에 연결되는 장치들의 종류
I/O 버스에는 다음과 같은 다양한 유형의 장치들이 컨트롤러나 어댑터를 통해 연결됩니다.
- USB 컨트롤러:
키보드, 마우스, 프린터, 외장 하드 드라이브 등 매우 다양한 주변 기기를 연결하는 표준 통로인 USB(Universal Serial Bus) 버스에 연결된 장치들을 관리합니다. - 그래픽 카드 (어댑터):
CPU를 대신하여 디스플레이 모니터의 픽셀을 그리는(painting) 역할을 하는 하드웨어 및 소프트웨어 로직을 포함합니다. - 호스트 버스 어댑터 (Host Bus Adapter):
SCSI나 SATA와 같은 통신 프로토콜을 사용하여 하나 이상의 디스크를 I/O 버스에 연결합니다.
- SCSI: SATA보다 일반적으로 더 빠르고 비싸며, 하나의 어댑터에 여러 디스크 드라이브를 연결할 수 있습니다.
- SATA: 하나의 어댑터에 하나의 드라이브만 연결할 수 있습니다.
이 외에도, 네트워크 어댑터와 같은 추가적인 장치들은 메인보드의 빈 확장 슬롯에 꽂아 I/O 버스와 직접 전기적으로 연결할 수 있습니다.
디스크 접근하기 (Accessing Disks)
CPU가 디스크에서 데이터를 읽어오는 과정은 다음과 같은 단계로 이루어집니다.
1단계: CPU의 읽기 명령 (메모리 맵 I/O)
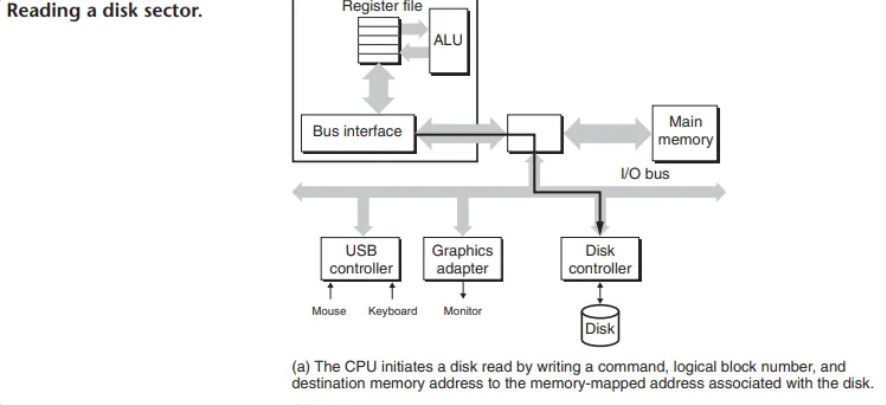
CPU는 메모리 맵 I/O(Memory-Mapped I/O)라는 기술을 사용하여 I/O 장치에 명령을 내립니다.
- 메모리 맵 I/O: 가상 주소 공간의 특정 영역을 I/O 장치와 통신하기 위한 I/O 포트(port)로 예약해두는 방식입니다. CPU는 이 특정 메모리 주소에 값을 읽거나 쓰는 방식으로, 마치 메모리에 접근하듯이 장치에 명령을 보냅니다. 메모리 맵 I/O(Memory-Mapped I/O, MMIO)는 CPU가 I/O 장치를 일반적인 메모리처럼 취급하여 제어하는 방식입니다. CPU의 가상 주소 공간의 일부를 디스크 컨트롤러나 그래픽 카드와 같은 하드웨어 장치에 할당(매핑)하고, CPU는 이 특별한 메모리 주소에 값을 읽거나 쓰는 방식으로 해당 장치와 통신합니다.
동작 원리
-
주소 공간 매핑: 시스템이 부팅될 때, 운영체제는 각 하드웨어 장치의 제어 레지스터들을 가상 메모리의 특정 주소 영역에 매핑합니다. 이 매핑된 주소를 I/O 포트라고 합니다.
-
CPU의 메모리 접근 명령어 사용: CPU는 이 I/O 포트에 접근하기 위해 별도의 특별한 I/O 명령어를 사용하는 것이 아니라, 우리가 흔히 아는
mov와 같은 일반적인 메모리 접근 명령어를 사용합니다. -
I/O 브릿지의 역할: CPU가 이 특별한 주소에
mov명령을 내리면, 칩셋의 I/O 브릿지가 이를 감지합니다. 그리고 "아, 이 주소는 RAM으로 보낼 것이 아니라, 디스크 컨트롤러에게 보내야 하는 명령이구나"라고 판단하여, 신호를 메모리가 아닌 해당 장치로 전달(route)합니다. -
장치 제어: 디스크 컨트롤러는 자신의 I/O 포트로 들어온 값을 읽고, 그것을 '데이터 읽기', '섹터 번호 지정' 등의 명령으로 해석하여 동작합니다.
