
8장. 예외 제어 흐름 (Exceptional Control Flow, ECF)
ECF는 프로그램의 내부 변수로는 알 수 없는 시스템 상태의 변화에 대응하기 위해 발생하는 제어 흐름의 급격한 변화를 의미합니다.
1. 제어 흐름 (Control Flow)
프로세서에 전원이 들어온 순간부터 꺼질 때까지, 프로그램 카운터(Program Counter)는 명령어 주소의 연속인 값을 가집니다.
- 제어 전달 (Control Transfer)
- 하나의 명령어 주소 에서 다음 주소 로의 전환을 의미합니다. 이러한 제어 전달의 연속을 제어 흐름(Control Flow)이라고 합니다.
- 순차적 제어 흐름 (Smooth Control Flow)
- 가장 단순한 제어 흐름으로, 현재 명령어 와 다음 명령어 가 메모리 상에서 서로 인접해 있는 경우를 말합니다.
- 급격한 제어 흐름 변경 (Abrupt Change)
- 점프(jump), 호출(call), 반환(return)과 같은 익숙한 명령어들에 의해 발생합니다.
- 이러한 변경은 주로 프로그램 변수로 표현되는 내부 프로그램 상태(internal program state)의 변화에 대응하기 위해 필요합니다.
2. 예외 제어 흐름 (ECF)의 개념
시스템은 프로그램 내부 상태 변화뿐만 아니라, 프로그램 실행과 직접 관련 없는 시스템 상태(system state)의 변화에도 반응해야 합니다.
- ECF 발생 예시
- 하드웨어 타이머가 일정한 간격으로 신호를 보낼 때
- 네트워크 어댑터에 패킷이 도착했을 때
- 프로그램이 디스크에 요청한 데이터가 준비되었을 때
- 부모 프로세스가 생성한 자식 프로세스가 종료되었을 때
- ECF의 발생 수준
- ECF는 컴퓨터 시스템의 모든 수준에서 발생합니다.
- 하드웨어 수준: 하드웨어에서 감지된 이벤트가 예외 핸들러(exception handler)로 제어를 급격하게 이전시킵니다.
- 운영체제 수준: 커널이 문맥 교환(context switch)을 통해 한 사용자 프로세스에서 다른 프로세스로 제어를 넘깁니다.
- 애플리케이션 수준: 한 프로세스가 다른 프로세스에게 시그널(signal)을 보내면, 수신 프로세스의 시그널 핸들러(signal handler)로 제어가 급격히 이전됩니다. 또는 비지역 점프(nonlocal jump)를 통해 일반적인 스택 규칙을 벗어나 다른 함수로 제어를 이동시킬 수 있습니다.
3. ECF 이해의 중요성
프로그래머가 ECF를 이해해야 하는 이유는 다음과 같습니다.
- 주요 시스템 개념 이해: ECF는 운영체제가 I/O, 프로세스, 가상 메모리를 구현하는 기본 메커니즘입니다.
- 애플리케이션-OS 상호작용 이해: 애플리케이션은 트랩(trap) 또는 시스템 콜(system call)이라는 ECF의 한 형태를 사용하여 OS에 서비스를 요청합니다. (예: 디스크 쓰기, 네트워크 읽기, 새 프로세스 생성)
- 새로운 애플리케이션 작성 능력: ECF 메커니즘을 이해하면 유닉스 쉘(shell)이나 웹 서버와 같은 흥미로운 프로그램을 만들 수 있습니다.
- 동시성(Concurrency) 이해: ECF는 동시성을 구현하는 기본 원리입니다. (예: 애플리케이션을 중단시키는 예외 핸들러, 시분할로 실행되는 프로세스와 스레드)
- 소프트웨어 예외(Exception) 원리 이해: C++나 Java의
try-catch-throw와 같은 고수준 소프트웨어 예외는 C언어의setjmp,longjmp함수와 같은 저수준 비지역 점프(ECF의 한 형태)를 통해 그 구현 원리를 파악할 수 있습니다.
8.1 예외 (Exceptions)
예외는 하드웨어와 운영체제가 함께 구현하는 예외 제어 흐름(ECF)의 한 형태입니다. 세부 사항은 시스템마다 다르지만 기본 개념은 동일합니다.
1. 예외의 개념 및 처리 과정
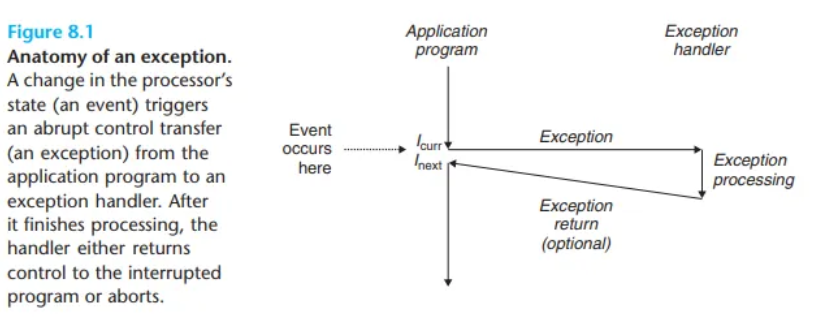
- 예외(Exception)란 프로세서의 상태(state) 변화에 대응하여 제어 흐름을 급격하게 변경하는 것을 말합니다.
- 이벤트(Event)
- 현재 명령어
I_curr를 실행하는 도중, 프로세서 내부의 비트나 신호로 인코딩된 상태에 중요한 변화가 발생하는 것을 이벤트(event)라고 합니다.
- 현재 명령어
- 예외 처리 과정
- 프로세서가 이벤트 발생을 감지합니다.
- 예외 테이블(exception table)이라는 점프 테이블을 통해 간접 프로시저 호출(indirect procedure call)을 합니다.
- 이 호출은 특정 이벤트를 처리하도록 설계된 운영체제 서브루틴, 즉 예외 핸들러(exception handler)를 실행시킵니다.
2. 이벤트의 종류
이벤트는 현재 실행 중인 명령어와의 관련성에 따라 나눌 수 있습니다.
- 현재 명령어 실행과 직접 관련된 경우
- 가상 메모리 페이지 폴트(page fault)
- 산술 오버플로우(arithmetic overflow)
- 0으로 나누기 시도
- 현재 명령어 실행과 관련 없는 경우
- 시스템 타이머 만료
- I/O 요청 완료
3. 예외 핸들러의 처리 후 동작
예외 핸들러가 처리를 완료하면, 예외를 발생시킨 이벤트의 종류에 따라 다음 세 가지 중 하나의 동작을 수행합니다.
- 핸들러는 제어를 현재 명령어
I_curr로 돌려줍니다. (이벤트가 발생했을 때 실행 중이던 명령어) - 핸들러는 제어를 다음 명령어
I_next로 돌려줍니다. (예외가 없었다면 다음에 실행되었을 명령어) - 핸들러는 인터럽트된 프로그램을 중단시킵니다.
8.1.1 예외 처리 (Exception Handling)
예외 처리는 하드웨어와 소프트웨어(OS)의 긴밀한 협력을 통해 이루어지므로, 각 구성 요소의 역할을 명확히 이해하는 것이 중요합니다.
1. 예외 처리의 기본 메커니즘
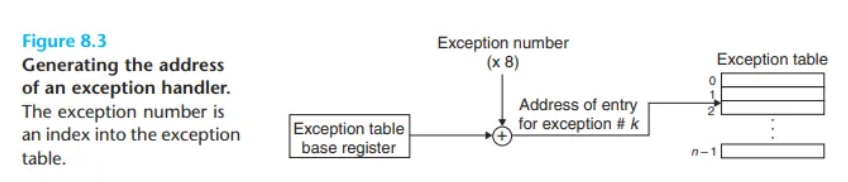
- 예외 번호 (Exception Number)
- 시스템에서 발생 가능한 모든 예외 유형에는 고유한 음이 아닌 정수 예외 번호가 할당됩니다.
- 프로세서 설계자 할당: 0으로 나누기, 페이지 폴트, 메모리 접근 위반, 브레이크포인트, 산술 오버플로우 등
- OS 커널 설계자 할당: 시스템 콜, 외부 I/O 장치로부터의 시그널 등
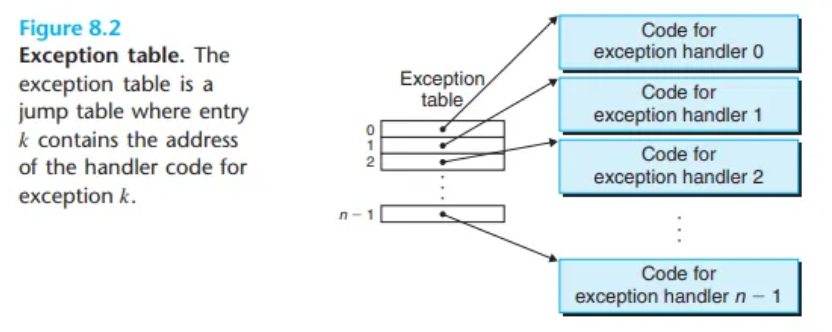
- 예외 테이블 (Exception Table)
- 시스템 부팅 시, 운영체제는 예외 테이블이라는 점프 테이블을 초기화합니다.
- 테이블의
k번째 항목에는k번 예외를 처리하는 핸들러의 주소가 저장됩니다. - 이 테이블의 시작 주소는 예외 테이블 베이스 레지스터(exception table base register)라는 특수 CPU 레지스터에 보관됩니다.
