
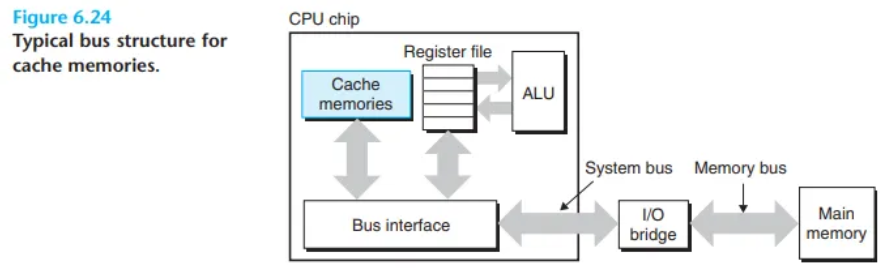
6.4 캐시 메모리 (Cache Memories)
캐시의 등장 배경
초창기 컴퓨터 시스템의 메모리 계층 구조는 CPU 레지스터, 메인 메모리, 디스크 저장 장치라는 단 3개의 레벨로만 구성되었습니다. 하지만 기술이 발전하면서 CPU의 처리 속도와 메인 메모리(DRAM)의 접근 속도 사이의 성능 격차(performance gap)가 점점 더 심각해졌습니다.
이러한 문제를 해결하기 위해, 시스템 설계자들은 CPU 레지스터 파일과 메인 메모리 사이에 작고 매우 빠른 SRAM 기반의 캐시 메모리를 추가해야만 했습니다.
캐시 계층의 발전
- L1 캐시 (레벨 1 캐시)
- CPU와 메인 메모리 사이에 처음으로 도입된 캐시입니다.
- CPU 코어와 가장 가까이 위치하며, 레지스터와 거의 비슷한 속도로 접근할 수 있습니다. (일반적으로 약 4 클럭 사이클 소요)
- L2 캐시 (레벨 2 캐시)
- CPU와 메인 메모리 사이의 성능 격차가 계속해서 벌어지자, 시스템 설계자들은 L1 캐시와 메인 메모리 사이에 더 큰 용량의 L2 캐시를 추가하여 대응했습니다.
- L1 캐시보다는 느리지만 메인 메모리보다는 훨씬 빠릅니다. (일반적으로 약 10 클럭 사이클 소요)
- L3 캐시 (레벨 3 캐시)
- 많은 현대 시스템은 여기서 더 나아가, L2 캐시와 메인 메모리 사이에 훨씬 더 큰 용량의 L3 캐시를 포함합니다.
- L3 캐시는 여러 CPU 코어가 공유하는 경우가 많습니다. (일반적으로 약 50 클럭 사이클 소요)
기본 원리와 논의의 단순화
이러한 캐시들의 구체적인 구성 방식(arrangement)에는 시스템마다 상당한 다양성이 존재하지만, 여러 계층의 캐시를 두어 속도 차이를 완충한다는 기본 원리는 모두 동일합니다.
이후 섹션에서의 논의를 단순화하기 위해, 앞으로는 CPU와 메인 메모리 사이에 단 하나의 L1 캐시만 존재하는 간단한 메모리 계층 구조를 가정하고 설명을 진행하겠습니다.
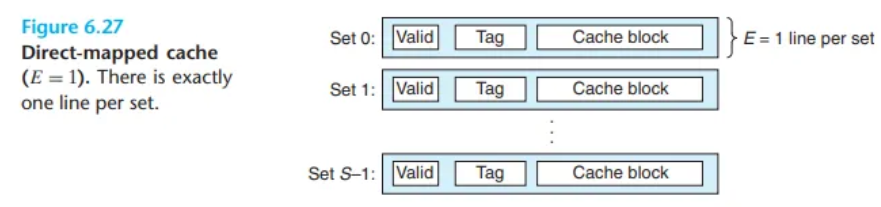
6.4.1 일반적인 캐시 메모리의 구조 (Generic Cache Memory Organization)
1. 캐시의 기본 구조
m비트의 메모리 주소를 사용하는 컴퓨터 시스템(즉, M=개의 고유한 주소를 가짐)을 가정해 봅시다. 이러한 시스템을 위한 캐시는 다음과 같이 구성됩니다.
- 캐시는 총 S=개의 세트(set)로 구성된 하나의 배열(array)입니다.
- 각 세트는 E개의 캐시 라인(cache line)으로 이루어져 있습니다.
- 각 캐시 라인은 다음 세 가지 요소로 구성됩니다.
- 데이터 블록(Data Block): B= 바이트 크기의 실제 데이터 덩어리입니다.
- 유효 비트(Valid Bit): 이 라인에 유효한(의미 있는) 데이터가 저장되어 있는지를 나타내는 1비트 플래그입니다. (1=유효, 0=무효)
- 태그 비트(Tag Bits): 이 캐시 라인에 어떤 메모리 블록이 저장되어 있는지를 고유하게 식별하는 t=m−(b+s) 비트 크기의 식별자입니다.
일반적으로 캐시의 구조는 (S, E, B, m)이라는 튜플(tuple)로 요약하여 표현할 수 있습니다.
캐시 크기(용량, C)의 정의
캐시의 크기 C는 모든 데이터 블록의 총합으로 계산됩니다. 태그 비트나 유효 비트 같은 부가 정보는 크기 계산에 포함하지 않습니다.C=S×E×B
2. 주소 해석을 통한 데이터 탐색 과정
CPU가 load 명령에 따라 특정 메모리 주소 A의 데이터를 읽으려고 할 때, 캐시는 이 주소 A의 비트들을 마치 매우 간단한 해시 함수를 사용하는 해시 테이블처럼 해석하여 원하는 데이터가 캐시에 있는지 즉시 알아냅니다.
m비트의 메모리 주소 A는 캐시의 파라미터 S와 B에 의해 다음과 같이 세 개의 필드로 나뉩니다.
| t bits (Tag) | s bits (Set Index) | b bits (Block Offset) | | m-1 (s+b) | (s+b)-1 b | b-1 0 |
데이터 탐색은 다음 3단계로 이루어집니다.
- 1단계: 세트 선택 (Set Selection)
- 주소
A의 가운데에 있는s개의 세트 인덱스 비트(set index bits)를 확인합니다. - 이 비트들을 부호 없는 정수로 해석하면, 데이터가 저장되어야 할 정확한 세트의 번호를 알 수 있습니다. (예:
s=10이면 0번부터 1023번 세트 중 하나를 가리킴)
- 주소
- 2단계: 라인 탐색 및 일치 확인 (Line Matching)
- 지정된 세트에 도착하면, 이제 그 세트 안에 있는
E개의 라인들 중에서 우리가 찾는 데이터가 들어있는 라인이 있는지 확인해야 합니다. - 주소
A의 상위t개의 태그 비트(tag bits)를 해당 세트 내의 모든(E개) 라인의 태그 비트와 비교합니다. - 특정 라인에 우리가 찾는 데이터가 존재하려면 두 가지 조건을 모두 만족해야 합니다.
- 라인의 유효 비트(valid bit)가 1이어야 한다.
- 라인의 태그 비트가 주소
A의 태그 비트와 일치해야 한다.
- 지정된 세트에 도착하면, 이제 그 세트 안에 있는
- 3단계: 데이터 추출 (Word Extraction)
- 위 두 단계를 통해 정확한 라인을 찾았다면(캐시 히트), 마지막으로 주소
A의 하위b개의 블록 오프셋 비트(block offset bits)를 사용합니다. - 이 오프셋 비트는
B바이트 크기의 데이터 블록 내에서 우리가 정확하게 원하는 워드(word)나 바이트(byte)의 상대적인 위치를 알려줍니다.
