
7.7.1 재배치 항목 (Relocation Entries)
어셈블러가 목적 모듈을 생성할 때, 코드와 데이터가 최종적으로 메모리 어느 곳에 저장될지 알지 못합니다. 또한, 다른 파일에 정의된 함수나 전역 변수의 주소도 알 수 없습니다.
따라서 어셈블러는 최종 위치를 알 수 없는 대상을 참조할 때마다 재배치 항목(relocation entry)을 생성합니다. 이 항목은 나중에 링커가 목적 파일들을 실행 파일로 병합할 때, 해당 참조를 어떻게 수정해야 하는지에 대한 '지시서' 역할을 합니다.
- 코드에 대한 재배치 항목은
.rel.text섹션에 저장됩니다. - 데이터에 대한 재배치 항목은
.rel.data섹션에 저장됩니다.
ELF 재배치 항목의 구조

ELF 재배치 항목은 다음과 같은 필드로 구성됩니다.
- offset: 수정이 필요한 참조가 위치한 섹션 내 오프셋(offset).
- symbol: 수정된 참조가 가리켜야 할 심볼을 식별합니다.
- type: 링커에게 참조를 어떻게 수정할지 알려주는 타입 정보.
- addend: 일부 재배치 타입에서 수정될 참조 값에 더해지는 부호 있는 상수(signed constant).
이 필드들은 링커(Linker)가 여러 목적 파일(.o)을 합쳐 하나의 최종 실행 파일을 만드는 과정 중, 재배치(Relocation) 단계에서 사용됩니다.
두 가지 핵심 재배치 타입
ELF는 32가지의 재배치 타입을 정의하지만, 가장 기본적인 두 가지는 다음과 같습니다.
R_X86_64_PC32: 32비트 PC-상대 주소(PC-relative address)를 사용하는 참조를 재배치합니다.- 동작 방식: CPU는 명령어에 인코딩된 32비트 값을 현재 프로그램 카운터(PC)의 실행 시점 값(항상 다음 명령어의 주소)에 더하여 유효 주소를 계산합니다.
R_X86_64_32: 32비트 절대 주소(absolute address)를 사용하는 참조를 재배치합니다.- 동작 방식: CPU는 명령어에 인코딩된 32비트 값을 다른 수정 없이 직접 유효 주소로 사용합니다.
이 두 타입은 gcc의 기본값인 x86-64 스몰 코드 모델(small code model)을 지원합니다. 이 모델은 실행 파일의 코드와 데이터 전체 크기가 2GB보다 작다고 가정하여, 32비트 주소 지정 방식으로 접근할 수 있도록 합니다.
이것은 어셈블러가 링커에게 남기는 "빈칸 채우기 문제지와 풀이법"이라고 생각하면 완벽합니다. 어셈블러는 sum 함수나 array 변수의 최종 주소를 모르기 때문에, 일단 코드에 빈칸(임시 주소)을 남겨두고, 링커에게 이 문제지를 전달하여 나중에 정답(최종 주소)을 채워 넣도록 지시하는 것입니다.
각 필드는 문제지에서 다음과 같은 역할을 합니다.
필드별 역할 (빈칸 채우기 문제)
1. offset: 문제 번호 (어디를?)
- 역할: 수정해야 할 빈칸의 정확한 위치를 알려줍니다.
- 예시: "
.text섹션 시작점에서부터 7바이트 떨어진 곳에 있는 4바이트짜리 빈칸을 채워라."
2. symbol: 문제의 힌트 (무엇으로?)
- 역할: 그 빈칸에 어떤 심볼의 최종 주소를 넣어야 하는지 알려줍니다.
- 예시: "이 빈칸의 정답은 바로
sum이라는 함수의 최종 주소다."
3. type: 풀이 방법 (어떻게?)
- 역할:
symbol의 주소를 어떤 형식으로 계산해서 넣을지 지시합니다. - 예시:
R_X86_64_32: "찾아낸sum함수의 주소를 그대로 빈칸에 적어라." (절대 주소)R_X86_64_PC32: "현재 이 명령어의 다음 위치에서sum함수까지의 거리를 계산해서 그 값을 적어라." (상대 주소)
4. addend: 추가 조건 (조정 값)
- 역할:
type에 따라 주소를 계산한 뒤, 추가로 더하거나 뺄 값을 지정합니다. - 예시: "
array변수의 주소를 찾은 뒤, 거기에 8을 더한 값을 최종 정답으로 적어라." (배열의 특정 원소array[2]에 접근하는 경우)
링커의 작업 흐름
- 링커는 재배치 항목이라는 "문제지"를 펼칩니다.
offset을 보고 수정할 코드의 정확한 위치로 이동합니다.symbol을 보고 필요한 심볼의 최종 확정된 가상 주소를 찾습니다.type과addend의 지시에 따라 주소를 올바른 형식으로 계산합니다.- 계산된 최종 주소 값을 1번에서 찾아간 코드 위치의 빈칸에 덮어쓰면서 문제를 해결합니다.
7.7.2 심볼 참조 재배치 (Relocating Symbol References)
이제 링커는 재배치 알고리즘을 사용하여 코드 내의 임시 주소들을 실제 실행 시점 주소로 수정하는 '찾아 바꾸기' 작업을 시작합니다. 이 알고리즘의 동작 방식은 Figure 7.10의 의사 코드에 잘 나타나 있으며, Figure 7.11의 main.o 코드를 예시로 사용합니다.


링커의 재배치 알고리즘 (Figure 7.10 의사 코드 설명)
링커는 이 알고리즘을 통해 재배치 항목(relocation entry)이라는 '지시서'를 보고 코드 수정을 수행합니다.
- 반복: 링커는 각 섹션(
.text,.data등)을 돌면서, 그 섹션에 속한 모든 재배치 항목(수정 지시서r)을 하나씩 확인합니다. - 위치 계산: 수정해야 할 참조의 정확한 위치(
refptr)를 계산합니다. (refptr = s + r.offset) - 타입 확인 및 수정: 재배치 항목의 타입(
r.type)에 따라 두 가지 다른 방식으로 주소를 계산하여 덮어씁니다.- PC-상대 주소 (
R_X86_64_PC32):- 계산 공식:
refptr = ADDR(r.symbol) + r.addend - refaddr - 의미: 목표 심볼의 최종 주소에서 이 명령어 다음의 주소(
refaddr)를 뺀 상대적인 거리(offset)를 계산하여 기록합니다.