- 예외 발생 및 핸들러 호출 과정
- [하드웨어] 실행 중 프로세서는 이벤트 발생을 감지하고, 해당하는 예외 번호
k를 결정합니다. - [하드웨어] 프로세서는 예외 테이블의
k번째 항목을 통해 간접 프로시저 호출(indirect procedure call)을 수행하여 예외를 발생시킵니다. - [소프트웨어] 해당 예외 핸들러가 실행되어 이벤트를 처리합니다.
- [소프트웨어] 핸들러는 처리가 끝나면 "return from interrupt" 명령어를 실행하여 중단된 프로그램으로 복귀할 수 있습니다. 이 명령어는 저장된 상태를 복원하고, 필요시 사용자 모드로 전환한 후 제어권을 넘겨줍니다.
Q. 간접 프로시저 호출이란?
호출할 함수의 주소를 메모리나 레지스터에서 읽어와 실행하는 방식입니다.
우리가 일반적으로 사용하는 함수 호출은 직접(Direct) 호출입니다.
- 직접 호출:
call function_A- 컴파일 시점에
function_A의 주소가 결정되어, 기계어 코드에 그 주소가 그대로 박혀있습니다. CPU는 그냥 그 주소로 점프하면 됩니다.
- 컴파일 시점에
반면, 간접(Indirect) 호출은 한 단계를 더 거칩니다.
- 간접 호출:
call [0x1000]- CPU에게 "0x1000 번지로 점프해!"가 아니라, "0x1000 번지에 가서 거기 적혀있는 주소로 점프해!" 라고 명령하는 것과 같습니다.
예외 처리가 바로 이 방식입니다. CPU는 예외 핸들러의 주소를 직접 알지 못합니다. 대신 (예외 테이블 베이스 레지스터 값) + (예외 번호) 계산을 통해 예외 테이블의 특정 위치로 찾아가, 거기 저장된 핸들러의 주소를 읽어온 뒤 그 주소로 점프(호출)합니다.
2. 예외 처리와 프로시저 호출의 차이점
예외 처리는 프로시저 호출과 유사하지만 다음과 같은 중요한 차이점이 있습니다.
- 반환 주소 (Return Address)
- 핸들러로 분기하기 전에 반환 주소를 스택에 푸시하는 것은 동일합니다.
- 하지만 예외의 종류에 따라 반환 주소는 이벤트 발생 시 실행 중이던 현재 명령어(
I_curr)가 될 수도 있고, 다음에 실행될 다음 명령어(I_next)가 될 수도 있습니다.
- 프로세서 상태 저장
- 프로세서는 반환 주소 외에도, 중단된 프로그램을 재시작하는 데 필요한 추가적인 프로세서 상태를 스택에 푸시합니다. (예: x86-64 시스템의 EFLAGS 레지스터)
- 스택 사용
- 사용자 프로그램에서 커널로 제어가 넘어갈 때, 이 모든 항목들(반환 주소, 상태 등)은 사용자 스택이 아닌 커널 스택(kernel's stack)에 저장됩니다.
- 실행 모드 (Execution Mode)
- 예외 핸들러는 커널 모드(kernel mode)에서 실행됩니다. 이는 핸들러가 모든 시스템 자원에 완전한 접근 권한을 가짐을 의미합니다.
Q. 인터럽트 발생 시 스택 전환 과정
- 인터럽트 발생: 사용자 모드에서 프로그램이 실행되던 중 하드웨어 인터럽트가 발생합니다.
- 모드 전환: CPU는 하드웨어적으로 사용자 모드에서 커널 모드로 즉시 전환합니다.
- 스택 포인터 교체: 이 과정에서 CPU는 현재 사용 중인 사용자 스택 포인터(SS:SP 또는 RSP)를 특수 레지스터(TSS 등)에 잠시 저장합니다. 그리고 OS가 미리 설정해 둔 커널 스택의 주소를 스택 포인터 레지스터에 로드합니다. 이제 CPU는 커널 스택을 가리킵니다.
- 상태 저장 (커널 스택에 푸시): CPU는 사용자 프로그램으로 안전하게 복귀하는 데 필요한 최소한의 정보(컨텍스트)를 새로 바뀐 커널 스택에 푸시합니다.
- 사용자 프로그램의 스택 포인터 값 (SS, RSP)
- 복귀할 명령어 주소 (CS, RIP)
- 플래그 레지스터 (EFLAGS)
- 기타 필요한 레지스터 등
- ISR 실행: ISR 코드가 실행됩니다. 이때 ISR이 사용하는 모든 지역 변수나 내부 함수 호출 정보는 오직 커널 스택에만 쌓입니다.
- 복귀 (
iret명령어): ISR의 모든 작업이 끝나면, 일반ret이 아닌 특수 명령어인iret(Interrupt Return)을 실행합니다. - 상태 복원 및 모드 전환:
iret명령어는 하드웨어에게 커널 스택에 저장해 두었던 상태(사용자 스택 포인터, 복귀 주소 등)를 다시 CPU 레지스터로 복원하라고 지시합니다. 이 과정에서 CPU는 자동으로 커널 모드에서 사용자 모드로 다시 전환됩니다. - 실행 재개: 사용자 프로그램은 인터럽트가 발생했던 바로 그 시점부터, 아무 일도 없었다는 듯이 실행을 이어갑니다.
8.1.2 예외의 종류 (Classes of Exceptions)
예외는 그 특성에 따라 인터럽트(interrupts), 트랩(traps), 폴트(faults), 그리고 어보트(aborts)의 네 가지 클래스로 나눌 수 있습니다.
이어지는 내용은 각 클래스의 속성을 요약한 표(Figure 8.4)를 바탕으로 설명됩니다.
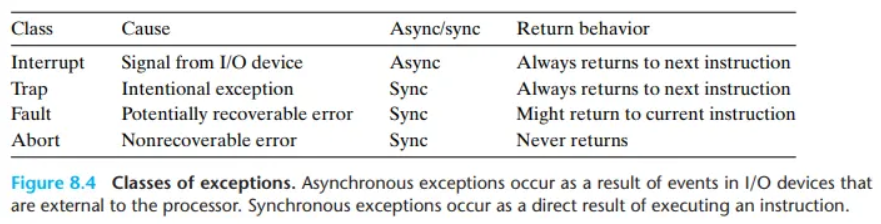
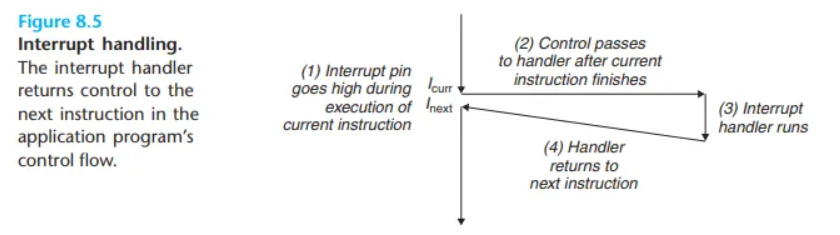
1. 인터럽트 (Interrupt)
- 원인 (Cause): 프로세서 외부의 I/O 장치로부터 오는 신호. (예: 키보드 입력, 마우스 움직임, 네트워크 패킷 도착, 타이머 만료)
- 동기/비동기 (Async/sync): 비동기 (Asynchronous). 현재 실행 중인 명령어와는 아무런 상관없이, 예측할 수 없는 타이밍에 외부 장치에 의해 발생합니다.
- 반환 동작 (Return behavior): 핸들러 처리 후 항상 다음 명령어 (
I_next)로 복귀합니다.- 인터럽트는 현재 실행 중인 프로그램의 잘못이 아니므로, 잠시 멈춰서 다른 일을 처리한 뒤 원래 하던 일의 다음 부분부터 계속 이어서 하면 됩니다.
2. 트랩 (Trap) 덫
- 원인 (Cause): 의도적인 예외. 프로그래머가 의도적으로 커널의 기능을 호출하기 위해 발생시킵니다.
- 대표적인 예: 시스템 콜(System Call).
open(),read(),fork()같은 함수를 호출하면, 프로그램은 스스로 트랩을 발생시켜 커널 모드로 전환하고 운영체제의 서비스를 요청합니다. 디버깅을 위한breakpoint도 트랩의 일종입니다. - 동기/비동기 (Async/sync): 동기 (Synchronous). 특정 명령어가 실행된 직접적인 결과로 발생합니다.
- 반환 동작 (Return behavior): 핸들러 처리 후 항상 다음 명령어 (
I_next)로 복귀합니다.- 시스템 콜은 OS에게 어떤 일을 시키는 것이므로, 그 일이 끝나면 프로그램은 자연스럽게 다음 코드를 실행합니다.
3. 폴트 (Fault)
- 원인 (Cause): 잠재적으로 복구 가능한 오류. 현재 명령어를 실행하다가 문제가 발생했지만, 핸들러가 이 문제를 해결하면 다시 실행을 시도해볼 수 있는 경우입니다.
- 대표적인 예: 페이지 폴트(Page Fault). 프로그램이 메모리에 없는 데이터에 접근하려고 할 때 발생합니다. 핸들러(OS)는 디스크에서 해당 데이터를 메모리로 가져온 뒤, 다시 원래 명령어를 실행시켜 작업을 이어가게 합니다. 권한 없는 메모리 주소에 접근하는 보호 폴트(segmentation fault)도 여기에 속하지만, 이 경우는 복구되지 않고 프로그램이 종료됩니다.
