
CSAPP
6.2 지역성 (Locality)
잘 작성된 컴퓨터 프로그램은 좋은 지역성(good locality)을 보이는 경향이 있습니다. 즉, 최근에 참조된 데이터 항목 근처에 있거나, 혹은 과거에 참조되었던 데이터 항목들을 다시 참조하는 경향이 있다는 것입니다. 지역성 원리(principle of locality)라고 알려진 이 경향은 하드웨어 및 소프트웨어 시스템의 설계와 성능에 막대한 영향을 미치는 지속적인 개념입니다.
지역성의 두 가지 형태
지역성은 일반적으로 시간 지역성(temporal locality)과 공간 지역성(spatial locality)이라는 두 가지 뚜렷한 형태로 설명됩니다.
- 시간 지역성: 좋은 시간 지역성을 가진 프로그램에서는, 한 번 참조된 메모리 위치는 가까운 미래에 여러 번 다시 참조될 가능성이 높습니다.
- 공간 지역성: 좋은 공간 지역성을 가진 프로그램에서는, 한 번 참조된 메모리 위치가 있다면, 프로그램은 가까운 미래에 그 근처의 메모리 위치를 참조할 가능성이 높습니다.
지역성이 중요한 이유: 성능
프로그래머는 지역성 원리를 이해해야 하는데, 일반적으로 지역성이 좋은 프로그램이 지역성이 나쁜 프로그램보다 더 빨리 실행되기 때문입니다. 현대 컴퓨터 시스템의 모든 계층은 지역성을 활용하도록 설계되어 있습니다.
- 하드웨어 수준: 지역성 원리 덕분에 컴퓨터 설계자들은 캐시 메모리라고 알려진 작고 빠른 메모리를 도입하여 주기억장치 접근 속도를 높일 수 있습니다. 이 캐시는 가장 최근에 참조된 명령어와 데이터 항목들의 블록을 저장합니다.
- 운영체제 수준: 지역성 원리 덕분에 시스템은 주기억장치(RAM)를 가상 주소 공간에서 가장 최근에 참조된 덩어리(chunk)들의 캐시로 사용할 수 있습니다. 마찬가지로, 운영체제는 주기억장치를 사용하여 디스크 파일 시스템에서 가장 최근에 사용된 디스크 블록을 캐시합니다.
- 응용 프로그램 수준: 지역성 원리는 응용 프로그램 설계에서도 중요한 역할을 합니다.
- 웹 브라우저: 최근에 참조한 문서를 로컬 디스크에 캐싱함으로써 시간 지역성을 활용합니다.
- 대용량 웹 서버: 최근에 요청된 문서들을 프론트엔드 디스크 캐시에 보관하여, 서버의 개입 없이 이러한 문서들에 대한 요청을 빠르게 처리합니다.
6.2.1 프로그램 데이터 참조의 지역성
잘 작성된 프로그램은 좋은 지역성을 보이는 경향이 있습니다. 지역성은 크게 두 가지로 나뉩니다.
- 시간 지역성 (Temporal Locality): 한 번 참조된 메모리 위치는 가까운 미래에 다시 참조될 가능성이 높다.
- 공간 지역성 (Spatial Locality): 한 번 참조된 메모리 위치가 있다면, 그 근처의 메모리 위치를 참조할 가능성이 높다.
스트라이드 (Stride): 공간 지역성의 척도
- 스트라이드-1 참조 패턴 (Stride-1 Reference Pattern): 메모리에 저장된 순서대로 데이터를 하나씩 순차적으로 접근하는 패턴입니다. 이는 최상의 공간 지역성을 의미합니다.
- 스트라이드-k 참조 패턴 (Stride-k Reference Pattern): 메모리에서
k개의 요소를 건너뛰며 접근하는 패턴입니다. 스트라이드가 커질수록 공간 지역성은 나빠집니다.
예시 1: 벡터 합계 (1차원 배열)
// (a) C code
long sumvec(long v[], long n) {
long i, sum = 0;
for (i = 0; i < n; i++)
sum += v[i];
return sum;
}- 변수
sum: 반복문이 돌 때마다 계속해서 참조됩니다. → 좋은 시간 지역성 - 배열
v:v[0],v[1],v[2]... 순서로 메모리에 저장된 순서대로 접근합니다. → 스트라이드-1 참조 패턴, 좋은 공간 지역성
결론: sumvec 함수는 전반적으로 좋은 지역성을 가집니다.
예시 2: 행렬 합계 - 행 우선 순회
// (a) C code
long sumarrayrows(long a[M][N]) {
long i, j, sum = 0;
for (i = 0; i < M; i++)
for (j = 0; j < N; j++)
sum += a[i][j];
return sum;
}- 동작: 바깥쪽 루프가 행(
i)을, 안쪽 루프가 열(j)을 순회합니다. - 접근 순서:
a[0][0],a[0][1],a[0][2], ...,a[1][0],a[1][1], ... - 분석: 이 접근 순서는 C언어의 2차원 배열이 메모리에 저장되는 방식(행 우선 순서, Row-major order)과 완벽하게 일치합니다.
- 결론: 전체 메모리 블록을 순차적으로 훑는 스트라이드-1 참조 패턴이 되어 매우 좋은 공간 지역성을 가집니다.
예시 3: 행렬 합계 - 열 우선 순회
// (a) C code
long sumarraycols(long a[M][N]) {
long i, j, sum = 0;
for (j = 0; j < N; j++) // 루프 순서 변경!
for (i = 0; i < M; i++)
sum += a[i][j];
return sum;
}- 동작: 바깥쪽 루프가 열(
j)을, 안쪽 루프가 행(i)을 순회합니다. - 접근 순서:
a[0][0],a[1][0],a[2][0], ...,a[0][1],a[1][1], ... - 분석:
a[0][0]다음에는 메모리상에서 한 행의 길이(N개의 요소)만큼 멀리 떨어진a[1][0]에 접근합니다. - 결론: 이는 스트라이드-N 참조 패턴이 되어, 캐시가 가져온 데이터의 대부분을 사용하지 못하고 계속해서 다른 메모리 블록을 가져와야 합니다. 따라서 공간 지역성이 매우 나쁩니다.
이처럼 for 루프의 순서를 바꾸는 사소한 코드 변경이 지역성에 큰 영향을 미쳐 프로그램의 성능을 극적으로 좌우할 수 있습니다.
6.2.2 명령어 인출의 지역성 (Locality of Instruction Fetches)
프로그램을 구성하는 명령어(instruction)들도 데이터와 마찬가지로 메모리에 저장되어 있으며, CPU가 이를 실행하기 위해 메모리에서 가져오는(fetch) 과정이 필요합니다. 따라서 데이터 접근에서 나타나는 참조 지역성(Locality of Reference) 원리가 명령어 인출 과정에도 동일하게 적용됩니다.
1. 명령어 인출의 공간적 지역성 (Spatial Locality)
- 정의: 특정 메모리 위치의 명령어가 참조되면, 그 근처에 있는 다른 명령어들도 곧 참조될 가능성이 높은 성질입니다.
- 본문 예시 (
for루프):for루프의 본문(body)을 구성하는 명령어들은 컴파일 시 메모리 상에 연속적인 주소에 나란히 배치됩니다. CPU가 루프의 첫 번째 명령어를 실행하면, 바로 다음 순서의 명령어를 실행하게 됩니다. - 효과: 이 때문에 CPU는 한 번에 하나의 명령어만 메모리에서 가져오는 것이 아니라, 캐시 라인(cache line)이라는 블록 단위로 연속된 명령어 묶음을 한꺼번에 명령어 캐시(Instruction Cache, I-Cache)로 가져옵니다. 이를 통해 후속 명령어들을 메인 메모리까지 가지 않고 매우 빠른 캐시에서 즉시 인출할 수 있어 성능이 향상됩니다.
2. 명령어 인출의 시간적 지역성 (Temporal Locality)
- 정의: 한 번 참조된 명령어가 가까운 미래에 다시 참조될 가능성이 높은 성질입니다.
- 본문 예시 (
for루프):for루프는 루프 본문을 여러 번 반복 실행합니다. 이는 루프 본문에 속한 동일한 명령어들이 짧은 시간 안에 계속해서 다시 인출되어야 함을 의미합니다. - 효과: 루프의 첫 번째 반복에서 명령어들이 I-Cache에 적재되면, 이후의 반복에서는 메인 메모리에 접근할 필요 없이 캐시에 있는 명령어를 재사용하게 됩니다. 이는 메모리 접근 지연 시간(latency)을 획기적으로 줄여줍니다.
3. 프로그램 코드의 중요한 속성: 불변성 (Immutability)
본문에서 강조하는 프로그램 코드와 데이터의 근본적인 차이점은 다음과 같습니다.
- 프로그램 코드는 실행 중에 거의 수정되지 않습니다 (Rarely modified at run time).
- CPU는 프로그램 실행 동안 메모리에서 명령어를 읽기만(read) 할 뿐, 해당 명령어 자체를 덮어쓰거나(overwrite) 수정하는(modify) 경우는 거의 없습니다. (JIT 컴파일러나 동적 코드 생성 같은 예외적인 경우가 있지만 일반적이지 않습니다.)
이러한 '읽기 전용(read-only)'에 가까운 특성 덕분에 명령어 캐시는 데이터 캐시(Data Cache)에 비해 관리가 더 단순하고 효율적입니다. 데이터 캐시는 읽기와 쓰기(write)가 모두 빈번하게 발생하므로, 쓰기 정책(write-policy), 캐시 일관성(cache coherency) 등 복잡한 문제를 고려해야 하지만 명령어 캐시는 이러한 부담이 훨씬 적습니다.
6.2.3 지역성 요약 (Summary of Locality)
이 섹션은 지역성의 기본 개념을 종합하고, 프로그래머가 코드를 보고 그 지역성을 정성적으로 평가할 수 있는 간단한 규칙들을 제시합니다.
