
9.9 동적 메모리 할당 (Dynamic Memory Allocation)
mmap이나 munmap 같은 저수준 함수를 직접 사용하는 것도 가능하지만, C 프로그래머들은 런타임에 추가적인 가상 메모리를 얻기 위해 동적 메모리 할당기(Dynamic Memory Allocator)를 사용하는 것이 더 편리하고 이식성이 높다고 생각합니다.
힙 (The Heap)
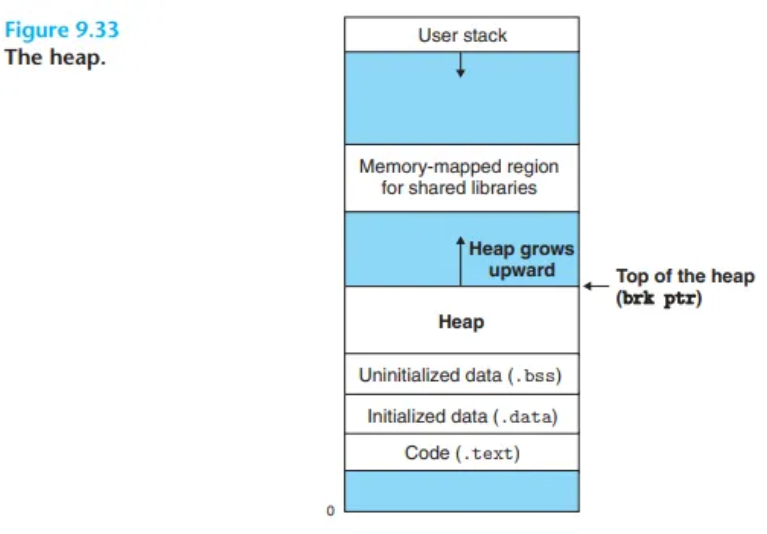
할당기는 프로세스 가상 메모리의 힙(Heap)이라고 알려진 영역을 관리합니다. (CSAPP 그림 9.33 참조)
- 위치: 힙은 일반적으로 초기화되지 않은 데이터 영역(.bss) 직후에 시작하며, 높은 주소 방향으로 "자라나는" 요구 제로(demand-zero) 메모리 영역입니다.
brk: 커널은 각 프로세스마다brk("브레이크"라고 발음)라는 변수를 유지하며, 이는 힙의 최상단(top)을 가리킵니다.
할당된 블록과 가용 블록
할당기는 힙을 다양한 크기의 블록(block) 집합으로 유지 관리합니다. 각 블록은 연속적인 가상 메모리 덩어리이며, 할당됨(allocated) 또는 가용(free) 상태 중 하나입니다.
- 할당된 블록 (Allocated Block): 애플리케이션이 사용하도록 명시적으로 예약된 블록입니다. 애플리케이션이 명시적으로 해제하거나 할당기 자체가 암시적으로 해제하기 전까지 할당된 상태로 남아있습니다.
- 가용 블록 (Free Block): 할당될 수 있는 상태의 블록입니다. 명시적으로 할당되기 전까지 가용 상태로 남아있습니다.
할당기의 두 가지 기본 스타일
두 스타일 모두 애플리케이션이 명시적으로 블록을 할당(allocate)해야 한다는 공통점이 있습니다. 차이점은 블록을 해제(free)하는 주체가 누구냐는 것입니다.
1. 명시적 할당기 (Explicit Allocators)
- 특징: 애플리케이션이 사용한 블록을 반드시 명시적으로 해제해야 합니다.
- 예시: C 표준 라이브러리의
malloc패키지 (malloc()으로 할당,free()로 해제), C++의new/delete연산자.
2. 암시적 할당기 (Implicit Allocators)
- 특징: 할당기(Allocator)가 프로그램이 더 이상 사용하지 않는 블록을 자동으로 감지하여 해제합니다.
- 별명: 가비지 컬렉터 (Garbage Collectors)라고 부르며, 이 자동 해제 과정을 가비지 컬렉션 (Garbage Collection)이라고 합니다.
- 예시: Lisp, ML, Java와 같은 고급 프로그래밍 언어들.
이 섹션의 나머지 부분은 명시적 할당기의 설계와 구현에 대해 초점을 맞춥니다.
9.9.1 malloc과 free 함수
C 표준 라이브러리는 malloc 패키지라고 알려진 명시적 할당기(explicit allocator)를 제공합니다. 프로그램은 malloc 함수를 호출하여 힙(heap)으로부터 블록을 할당받습니다.
malloc 함수
#include <stdlib.h>
void *malloc(size_t size);
// 성공 시 할당된 블록 포인터, 실패 시 NULL 반환malloc 함수는 최소 size 바이트 크기의 메모리 블록 포인터를 반환하며, 이 블록은 그 안에 포함될 수 있는 어떤 종류의 데이터 객체에 대해서도 적절하게 정렬(aligned)되어 있습니다.
- 정렬 (Alignment):
- 32-bit 모드: 반환되는 주소는 항상 8의 배수입니다.
- 64-bit 모드: 반환되는 주소는 항상 16의 배수입니다.
- 초기화:
malloc은 반환하는 메모리를 초기화하지 않습니다.- 초기화된 메모리를 원하면
calloc을 사용합니다. (malloc을 감싼 래퍼 함수로, 0으로 초기화합니다.) - 이미 할당된 블록의 크기를 변경하려면
realloc을 사용합니다.
- 초기화된 메모리를 원하면
- 실패:
malloc이 (예: 가용 가상 메모리보다 큰 요청) 문제를 만나면NULL을 반환하고errno를 설정합니다.