- 동기/비동기 (Async/sync): 동기 (Synchronous). 오류를 유발한 특정 명령어를 실행했기 때문에 발생합니다.
- 반환 동작 (Return behavior): 핸들러가 문제를 성공적으로 해결하면 현재 명령어 (
I_curr)를 재실행하기 위해 복귀합니다. 해결할 수 없는 문제라면 프로그램을 종료시킵니다.
4. 어보트/중단 (Abort)
- 원인 (Cause): 복구 불가능한 치명적인 오류. 주로 심각한 하드웨어 고장으로 인해 발생합니다.
- 대표적인 예: 메모리 칩의 물리적 손상으로 인한 패리티 에러(Parity Error) 등 하드웨어 오작동.
- 동기/비동기 (Async/sync): 동기 (Synchronous). 명령어를 실행하는 과정에서 하드웨어 결함이 발견되어 발생합니다.
- 반환 동작 (Return behavior): 절대 복귀하지 않습니다 (Never returns).
- 시스템이 불안정한 상태에 빠졌음을 의미하므로, 핸들러는 해당 프로그램을 즉시 강제 종료시키거나 시스템 전체를 중지시킵니다.
인터럽트 (Interrupts)
인터럽트는 프로세서 외부의 I/O 장치로부터 오는 신호에 의해 비동기적으로(asynchronously) 발생하는 예외입니다.
1. 인터럽트의 특징
- 비동기적 발생
- 특정 명령어의 실행으로 인해 발생하는 것이 아니기 때문에 "비동기적"이라고 합니다.
- 인터럽트를 처리하는 예외 핸들러는 종종 인터럽트 핸들러(interrupt handlers)라고 불립니다.
2. 인터럽트 처리 과정
- 네트워크 어댑터, 디스크 컨트롤러, 타이머 칩과 같은 I/O 장치가 프로세서 칩의 특정 핀에 신호를 보내고, 시스템 버스에 자신을 식별하는 예외 번호를 전달하여 인터럽트를 발생시킵니다.
- 프로세서는 현재 실행 중이던 명령어를 완전히 마칩니다.
- 그 후, 프로세서는 인터럽트 핀의 신호(high)를 감지하고 시스템 버스에서 예외 번호를 읽어와 해당하는 인터럽트 핸들러를 호출합니다.
- 핸들러가 작업을 마치고 반환되면, 제어는 다음 명령어(
I_next)로 넘어갑니다. (즉, 인터럽트가 없었다면 실행되었을 바로 그 다음 명령어) - 결과적으로 프로그램은 마치 인터럽트가 전혀 발생하지 않았던 것처럼 실행을 계속 이어나갑니다.
💡 동기적 예외 vs 비동기적 예외
- 인터럽트는 I/O 장치에 의해 비동기적으로 발생합니다.
- 나머지 예외들(트랩, 폴트, 어보트)은 현재 실행 중인 명령어, 즉 폴트 유발 명령어(faulting instruction)의 결과로 동기적으로(synchronously) 발생합니다.
트랩(Traps)과 시스템 콜(System Calls)
- 트랩(Trap)은 특정 명령어를 실행한 결과로 발생하는 의도적인 예외입니다. 인터럽트와 마찬가지로, 트랩 핸들러는 처리가 끝나면 제어를 다음 명령어(
I_next)로 돌려줍니다.
1. 시스템 콜 (System Call)
트랩의 가장 중요한 용도는 사용자 프로그램과 커널 사이에 프로시저와 유사한 인터페이스를 제공하는 것인데, 이를 시스템 콜이라고 합니다.
- 목적: 사용자 프로그램은 파일 읽기(
read), 새 프로세스 생성(fork), 현재 프로세스 종료(exit) 등 커널의 서비스가 필요한 경우가 많습니다. 시스템 콜은 이러한 커널 서비스에 대한 통제된 접근을 허용하기 위한 메커니즘입니다. - 동작 과정:
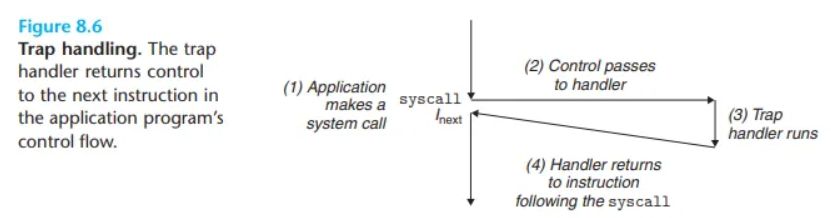
- 사용자 프로그램이 커널 서비스
n을 요청하기 위해 특별한syscall n명령어를 실행합니다. syscall명령어 실행은 트랩을 발생시켜 예외 핸들러를 호출합니다.- 예외 핸들러는 인자(
n)를 해석하여 해당하는 커널 루틴(kernel routine)을 호출하고 서비스를 수행합니다.
2. 시스템 콜 vs 일반 함수 호출
프로그래머 관점에서는 시스템 콜이 일반 함수 호출과 동일하게 보이지만, 내부 구현 방식은 매우 다릅니다.
- 일반 함수 (Regular Function)
- 사용자 모드(user mode)에서 실행됩니다.
- 실행할 수 있는 명령어의 종류에 제약이 있습니다.
- 호출한 함수와 동일한 사용자 스택에 접근합니다.
- 시스템 콜 (System Call)
- 커널 모드(kernel mode)에서 실행됩니다.
- 특권 명령어(privileged instructions)를 실행할 수 있습니다.
- 커널 내에 정의된 별도의 커널 스택에 접근합니다.
폴트 (Faults)
폴트는 핸들러가 복구할 수도 있는 오류(potentially recoverable error)로 인해 발생합니다.
1. 폴트의 처리 과정
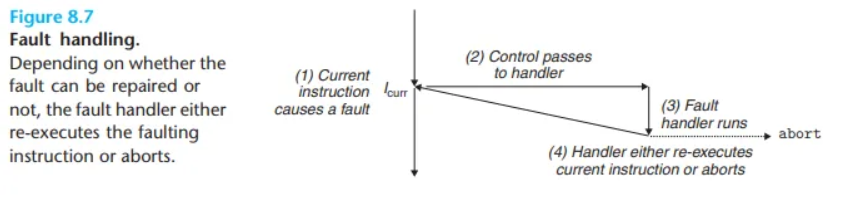
- 폴트가 발생하면, 프로세서는 제어권을 폴트 핸들러로 넘깁니다.
- 핸들러는 오류 상태를 수정하려고 시도합니다.
- 수정 성공 시: 제어권을 오류를 유발했던 현재 명령어(
I_curr)로 돌려주어 재실행하게 합니다. - 수정 실패 시: 커널 내의 중단 루틴(abort routine)으로 제어를 넘겨, 오류를 일으킨 애플리케이션을 강제 종료시킵니다.
- 수정 성공 시: 제어권을 오류를 유발했던 현재 명령어(
2. 대표적인 예: 페이지 폴트 (Page Fault)
페이지 폴트는 폴트의 가장 대표적인 예시입니다.
- 발생 원인: 명령어가 참조하는 가상 주소에 해당하는 페이지가 물리 메모리(RAM)에 없고 디스크에 있을 때 발생합니다.
- 처리: 페이지 폴트 핸들러는 디스크에서 해당 페이지를 메모리로 로드한 후, 제어권을 다시 원래 명령어로 돌려줍니다.
- 결과: 명령어가 다시 실행될 때는 필요한 페이지가 메모리에 존재하므로, 이번에는 폴트 없이 성공적으로 실행을 완료할 수 있습니다.
어보트/중단 (Aborts)
어보트는 복구 불가능한 치명적인 오류(unrecoverable fatal error)로 인해 발생하며, 주로 하드웨어 오류가 원인입니다.
- 발생 원인: DRAM이나 SRAM 비트가 손상되어 발생하는 패리티 오류(parity error)와 같은 심각한 하드웨어 문제입니다.
- 처리:
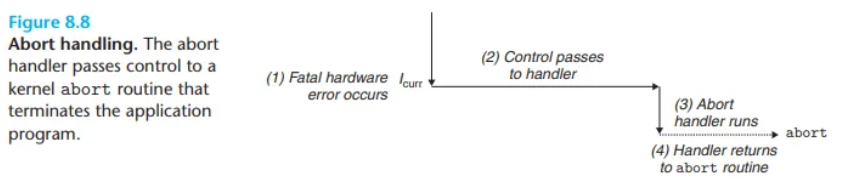
- 어보트 핸들러는 제어권을 **절대 애플리케이션으로 돌려주지 않습니다.**
- 핸들러는 애플리케이션을 종료시키는 **중단 루틴(abort routine)**으로 제어를 넘깁니다.Exception 예시

8.1.3 Linux/x86-64 시스템의 예외
x86-64 시스템에는 최대 256개의 서로 다른 예외 유형이 정의되어 있습니다.
- 예외 번호 0 ~ 31: Intel 아키텍처 설계자들이 정의한 예외입니다. 따라서 모든 x86-64 시스템에서 동일하게 사용됩니다.
- 예외 번호 32 ~ 255: 운영체제가 정의하는 인터럽트와 트랩에 해당합니다.