1. 변수에 대한 시간적 지역성
- 규칙: 동일한 변수를 반복적으로 참조하는 프로그램은 좋은 시간적 지역성(temporal locality)을 갖습니다.
- 설명: 루프의 카운터 변수나 특정 계산 결과를 누적하는 변수처럼, 짧은 시간 내에 같은 메모리 위치(변수)에 여러 번 접근하는 코드가 이에 해당합니다.
- 효과: 변수가 처음 참조될 때 캐시에 로드된 후, 이후의 접근은 모두 메인 메모리가 아닌 빠른 캐시에서 직접 이루어지므로 성능이 향상됩니다.
2. 참조 패턴과 공간적 지역성 (Stride)
- 규칙:
stride-k참조 패턴을 가진 프로그램에서는stride(메모리 접근 간격)가 작을수록 공간적 지역성(spatial locality)이 좋습니다. 특히stride-1패턴(예: 배열의 순차 접근)이 가장 좋습니다. - 설명:
- 좋은 예 (stride-1):
array[0],array[1],array[2], ... 처럼 메모리에 연속된 데이터에 순서대로 접근하는 경우입니다. - 나쁜 예 (large stride):
array[0],array[100],array[200], ... 처럼 메모리 주소를 크게 건너뛰며 접근하는 경우입니다.
- 좋은 예 (stride-1):
- 효과:
stride가 작으면 하나의 데이터를 읽을 때 캐시 라인에 함께 로드된 주변 데이터가 실제로 사용될 확률이 높아져 캐시 히트율이 증가합니다.stride가 크면 캐시의 이점을 거의 활용하지 못하고 매번 메모리 접근이 발생할 수 있습니다.
3. 루프의 명령어 지역성
- 규칙: 루프(Loop)는 명령어 인출 관점에서 좋은 시간적 및 공간적 지역성을 모두 갖습니다. 루프 본문(body)의 크기가 작고, 반복 횟수가 많을수록 지역성은 더욱 향상됩니다.
- 설명:
- 공간적 지역성: 루프를 구성하는 명령어들은 메모리에 연속적으로 저장되므로, 한 번의 인출로 여러 명령어가 함께 캐시에 로드됩니다.
- 시간적 지역성: 루프가 반복 실행되면서 캐시에 저장된 동일한 명령어들이 계속 재사용됩니다.
- 효과: 루프 본문이 작으면 전체 코드가 소수의 캐시 라인의 효율이 극대화되고, 반복이 많을수록 캐시에 로드된 명령어를 재사용하는 횟수가 늘어나 초기 메모리 접근 비용을 상쇄하고도 남는 큰 성능 이득을 봅니다.
프로그래머를 위한 시사점
이러한 정성적인 지역성 판단 능력은 프로그래머에게 매우 중요하고 유용한 기술입니다. 향후 캐시 히트(cache hit)와 미스(miss)라는 정량적 지표를 통해 지역성이 좋은 프로그램이 왜 더 빨리 실행되는지 명확히 이해하게 될 것입니다. 하지만 그에 앞서 소스 코드를 보고 지역성의 좋고 나쁨을 직관적으로 파악할 수 있다면, 하드웨어의 성능을 최대한 활용하는 효율적인 코드를 작성하는 데 큰 도움이 됩니다.
6.3 메모리 계층 구조 (The Memory Hierarchy)
이 섹션에서는 앞서 논의된 하드웨어 기술의 특성과 소프트웨어의 동작 특성이라는 두 가지 근본적인 속성을 어떻게 결합하여 효율적인 메모리 시스템을 구축하는지에 대해 설명합니다.
메모리 계층 구조의 배경
컴퓨터 시스템에는 상호 보완적인 두 가지 기본 속성이 존재합니다.
- 저장 기술 (Hardware): 저장 장치는 빠를수록 바이트당 비용이 비싸고 용량이 작습니다. 반대로 느린 기술은 저렴하고 대용량을 가집니다. 특히 CPU의 처리 속도와 메인 메모리의 접근 속도 간의 격차는 계속해서 벌어지고 있습니다.
- 컴퓨터 소프트웨어 (Software): 잘 작성된 프로그램은 지역성(locality)이 좋은 경향을 보입니다. 즉, 한 번 접근했던 메모리 위치나 그 주변 위치에 다시 접근할 확률이 높습니다.
컴퓨팅 역사상 가장 다행스러운 우연 중 하나는, 하드웨어의 물리적 제약(비싸고 빠른 저장장치 vs. 싸고 느린 저장장치)과 소프트웨어의 예측 가능한 동작(지역성)이 서로를 완벽하게 보완한다는 점입니다. 이러한 상호 보완적인 특성은 오늘날 모든 현대 컴퓨터 시스템에서 사용하는 메모리 계층 구조(memory hierarchy)라는 접근법의 기반이 됩니다.
메모리 계층 구조의 원리 및 구조
메모리 계층 구조는 작고 빠른 저장 장치를 상위에, 크고 느린 저장 장치를 하위에 두어 계층적으로 구성하는 방식입니다. 이 구조의 핵심 원리는 상위 계층을 하위 계층의 캐시(cache)로 사용하는 것입니다.
일반적으로 계층 구조에서 상위 계층(pyramid의 꼭대기)에서 하위 계층으로 내려갈수록 저장 장치는 더 느려지고(slower), 바이트당 비용이 저렴해지며(cheaper), 용량이 커집니다(larger).
전형적인 메모리 계층 구조는 다음과 같습니다.
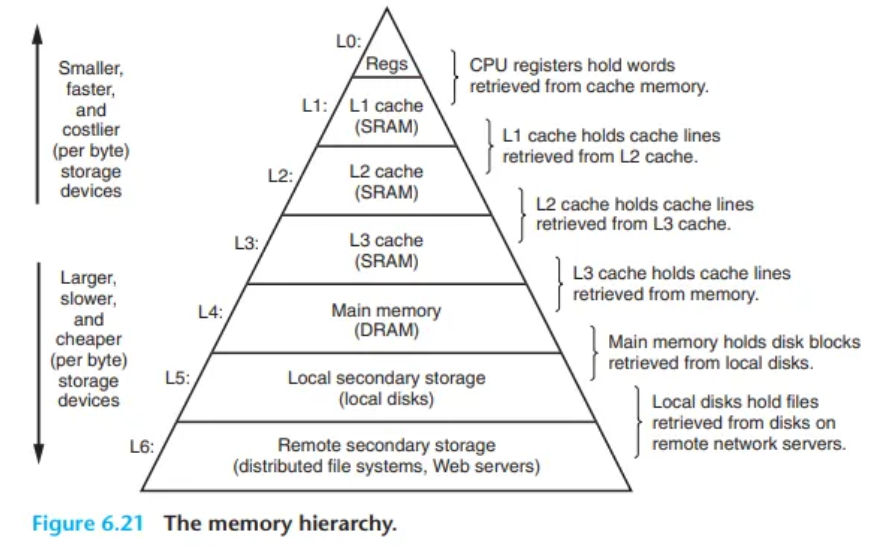
- L0: CPU 레지스터 (CPU Registers)
- CPU 내부에 위치하며, 단일 클럭 사이클 내에 접근할 수 있는 가장 빠른 메모리입니다. 용량은 수십~수백 바이트로 매우 작습니다.
- L1, L2, L3: 캐시 메모리 (Cache Memories)
- CPU와 메인 메모리 사이에 위치하는 SRAM 기반의 고속 메모리입니다. 수 클럭 사이클 내에 접근 가능합니다. L1, L2, L3 순으로 점차 용량이 커지고 속도는 느려집니다.
- L4: 메인 메모리 (Main Memory)
- DRAM 기반의 주 기억 장치입니다. 캐시보다 훨씬 큰 용량을 가지지만, 접근하는 데 수십에서 수백 클럭 사이클이 소요되어 속도가 훨씬 느립니다.
- L5: 로컬 디스크 (Local Disks)
- HDD나 SSD와 같은 보조 기억 장치입니다. 용량은 메인 메모리보다 훨씬 크지만, 접근 속도는 기계적/전기적 지연 시간으로 인해 매우 느립니다.
- L6: 원격 저장소 (Remote Storage)
- 네트워크를 통해 접근하는 다른 서버의 디스크를 의미합니다. AFS(Andrew File System), NFS(Network File System)와 같은 분산 파일 시스템이나 월드 와이드 웹(WWW)을 통해 접근하는 웹 서버의 파일이 여기에 해당합니다. 가장 느리지만 사실상 무한한 용량을 제공할 수 있습니다.
이러한 계층 구조는 프로그램의 지역성 원리 덕분에 효율적으로 동작합니다. CPU가 필요로 하는 대부분의 데이터와 명령어는 상위 계층(레지스터, 캐시)에 존재하게 되므로, 시스템 전체적으로는 크고(large), 빠르고(fast), 저렴한(inexpensive) 메모리를 사용하는 것과 같은 효과를 얻게 됩니다.
6.3.1 메모리 계층 구조에서의 캐싱 (Caching in the Memory Hierarchy)
1. 캐시(Cache)의 기본 개념
- 정의: 캐시는 더 크고 느린 저장 장치에 저장된 데이터 객체들을 위한 임시 저장소(staging area) 역할을 하는 작고 빠른 저장 장치를 의미합니다. 이 캐시를 활용하는 과정을 캐싱(caching)이라고 합니다.
2. 계층 구조의 핵심 원리: 계층적 캐싱
- 메모리 계층 구조의 중심 아이디어는, 모든 계층
k에 대해k레벨의 더 작고 빠른 저장 장치가 바로 아래 단계인k+1레벨의 더 크고 느린 저장 장치를 위한 캐시 역할을 한다는 것입니다. - 즉, 계층 구조의 각 레벨은 바로 아래 하위 레벨로부터 데이터 객체를 캐싱합니다.
- 예시:
- 로컬 디스크(L5)는 네트워크를 통해 가져온 원격 파일(L6)의 캐시 역할을 합니다.