- 위 두 단계를 통해 정확한 라인을 찾았다면(캐시 히트), 마지막으로 주소
3. 캐시 파라미터 요약
| 기호 | 설명 |
|---|---|
| 기본 파라미터 | |
| m | 메모리 주소의 비트 수 |
| 고유한 메모리 주소의 총 개수 | |
| 캐시 구조 파라미터 | |
| 캐시 내의 세트(Set) 총 개수 | |
| E | 한 세트당 캐시 라인(Line)의 개수 (연관성, Associativity) |
| 한 캐시 라인 내의 블록(Block) 크기 (바이트 단위) | |
| 파생 파라미터 | |
| s | 세트 인덱스를 위한 주소 비트 수 |
| b | 블록 오프셋을 위한 주소 비트 수 |
| t=m−(s+b) | 태그를 위한 주소 비트 수 |
| C=S×E×B | 태그와 유효 비트를 제외한 캐시의 총 크기 (용량) |
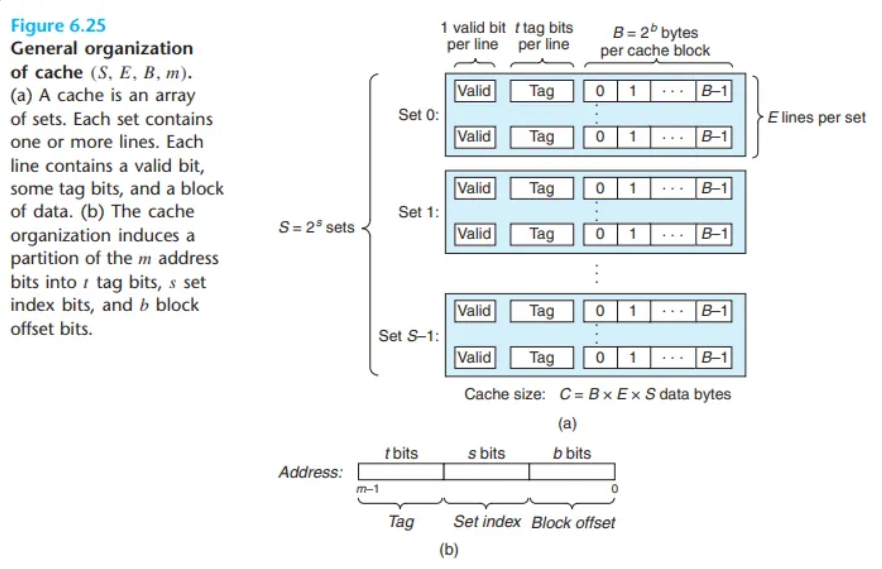
6.4.2 직접 매핑 캐시 (Direct-Mapped Caches)
캐시는 세트당 캐시 라인의 개수(E)에 따라 여러 종류로 나뉩니다. 세트당 단 하나의 라인(E=1)만을 갖는 캐시를 직접 매핑 캐시(direct-mapped cache)라고 합니다.
직접 매핑 캐시의 동작 과정
CPU, 레지스터 파일, L1 캐시, 메인 메모리로 구성된 시스템을 가정해 봅시다. CPU가 메모리 워드 w를 읽는 명령어를 실행하면, 먼저 L1 캐시에 w를 요청합니다.
- 캐시 히트 (Cache Hit)의 경우:
만약 L1 캐시가w의 복사본을 가지고 있다면, L1 캐시 히트(L1 cache hit)가 발생합니다. 이 경우 캐시는 신속하게w를 추출하여 CPU에 반환합니다. - 캐시 미스 (Cache Miss)의 경우:
반대로, 캐시에w가 없다면 캐시 미스(cache miss)가 발생합니다. 이때 CPU는 L1 캐시가w를 포함하는 블록 전체의 복사본을 메인 메모리에 요청하여 가져올 때까지 반드시 대기(wait/stall)해야 합니다. 메모리로부터 요청된 블록이 도착하면, L1 캐시는 그 블록을 자신의 캐시 라인 중 하나에 저장하고, 저장된 블록에서w를 추출한 뒤 CPU로 반환합니다.
데이터 탐색의 3단계
캐시가 요청이 히트인지 미스인지 판단하고, 요청된 워드를 추출하는 전체 과정은 다음과 같은 3단계로 구성됩니다. 이 단계들은 앞서 6.4.1절에서 설명한 일반적인 캐시 구조의 동작 원리와 동일합니다.
- 세트 선택 (Set Selection)
- 라인 일치 확인 (Line Matching)
- 워드 추출 (Word Extraction)
직접 매핑 캐시에서의 세트 선택 (Set Selection in Direct-Mapped Caches)
이 단계에서 캐시는 먼저 메모리 주소 w의 중간 부분에서 s개의 세트 인덱스 비트(set index bits)를 추출합니다.
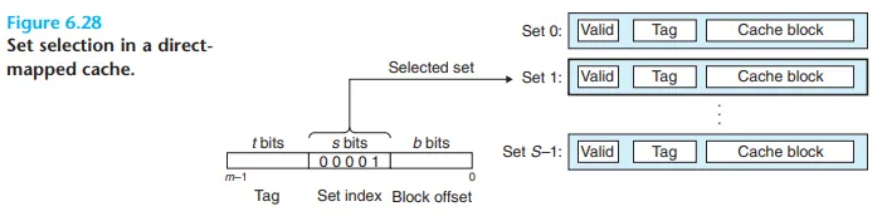
- 동작 원리: 추출된 이 비트들은 부호 없는 정수(unsigned integer)로 해석되며, 이 정수 값은 캐시 내의 세트 번호(set number)에 직접 대응됩니다.
- 구조적 관점: 만약 캐시를 세트들로 이루어진 하나의 1차원 배열(one-dimensional array)이라고 생각한다면, 세트 인덱스 비트는 이 배열에 접근하기 위한 인덱스(index) 역할을 합니다. 하드웨어는 이 인덱스 값을 사용하여 어떤 계산도 없이 즉시 해당 세트로 찾아갈 수 있습니다.
- 본문 예시: 그림 6.28의 예시에서, 세트 인덱스 비트가
00001(2진수)이라면 이는 정수1로 해석됩니다. 따라서 이 주소에 해당하는 데이터는 반드시 캐시의 1번 세트(set 1)에 저장되어야 함을 의미합니다. 캐시는 즉시 1번 세트를 선택하여 다음 단계를 진행합니다.
직접 매핑 캐시에서의 라인 일치 확인 (Line Matching in Direct-Mapped Caches)
이전 단계에서 특정 세트 i를 선택했으므로, 다음 단계는 우리가 찾는 워드 w의 복사본이 세트 i 안에 포함된 캐시 라인에 저장되어 있는지를 판단하는 것입니다.
직접 매핑 캐시(Direct-Mapped Cache)에서는 이 과정이 매우 간단하고 빠릅니다. 왜냐하면 정의에 따라 세트당 단 하나의 캐시 라인만 존재하기 때문입니다 (E=1).
따라서, 워드 w의 복사본이 해당 라인에 들어있다고 확신하려면 다음 두 가지 조건이 모두 만족되어야 합니다.
- 라인의 유효 비트(valid bit)가 1로 설정되어 있어야 합니다.
- 캐시 라인에 저장된 태그(tag)가 주소
w의 태그와 일치해야 합니다.
동작 예시
본문 예시(그림 6.29)에서는 이 과정이 다음과 같이 진행됩니다.
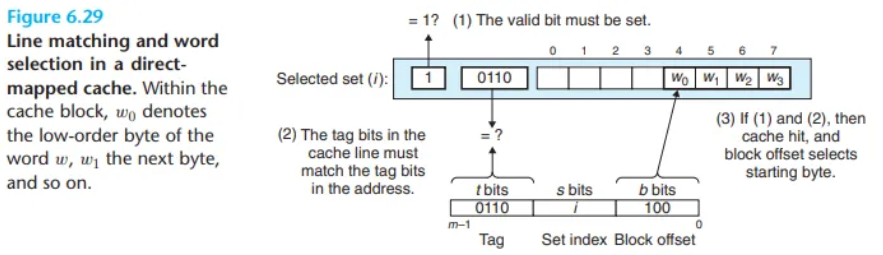
- 세트 선택: 이전 단계에서 특정 세트가 선택되었습니다. 이 세트에는 단 하나의 캐시 라인만 존재합니다.
- 유효 비트 확인: 먼저, 이 라인의 유효 비트가 1로 설정되어 있는 것을 확인합니다. 이를 통해 이 라인에 저장된 태그와 데이터 블록이 쓰레기 값이 아닌 의미 있는 정보라는 것을 알 수 있습니다.
- 태그 비교: 다음으로, 캐시 라인에 저장된 태그 비트와 CPU가 요청한 주소의 태그 비트를 비교합니다. 이 두 태그가 서로 일치하는 것을 확인했습니다.
위 두 조건이 모두 만족되었으므로, 우리는 우리가 원하는 워드의 복사본이 바로 이 라인에 저장되어 있음을 확신할 수 있습니다. 즉, 캐시 히트(cache hit)가 발생한 것입니다.
반대로, 만약 유효 비트가 0이거나 태그가 일치하지 않았다면, 둘 중 하나라도 만족하지 못했다면 캐시 미스(cache miss)가 발생했을 것입니다.