Linux/x86-64의 폴트(Faults)와 중단(Aborts)
- 나누기 오류 (Divide error, 예외 0)
- 원인: 애플리케이션이 0으로 나누기를 시도하거나, 나눗셈 결과가 목적지 피연산자(operand)에 비해 너무 클 때 발생합니다.
- 처리: 유닉스(Linux)는 이 오류를 복구하려 하지 않고, 프로그램을 중단(abort)시킵니다.
- 쉘 보고: 일반적으로 "Floating point exception"으로 보고됩니다.
- 일반 보호 폴트 (General protection fault, 예외 13)
- 원인: 주로 프로그램이 정의되지 않은 가상 메모리 영역을 참조하거나, 읽기 전용(read-only)인 코드 세그먼트에 쓰려고 할 때 등 다양한 이유로 발생합니다.
- 처리: Linux는 이 폴트를 복구하지 않고 프로그램을 종료시킵니다.
- 쉘 보고: 일반적으로 "Segmentation fault"로 보고됩니다.
- 페이지 폴트 (Page fault, 예외 14)
- 특징: 오류를 유발한 명령어가 재시작되는 대표적인 예외입니다.
- 처리: 핸들러는 디스크에 있는 가상 메모리의 해당 페이지를 물리 메모리의 페이지로 매핑한 다음, 오류를 일으킨 명령어를 재시작합니다.
- 머신 체크 (Machine check, 예외 18)
- 원인: 오류를 유발한 명령어를 실행하는 동안 감지된 치명적인 하드웨어 오류의 결과로 발생합니다.
- 처리: 머신 체크 핸들러는 제어권을 절대 애플리케이션 프로그램으로 돌려주지 않습니다.
Linux/x86-64 시스템 콜 (System Calls)
Linux는 파일 읽기/쓰기, 프로세스 생성 등 커널 서비스를 애플리케이션이 요청할 때 사용하는 수백 개의 시스템 콜을 제공합니다.
1. 시스템 콜 호출 방식
각 시스템 콜은 커널 내 점프 테이블의 오프셋에 해당하는 고유한 정수 번호를 가집니다.
- C 라이브러리 래퍼 함수 (Wrapper Functions)
- C 프로그램은 대부분 표준 라이브러리에서 제공하는 편리한 래퍼(wrapper) 함수를 사용합니다. (예:
printf,read) - 이 래퍼 함수는 인자들을 정리하고, 적절한 시스템 콜 명령으로 커널에 트랩을 건 뒤, 반환 값을 호출 프로그램에 전달하는 역할을 합니다.
- 일반적으로 시스템 콜과 그 래퍼 함수는 시스템 수준 함수(system-level functions)라고 통칭합니다.
- C 프로그램은 대부분 표준 라이브러리에서 제공하는 편리한 래퍼(wrapper) 함수를 사용합니다. (예:
- 직접 호출 (
syscall명령어)- x86-64 시스템에서는
syscall이라는 트랩 명령어를 통해 시스템 콜을 직접 호출할 수 있습니다.
- x86-64 시스템에서는
2. syscall 명령어 호출 규약
Linux 시스템 콜의 모든 인자는 스택이 아닌 범용 레지스터를 통해 전달됩니다.
%rax: 호출할 시스템 콜의 번호를 저장합니다.%rdi,%rsi,%rdx,%r10,%r8,%r9: 최대 6개의 인자를 순서대로 저장합니다. (첫 번째 인자는%rdi, 두 번째는%rsi...)- 반환 값: 시스템 콜이 반환되면
%rax레지스터에 결과값이 저장됩니다. -4095에서 -1 사이의 음수 값은 오류가 발생했음을 의미합니다.
3. 어셈블리 코드 예제: hello 프로그램

제공된 어셈블리 코드는 C 라이브러리 함수(printf) 없이 syscall 명령어로 write와 _exit 시스템 콜을 직접 호출하여 "hello, world"를 출력합니다.
write함수 호출 (lines 9-13)movq $1, %rax:write시스템 콜의 번호인 1을%rax에 저장합니다.movq $1, %rdi: 첫 번째 인자인 stdout의 파일 디스크립터(1)를%rdi에 저장합니다.movq $string, %rsi: 두 번째 인자인 출력할 문자열의 주소를%rsi에 저장합니다.movq $len, %rdx: 세 번째 인자인 문자열의 길이를%rdx에 저장합니다.syscall: 시스템 콜을 실행하여 커널에 트랩을 겁니다.
_exit함수 호출 (lines 14-16)movq $60, %rax:_exit시스템 콜의 번호인 60을%rax에 저장합니다.movq $0, %rdi: 첫 번째 인자인 종료 상태(0)를%rdi에 저장합니다.syscall: 시스템 콜을 실행하여 프로그램을 종료합니다.
8.5 시그널 (Signals)
지금까지 하드웨어와 소프트웨어가 협력하는 저수준(low-level) 예외 메커니즘과, 이를 이용한 문맥 교환(context switch)을 살펴보았습니다. 이제 더 높은 수준(higher-level)의 소프트웨어 예외 제어 흐름인 Linux 시그널(signal)에 대해 알아보겠습니다. 시그널은 프로세스와 커널이 다른 프로세스를 중단시킬 수 있도록 허용합니다.
1. 시그널의 개념
- 시그널(Signal)은 시스템에서 어떤 유형의 이벤트가 발생했음을 프로세스에게 알리는 작은 메시지입니다. Linux 시스템은 약 30가지의 서로 다른 시그널 유형을 지원합니다.
각 시그널 유형은 특정 시스템 이벤트에 해당합니다.
- 저수준 하드웨어 예외를 사용자 프로세스에 노출
- 일반적으로 저수준 하드웨어 예외는 커널의 예외 핸들러에 의해 처리되며 사용자 프로세스에게는 보이지 않습니다. 시그널은 이러한 예외의 발생을 사용자 프로세스에 노출하는 메커니즘을 제공합니다.
- SIGFPE (8번): 프로세스가 0으로 나누기를 시도할 때 커널이 보냅니다.
- SIGILL (4번): 프로세스가 잘못된 명령어를 실행할 때 커널이 보냅니다.
- SIGSEGV (11번): 프로세스가 잘못된 메모리 참조를 할 때 커널이 보냅니다.
- 고수준 소프트웨어 이벤트에 해당
- 다른 시그널들은 커널이나 다른 사용자 프로세스에서 발생하는 고수준 소프트웨어 이벤트에 해당합니다.
- SIGINT (2번): 포그라운드(foreground)에서 실행 중인 프로세스가 있을 때 사용자가
Ctrl+C를 입력하면, 커널이 해당 포그라운드 프로세스 그룹의 각 프로세스에 이 시그널을 보냅니다. - SIGKILL (9번): 한 프로세스가 다른 프로세스를 강제로 종료시키기 위해 이 시그널을 보낼 수 있습니다.
- SIGCHLD (17번): 자식 프로세스가 종료되거나 멈추면, 커널이 부모 프로세스에 이 시그널을 보냅니다.
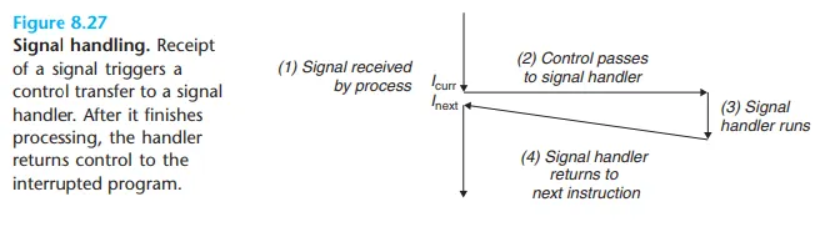
8.5.1 시그널 관련 용어 (Signal Terminology)
시그널이 목적지 프로세스로 전달되는 과정은 두 가지 명확한 단계로 이루어집니다.
1. 시그널 전송 (Sending a Signal)
시그널 전송이란 커널이 목적지 프로세스의 컨텍스트(context)에 있는 특정 상태를 업데이트하여 시그널을 전달(deliver)하는 것을 의미합니다. 시그널이 전달되는 이유는 두 가지입니다.
- 커널이 0으로 나누기 오류나 자식 프로세스의 종료와 같은 시스템 이벤트를 감지했을 때.
- 한 프로세스가
kill함수를 호출하여, 커널에게 특정 프로세스로 시그널을 보내달라고 명시적으로 요청했을 때. (프로세스는 자기 자신에게 시그널을 보낼 수도 있습니다.)
2. 시그널 수신 (Receiving a Signal)
시그널 수신이란 목적지 프로세스가 커널에 의해 강제로 시그널 전달에 대한 반응을 보이는 것을 의미합니다. 프로세스는 다음 세 가지 방식으로 반응할 수 있습니다.
- 시그널을 무시(ignore)한다.
- 프로세스를 종료(terminate)한다.
- 시그널 핸들러(signal handler)라는 사용자 수준 함수를 실행하여 시그널을 잡는다(catch).
3. 시그널의 상태와 관리
- 대기 중인 시그널 (Pending Signal)
- 전송은 되었지만 아직 수신되지 않은 시그널을 의미합니다.
- 어떤 시점에, 특정 유형의 대기 중인 시그널은 최대 한 개만 존재할 수 있습니다. 만약
k타입의 대기 시그널이 이미 있는데, 또 다른k타입 시그널이 전송되면 그 시그널은 큐에 쌓이지 않고 그냥 버려집니다(discarded).
