
9.6 주소 변환 (Address Translation)
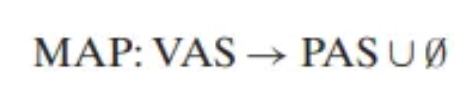
여기서 MAP(A)는 다음과 같습니다.
- 가상 주소 의 데이터가 PAS의 물리 주소 에 존재한다면:
- 가상 주소 의 데이터가 PAS의 물리 메모리에 존재하지 않는다면: (공집합)
MMU를 이용한 주소 변환
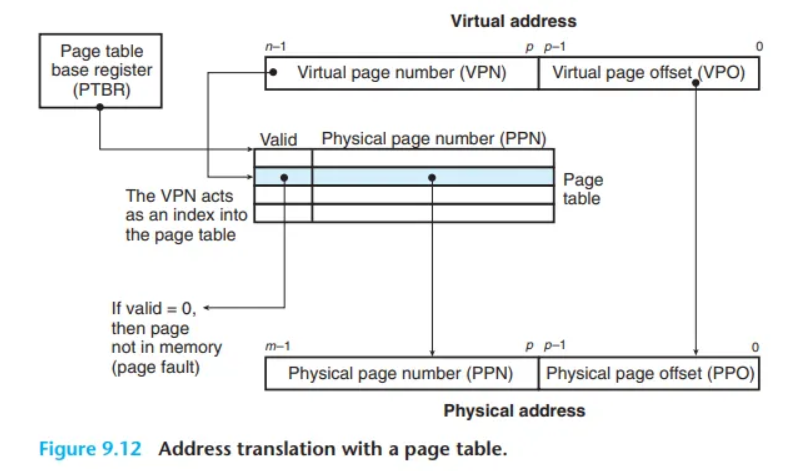
(CSAPP 그림 9.12 참조) MMU(메모리 관리 장치)는 페이지 테이블(page table)을 사용하여 이 매핑을 수행합니다. CPU의 제어 레지스터인 페이지 테이블 베이스 레지스터(PTBR, Page Table Base Register)는 현재 페이지 테이블의 시작 주소를 가리킵니다.
-bit 가상 주소는 두 가지 구성 요소를 가집니다.
- -bit의 가상 페이지 오프셋 (VPO, Virtual Page Offset)
- -bit의 가상 페이지 번호 (VPN, Virtual Page Number)
MMU는 이 VPN을 사용하여 적절한 PTE(Page Table Entry)를 선택합니다. 예를 들어, VPN 0은 PTE 0을, VPN 1은 PTE 1을 선택하는 식입니다.
결과적으로 얻게 되는 물리 주소는 페이지 테이블 엔트리(PTE)로부터 얻은 물리 페이지 번호(PPN, Physical Page Number)와 가상 주소로부터 얻은 가상 페이지 오프셋(VPO)을 연결(concatenation)하여 만들어집니다. 물리 페이지와 가상 페이지의 크기는 모두 바이트로 동일하므로, 물리 페이지 오프셋(PPO)은 가상 페이지 오프셋(VPO)과 동일합니다.
페이지 히트 (Page Hit)
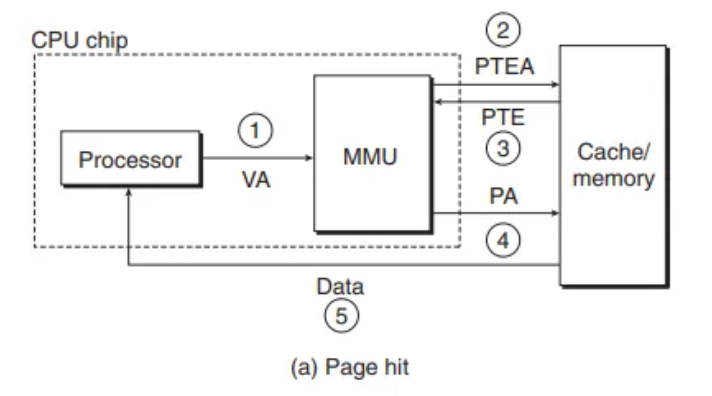
(CSAPP 그림 9.13(a) 참조) 페이지 히트가 발생했을 때 CPU 하드웨어가 수행하는 단계는 다음과 같습니다. 이 과정은 전적으로 하드웨어에 의해 처리됩니다.
- 1단계: 프로세서가 가상 주소를 생성하여 MMU로 보냅니다.
- 2단계: MMU는 PTE 주소를 생성하고, 이 주소를 캐시/메인 메모리에 요청합니다.
- 3단계: 캐시/메인 메모리는 PTE를 MMU로 반환합니다.
- 4단계: MMU는 물리 주소를 구성(construct)하여 캐시/메인 메모리로 보냅니다.
- 5단계: 캐시/메인 메모리는 요청된 데이터 워드(word)를 프로세서로 반환합니다.
페이지 폴트 (Page Fault)
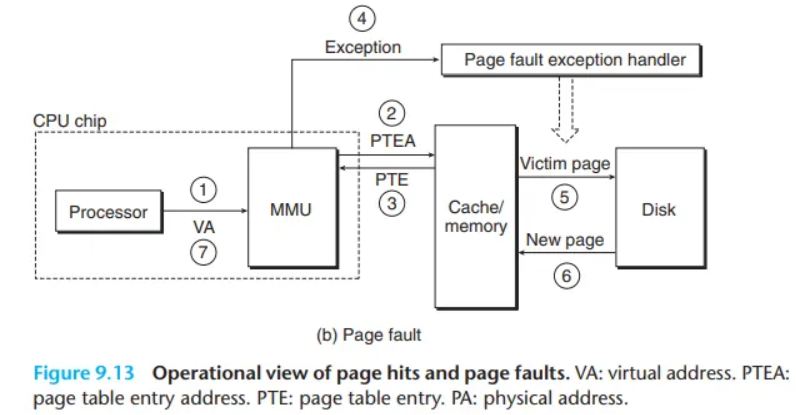
(CSAPP 그림 9.13(b) 참조) 페이지 히트와 달리, 페이지 폴트를 처리하는 것은 하드웨어와 운영체제 커널 간의 협력이 필요합니다.
- 1~3단계: 페이지 히트의 1~3단계와 동일합니다.
- 4단계: PTE의 유효 비트(valid bit)가 0이므로, MMU는 예외(exception)를 발생시킵니다. 이로 인해 CPU의 제어권이 운영체제 커널 내의 페이지 폴트 예외 핸들러(page fault exception handler)로 넘어갑니다.
- 5단계: 폴트 핸들러는 물리 메모리에서 희생 페이지(victim page)를 식별하고, 만약 이 페이지가 수정되었다면 디스크로 페이지 아웃(page out)시킵니다.
- 6단계: 폴트 핸들러는 새로운 페이지를 메모리로 페이지 인(page in)하고, 메모리에 있는 PTE를 업데이트합니다.
- 7단계: 폴트 핸들러는 원래의 프로세스로 복귀하며, 이로 인해 폴트를 발생시켰던 명령어가 재시작(restarted)됩니다. CPU는 문제가 되었던 가상 주소를 MMU로 다시 보냅니다. 이제 해당 가상 페이지가 물리 메모리에 캐시되었으므로 페이지 히트가 발생하고, MMU가 페이지 히트 절차를 수행한 후 메인 메모리는 요청된 워드를 프로세서로 반환합니다.
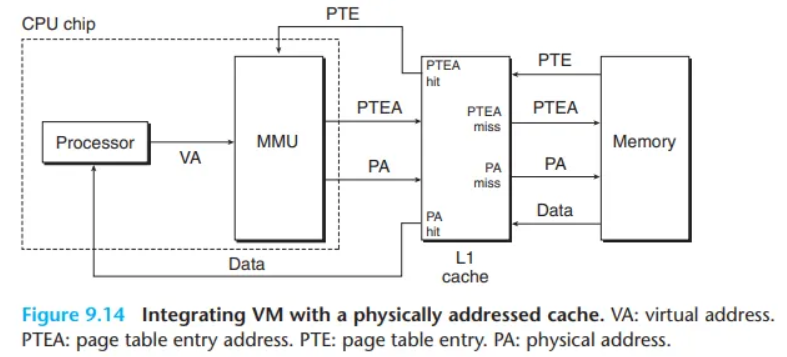
9.6.1 캐시와 가상 메모리의 통합 (Integrating Caches and VM)
SRAM 캐시에 접근하는 방식에는 가상 주소와 물리 주소 방식이 있으며, 대부분의 시스템은 물리 주소(Physical Address) 방식을 채택합니다.
- 핵심 동작 원리
- CPU가 주소를 요청하면, 주소 변환(MMU, TLB)이 캐시 조회(lookup)보다 먼저 일어납니다.