직접 매핑 캐시에서의 워드 선택 (Word Selection in Direct-Mapped Caches)
일단 캐시 히트(hit)가 발생하면, 우리가 찾는 워드 w가 해당 블록 어딘가에 존재한다는 것을 알게 됩니다. 이 마지막 단계는 그 블록 내에서 원하는 워드가 정확히 어디서부터 시작하는지를 결정하는 과정입니다.
- 동작 원리: 이 위치는 주소의 가장 하위 비트들인 블록 오프셋 비트(block offset bits)를 통해 알 수 있습니다. 블록 오프셋 비트는 원하는 워드의 첫 번째 바이트(first byte)가 블록 내에서 얼마나 떨어져 있는지를 나타내는 상대적인 주소입니다.
- 구조적 관점: 캐시를 라인들의 배열로 생각했던 것처럼, 하나의 블록은 바이트들의 배열(array of bytes)로, 그리고 바이트 오프셋(byte offset)은 그 배열의 인덱스(index)로 생각할 수 있습니다.
- 본문 예시: 그림 6.29의 예시에서, 블록 오프셋 비트가
100(2진수)인 것은 우리가 찾는 워드w의 복사본이 해당 블록의 4번째 바이트(byte 4)에서부터 시작한다는 것을 의미합니다. (여기서는 워드의 크기가 4바이트라고 가정합니다.) 따라서 캐시는 블록의 4, 5, 6, 7번 바이트를 묶어 하나의 워드로 CPU에 전달하게 됩니다.
직접 매핑 캐시에서 미스 발생 시 라인 교체 (Line Replacement on Misses in Direct-Mapped Caches)
상황
캐시 미스(miss)가 발생하면, 캐시는 메모리 계층 구조의 다음 레벨(예: 메인 메모리)로부터 요청된 블록을 가져와야 합니다. 그리고 이 새로운 블록을 주소의 세트 인덱스 비트(set index bits)가 가리키는 세트의 캐시 라인에 저장해야 합니다.
교체 정책
일반적으로, 만약 해당 세트가 유효한 캐시 라인들로 이미 가득 차 있다면, 기존 라인 중 하나는 반드시 교체(evicted)되어야 합니다.
그러나 직접 매핑 캐시(direct-mapped cache)의 경우, 각 세트는 정확히 하나의 라인(E=1)만을 포함하므로 이 교체 정책은 매우 간단하고 자명합니다(trivial).
- 동작 원리: 선택의 여지가 없습니다. 세트 인덱스가 가리키는 곳에는 단 하나의 라인만 존재하기 때문에, 캐시 미스가 발생하면 그곳에 현재 저장되어 있는 라인을 새로 가져온 라인으로 무조건 덮어쓰면(replace) 됩니다. 복잡한 교체 알고리즘(LRU)이 전혀 필요하지 않습니다.
직접 매핑 캐시의 동작 과정 통합 예시 (Putting It Together: A Direct-Mapped Cache in Action)
캐시가 세트를 선택하고 라인을 식별하는 메커니즘은 극도로 단순해야만 합니다. 왜냐하면 하드웨어는 이 모든 과정을 수 나노초(nanoseconds) 안에 수행해야 하기 때문입니다. 하지만 인간에게는 이러한 비트 조작 방식이 혼란스러울 수 있으므로, 구체적인 예시를 통해 전체 과정을 명확히 이해해 보겠습니다.
1. 시스템 사양 정의
다음과 같은 사양을 가진 직접 매핑 캐시가 있다고 가정합시다.
(S, E, B, m) = (4, 1, 2, 4)
각 파라미터의 의미는 다음과 같습니다.
- S = 4: 캐시에는 총 4개의 세트(set)가 있습니다. (s=2)
- E = 1: 세트당 라인은 1개입니다. (즉, 직접 매핑 방식)
- B = 2: 블록 크기는 2바이트입니다. (b=1)
- m = 4: 메모리 주소는 4비트입니다.
또한, 워드(word)의 크기는 1바이트라고 가정하겠습니다.
2. 주소 공간 분석
캐시를 처음 배울 때는 전체 주소 공간을 나열하고 주소 비트를 분할해 보는 것이 매우 유익합니다. 4비트 주소 체계는 다음과 같이 Tag, Index, Offset으로 나뉩니다.
- Offset (b): 블록 크기가 2바이트()이므로, 하위 1비트가 오프셋이 됩니다.
- Index (s): 세트 개수가 4개()이므로, 중간 2비트가 인덱스가 됩니다.
- Tag (t): 나머지 상위 1비트가 태그가 됩니다. (
t = m - s - b = 4 - 2 - 1 = 1)
[4비트 주소 구조: t s s o]
| Tag(1) | Index(2) | Offset(1) |
이 주소 공간에서 주목할 만한 점들은 다음과 같습니다.
- 메모리 블록 식별: 태그와 인덱스 비트를 합치면(
t s s) 메모리의 각 블록을 고유하게 식별할 수 있습니다. 예를 들어, 블록 0은 주소 0(0000), 1(0001)로 구성되고, 블록 1은 주소 2(0010), 3(0011)으로 구성됩니다. - 블록 매핑: 메모리 블록은 총 8개()이지만 캐시 세트는 4개뿐이므로, 여러 블록이 동일한 캐시 세트로 매핑됩니다. 예를 들어, 블록 0(인덱스
00)과 블록 4(인덱스00)는 모두 0번 세트(set 0)로 매핑됩니다. - 태그의 역할: 동일한 세트로 매핑되는 블록들은 태그 비트에 의해 고유하게 구별됩니다. 예를 들어, 0번 세트로 매핑되는 블록 0의 태그는
0이고 블록 4의 태그는1입니다.
3. CPU 읽기 요청 시뮬레이션
CPU가 1바이트 워드를 순차적으로 읽는다고 가정하고 캐시의 동작을 시뮬레이션해 봅시다.
초기 캐시 상태 (비어 있음):
(V = Valid bit)
| Set | V | Tag | block[0] | block[1] |
|---|---|---|---|---|
| 0 | 0 | |||
| 1 | 0 | |||
| 2 | 0 | |||
| 3 | 0 |
1. 주소 0 (0000)의 워드 읽기
- 분석: 주소
0000→ Tag=0, Index=00(Set 0), Offset=0 - 결과: 캐시 미스 (Cache Miss). 0번 세트의 유효 비트(Valid bit)가
0이기 때문입니다. - 동작: 메모리에서 블록 0을 가져와 0번 세트에 저장합니다. 유효 비트를
1로, 태그를0으로 설정합니다. 블록의 0번째 바이트m[0]을 CPU에 반환합니다.
| Set | V | Tag | block[0] | block[1] |
|---|---|---|---|---|
| 0 | 1 | 0 | m[0] | m[1] |
| 1 | 0 | |||
| 2 | 0 | |||
| 3 | 0 |
2. 주소 1 (0001)의 워드 읽기
- 분석: 주소
0001→ Tag=0, Index=00(Set 0), Offset=1 - 결과: 캐시 히트 (Cache Hit). 0번 세트의 유효 비트는
1이고, 태그(0)도 일치합니다. - 동작: 캐시 라인의 블록에서 1번째 바이트
m[1]을 즉시 CPU에 반환합니다. 캐시의 상태는 변하지 않습니다.
3. 주소 13 (1101)의 워드 읽기
- 분석: 주소
1101→ Tag=1, Index=10(Set 2), Offset=1 - 결과: 캐시 미스 (Cache Miss). 2번 세트의 유효 비트가
0이기 때문입니다. - 동작: 메모리에서 블록 6(
110x에 해당)을 가져와 2번 세트에 저장하고m[13]을 CPU에 반환합니다.
| Set | V | Tag | block[0] | block[1] |
|---|---|---|---|---|
| 0 | 1 | 0 | m[0] | m[1] |
| 1 | 0 | |||
| 2 | 1 | 1 | m[12] | m[13] |
| 3 | 0 |
4. 주소 8 (1000)의 워드 읽기
- 분석: 주소
1000→ Tag=1, Index=00(Set 0), Offset=0 - 결과: 캐시 미스 (Cache Miss). 0번 세트의 유효 비트는
1이지만, 라인에 저장된 태그(0)가 주소의 태그(1)와 일치하지 않기 때문입니다. - 동작: 메모리에서 블록 4를 가져와 0번 세트에 덮어씁니다 (교체). 그리고
m[8]을 CPU에 반환합니다.
| Set | V | Tag | block[0] | block[1] |
|---|---|---|---|---|
| 0 | 1 | 1 | m[8] | m[9] |
| 1 | 0 | |||
| 2 | 1 | 1 | m[12] | m[13] |
| 3 | 0 |
5. 주소 0 (0000)의 워드 읽기
- 분석: 주소
0000→ Tag=0, Index=00(Set 0), Offset=0 - 결과: 또다시 캐시 미스 (Cache Miss). 바로 이전의 주소 8 접근으로 인해 블록 0이 캐시에서 쫓겨났기 때문입니다.