- 시그널 블록 (Blocking a Signal)
- 프로세스는 특정 시그널의 수신을 선택적으로 블록(block)할 수 있습니다.
- 시그널이 블록되면, 전달은 될 수 있지만(즉, pending 상태가 됨) 프로세스가 해당 시그널을 언블록(unblock)하기 전까지는 수신되지 않습니다.
- 커널의 관리 방식
- 대기 중인 시그널은 최대 한 번만 수신됩니다.
- 커널은 각 프로세스마다 두 개의 비트 벡터(bit vector)를 유지합니다.
pending비트 벡터: 대기 중인 시그널 집합을 관리합니다.k타입 시그널이 전달되면k번째 비트를 설정(set)하고, 수신되면 해제(clear)합니다.blocked비트 벡터: 블록된 시그널 집합을 관리합니다.
8.5.2 시그널 전송 (Sending Signals)
Unix 시스템은 프로세스에 시그널을 보내기 위한 여러 메커니즘을 제공합니다. 이 모든 메커니즘은 프로세스 그룹(process group)이라는 개념에 의존합니다.
프로세스 그룹 (Process Groups)
모든 프로세스는 정확히 하나의 프로세스 그룹에 속하며, 이 그룹은 양의 정수인 프로세스 그룹 ID (process group ID)로 식별됩니다.
getpgrp함수pid_t getpgrp(void);- 현재 프로세스의 프로세스 그룹 ID를 반환합니다.
- 프로세스 그룹 소속 규칙
- 기본적으로, 자식 프로세스는 부모 프로세스와 동일한 프로세스 그룹에 속합니다.
setpgid함수를 사용하여 자신 또는 다른 프로세스의 프로세스 그룹을 변경할 수 있습니다.
setpgid함수int setpgid(pid_t pid, pid_t pgid);pid로 지정된 프로세스의 프로세스 그룹을pgid로 변경합니다.pid가 0이면, 현재 프로세스의 PID가 사용됩니다.pgid가 0이면,pid로 지정된 프로세스의 PID가 프로세스 그룹 ID로 사용됩니다.
- 예시:
- 만약 15213번 프로세스가
setpgid(0, 0);을 호출하면, 이는 자신의 PID를 자신의 프로세스 그룹 ID로 사용하는 새로운 프로세스 그룹을 생성하는 것과 같습니다. 이 프로세스는 새로운 프로세스 그룹의 리더가 됩니다.
- 만약 15213번 프로세스가
/bin/kill 프로그램을 이용한 시그널 전송
/bin/kill 프로그램은 다른 프로세스에게 임의의 시그널을 보낼 수 있습니다.
- 특정 프로세스에게 보내기:
linux> /bin/kill -9 15213- 위 명령어는 프로세스 ID가 15213인 프로세스에게 시그널 9번(
SIGKILL)을 보냅니다.
- 프로세스 그룹 전체에게 보내기:
- PID 앞에 음수 기호(-)를 붙이면 해당 프로세스 그룹에 속한 모든 프로세스에게 시그널을 보냅니다.
linux> /bin/kill -9 -15213- 위 명령어는 프로세스 그룹 ID가 15213인 그룹 내 모든 프로세스에게
SIGKILL시그널을 보냅니다.
참고: 쉘에 내장된 kill 명령어와 구분하기 위해 전체 경로(/bin/kill)를 사용하기도 합니다.
키보드를 이용한 시그널 전송
Unix 쉘은 하나의 명령 라인을 실행하며 생성된 프로세스들을 잡(job)이라는 단위로 관리합니다.
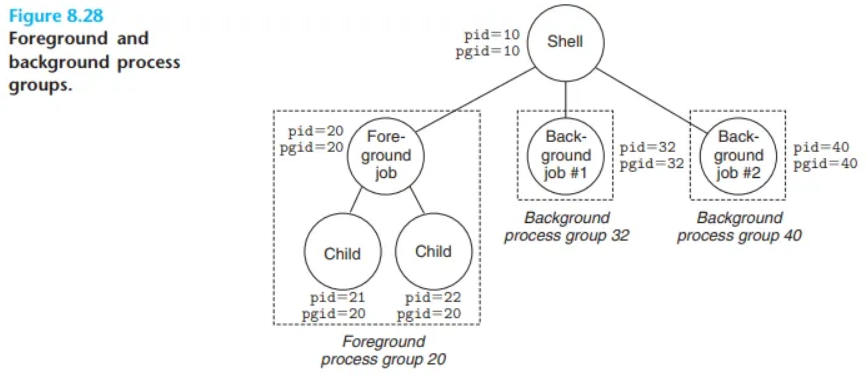
- 잡(Job)의 종류:
- 포그라운드 잡 (Foreground job): 어느 시점에서든 최대 한 개만 존재할 수 있습니다.
- 백그라운드 잡 (Background jobs): 여러 개 존재할 수 있습니다.
- 잡과 프로세스 그룹:
- 쉘은 각 잡마다 별도의 프로세스 그룹을 생성합니다.
- 예를 들어,
ls | sort명령어는ls와sort두 개의 프로세스로 구성된 하나의 포그라운드 잡을 생성하며, 이 두 프로세스는 같은 프로세스 그룹에 속하게 됩니다.
- 키보드 입력과 시그널:
Ctrl+C: 키보드로Ctrl+C를 입력하면, 커널은 포그라운드 프로세스 그룹에 속한 모든 프로세스에게SIGINT시그널을 보냅니다. 기본 동작은 포그라운드 잡을 종료(terminate)시키는 것입니다.Ctrl+Z: 키보드로Ctrl+Z를 입력하면, 커널은 포그라운드 프로세스 그룹에 속한 모든 프로세스에게SIGTSTP시그널을 보냅니다. 기본 동작은 포그라운드 잡을 정지(stop/suspend)시키는 것입니다.
kill 함수를 이용한 시그널 전송
프로세스는 kill 함수를 호출하여 다른 프로세스(자기 자신 포함)에게 시그널을 보낼 수 있습니다.
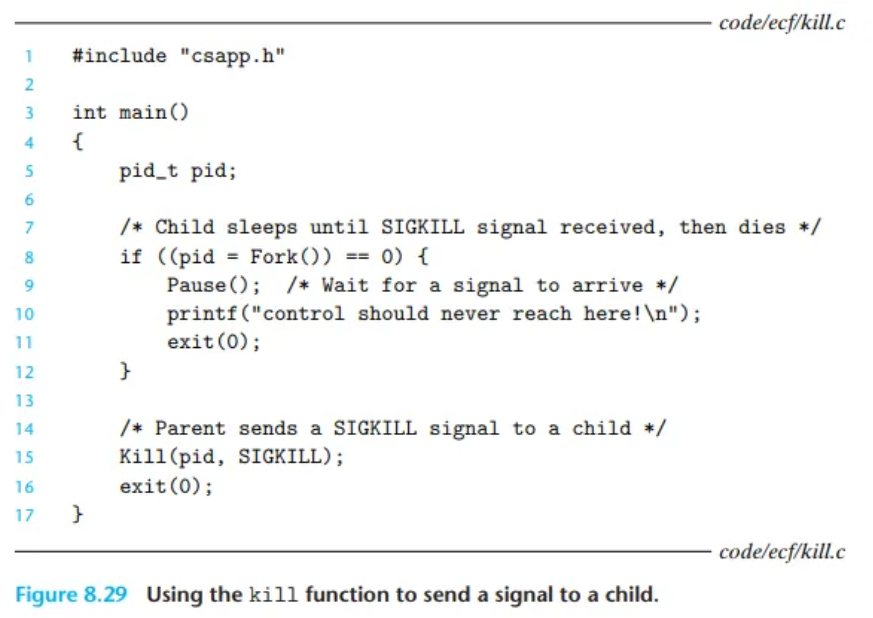
- 함수 원형:
#include <sys/types.h> #include <signal.h> int kill(pid_t pid, int sig); // 성공 시 0, 오류 시 -1 반환 pid값에 따른 동작:pid > 0:pid로 지정된 특정 프로세스에게sig시그널을 보냅니다.pid == 0: 호출한 프로세스가 속한 프로세스 그룹 내의 모든 프로세스에게sig시그널을 보냅니다.pid < 0: 프로세스 그룹 ID가|pid|(pid의 절댓값)인 그룹 내의 모든 프로세스에게sig시그널을 보냅니다.
alarm 함수를 이용한 시그널 전송
프로세스는 alarm 함수를 호출하여 자기 자신에게 SIGALRM 시그널을 보낼 수 있습니다.
- 함수 원형:
#include <unistd.h> unsigned int alarm(unsigned int secs); // 이전 알람의 남은 시간을 반환, 이전 알람이 없었다면 0을 반환 - 동작 방식:
alarm(secs)를 호출하면, 커널은secs초 후에 호출한 프로세스에게SIGALRM시그널을 보내도록 예약합니다.- 만약
secs가 0이면, 새로운 알람은 예약되지 않고 기존의 예약된 알람이 취소됩니다. alarm함수를 호출하면 이전에 예약된 알람은 항상 취소됩니다.- 반환 값: 이전에 예약된 알람이 취소되지 않았다면 전달되기까지 남아있었을 시간(초)을 반환합니다. 이전에 예약된 알람이 없었다면 0을 반환합니다.
8.5.3 시그널 수신 (Receiving Signals)
1. 시그널 수신 과정
커널이 프로세스 p를 커널 모드에서 사용자 모드로 전환할 때마다(예: 시스템 콜에서 복귀하거나 문맥 교환이 완료될 때), 해당 프로세스의 블록되지 않은 대기 시그널 집합(pending & ~blocked)을 확인합니다.