힙(Heap) 확장: sbrk 함수
malloc과 같은 동적 메모리 할당기는 mmap/munmap을 사용하거나, sbrk 함수를 사용하여 힙 메모리를 명시적으로 할당/해제할 수 있습니다.
#include <unistd.h>
void *sbrk(intptr_t incr);
// 성공 시 이전 brk 포인터, 실패 시 -1 반환sbrk 함수는 커널의 brk 포인터에 incr 값을 더하여 힙을 늘리거나 줄입니다.
- 성공 시:
brk의 이전(old) 값을 반환합니다. - 실패 시: -1을 반환하고
errno를ENOMEM으로 설정합니다. sbrk(0)은brk의 현재 값을 반환합니다.- Q. malloc과 mmap의 차이점 가장 큰 차이점은 '계층(Layer)'입니다.
malloc()은 C 라이브러리가 제공하는 함수(Library Function)이고,sbrk()는malloc()이 커널에게 메모리를 요청할 때 내부적으로 사용하는 시스템 콜(System Call)입니다.
즉,malloc()은 User-space에서,sbrk()는 Kernel-space에서 작동합니다.malloc()은 힙(Heap) 내부를 관리하고,sbrk()는 힙(Heap)의 전체 크기를 커널과 협상합니다.malloc()(라이브러리 함수 / 힙 관리자)malloc()은stdlib.h에 선언된 C 표준 라이브러리 함수입니다. 이 함수의 주된 목적은 개발자에게 힙 메모리 관리를 편리하게 제공하는 것입니다.-
관리 단위: 힙 내부의 개별 블록(Block)을 관리합니다.
-
주요 역할:
1. **가용 블록 검색:** `free()`로 반환된 블록들(Free List) 중에서 요청받은 `size`에 맞는 블록이 있는지 검색합니다. 2. **단편화 관리:** 블록을 나누고(splitting) 합치면서(coalescing) 힙의 메모리 파편화를 최소화합니다. 3. **메타데이터 관리:** 각 블록의 크기, 상태(할당/가용) 등을 기록하기 위해 블록 헤더(Header)에 메타데이터를 저장합니다. - **커널 호출 시점:** 힙에 요청을 만족할 만한 가용 블록이 **없을 때만** 커널에 "메모리를 더 달라"고 요청합니다.sbrk()(시스템 콜 / 힙 확장자)sbrk()는unistd.h에 선언된 시스템 콜입니다. 이 함수는 커널에게 "프로세스의 힙(Heap) 영역을 늘리거나 줄여달라"고 직접 요청하는 유일한 저수준(low-level) 인터페이스입니다. -
관리 단위: 힙 영역의 전체 끝 지점 (
brk포인터) -
주요 역할:
1. **`brk` 포인터 이동:** 커널이 관리하는 `task_struct`의 `brk` 포인터 위치를 `incr`만큼 이동시킵니다. 2. **VMA 확장:** `brk`가 이동하면, 커널은 해당 프로세스의 **힙(Heap) VMA (`vm_area_struct`)**의 `vm_end` 주소를 갱신하여 가상 주소 공간을 합법적으로 확장시킵니다. - `sbrk()`는 힙 내부에 `malloc`이 관리하는 블록이 몇 개 있는지, 그 상태가 어떤지 **전혀 알지 못합니다.** 단지 힙의 "울타리"만 뒤로 밀어줄 뿐입니다.핵심 차이점 요약
구분malloc()sbrk()계층C 라이브러리 함수 (User-space)시스템 콜 (Kernel-space)관리 단위힙 내부의 개별 블록(Block)힙 영역의 전체 끝 지점 (
brk)역할힙을 효율적으로 관리 (단편화, 가용 리스트)커널로부터 힙 메모리 총량을 할당/해제free()동작블록을 '가용' 상태로 변경 (OS 반환 X)sbrk(-n)로 힙을 줄일 수 있으나free()가 직접 호출하지 않음내부 호출sbrk()또는mmap()을 호출함호출당함 (커널 코드 실행)malloc의 두 가지 전략현대의
malloc은 요청 크기에 따라sbrk()와mmap()을 구분해서 사용합니다.
- 작은 요청 (e.g., < 128KB):
sbrk()를 호출해 힙을 크게 확장한 뒤, 그 안에서 블록을 잘게 쪼개 줍니다. - 큰 요청 (e.g., > 128KB):
sbrk()를 쓰지 않고mmap()시스템 콜을 직접 호출합니다. (이유:free()할 때munmap()으로 즉시 OS에 메모리를 반환할 수 있어 효율적임)
-
free 함수
프로그램은 free 함수를 호출하여 할당된 힙 블록을 해제합니다.
#include <stdlib.h>
void free(void *ptr);
// 반환 값 없음 (nothing)ptr인자는 반드시malloc,calloc,realloc을 통해 얻은 할당된 블록의 시작 주소여야 합니다.- 위험성 (Undefined Behavior):
- 만약
ptr이 유효한 블록의 시작 주소가 아니라면,free의 동작은 정의되지 않습니다(undefined). free는 아무것도 반환하지 않기 때문에, 애플리케이션에 무언가 잘못되었음을 알려주지 않습니다. 이는 매우 찾기 힘든 런타임 에러를 유발할 수 있습니다.