- 즉, 가상 주소가 물리 주소로 변환된 후에, 그 물리 주소를 사용하여 캐시를 확인합니다.
- 물리 주소 방식의 장점
- 프로세스 간 공유 용이: 여러 프로세스가 캐시 메모리를 공유하거나, 동일한 데이터를 가리키는 블록을 공유하기 간단합니다.
- 보호 문제 단순화: 데이터 접근 권한 확인은 주소 변환 과정에서 이미 끝나므로, 캐시는 복잡한 보호(protection) 문제를 신경 쓸 필요가 없습니다.
- 참고 사항
- 주소 변환에 사용되는 페이지 테이블 엔트리(PTE) 자체도 일반 데이터처럼 캐시에 저장될 수 있습니다.
- 메인 아이디어는 주소 번역이 캐시 참조 이전에 일어난다는 점입니다.
9.6.2 TLB를 사용한 주소 번역 속도의 개선
TLB (Translation Lookaside Buffer)
주소 변환 과정의 속도를 높이기 위해 사용하는 PTE(페이지 테이블 엔트리) 전용 고속 캐시입니다. MMU 내부에 위치합니다.
- 목표: CPU가 가상 주소를 물리 주소로 변환할 때마다 페이지 테이블을 보기 위해 L1 캐시나 메인 메모리까지 접근하는 시간 비용을 줄이는 것입니다.

- 동작 방식: 가상 주소의 VPN(가상 페이지 번호)을 태그(Tag)와 인덱스(Index)로 사용하여 TLB에서 원하는 PTE를 빠르게 찾아냅니다.
TLB 히트 (TLB Hit)
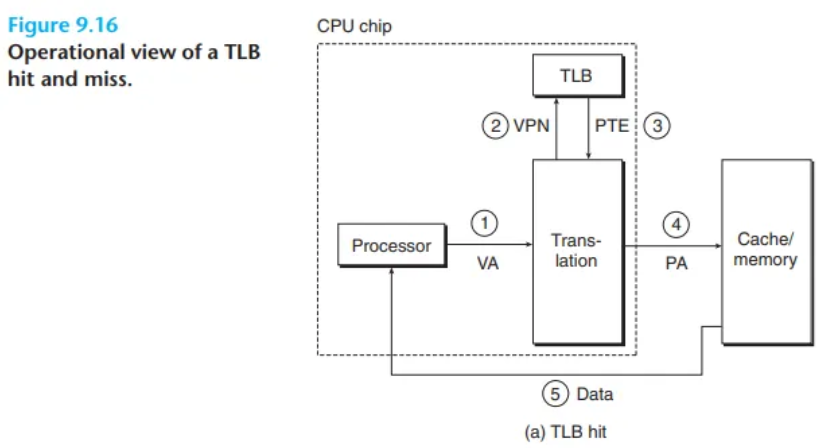
필요한 PTE가 TLB에 존재하는 경우로, 가장 일반적이고 빠른 시나리오입니다.
- 핵심: 모든 주소 변환 과정이 MMU 칩 내에서 매우 빠르게 완료됩니다.
- 동작 순서:
- CPU가 가상 주소를 생성합니다.
- MMU가 TLB에서 즉시 PTE를 가져옵니다.
- 가져온 PTE로 물리 주소를 만들고, 이를 캐시/메인 메모리로 보냅니다.
- 메모리가 해당 데이터를 CPU로 반환합니다.
TLB 미스 (TLB Miss)
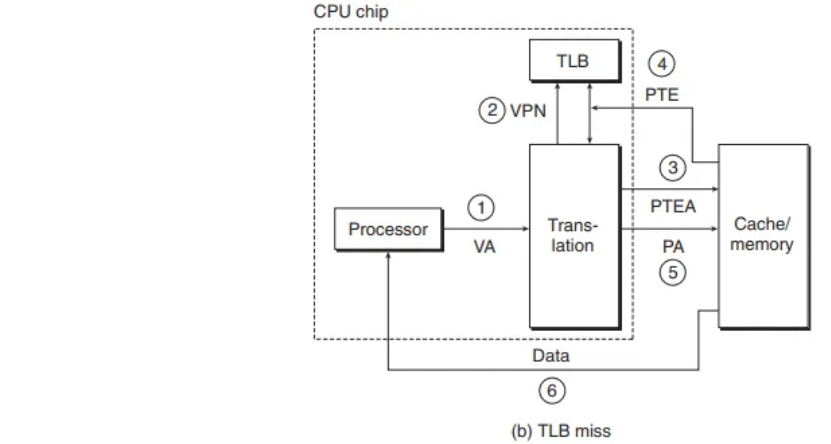
필요한 PTE가 TLB에 존재하지 않는 경우입니다.
- 동작 순서:
- MMU는 더 느린 L1 캐시나 메인 메모리에서 PTE를 가져와야 합니다.
- 가져온 PTE를 TLB에 새로 저장합니다. (이 과정에서 기존의 다른 PTE가 교체될 수 있습니다.)
- PTE를 확보했으므로, 이후 과정은 TLB 히트와 동일하게 진행됩니다.
9.6.3 다중 레벨 페이지 테이블 (Multi-Level Page Tables)
단일 페이지 테이블 방식은 주소 공간이 클 경우 (예: 32-bit, 64-bit) 심각한 메모리 낭비를 초래합니다. 프로그램이 실제 사용하는 메모리는 일부에 불과함에도, 전체 주소 공간을 매핑하기 위한 거대한 페이지 테이블(수 MB ~ 수 GB)을 항상 메모리에 유지해야 하기 때문입니다.
해결책: 페이지 테이블의 계층화
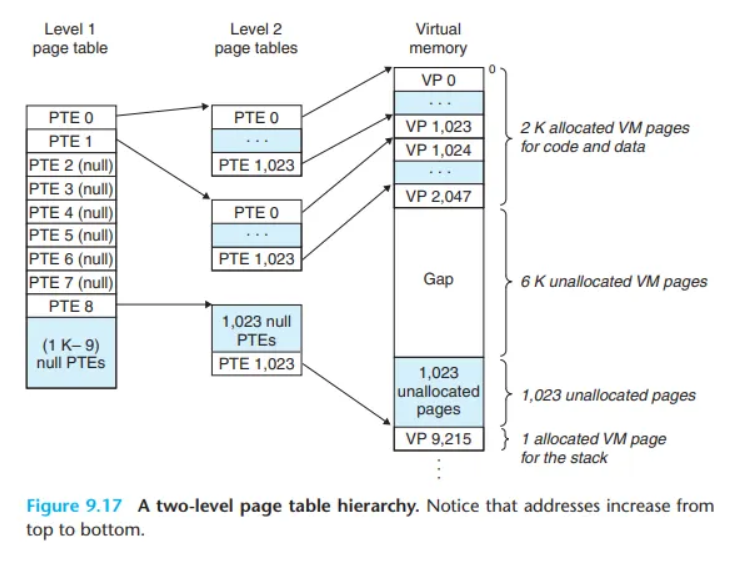
이 문제를 해결하기 위해 페이지 테이블을 여러 계층으로 나누는 다중 레벨 페이지 테이블 방식을 사용합니다. (예시: 2-레벨 페이지 테이블)
- Level 1 페이지 테이블:
- 전체 가상 주소 공간을 큰 덩어리(chunk) (예: 4MB) 단위로 나눕니다.
- 각 PTE는 이 덩어리 하나를 담당하며, 해당 덩어리 내에 할당된 페이지가 하나라도 있으면 Level 2 페이지 테이블의 시작 주소를 가리킵니다.
- 만약 덩어리 전체가 사용되지 않으면(unallocated), Level 1 PTE는 null이 됩니다.
- Level 2 페이지 테이블:
- Level 1 PTE가 가리키는 테이블입니다.
- 각 PTE는 최종적으로 하나의 물리 페이지 프레임 번호(PPN)를 가리킵니다. 이는 단일 레벨 페이지 테이블의 PTE와 역할이 같습니다.
다중 레벨 페이징의 장점
이 방식은 두 가지 방법으로 메모리 요구량을 줄입니다.
- Level 2 테이블 생략: Level 1 PTE가 null이면, 그에 해당하는 Level 2 페이지 테이블은 아예 생성할 필요가 없습니다. 대부분의 프로그램은 주소 공간의 많은 부분을 비워두므로 상당한 메모리를 절약할 수 있습니다.
- 페이징 인/아웃: Level 1 테이블만 항상 메인 메모리에 유지하면 됩니다. Level 2 테이블들은 필요할 때만 메모리로 로드(page-in)하고, 필요 없으면 디스크로 내릴 수(page-out) 있어 메인 메모리에 대한 부담을 줄입니다.