- 집합이 비어있을 경우 (일반적인 경우): 커널은 제어권을 프로세스
p의 논리적 제어 흐름상 다음 명령어(I_next)로 넘깁니다. - 집합이 비어있지 않을 경우: 커널은 집합 내에서 특정 시그널
k(보통 가장 작은 번호의 시그널)를 선택하여 프로세스p가 해당 시그널을 수신하도록 강제합니다. 시그널 수신은 프로세스의 특정 행동을 유발하며, 그 행동이 완료되면 제어권은 다시 다음 명령어(I_next)로 넘어갑니다.
2. 기본 처리 행동 (Default Action)
각 시그널 유형에는 미리 정의된 기본 처리 행동(default action)이 있으며, 다음 중 하나에 해당합니다.
- 프로세스를 종료(terminate)시킨다.
- 프로세스를 종료시키고 코어 덤프(core dump)를 생성한다.
SIGCONT시그널을 받을 때까지 프로세스를 정지(stop/suspend)시킨다.- 시그널을 무시(ignore)한다.
예를 들어, SIGKILL의 기본 행동은 프로세스 종료이고, SIGCHLD의 기본 행동은 무시입니다. 프로세스는 signal 함수를 사용하여 이러한 기본 행동을 수정할 수 있습니다. 단, SIGSTOP과 SIGKILL의 기본 행동은 절대 변경할 수 없습니다.
Q. 코어 덤프란?
코어 덤프(Core Dump)는 프로그램이 비정상적으로 종료될 때, 그 순간의 메모리 상태를 그대로 복사해서 저장해 놓은 파일입니다. 주로 디버깅 목적으로 사용됩니다.
코어 덤프의 목적과 내용
코어 덤프의 유일한 목적은 사후 디버깅(post-mortem debugging)입니다. 프로그램이 왜 죽었는지 원인을 찾기 위해 만들어집니다. 이 파일 안에는 프로그램이 충돌한 순간의 거의 모든 정보가 담겨 있습니다.
- 메모리 스냅샷: 스택, 힙 등 프로세스가 사용하던 모든 메모리 영역의 데이터
- CPU 레지스터 값: 충돌 시점의 모든 CPU 레지스터 값
- 프로그램 카운터(PC): 어떤 명령어를 실행하다가 오류가 발생했는지 알려주는 정보
- 프로세스 상태 정보: 프로세스 ID, 시그널 번호 등
현대 운영체제에서의 코어 덤프
코어 덤프는 프로그램의 메모리 전체를 복사하기 때문에 파일 크기가 매우 클 수 있습니다. 이 때문에 현대의 많은 운영체제에서는 기본적으로 코어 덤프 생성을 비활성화해두는 경우가 많습니다. ulimit -c unlimited 같은 명령어를 사용해 코어 덤프 파일의 최대 크기 제한을 풀어야 생성되기도 합니다.
3. signal 함수를 이용한 처리 행동 변경
signal 함수는 특정 시그널(signum)에 대한 처리 행동을 변경합니다.

- 함수 원형:
#include <signal.h> typedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler); // 성공 시 이전 핸들러의 포인터 반환, 오류 시 SIG_ERR 반환 handler인자에 따른 세 가지 동작:SIG_IGN:signum타입의 시그널을 무시합니다.SIG_DFL:signum타입의 시그널에 대한 행동을 기본값으로 복원합니다.- 사용자 정의 함수 주소:
signum타입의 시그널을 수신할 때마다 시그널 핸들러(signal handler)라고 불리는 사용자 정의 함수를 호출합니다.
4. 시그널 핸들러의 동작과 용어
- 핸들러 설치 (Installing the handler):
signal함수에 핸들러의 주소를 전달하여 기본 행동을 변경하는 것을 의미합니다. - 시그널 잡기 (Catching the signal): 설치된 핸들러가 호출되는 것을 의미합니다.
- 시그널 처리 (Handling the signal): 핸들러가 실행되는 것을 의미합니다.
핸들러가 실행을 마치고 반환되면, 제어권은 일반적으로 시그널에 의해 중단되었던 바로 그 지점의 명령어로 돌아갑니다. (단, 일부 시스템에서는 중단된 시스템 콜이 오류를 반환하며 즉시 복귀하기도 합니다.)
5. 중첩된 시그널 핸들러 (Nested Signal Handlers)
시그널 핸들러의 실행은 다른 시그널에 의해 중단될 수 있습니다.
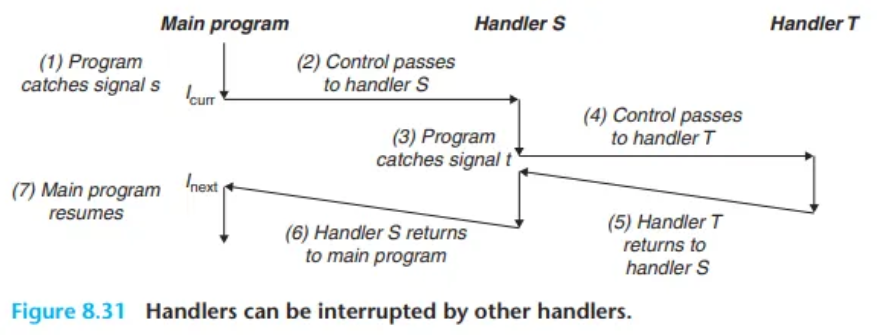
예를 들어, 메인 프로그램이 s 시그널을 받아 핸들러 S를 실행하던 중, 다른 시그널 t를 받게 되면 S의 실행이 중단되고 핸들러 T가 실행됩니다. T가 반환되면 S가 중단되었던 지점부터 실행을 재개하고
8.5.4 시그널 블록과 언블록 (Blocking and Unblocking Signals)
Linux는 시그널을 블록하기 위한 암묵적 메커니즘과 명시적 메커니즘을 제공합니다.
1. 시그널 블록 메커니즘
- 암묵적 블록 메커니즘 (Implicit blocking mechanism)
- 커널은 기본적으로, 현재 핸들러가 처리하고 있는 것과 동일한 타입의 시그널이 도착하면 자동으로 블록합니다.
- 예를 들어, 프로세스가
s시그널을 받아 핸들러S를 실행하는 중에 또 다른s시그널이 도착하면, 그 시그널은pending상태가 되지만 핸들러S가 반환될 때까지 수신되지 않습니다. 이는 핸들러가 자기 자신에 의해 중단되는 것을 방지합니다.
- 명시적 블록 메커니즘 (Explicit blocking mechanism)
- 애플리케이션은
sigprocmask함수와 관련 함수들을 사용하여 특정 시그널을 명시적으로 블록하거나 언블록할 수 있습니다.
- 애플리케이션은
2. sigprocmask 함수와 시그널 집합
sigprocmask 함수는 현재 블록된 시그널의 집합(blocked 비트 벡터)을 변경합니다.
- 함수 원형 및 관련 함수:
#include <signal.h> // 핵심 함수: 시그널 마스크를 변경 int sigprocmask(int how, const sigset_t *set, sigset_t *oldset); // 시그널 집합(sigset_t)을 조작하는 헬퍼 함수들 int sigemptyset(sigset_t *set); // 집합을 비움 int sigfillset(sigset_t *set); // 모든 시그널을 집합에 추가 int sigaddset(sigset_t *set, int signum); // 특정 시그널을 추가 int sigdelset(sigset_t *set, int signum); // 특정 시그널을 제거 int sigismember(const sigset_t *set, int signum); // 멤버인지 확인 how인자에 따른 동작:SIG_BLOCK:set에 포함된 시그널들을 현재blocked집합에 추가합니다 (blocked = blocked | set).SIG_UNBLOCK:set에 포함된 시그널들을 현재blocked집합에서 제거합니다 (blocked = blocked & ~set).SIG_SETMASK: 현재blocked집합을set으로 완전히 교체합니다 (blocked = set).
oldset인자:oldset이 NULL이 아니면, 변경하기 이전의blocked비트 벡터 값이oldset에 저장됩니다. 이는 나중에 원래 상태로 복원할 때 유용합니다.
3. 코드 예제 분석 (Figure 8.32)
제공된 코드는 sigprocmask를 사용하여 SIGINT 시그널의 수신을 일시적으로 차단하는 방법을 보여줍니다.

sigemptyset(&mask);:mask라는 시그널 집합을 비웁니다.sigaddset(&mask, SIGINT);:mask집합에SIGINT시그널을 추가합니다. 이제mask는SIGINT만 포함한 집합이 됩니다.sigprocmask(SIG_BLOCK, &mask, &prev_mask);:SIG_BLOCK을 사용하여mask에 있는SIGINT를 현재 프로세스의 블록 목록에 추가합니다.- 동시에, 이 함수를 호출하기 전의 원래 블록 목록은
prev_mask에 저장됩니다. - 이제 이 다음 코드 영역은
SIGINT에 의해 중단되지 않는 임계 구역(critical section)이 됩니다.
sigprocmask(SIG_SETMASK, &prev_mask, NULL);:- 임계 구역의 작업이 끝나면,
SIG_SETMASK를 사용하여 이전에 저장해 둔prev_mask로 블록 목록을 완전히 복원합니다. - 이로써
SIGINT의 블록이 해제되고, 프로세스는 원래의 시그널 수신 상태로 돌아갑니다.