- 계산 공식:
- 절대 주소 (
R_X86_64_32):- 계산 공식:
refptr = ADDR(r.symbol) + r.addend - 의미: 목표 심볼의 최종 주소를 계산하여 코드에 직접 기록합니다.
- 계산 공식:
- PC-상대 주소 (
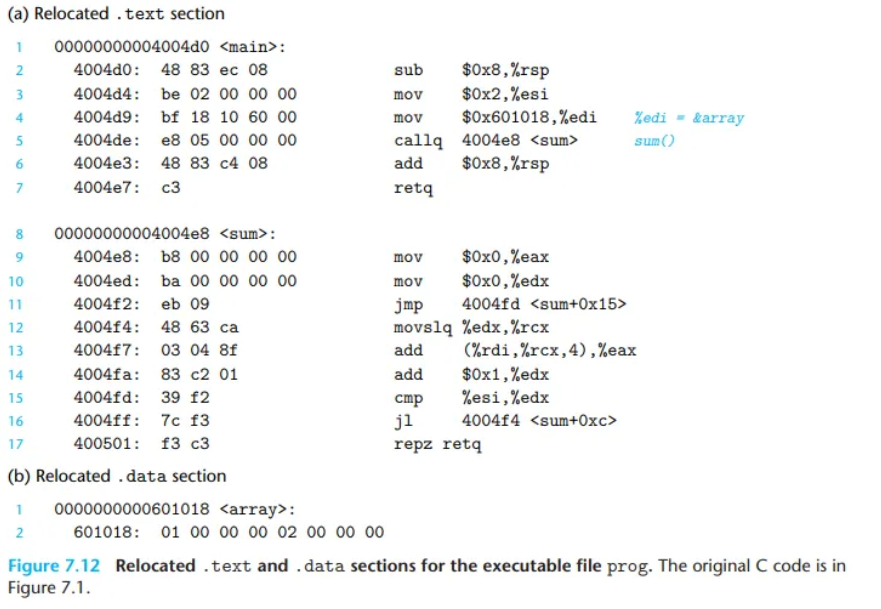
main.o 코드 재배치 예시 (Figure 7.11)
main.o의 기계어 코드에는 array와 sum이라는 두 개의 전역 심볼 참조가 있으며, 어셈블러는 각각에 대한 재배치 항목을 생성했습니다.
array참조 (오프셋0xa): 절대 주소 (R_X86_64_32)로 재배치해야 합니다.sum참조 (오프셋0xf): PC-상대 주소 (R_X86_64_PC32)로 재배치해야 합니다.
링커는 이 두 항목을 다음 섹션에서 설명하는 방식에 따라 수정하게 됩니다.
PC-상대 참조 재배치 (Relocating PC-Relative References)
이 과정은 링커가 call sum과 같은 함수 호출 명령어의 임시 주소를 어떻게 올바른 값으로 채워 넣는지 보여줍니다. 핵심은 목표 함수의 절대 주소를 직접 쓰는 것이 아니라, 현재 위치에서 목표까지의 상대적인 거리(offset)를 계산하여 기록하는 것입니다.
1. 문제: 어셈블러가 남긴 지시서 (Relocation Entry)
어셈블러는 sum 함수의 최종 주소를 모르기 때문에, call 명령어 뒤에 4바이트짜리 빈칸(00 00 00 00)을 남기고, 링커에게 다음과 같은 지시서(재배치 항목)를 전달합니다.
r.offset = 0xf: 수정할 빈칸은.text섹션 시작 후0xf바이트 지점에 있습니다.r.symbol = sum: 이 빈칸은sum함수를 가리켜야 합니다.r.type = R_X86_64_PC32: 계산 방식은 '현재 위치로부터의 거리'(PC-상대 주소)를 사용해야 합니다.r.addend = -4: 계산할 때 -4를 추가로 보정해주세요.
2. 링커의 계산 과정
링커는 이제 최종 주소를 알고 있습니다.
.text섹션의 시작 주소:ADDR(.text) = 0x4004d0sum함수의 시작 주소:ADDR(sum) = 0x4004e8
이제 링커는 지시서에 따라 빈칸에 들어갈 값을 계산합니다.
① 참조 위치 주소 계산 (refaddr): 빈칸(수정될 값) 자체의 실행 시점 주소를 계산합니다.
refaddr = ADDR(.text) + r.offset = 0x4004d0 + 0xf = 0x4004df
② 최종 값 계산 (*refptr): PC-상대 주소 계산 공식을 적용합니다.
*refptr = ADDR(sum) + r.addend - refaddr*refptr = 0x4004e8 + (-4) - 0x4004df*refptr = 0x5
링커는 계산된 최종 값 0x5를 코드의 빈칸에 덮어씁니다.
3. 결과: 완성된 기계어 코드
원래 e8 00 00 00 00이었던 코드가 다음과 같이 수정됩니다.
4004de: e8 05 00 00 00 callq 4004e8 <sum>
4. 실행 시점(Run-time)의 동작 원리
프로그램이 실행되어 CPU가 주소 0x4004de의 call 명령어를 실행할 때, 프로그램 카운터(PC)는 이미 다음 명령어의 주소(0x4004e3)를 가리키고 있습니다.
CPU는 이 call 명령어를 다음과 같이 처리합니다.
- 현재 PC 값(
0x4004e3)을 스택에 저장합니다. (나중에 돌아와야 하므로) - PC 값을 업데이트합니다:
PC ← 현재 PC + 명령어에 기록된 값PC ← 0x4004e3 + 0x5 = 0x4004e8
결과적으로 PC는 정확히 sum 함수의 시작 주소인 0x4004e8로 점프하게 되어, 우리가 원했던 대로 함수가 올바르게 호출됩니다.
절대 참조 재배치 (Relocating Absolute References)
절대 참조 재배치는 PC-상대 참조보다 훨씬 간단합니다. 이 과정은 링커가 전역 변수의 최종 메모리 주소를 코드에 직접 기록하는, 직관적인 '찾아 바꾸기' 작업입니다.