- 메인 메모리(L4)는 로컬 디스크(L5)에 있는 데이터의 캐시 역할을 합니다.
- L3 캐시는 메인 메모리(L4)의 캐시 역할을 합니다.
- ... 이 관계는 가장 작고 빠른 저장소인 CPU 레지스터(L0)까지 이어집니다.
3. 데이터 전송 단위: 블록(Block)
- 데이터는 계층 간에 임의의 단위가 아닌, 정해진 덩어리 단위로 움직입니다. 하위 계층(
k+1)의 저장 공간은 연속적인 데이터 덩어리인 블록(block)으로 분할되어 관리됩니다.- 각 블록은 다른 블록과 구별되는 고유한 주소(address)나 이름(name)을 가집니다.
- 블록 크기는 고정된 크기(일반적인 경우)일 수도 있고, 웹 서버에 저장된 HTML 파일처럼 가변 크기일 수도 있습니다.
- 상위 계층(
k)의 캐시 역시 하위 계층과 동일한 크기의 블록들로 구성되지만, 그 개수는 훨씬 적습니다. - 따라서 캐시는 특정 시점에 하위 계층에 있는 전체 블록들 중 일부의 복사본(copies of a subset)만을 저장하고 있습니다.
4. 블록 단위 데이터 전송과 블록 크기의 가변성
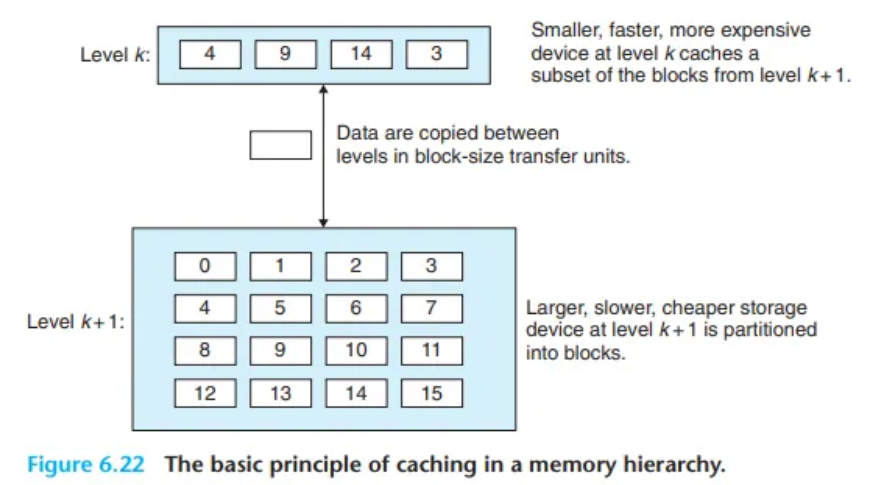
- 핵심: 데이터는 항상 블록 크기 전송 단위(block-size transfer units)로
k레벨과k+1레벨 사이에서 상호 복사됩니다. - 중요한 점: 인접한 두 계층 사이의 블록 크기는 고정되어 있지만, 계층의 쌍마다 블록 크기는 다를 수 있습니다.
- L1 캐시와 L0 레지스터 사이의 전송: 일반적으로 워드(word) 크기(e.g., 8바이트) 블록을 사용합니다.
- L2와 L1 캐시 (및 L3-L2, L4-L3) 사이의 전송: 보통 수십 바이트(e.g., 64바이트) 크기의 블록(캐시 라인)을 사용합니다.
- L5 디스크와 L4 메인 메모리 사이의 전송: 수백 또는 수천 바이트(e.g., 4KB) 크기의 블록(페이지)을 사용합니다.
- 경향: 일반적으로 계층 구조에서 하위 계층(CPU에서 멀수록)에 있는 장치일수록 접근 시간이 길기(longer access times) 때문에, 이 긴 접근 시간을 상쇄(amortize)하기 위해 더 큰 블록 크기를 사용하는 경향이 있습니다. 즉, 한 번의 느린 접근으로 더 많은 데이터를 미리 가져와, 향후 필요할 수 있는 추가적인 접근 횟수를 줄이는 것이 전체적으로 더 효율적이기 때문입니다.
Q. 캐시를 사용하면 동기화 문제가 발생할텐데 어떻게 해결할까?
동기화 문제를 컴퓨터 구조에서는 캐시 일관성 문제(Cache Coherence Problem)라고 부릅니다.
캐시 일관성 문제가 발생하는 근본 원인
이 문제는 여러 개의 캐시가 하나의 공유 메모리(Shared Main Memory)를 사용할 때 발생합니다. 현대의 거의 모든 CPU는 멀티코어(Multi-core) 구조이므로, 각 코어는 자신만의 독립적인 L1, L2 캐시를 가집니다.
[문제 발생 시나리오]
공유 문서(메인 메모리)를 여러 팀원(코어)이 각자 복사본(캐시)을 떠서 작업하는 상황을 상상해 보세요.
- 초기 상태: 변수
X의 값은 메인 메모리에10으로 저장되어 있습니다.- Core A의 읽기:
Core A가X를 읽습니다.X=10이라는 데이터가Core A의 캐시에 복사됩니다.- Core B의 읽기:
Core B도X를 읽습니다.X=10이라는 데이터가Core B의 캐시에 복사됩니다. (현재까지는 문제없음)- Core A의 쓰기:
Core A가X의 값을20으로 변경합니다. 이 변경은 일단Core A의 캐시에만 반영됩니다.- 문제 발생: 이제
Core B가X를 다시 읽으려고 합니다.Core B는 자신의 캐시에 있는X의 값(10)을 참조하게 됩니다.
- 시스템의 모순:
Core A는X를20으로 알고 있는데,Core B는X를10으로 알고 있는 데이터 불일치(Inconsistency) 상태가 발생합니다.
이러한 불일치를 방지하고, 모든 코어가 항상 특정 메모리 주소에 대해 동일한 최신 값을 볼 수 있도록 보장하는 메커니즘을 캐시 일관성 프로토콜(Cache Coherence Protocol)이라고 합니다.
해결책: 캐시 일관성 프로토콜
이 프로토콜은 크게 두 가지 방식으로 나뉩니다.
1. 스누핑 기반 프로토콜 (Snooping-based Protocols)
버스(Bus) 구조로 연결된 소규모 멀티코어 시스템(대부분의 데스크탑, 노트북 CPU)에서 주로 사용됩니다.
- 핵심 아이디어: 모든 캐시 컨트롤러가 공유 버스(Shared Bus)를 지속적으로 엿듣고(snooping) 있습니다. 버스는 모든 코어가 공유하는 통신 채널입니다. 어떤 코어가 메모리 관련 작업을 하려고 하면, 이 요청을 버스를 통해 모든 코어에게 방송(broadcast)합니다.
- 동작 방식:
Core A가 자신의 캐시에 있는 데이터(예:X)를 수정하려고 합니다.Core A는 이 쓰기(write) 요청을 버스를 통해 모든 다른 코어에게 방송합니다.- 다른 코어들(
Core B,C,D...)의 캐시 컨트롤러는 이 방송을 '스누핑'합니다. - 방송을 들은
Core B는 "아,Core A가X를 수정하는구나. 내가 가진X의 복사본은 이제 낡은(stale) 데이터가 되겠네"라고 판단합니다. Core B는 자신의 캐시에 있는X의 복사본을 무효화(Invalidate)하거나,Core A가 방송한 새 값으로 갱신(Update)합니다.
- 두 가지 주요 정책:
- 쓰기-무효화 (Write-Invalidate): (가장 널리 쓰임) 다른 코어가 특정 데이터를 수정하면, 내 캐시에 있는 해당 데이터 복사본을 그냥 '무효(Invalid)' 상태로 만들어 버립니다. 나중에 내가 그 데이터가 필요해지면, 그때 가서 메모리나 최신 값을 가진 다른 캐시로부터 다시 읽어옵니다. 버스 트래픽이 적어 효율적입니다.
- 쓰기-갱신 (Write-Update): 다른 코어가 데이터를 수정하면, 수정된 새로운 값을 버스를 통해 방송하여 모든 복사본을 즉시 갱신합니다. 모든 코어가 항상 최신 값을 가지지만, 쓰기가 발생할 때마다 데이터 전체를 방송해야 하므로 버스 트래픽이 매우 큽니다.
※ 대표적인 스누핑 프로토콜: MESI 프로토콜
현대 CPU에서 가장 널리 사용되는 쓰기-무효화 기반의 프로토콜입니다. 각 캐시 라인은 다음 네 가지 상태 중 하나를 가집니다.
- M (Modified, 수정):
- 이 캐시에만 유일한 복사본이 존재한다.
- 이 복사본은 메인 메모리의 값과 달라 '더럽혀진(dirty)' 상태이다. (내가 값을 수정했음)
- 나중에 이 캐시 라인이 교체될 때, 반드시 메인 메모리에 최신 값을 써주어야(write-back) 한다.
- E (Exclusive, 배타):
- 이 캐시에만 유일한 복사본이 존재한다.
- 메인 메모리의 값과 동일한 '깨끗한(clean)' 상태이다.
- 다른 코어의 방해 없이 언제든지 M 상태로 변경(쓰기 작업)할 수 있다.
- S (Shared, 공유):
- 데이터 복사본이 여러 다른 캐시에도 존재할 수 있다.
- 메인 메모리의 값과 동일한 '깨끗한' 상태이다.
- 이 상태의 데이터를 수정하려면, 다른 모든 복사본을 무효화(Invalidate)하겠다는 신호를 버스에 보내야 한다.
- I (Invalid, 무효):
- 이 캐시 라인의 데이터는 유효하지 않다(쓸모없다).
- 이 데이터를 읽으려면 반드시 메인 메모리나 다른 캐시로부터 새로 가져와야 한다.