- 임계 구역의 작업이 끝나면,
8.5.5 시그널 핸들러 작성하기 (Writing Signal Handlers)
시그널 핸들링은 Linux 시스템 수준 프로그래밍에서 가장 까다로운 부분 중 하나입니다.
시그널 핸들링의 어려움
핸들러는 다음과 같은 속성 때문에 논리적으로 추론하기 어렵습니다.
- 핸들러는 메인 프로그램과 동시적으로(concurrently) 실행되며 동일한 전역 변수를 공유하므로, 메인 프로그램 및 다른 핸들러와 충돌을 일으킬 수 있습니다.
- 시그널이 언제 어떻게 수신되는지에 대한 규칙이 종종 직관에 반하는 경우가 많습니다.
- 시스템마다 시그널 핸들링 방식(semantics)이 다를 수 있습니다.
이 섹션에서는 이러한 문제들을 해결하고, 안전하고 정확하며 이식성 있는 시그널 핸들러를 작성하기 위한 기본 지침을 제공합니다.
안전한 시그널 핸들링 (Safe Signal Handling)
시그널 핸들러가 까다로운 주된 이유는 메인 프로그램 및 다른 핸들러와 동시적으로 실행될 수 있기 때문입니다. 만약 핸들러와 메인 프로그램이 동일한 전역 자료구조에 동시에 접근하면, 그 결과는 예측 불가능하며 종종 치명적인 오류로 이어질 수 있습니다.
이러한 지침을 무시하면, 대부분의 경우에는 올바르게 작동하지만 아주 가끔 예측 불가능하고 재현할 수 없는 방식으로 실패하는 미묘한 동시성 오류가 발생할 위험이 있습니다. 이런 오류는 디버깅하기가 극도로 어렵습니다.
G0. 핸들러는 최대한 단순하게 유지하라
핸들러는 가능한 한 작고 단순하게 만드는 것이 가장 안전합니다. 예를 들어, 핸들러는 전역 플래그(global flag)만 설정하고 즉시 반환하고, 실제 시그널 처리는 주기적으로 플래그를 확인하는 메인 프로그램이 담당하도록 하는 것이 좋습니다.
G1. 비동기-시그널-안전(Async-Signal-Safe) 함수만 호출하라


시그널 핸들러 내에서는 비동기-시그널-안전 함수만 호출해야 합니다. 안전한 함수는 재진입 가능(reentrant)하거나 시그널 핸들러에 의해 중단되지 않는 속성을 가집니다.
- 주의:
printf,sprintf,malloc,exit와 같이 널리 쓰이는 많은 함수들은 안전하지 않습니다. - 해결책:
- 핸들러에서 안전하게 출력하려면
write시스템 콜을 직접 사용해야 합니다. CSAPP 라이브러리는 이를 위해 Sio (Safe I/O) 패키지를 제공합니다. (sio_puts,sio_putl) - 프로세스를 종료할 때는
exit대신 안전한 버전인_exit를 사용해야 합니다.
- 핸들러에서 안전하게 출력하려면
G2. errno를 저장하고 복원하라
많은 비동기-시그널-안전 함수들은 오류 발생 시 errno 전역 변수를 설정합니다. 핸들러 내에서 이런 함수를 호출하면 메인 프로그램의 errno 값에 영향을 줄 수 있습니다.
- 해결책: 핸들러가 반환될 가능성이 있다면, 핸들러 진입 시
errno값을 지역 변수에 저장하고, 핸들러가 반환하기 직전에 원래 값으로 복원해야 합니다.
G3. 공유 전역 자료구조 접근 시 모든 시그널을 블록하라
핸들러가 메인 프로그램이나 다른 핸들러와 전역 자료구조를 공유한다면, 해당 자료구조에 접근하는 동안에는 모든 시그널을 일시적으로 블록해야 합니다. 이는 여러 명령어에 걸쳐 자료구조를 수정하는 도중에 핸들러가 끼어들어 데이터가 깨지는 상태(inconsistent state)를 방지합니다.
G4. 전역 변수는 volatile로 선언하라
최적화 컴파일러는 메인 프로그램에서 값이 변하지 않는 것처럼 보이는 전역 변수를 레지스터에 캐싱할 수 있습니다. 이렇게 되면 메인 프로그램은 핸들러가 수정한 최신 값을 메모리에서 읽지 못하게 됩니다.
- 해결책: 변수를
volatile키워드와 함께 선언하면(volatile int g;), 컴파일러에게 해당 변수를 캐싱하지 말고 매번 메모리에서 직접 읽도록 강제할 수 있습니다.
G5. 플래그는 sig_atomic_t로 선언하라
핸들러가 플래그를 설정하고 메인 프로그램이 이를 읽는 일반적인 설계에서, C는 sig_atomic_t라는 특별한 정수 타입을 제공합니다.
- 특징: 이 타입의 변수에 대한 읽기와 쓰기는 원자적(atomic)임이 보장됩니다. 즉, 단일 명령어로 처리되어 중간에 중단되지 않습니다.
- 주의: 원자성은 단일 읽기/쓰기에만 적용되며,
flag++와 같이 여러 명령어가 필요한 연산에는 적용되지 않습니다. - 선언 예시:
volatile sig_atomic_t flag;(volatile과 함께 사용하는 것이 일반적입니다.)
결론: 보수적인 접근법
위에 제시된 지침들은 보수적이며 항상 엄격하게 필요한 것은 아닐 수 있습니다. 하지만 반례를 증명하기는 매우 어렵기 때문에, 핸들러를 최대한 단순하게 유지하고, 안전 함수를 호출하며, errno를 저장/복원하고, 공유 데이터 접근을 보호하는 보수적인 접근법을 따르는 것이 권장됩니다.
정확한 시그널 처리
1. 핵심 문제: 시그널은 큐에 쌓이지 않는다
시그널의 비직관적인 측면 중 하나는 대기 중인(pending) 시그널이 큐에 저장되지 않는다는 것입니다.
- 동작 원리: 커널의
pending비트 벡터는 각 시그널 종류마다 단 하나의 비트만 가지고 있습니다. - 결과: 특정 타입의 대기 시그널은 최대 한 개만 존재할 수 있습니다. 만약
SIGCHLD핸들러가 실행 중이어서SIGCHLD시그널이 블록된 상태일 때, 두 번째SIGCHLD가 도착하면pending비트가 1이 됩니다. 그러나 세 번째SIGCHLD가 도착하면, 이미pending비트가 1이므로 이 시그널은 그냥 버려집니다. - 핵심 아이디어: 대기 시그널의 존재는 "적어도 하나의 시그널이 도착했다"는 사실만을 알려줄 뿐, 몇 개가 도착했는지는 알려주지 않습니다.
2. 잘못된 핸들링 예제 (signal1)
문제 상황: 부모 프로세스가 여러 자식 프로세스를 생성하고, 자식이 종료될 때마다 발생하는 SIGCHLD 시그널을 핸들러로 처리하여 자식을 수확(reap)하려고 합니다.
- 잘못된 가정:
SIGCHLD시그널 하나가 자식 하나의 종료에 해당한다고 가정하고, 핸들러가 호출될 때마다 자식을 한 명만 수확(wait)합니다.

- 실패 시나리오:
- 첫 번째 자식이 종료되고,
SIGCHLD시그널이 부모에게 전달되어 핸들러가 실행됩니다. - 핸들러가 실행되는 동안
SIGCHLD시그널은 암묵적으로 블록됩니다. - 두 번째 자식이 종료됩니다.
SIGCHLD시그널이 전달되지만 블록되어pending상태가 됩니다. - 세 번째 자식이 종료됩니다. 또 다른
SIGCHLD가 전달되지만, 이미 같은 종류의 시그널이pending상태이므로 이 시그널은 버려집니다. - 첫 번째 핸들러가 종료되면, 커널은
pending상태의 시그널을 처리하기 위해 핸들러를 두 번째로 실행합니다. - 두 번째 핸들러가 종료된 후, 더 이상
pending상태인SIGCHLD는 없습니다. 세 번째 자식의 종료에 대한 정보는 영원히 사라집니다.
- 첫 번째 자식이 종료되고,
- 결과: 자식 3개가 종료되었지만 핸들러는 2번만 호출되어 2개의 자식만 수확하고, 나머지 1개는 좀비(zombie) 프로세스로 남게 됩니다.
- 교훈: 시그널은 다른 프로세스에서 발생한 이벤트의 횟수를 세는 용도로 사용할 수 없습니다.
3. 올바른 해결책 (signal2)
이 문제를 해결하려면, SIGCHLD 핸들러가 호출될 때마다 수확 가능한 모든 좀비 자식을 수확하도록 수정해야 합니다.

- 올바른 설계: 핸들러 내부에 반복문을 사용하여, 더 이상 수확할 좀비 자식이 없을 때까지
wait(또는waitpid) 함수를 계속 호출해야 합니다. - 결과: 이 방식을 사용하면, 여러 자식이 거의 동시에 종료되어
SIGCHLD시그널 일부가 버려지더라도, 한 번의 핸들러 실행으로 모든 좀비 자식을 깨끗하게 정리할 수 있습니다.
호환성 시그널 핸들링 (Portable Signal Handling)
Unix 시그널 핸들링의 또 다른 까다로운 점은 시스템마다 시그널을 처리하는 방식(semantics)이 다르다는 것입니다. 이로 인해 한 시스템에서 잘 동작하는 코드가 다른 시스템에서는 오작동할 수 있습니다.