- 만약
동작 예시 (Figure 9.34)
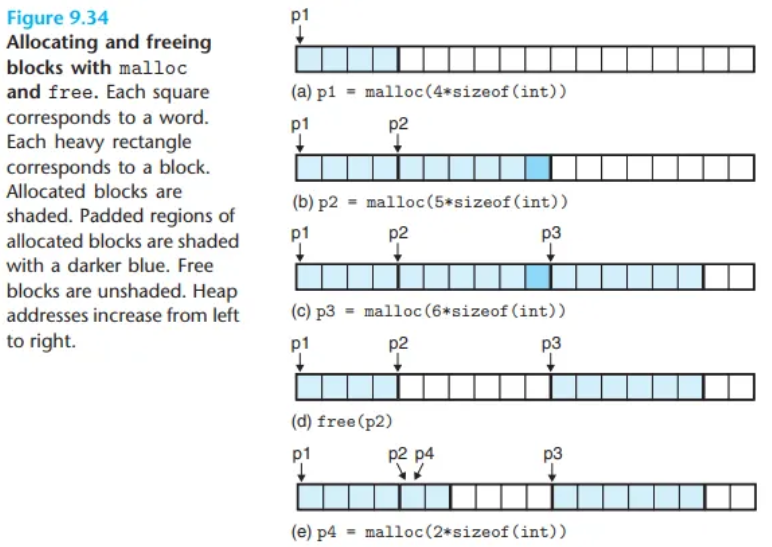
(16워드 크기의 작은 힙 예시)
- (a) 4워드 블록 요청 → 4워드 할당.
- (b) 5워드 블록 요청 → 6워드 블록 할당.
- 이유:
malloc이 가용 블록(free block)을 double-word 경계로 정렬시키기 위해 1워드의 패딩(padding)을 추가합니다.
- 이유:
- (c) 6워드 블록 요청 → 6워드 할당.
- (d) (b)에서 할당했던 6워드 블록을 해제(
free(p2)).- 주의:
free호출 후에도 포인터p2는 여전히 해제된 블록을 가리킵니다 (댕글링 포인터). 이p2를 다시 사용하지 않는 것은 애플리케이션의 책임입니다.
- 주의:
- (e) 2워드 블록 요청 →
malloc이 (d)에서 해제되어 가용 상태가 된 블록의 일부를 재할당합니다.
9.9.2 왜 동적 메모리 할당을 사용하는가?
프로그램이 동적 메모리 할당을 사용하는 가장 중요한 이유는, 프로그램이 실행될 때(run time)가 되기 전까지는 특정 데이터 구조의 크기를 알 수 없는 경우가 많기 때문입니다.
정적 할당의 문제점 (나쁜 접근)
stdin(표준 입력)으로부터 n개의 정수를 입력받아 배열에 저장하는 간단한 C 프로그램을 예로 들어 보겠습니다.
나쁜 접근 방식은 배열의 크기를 하드코딩된 최댓값으로 미리 정의하는 것입니다.
#define MAXN 15213 // 임의의 최댓값
int array[MAXN];
// ...
scanf("%d", &n);
if (n > MAXN)
app_error("Input file too big");- 문제점 1 (임의성):
MAXN값은 임의적이며, 프로그램을 실행하는 기계의 실제 가용 가상 메모리 총량과는 아무런 관련이 없습니다. - 문제점 2 (유지보수): 만약 사용자가
MAXN보다 큰 파일을 읽고 싶다면, 유일한 해결책은MAXN값을 더 크게 수정하여 프로그램을 재컴파일(recompile)하는 것입니다. 이는 대규모 소프트웨어 제품에서 "유지보수 악몽(maintenance nightmare)"이 될 수 있습니다.
동적 할당의 장점 (좋은 접근)
더 나은 접근 방식은 n의 값을 알게 된 런타임에 배열을 동적으로 할당하는 것입니다.
int *array, i, n;
// ...
scanf("%d", &n); // n의 값을 런타임에 먼저 읽음
array = (int *)Malloc(n * sizeof(int)); // n의 크기만큼 정확히 할당
// ...
free(array); // 사용 후 해제- 장점: 이 접근 방식에서는 배열의 최대 크기가 임의의 상수(
MAXN)가 아니라, 시스템에서 가용한 가상 메모리의 총량에 의해서만 제한됩니다.
동적 메모리 할당은 유용하고 중요한 프로그래밍 기법이지만, 이를 올바르게 사용하기 위해서는 프로그래머가 그 동작 방식을 이해해야 하며, 잘못 사용하면 끔찍한 오류가 발생할 수 있습니다.
9.9.3 할당기의 요구사항과 목표
명시적 할당기(Explicit allocator)는 다음과 같은 엄격한 제약 조건 하에서 동작해야 합니다.
할당기의 제약 조건
- 임의의 요청 순서 처리 (Handling arbitrary request sequences)
- 할당기는 애플리케이션의
alloc,free요청이 어떤 순서로 들어올지 가정할 수 없습니다. (예:alloc과free가 중첩된다거나, 요청 수가 일치한다고 가정 불가) - 단,
free요청은 반드시 이전에alloc으로 할당된 블록에 대해서만 이루어져야 한다는 제약은 있습니다.
- 할당기는 애플리케이션의
- 즉각적인 응답 (Making immediate responses to requests)
- 할당기는
alloc요청에 즉시 응답해야 합니다. - 성능 향상을 위해 요청 순서를 바꾸거나(reorder) 버퍼링(buffer)하는 것이 허용되지 않습니다.
- 할당기는
- 힙만 사용 (Using only the heap)
- 할당기가 확장성(scalable)을 갖추려면, 할당기가 사용하는 (연결 리스트 같은) 비-스칼라(nonscalar) 자료구조들은 반드시 힙(heap) 자체 내에 저장되어야 합니다.
- Q. 비-스칼라 자료구조란? 이 말은
malloc과 같은 힙(Heap) 관리자가 사용하는 내부 장부(metadata) 역시, 관리 대상인 힙(Heap) 메모리 공간 안에 저장되어야 한다는 의미입니다.malloc이 자신의 메타데이터를 저장하기 위해 힙과 분리된 별도의 고정된 메모리(예: 전역 변수 배열)를 사용하면 확장성(Scalability)이 떨어지기 때문입니다."비-스칼라 자료구조"란? (관리자의 장부)
-
malloc(할당기)은 어떤 힙 블록이 비어있는지(free) 추적해야 합니다. -
이를 위해 가용 리스트(Free List)라는 연결 리스트(Linked List)를 사용합니다.