MESI를 통한 문제 해결 과정:
- 초기:
X는 메모리에만 있음. Core A가X읽기 →Core A캐시의X는 E (Exclusive) 상태가 됨.Core B가X읽기 →Core B가 버스에 읽기 요청을 방송.Core A가 이를 스누핑하고 응답함.Core A캐시의X는 E → S (Shared)로 변경.Core B캐시의X는 S (Shared) 상태로 적재.
Core A가X에 쓰기 (값을 20으로 변경)Core A는 버스에 "X를 무효화하라"는 신호를 방송.Core A캐시의X는 S → M (Modified)로 변경.- 신호를 스누핑한
Core B캐시의X는 S → I (Invalid)로 변경.
Core B가X를 다시 읽으려고 할 때, 자신의 캐시 라인이I상태이므로 캐시 미스가 발생!Core B는 버스에X를 읽겠다는 요청을 방송.Core A가 이를 스누핑하고, M 상태인 자신의 최신 데이터(20)를 메인 메모리에 쓴 다음,Core B에게도 전달해준다.- 이제
Core A와Core B모두X를 S (Shared) 상태로 가지게 된다.
이처럼 복잡한 상태 전이를 통해 하드웨어는 데이터 불일치 문제를 자동으로 해결합니다.
2. 디렉토리 기반 프로토콜 (Directory-based Protocols)
수십, 수백 개의 코어를 가진 대규모 시스템(서버, 슈퍼컴퓨터)에서 사용됩니다.
- 핵심 아이디어: 스누핑은 모든 코어가 참여하는 방송 방식이라 코어 수가 많아지면 버스가 병목이 됩니다. 이를 해결하기 위해, 데이터의 공유 상태를 관리하는 중앙 관리소, 즉 디렉토리(Directory)를 둡니다.
- 동작 방식:
- 메인 메모리의 특정 영역에 각 메모리 블록에 대한 정보를 저장하는 '디렉토리'가 있습니다.
- 이 디렉토리에는 "어떤 메모리 블록을", "어떤 코어들이", "어떤 상태(수정, 공유 등)로" 캐싱하고 있는지 모든 정보가 기록됩니다.
Core A가 특정 블록에 쓰기를 원하면, 버스에 방송하는 대신 디렉토리에 요청을 보냅니다.- 디렉토리는 자신의 기록을 보고, 해당 블록을 캐싱하고 있는 다른 코어들(
Core C,Core F등)에게만 점대점(point-to-point)으로 무효화 메시지를 보냅니다. - 불필요한 방송이 사라져 확장성이 매우 뛰어납니다.
결론
캐시 동기화, 즉 캐시 일관성 문제는 프로그래머가 직접 관리하는 것이 아니라, CPU 내부에 구현된 정교한 하드웨어 프로토콜(주로 MESI)이 자동으로 처리합니다. 이 보이지 않는 관리 덕분에 멀티코어 환경에서도 프로그래머는 데이터가 항상 일관성 있게 유지된다는 신뢰를 바탕으로 프로그래밍할 수 있습니다.
캐시 히트 (Cache Hit)
1. 캐시 히트의 정의
프로그램이 특정 데이터(객체 d)를 필요로 할 때, 먼저 상위 계층 캐시(k 레벨)에서 해당 데이터를 찾습니다. 이때, 찾고자 하는 데이터가 캐시에 이미 존재하여 바로 가져올 수 있는 경우를 캐시 히트(cache hit)라고 합니다.
2. 동작 과정 및 효과
- 탐색: 프로그램이
k+1레벨(예: 메인 메모리)에 저장된 데이터 객체d를 필요로 할 때, 먼저k레벨(예: L1 캐시)에d가 포함된 블록이 있는지 확인합니다. - 발견 (히트 발생): 만약
d가k레벨 캐시에 존재한다면, 캐시 히트가 발생합니다. - 효과: 프로그램은 느린
k+1레벨까지 내려갈 필요 없이, 메모리 계층 구조의 원리에 따라 훨씬 빠른k레벨에서 데이터를 즉시 읽어옵니다. 이로 인해 메모리 접근 지연 시간이 크게 줄어들어 프로그램 전체의 실행 속도가 향상됩니다.
3. 지역성과의 관계
캐시 히트는 프로그램의 참조 지역성(locality of reference)이 좋을 때 더 빈번하게 발생합니다.
- 본문 예시: 시간적 지역성(temporal locality)이 좋은 프로그램은 이전에 접근했던 데이터를 가까운 미래에 다시 참조할 확률이 높습니다. 예를 들어, 프로그램이 이전에 접근했던 '블록 14'에 있는 데이터를 다시 읽으려고 할 때, 이 블록이 이미
k레벨 캐시에 복사되어 있다면 캐시 히트가 발생하여 매우 빠르게 데이터를 가져올 수 있습니다.
캐시 미스 (Cache Misses)
1. 캐시 미스의 정의
반대로, 프로그램이 필요로 하는 데이터 객체 d가 상위 계층 캐시(k 레벨)에 존재하지 않는 경우를 캐시 미스(cache miss)라고 합니다.
2. 동작 과정
캐시 미스가 발생하면, 다음과 같은 과정이 진행됩니다.
- 하위 계층에서 데이터 인출:
k레벨의 캐시는d를 포함하고 있는 블록(block) 전체를 하위 계층인k+1레벨의 캐시(또는 메모리)로부터 가져옵니다. - 캐시에 블록 적재: 가져온 블록을
k레벨 캐시의 비어있는 공간에 저장합니다. - 프로그램에 데이터 전달: 이제 데이터가
k레벨 캐시에 존재하므로, 프로그램은 캐시 히트가 발생했을 때와 마찬가지로 캐시에서 데이터를 읽어갈 수 있습니다.
3. 블록 교체 (Replacing and Evicting)
- 상황: 캐시 미스가 발생하여 새로운 블록을 가져와야 하는데,
k레벨 캐시가 이미 가득 차 있는 경우. - 과정: 기존에 있던 블록 중 하나를 덮어써야 합니다. 이 과정을 교체(replacing) 또는 축출(evicting)이라고 합니다.
- 용어: 이때 제거되는 블록을 희생 블록(victim block)이라고 부릅니다.
4. 교체 정책 (Replacement Policy)
어떤 블록을 희생 블록으로 선택할지 결정하는 규칙을 교체 정책(replacement policy)이라고 합니다. 캐시의 성능에 중요한 영향을 미치며, 다양한 알고리즘이 있습니다.
- 임의 교체 정책 (Random Replacement Policy): 무작위로 희생 블록을 선택합니다.
- LRU (Least Recently Used) 교체 정책: 가장 오랫동안 참조되지 않은 블록(가장 과거에 마지막으로 사용된 블록)을 선택하여 교체합니다.
Q. 추가적인 교체 알고리즘
1. LRU (Least Recently Used)
- 개념: 가장 오랫동안 참조되지 않은 블록을 교체 대상으로 선택합니다. "최근에 사용되지 않은 데이터는 미래에도 사용되지 않을 것이다"라는 시간적 지역성(Temporal Locality)에 가장 강력하게 기반한 정책입니다.
- 동작 방식: 각 캐시 블록마다 마지막으로 접근된 시간을 기록하거나, 모든 블록의 접근 순서를 유지해야 합니다. 일반적으로 모든 블록을 접근 순서에 따라 연결 리스트(Linked List) 형태로 관리합니다. 데이터가 참조되면 해당 블록을 리스트의 맨 앞으로 가져오고, 교체가 필요할 때는 리스트의 맨 뒤에 있는 블록을 제거합니다.
- 장점:
- 이론적으로 매우 높은 캐시 히트율을 제공합니다. 많은 실제 워크로드에서 가장 효과적인 알고리즘 중 하나로 알려져 있습니다.
- 단점:
- 완벽한 구현 비용이 매우 높습니다. 모든 접근마다 블록의 순서를 변경해야 하므로 하드웨어적으로 복잡하고 느려질 수 있습니다. 이 때문에 실제 하드웨어 캐시에서는 LRU의 동작을 근사(approximate)하는 유사-LRU(Pseudo-LRU) 알고리즘을 사용하는 경우가 많습니다.
- 특정 패턴에 취약: 대규모의 순차적 접근(예: 거대한 배열을 한 번만 스캔)이 발생하면, 최근에 접근한 데이터가 곧바로 캐시에서 밀려나는 문제가 발생할 수 있습니다.
2. FIFO (First-In, First-Out)
- 개념: 가장 먼저 캐시에 들어온 블록을 교체 대상으로 선택합니다. 마치 큐(Queue)처럼 동작합니다.
- 동작 방식: 각 블록이 캐시에 들어온 순서를 기억합니다. 교체가 필요하면 가장 오래된 블록, 즉 큐의 맨 앞에 있는 블록을 제거합니다.
- 장점:
- 구현이 매우 간단하고 하드웨어 비용이 저렴합니다.
- 단점:
- 성능이 좋지 않은 경우가 많습니다. 자주 사용되는 블록이라도 단지 오래전에 들어왔다는 이유만으로 교체될 수 있기 때문입니다. 이는 지역성 원리를 제대로 반영하지 못합니다.
- Belady's Anomaly: 특정 페이지 참조 순서에 대해 캐시 크기를 늘렸음에도 불구하고 오히려 캐시 미스가 증가하는 이상 현상이 발생할 수 있습니다.
3. LFU (Least Frequently Used)
- 개념: 참조된 횟수가 가장 적은 블록을 교체 대상으로 선택합니다. "과거에 참조 횟수가 적었다면 미래에도 적을 것이다"라는 가정에 기반합니다.
- 동작 방식: 각 캐시 블록마다 참조 횟수를 저장하는 카운터(counter)를 유지합니다. 교체가 필요할 때 카운터 값이 가장 작은 블록을 제거합니다.
- 장점:
- 프로그램 실행 초기에 로드되어 꾸준히 사용되는 데이터(예: 핵심 데이터 구조)를 캐시에 오래 유지시키는 데 효과적입니다.
- 단점:
- 구현이 복잡합니다. 각 블록마다 카운터를 유지하고 갱신해야 합니다.