장점
- 단순성: CPU는 모든 것을 메모리로 취급하므로, 복잡한 I/O 전용 명령어 없이 동일한 방식으로 장치를 제어할 수 있습니다.
- 유연성: C언어와 같은 고급 언어에서 포인터를 이용해 장치를 직접 제어하는 코드를 작성하기 용이합니다.
-
예시:
디스크 컨트롤러가 주소 0xa0에 매핑되어 있다고 가정하면, CPU는 0xa0 주소에 세 번의 쓰기(store) 명령을 실행하여 디스크 읽기를 시작합니다.
- 명령어 쓰기: "읽기 시작"과 같은 명령어를 보냅니다.
- 논리 블록 번호 쓰기: 읽어야 할 데이터의 논리 블록 번호를 보냅니다.
- 메모리 주소 쓰기: 디스크 데이터를 저장할 주기억장치의 주소를 보냅니다.
요청을 보낸 후, CPU는 디스크가 데이터를 읽는 느린 시간 동안 다른 작업을 수행합니다.
2단계: 디스크의 데이터 전송 (DMA)
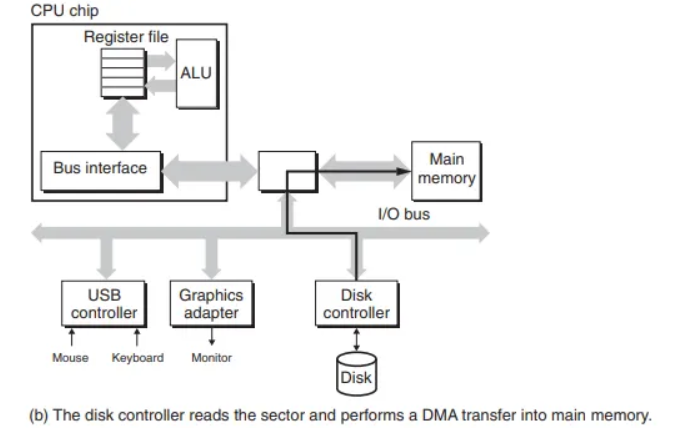
- 디스크 컨트롤러는 CPU로부터 읽기 명령을 받으면, 논리 블록 번호를 실제 물리 섹터 주소로 변환합니다.
- 해당 섹터의 내용을 읽습니다.
- 읽은 내용을 CPU의 개입 없이 주기억장치로 직접 전송합니다.
이처럼 장치가 CPU를 거치지 않고 스스로 버스 트랜잭션을 수행하여 메모리에 접근하는 과정을 직접 메모리 접근(Direct Memory Access, DMA)이라고 합니다.
3단계: 디스크의 완료 신호 (인터럽트)
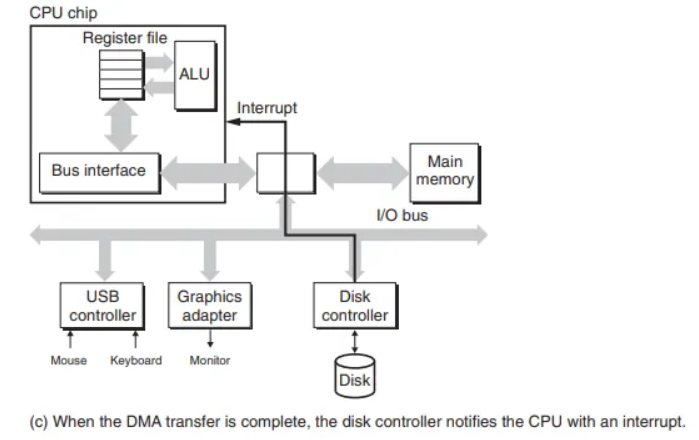
- DMA 전송이 모두 끝나고 데이터가 주기억장치에 안전하게 저장되면, 디스크 컨트롤러는 인터럽트(interrupt) 신호를 보내 CPU에게 작업이 완료되었음을 알립니다.
- 인터럽트 신호를 받은 CPU는 현재 하던 일을 잠시 멈추고, 운영체제 루틴으로 점프합니다.
- 운영체제 루틴은 I/O 작업이 완료되었다는 사실을 기록하고, 원래 CPU가 작업하던 지점으로 제어권을 되돌려줍니다.
6.1.3 SSD (Solid State Disks)
- SSD(Solid State Disk)는 플래시 메모리에 기반한 저장 기술로, 전통적인 회전식 디스크(HDD)를 대체하는 매력적인 대안입니다.
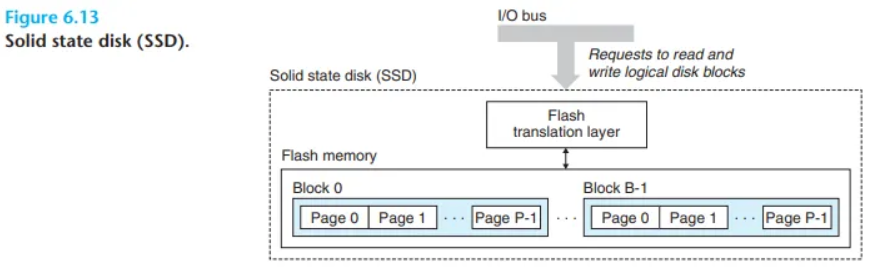
1. SSD의 기본 구조
- 구성: 하나 이상의 플래시 메모리 칩과, 디스크 컨트롤러 역할을 하는 플래시 변환 계층(flash translation layer)으로 구성됩니다.