- 설명: 캐시에 충분한 공간이 있음에도 불구하고, 동일한 세트로 매핑되는 블록들을 번갈아 참조하면서 계속해서 미스가 발생하는 이런 현상이 바로 충돌 미스(Conflict Miss)의 대표적인 예입니다.
- 동작: 메모리에서 블록 0을 다시 가져와 0번 세트에 덮어씁니다.
| Set | V | Tag | block[0] | block[1] |
|---|---|---|---|---|
| 0 | 1 | 0 | m[0] | m[1] |
| 1 | 0 | |||
| 2 | 1 | 1 | m[12] | m[13] |
| 3 | 0 |
직접 매핑 캐시에서의 충돌 미스 (Conflict Misses in Direct-Mapped Caches)
충돌 미스는 실제 프로그램에서 흔하게 발생하며, 때로는 이해하기 힘든 성능 문제를 일으키는 원인이 됩니다. 특히 직접 매핑 캐시에서는 프로그램이 배열의 크기를 2의 거듭제곱(power of 2)으로 사용할 때 충돌 미스가 자주 발생합니다.
문제 시나리오: dotprod 함수 예제
두 벡터의 내적(dot product)을 계산하는 다음 함수를 예로 들어보겠습니다.
float dotprod(float x[8], float y[8])
{
float sum = 0.0;
int i;
for (i = 0; i < 8; i++)
sum += x[i] * y[i];
return sum;
}이 함수는 배열 x와 y에 대해 순차적으로 접근하므로 좋은 공간적 지역성을 가집니다. 따라서 높은 캐시 히트율을 기대할 수 있지만, 항상 그렇지는 않습니다.
다음과 같은 시스템 환경을 가정해 봅시다.
float자료형은 4바이트입니다.- 배열
x는 메모리 주소 0부터 시작하는 32바이트 연속 공간에 저장됩니다. - 배열
y는x바로 뒤인 주소 32부터 시작합니다. - 캐시 블록 크기는 16바이트입니다 (float 4개를 담을 수 있음).
- 캐시는 총 2개의 세트(set)를 가집니다 (전체 캐시 크기 = 2 sets * 16 bytes/block = 32 bytes).
- 변수
sum은 CPU 레지스터에 저장되어 메모리 참조가 필요 없다고 가정합니다.
이 가정 하에, 각 배열 요소 x[i]와 y[i]는 항상 동일한 캐시 세트로 매핑됩니다.
| 요소 | 주소 | 세트 인덱스 | 요소 | 주소 | 세트 인덱스 | |
|---|---|---|---|---|---|---|
| x[0] | 0 | 0 | y[0] | 32 | 0 | |
| x[1] | 4 | 0 | y[1] | 36 | 0 | |
| x[2] | 8 | 0 | y[2] | 40 | 0 | |
| x[3] | 12 | 0 | y[3] | 44 | 0 | |
| x[4] | 16 | 1 | y[4] | 48 | 1 | |
| x[5] | 20 | 1 | y[5] | 52 | 1 | |
| x[6] | 24 | 1 | y[6] | 56 | 1 | |
| x[7] | 28 | 1 | y[7] | 60 | 1 |
(세트 인덱스 = (주소 / 블록 크기) % 세트 개수 = (주소 / 16) % 2)
동작 과정: 스래싱(Thrashing)의 발생
- 루프의 첫 번째 반복에서
x[0]에 접근합니다. 이는 미스(miss)이며,x[0]~x[3]을 포함하는 블록이 0번 세트에 로드됩니다. - 다음으로
y[0]에 접근합니다. 이 또한 미스이며,y[0]~y[3]을 포함하는 블록이 0번 세트로 로드됩니다. 이 과정에서 바로 이전에 가져왔던x의 블록을 덮어쓰게(교체하게) 됩니다. - 두 번째 반복에서
x[1]에 접근합니다. 이는 또 다시 미스입니다. 왜냐하면y블록이x블록을 덮어썼기 때문입니다. 결국x[0]~x[3]블록이 다시 0번 세트로 로드되며, 이번에는y블록을 덮어씁니다.
이것이 바로 충돌 미스입니다. x와 y에 대한 모든 후속 참조는 x의 블록과 y의 블록 사이를 계속 왔다 갔다 하며 서로를 쫓아내는 결과를 낳습니다.
스래싱 (Thrashing)
캐시가 동일한 세트의 캐시 블록들을 반복적으로 로드하고 축출(evicting)하는 모든 상황을 설명하는 용어입니다.
결론적으로, 프로그램의 공간적 지역성이 좋고 캐시에 x와 y의 블록을 모두 담을 공간이 있음에도 불구하고, 두 블록이 동일한 캐시 세트로 매핑되기 때문에 모든 참조가 충돌 미스로 이어집니다. 이러한 종류의 스래싱으로 인해 프로그램 실행 속도가 2~3배까지 느려지는 것은 드문 일이 아닙니다.
해결책: 패딩(Padding) 기법
다행히도, 프로그래머는 이 현상을 인지하기만 하면 스래싱 문제를 쉽게 해결할 수 있습니다. 한 가지 간단한 해결책은 각 배열의 끝에 B 바이트(블록 크기)만큼의 패딩(padding)을 추가하는 것입니다.
예를 들어, float x[8] 대신 float x[12]로 선언해 봅시다.
x배열의 크기: 12 * 4 bytes = 48 bytesy배열의 시작 주소: 48
이렇게 하면 배열 요소와 세트 간의 매핑이 다음과 같이 변경됩니다.
| 요소 | 주소 | 세트 인덱스 | 요소 | 주소 | 세트 인덱스 | |
|---|---|---|---|---|---|---|
| x[0] | 0 | 0 | y[0] | 48 | 1 | |
| x[1] | 4 | 0 | y[1] | 52 | 1 | |
| x[2] | 8 | 0 | y[2] | 56 | 1 | |
| x[3] | 12 | 0 | y[3] | 60 | 1 | |
| x[4] | 16 | 1 | y[4] | 64 | 0 | |
| x[5] | 20 | 1 | y[5] | 68 | 0 | |
| x[6] | 24 | 1 | y[6] | 72 | 0 | |
| x[7] | 28 | 1 | y[7] | 76 | 0 |
x 배열 끝에 패딩을 추가함으로써, 이제 x[i]와 y[i]는 서로 다른 세트로 매핑됩니다. 예를 들어, x[0]은 0번 세트로, y[0]은 1번 세트로 매핑됩니다. 이로써 두 배열의 블록이 캐시 내에 평화롭게 공존할 수 있게 되어, 파괴적인 스래싱 현상이 사라지고 캐시 히트율이 극적으로 향상됩니다.
부가 설명: 왜 중간 비트를 인덱스로 사용하는가? (Why index with the middle bits?)
사용자는 왜 캐시가 주소의 상위 비트(high-order bits) 대신 중간 비트(middle bits)를 세트 인덱스로 사용하는지 궁금할 수 있습니다. 여기에는 중간 비트를 사용하는 것이 더 나은 합당한 이유가 있습니다.
핵심 요약
중간 비트를 인덱스로 사용하는 이유는 프로그램의 공간적 지역성(spatial locality)을 최대한 활용하기 위함입니다. 중간 비트를 사용하면 메모리 상에서 서로 인접한(contiguous) 블록들이 캐시의 서로 다른 세트로 분산되어 매핑됩니다. 이는 캐시 공간을 효율적으로 사용하게 하여 히트율을 높입니다.
1. 상위 비트를 인덱스로 사용할 경우의 문제점
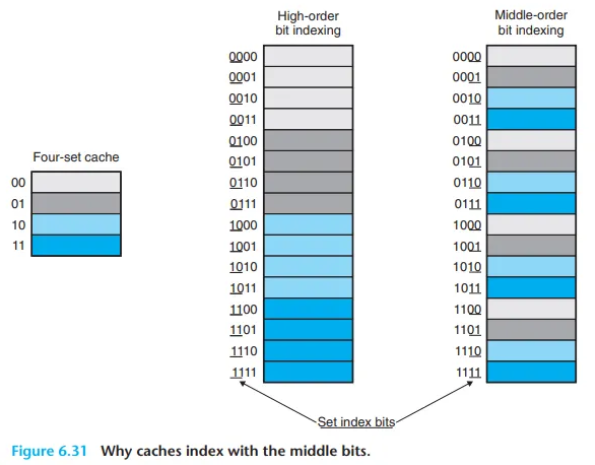
만약 주소의 상위 비트를 인덱스로 사용하면, 연속적인 메모리 블록들이 동일한 캐시 세트로 매핑되는 문제가 발생합니다.