1. 문제: 어셈블러가 남긴 지시서 (Relocation Entry)
어셈블러는 array 변수의 최종 주소를 모르기 때문에, mov 명령어에 4바이트짜리 자리 표시자(placeholder) 00 00 00 00을 남기고, 링커에게 다음과 같은 지시서를 전달합니다.
r.offset = 0xa: 수정할 위치는.text섹션 시작 후0xa바이트 지점입니다.r.symbol = array: 이 자리에는array변수의 주소가 들어가야 합니다.r.type = R_X86_64_32: 주소를 계산 없이 그대로(절대 주소) 사용해야 합니다.r.addend = 0: 주소에 추가로 더할 값은 없습니다.
2. 링커의 계산 과정
링커는 이제 array 변수의 최종 주소가 0x601018임을 알고 있습니다. 링커는 지시서에 따라 자리 표시자에 들어갈 값을 계산합니다.
- 최종 값 계산 (
refptr): 절대 주소 계산 공식을 적용합니다.
refptr = ADDR(array) + r.addendrefptr = 0x601018 + 0refptr = 0x601018
링커는 계산된 최종 주소 0x601018을 코드의 자리 표시자에 덮어씁니다.
3. 결과: 완성된 기계어 코드
원래 bf 00 00 00 00이었던 코드가 다음과 같이 수정됩니다.
(x86 시스템은 리틀 엔디안(little-endian) 바이트 순서를 사용하므로 0x601018은 18 10 60 00으로 저장됩니다.)
4004d9: bf 18 10 60 00 mov $0x601018,%edi
이제 이 mov 명령어는 실행 시점에 정확히 array 변수의 시작 주소인 0x601018을 %edi 레지스터에 복사하게 됩니다.
4. 최종 실행 파일 (Figure 7.12)
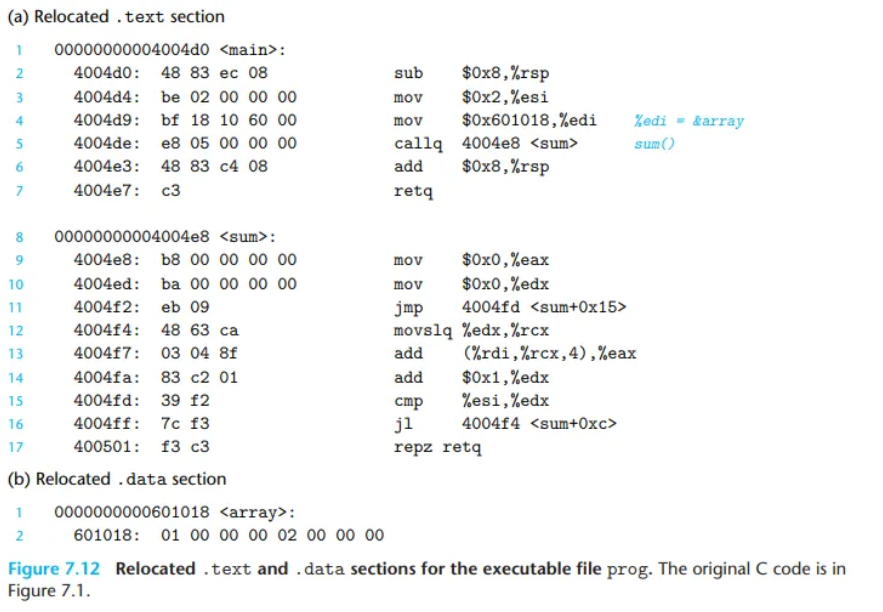
링커가 PC-상대 참조(sum 호출)와 절대 참조(array 주소)에 대한 모든 재배치 작업을 완료하고 나면, .text와 .data 섹션은 완전한 형태가 됩니다.
이제 이 실행 파일은 운영체제의 로더(loader)에 의해 메모리에 직접 복사되기만 하면, 어떠한 추가 수정 없이도 즉시 실행될 수 있는 '준비 완료' 상태가 됩니다.
7.8 실행 가능 목적 파일 (Executable Object Files)
링커가 여러 목적 파일들을 병합하고 나면, 텍스트 파일이었던 C 프로그램은 메모리에 로드하여 실행하는 데 필요한 모든 정보를 담고 있는 단일 바이너리 파일, 즉 실행 가능 목적 파일(executable object file)로 변환됩니다.
실행 파일의 구조와 특징
실행 파일의 형식은 재배치 가능 목적 파일과 유사하지만, 몇 가지 중요한 차이점이 있습니다.
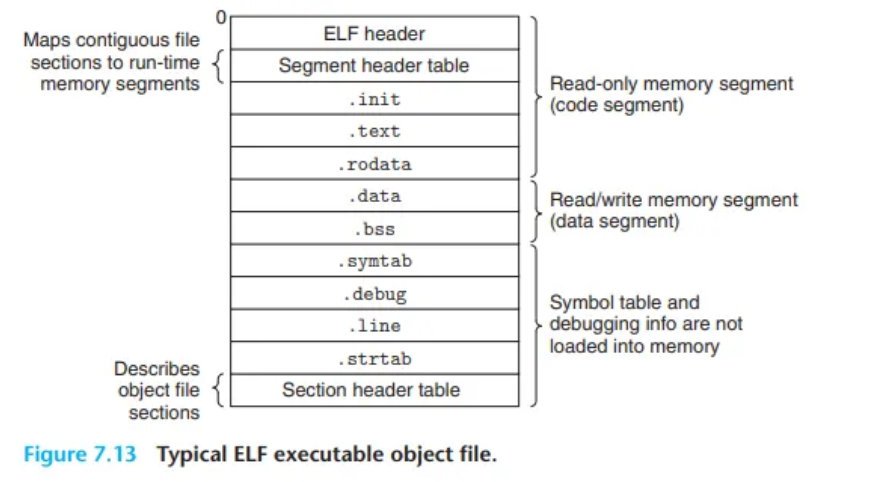
- ELF 헤더 (ELF Header): 파일의 전반적인 형식을 설명하며, 프로그램이 실행될 때 가장 먼저 실행될 명령어의 주소인 엔트리 포인트(entry point)를 포함합니다.
- 재배치 완료된 섹션들:
.text,.rodata,.data같은 섹션들은 재배치 가능 파일과 유사하지만, 모든 주소가 최종 실행 시점 메모리 주소로 확정(재배치)된 상태입니다. .init섹션: 프로그램의 초기화 코드가 호출할_init이라는 작은 함수를 정의합니다..rel섹션의 부재: 실행 파일은 이미 모든 링크 작업이 완료된 상태이므로, 추가적인 주소 수정이 필요 없어 재배치 항목(.rel섹션)이 존재하지 않습니다.