- 과거 이력에 지나치게 의존합니다. 프로그램의 특정 단계(phase)에서 집중적으로 사용되어 카운터가 높아진 블록이, 더 이상 사용되지 않음에도 불구하고 캐시에 계속 남아있을 수 있습니다. 반면, 이제 막 사용되기 시작한 새로운 데이터는 카운터가 낮아 바로 교체될 수 있습니다.
4. 무작위 교체 (Random Replacement)
- 개념: 말 그대로 임의의 블록을 무작위로 선택하여 교체합니다.
- 동작 방식: 교체가 필요할 때, 특별한 로직 없이 하드웨어가 무작위로 희생 블록(victim block)을 하나 고릅니다.
- 장점:
- LRU나 LFU에 비해 하드웨어 구현이 매우 간단하고 빠릅니다.
- 특정 참조 패턴에 의해 성능이 급격히 나빠지는 최악의 경우를 피할 수 있습니다.
- 단점:
- 지역성 원리를 전혀 활용하지 않기 때문에 성능을 예측하기 어렵고, 평균적으로 LRU보다 성능이 떨어집니다. 하지만 매우 큰 캐시에서는 LRU와 비슷한 성능을 보이기도 합니다.
5. 고급 교체 알고리즘 (Advanced Algorithms)
실제 시스템에서는 위의 기본 알고리즘들의 단점을 보완한 다양한 변형 및 하이브리드 알고리즘이 사용됩니다.
- Clock (Second-Chance) Algorithm: FIFO를 기반으로 하되, 각 블록에 참조 비트(reference bit)를 추가하여 기회를 한 번 더 주는 방식입니다. FIFO의 단점을 보완하면서도 구현이 비교적 간단하여 운영체제의 페이징 시스템에서 자주 사용됩니다.
- SLRU (Segmented LRU): 캐시를 두 개의 세그먼트(Probationary, Protected)로 나눕니다. 새로운 데이터는 Probationary에 들어가고, 여기서 한 번 더 참조되면 Protected로 승격됩니다. 교체는 Probationary 세그먼트의 LRU 블록부터 이루어집니다. 한 번만 사용되고 버려지는 데이터가 중요한 데이터를 밀어내는 것을 방지합니다.
- ARC (Adaptive Replacement Cache): LRU와 LFU의 장점을 결합하려는 시도입니다. 최근성과 빈도를 모두 동적으로 고려하여 워크로드 패턴에 맞춰 적응적으로 동작합니다. 복잡하지만 높은 성능을 보입니다.
1. Clock (Second-Chance) 알고리즘
Clock 알고리즘은 LRU의 좋은 성능을 근사(approximate)하면서도 FIFO처럼 구현 비용이 낮은 매우 효율적인 알고리즘입니다. 주로 운영체제(OS)의 가상 메모리 시스템에서 페이지 교체 알고리즘으로 널리 사용됩니다.핵심 아이디어
-
기본적인 구조는 원형 큐(Circular Queue)를 사용하여 FIFO처럼 동작합니다.
-
각 블록(페이지)마다 참조 비트(Reference Bit)라는 1비트짜리 플래그를 추가합니다.
참조 비트 = 1: 최근에 접근된 적이 있음.참조 비트 = 0: 최근에 접근된 적이 없음.
-
"시곗바늘(Clock Hand)" 포인터가 캐시 블록들을 순차적으로 가리키며 교체 대상을 찾습니다.
동작 과정 (Step-by-Step)
-
페이지 폴트 (캐시 미스) 발생: 새로운 페이지(블록)를 캐시에 적재해야 하지만 캐시가 가득 찬 상황입니다.
-
교체 대상 탐색 시작: '시곗바늘' 포인터가 현재 가리키고 있는 위치의 블록부터 검사를 시작합니다.
-
참조 비트 확인:
- 만약 참조 비트가
1이라면: "최근에 사용되었으니 한 번 더 기회를 주자"는 의미입니다. 해당 블록을 교체하지 않고, 참조 비트를0으로 바꾼 후 시곗바늘을 다음 블록으로 이동합니다. - 만약 참조 비트가
0이라면: "최근에 사용된 적이 없으니 교체해도 좋다"는 의미입니다. 이 블록을 희생 블록(victim)으로 선택하여 새로운 블록으로 교체합니다. 교체가 완료되면 시곗바늘을 다음 위치로 이동시키고 탐색을 종료합니다.
- 만약 참조 비트가
-
페이지 접근 (캐시 히트) 발생: CPU가 이미 캐시에 있는 페이지에 접근하면, 해당 페이지의 참조 비트를
1로 설정합니다. (접근했음을 표시)이 과정을 통해 자주 사용되는 블록은 계속해서 참조 비트가
1로 갱신되므로 교체되지 않고 살아남고, 오랫동안 사용되지 않은 블록은 결국 참조 비트가0인 상태에서 시곗바늘에 의해 발각되어 교체됩니다. 이는 LRU의 동작 원리를 매우 낮은 비용으로 훌륭하게 모방합니다.
2. SLRU (Segmented LRU) 알고리즘
SLRU는 한 번만 사용되고 버려지는 데이터(low locality)가 자주 사용되는 중요한 데이터(high locality)를 캐시에서 밀어내는 문제(Cache Pollution)를 해결하기 위해 설계되었습니다.
핵심 아이디어
-
전체 캐시 공간을 두 개의 논리적인 구역(Segment)으로 분할합니다.
- 보호 단계 세그먼트 (Protected Segment): 중요하고 자주 참조되는 "뜨거운(hot)" 데이터를 보관합니다.
- 유예 단계 세그먼트 (Probationary Segment): 새로 들어오거나 한 번만 참조된 "차가운(cold)" 데이터를 보관합니다.
-
각 세그먼트는 내부적으로 독립적인 LRU 리스트로 관리됩니다.
동작 과정 (Step-by-Step)
-
새로운 데이터 적재 (Cache Miss):
- 새로운 블록은 항상 Probationary 세그먼트의 MRU(Most Recently Used) 위치에 추가됩니다.
-
데이터 접근 (Cache Hit):
- Probationary 세그먼트에서 히트 발생: 해당 블록은 중요하다고 판단되어 Protected 세그먼트의 MRU 위치로 승격(promote)됩니다. 즉, 이 블록은 이제 "뜨거운" 데이터로 취급됩니다.
- Protected 세그먼트에서 히트 발생: 해당 블록은 여전히 중요하므로, Protected 세그먼트 내에서 MRU 위치로 이동합니다.
-
교체 발생:
- 교체는 항상 Probationary 세그먼트의 LRU 블록부터 이루어집니다.
- 만약 Probationary 세그먼트가 비어있다면, Protected 세그먼트의 LRU 블록이 Probationary 세그먼트의 MRU 위치로 강등(demote)된 후, Probationary 세그먼트의 LRU 블록(방금 강등된 블록)이 교체됩니다.이 방식을 통해,
for루프를 돌며 거대한 배열을 한 번만 스캔하는 것과 같은 작업은 Probationary 세그먼트에서만 머물다가 조용히 사라집니다. 반면, 반복적으로 접근되는 데이터는 Protected 세그먼트로 승격되어 캐시에 오래 머무를 수 있게 됩니다.
3. ARC (Adaptive Replacement Cache) 알고리즘
ARC는 워크로드의 패턴이 동적으로 변하는 상황에 적응하기 위해 설계된 매우 정교한 알고리즘입니다. "최근성(Recency)"이 중요한 패턴과 "빈도(Frequency)"가 중요한 패턴 사이에서 스스로 균형을 맞춥니다.
핵심 아이디어
-
최근에 한 번만 참조된 데이터(Recency)와 여러 번 참조된 데이터(Frequency)를 별도로 관리합니다.
-
실제 캐시(T1, T2)뿐만 아니라, 캐시에서 쫓겨난 블록의 이력을 추적하는 고스트 캐시(B1, B2)를 함께 사용합니다.
-T1: 최근에 한 번만 접근한 블록을 관리하는 LRU 리스트 (Recency 중심).
-T2: 최근에 두 번 이상 접근한 블록을 관리하는 LRU 리스트 (Frequency 중심).
-B1: T1에서 쫓겨난 블록들의 "유령(ghost)" 리스트.
-B2: T2에서 쫓겨난 블록들의 "유령" 리스트.동작 과정 (Step-by-Step)
-
새로운 데이터 적재 (Cache Miss & Ghost Miss):
B1,B2어디에도 없는 새로운 블록은 T1(Recency 리스트)에 추가됩니다.
-
데이터 접근 (Cache Hit):
- T1에서 히트 발생: 해당 블록은 이제 "자주 사용될 가능성이 있는" 데이터로 간주되어 T2(Frequency 리스트)로 이동합니다.
- T2에서 히트 발생: T2 내에서 MRU 위치로 이동합니다.
-
유령 캐시에서의 히트 (Cache Miss & Ghost Hit):
- 실제 캐시(T1, T2)에는 없지만, B1(Recency 유령)에서 히트가 발생하면: 이는 "최근성" 중심의 캐시 크기를 늘려야 한다는 신호입니다. 시스템은 T1의 목표 크기를 늘리고 T2의 목표 크기를 줄입니다. 데이터는 T2에 적재됩니다.
- B2(Frequency 유령)에서 히트가 발생하면: 이는 "빈도" 중심의 캐시 크기를 늘려야 한다는 신호입니다. 시스템은 T2의 목표 크기를 늘리고 T1의 목표 크기를 줄입니다. 데이터는 T2에 적재됩니다.
-
교체 발생:
- T1과 T2의 합이 전체 캐시 크기를 초과하면, 목표 크기에 따라 T1 또는 T2의 LRU 블록이 교체됩니다.