- 동작 방식: 주소가 순차적으로 증가할 때, 가장 먼저 변하는 것은 하위 비트들입니다. 상위 비트들은 한참 동안 변하지 않습니다. 따라서 상위 비트를 인덱스로 사용하면, 주소
0, 1, 2, 3...에 해당하는 여러 연속된 블록들이 모두 동일한 인덱스 값을 갖게 됩니다. - 예시 (본문 그림 6.31): 첫 4개의 메모리 블록은 모두 첫 번째 캐시 세트(Set 0)로 매핑되고, 다음 4개의 블록은 모두 두 번째 캐시 세트(Set 1)로 매핑됩니다.
- 문제점: 공간적 지역성이 좋은 프로그램이 배열을 순차적으로 탐색(scan)한다고 가정해 봅시다. 프로그램은
Block 0,Block 1,Block 2,Block 3순서로 접근할 것입니다. 하지만 이 블록들은 모두 Set 0으로만 매핑됩니다. 결국Block 1이Block 0을 쫓아내고,Block 2가Block 1을 쫓아내는 스래싱(thrashing)이 발생합니다. 캐시의 다른 세트들이 텅 비어있음에도 불구하고, 캐시는 특정 순간에 배열의 단 하나의 블록 크기만큼의 조각만을 담을 수 있게 됩니다. 이는 캐시 공간의 매우 비효율적인 사용입니다.
2. 중간 비트를 인덱스로 사용할 경우의 장점
이와 대조적으로, 중간 비트를 인덱스로 사용하면 인접한 블록들은 항상 서로 다른 캐시 세트로 매핑됩니다.
- 동작 방식: 메모리 주소가 블록 크기만큼 증가하면(즉, 다음 블록으로 넘어가면),
Tag와Index비트 경계에 있는 비트부터 순차적으로 변하게 됩니다. 즉,Index비트가 가장 먼저 바뀝니다. - 결과: 이 방식 덕분에
Block 0은Set 0으로,Block 1은Set 1로,Block 2는Set 2로... 이런 식으로 데이터가 캐시의 여러 세트에 골고루 분산되어 저장됩니다. - 장점: 프로그램이 배열을 순차적으로 탐색할 때, 연속된 블록들이 캐시의 다른 세트들에 차곡차곡 쌓이게 됩니다. 이로써 캐시는 전체 캐시 크기(C)만큼의 배열 조각을 한 번에 담을 수 있게 됩니다. 이는 공간적 지역성의 이점을 극대화하여 캐시 히트율을 크게 향상시키는 매우 효율적인 방식입니다.
결론적으로, 중간 비트 인덱싱은 순차적 메모리 접근 패턴이 캐시의 특정 부분에만 집중되지 않고 캐시 전체에 고르게 퍼지도록 보장하는, 영리한 하드웨어 설계 기법입니다.
6.4.3 세트 연관 캐시 (Set Associative Caches)
세트 연관 캐시의 등장 배경
직접 매핑 캐시에서 발생하는 충돌 미스(conflict miss) 문제는, 각 세트가 정확히 하나의 라인만 가질 수 있다(E=1)는 제약 조건에서 비롯됩니다.
- 세트 연관 캐시(set associative cache)는 이 제약 조건을 완화(relax)하여, 각 세트가 하나 이상의 캐시 라인을 가질 수 있도록 한 구조입니다.
- 정의:
1 < E < C/B조건을 만족하는 캐시를 일반적으로 E-way 세트 연관 캐시(E-way set associative cache)라고 부릅니다. (여기서C는 캐시 크기,B는 블록 크기입니다.) - 특수 케이스:
E = C/B가 되는 극단적인 경우(완전 연관 캐시)는 다음 섹션에서 다룹니다.
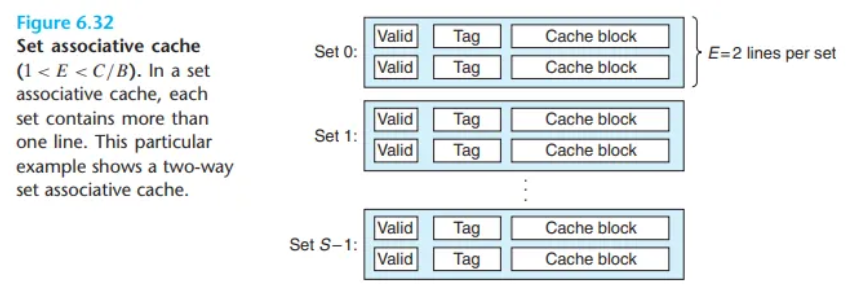
- 예시: 본문 그림 6.32는 2-way 세트 연관 캐시의 구조를 보여줍니다. 즉, 각 세트가 2개의 캐시 라인을 가집니다.
세트 연관 캐시에서의 세트 선택 (Set Selection in Set Associative Caches)
세트 연관 캐시에서 데이터 탐색의 첫 번째 단계인 '세트 선택' 과정은 직접 매핑 캐시와 완전히 동일(identical)합니다.
- 동작 원리: 캐시 하드웨어는 메모리 주소의 중간에 있는 세트 인덱스 비트(set index bits)를 사용하여, 데이터가 속해야 할 세트를 직접적으로 식별합니다.
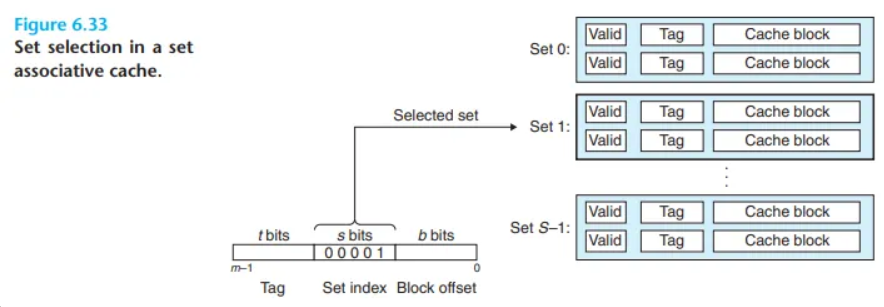
이 원리는 그림 6.33에 요약되어 있으며, 세트 연관성의 정도(E의 값)와는 무관하게 동일한 방식으로 동작합니다.
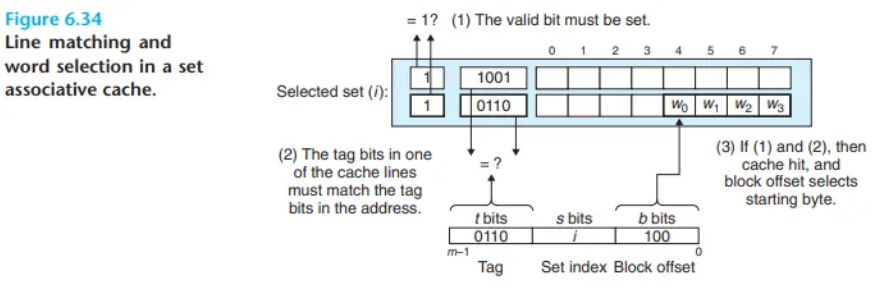
세트 연관 캐시에서의 라인 일치 확인 및 워드 선택 (Line Matching and Word Selection in Set Associative Caches)
1. 라인 일치 확인 (Line Matching)
세트 연관 캐시에서의 라인 일치 확인 과정은 직접 매핑 캐시보다 더 복잡(involved)합니다. 그 이유는 요청된 워드가 세트 안에 있는지 판별하기 위해, 세트 내에 있는 여러 라인(E개)의 태그와 유효 비트를 모두 검사해야 하기 때문입니다.
이 과정을 이해하기 위해 연관 메모리(associative memory)라는 개념을 도입할 수 있습니다.
- 일반 메모리 (Conventional Memory): 주소(address)를 입력으로 받아 해당 주소에 저장된 값(value)을 반환하는 값들의 배열입니다.
address → value - 연관 메모리 (Associative Memory): (키, 값) 쌍으로 이루어진 배열이며, 키(key)를 입력으로 받아 입력 키와 일치하는 (키, 값) 쌍의 값(value)을 반환합니다.
key → value(키 검색 기반)
세트 연관 캐시의 각 세트(set)는 바로 이 작은 연관 메모리처럼 동작한다고 생각할 수 있습니다.