-
이 연결 리스트는
next(다음 노드 포인터),prev(이전 노드 포인터) 같은 복잡한 정보를 담고 있습니다. 이것이 바로 텍스트에서 말하는 "비-스칼라(non-scalar) 자료구조"입니다. (즉,int같은 단순 값이 아닌 구조체나 리스트)"힙 자체 내에 저장"이란? (장부를 땅에다 적기)
이
next와prev포인터 정보를 어디에 저장해야 할까요?❌ 나쁜 방법 (확장성 없음 - Scalable X)
malloc라이브러리가 내부에 고정된 크기의 전역 배열을 두는 방식입니다.
struct FreeBlockInfo g_free_list[1000]; -
문제: 이
malloc은 힙의 실제 크기와 상관없이, 최대 1000개의 가용 블록밖에 추적하지 못합니다. 프로그램이malloc과free를 반복하여 1001개의 가용 블록 조각이 생기는 순간, 할당기는 동작을 멈춥니다. 즉, 확장성(Scalability)이 없습니다.✅ 좋은 방법 (확장성 있음 - Scalable O)
-
"가용 블록(Free Block)의 빈 공간을 재활용"하는 방식입니다.
-
어떤 블록이
free()되면, 그 블록은 당장 사용자가 쓰지 않는 빈 공간이 됩니다. -
malloc은 이 빈 공간의 앞부분을next와prev포인터를 저장하는 용도로 '슬쩍' 사용합니다. -
즉, 가용 블록(Free Block) 자체가 가용 리스트(Free List)의 노드(Node)가 되는 것입니다.
결론
"힙 자체 내에 저장"해야 한다는 제약은,
malloc이 관리해야 할 대상(힙)이 커지면, 관리에 필요한 도구(가용 리스트)도 그에 맞춰 자동으로 함께 커질 수 있어야 한다는 "확장성"의 요구사항을 만족하기 위한 것입니다.가용 블록의 빈 공간을
next/prev포인터 저장소로 재활용함으로써, 힙에 가용 블록이 100만 개가 생겨도, 그 100만 개의 블록이 각자 자신의 리스트 노드 정보를 저장할 공간을 스스로 제공하므로 확장이 가능해집니다.malloc소스 코드 (개념)malloc라이브러리의 소스 코드는 (개념적으로) 다음과 같이 생겼습니다./* ---------- This code is INSIDE the C library ---------- */ // 1. "관리인의 책상" (라이브러리의 전역/정적 데이터 영역) // 이것이 바로 '시작점'을 유지하는 포인터입니다. static struct free_block *free_list_head = NULL; // 2. "힙(땅)" 내부의 노드 구조체 struct free_block { size_t size; struct free_block *next; // 이 포인터는 '힙' 내부에 저장됨 struct free_block *prev; // 이 포인터도 '힙' 내부에 저장됨 // ... (이 뒤로 실제 빈 공간이 있음) ... }; /* 사용자가 malloc을 호출하면... */ void *malloc(size_t size) { // 3. "책상"에서 '시작점'을 찾아 검색을 시작합니다. struct free_block *current = free_list_head; // ... (current를 따라가며 적절한 블록을 찾음) ... } /* 사용자가 free를 호출하면... */ void free(void *ptr) { struct free_block *freed_block = (struct free_block *)ptr; // 4. "책상"의 '시작점'을 업데이트합니다. (예: 리스트의 맨 앞에 추가) freed_block->next = free_list_head; free_list_head = freed_block; // '시작점'이 새로 해제된 블록으로 변경됨 }
-
- 블록 정렬 (Alignment requirement)
- 할당기는 반환하는 블록이 어떤 종류의 데이터 객체라도 담을 수 있도록 적절하게 정렬(align)해야 합니다. (예: 8바이트 또는 16바이트 경계)
- 할당된 블록은 수정 금지 (Not modifying allocated blocks)
- 할당기는 오직 가용 블록(free block)만을 조작하고 변경할 수 있습니다.
- 일단 블록이 할당되면, 그 블록을 수정하거나 이동(move)시킬 수 없습니다.
- 따라서 할당된 블록들을 모아 단편화를 줄이는 압축(compaction)과 같은 기술은 허용되지 않습니다.
할당기의 성능 목표
이러한 제약 하에서, 할당기 제작자는 서로 상충 관계(conflicting)에 있는 다음 두 가지 성능 목표를 달성하려 합니다.
목표 1: 처리율 극대화 (Maximizing Throughput)
- 정의: 처리율(Throughput)이란 단위 시간당 할당기가 완료하는 요청(
alloc+free)의 수입니다. (예: 1,000 ops/sec) - 달성 방법:
alloc과free요청을 처리하는 평균 시간을 최소화하여 처리율을 극대화합니다. - (참고:
alloc의 최악 시간 복잡도가 이고free가 인 할당기를 만드는 것은 어렵지 않습니다.)
목표 2: 메모리 사용률 극대화 (Maximizing Memory Utilization)
- 배경: 가상 메모리도 디스크의 스왑 공간(swap space) 총량에 의해 제한되는 유한한 자원입니다.