주소 변환 과정 및 성능
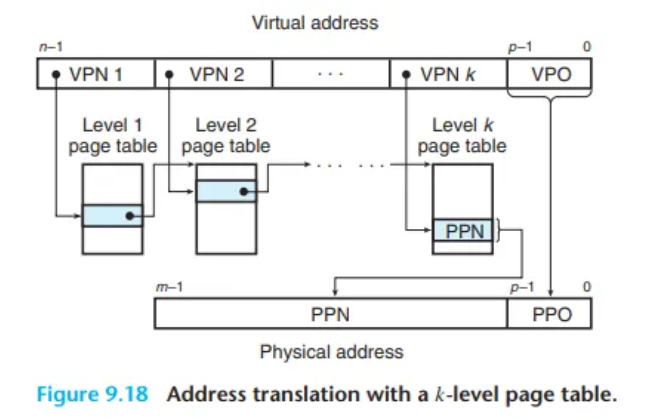
- 변환 과정: -레벨 테이블에서 가상 주소는 개의 VPN과 1개의 VPO로 나뉩니다. MMU는 Level 1 테이블부터 Level 테이블까지 총 개의 PTE를 순차적으로 접근해야 최종 물리 주소를 얻을 수 있습니다.
- 성능 문제와 해결: 언뜻 보면 메모리를 번 접근해야 해서 매우 느릴 것 같지만, TLB가 이 문제를 해결합니다. TLB는 각 레벨의 페이지 테이블 PTE들을 모두 캐싱하므로, 실제로는 다중 레벨 페이지 테이블의 주소 변환 속도가 단일 레벨 방식에 비해 크게 느리지 않습니다.
9.6.4 종합: end-to-end(종단) 주소 변환
지금까지 배운 TLB, 페이지 테이블, L1 캐시를 모두 사용하는 가상 시스템의 전체 주소 변환 과정을 구체적인 예시를 통해 살펴봅니다.
시스템 기본 가정
- VA (가상 주소): 14 bits (n=14)
- PA (물리 주소): 12 bits (m=12)
- 페이지 크기: 64 Bytes (P=64, 즉 )
- TLB: 4-way set associative, 총 16개 엔트리 (즉, 4개 세트)
- L1 d-cache: 물리 주소 방식(Physically addressed), Direct-mapped, 라인 크기 4 Bytes, 총 16개 세트
주소 필드 분해
위 가정에 따라 각 주소는 다음과 같이 나뉘어 사용됩니다.
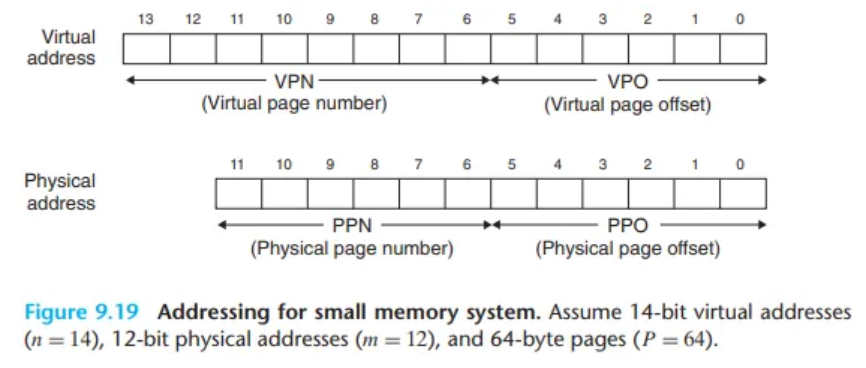

- 가상 주소 (VA, 14 bits)
- VPO (가상 페이지 오프셋): 하위 6 bits (페이지 크기 )
- VPN (가상 페이지 번호): 상위 8 bits (14 - 6)
- 물리 주소 (PA, 12 bits)
- PPO (물리 페이지 오프셋): 하위 6 bits (VPO와 동일)
- PPN (물리 페이지 번호): 상위 6 bits (12 - 6)
- TLB 조회 (VPN 사용)
- TLB는 4개 세트()를 가짐
- TLBI (TLB 인덱스): VPN의 하위 2 bits
- TLBT (TLB 태그): VPN의 상위 6 bits (8 - 2)
- 캐시 조회 (PA 사용)
- 캐시는 16개 세트(), 라인 당 4 바이트()
- CO (캐시 오프셋): PA의 하위 2 bits
- CI (캐시 인덱스): PA의 다음 4 bits
- CT (캐시 태그): PA의 상위 6 bits (12 - 4 - 2)
변환 예시: VA 0x03D4 읽기
CPU가 가상 주소 0x03D4에 있는 1바이트를 읽으려 할 때의 과정입니다.
1. 가상 주소 분석
- VA:
0x03D4 - VPN (상위 8 bits):
0x0F - VPO (하위 6 bits):
0x14
2. TLB 조회 (주소 변환)
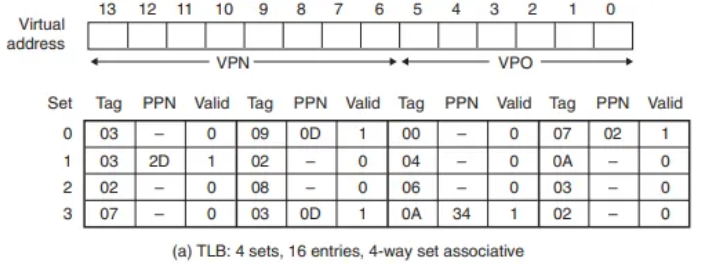
- MMU가 VPN(
0x0F)을 TLB로 보냅니다. - VPN(
0x0F)을 분해: TLB 인덱스 =0x3, TLB 태그 =0x3
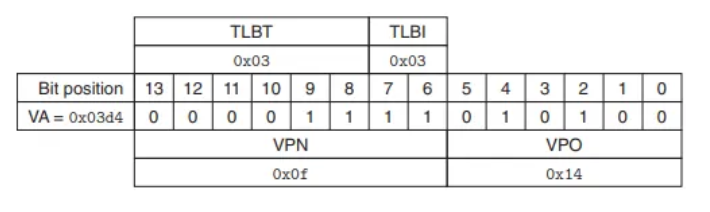
- 결과: TLB Hit
- TLB의
Set 0x3을 확인합니다. - 해당 세트의 두 번째 엔트리에서 태그(
0x3)가 일치하고 유효 비트(Valid)가 켜져 있는 것을 발견합니다. - 캐시된 PPN(
0x0D)을 즉시 MMU로 반환합니다.
- TLB의
3. 물리 주소(PA) 생성
- MMU가 TLB로부터 받은 PPN과 원래의 VPO를 결합합니다.
- PPN (
0x0D) + VPO (0x14) PA0x354
4. L1 캐시 조회
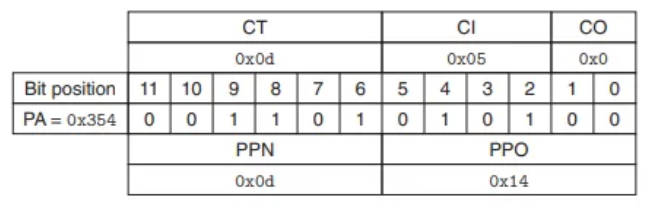
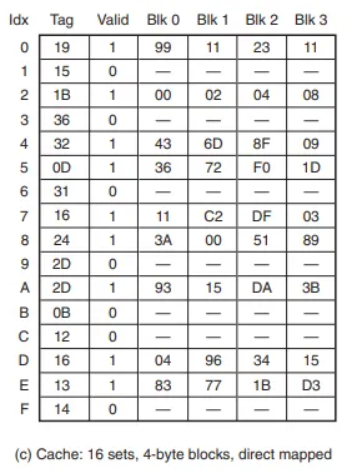
- 이제 MMU가 물리 주소
0x354를 L1 캐시로 보냅니다. - PA(
0x354)를 분해: CT =0x0D, CI =0x5, CO =0x0 - 결과: Cache Hit
- 캐시의
Set 0x5로 접근합니다. - 해당 세트의 태그가 CT(
0x0D)와 일치하는 것을 확인합니다.
- 캐시의
5. 데이터 반환
- 캐시 히트가 발생했으므로, 해당 캐시 라인에서 CO(
0x0) 위치의 데이터를 읽습니다. - 데이터
0x36을 읽어 CPU로 최종 반환합니다.