- 키 (Key): 태그(tag)와 유효 비트(valid bit)의 조합
- 값 (Value): 데이터 블록(block)의 내용물
라인 일치 확인 과정에서 캐시 하드웨어는 CPU가 보낸 주소의 태그를 '입력 키'로 사용합니다. 그리고 이 '입력 키'를 현재 선택된 세트 안에 있는 모든 라인들의 '키(저장된 태그 + 유효 비트)'와 동시에, 병렬적으로 비교합니다.
여기서 중요한 아이디어는, 해당 세트로 매핑되는 모든 메모리 블록은 그 세트 안의 어떤 라인에든(any line) 위치할 수 있다는 점입니다. 따라서 캐시는 반드시 세트 내의 각 라인을 모두 검색하여, 유효 비트가 1이고 태그가 주소의 태그와 일치하는 라인이 있는지 찾아야 합니다. 만약 그런 라인을 찾으면, 캐시 히트(cache hit)가 발생합니다.
2. 워드 선택 (Word Selection)
일단 캐시 히트가 발생하여 원하는 데이터가 담긴 라인이 확정되면, 마지막 단계인 '워드 선택' 과정은 이전(직접 매핑 캐시)과 동일합니다.
주소의 하위 비트인 블록 오프셋(block offset)을 사용하여, 블록 내에서 CPU가 정확하게 원하는 워드의 위치를 찾아내어 반환합니다.
세트 연관 캐시에서 미스 발생 시 라인 교체 (Line Replacement on Misses in Set Associative Caches)
1. 교체 문제의 발생
만약 CPU가 요청한 워드가 현재 선택된 세트 내의 어떤 라인에도 저장되어 있지 않다면, 캐시 미스(cache miss)가 발생합니다. 이 경우 캐시는 해당 워드를 포함하는 블록을 메모리에서 가져와야 합니다.
하지만 캐시가 블록을 가져온 후, 세트 내의 어떤 라인을 교체해야 할까요?
- 쉬운 경우 (빈 라인이 있을 때): 물론, 세트 내에 비어있는(유효 비트가 0인) 라인이 있다면, 그 라인이 좋은 후보가 될 것입니다.
- 어려운 경우 (세트가 가득 찼을 때): 하지만 세트 내에 빈 라인이 없다면, 우리는 기존의 비어있지 않은 라인들 중 하나를 희생양으로 선택해야만 합니다. 그리고 CPU가 가까운 미래에 이 교체된 라인을 참조하지 않기를 바랄 수밖에 없습니다.
2. 교체 정책의 종류 (Replacement Policies)
프로그래머가 캐시 교체 정책에 대한 지식을 자신의 코드에 직접적으로 활용하기는 매우 어렵기 때문에, 여기서는 아주 자세한 내용까지는 다루지 않겠습니다.
- 임의 교체 정책 (Random Replacement): 가장 간단한 교체 정책은 교체할 라인을 무작위로 선택하는 것입니다.
- 더 정교한 정책들: 다른 더 정교한 정책들은 지역성의 원리(principle of locality)를 활용하여, 교체된 라인이 가까운 미래에 참조될 확률을 최소화하려고 시도합니다.
- 최소 빈도 사용 (LFU, Least Frequently Used) 정책: 과거의 특정 시간 동안 참조된 횟수가 가장 적은 라인을 교체합니다.
- 최근 최소 사용 (LRU, Least Recently Used) 정책: 가장 오래 전에 마지막으로 접근된(last accessed the furthest in the past) 라인을 교체합니다.
3. 비용과 효용의 트레이드오프 (Cost-Benefit Trade-off)
이러한 모든 정교한 정책들은 추가적인 시간과 하드웨어를 필요로 하는 단점이 있습니다.
하지만 메모리 계층 구조에서 CPU로부터 멀어질수록(하위 계층으로 갈수록), 미스 발생으로 인한 비용(성능 저하)은 더욱 비싸집니다. 따라서 하위 계층 캐시일수록, 좋은 교체 정책을 사용하여 미스를 최소화하는 것이 더욱 가치 있는 일이 됩니다.
6.4.4 완전 연관 캐시 (Fully Associative Caches)

완전 연관 캐시는 세트 연관 캐시의 가장 극단적인 형태로, 단 하나의 세트(set)가 캐시의 모든 라인을 포함하는 구조입니다. 즉, E = C/B 인 경우를 말합니다. (E: 세트당 라인 수, C: 캐시 전체 크기, B: 블록 크기)
이는 메모리 블록이 캐시 내의 어떤 비어있는 라인이든 자유롭게 들어갈 수 있다는 의미입니다.
완전 연관 캐시에서의 세트 선택 (Set Selection in Fully Associative Caches)
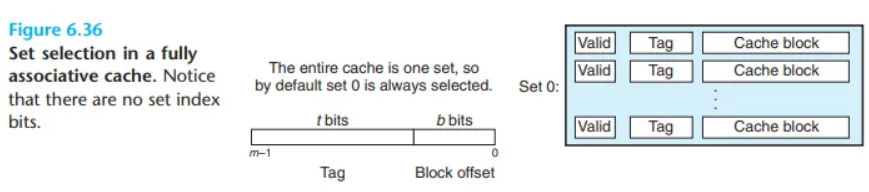
완전 연관 캐시에서의 세트 선택 과정은 매우 간단하고 자명합니다(trivial). 왜냐하면 캐시 전체가 단 하나의 세트로 이루어져 있기 때문입니다.
- 동작 원리: 선택할 세트가 하나뿐이므로, 세트를 고르는 과정 자체가 무의미합니다.
- 주소 구조의 변화: 이 때문에 메모리 주소에는 세트를 선택하기 위한 세트 인덱스 비트(set index bits)가 존재하지 않습니다. 주소는 오직 태그(tag)와 블록 오프셋(block offset)이라는 두 부분으로만 나뉩니다.
라인 일치 확인 및 워드 선택 (Line Matching and Word Selection in Fully Associative Caches)
완전 연관 캐시에서의 라인 일치 확인과 워드 선택 과정은 세트 연관 캐시와 동일한 방식으로 동작합니다. 주된 차이점은 규모(scale)의 문제입니다.
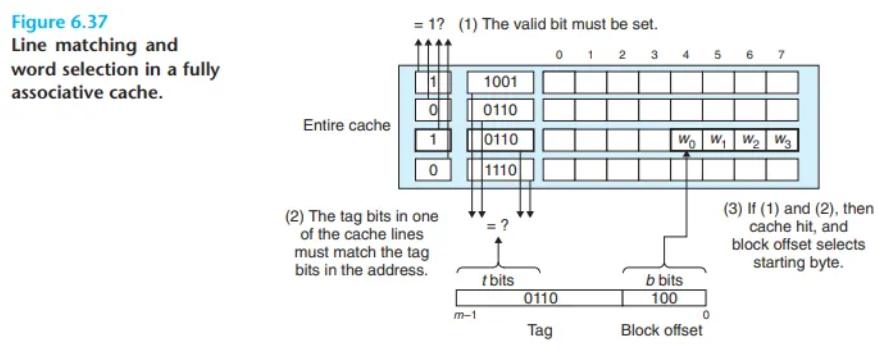
- 라인 일치 확인: 캐시 하드웨어는 CPU가 보낸 주소의 태그를 캐시 내에 있는 모든(All) 라인의 태그와 동시에, 병렬적으로 비교해야 합니다. 세트 연관 캐시가 '세트 내에서만' 병렬 비교를 했던 것과 달리, 완전 연관 캐시는 '캐시 전체에서' 병렬 비교를 수행합니다.
- 워드 선택: 일단 히트가 발생하여 라인이 확정되면, 블록 오프셋을 사용하여 블록 내에서 원하는 워드를 추출하는 방식은 이전과 동일합니다.
구현의 어려움과 실제 사용 사례
수많은 태그를 병렬적으로 검색해야 하므로, 크면서(large) 동시에 빠른(fast) 완전 연관 캐시를 만드는 것은 기술적으로 매우 어렵고 비용이 많이 듭니다.
결과적으로, 완전 연관 캐시는 다음과 같은 소규모 캐시에만 적합합니다.