- 교체된 블록은 각각 B1과 B2 고스트 리스트로 이동하여 이력을 남깁니다.ARC는 이처럼 고스트 캐시를 통해 "만약 캐시 크기가 조금 더 컸더라면 히트가 되었을까?"를 지속적으로 자문하며, 워크로드에 가장 적합한 Recency와 Frequency의 비율을 동적으로 찾아갑니다. 이 때문에 복잡하지만 매우 높은 성능을 보여주며, ZFS 파일 시스템 등 실제 고성능 시스템에서 채택되어 사용됩니다.
-
5. 캐시 미스 처리 후의 상태
- 본문 예시: '블록 12'에 있는 데이터를 읽으려고 할 때, 이 블록이 현재
k레벨 캐시에 없으므로 캐시 미스가 발생합니다. - 결과: 미스가 처리된 후,
k+1레벨로부터 가져온 '블록 12'는k레벨 캐시에 저장됩니다. 이렇게 저장된 블록은 향후의 추가적인 접근을 대비하여(in expectation of later accesses) 캐시에 남아있게 됩니다. 이는 지역성 원리에 따라, 한번 접근된 데이터는 곧 다시 접근될 가능성이 높기 때문입니다.
캐시 미스의 종류 (Kinds of Cache Misses)
때로는 캐시 미스를 원인에 따라 몇 가지 종류로 구분하여 분석하는 것이 유용합니다. 캐시 미스는 크게 세 가지, 즉 3C(Compulsory, Conflict, Capacity)로 분류할 수 있습니다.
1. 강제적 미스 (Compulsory Miss / Cold Miss)
- 정의: 캐시가 비어있는 상태(cold cache)에서 특정 데이터 블록에 처음으로 접근할 때 발생하는 필연적인 미스입니다.
- 원인: 프로그램이 시작되거나 캐시가 초기화된 직후에는 캐시 안에 아무 데이터도 없습니다. 따라서 어떤 데이터에 접근하든 반드시 첫 번째 접근은 미스가 될 수밖에 없습니다.
- 특징: 이는 일시적인(transient) 현상입니다. 프로그램이 계속 실행되어 반복적인 메모리 접근을 통해 캐시가 어느 정도 채워지고 나면("warmed up"), 동일한 데이터에 대한 강제적 미스는 더 이상 발생하지 않습니다. 이 미스는 캐시의 크기나 교체 정책과 무관하게 반드시 발생합니다.
2. 충돌 미스 (Conflict Miss)
- 정의: 캐시에 데이터를 저장할 충분한 공간이 있음에도 불구하고, 여러 데이터 블록이 동일한 캐시 위치(블록 또는 세트)에 매핑(mapping)되어 충돌이 발생함으로써 발생하는 미스입니다.
- 원인: 하드웨어 캐시는 속도를 위해 유연성이 떨어지는 제한적인 배치 정책(restrictive placement policy)을 사용합니다. 예를 들어,
k+1레벨의i번째 블록은 반드시k레벨의(i mod 4)번째 위치에만 저장될 수 있다는 규칙이 있을 수 있습니다. 이런 정책은 특정 위치에 대한 경쟁을 유발합니다. - 특징 및 예시:
- 본문의 예시처럼,
k+1레벨의0, 4, 8, 12번 블록이 모두k레벨의0번 위치에만 매핑된다고 가정해 봅시다. - 이때 프로그램이
0번 블록과8번 블록을 번갈아 가며 반복적으로 접근(0→8→0→8→ ...)한다면, 두 블록은 캐시의0번 자리를 놓고 서로를 계속 덮어쓰게(축출하게) 됩니다. - 비록 캐시에 다른 3개의 빈 공간이 있더라도, 이 두 블록은 같은 위치에 매핑되기 때문에 접근할 때마다 미스가 발생합니다. 이것이 바로 충돌 미스입니다.
- 본문의 예시처럼,
Q. 캐시 매핑의 종류는?
캐시 매핑은 메인 메모리의 블록을 캐시의 어느 라인(line)에 위치시킬 것인지를 결정하는 규칙입니다. 이 규칙에 따라 캐시의 성능과 하드웨어 복잡성이 크게 달라집니다. 주요 매핑 방식은 세 가지가 있습니다.
메모리 주소의 구조
세 가지 방식을 이해하기 전에, CPU가 사용하는 메모리 주소가 캐시에 의해 어떻게 해석되는지 알아야 합니다. 주소는 보통 세 부분으로 나뉩니다.
- Tag (태그): 캐시 라인에 저장된 데이터가 우리가 찾고 있는 메모리 블록이 맞는지 확인하기 위한 고유 식별자입니다. 주소의 최상위 비트들이 사용됩니다.
- Index (인덱스): 메모리 블록이 저장될 캐시 라인의 위치(또는 세트의 위치)를 지정합니다. 주소의 중간 비트들이 사용됩니다.
- Offset (오프셋): 캐시 라인 내에서 원하는 데이터(보통 1바이트)의 정확한 위치를 지정합니다. 주소의 최하위 비트들이 사용됩니다.
이 세 부분의 비율이 어떻게 되느냐에 따라 매핑 방식이 결정됩니다.
1. 직접 매핑 (Direct Mapped Cache)
사용자가 본문 예시에서 본 (i mod 4) 방식이 바로 직접 매핑입니다.
- 개념: 메인 메모리의 각 블록은 캐시 내에서 단 하나의 정해진 위치(라인)에만 저장될 수 있습니다. 가장 간단하고 제한적인 방식입니다.
- 매핑 공식:
(캐시 라인 인덱스) = (메인 메모리 블록 주소) % (전체 캐시 라인 수) - 주소 구조:
Tag,Index,Offset세 부분을 모두 사용합니다. - 동작 방식:
- 주소의
Index필드를 보고 해당하는 캐시 라인으로 바로 찾아갑니다. - 해당 라인의
Tag와 주소의Tag를 비교합니다. - 일치하면 Cache Hit, 불일치하면 Cache Miss (Conflict Miss)입니다.
- 주소의
- 장점:
- 찾아야 할 위치가 단 하나이므로 회로가 매우 간단하고 빠릅니다.
- 하드웨어 구현 비용이 저렴합니다.
- 단점:
- 충돌 미스(Conflict Miss)에 매우 취약합니다. 본문 예시처럼, 서로 다른 메모리 블록(
0번,8번)이 같은 캐시 라인 인덱스로 매핑될 경우, 캐시에 다른 공간이 많아도 이 두 블록은 서로를 계속 덮어쓰며 미스를 유발합니다.
- 충돌 미스(Conflict Miss)에 매우 취약합니다. 본문 예시처럼, 서로 다른 메모리 블록(
2. 완전 연관 매핑 (Fully Associative Cache)
직접 매핑의 정반대 개념으로, 가장 유연한 방식입니다.
- 개념: 메인 메모리의 블록이 캐시 내의 어떤 비어있는 라인이든 자유롭게 들어갈 수 있습니다.
- 주소 구조:
Index필드가 없습니다. 주소는Tag와Offset으로만 나뉩니다. - 동작 방식:
- 찾으려는 데이터의
Tag를 캐시 내의 모든 라인의Tag와 동시에 비교해야 합니다. - 이 중 하나라도 일치하면 Cache Hit입니다.
- 일치하는 것이 없으면 Cache Miss이며, 캐시가 가득 찼다면 교체 정책(LRU 등)에 따라 희생 블록을 선택합니다.
- 찾으려는 데이터의
- 장점:
- 매핑 위치에 제약이 없으므로 충돌 미스가 원천적으로 발생하지 않습니다.
- 캐시 공간을 가장 효율적으로 활용하여 히트율이 높습니다.
- 단점:
- 모든 라인을 동시에 비교해야 하므로 비교기(Comparator) 회로가 매우 복잡하고 비쌉니다.
- 비교해야 할 라인이 많아질수록 검색 속도가 느려집니다. 따라서 L1, L2 같은 대용량 캐시에는 실용적이지 않습니다.
3. 세트 연관 매핑 (Set Associative Cache)
직접 매핑과 완전 연관 매핑의 장점을 절충한 방식으로, 현대 CPU에서 가장 널리 사용됩니다.
- 개념: 캐시 라인들을 여러 개의 세트(Set)라는 그룹으로 묶습니다. 메인 메모리의 블록은 정해진 하나의 세트 안에서만 위치할 수 있지만, 그 세트 내에서는 어떤 라인이든 자유롭게 들어갈 수 있습니다.
- 매핑 공식:
(캐시 세트 인덱스) = (메인 메모리 블록 주소) % (전체 캐시 세트 수) - 주소 구조:
Tag,Index,Offset세 부분을 모두 사용합니다. 단, 여기서Index는 라인이 아닌 세트를 지정합니다. - 동작 방식:
- 주소의
Index필드를 보고 해당하는 세트로 찾아갑니다. - 그 세트 내에 있는 모든 라인들의
Tag를 동시에 비교합니다. (작은 규모의 완전 연관 매핑처럼 동작) - 일치하는
Tag가 있으면 Cache Hit입니다. - 없으면 Cache Miss이며, 해당 세트가 가득 찼다면 세트 내에서 교체 정책(LRU 등)을 적용합니다.
- 주소의
- N-way Set Associative: 하나의 세트가 N개의 라인으로 구성된 것을 의미합니다.
- Direct Mapped는
1-way Set Associative로 볼 수 있습니다. - Fully Associative는 전체 캐시가
하나의 거대한 세트인 것으로 볼 수 있습니다.
- Direct Mapped는
- 장점:
- 직접 매핑에 비해 충돌 미스를 크게 줄여줍니다. (예: 4-way라면, 같은 인덱스에 매핑되는 블록이 최대 4개까지 공존 가능)
- 완전 연관 매핑보다 하드웨어가 훨씬 저렴하고 빠릅니다.
- 단점:
- 직접 매핑보다는 회로가 복잡하고 비용이 더 듭니다.