기타 발생 가능한 경로
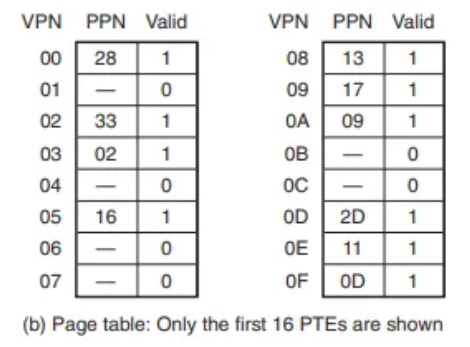
- TLB Miss: MMU가 메인 메모리의 페이지 테이블에서 PTE를 직접 가져와야 합니다.
- Page Fault: TLB 미스 후 가져온 PTE가 유효하지 않으면(invalid), 커널이 디스크에서 페이지를 가져옵니다.
- Cache Miss: PTE는 유효했지만, 물리 주소에 해당하는 데이터가 L1 캐시에 없으면 메인 메모리에서 데이터를 가져옵니다.
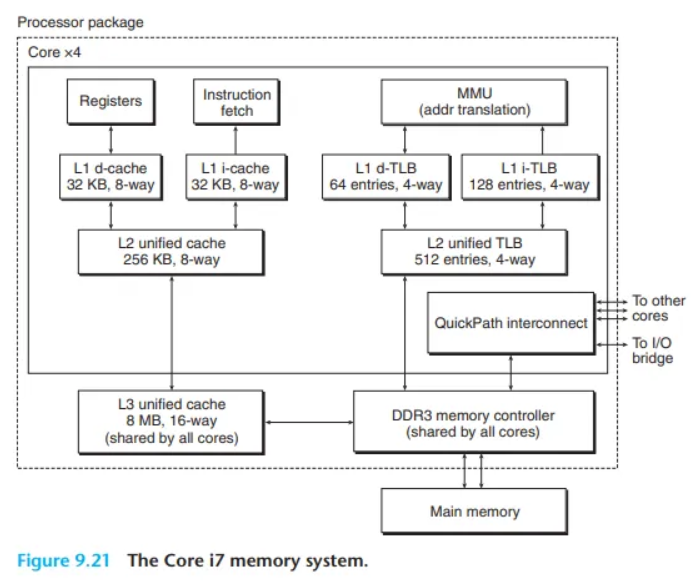
9.7 사례 연구: Intel Core i7 / Linux 메모리 시스템
Intel Core i7(Haswell 아키텍처)과 리눅스 시스템의 실제 메모리 시스템 구성 요소입니다.
주소 공간 (Address Spaces)
- 가상 주소 공간 (Virtual): 48-bit (256 TB 지원)
- 물리 주소 공간 (Physical): 52-bit (4 PB 지원)
- 호환성: 32-bit (4 GB) 모드도 지원합니다.
프로세서 칩 구성
- 4개의 코어 (Cores)
- 모든 코어가 공유하는 대용량 L3 캐시
- DDR3 메모리 컨트롤러
코어(Core)별 구성 요소
- 계층화된 TLB (TLB Hierarchy)
- 계층화된 데이터 및 명령어 캐시 (L1, L2)
- 다른 코어와 직접 통신하기 위한 고속 QuickPath 링크
컴포넌트 상세 스펙
- 페이지 크기 (Page Size)
- 시스템 설정 시 4KB 또는 4MB로 구성 가능합니다.
- 리눅스(Linux)는 4KB 페이지를 사용합니다.
- TLB (Translation Lookaside Buffers)
- 주소 방식: 가상 주소 방식 (Virtually Addressed)
- 연관성: 4-way Set Associative
- L1, L2, L3 캐시 (Caches)
- 주소 방식: 물리 주소 방식 (Physically Addressed)
- 블록 크기 (Block Size): 64 Bytes (L1, L2, L3 공통)
- 연관성 (Associativity):
- L1 & L2: 8-way Set Associative
- L3: 16-way Set Associative
9.7.1 Core i7 주소 변환 (Address Translation)
Core i7의 MMU가 가상 주소를 물리 주소로 변환하는 전체 과정을 요약합니다.
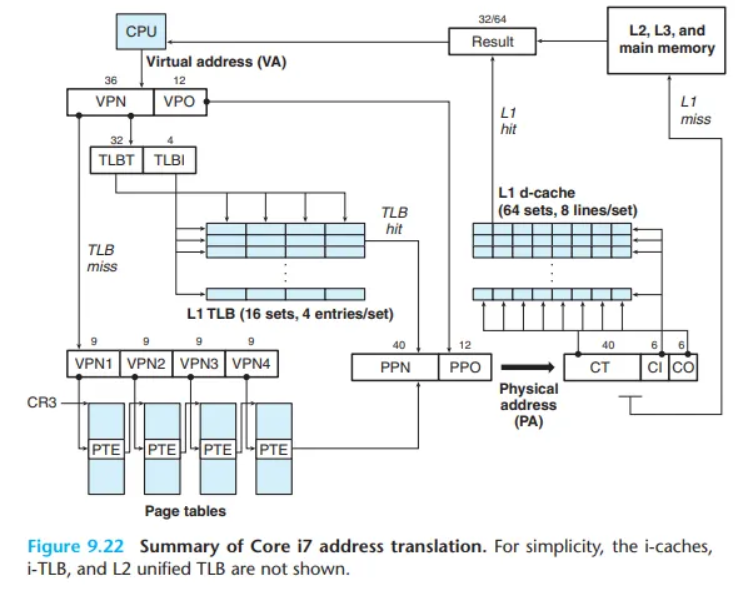
4-레벨 페이지 테이블 계층 구조
Core i7은 4-레벨 페이지 테이블 계층 구조를 사용하며, 각 프로세스는 자신만의 독립적인 페이지 테이블 계층을 가집니다.
- CR3 제어 레지스터: 현재 실행 중인 프로세스의 Level 1 (L1) 페이지 테이블의 시작 물리 주소를 저장합니다. 이 값은 프로세스 컨텍스트(context)의 일부이며, 컨텍스트 스위치(context switch) 시 함께 복원됩니다.
- 리눅스 환경: 리눅스는 4KB 페이지를 사용하며, 할당된 페이지와 연관된 모든 레벨의 페이지 테이블들은 항상 메인 메모리에 상주(memory-resident)합니다.
페이지 테이블 엔트리 (PTE) 구조
모든 페이지 테이블(L1~L4)과 데이터 페이지는 4KB 크기로 정렬되어야 합니다.
- L1, L2, L3 PTE:
P=1(Present 비트, 리눅스에서는 항상 1)일 때, 다음 레벨 페이지 테이블(L2, L3, L4)의 시작 주소를 가리키는 40-bit 물리 페이지 번호(PPN)를 포함합니다. - L4 PTE:
P=1일 때, 데이터가 저장된 최종 물리 페이지의 시작 주소를 가리키는 40-bit PPN을 포함합니다.
PTE 내의 주요 비트
PTE는 주소(PPN) 외에 다음과 같은 중요한 제어 비트들을 포함합니다.
1. 접근 제어 비트 (Permission Bits)
- R/W (읽기/쓰기): 페이지를 읽기/쓰기 또는 읽기 전용으로 설정합니다.
- U/S (사용자/슈퍼바이저): 사용자 모드(user mode)에서 이 페이지에 접근 가능한지 여부를 결정합니다. (커널 코드 및 데이터 보호용)
- XD (실행 금지): 특정 메모리 페이지에서의 명령어 실행(fetch)을 금지시킵니다. 이는 버퍼 오버플로우 공격을 방지하는 데 사용되는 중요한 보안 기능입니다.
2. 커널 사용 비트 (MMU가 자동 설정)
- A (접근 비트, Reference bit): 페이지가 (읽기 또는 쓰기) 접근될 때마다 MMU가 설정합니다. 커널이 페이지 교체 알고리즘(예: LRU)을 구현하는 데 사용합니다.
- D (Dirty 비트): 페이지에 쓰기(write)가 발생할 때마다 MMU가 설정합니다. 커널이 이 페이지를 디스크로 내릴 때(희생 페이지로 선택 시), 이 비트를 보고 디스크에 다시 써야 할지(write-back) 결정합니다.