프로그램 헤더 테이블과 메모리 세그먼트
ELF 실행 파일은 메모리에 쉽게 로드될 수 있도록 설계되었습니다. 파일의 연속적인 덩어리(chunk)들이 메모리의 연속적인 세그먼트(segment)에 매핑되는데, 이 매핑 정보는 프로그램 헤더 테이블(program header table)에 담겨 있습니다.
이 테이블에 따라 실행 파일의 내용이 두 개의 주요 메모리 세그먼트로 초기화됩니다.
- 코드 세그먼트 (Code Segment)
- 권한: 읽기/실행 (Read/Execute)
- 내용: ELF 헤더, 프로그램 헤더 테이블,
.init,.text,.rodata섹션들을 포함합니다. - 특징: 프로그램의 실행 코드와 변경 불가능한 데이터로 구성됩니다.
- 데이터 세그먼트 (Data Segment)
- 권한: 읽기/쓰기 (Read/Write)
- 내용:
.data섹션과.bss섹션의 정보를 포함합니다. - 특징: 파일에 저장된
.data섹션의 내용으로 초기화되며, 파일에 공간을 차지하지 않았던.bss영역은 이 세그먼트 내에서 0으로 초기화될 메모리 공간을 예약합니다.
세그먼트 정렬 (Alignment) 요구사항
링커는 세그먼트의 시작 가상 주소(vaddr)와 파일 내 오프셋(off)이 특정 정렬(align) 값을 기준으로 같은 나머지를 갖도록 주소를 선택합니다.
vaddr mod align = off mod align
이 요구사항은 가상 메모리가 2의 거듭제곱 크기를 갖는 큰 덩어리로 구성되기 때문에, 실행 시 파일의 세그먼트를 메모리로 효율적으로 전송하기 위한 최적화 기법입니다. (자세한 내용은 9장 가상 메모리에서 다룹니다.)
7.9 실행 가능 목적 파일 로딩 (Loading Executable Object Files)
사용자가 셸 커맨드 라인에 ./prog와 같이 실행 파일 이름을 입력하면, 셸은 로더(loader)라는 운영체제 코드를 호출합니다. 로더는 실행 파일의 코드와 데이터를 디스크에서 메모리로 복사한 뒤, 프로그램의 첫 번째 명령어, 즉 엔트리 포인트(entry point)로 점프하여 프로그램을 실행시킵니다. 이처럼 프로그램을 메모리에 복사하고 실행하는 과정을 로딩(loading)이라고 합니다.
실행 시점 메모리 이미지 (Run-time Memory Image)
실행 중인 모든 리눅스 프로그램은 아래와 유사한 실행 시점 메모리 이미지(run-time memory image)를 가집니다.
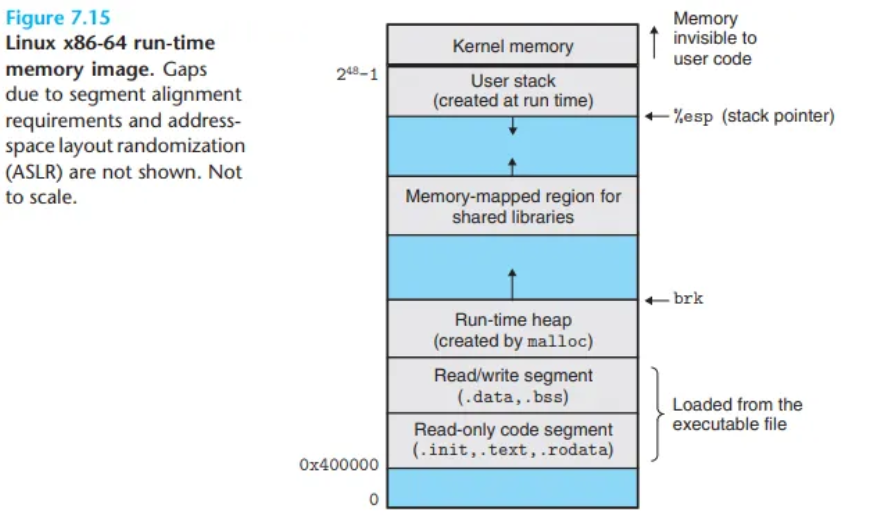
- 코드 및 데이터 세그먼트: x86-64 리눅스 시스템에서 코드 세그먼트는 주소
0x400000에서 시작하며, 그 뒤를 데이터 세그먼트가 따릅니다. - 힙 (Heap): 데이터 세그먼트 바로 다음에 위치하며,
malloc라이브러리 함수 호출을 통해 낮은 주소에서 높은 주소로 자라납니다. - 공유 라이브러리 영역: 힙 다음에 위치하며, 공유 모듈을 위해 예약된 공간입니다.
- 스택 (Stack): 사용 가능한 가장 높은 사용자 주소 바로 아래에서 시작하여, 높은 주소에서 낮은 주소로 자라납니다.
- 커널 (Kernel): 스택 위의 영역은 운영체제의 코드와 데이터를 위해 예약된 공간입니다.
참고: 실제로는 주소 공간 배치 랜덤화(ASLR) 기술로 인해 스택, 공유 라이브러리, 힙 등의 시작 주소는 실행할 때마다 바뀌지만, 이들의 상대적인 위치 관계는 동일하게 유지됩니다.
Q. 공유 라이브러리 영역?
2. 공유 라이브러리 영역의 역할: 코드 재사용과 효율성
공유 라이브러리 영역의 핵심 역할은 "자주 사용되는 코드를 메모리에 한 번만 올려놓고, 여러 프로그램이 함께 공유해서 사용하게 하는 것"입니다.
우리가 C언어로 printf("hello"); 코드를 짜면, printf 함수의 실제 기계어 코드는 우리 프로그램에 포함되지 않습니다. 대신, 공유 라이브러리 (Shared Library) 인 libc.so 파일 안에 들어있죠. 이 libc.so가 로드되는 공간이 바로 공유 라이브러리 영역입니다.
이 방식의 장점은 명확합니다.