- 동작: USB나 SATA 같은 표준 I/O 버스 슬롯에 연결되며, 운영체제에게는 일반적인 디스크처럼 보입니다. CPU로부터 논리 블록 읽기/쓰기 요청을 받아 처리합니다.
- 플래시 변환 계층: 논리 블록 번호를 실제 플래시 메모리의 물리적 위치로 번역하는 역할을 합니다.
2. 플래시 메모리의 동작 원리와 성능
플래시 메모리는 블록(block)과 페이지(page)라는 단위로 구성됩니다.
- 읽기/쓰기 단위: 데이터는 페이지 단위(512B ~ 4KB)로 읽고 씁니다.
- 삭제 단위: 데이터를 쓰기 전에는 반드시 페이지가 속한 블록 전체를 지워야 합니다. 블록을 지우는 데는 약 1ms로, 페이지 접근보다 훨씬 오래 걸립니다.
- 쓰기 수명: 하나의 블록은 약 10만 번 정도 반복해서 쓰고 지우면 수명이 다해 더 이상 사용할 수 없습니다.
왜 랜덤 쓰기가 읽기보다 느린가?
- 블록 삭제 시간: 쓰기 작업은 종종 블록을 먼저 지워야 하는데, 이 삭제 과정이 매우 느립니다.
- 쓰기 증폭 (Write Amplification): 만약 데이터가 이미 들어있는 페이지를 수정하려고 하면, 해당 블록에서 유효한 다른 모든 페이지의 데이터를 새로운 빈 블록으로 먼저 복사한 뒤에야 쓰기 작업을 할 수 있습니다. 이 불필요한 복사 작업 때문에 쓰기 속도가 크게 저하됩니다.
3. SSD의 장점과 단점
- 장점:
- 빠른 속도: 움직이는 부품이 없어 HDD보다 랜덤 접근 속도가 월등히 빠릅니다.
- 저전력, 고내구성: 전력 소모가 적고, 충격에 강합니다.
- 단점:
- 쓰기 수명 문제: 반복적인 쓰기로 인해 플래시 블록이 마모될 수 있습니다. 웨어 레벨링(wear-leveling) 로직이 모든 블록에 쓰기 작업을 분산시켜 수명을 극대화하지만, 한계는 존재합니다.
- 높은 가격: HDD보다 바이트당 가격이 훨씬 비싸, 일반적으로 용량이 더 작습니다. (하지만 가격 격차는 점차 줄어들고 있습니다.)
SSD는 노트북, 데스크톱, 서버 등에서 HDD를 대체하는 중요한 저장 장치로 자리 잡았으며, 그 사용처는 계속해서 확대되고 있습니다.
6.1.4 저장 기술 동향
1. 가격과 성능의 트레이드오프
서로 다른 저장 기술들은 각기 다른 가격과 성능의 트레이드오프 관계를 가집니다.
- 속도: SRAM > DRAM > SSD > 회전식 디스크(HDD)
- 바이트당 가격: SRAM > DRAM > SSD > 회전식 디스크(HDD)
빠른 저장 장치는 항상 느린 저장 장치보다 비쌉니다.
2. 발전 속도의 차이
저장 기술들의 가격과 성능은 매우 다른 속도로 발전해 왔습니다.
- SRAM: 1985년 이후, 접근 시간과 메가바이트당 비용이 약 100배 개선되었습니다.
- DRAM: 접근 시간은 10배 개선되는 데 그쳤지만, 메가바이트당 비용은 44,000배나 감소했습니다.
- 디스크: 접근 시간은 25배 개선되는 데 그쳤지만, 메가바이트당 비용은 3,000,000배 이상 폭락했습니다.
핵심 통찰: 메모리와 디스크 기술은 접근 시간(속도)을 줄이는 것보다 밀도(용량)를 높여 비용을 줄이는 것이 훨씬 더 쉽다는 기본적인 사실을 보여줍니다.
3. CPU 성능과의 격차 심화
CPU의 성능은 DRAM이나 디스크의 성능보다 훨씬 더 빠르게 발전해 왔습니다.
- 1985년부터 2010년까지 CPU의 사이클 타임은 500배 향상되었습니다. (멀티코어를 고려한 유효 사이클 타임은 2,000배 향상)
SRAM의 성능은 CPU의 발전 속도를 어느 정도 따라가고 있지만, DRAM 및 디스크와 CPU 사이의 성능 격차는 점점 더 벌어지고 있습니다. 이는 현대 컴퓨터 시스템에서 메모리 계층 구조와 캐시의 중요성이 더욱 커지는 이유입니다.