Q. 좀 더 자세히 알아보자.
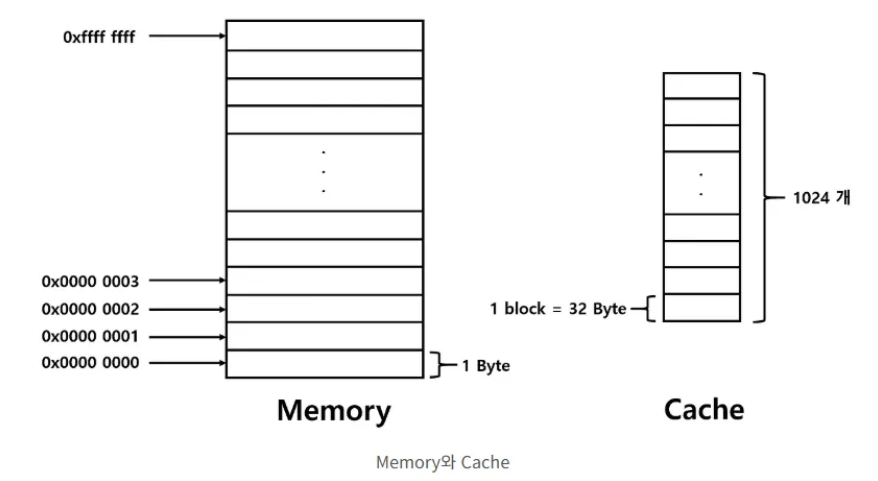
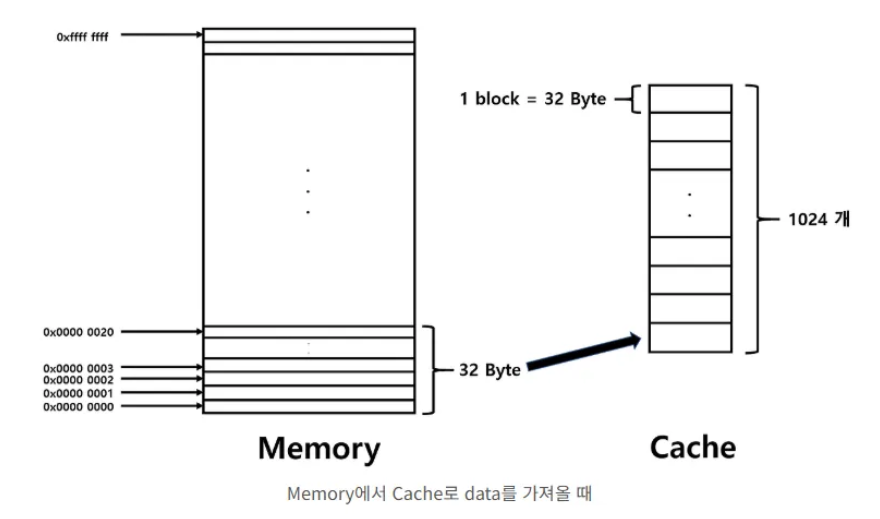
1. 시스템 가정
- 메모리 주소 길이: 32비트 (0x0000 0000 ~ 0xFFFFFFFF, 총 4GB 주소 공간)
- 캐시의 총 크기: 32 KByte
- 캐시 블록(라인)의 크기: 32 Byte
- 캐시 라인의 총 개수: 32 KByte / 32 Byte = 1024 개 = 개
이 사양을 바탕으로, 캐시 매핑(Cache Mapping) 방식에 따라 32비트 주소가 어떻게 Tag, Index, Offset으로 나뉘는지 살펴보겠습니다. 이미지에는 매핑 방식이 명시되지 않았으므로, 가장 대표적인 직접 매핑과 세트 연관 매핑 두 가지 경우를 모두 설명하겠습니다.
경우 1: 직접 매핑 (Direct Mapped)
가장 간단한 방식으로, 메모리의 각 블록이 캐시의 정해진 단 한 곳에만 위치할 수 있는 구조입니다.
주소 필드 크기 계산
- Offset 필드:
- 하나의 캐시 블록이 32 Byte(25)의 데이터를 담고 있습니다. 이 32바이트 중 특정 1바이트를 가리키기 위해서는 5비트가 필요합니다.
- Offset = 하위 5비트 (비트 0 ~ 4)
- Index 필드:
- 캐시 라인의 총 개수가 1024개()입니다. 1024개의 라인 중 어느 라인에 저장될지를 지정해야 하므로 10비트가 필요합니다.
- Index = 중간 10비트 (비트 5 ~ 14)
- Tag 필드:
- 전체 주소 32비트에서 Offset과 Index 비트를 제외한 나머지입니다.
32 - 5 (Offset) - 10 (Index) = 17- Tag = 상위 17비트 (비트 15 ~ 31)
[직접 매핑 주소 구조]
| Tag (17 bits) | Index (10 bits) | Offset (5 bits) | | 31 15 | 14 5 | 4 0 |
동작 예시
CPU가 메모리 주소 0x0123ABCD 에 접근한다고 가정해 봅시다.
- 주소 분해:
- 주소
0x0123ABCD를 이진수로 변환합니다. 0000 0001 0010 0011 1010 1011 1100 1101- 위 구조에 따라 세 부분으로 나눕니다.
- Tag:
0000 0001 0010 0011 1(0x0091D) - Index:
010 1011 1100(0x2BC, 십진수 700) - Offset:
0 1101(0x0D, 십진수 13)
- Tag:
- 주소
- 캐시 접근:
- ① Index 확인: 캐시 컨트롤러는 Index 값
0x2BC(700)를 보고, 700번 캐시 라인으로 즉시 찾아갑니다. - ② Tag 비교: 700번 라인에 저장된 Tag 값과 CPU가 보낸 주소의 Tag 값
0x0091D를 비교합니다.- Hit: 두 Tag가 일치하면, 찾는 데이터가 이 라인에 있다는 의미입니다.
- Miss: Tag가 다르거나 라인이 비어있으면, 메인 메모리에서 해당 블록 전체를 가져와 700번 라인을 덮어쓰고 Tag를
0x0091D로 업데이트합니다.
- ③ Offset 사용: Hit이 확인되면, 32 Byte 크기의 블록 내에서 Offset 값
0x0D(13)에 해당하는 13번째 바이트를 CPU에 전달합니다.
- ① Index 확인: 캐시 컨트롤러는 Index 값
경우 2: 세트 연관 매핑 (Set Associative) - (4-way 예시)
현대 CPU에서 가장 널리 쓰이는 방식으로, 직접 매핑의 충돌 문제를 완화한 구조입니다. 4개의 라인을 하나의 세트(Set)로 묶는다고 가정해 보겠습니다.
주소 필드 크기 계산 (4-way Set Associative)
- 세트의 총 개수 계산:
- 전체 라인 수: 1024개
- Way의 수: 4 (4개의 라인이 1개의 세트를 구성)
- 세트의 수 = 1024 / 4 = 256개 = 2^8개
- Offset 필드:
- 블록 크기는 동일하므로 5비트로 변하지 않습니다.
- Index 필드:
- 이제 Index는 라인이 아닌 세트를 가리킵니다. 총 256개(28)의 세트가 있으므로, 이 중 하나를 특정하기 위해 8비트가 필요합니다.
- Index = 중간 8비트 (비트 5 ~ 12)
- Tag 필드:
32 - 5 (Offset) - 8 (Index) = 19- Tag = 상위 19비트 (비트 13 ~ 31)
[4-way 세트 연관 매핑 주소 구조]
| Tag (19 bits) | Index (8 bits) | Offset (5 bits) | | 31 13 | 12 5 | 4 0 |
동작 예시
동일한 주소 0x0123ABCD에 접근하는 경우입니다.
- 주소 분해:
0000 0001 0010 0011 1010 1011 1100 1101- 새로운 구조에 따라 나눕니다.
- Tag:
0000 0001 0010 0011 101(0x0048F) - Index:
0 1011 110(0x5E, 십진수 94) - Offset:
0 1101(0x0D, 십진수 13)
- Tag:
- 캐시 접근:
- ① Index 확인: 캐시 컨트롤러는 Index 값
0x5E(94)를 보고, 94번 세트로 찾아갑니다. - ② Tag 비교: 94번 세트 내에 있는 4개의 라인 모두의 Tag 값을 CPU가 보낸 주소의 Tag 값
0x0048F와 동시에 비교합니다.- Hit: 4개 중 하나라도 Tag가 일치하면 Hit입니다.
- Miss: 4개 모두 Tag가 일치하지 않으면 Miss입니다. 메인 메모리에서 데이터를 가져와 세트 내의 비어있는 라인에 저장합니다. 만약 4개 라인이 모두 차 있다면, LRU 같은 교체 정책에 따라 하나를 골라 덮어씁니다.
- ③ Offset 사용: Hit된 라인을 찾으면, 그 라인의 32 Byte 블록 내에서 Offset
0x0D에 해당하는 바이트를 CPU에 전달합니다.
- ① Index 확인: 캐시 컨트롤러는 Index 값
결론
이처럼 동일한 캐시 사양이라도 어떤 매핑 방식을 채택하느냐에 따라 32비트 주소를 해석하는 방법(Tag, Index, Offset의 경계)이 달라집니다. 이는 캐시의 성능(충돌 미스 발생률)과 하드웨어 구현 복잡도(비용) 사이의 중요한 트레이드오프를 결정하는 핵심 요소입니다.
3. 용량 미스 (Capacity Miss)
- 정의: 프로그램이 현재 필요로 하는 데이터의 집합, 즉 워킹셋(working set)의 크기가 캐시의 전체 용량보다 커서 발생하는 미스입니다.
- 원인: 이는 간단히 말해 캐시가 너무 작아서 발생하는 문제입니다. 프로그램이 다뤄야 할 데이터의 양이 캐시가 한 번에 담을 수 있는 양을 초과하는 경우입니다.
- 특징 및 예시:
- 프로그램은 보통 루프와 같은 단계(phase)별로 실행되며, 각 단계는 특정 데이터 블록 집합(워킹셋)에 집중적으로 접근합니다.