주소 변환 전체 과정
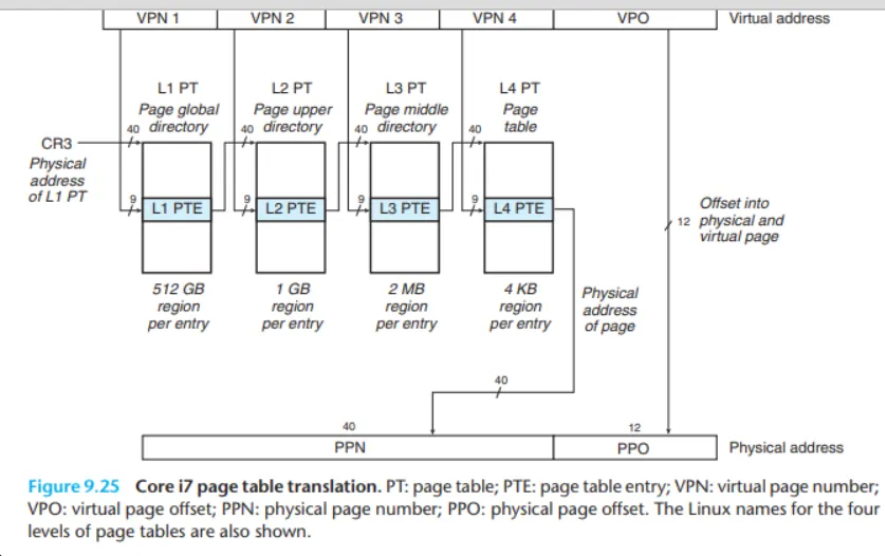
(Core i7의 48-bit 가상 주소 중 12-bit VPO를 제외한) 상위 36-bit VPN은 4개의 9-bit 청크로 나뉩니다.
- 각 9-bit 청크는 각 레벨 페이지 테이블(L1~L4)의 오프셋(offset)으로 사용됩니다.
- 변환 순서:
- CR3 레지스터가 L1 테이블의 시작 주소를 가리킵니다.
- VPN 1 (첫 9-bit)을 L1 테이블의 오프셋으로 사용 L2 테이블의 주소를 얻습니다.
- VPN 2 (다음 9-bit)를 L2 테이블의 오프셋으로 사용 L3 테이블의 주소를 얻습니다.
- VPN 3 (다음 9-bit)를 L3 테이블의 오프셋으로 사용 L4 테이블의 주소를 얻습니다.
- VPN 4 (마지막 9-bit)를 L4 테이블의 오프셋으로 사용 최종 데이터 페이지의 PPN을 얻습니다.
- 이 PPN과 원래의 VPO를 결합하여 최종 물리 주소를 만듭니다.
9.7.2 리눅스 가상 메모리 시스템
프로세스별 가상 주소 공간
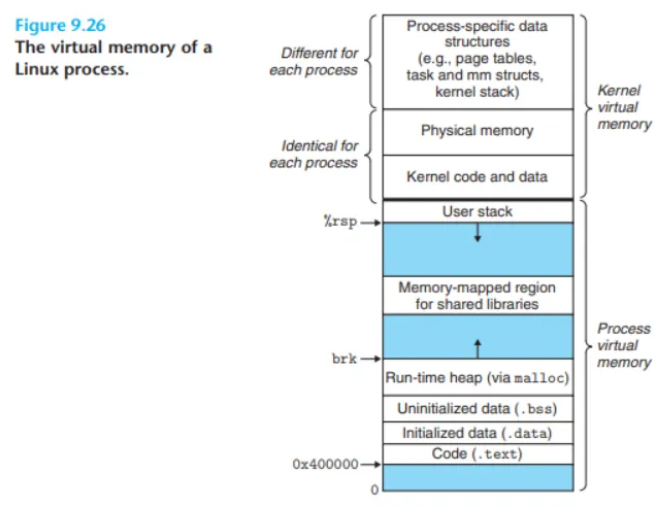
리눅스는 각 프로세스마다 (CSAPP 그림 9.26에서 보듯이) 익숙한 코드, 데이터, 힙, 공유 라이브러리, 스택 세그먼트로 구성된 별도의 가상 주소 공간을 유지 관리합니다.
커널 가상 메모리 (Kernel Virtual Memory)
사용자 스택 영역 위쪽에 위치하는 커널 가상 메모리는 커널의 코드와 데이터 구조를 포함하며, 그 영역은 크게 두 가지 유형으로 나뉩니다.
1. 모든 프로세스가 공유하는 영역
- 커널의 코드, 전역 데이터 구조(global data structures) 등은 모든 프로세스가 공유하는 물리 페이지에 매핑됩니다.
- 물리 메모리 직접 매핑: 리눅스는 시스템의 전체 DRAM 크기와 동일한 크기의 연속적인 가상 페이지 집합을, 그에 상응하는 연속적인 물리 페이지 집합에 직접 매핑합니다.
- 이유: 커널이 페이지 테이블에 접근하거나 특정 물리 메모리 주소에 매핑된 장치(device)에 대해 메모리 맵 I/O를 수행해야 할 때, 어떤 물리 메모리 위치든 편리하게 접근할 수 있도록 하기 위함입니다.
2. 프로세스별로 고유한 영역
- 커널 가상 메모리의 다른 영역들은 프로세스마다 서로 다른 데이터를 포함합니다.
- 예시:
- 해당 프로세스의 페이지 테이블
- 커널이 해당 프로세스의 컨텍스트에서 코드를 실행할 때 사용하는 커널 스택
- 해당 프로세스의 가상 주소 공간 구성을 추적하는 다양한 데이터 구조들
리눅스 가상 메모리 영역 (Linux Virtual Memory Areas)
리눅스는 가상 메모리를 '영역(Area)' (또는 세그먼트)의 집합으로 관리합니다.
- 영역(Area)의 정의:
- 특정 방식(예: 코드, 데이터, 스택)으로 서로 연관된 페이지들로 이루어진, 연속적인(contiguous) 가상 메모리 덩어리(chunk)입니다.
- 코드 세그먼트, 데이터 세그먼트, 힙, 공유 라이브러리, 사용자 스택이 모두 각각의 고유한 '영역'입니다.
- 영역(Area)의 중요성 (Gaps):
- 할당된 모든 가상 페이지는 반드시 어떤 '영역'에 속합니다.
- 어떤 '영역'에도 속하지 않는 가상 페이지는 "존재하지 않는(nonexisting)" 페이지로 간주되며, 프로세스가 참조할 수 없습니다.
- 이 '영역' 개념 덕분에 가상 주소 공간 사이에 공백(gaps)이 존재할 수 있습니다.
- 커널은 이 공백(존재하지 않는 페이지)을 관리할 필요가 없으므로, 메모리, 디스크, 커널 자원이 낭비되지 않습니다.
가상 메모리 관리를 위한 커널 자료구조
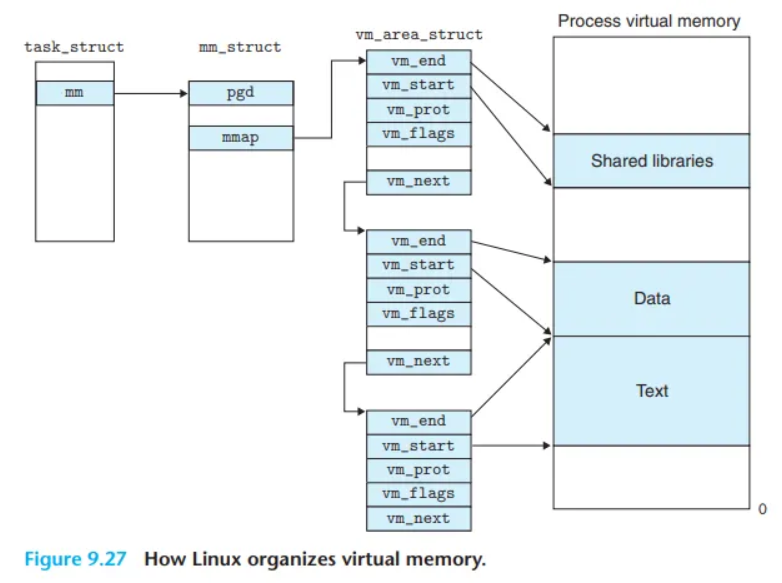
커널은 각 프로세스의 가상 메모리 '영역'들을 추적하기 위해 다음과 같은 자료구조를 사용합니다.
task_struct(작업 구조체)- 커널이 시스템의 각 프로세스마다 유지하는 최상위 구조체입니다.
- PID, 사용자 스택 포인터, 실행 파일 이름 등 프로세스 실행에 필요한 모든 정보를 포함합니다.
mm_struct(메모리 관리 구조체)task_struct내부에 있으며, 해당 프로세스의 가상 메모리 현재 상태를 나타냅니다.- 주요 필드:
pgd: Level 1 페이지 테이블(페이지 전역 디렉터리)의 시작 주소를 가리킵니다. (컨텍스트 스위치 시 이 값이 CR3 레지스터에 로드됩니다.)mmap:vm_area_struct들의 연결 리스트(linked list) 시작점을 가리킵니다.
vm_area_struct(영역 구조체)- 특정 '영역(Area)' 하나의 속성을 정의하는 구조체입니다. (
mmap을 통해 리스트로 연결됩니다.) - 주요 필드:
vm_start: 영역의 시작 가상 주소vm_end: 영역의 끝 가상 주소 (끝 주소 + 1)vm_prot: 해당 영역 내 모든 페이지의 읽기/쓰기/실행 권한 (Protection)vm_flags: 해당 영역의 페이지들이 공유(shared)되는지 사적(private)인지 등을 기술하는 플래그vm_next: 리스트에서 다음vm_area_struct를 가리키는 포인터
- 특정 '영역(Area)' 하나의 속성을 정의하는 구조체입니다. (
리눅스 페이지 폴트 예외 처리 (Linux Page Fault Exception Handling)
MMU가 가상 주소 A를 변환하려다 페이지 폴트를 발생시키면, 제어권이 커널의 페이지 폴트 핸들러로 넘어와 다음 3단계를 순차적으로 수행합니다.