- Q. 왜 가상 메모리도 디스크의 스왑 공간 총량에 의해 제한되는 유한한 자원일까? 그 문장은 '이론상의' 가상 주소 공간과 '실제로 사용할 수 있는' 가상 메모리를 구분하지 않아 약간 혼란을 줄 수 있습니다. 질문하신 "왜 스왑 공간에 의해 제한되는가?"에 대한 답은, 운영체제(OS)가 약속한 메모리를 실제로 보관할 물리적인 저장소가 필요하기 때문입니다. 이때 '익명 페이지(Anonymous Page)'가 핵심입니다.
1. "주소 공간" vs "실제 사용"
먼저 두 가지를 구분해야 합니다.-
가상 주소 공간 (Virtual Address Space):
- 64-bit 시스템에서 말하는 256TB 같은 이론적인 주소 범위입니다.
- 이것은 그냥 "지도"일 뿐이며, 커널이 관리하는
vm_area_struct(VMA)로 예약만 해둔 상태입니다. - 이 "지도"를 예약하는 데는 비용이 거의 들지 않습니다.
-
사용한 가상 메모리 (Committed Memory):
-malloc이나 스택 사용으로 "실제로 사용(touch)"하여 페이지 폴트가 발생한 메모리입니다.
- 이것은 "지도" 위에 "실제 지어진 집"입니다.
- OS는 이 "집"을 보관할 물리적인 공간을 보장(commit)해야 합니다.
2. OS의 "보관 약속" (Backing Store)
OS가 이 "실제 집(사용한 페이지)"을 보관할 수 있는 물리적인 장소, 즉 '근본(Backing Store)'은 딱 두 종류입니다.
-
일반 파일 (File-backed):
.text(코드),libc.so,mmap으로 연 파일 등이 해당합니다.- 이 페이지들의 '근본'은 원본 파일 그 자체입니다.
- RAM에서 쫓겨나도 스왑 공간(Swap Space)으로 가지 않습니다. (그냥 버리거나, 원본 파일에 덮어쓰면 됩니다.)
-
익명 파일 (Anonymous):
- 힙(Heap,malloc), 스택(Stack)이 여기에 해당합니다.
- 이 페이지들은 '근본' 파일이 없습니다.
- 만약 이 페이지가 RAM에서 쫓겨날 때 그냥 버린다면,malloc으로 만든 데이터가 영구적으로 유실됩니다.
- 따라서 OS는 이 페이지의 유일한 피난처로 스왑 공간(Swap Space)을 사용합니다.
3. 결론: [RAM + 스왑] = 총량의 한계
시스템 전체에서 '실제로 사용 중인' 모든 익명 페이지(힙+스택)는, 그 존재 자체가 다음 두 곳 중 하나에 반드시 있어야 합니다.
-
물리 RAM (빠른 작업 공간)
-
스왑 공간 (느린 피난처)
즉, 시스템이 감당할 수 있는 '익명 페이지'의 총량은
[물리 RAM 크기] + [스왑 공간 크기]를 절대 넘을 수 없습니다.malloc으로 1TB를 요청하는 것은 "지도(VMA)"를 예약하는 것이라 가능하지만, 그 1TB를 전부 사용(write)하는 순간, OS는 그 1TB의 데이터를 RAM 아니면 스왑에 실제로 저장해야 합니다.만약
RAM과스왑 공간이 모두 꽉 찼는데, 어떤 프로세스가 또 다른 익명 페이지(malloc등)를 사용하려고 하면 (페이지 폴트 발생), OS는 데이터를 더 이상 저장할 곳이 없습니다. 이때malloc이NULL을 반환하거나, 리눅스의 OOM Killer가 작동하여 프로세스를 강제 종료시킵니다.요약:
"가상 메모리가 스왑에 의해 제한된다"는 말은, '이론상의 주소 공간(256TB)'이 아니라 '프로세스가 실제로 사용할 수 있는 힙/스택의 총량'이[RAM + 스왑]이라는 물리적 저장소의 합에 의해 제한된다는 의미입니다.
-
- Q. 힙, 스택, bss같은건 익명파일이므로 스왑 공간에 스왑되는거고 data, text는 일반 파일이므로 스왑 공간으로 가는게 아니라 만약 바뀐것이 있다면 디스크에 수정을 한다는 말일까?
메모리 세그먼트별 페이징 아웃 (Backing Store) 전략
페이지가 물리 메모리(RAM)에서 쫓겨날 때(Page-Out) 어디로 가는지는, 해당 페이지의 '원본(Backing Store)'이 무엇이냐에 따라 결정됩니다.1. 익명 페이지 (Anonymous Pages) → 스왑 공간
대상이 되는 세그먼트:-
Heap(e.g.,malloc으로 할당된 메모리) -
Stack(함수 호출 시 사용되는 스택) -
BSS(초기화되지 않은 전역/정적 변수)특징:
이들은 디스크에 대응되는 특정 '원본 파일'이 없는 순수한 데이터입니다.동작:
이 페이지들은 '근본'이 없으므로, 수정된(Dirty) 상태에서 RAM 밖으로 쫓겨날 때 데이터가 유실되는 것을 막아야 합니다. 따라서 이 페이지들의 유일한 피난처인 스왑 공간(Swap File)으로 저장됩니다.
2. 파일 기반 페이지 (File-Backed Pages)
이들은
.text와.data로 나뉘며, 동작 방식이 완전히 다릅니다.2-1.
.text세그먼트 (코드) → 버려짐 (Discard) -
스왑 공간으로 가지 않습니다. (O)
-
원본 파일을 수정하지 않습니다. (X)
.text세그먼트는 읽기 전용(Read-Only)이므로 절대 수정(Dirty)되지 않습니다. 따라서 RAM에서 쫓겨날 때, 커널은 이 페이지를 스왑 파일에 저장할 필요 없이 그냥 버립니다(Discard).나중에 이 코드가 다시 필요해지면, 디스크에 있는 원본 실행 파일(
a.out)에서 다시 읽어오면 됩니다.2-2.