- 메모리 절약 (RAM Efficiency): 만약 100개의 프로그램이 동시에 실행되면서 모두
printf를 사용한다고 상상해 보세요. 정적 라이브러리 방식이라면 100개의printf코드 복사본이 메모리를 차지하겠지만, 공유 라이브러리 방식에서는 단 하나의printf코드만 물리 메모리(RAM)에 올라가고, 모든 프로그램이 이 코드를 공동으로 참조합니다. 이는 엄청난 메모리 절약 효과를 가져옵니다. - 실행 파일 크기 감소:
printf같은 거대한 라이브러리 코드가 최종 실행 파일에 포함되지 않으므로, 실행 파일 자체의 크기가 매우 작아집니다. → 프로그램 실행 시 동적 링커가 메모리로 올립니다.실제 동작 과정
1. 컴파일 시점: '약속'만 기록하기
컴파일러는printf("hello");코드를 보고, "아, 이건libc.so라는 공유 라이브러리에 있는 함수구나"라고 인식합니다. 그래서 실행 파일에printf의 기계어 코드 수천 줄을 복사하는 대신, 다음과 같은 자리 표시자(placeholder)만 남깁니다.
이것이 바로 실행 파일의 크기가 작은 이유입니다."이 프로그램은 libc.so 파일에 있는 printf라는 이름의 함수를 필요로 합니다."
2. 실행 시점: '약속'을 연결하기
사용자가./prog를 실행하면, 운영체제의 로더(Loader)가 프로그램을 메모리에 올립니다.-
동적 링커 호출: 로더는 파일에 "공유 라이브러리가 필요하다"는 표시를 보고, 내 프로그램보다 먼저 동적 링커(
ld-linux.so)를 실행시킵니다. -
라이브러리 로드: 동적 링커는
libc.so파일을 찾아 메모리의 '공유 라이브러리 영역'에 올립니다. 이제printf함수의 실제 코드는 메모리 어딘가에 위치하게 됩니다. -
주소 연결 (Linking): 동적 링커는 내 프로그램에 있던
printf자리 표시자로 돌아가, 방금 메모리에 올라간printf함수의 실제 메모리 주소를 정확하게 적어 넣습니다. 이 과정이 바로 '동적 링킹'입니다.3. 함수 실행: 연결된 주소로 점프하기
이제 모든 준비가 끝났습니다. 내 프로그램이 실행되다가
printf를 호출하는 부분에 도달하면, 이제는 비어있지 않은 자리 표시자를 보고 연결된 실제printf함수의 메모리 주소로 점프하여 코드를 실행합니다.
-
- 쉬운 업데이트 및 유지보수: 만약
printf함수에 보안 취약점이 발견되었다고 해봅시다. 시스템 관리자는libc.so파일 단 하나만 새로운 버전으로 교체하면 됩니다. 그러면 해당 라이브러리를 사용하는 모든 프로그램은 다음 실행 시 자동으로 보안 패치가 적용된 새로운printf함수를 사용하게 됩니다. 각 프로그램을 다시 컴파일할 필요가 전혀 없습니다.
이 모든 과정은 프로그램이 시작될 때 동적 링커(Dynamic Linker)(ld-linux.so)에 의해 자동으로 처리됩니다. 동적 링커가 필요한 .so 파일을 찾아서 이 공유 라이브러리 영역에 매핑하고, 프로그램의 함수 호출과 라이브러리 속 실제 함수를 연결해 줍니다.
로딩 과정 (Loading Process)
로더가 실행되면 다음과 같은 단계를 거쳐 메모리 이미지를 생성하고 프로그램을 실행합니다.
- 로더는 실행 파일의 프로그램 헤더 테이블(program header table)을 보고, 파일의 덩어리(chunk)들을 코드 및 데이터 세그먼트에 복사합니다.
- 복사가 완료되면, 로더는 프로그램의 엔트리 포인트(entry point)로 점프합니다.
- 이 엔트리 포인트는 사용자의
main함수가 아니라, 항상 시스템 목적 파일(crt1.o)에 정의된_start함수의 주소입니다. _start함수는 C 표준 라이브러리(libc.so)에 있는__libc_start_main함수를 호출합니다.__libc_start_main함수는 실행 환경을 초기화하고, 드디어 사용자가 작성한main함수를 호출합니다.main함수가 종료되면 그 반환값을 처리하고, 필요시 제어권을 커널에게 다시 넘깁니다.
실행 흐름 요약: 로더 → _start → __libc_start_main → main
Q. 시스템 목적 파일(crt1.o)란?
crt1.o는 C 프로그램이 main 함수를 실행하기 전에 필요한 최소한의 준비 작업을 해주는 '시동 파일'입니다.
모든 C 프로그램의 진짜 시작점은 main 함수가 아니라, crt1.o 파일 안에 있는 _start라는 아주 작은 함수입니다. 운영체제의 로더는 프로그램을 실행할 때 이 _start 함수를 가장 먼저 호출합니다.
crt1.o의 역할
crt1.o의 이름은 C Run-Time startup (object file 1)의 약자입니다. 그 역할은 다음과 같습니다.
- 진짜 진입점(
_start) 제공: 운영체제로부터 프로그램의 제어권을 가장 먼저 넘겨받습니다. - C 표준 라이브러리 초기화 함수 호출:
_start함수는 자신이 직접 복잡한 일을 하지 않고, C 표준 라이브러리(libc.so)에 있는__libc_start_main이라는 더 큰 준비 함수를 호출하는 다리 역할을 합니다. main함수 호출 준비:__libc_start_main함수가 스택에서argc,argv같은main함수에 필요한 인자들을 정리하고, 표준 입출력(stdin, stdout)을 설정하는 등 C 언어 환경을 완벽하게 준비시킵니다.main함수 실행 및 마무리: 모든 준비가 끝나면, 드디어 우리가 작성한main함수를 호출합니다.main함수가 끝나고 값을 반환하면, 그 값을 받아서 프로그램을 안전하게 종료시키는exit시스템 콜을 호출하는 뒷정리까지 담당합니다.