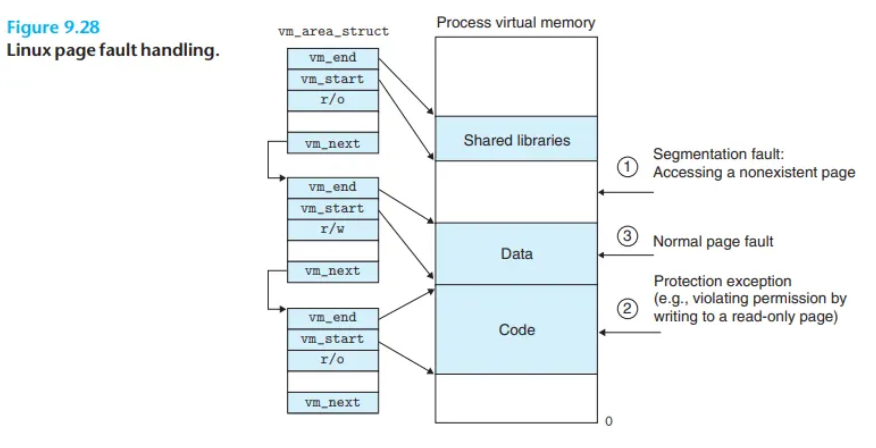
1단계: 가상 주소 A가 유효한 영역(Area)에 속하는가?
- 검사 내용:
A가vm_area_struct리스트에 정의된 영역 내(vm_start~vm_end사이)에 존재하는지 확인합니다. - 검사 실패 (오류 1):
A가 어떤 영역에도 속하지 않는 불법적인 주소라면, 핸들러는 세그멘테이션 폴트(Segmentation fault)를 발생시키고 프로세스를 종료시킵니다. - 참고 (성능 최적화):
mmap등으로 영역이 많아지면 리스트 순차 검색은 비효율적이므로, 리눅스는 실제로는 트리(tree) 자료구조를 사용하여 이 검색을 빠르게 수행합니다.
2단계: 메모리 접근 권한이 유효한가?
- 검사 내용: 주소
A가 유효한 영역에 속하더라도, 프로세스가 해당 영역에 대해 요청된 작업(읽기/쓰기/실행)을 수행할 권한(vm_prot)이 있는지 확인합니다. - 실패 예시:
- 읽기 전용(read-only)인 코드 세그먼트에 쓰기(write)를 시도함.
- 사용자 모드(user mode)에서 커널 가상 메모리 영역을 읽으려 시도함.
- 검사 실패 (오류 2): 접근 권한이 없다면, 핸들러는 보호 예외(Protection exception)를 발생시키고 프로세스를 종료시킵니다.
3단계: (유효한) 페이지 폴트 처리
- 상황: 1, 2단계를 모두 통과했다면, 이는 합법적인 주소에 대한 합법적인 접근이지만 해당 페이지가 단지 물리 메모리(DRAM)에 없는(Valid bit=0) 경우입니다.
- 처리 순서:
- 물리 메모리에서 쫓아낼 희생 페이지(victim page)를 선택합니다.
- 만약 희생 페이지가 수정된 상태(Dirty bit=1)라면, 디스크로 페이지 아웃(page out)하여 변경 사항을 저장합니다.
- 필요한 새 페이지를 디스크에서 물리 메모리로 페이지 인(page in)합니다.
- 페이지 테이블(PTE)을 업데이트합니다. (새 PPN을 적고 Valid bit=1로 설정)
- 복귀: 핸들러가 반환되면, CPU는 폴트를 일으켰던 원래 명령어를 재시작합니다. 이번에는 MMU가
A를 정상적으로 변환하고, 명령어가 성공적으로 수행됩니다.
9.8 메모리 매핑 (Memory Mapping)
리눅스는 가상 메모리 영역(VMA)을 디스크 상의 객체(object)와 연결하여 초기화하는데, 이 과정을 메모리 매핑(memory mapping)이라고 합니다. 영역(Area)은 다음 두 가지 유형의 객체 중 하나에 매핑될 수 있습니다.
1. 일반 파일 (Regular File)
- 대상: 실행 파일과 같은 리눅스 파일 시스템의 일반 디스크 파일입니다.
- 동작:
- VMA는 파일의 연속적인 섹션(contiguous section)에 매핑됩니다.
- 파일 섹션은 페이지 크기 조각으로 나뉘어, 각 조각이 가상 페이지의 초기 내용이 됩니다.
- 초기화: 요구 페이징(Demand Paging)을 사용합니다.
- CPU가 해당 가상 페이지에 처음 접근(touch)할 때까지는 어떤 데이터도 물리 메모리로 로드되지 않습니다.
- 페이지 폴트가 발생하면 그때 디스크에서 해당 파일 조각을 읽어옵니다.
- 패딩: VMA가 파일 섹션보다 더 크면, 남는 영역은 0으로 채워집니다(padded).
2. 익명 파일 (Anonymous File)
- 대상: 파일과 연결되지 않으며, 커널이 생성하는 0으로 채워진 가상의 파일입니다. (예:
malloc으로 할당된 힙 영역) - 동작:
- CPU가 이 영역의 가상 페이지에 처음 접근(touch)하면 페이지 폴트가 발생합니다.
- 초기화:
- 커널은 물리 메모리에서 적절한 희생 페이지(victim page)를 찾습니다.
- 희생 페이지가 더티(dirty)하면 디스크(스왑 파일)로 페이지 아웃(swap out)시킵니다.
- 커널은 이 희생 페이지를 0 (binary zeros)으로 덮어씁니다.
- 페이지 테이블(PTE)을 업데이트하여 이 페이지가 메모리에 있다고 표시합니다.
- 특징: 디스크와 메모리 간에 어떠한 데이터 전송(transfer)도 일어나지 않습니다. (단지 0으로 덮어쓸 뿐입니다.)
- 별명: 이러한 이유로 익명 파일에 매핑된 페이지를 요구 제로 페이지(demand-zero pages)라고 부릅니다.
스왑 파일 (Swap File) / 스왑 공간 (Swap Area)
- 역할: 일단 가상 페이지가 (일반 파일이든 익명 파일이든) 초기화된 후에는, 이 페이지들은 물리 메모리와 커널이 관리하는 특별한 스왑 파일 사이를 오가며 스왑(page in/out)됩니다.
- 중요한 점: 스왑 공간의 총 크기는 현재 실행 중인 모든 프로세스가 할당할 수 있는 가상 페이지의 총량을 제한(bounds)합니다.
- Q. 가상 메모리에서 텍스트 영역을 접근하면 일반 파일에 매핑된다는 사실을 어떻게 알고 있을까? 시스템이 "알아서" 파악하는 것이 아니라, 프로그램이 메모리에 로드되는 시점에 커널이 미리 그렇게 설정을 해두기 때문입니다. 이 과정은
execve()시스템 콜(예: 셸에서./a.out을 입력하는 순간)이 호출될 때 발생합니다.1. 설계도: 실행 파일(ELF)의 '프로그램 헤더'
모든 리눅스 실행 파일(주로 ELF 형식)은 내부에 "프로그램 헤더 테이블(Program Header Table)"이라는 '설계도' 또는 '지침서'를 가지고 있습니다. 이 헤더에는 커널이 메모리를 어떻게 설정해야 하는지에 대한 정보가 담겨 있습니다.readelf -l <실행 파일>명령어로 직접 볼 수 있으며, 대략 이런 내용이 들어있습니다.-
항목 1 (Text Segment): "이 파일의 0x1000 오프셋부터 0x5000 바이트만큼의 데이터를 가상 주소
0x400000에 매핑하세요. 권한은 읽기(R), 실행(X)입니다." -
항목 2 (Data Segment): "이 파일의 0x6000 오프셋부터 0x2000 바이트만큼의 데이터를 가상 주소
0x605000에 매핑하세요. 권한은 읽기(R), 쓰기(W)입니다." -
항목 3 (BSS Segment): "가상 주소
0x607000부터0x1000바이트만큼의 공간을 0으로 채워서 매핑하세요. 파일에서 읽을 필요 없습니다. 권한은 읽기(R), 쓰기(W)입니다."