- TLB (Translation Lookaside Buffer): 가상 메모리 시스템에서 페이지 테이블 항목(가상 주소-물리 주소 변환 정보)을 캐싱하는 데 사용되는 작은 고속 캐시입니다. TLB는 특정 가상 주소에 대한 변환 정보가 있는지 전체를 빠르게 검색해야 하므로, 완전 연관 방식이 이상적입니다. (9.6.2절에서 자세히 다룸)
6.4.5 쓰기 작업 관련 이슈 (Issues with Writes)
지금까지 살펴본 것처럼, 읽기(read) 작업에 대한 캐시의 동작은 비교적 직관적입니다. 먼저 원하는 워드 w의 복사본을 캐시에서 찾고, 히트(hit)하면 즉시 반환합니다. 미스(miss)가 발생하면 w를 포함하는 블록을 하위 메모리 계층에서 가져와 캐시 라인에 저장한 후 w를 반환합니다.
하지만 쓰기(write) 작업의 상황은 조금 더 복잡합니다. 이 복잡성은 크게 두 가지 질문으로 나뉩니다.
- 쓰기 히트(Write Hit) 시: 캐시에 있는 복사본을 갱신한 후, 하위 계층(메인 메모리)의 원본은 언제 갱신할 것인가?
- 쓰기 미스(Write Miss) 시: 캐시에 데이터가 없을 때, 쓰기 작업을 어떻게 처리할 것인가?
1. 쓰기 히트(Write Hit)에 대한 정책
CPU가 쓰려는 워드 w가 이미 캐시에 존재하는 경우(쓰기 히트), 캐시는 두 가지 정책 중 하나를 따릅니다.
가. 즉시 쓰기 (Write-Through)
- 동작: 캐시에 있는
w의 복사본을 갱신하는 즉시, 해당 캐시 블록을 하위 메모리 계층에 바로 씁니다. - 장점: 구현이 매우 간단하며, 캐시와 메모리 간의 데이터가 항상 일치(consistent) 상태를 유지합니다.
- 단점: 모든 쓰기 작업마다 버스 트래픽(bus traffic)을 유발하여 시스템 버스의 병목 현상을 일으킬 수 있습니다. 이는 성능 저하의 주요 원인이 됩니다.
나. 나중 쓰기 (Write-Back)
- 동작: 캐시에 있는
w의 복사본만 갱신하고, 하위 계층으로의 갱신은 가능한 한 미룹니다. 갱신된 블록은 교체 알고리즘에 의해 캐시에서 축출(evicted)될 때만 하위 메모리 계층에 써집니다. - 장점: 지역성(locality) 원리 덕분에, 같은 블록에 여러 번의 쓰기 작업이 발생하더라도 실제 메모리 쓰기는 단 한 번만(축출될 때) 일어나므로 버스 트래픽을 획기적으로 줄일 수 있습니다.
- 단점: 구현이 더 복잡합니다. 캐시는 각 라인마다 해당 블록이 수정되었는지 여부를 나타내는 더티 비트(dirty bit)를 추가로 유지해야 합니다.
- 여러 코어에서의 일관성 문제는 MESI 방법으로 해결
2. 쓰기 미스(Write Miss)에 대한 정책
CPU가 쓰려는 워드 w가 캐시에 없는 경우(쓰기 미스), 두 가지 접근 방식이 있습니다.
가. 쓰기 시 할당 (Write-Allocate)
- 동작: 쓰기 미스가 발생하면, 먼저 하위 계층에서 해당 블록을 캐시로 읽어 들인 후(load), 그 캐시 블록에 쓰기 작업을 수행합니다. (읽기 미스와 유사하게 동작)
- 목표: 쓰기 작업의 공간적 지역성(spatial locality of writes)을 활용하려는 시도입니다. (하나를 쓴 후, 그 주변에 또 쓸 가능성이 높다고 가정)
- 단점: 모든 쓰기 미스가 하위 계층에서 캐시로의 블록 전송을 유발합니다.
나. 쓰기 시 미할당 (No-Write-Allocate)
- 동작: 캐시를 거치지 않고(bypass), 해당 워드를 하위 메모리 계층에 직접 씁니다. 캐시의 내용은 전혀 변경되지 않습니다.
- 목표: 불필요한 블록 읽기 과정을 생략하여 오버헤드를 줄입니다.
일반적으로 이 정책들은 다음과 같이 조합되어 사용됩니다.
- 즉시 쓰기 (Write-Through) 캐시는 보통 쓰기 시 미할당 (No-Write-Allocate) 방식을 사용합니다. (어차피 메모리에 바로 쓸 것이므로 굳이 캐시에 가져올 필요가 없음)
- 나중 쓰기 (Write-Back) 캐시는 보통 쓰기 시 할당 (Write-Allocate) 방식을 사용합니다. (쓰기 작업을 미루려면 일단 데이터를 캐시 안에 가지고 있어야 함)
프로그래머를 위한 조언
쓰기 작업을 위한 캐시 최적화는 매우 미묘하고 어려운 문제입니다. 여기서 다룬 내용은 빙산의 일각에 불과하며, 세부 사항은 시스템마다 다르고 종종 독점 기술이거나 문서화가 잘 되어있지 않습니다.
합리적으로 캐시 친화적인(cache-friendly) 프로그램을 작성하려는 프로그래머에게는, 정신적인 모델(mental model)로서 나중 쓰기, 쓰기 시 할당(Write-Back, Write-Allocate) 방식의 캐시를 가정하는 것을 제안합니다. 여기에는 몇 가지 이유가 있습니다.
- 현대 시스템의 경향: 하위 메모리 계층으로 갈수록 전송 시간이 길어지기 때문에,
즉시 쓰기보다나중 쓰기방식이 더 선호됩니다. 예를 들어, 메인 메모리를 디스크의 캐시로 사용하는 가상 메모리 시스템은나중 쓰기만을 사용합니다. 또한, 로직 집적도가 높아지면서나중 쓰기의 복잡성이라는 단점이 줄어들어, 현대 시스템의 모든 캐시 레벨에서나중 쓰기방식이 점점 더 많이 채택되고 있습니다. - 읽기와의 대칭성:
나중 쓰기, 쓰기 시 할당방식은 읽기 작업과 마찬가지로 지역성을 활용하려는 대칭적인 접근 방식을 취합니다. - 높은 수준의 최적화 가능: 이 모델을 가정함으로써, 프로그래머는 특정 메모리 시스템에 맞춰 코드를 최적화하려는 노력 대신, 좋은 공간적/시간적 지역성을 갖도록 프로그램을 개발하는 높은 수준의 목표에 집중할 수 있습니다.
6.4.6 실제 캐시 계층 구조의 해부 (Anatomy of a Real Cache Hierarchy)
지금까지 우리는 캐시가 프로그램 데이터만을 저장한다고 가정했지만, 사실 캐시는 데이터뿐만 아니라 명령어(instructions)도 저장할 수 있습니다.
- I-cache (명령어 캐시): 오직 명령어만 저장하는 캐시입니다.
- D-cache (데이터 캐시): 오직 프로그램 데이터만 저장하는 캐시입니다.
- 통합 캐시 (Unified Cache): 명령어와 데이터를 모두 저장하는 캐시입니다.
1. I-cache와 D-cache의 분리
현대의 프로세서는 별도의 I-cache와 D-cache를 포함합니다. 여기에는 여러 가지 중요한 이유가 있습니다.
- 동시 접근 및 성능 향상: 두 개의 캐시를 분리함으로써, 프로세서는 파이프라인의 다른 단계에서 명령어 워드(instruction word)와 데이터 워드(data word)를 동시에 읽을 수 있습니다. 만약 캐시가 하나라면, 명령어 인출(Instruction Fetch)과 데이터 접근(Memory Access)이 단일 캐시 포트를 두고 경쟁해야 하는 구조적 위험(structural hazard)이 발생하여 성능이 저하됩니다.
- I-cache의 단순성: I-cache는 일반적으로 읽기 전용(read-only)이므로 더 단순하게 설계할 수 있습니다. 데이터의 수정이 거의 없기 때문에, 복잡한 쓰기 정책(write policy)이나 캐시 일관성 프로토콜(coherence protocol)을 위한 하드웨어가 필요 없어 더 작고 빠르게 만들 수 있습니다.
- 패턴에 따른 최적화: 명령어 접근 패턴과 데이터 접근 패턴은 다릅니다. 두 캐시를 분리하면 각각의 패턴에 맞춰 블록 크기, 연관성(associativity), 용량 등을 다르게 최적화할 수 있습니다. 예를 들어, 명령어 접근은 순차적인 경향이 강하고, 데이터 접근은 더 불규칙적일 수 있습니다.
- 충돌 미스 방지: 캐시를 분리하면 데이터 접근이 명령어 접근과 충돌 미스(conflict miss)를 일으키지 않도록 보장할 수 있으며, 그 반대도 마찬가지입니다. 즉, 중요한 데이터가 방금 가져온 명령어 때문에 캐시에서 쫓겨나는 일을 방지할 수 있습니다.