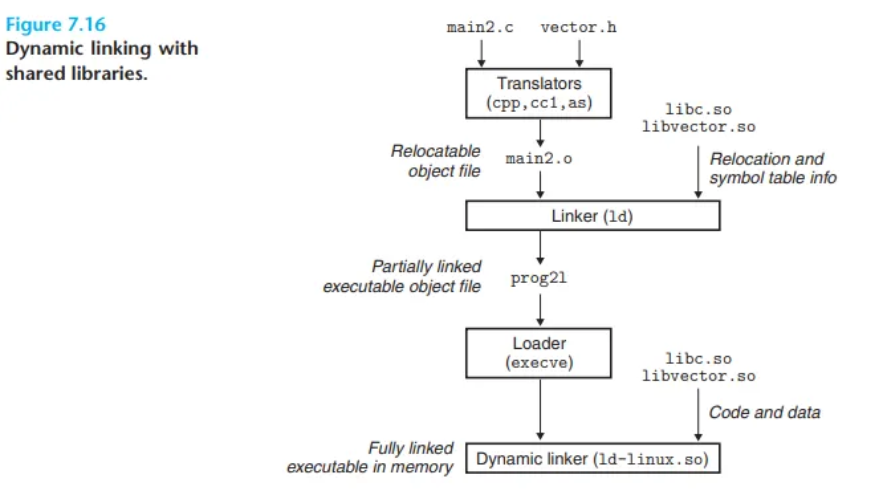
7.10 공유 라이브러리를 이용한 동적 링킹 (Dynamic Linking with Shared Libraries)
정적 라이브러리는 많은 문제를 해결했지만, 여전히 몇 가지 중요한 단점을 가지고 있습니다.
정적 라이브러리의 한계
- 유지보수 및 업데이트의 어려움
- 정적 라이브러리도 주기적으로 업데이트되어야 합니다. 만약 프로그래머가 최신 버전의 라이브러리를 사용하고 싶다면, 라이브러리가 변경되었다는 사실을 인지하고 자신의 프로그램을 명시적으로 다시 링크(relink)해야 합니다.
- 메모리 낭비
- 거의 모든 C 프로그램은
printf,scanf와 같은 표준 I/O 함수를 사용합니다. 정적 링킹 방식에서는 이 함수들의 코드가 실행 중인 각 프로세스의 텍스트 세그먼트에 중복으로 복사됩니다. 수백 개의 프로세스가 실행되는 일반적인 시스템에서 이는 희소한 메모리 자원의 심각한 낭비입니다.
- 거의 모든 C 프로그램은
공유 라이브러리: 현대적인 해결책
- 공유 라이브러리(Shared Library)는 정적 라이브러리의 단점을 해결하기 위한 현대적인 혁신입니다. 공유 라이브러리는 실행 시점이나 로드 시점에 임의의 메모리 주소에 로드되어, 메모리 상의 프로그램과 연결(link)될 수 있는 목적 모듈입니다. 이 과정을 동적 링킹(dynamic linking)이라 하며, 동적 링커(dynamic linker)라는 프로그램에 의해 수행됩니다.
- 리눅스 시스템에서는
.so(Shared Objects) 확장자를 사용합니다. - 마이크로소프트 윈도우에서는 DLL(Dynamic Link Libraries)이라고 부릅니다.
공유 라이브러리의 두 가지 '공유' 의미
- 파일 시스템에서의 공유: 파일 시스템에는 특정 라이브러리에 대한
.so파일이 단 하나만 존재합니다. 이 라이브러리를 참조하는 모든 실행 파일들은 이.so파일을 공유합니다. (정적 라이브러리는 라이브러리의 내용이 각 실행 파일에 복사되어 포함됩니다.) - 메모리에서의 공유: 메모리에 로드된 공유 라이브러리의
.text섹션(코드) 복사본 하나를 여러 다른 실행 중인 프로세스들이 함께 공유할 수 있습니다. 이는 엄청난 메모리 절약 효과를 가져옵니다.
공유 라이브러리 생성 및 사용법
- 생성 (Creation)
컴파일러 드라이버에 특별한 지시어(shared,fpic)를 사용하여 공유 라이브러리를 생성합니다.
linux> gcc -shared -fpic -o libvector.so addvec.c multvec.c
-fpic: 컴파일러에게 위치 독립적인 코드(Position-Independent Code, PIC)를 생성하라고 지시합니다. 이 코드는 메모리의 어떤 주소에 로드되더라도 올바르게 실행될 수 있습니다.
-shared: 링커에게 공유 목적 파일을 생성하라고 지시합니다. - 링크 (Linking)
생성된 공유 라이브러리를 프로그램과 링크합니다.
linux> gcc -o prog2l main2.c ./libvector.so
- 중요: 이 단계에서libvector.so의 코드나 데이터는 실행 파일prog2l에 전혀 복사되지 않습니다. 대신 링커는 나중에 로드 시점에libvector.so의 코드와 데이터 참조를 해결할 수 있도록 해주는 약간의 재배치 및 심볼 테이블 정보만 복사합니다.
로더와 동적 링커의 실행 과정
- 사용자가
./prog2l을 실행하면, 로더(loader)는 부분적으로 링크된 실행 파일prog2l을 메모리에 올립니다. - 로더는
prog2l파일 안에 있는.interp섹션을 발견합니다. 이 섹션에는 동적 링커(ld-linux.so등)의 경로 이름이 담겨 있습니다. - 로더는 애플리케이션에 제어권을 넘기는 대신, 동적 링커를 로드하고 실행합니다.
- 동적 링커가 나머지 링크 작업을 마무리합니다.
libc.so의 코드와 데이터를 메모리 세그먼트에 재배치합니다.libvector.so의 코드와 데이터를 다른 메모리 세그먼트에 재배치합니다.prog2l코드 내에서libc.so와libvector.so의 심볼을 참조하는 모든 부분을 실제 메모리 주소로 재배치(수정)합니다.
- 마지막으로 동적 링커가 애플리케이션에 제어권을 넘깁니다.
이 시점 이후로 공유 라이브러리의 메모리 위치는 고정되며 프로그램 실행 중에 바뀌지 않습니다.
실행 흐름 요약: 로더 → 동적 링커 → 애플리케이션
번외: 로더는 실제 어떻게 동작하는가?
지금까지의 로딩에 대한 설명은 개념적으로는 맞지만, 의도적으로 완전히 정확하게 설명하지는 않았습니다. 로딩이 실제로 어떻게 동작하는지 이해하려면, 아직 다루지 않은 프로세스(process), 가상 메모리(virtual memory), 메모리 매핑(memory mapping)의 개념을 알아야 합니다. 이 개념들을 8장과 9장에서 배우면서 로딩에 대해 다시 살펴보고 점차 그 비밀을 밝힐 것입니다.