2. 설정: 커널의 VMA 생성
execve()가 호출되면, 커널은 이 '프로그램 헤더'를 읽습니다.
-
VMA 생성: 커널은 이 헤더의 각 항목(세그먼트)에 대해 가상 메모리 영역(VMA)을 생성합니다.
-
매핑 정보 저장:
- 텍스트 영역 VMA를 만들 때, 커널은 이 VMA 구조체에 "이 영역은./a.out파일의0x1000오프셋에 연결된다"는 정보를 명시적으로 기록합니다.
- BSS나 힙(Heap) 영역 VMA를 만들 때는, "이 영역은 특정 파일이 없는 '익명 파일(Anonymous file)'에 연결된다"고 기록합니다.
3. 실행: 페이지 폴트 발생 시
이제 모든 설정이 끝났습니다. 프로그램이 실행되다가 텍스트 영역의 특정 주소(예:
0x400100)에 처음 접근합니다. -
페이지 폴트(Page Fault) 발생: (요구 페이징 때문에) 아직 이 주소에 해당하는 물리 메모리가 없습니다. CPU는 페이지 폴트 예외를 발생시켜 커널을 호출합니다.
-
커널의 VMA 확인: 커널(페이지 폴트 핸들러)은 "주소
0x400100이 속한 VMA가 어디지?"라고 찾습니다. -
"정답" 확인: 커널은 1번에서 설정해 둔 텍스트 영역 VMA를 찾습니다. 그리고 그 VMA에 저장된 정보를 읽습니다.
- "아, 이 VMA는 일반 파일(
./a.out)에 매핑되어 있구나. 파일 오프셋은0x1000이군."
- "아, 이 VMA는 일반 파일(
-
페이지 로드: 커널은 디스크에서
./a.out파일을 열어 해당 오프셋의 데이터를 읽어와 물리 메모리에 올린 후, 페이지 테이블을 업데이트합니다.만약 접근한 주소가 힙 영역이었다면, 커널은 힙 VMA를 찾았을 것이고, "아, 이건 익명 파일이네"라고 확인한 뒤 디스크를 읽는 대신 그냥 0으로 채워진 물리 페이지(요구-제로 페이지)를 할당했을 것입니다.
결론: 텍스트 영역 접근 시 일반 파일에 매핑된다는 것을 아는 이유는, 프로그램 로드 시점에 커널이 ELF 파일의 지시대로 VMA에 "이 영역은 그 파일이다"라고 미리 '꼬리표'를 붙여두었기 때문입니다.
-
9.8.1 공유 객체 다시 보기 (Shared Objects Revisited)
메모리 매핑은 가상 메모리 시스템을 파일 시스템과 통합하여, 프로그램과 데이터를 메모리에 효율적으로 로드하고 공유하는 방법을 제공합니다.
문제점: bash 셸이나 C 표준 라이브러리(printf 등)처럼, 많은 프로세스가 동일한 읽기 전용(read-only) 코드를 사용합니다. 이 중복된 코드를 프로세스마다 물리 메모리에 두는 것은 극심한 낭비입니다.
해결책: 객체를 공유(shared) 또는 사적(private)으로 매핑하여 이 문제를 해결합니다.
1. 공유 객체 매핑 (Shared Object Mapping)
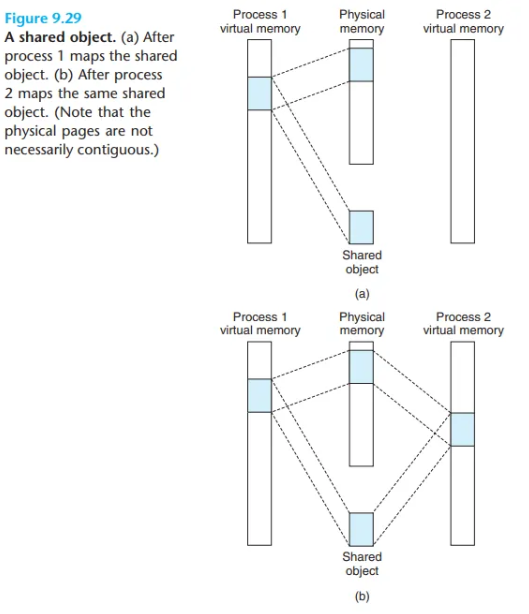
프로세스가 가상 메모리 영역(VMA)에 공유 객체를 매핑하는 경우입니다.
- 쓰기(Write) 동작:
- 한 프로세스가 이 영역에 쓴 내용은, 이 객체를 매핑한 다른 모든 프로세스에게 즉시 보입니다(visible).
- 이 변경 사항은 디스크의 원본 객체(파일)에도 반영됩니다.
- 커널의 최적화:
- 프로세스 1이 공유 객체를 매핑합니다.
- 프로세스 2가 (파일 이름을 통해) 동일한 객체를 매핑하려 하면, 커널은 이를 인지합니다.
- 커널은 프로세스 2의 페이지 테이블 엔트리(PTE)가, 프로세스 1이 이미 사용 중인 동일한 물리 페이지를 가리키도록 설정합니다.
- 핵심: 여러 프로세스가 동일한 객체를 매핑하더라도, 물리 메모리에는 단 하나의 복사본만 유지됩니다.
2. 사적 객체 매핑 (Private Object Mapping)과 Copy-on-Write
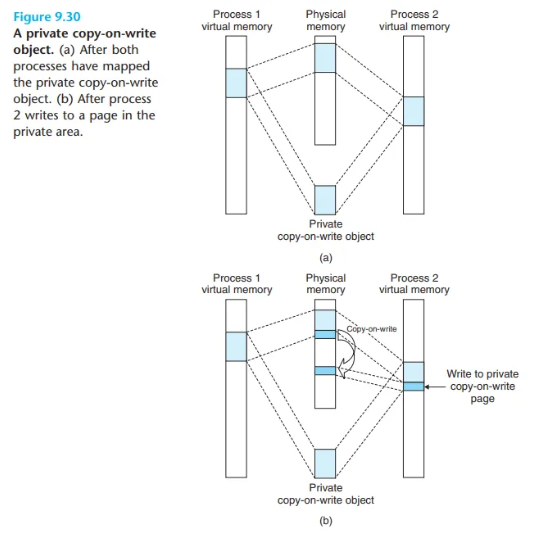
프로세스가 가상 메모리 영역(VMA)에 사적 객체를 매핑하는 경우입니다.
- 쓰기(Write) 동작:
- 한 프로세스가 이 영역에 쓴 내용은 다른 프로세스에게 보이지 않습니다.
- 이 변경 사항은 디스크의 원본 객체(파일)에 반영되지 않습니다.
- 구현 기법: Copy-on-Write (COW)
-
초기 상태: 사적 객체 매핑은 처음에는 공유 객체와 똑같이 동작합니다. 즉, 여러 프로세스가 동일한 객체를 매핑하더라도, 모두 단 하나의 동일한 물리 페이지 복사본을 가리킵니다.
-
권한 설정: 이때 커널은 이 '사적 영역'에 해당하는 모든 PTE를 읽기 전용(Read-only)으로 플래그하고, VMA(영역 구조체)에는 "private copy-on-write"라고 표시합니다.
-
읽기: 모든 프로세스가 읽기만 하는 동안은, 계속해서 단일 물리 복사본을 효율적으로 공유합니다.
→ 보호 오류 유발
-
9.8.2 fork 함수 다시 보기
가상 메모리와 메모리 매핑을 이해했으므로, fork 함수가 어떻게 자신만의 독립적인 가상 주소 공간을 가진 새 프로세스를 생성하는지 명확히 파악할 수 있습니다.
fork 호출 시 커널의 동작
현재 프로세스가 fork 함수를 호출하면, 커널은 새 프로세스를 위한 다양한 자료구조를 생성하고 고유한 PID를 할당합니다. 새 프로세스의 가상 메모리를 생성하기 위해 커널은 다음과 같은 작업을 수행합니다.
- 현재 프로세스(부모)의
mm_struct,area struct(VMA), 페이지 테이블의 정확한 복사본을 만듭니다. - 두 프로세스(부모와 자식) 모두의 각 페이지를 '읽기 전용(read-only)'으로 플래그합니다.
- 두 프로세스 모두의 각
area struct(VMA)를 'private copy-on-write' (사적 쓰기 시 복사)로 플래그합니다.
fork 반환 후 및 이후 쓰기 작업
fork 함수가 새 프로세스(자식)에서 반환될 때, 자식 프로세스는 fork가 호출된 시점과 정확히 동일한 가상 메모리 복사본을 갖게 됩니다.