.data세그먼트 (초기화된 데이터) 스왑 공간.data세그먼트는 Copy-on-Write (COW) 메커니즘을 통해 '파일 기반'에서 '익명 페이지'로 전환됩니다.
-
초기 로드 (파일 기반):
프로세스가 처음 로드될 때,.data는 원본 실행 파일(a.out)의 초기값을 읽어옵니다. 이때는 여러 프로세스가 물리 메모리를 공유하며 읽기 전용(Read-Only)으로 매핑됩니다. -
첫 쓰기 시도 (보호 예외):
프로세스가 전역 변수 등.data영역에 처음으로 쓰기(write)를 시도하면, '읽기 전용'으로 설정된 권한 때문에 보호 예외(Protection Fault)가 발생합니다. -
복사 및 분리 (COW):
커널은 이 예외가 COW를 위한 것임을 인지하고, 해당 페이지의 새로운 '사적인(Private)' 복사본을 다른 물리 메모리 공간에 생성합니다. -
익명 페이지로 전환:
이 '사적인 복사본'은 더 이상 원본 실행 파일(a.out)과 아무런 연결이 없는 힙이나 스택과 같은 익명 페이지(Anonymous Page)가 됩니다.결론:
일단 한번 수정된.data페이지는 '익명 페이지' 취급을 받으므로, RAM에서 쫓겨날 때는 원본 파일을 건드리지 않고 힙이나 스택처럼 스왑 공간(Swap File)으로 갑니다.
-
- Q. data가 왜 보호 예외가 발생하는걸까? 어떤 보호가 되어있길래?
.data세그먼트가 '보호'되어 있는 이유는, 운영체제가 프로세스 간 메모리 공유(Memory Sharing)를 효율적으로 하기 위해 의도적으로 읽기 전용(Read-Only) 플래그라는 '덫'을 설치해 놨기 때문입니다. 이것이 바로 Copy-on-Write (COW) 메커니즘의 핵심입니다.1. 왜 Read-Only로 보호하나요? (메모리 공유)
프로세스가 처음 실행될 때,.data세그먼트(초기화된 전역 변수)는 디스크의 실행 파일(a.out)에서 로드됩니다. 만약bash라는 프로그램을 10개 실행시킨다고 상상해 봅시다.
.data세그먼트의 초기값은 10개 프로세스 모두 100% 동일합니다.-
나쁜 방식:
.data세그먼트(예: 1MB)를 10번 로드하여 물리 메모리 10MB를 낭비합니다. -
좋은 방식 (COW):
1..data세그먼트(1MB)를 물리 메모리(페이지 캐시)에 단 한 번만 로드합니다.
2. 10개 프로세스의 페이지 테이블(PTE)이 모두 이 '단 하나의 공유 페이지'를 가리키도록 매핑합니다.여기서 문제가 발생합니다. 이 페이지는 '공유'되어 있는데, 만약 프로세스 A가 이 공유 페이지에 쓰기를 하면, 프로세스 B~J의 데이터까지 오염됩니다. (프로세스 격리 위반)
이것을 막기 위해, 커널은 10개 프로세스 모두의
.data영역 PTE에 "쓰기 금지 (Read-Only)"라는 '보호' 플래그를 설정합니다.
2. Copy-on-Write (COW) 동작 방식
이 '보호'는 진짜 오류(Error)가 아니라, 커널에게 신호를 주기 위한 의도된 함정(Intentional Trap)입니다.
-
공유 매핑 (초기 상태):
- 프로세스 A와 B가 동일한 물리 페이지 P1을 가리킵니다.
- A의 PTE → P1 (권한: Read-Only)
- B의 PTE → P1 (권한: Read-Only)
-
쓰기 시도 및 보호 예외 (Protection Fault):
- 프로세스 A가 자신의 전역 변수(e.g.,
my_global = 10;)에 쓰기(Write)를 시도합니다. - MMU(하드웨어)가 A의 PTE를 확인하고, "Read-Only" 플래그가 설정된 것을 발견합니다.
- MMU가 CPU에 "보호 예외 (Protection Fault)"를 발생시킵니다.
- 프로세스 A가 자신의 전역 변수(e.g.,
-
커널 개입 (페이지 폴트 핸들러):
- 커널이 예외를 받아서 확인합니다. "이 주소는
.data영역이고, COW(Copy-on-Write)가 설정된 페이지네. 진짜 오류가 아니구나."
- 커널이 예외를 받아서 확인합니다. "이 주소는
-
복사 (Copy):
- 커널이 새로운 물리 페이지 P2를 할당합니다.
- 기존의 P1의 내용을 P2로 그대로 복사(Copy)합니다.
-
재매핑 및 권한 변경 (Write):
- 커널이 프로세스 A의 PTE만 수정합니다.
- A의 PTE → P2 (권한: Read/Write)
- (프로세스 B는 여전히 P1을 Read-Only로 가리키고 있습니다.)
-
명령어 재시작:
- 커널이 프로세스 A로 복귀하고, 실패했던 쓰기 명령을 재시작합니다.
- 이제 A는 자신만의 사적인(Private) 복사본 P2에my_global = 10;쓰기를 성공적으로 완료합니다.
결론
.data에 걸려있는 '보호'란, 공유 메모리 오염을 막기 위해 커널이 설정한 '임시 읽기 전용(Temporary Read-Only)' 플래그입니다.이 '보호 예외'는 쓰기 작업이 일어나는 순간을 포착하여, 그 즉시 "사본을 만들고(Copy)" → "사본에 쓰도록(on-Write)" 유도하는 COW 메커니즘의 트리거(Trigger) 역할을 합니다.