1. 시그널 핸들링의 이식성 문제
주요 차이점은 다음과 같습니다.
signal함수의 동작 방식 차이:- 일부 구형 Unix 시스템에서는, 특정 시그널
k에 대한 핸들러가 실행되고 나면 해당 시그널에 대한 처리 방식이 기본값으로 다시 복원됩니다. - 이런 시스템에서는 핸들러가 실행될 때마다 매번
signal()함수를 다시 호출하여 핸들러를 재설치해야 합니다.
- 일부 구형 Unix 시스템에서는, 특정 시그널
- 시스템 콜 중단 문제:
read,wait,accept와 같이 오랫동안 프로세스를 블록시킬 수 있는 시스템 콜을 느린 시스템 콜(slow system calls)이라고 합니다.- 일부 구형 Unix 시스템에서는, 이런 느린 시스템 콜이 시그널 핸들러에 의해 중단되면 핸들러가 반환된 후에도 시스템 콜이 재개되지 않습니다. 대신, 즉시 오류를 반환하며
errno를EINTR로 설정합니다. - 이런 시스템에서는 프로그래머가 중단된 시스템 콜을 수동으로 재시작하는 코드를 직접 포함해야 합니다.
2. 해결책: sigaction 함수와 Signal 래퍼
이러한 이식성 문제를 해결하기 위해, POSIX 표준은 sigaction 함수를 정의합니다. 이 함수를 사용하면 핸들러를 설치할 때 원하는 시그널 처리 방식을 명확하게 지정할 수 있습니다.
int sigaction(int signum, struct sigaction *act, struct sigaction *oldact);
하지만 sigaction 함수는 복잡한 구조체를 직접 설정해야 해서 다루기 어렵습니다. 더 나은 접근법은 sigaction을 대신 호출해주는 Signal이라는 래퍼 함수(wrapper function)를 사용하는 것입니다. (CSAPP 라이브러리에 포함)

3. Signal 래퍼 함수의 동작 방식
Signal 래퍼 함수는 다음과 같이 예측 가능하고 이식성 있는 방식으로 핸들러를 설치해 줍니다.
- 핸들러가 현재 처리 중인 타입의 시그널만 블록됩니다.
- 모든 시그널 구현과 마찬가지로, 시그널은 큐에 쌓이지 않습니다.
- 중단된 시스템 콜은 가능한 경우 자동으로 재시작됩니다. (
EINTR문제를 해결) - 일단 핸들러가 설치되면,
Signal함수가SIG_IGN이나SIG_DFL인자와 함께 다시 호출되기 전까지는 계속 설치된 상태를 유지합니다. (핸들러를 재설치할 필요 없음)
8.5.6 동시성 버그를 피하기 위한 흐름 동기화
메인 프로그램과 시그널 핸들러 같은 동시성 흐름(concurrent flows)이 동일한 전역 변수를 공유할 때 발생하는 경쟁 상태(Race Condition)라는 심각한 버그와 그 해결책을 설명합니다.
1. 문제 상황: 쉘의 작업 목록 관리
Unix 쉘과 유사한 프로그램을 예로 들어, 부모 프로세스가 전역 작업 목록(job list)을 사용하여 자식 프로세스를 관리하는 상황을 가정합니다.
addjob: 부모는fork로 자식을 생성한 후, 이 함수를 호출하여 작업 목록에 자식을 추가합니다.deletejob: 자식이 종료되어SIGCHLD시그널을 받으면, 핸들러 내에서 이 함수를 호출하여 작업 목록에서 자식을 제거합니다.
이 코드는 겉보기에 문제가 없어 보이지만, 실행 순서에 따라 치명적인 버그가 발생할 수 있습니다.
2. 경쟁 상태 (Race Condition) 발생 시나리오
다음과 같은 최악의 실행 순서(interleaving)가 가능합니다.

- 부모가
fork를 호출하고, 커널은 부모 대신 새로 생성된 자식을 먼저 실행시킵니다. - 부모가 다시 실행될 기회를 얻기 전에, 자식은 실행을 마치고 종료되어 좀비가 됩니다. 이로 인해 커널은 부모에게
SIGCHLD시그널을 전달합니다. - 나중에 부모가 실행될 차례가 되었을 때, 커널은 부모의 코드를 실행하기에 앞서 대기 중인
SIGCHLD시그널을 먼저 처리하도록 시그널 핸들러를 실행시킵니다. - 핸들러는
deletejob을 호출하지만, 아직 부모가 자식을 목록에 추가하지 않았기 때문에 아무런 일도 일어나지 않습니다. - 핸들러가 종료된 후, 부모는 비로소
fork함수에서 반환되어addjob을 호출합니다. 이로 인해 이미 존재하지 않는 자식이 작업 목록에 잘못 추가됩니다.
이것이 바로 addjob과 deletejob 사이의 경쟁 상태입니다. addjob이 먼저 실행되면(경쟁에서 이기면) 결과는 올바르지만, deletejob이 먼저 호출되면(경쟁에서 지면) 결과는 틀리게 됩니다.
3. 해결책: 시그널 블로킹을 통한 동기화
이 경쟁 상태는 시그널 블로킹을 통해 해결할 수 있습니다.

fork를 호출하기 전에,SIGCHLD시그널을 블록(block)합니다.fork를 호출하고addjob까지 실행을 마친 후에,SIGCHLD시그널을 언블록(unblock)합니다.
이렇게 하면 addjob이 항상 SIGCHLD 핸들러의 deletejob보다 먼저 실행되는 것이 보장됩니다. 시그널이 블록된 동안 도착한 SIGCHLD는 addjob이 끝난 뒤 언블록하는 순간 처리되기 때문입니다.
주의: 자식 프로세스는 부모의 블록된 시그널 집합을 상속받으므로, 자식은 execve를 호출하기 전에 반드시 블록된 SIGCHLD 시그널을 언블록 해주어야 합니다.
명시적으로 시그널 기다리기 (sigsuspend)
메인 프로그램이 특정 시그널 핸들러가 실행되기를 효율적이고 안전하게 기다려야 할 때가 있습니다. 단순한 방법들은 리소스를 낭비하거나 심각한 버그를 유발할 수 있으므로, sigsuspend 함수를 사용해야 합니다.
1. 문제 상황: 잘못된 대기 방법들
쉘이 자식 프로세스의 종료를 기다리는 상황을 가정할 때, 다음과 같은 잘못된 방법들을 사용할 수 있습니다.
가. 무한 루프 (Spin Loop) - 리소스 낭비
전역 변수 pid를 핸들러가 설정할 때까지 메인 루프가 계속 확인하는 방식입니다.
while (!pid)
; /* Spin loop */- 문제점: CPU 리소스를 극심하게 낭비합니다. 프로세스가 유용한 일 없이 CPU를 100% 사용합니다.
나. pause 함수 사용 - 경쟁 상태 발생
루프 안에 pause 함수를 넣어 리소스 낭비를 줄이려는 시도입니다.
while (!pid) /* Race! */
pause();- 문제점:
while조건문 확인과pause()호출 사이의 틈 때문에 심각한 경쟁 상태(Race Condition)가 발생합니다. 조건 확인 직후 시그널이 도착하면,pause는 영원히 잠들게 될 수 있습니다.
다. sleep 함수 사용 - 비효율적
sleep 함수를 사용하여 일정 시간 대기하는 방법입니다.
while (!pid) /* Too slow! */
sleep(1);- 문제점: 비효율적이고 반응이 느립니다.
sleep호출 직후 시그널이 오면 불필요하게 오래 기다려야 합니다.
2. 올바른 해결책: sigsuspend 함수
이 문제를 해결하기 위한 올바른 방법은 sigsuspend를 사용하는 것입니다.
- 함수 원형:
#include <signal.h> int sigsuspend(const sigset_t *mask); - 동작 방식:
sigsuspend는 다음 두 가지 작업을 원자적(atomic)으로, 즉 중간에 절대 중단되지 않는 단일 연산으로 수행합니다.- 현재 프로세스의 블록된 시그널 집합을
mask로 일시적으로 교체합니다. - 시그널이 도착할 때까지 프로세스를 잠들게 합니다(suspend).
- 현재 프로세스의 블록된 시그널 집합을
핸들러가 실행되고 반환되면, sigsuspend도 반환되며 블록된 시그널 집합은 sigsuspend 호출 이전의 원래 상태로 자동 복원됩니다. 이 원자성은 pause의 경쟁 상태 문제를 원천적으로 제거합니다.
sigsuspend 사용법
올바른 대기 방식은 다음과 같습니다.
- 루프에 진입하기 전에 기다릴 시그널(
SIGCHLD)을 블록합니다. - 루프 안에서
sigsuspend를 호출하면서, 인자로 기다릴 시그널의 블록을 잠시 푸는 임시 마스크를 전달합니다. sigsuspend는 시그널이 올 때까지 프로세스를 효율적으로 잠재웁니다.- 시그널이 도착해 핸들러가 실행된 후,
sigsuspend가 반환되면 시그널은 다시 자동으로 블록됩니다. - 루프의 조건문이 거짓이 되어 루프를 안전하게 탈출합니다.
이 방식은 리소스를 낭비하지 않고, 경쟁 상태를 피하며, 효율적으로 시그널을 기다릴 수 있는 가장 올바른 방법입니다.