성급한 독자를 위해, 로딩이 실제 어떻게 동작하는지 미리 살펴보겠습니다.
리눅스의 각 프로그램은 자신만의 가상 주소 공간(virtual address space)을 갖는 프로세스(process) 컨텍스트 내에서 실행됩니다. 셸이 프로그램을 실행하면, 부모 셸 프로세스는 자신과 똑같은 자식 프로세스를 복제(fork)합니다. 이 자식 프로세스는 execve 시스템 콜을 통해 로더를 호출합니다.
로더는 자식 프로세스의 기존 가상 메모리 세그먼트들을 삭제하고, 새로운 코드, 데이터, 힙, 스택 세그먼트를 생성합니다. 새로운 스택과 힙 세그먼트는 0으로 초기화됩니다. 새로운 코드와 데이터 세그먼트는 가상 주소 공간의 페이지(page)들을 실행 파일의 페이지 크기 덩어리(page-size chunks)에 매핑(mapping)함으로써 초기화됩니다. 마지막으로, 로더는 _start 주소로 점프하고, 이는 최종적으로 애플리케이션의 main 루틴을 호출하게 됩니다.
핵심은, 일부 헤더 정보를 제외하면, 로딩 중에는 디스크에서 메모리로의 실질적인 데이터 복사가 일어나지 않는다는 점입니다. 데이터 복사는 CPU가 매핑된 가상 페이지를 참조하는 시점까지 지연됩니다. 참조가 발생하는 그 순간, 운영체제는 페이징(paging) 메커니즘을 사용하여 해당 페이지를 디스크에서 메모리로 자동 전송합니다.
7.11 애플리케이션에서 공유 라이브러리 로딩 및 링킹
지금까지는 애플리케이션이 실행되기 직전, 로드될 때 동적 링커가 공유 라이브러리를 로드하고 링크하는 시나리오에 대해 다루었습니다. 하지만, 애플리케이션이 실행 중인 동안 동적 링커에게 임의의 공유 라이브러리를 로드하고 링크하도록 요청하는 것도 가능합니다. 이는 컴파일 시점에 해당 라이브러리에 대해 링크할 필요 없이 이루어집니다.
이러한 실행 시점 동적 링킹은 매우 강력하고 유용한 기술이며, 실제 세계에서 다음과 같은 사례에 사용됩니다.
- 소프트웨어 배포: 마이크로소프트 윈도우 애플리케이션 개발자들은 소프트웨어 업데이트를 배포하기 위해 공유 라이브러리(DLL)를 자주 사용합니다. 새로운 버전의 공유 라이브러리를 생성하여 배포하면, 사용자는 이를 다운로드하여 기존 버전을 대체할 수 있습니다. 다음에 애플리케이션을 실행할 때, 프로그램은 자동으로 새로운 공유 라이브러리를 링크하고 로드합니다.
- 고성능 웹 서버 구축: 많은 웹 서버는 개인화된 웹 페이지와 같은 동적 콘텐츠를 생성합니다. 초기 웹 서버는
fork와execve를 사용하여 자식 프로세스를 생성하고 그 안에서 "CGI 프로그램"을 실행하는 방식으로 동적 콘텐츠를 처리했습니다. 그러나 현대의 고성능 웹 서버는 동적 링킹에 기반한 더 효율적인 접근 방식을 사용합니다.
각각의 동적 콘텐츠 생성 기능을 공유 라이브러리로 패키징한 뒤, 웹 브라우저로부터 요청이 오면 서버는 해당 기능을 동적으로 로드하고 링크하여 직접 호출합니다. 이 방식은 함수를 자식 프로세스에서 실행하는 것보다 훨씬 효율적입니다. 한번 로드된 함수는 서버의 주소 공간에 캐시되어 남아있으므로, 이후의 요청들은 간단한 함수 호출 비용만으로 처리할 수 있습니다. 이는 서버를 중단시키지 않고도 기존 기능을 업데이트하거나 새로운 기능을 추가하는 것을 가능하게 합니다.
리눅스의 동적 링킹 인터페이스
리눅스 시스템은 애플리케이션이 실행 중에 공유 라이브러리를 로드하고 링크할 수 있도록 동적 링커에 대한 간단한 인터페이스를 제공합니다.
dlopen(filename, flag):filename이라는 이름의 공유 라이브러리를 로드하고 링크합니다.flag인자로는 외부 심볼 참조를 즉시 해결하라는RTLD_NOW나, 라이브러리의 코드가 실행될 때까지 심볼 해석을 지연시키라는RTLD_LAZY중 하나를 반드시 포함해야 합니다.dlsym(handle, symbol): 이전에 열린 공유 라이브러리를 가리키는 핸들(handle)과 심볼 이름을 받아, 해당 심볼의 주소를 반환합니다. 심볼이 없으면NULL을 반환합니다.dlclose(handle): 해당 라이브러리를 사용하는 다른 공유 라이브러리가 더 이상 없다면, 공유 라이브러리를 언로드(unload)합니다.dlerror():dlopen,dlsym,dlclose호출 결과 발생한 가장 최근의 오류를 설명하는 문자열을 반환합니다. 오류가 없었다면NULL을 반환합니다.
이 인터페이스를 사용하여 libvector.so 공유 라이브러리를 실행 중에 동적으로 링크하고 addvec 루틴을 호출하는 예제 프로그램(Figure 7.17)을 컴파일하려면 다음과 같이 gcc를 호출합니다.
linux> gcc -rdynamic -o prog2r dll.c -ldl
7.12 위치 독립적인 코드 (PIC, Position-Independent Code)
공유 라이브러리의 핵심 목적은 여러 실행 중인 프로세스가 메모리에서 동일한 라이브러리 코드를 공유하여 귀중한 메모리 자원을 절약하는 것입니다. 그렇다면 여러 프로세스가 어떻게 프로그램의 단일 복사본을 공유할 수 있을까요?
고정 주소 방식의 문제점
한 가지 접근법은 각 공유 라이브러리에 미리 전용 주소 공간 덩어리를 할당하고, 로더가 항상 해당 주소에 공유 라이브러리를 로드하도록 하는 것입니다.
이 방식은 간단해 보이지만 다음과 같은 심각한 문제들을 야기합니다.