그리고 이 '사본'이 만들어진 순간, 이 페이지는 원본 파일과의 연결이 끊어지고 익명 페이지(Anonymous Page)가 되므로, 나중에 쫓겨날 때 스왑 파일(Swap File)로 가게 되는 것입니다.
-
- Q. read-only는 페이지 테이블 플래그에 설정되어있어서 알 수 있었는데 COW가 설정된 건 어떻게 알까? 커널은 PTE (Page Table Entry)가 아닌, 그보다 상위의 논리적 자료구조인
vm_area_struct(VMA)에 있는vm_flags를 보고 COW(Copy-on-Write)가 설정된 것을 압니다. 즉, 하드웨어(MMU)가 아는 정보와 커널(OS)이 아는 정보가 다릅니다. 커널은 이 정보의 불일치를 이용해 COW를 구현합니다.-
PTE(하드웨어용): MMU가 직접 읽는 페이지 테이블 항목.R/W(읽기/쓰기) 비트가 있습니다. -
VMA(커널용): 커널이 관리하는vm_area_struct. 해당 메모리 영역의 진짜 속성을 담은vm_flags가 있습니다. (예:VM_WRITE,VM_READ,VM_SHARED)
보호 예외(페이지 폴트) 발생 시 커널의 판단 과정
CPU가 쓰기(Write)를 시도 → MMU가
PTE를 확인 →R/W비트가 0 (Read-Only) → 보호 예외 발생!이제 제어권이 커널로 넘어옵니다. 커널은 폴트가 발생한 가상 주소를 가지고, 그 주소가 속한
VMA를 찾아vm_flags를 확인합니다.
시나리오 1: 진짜 오류 (Segfault) - (예:
.text코드 영역)
-
PTE(하드웨어):R/W비트가 0 (Read-Only)입니다. -
VMA(커널):vm_flags에VM_WRITE비트가 꺼져(0) 있습니다. -
커널의 판단: "하드웨어도 쓰기 금지라 했고, 내 장부(VMA)에도 쓰기 가능(
VM_WRITE) 표시가 없네. 이건 진짜 불법적인 접근이다." -
결과: 세그멘테이션 폴트 (SIGSEGV)를 보내고 프로세스를 종료시킵니다.
시나리오 2: COW 트리거 - (예:
.data또는fork()직후) -
PTE(하드웨어):R/W비트가 0 (Read-Only)입니다. (커널이 일부러 설치한 '덫') -
VMA(커널):vm_flags에VM_WRITE비트가 켜져(1) 있습니다. -
커널의 판단: "하드웨어는 쓰기 금지(R/O)라고 했지만, 내 장부(VMA)에는 쓰기 가능(
VM_WRITE)이라고 되어 있네. 아, 이건 COW(Copy-on-Write)를 수행하라는 신호구나." -
결과: 페이지 복사본을 만들고, PTE가 새 복사본을 가리키도록 변경한 뒤,
PTE의R/W비트를 1 (Writeable)로 설정해 줍니다.
-
- Q. 왜 가상 메모리도 디스크의 스왑 공간 총량에 의해 제한되는 유한한 자원일까? 그 문장은 '이론상의' 가상 주소 공간과 '실제로 사용할 수 있는' 가상 메모리를 구분하지 않아 약간 혼란을 줄 수 있습니다. 질문하신 "왜 스왑 공간에 의해 제한되는가?"에 대한 답은, 운영체제(OS)가 약속한 메모리를 실제로 보관할 물리적인 저장소가 필요하기 때문입니다. 이때 '익명 페이지(Anonymous Page)'가 핵심입니다.
- 주요 지표: 최고 사용률(Peak Utilization)이 가장 유용한 척도입니다.
- 변수 정의:
- 페이로드 (Payload): 애플리케이션이 실제로 요청한 바이트 수 ().
- (총 페이로드): k번째 요청 완료 후, 현재 할당된 모든 블록들의 페이로드 합계.
- (힙 크기): k번째 요청 완료 후, 힙의 현재 전체 크기 (단조 증가).
- 최고 사용률 () 계산:
- 목표: 전체 요청()에 대한 최고 사용률 을 최대화하는 것입니다.
목표 간의 상충 관계 (Tension)
처리율 극대화와 메모리 사용률 극대화 사이에는 긴장(상충) 관계(tension)가 존재합니다.
- 예를 들어, 처리율(특히
free속도)을 높이는 간단한 할당기(e.g.,free를 로 만들기)는 힙 사용률(메모리 단편화)을 희생시키기 쉽습니다. - free가 O(1)이라면 메모리 단편화가 생기는 이유 이 문장은 "가장 빠른
free"와 "가장 효율적인 메모리 사용"은 동시에 달성하기 어렵다는 뜻입니다.free속도를 O(1) (아주 빠름)로 만들려면,free가 하는 일을 최소한으로 줄여야 합니다. 하지만 이렇게 하면 외부 단편화(External Fragmentation)가 발생하여 힙 사용률이 나빠집니다.free를 O(1)로 만드는 '게으른' 방식 (처리율 높음)free(ptr)가 호출되었을 때, 할당기가 하는 일이 "해제된 블록을 가용 리스트(Free List)의 맨 앞에 추가"하는 것뿐이라고 가정해 봅시다.-
장점 (처리율 높음):
- 이 작업은 가용 블록이 힙에 100만 개가 있든 10개가 있든, 포인터 몇 개만 바꾸면 끝납니다.
free의 실행 시간이 항상 일정(Constant Time, O(1))합니다.
-
단점 (사용률 낮음 - 단편화):
- 이 방식은 해제된 블록의 양옆(인접) 블록이 비어있는지 확인하지 않습니다.