- 단점: 이 분리의 비용으로 잠재적인 용량 미스(capacity miss)가 증가할 수 있습니다. 예를 들어, 프로그램이 데이터 위주로 실행되어 I-cache를 거의 사용하지 않는다면, I-cache에 할당된 공간은 낭비되고 D-cache의 공간은 부족해지는 상황이 발생할 수 있습니다.
2. 실제 예시: Intel Core i7 프로세서
본문 그림 6.38은 Intel Core i7 프로세서의 캐시 계층 구조를 보여줍니다.
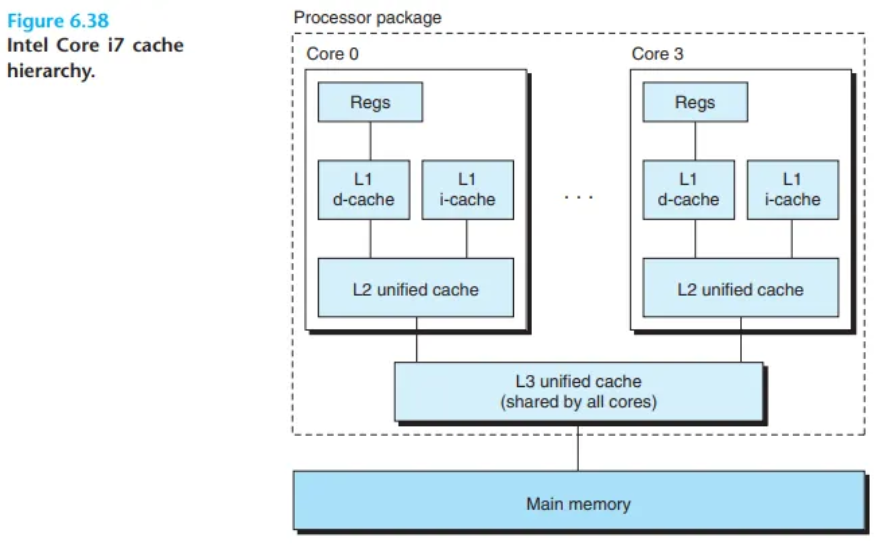
- 구조: 하나의 CPU 칩은 4개의 코어(core)를 가집니다.
- 각 코어의 전용(Private) 캐시:
- 자신만의 L1 I-cache
- 자신만의 L1 D-cache
- 자신만의 L2 통합 캐시 (unified cache)
- 코어 간 공유(Shared) 캐시:
- 모든 코어가 하나의 L3 통합 캐시를 공유합니다.
이 계층 구조의 흥미로운 특징은 모든 SRAM 캐시 메모리가 CPU 칩 내에 포함되어 있다는 점입니다. 본문 그림 6.39는 이 Core i7 캐시들의 기본 특성(용량, 연관성, 접근 속도 등)을 요약하여 보여줍니다.
6.4.7 캐시 파라미터가 성능에 미치는 영향 (Performance Impact of Cache Parameters)
캐시의 성능은 여러 가지 지표로 평가됩니다.
- 미스율 (Miss Rate): 프로그램(또는 프로그램의 일부)이 실행되는 동안 발생하는 전체 메모리 참조 중 미스(miss)가 차지하는 비율입니다.
- 히트율 (Hit Rate): 전체 메모리 참조 중 히트(hit)가 차지하는 비율입니다.
- 히트 시간 (Hit Time): 캐시에 있는 워드(word)를 CPU로 전달하는 데 걸리는 시간입니다. 세트 선택, 라인 식별, 워드 선택에 걸리는 시간을 모두 포함합니다. L1 캐시의 경우 히트 시간은 보통 수 클럭 사이클 정도입니다.
- 미스 패널티 (Miss Penalty): 미스로 인해 추가적으로 소요되는 시간입니다. L1 미스를 L2에서 처리할 경우 패널티는 약 10 사이클, L3에서 처리할 경우 50 사이클, 메인 메모리에서 처리할 경우 200 사이클 정도입니다.
캐시 메모리의 비용과 성능 간의 상충 관계(trade-off)를 최적화하는 것은 실제 벤치마크 코드를 통한 광범위한 시뮬레이션이 필요한 미묘한 작업이므로 이 책의 범위를 벗어납니다. 하지만, 몇 가지 정성적인 상충 관계는 식별할 수 있습니다.
캐시 크기(Cache Size)의 영향
- 장점: 더 큰 캐시는 일반적으로 히트율을 증가시키는 경향이 있습니다. 더 많은 데이터를 저장할 수 있으므로 용량 미스(capacity miss)가 줄어듭니다.
- 단점: 큰 메모리는 작고 빠른 메모리보다 물리적으로 신호 전달 거리가 길어지므로 더 느리게 동작합니다. 결과적으로, 더 큰 캐시는 히트 시간을 증가시키는 경향이 있습니다. 이것이 바로 L1 캐시가 L2보다 작고, L2가 L3보다 작은 이유를 설명합니다.
블록 크기(Block Size)의 영향
큰 블록은 장단점이 섞여 있는 양날의 검(mixed blessing)입니다.
- 장점: 더 큰 블록은 프로그램에 존재할 수 있는 공간적 지역성(spatial locality)을 활용하여 히트율을 높이는 데 도움을 줄 수 있습니다. 한 번의 미스로 더 많은 인접 데이터를 가져오기 때문입니다.
- 단점:
- 주어진 캐시 크기에서 블록이 커진다는 것은, 전체 캐시 라인의 수가 줄어든다는 것을 의미합니다. 이는 공간적 지역성보다 시간적 지역성이 더 강한 프로그램의 히트율을 해칠 수 있습니다.
- 더 큰 블록은 미스 패널티에도 부정적인 영향을 미칩니다. 한 번에 더 많은 데이터를 전송해야 하므로 전송 시간이 길어지기 때문입니다.
- 절충안: Core i7과 같은 현대 시스템은 64바이트 크기의 캐시 블록을 사용하여 절충안을 찾습니다.
연관성(Associativity)의 영향
여기서의 쟁점은 세트당 캐시 라인의 수인 파라미터 E의 선택이 미치는 영향입니다.
- 장점: 더 높은 연관성(즉, 더 큰
E값)은 충돌 미스로 인한 스래싱(thrashing) 현상에 대한 캐시의 취약성을 감소시킵니다. - 단점: 더 높은 연관성은 상당한 비용을 수반합니다.
- 구현 비용이 비싸고 빠르게 만들기 어렵습니다. 라인당 더 많은 태그 비트, 라인별 추가적인 LRU 상태 비트, 그리고 더 많은 제어 로직(병렬 비교기)이 필요합니다.
- 증가된 복잡성 때문에 히트 시간이 증가할 수 있습니다.
- 희생 라인(victim line)을 선택하는 과정이 복잡해져 미스 패널티가 증가할 수도 있습니다.
연관성의 선택은 궁극적으로 히트 시간과 미스 패널티 사이의 상충 관계로 귀결됩니다. 전통적으로, 클럭 속도를 높이는 고성능 시스템들은 미스 패널티가 불과 몇 사이클인 L1 캐시에는 낮은 연관성을 채택하고, 미스 패널티가 더 큰 하위 레벨 캐시에는 높은 연관성을 채택하는 경향이 있습니다. 예를 들어, Intel Core i7 시스템에서 L1과 L2 캐시는 8-way 연관이고, L3 캐시는 16-way 연관입니다.
쓰기 전략(Write Strategy)의 영향
- 즉시 쓰기 (Write-Through):
- 장점: 구현이 더 간단하며, 캐시와 독립적으로 동작하는 쓰기 버퍼(write buffer)를 사용하여 메모리를 갱신할 수 있습니다. 또한, 읽기 미스(read miss)의 비용이 더 저렴합니다. (더티 블록을 먼저 메모리에 쓸 필요가 없기 때문)
- 나중 쓰기 (Write-Back):
- 장점: 메모리로의 전송 횟수를 줄여, DMA(Direct Memory Access)를 수행하는 I/O 장치들이 사용할 수 있는 메모리 대역폭을 더 많이 확보해 줍니다. 계층 구조의 하위로 내려가 전송 시간이 길어질수록 전송 횟수를 줄이는 것은 점점 더 중요해집니다.
일반적으로, 계층 구조에서 더 아래에 있는 캐시일수록 즉시 쓰기보다는 나중 쓰기 방식을 사용할 가능성이 더 높습니다.