이후, 부모나 자식 프로세스 중 어느 쪽이든 쓰기(write) 작업을 수행하면, Copy-on-Write (COW) 메커니즘이 작동하여 해당 페이지의 새로운 복사본을 생성합니다.
이러한 방식을 통해, (초기에는 물리 메모리를 공유함에도 불구하고) 각 프로세스가 자신만의 사적인 주소 공간을 갖는다는 추상화(abstraction)가 완벽하게 보존됩니다.
9.8.3 execve 함수 다시 보기
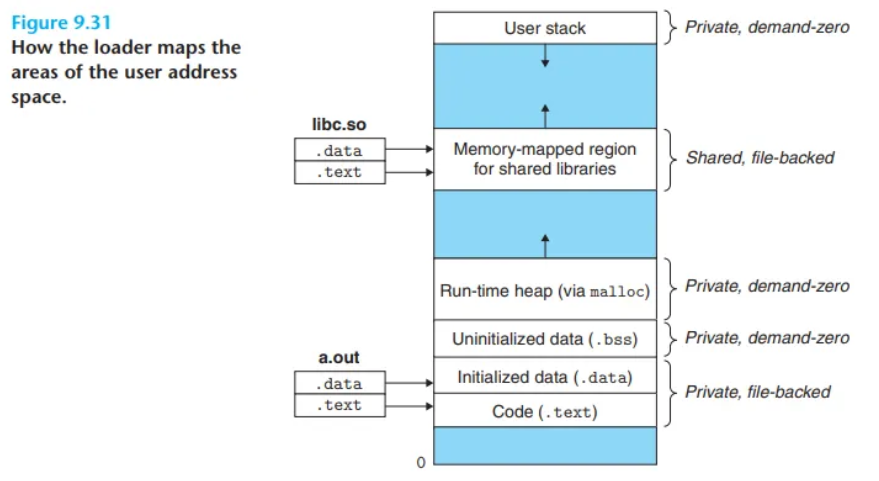
가상 메모리와 메모리 매핑은 프로그램을 메모리에 로드(적재)하는 과정에서도 핵심적인 역할을 합니다. 이 개념들을 이해했으므로, execve 함수가 실제로 어떻게 프로그램을 로드하고 실행하는지 파악할 수 있습니다.
현재 프로세스에서 실행 중인 프로그램이 다음과 같은 호출을 했다고 가정해 봅시다.
execve("a.out", NULL, NULL);
8장에서 배운 대로, execve 함수는 현재 프로세스 내에서 a.out 실행 파일에 포함된 프로그램을 로드하고 실행합니다. 이는 사실상 현재 프로그램을 a.out 프로그램으로 교체(replace)하는 것입니다.
a.out을 로드하고 실행하는 데는 다음 4단계가 필요합니다.
- 기존 사용자 영역 삭제
현재 프로세스 가상 주소의 사용자 부분에 있는 기존area struct(VMA)들을 모두 삭제합니다. - 사적 영역(private areas) 매핑
새 프로그램의 코드, 데이터, bss, 스택 영역을 위한 새로운area struct를 생성합니다. 이 모든 새 영역은 'private copy-on-write' (사적 쓰기 시 복사) 속성을 갖습니다.
- 코드 및 데이터 영역:a.out파일의.text와.data섹션에 매핑됩니다. (일반 파일 매핑)
- bss 영역:a.out파일에 크기 정보만 있는 익명 파일(anonymous file)에 매핑되며, '요구-제로(demand-zero)' 방식으로 초기화됩니다.
- 스택 및 힙 영역: 역시 '요구-제로' 방식의 익명 파일에 매핑되며, 처음 길이는 0입니다. - 공유 영역(shared areas) 매핑
만약a.out프로그램이 표준 C 라이브러리인libc.so와 같은 공유 객체(shared objects)와 링크되었다면, 이 객체들은 프로그램에 동적으로 링크되며, 이후 사용자 가상 주소 공간의 공유 영역(shared region)에 매핑됩니다. - 프로그램 카운터(PC) 설정
execve가 마지막으로 하는 일은 현재 프로세스 컨텍스트의 프로그램 카운터(PC)를 새 프로그램의 코드 영역 진입점(entry point)을 가리키도록 설정하는 것입니다.
이후 이 프로세스가 다음번에 스케줄링되면, 이 진입점부터 실행을 시작할 것입니다. 리눅스는 필요에 따라 코드와 데이터 페이지를 (디스크에서 물리 메모리로) 스왑인(swap in) 할 것입니다.
9.8.4 mmap 함수를 이용한 사용자 수준 메모리 매핑
리눅스 프로세스는 mmap 함수를 사용하여 가상 메모리의 새 영역을 생성하고, 이 영역에 객체를 매핑할 수 있습니다.
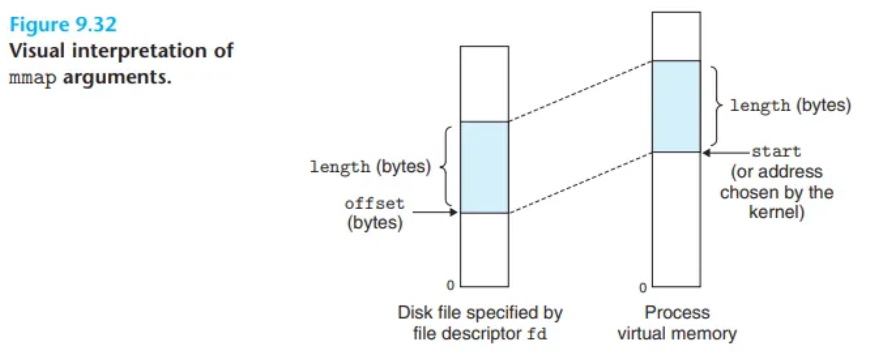
#include <unistd.h>
#include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags,
int fd, off_t offset);
// 성공 시: 매핑된 영역의 포인터 반환
// 오류 시: MAP_FAILED (−1) 반환mmap 함수는 커널에 새로운 가상 메모리 영역(VMA) 생성을 요청합니다. 이 영역은 가급적 start 주소에서 시작하며, 파일 디스크립터 fd로 명시된 객체의 연속적인 조각을 이 새로운 영역에 매핑합니다. 이 연속적인 객체 조각은 length 바이트 크기를 가지며, 파일의 시작 지점으로부터 offset 바이트 떨어진 곳에서 시작합니다.
start 주소는 단지 힌트(hint)일 뿐이며, 보통 NULL로 지정됩니다. (이 문서의 목적상, start 주소는 항상 NULL이라고 가정하겠습니다.) [그림 9.32]는 이 인자들의 의미를 묘사합니다.
prot 인자는 새로 매핑된 가상 메모리 영역의 접근 권한을 기술하는 비트들을 포함합니다 (즉, 해당 area struct의 vm_prot 비트들).
PROT_EXEC: 영역 내의 페이지들이 CPU에 의해 실행될 수 있는 명령어로 구성됩니다.PROT_READ: 영역 내의 페이지들을 읽을 수 있습니다.PROT_WRITE: 영역 내의 페이지들에 쓸 수 있습니다.PROT_NONE: 영역 내의 페이지들에 접근할 수 없습니다.
flags 인자는 매핑된 객체의 타입을 기술하는 비트들로 구성됩니다.
MAP_ANON플래그 비트가 설정되면, 후방 저장소(backing store)는 익명 객체(anonymous object)이며 해당 가상 페이지는 '요구-제로(demand-zero)' 방식입니다.MAP_PRIVATE은 사적 'copy-on-write' 객체임을 나타냅니다.MAP_SHARED는 공유 객체임을 나타냅니다.
예를 들어,
bufp = Mmap(NULL, size, PROT_READ, MAP_PRIVATE|MAP_ANON, 0, 0);위 코드는 커널에 size 바이트 크기의, 읽기 전용, 사적(private), 요구-제로(demand-zero) 속성을 가진 가상 메모리 영역을 새로 생성하도록 요청합니다. 호출이 성공하면 bufp는 이 새 영역의 주소를 갖게 됩니다.
munmap 함수
munmap 함수는 가상 메모리의 영역들을 삭제합니다.
#include <unistd.h>
#include <sys/mman.h>
int munmap(void *start, size_t length);
// 성공 시: 0 반환
// 오류 시: −1 반환munmap 함수는 가상 주소 start에서 시작하여 이후 length 바이트로 구성된 영역을 삭제합니다. 이 함수가 실행된 후 삭제된 영역에 접근하려고 하면 세그멘테이션 오류(segmentation fault)가 발생합니다.