- 만약 중첩 루프가 처리해야 할 배열의 크기가 캐시의 전체 크기보다 크다면, 배열의 앞부분을 처리하고 뒷부분으로 넘어갈 때 앞부분 데이터는 캐시에서 밀려나게 됩니다.
- 이후 다시 배열의 앞부분 데이터가 필요해지면, 이미 캐시에서 사라졌기 때문에 용량 미스가 발생합니다. 이는 충돌 때문이 아니라 순수하게 공간이 부족해서 발생하는 문제입니다.
캐시 관리 (Cache Management)
메모리 계층 구조의 본질은 각 계층의 저장 장치가 바로 아래 하위 계층을 위한 캐시 역할을 한다는 것입니다. 따라서 각 계층에서는 어떤 형태의 '로직(logic)'이 캐시를 관리(manage)해야 합니다.
여기서 '관리'란, 캐시 저장 공간을 블록(block) 단위로 분할하고, 서로 다른 계층 간에 블록을 전송하며, 캐시 히트(hit)와 미스(miss)를 판단하고 그에 따라 처리하는 모든 작업을 의미합니다.
캐시 관리 주체: 하드웨어, 소프트웨어, 또는 둘의 조합
캐시를 관리하는 로직은 구현되는 계층에 따라 하드웨어일 수도 있고, 소프트웨어일 수도 있으며, 또는 이 둘의 조합일 수도 있습니다. 각 계층별 관리 주체는 다음과 같습니다.
- 레지스터 파일 (Register File, L0)
- 관리 주체: 컴파일러 (소프트웨어)
- 설명: 메모리 계층의 최상위인 레지스터 파일은 컴파일러가 전적으로 관리합니다. 컴파일러는 어떤 데이터를 레지스터에 저장할지, 미스가 발생했을 때(즉, 필요한 데이터가 레지스터에 없을 때) 언제 메모리에서 로드(load) 명령을 내릴지, 그리고 어떤 레지스터에 데이터를 저장할지를 최적화 과정에서 결정합니다.
- L1, L2, L3 캐시
- 관리 주체: 하드웨어 로직 (Hardware Logic)
- 설명: 이 캐시들은 캐시 내에 내장된(built-in) 전용 하드웨어 회로에 의해 완전하게(entirely) 관리됩니다. 블록 전송, 주소 매핑, 히트/미스 판단, 블록 교체 등의 모든 과정이 OS나 소프트웨어의 개입 없이 하드웨어 수준에서 자동으로, 그리고 매우 빠르게 이루어집니다.
- 메인 메모리 (DRAM, L4 - 디스크의 캐시 역할)
- 관리 주체: 운영체제(OS) 소프트웨어와 CPU의 주소 변환 하드웨어(MMU)의 조합
- 설명: 가상 메모리 시스템에서 DRAM은 디스크에 저장된 데이터 블록(페이지)을 위한 캐시 역할을 합니다. 어떤 페이지를 메모리로 올리고 내릴지(페이징) 결정하는 것은 OS의 책임이지만, 가상 주소를 실제 물리 주소로 변환하는 과정은 CPU 내의 주소 변환 하드웨어(MMU)가 담당합니다. 이처럼 하드웨어와 소프트웨어가 협력하여 관리합니다.
- 로컬 디스크 (Local Disk, L5 - 원격 저장소의 캐시 역할)
- 관리 주체: 클라이언트 프로세스 (소프트웨어)
- 설명: AFS(Andrew File System)와 같은 분산 파일 시스템 환경에서, 로컬 디스크는 네트워크를 통해 접근하는 원격 서버의 파일들을 위한 캐시 역할을 합니다. 이 관리는 사용자의 로컬 머신에서 실행되는 AFS 클라이언트 프로세스라는 소프트웨어에 의해 이루어집니다.
프로그래머 관점에서의 투명성 (Transparency)
대부분의 경우, 이러한 캐시 관리 메커니즘은 자동으로 동작하며 프로그래머가 작성하는 응용 프로그램에서 어떤 명시적인 조치를 요구하지 않습니다. 프로그래머는 그저 메모리에 데이터를 읽고 쓰는 코드를 작성할 뿐이지만, 이 계층화된 자동 관리 시스템 덕분에 프로그램은 훨씬 빠른 성능으로 실행될 수 있습니다.
6.3.2 메모리 계층 구조 개념 요약
캐싱(caching)에 기반한 메모리 계층 구조가 효과적으로 동작하는 이유는 두 가지 근본적인 원리, 즉 경제성과 지역성(locality) 때문입니다. 느린 저장장치는 빠른 저장장치보다 저렴하며, 프로그램은 지역성이라는 예측 가능한 경향을 보입니다.
1. 시간적 지역성의 활용 (Exploiting Temporal Locality)
- 원리: 시간적 지역성 때문에, 프로그램은 동일한 데이터 객체를 여러 번 재사용할 가능성이 높습니다.
- 효과: 데이터 객체에 처음 접근할 때 발생하는 캐시 미스(miss)로 인해 해당 객체가 캐시에 복사되고 나면, 이후의 접근은 캐시 히트(hit)가 될 것으로 기대할 수 있습니다. 캐시는 하위 계층 저장장치보다 훨씬 빠르므로, 이러한 후속 히트들은 최초의 미스보다 훨씬 빠른 속도로 처리될 수 있습니다.
2. 공간적 지역성의 활용 (Exploiting Spatial Locality)
- 원리: 캐시 블록은 일반적으로 여러 데이터 객체를 포함합니다. 공간적 지역성 때문에, 특정 데이터에 대한 캐시 미스로 인해 하나의 블록 전체를 메모리에서 가져온 후, 프로그램이 그 블록 내의 다른 데이터 객체들을 연이어 참조할 것으로 기대할 수 있습니다.
- 효과: 결과적으로, 한 번의 미스로 블록 전체를 복사해오는 데 들었던 초기 비용(cost)은, 블록 내 다른 데이터들에 대한 빠른 후속 접근들(캐시 히트)을 통해 상쇄(amortize)됩니다. 즉, 비싼 한 번의 작업으로 얻은 이득을 여러 번의 저렴한 작업에서 나누어 누리는 효과를 얻습니다.
현대 시스템에서의 캐시의 보편성
캐시는 현대 시스템의 거의 모든 곳에서 사용됩니다. CPU 칩 내부, 운영체제(OS), 분산 파일 시스템, 그리고 월드 와이드 웹(WWW)에 이르기까지 다양한 영역에서 활용됩니다.
정글에서 스켈레톤 코드가 주어지고 필요한 부분만 구현하였다.
insertSortedLL
int insertSortedLL(LinkedList *ll, int item)
{
if (ll -> head == NULL) {
insertNode(ll, 0, item);
return 0;
}
ListNode *find_node = NULL;
int index = ll->size;
for (int i = 0; i < ll -> size; i++) {
find_node = findNode(ll, i);
if (find_node != NULL && find_node -> item == item) {
return -1;
}
if (find_node != NULL && find_node -> item > item) {
index = i;
break;
}
}
insertNode(ll, index, item);
return index;
}
alternateMergeLinkedList
int max(int a, int b) {
if (a >= b) return a;
return b;
}
void alternateMergeLinkedList(LinkedList *ll1, LinkedList *ll2)
{
int count = max(ll1 -> size, ll2 -> size);
int index_for_add = 1;
while (--count > 0) {
ListNode *find_node = findNode(ll2, 0);
if (find_node == NULL)
return;
insertNode(ll1, index_for_add, find_node -> item);
removeNode(ll2, 0);
index_for_add += 2;
}
if (ll2 -> size > 0) {
for (int i = 0; i < ll2->size; i++) {
ListNode *find_node = findNode(ll2, i);
if (find_node != NULL)
insertNode(ll1, ll1->size, find_node->item);
}
}
}moveOddItemsToBack
void moveOddItemsToBack(LinkedList *ll)
{
int size = ll -> size;
for (int i = 0; i < size; i++) {
ListNode *find_node = findNode(ll, i);
if (find_node != NULL) {
if (find_node -> item % 2 == 1) {
insertNode(ll, ll->size, find_node -> item);
removeNode(ll, i);
i--;
size--;
}
}
}
}moveEvenItemsToBack
void moveEvenItemsToBack(LinkedList *ll)
{
int size = ll -> size;
for (int i = 0; i < size; i++) {
ListNode *find_node = findNode(ll, i);
if (find_node != NULL) {
if (find_node -> item % 2 == 0) {
insertNode(ll, ll->size, find_node -> item);
removeNode(ll, i);
i--;
size--;
}
}
}
}frontBackSplitLinkedList
void frontBackSplitLinkedList(LinkedList *ll, LinkedList *resultFrontList, LinkedList *resultBackList)
{
int size = ll->size;
int mid = size / 2;
for (int i = 0; i < size; i++) {
ListNode *find_node = findNode(ll, i);
if (find_node == NULL)
return;
if (i <= mid) {
insertNode(resultFrontList, resultFrontList -> size, find_node->item);
} else {
insertNode(resultBackList, resultBackList -> size, find_node->item);
}
}
}moveMaxToFront
int moveMaxToFront(ListNode **ptrHead)
{
if (ptrHead == NULL) return -1;
if (*ptrHead == NULL) return -1;
ListNode *current = *ptrHead;
ListNode *max_current = *ptrHead;
ListNode *max_prev = NULL;
int max = current->item;
while (current->next != NULL) {
if (max < current->next->item) {
max = current->next->item;
max_prev = current;
max_current = current->next;
}
current = current->next;
}
ListNode *temp = max_current;
max_prev->next = max_current->next;
temp->next = *ptrHead;
*ptrHead = temp;
return 0;
}RecursiveReverse
void RecursiveReverse(ListNode **ptrHead)
{
if (*ptrHead == NULL || (*ptrHead)->next == NULL)
return;
ListNode *first = *ptrHead;
ListNode *rest = first->next;
RecursiveReverse(&rest);
first->next->next = first;
first->next = NULL;
*ptrHead = rest;
}