- 주소 공간의 비효율적 사용: 프로세스가 특정 라이브러리를 사용하지 않더라도, 해당 라이브러리를 위한 주소 공간은 항상 할당된 채로 낭비됩니다.
- 관리의 어려움:
- 할당된 주소 공간 덩어리들이 서로 겹치지 않도록 관리해야 합니다.
- 라이브러리가 수정될 때마다 할당된 공간에 여전히 맞는지 확인해야 합니다.
- 새로운 라이브러리를 추가할 때마다 빈 공간을 찾아야 합니다.
- 단편화 문제: 시간이 지남에 따라 주소 공간은 사용되지는 않지만 사용할 수도 없는 작은 구멍들로 가득 차게 됩니다.
- 시스템 비호환성: 라이브러리의 메모리 할당이 시스템마다 달라져 관리 부담이 가중됩니다.
해결책: 위치 독립적인 코드 (PIC)
이러한 문제들을 피하기 위해, 현대 시스템은 공유 모듈의 코드 세그먼트가 링커에 의해 수정될 필요 없이 메모리의 어느 곳에나 로드될 수 있도록 컴파일합니다. 이 접근법 덕분에 공유 모듈 코드 세그먼트의 단일 복사본을 무제한의 프로세스들이 공유할 수 있습니다. (물론, 각 프로세스는 여전히 자신만의 읽기/쓰기 가능한 데이터 세그먼트 복사본을 가집니다.)
이처럼 어떠한 재배치도 필요 없이 로드될 수 있는 코드를 위치 독립적인 코드(Position-Independent Code, PIC)라고 합니다. GNU 컴파일 시스템에서는 gcc에 -fpic 옵션을 사용하여 PIC를 생성하도록 지시하며, 공유 라이브러리는 반드시 이 옵션으로 컴파일되어야 합니다.
x86-64 시스템에서 같은 실행 모듈 내의 심볼을 참조하는 것은 PIC를 위해 특별한 처리가 필요하지 않습니다. 이러한 참조는 PC-상대 주소 지정을 사용하여 컴파일되고 정적 링커에 의해 재배치될 수 있습니다. 그러나, 공유 모듈에 의해 정의된 외부 프로시저나 전역 변수를 참조하는 경우에는 특별한 기법이 필요합니다.
PIC 데이터 참조 (PIC Data References)
컴파일러는 공유 라이브러리의 코드 세그먼트와 데이터 세그먼트 사이의 거리는 항상 일정하다는 흥미로운 사실을 이용하여 PIC 전역 변수 참조를 생성합니다. 즉, 라이브러리가 메모리의 어느 위치에 로드되더라도, 코드 내의 특정 명령어와 데이터 세그먼트 내의 특정 변수 사이의 거리는 변하지 않는 실행 시점 상수입니다.
전역 오프셋 테이블 (GOT, Global Offset Table)
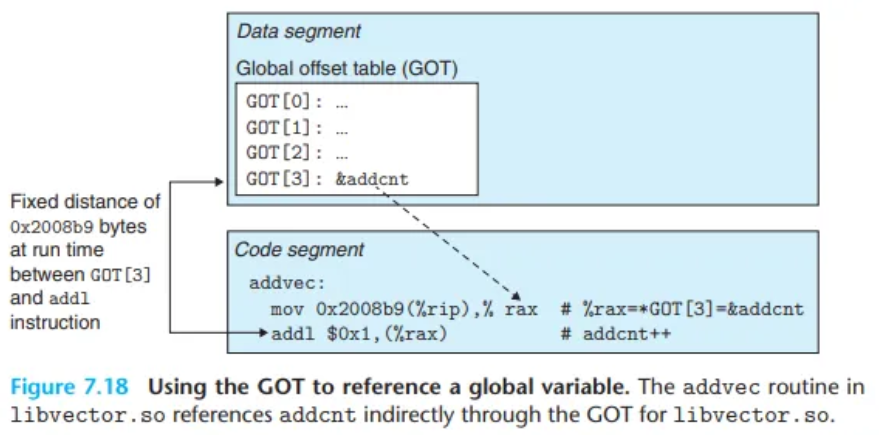
컴파일러는 이 원리를 활용하여 데이터 세그먼트의 시작 부분에 전역 오프셋 테이블(Global Offset Table, GOT)이라는 테이블을 만듭니다.
- 구조: GOT는 해당 목적 모듈이 참조하는 모든 전역 데이터 객체(함수 또는 전역 변수)에 대해 8바이트 크기의 항목(entry)을 가집니다.
- 컴파일러의 역할: 컴파일러는 코드에서 전역 변수를 직접 참조하는 대신, GOT에 있는 해당 항목을 PC-상대 주소로 참조하는 코드를 생성합니다. 또한, GOT의 각 항목에 대한 재배치 레코드를 생성합니다.
- 동적 링커의 역할: 프로그램이 로드될 때, 동적 링커는 GOT의 각 항목을 재배치하여 해당 항목이 가리키는 객체의 실제 절대 주소를 담도록 수정합니다.
동작 방식: 간접 주소 지정
이 방식의 핵심은, 명령어에서 GOT 항목까지의 상대 거리는 항상 일정하므로 PC-상대 주소 지정이 완벽하게 동작한다는 점입니다. 실제 변수 접근은 다음과 같은 2단계 간접 참조로 이루어집니다.
- 코드는 PC-상대 주소 지정을 사용하여 GOT에서 해당 변수의 항목을 찾습니다.
- 해당 GOT 항목에 저장된 실제 절대 주소를 읽어와서 최종적으로 변수에 접근합니다.
예를 들어, libvector.so의 addvec 루틴은 전역 변수 addcnt의 주소를 GOT의 세 번째 항목(GOT[3])을 통해 간접적으로 로드한 다음, 메모리에서 addcnt 값을 증가시킵니다.
참고: addcnt는 libvector.so 모듈 내에 정의되어 있으므로, 컴파일러는 addcnt에 대한 직접적인 PC-상대 참조를 생성할 수도 있었습니다. 하지만 만약 addcnt가 다른 공유 모듈에 정의되어 있었다면 GOT를 통한 간접 접근이 반드시 필요합니다. 컴파일러는 모든 참조에 대해 가장 일반적인 해결책인 GOT를 사용하도록 선택한 것입니다.