- 예시:[10B 가용][20B 가용][10B 가용]
- 위 3개의 블록이 메모리상에 연속으로 붙어있어도, 이 할당기는 이들을 하나의 큰 40B 블록으로 '병합(Coalescing)'하지 않습니다.
- 가용 리스트에는[10B],[20B],[10B]조각만 3개 등록됩니다.'병합'을 하지 않았을 때의 희생 (단편화 발생)
위 '게으른' 방식의 결과, 힙의 상태가 다음과 같다고 가정해 봅시다.
-
물리적 힙 상태:
[ 40B의 연속된 빈 공간 ] -
할당기의 가용 리스트:
[10B 조각] -> [20B 조각] -> [10B 조각]이때 사용자가 `malloc(30B)`를 요청합니다. 1. **할당 실패:** 할당기는 가용 리스트를 봅니다. 30B보다 큰 조각이 없습니다. 2. **단편화:** 실제로는 40B의 연속된 공간이 있음에도 불구하고, '병합'을 안 했기 때문에 30B 요청을 처리하지 못합니다. 이것이 바로 **외부 단편화**입니다.결론
"free를 O(1)로 만든다" → free 시 인접 블록을 확인하고 합치는 '병합(Coalescing)' 작업을 포기한다. (처리율 극대화)
"힙 사용률을 희생시킨다"→ '병합'을 포기한 결과, 힙이 잘게 조각나서 큰 요청을 처리 못하는 외부 단편화가 발생한다. (사용률 저하)
좋은 할당기 설계의 핵심 과제는 이 두 목표 사이에서 적절한 균형점을 찾는 것입니다.
-
9.9.5 구현 이슈 (Implementation Issues)
가장 단순하게 상상할 수 있는 할당기는 힙(heap)을 거대한 바이트 배열로, p라는 포인터를 배열의 시작점으로 간주하는 방식일 것입니다.
malloc(size):p의 현재 값을 저장하고,p를size만큼 증가시킨 뒤,p의 옛날 값을 반환합니다.free(): 아무것도 하지 않고 반환합니다.
이 '순진한(naive) 할당기'는 설계상 극단적인 예시입니다. malloc과 free가 단 몇 개의 명령어로 실행되므로 처리율(throughput)은 극도로 좋지만, 어떤 블록도 재사용하지 않기 때문에 메모리 사용률(memory utilization)은 극도로 나쁩니다.
실용적인 할당기의 4가지 구현 이슈
처리율과 사용률 사이의 균형을 맞추는 실용적인 할당기는 반드시 다음 네 가지 이슈를 고려해야 합니다.
- 가용 블록 조직 (Free block organization)
- 질문: 가용(free) 블록들을 어떻게 추적하고 관리할 것인가?
- 배치 (Placement)
- 질문: 새로 할당할 블록을 여러 가용 블록 중 어느 것에 배치할 것인가?
- 분할 (Splitting)
- 질문: 큰 가용 블록에 작은 블록을 배치한 후, 그 가용 블록의 남은 부분은 어떻게 처리할 것인가?
- 병합 (Coalescing)
- 질문: 방금
free()되어 해제된 블록은 어떻게 처리할 것인가? (예: 인접한 다른 가용 블록과 합칠 것인가?)
- 질문: 방금
이 섹션의 나머지 부분에서는 이러한 이슈들을 암시적 가용 리스트(implicit free list)라는 단순한 가용 블록 조직 방식을 예로 들어 자세히 살펴볼 것입니다.
9.9.6 암시적 가용 리스트 (Implicit Free Lists)
실용적인 할당기는 블록의 경계를 구분하고, 할당된 블록과 가용 블록을 구별할 수 있는 자료구조가 필요합니다. 대부분의 할당기는 이 정보를 블록 자체에 포함(embed)시킵니다.
블록 구조 (Block Format)
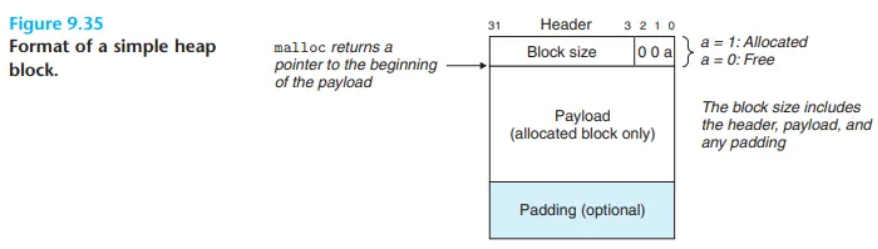
(CSAPP 그림 9.35 참조) 가장 간단한 접근 방식에서 블록은 다음과 같이 구성됩니다.
- 헤더 (Header): 1워드(word). 블록의 정보(크기, 할당 여부)를 담습니다.
- 페이로드 (Payload):
malloc이 요청한 실제 데이터. - 패딩 (Padding): (선택 사항) 정렬을 맞추거나 단편화를 줄이기 위한 추가 공간.
헤더 (Header)의 최적화
헤더는 블록의 전체 크기와 할당/가용 여부를 동시에 인코딩합니다.
-
배경 (정렬): 8바이트(double-word) 정렬 제약 조건이 있다면, 모든 블록 크기는 항상 8의 배수입니다.
-
특징: 8의 배수인 숫자는 2진수로 표현하면 항상 하위 3비트가
000입니다.(예: )
-
최적화: 어차피 0인 이 3비트를 낭비하지 말고, 플래그(flag)로 사용합니다.
-
구현: 여기서는 이 3비트 중 최하위 비트(LSB)를 할당 비트(allocated bit)로 사용합니다.
1: 할당됨 (Allocated)0: 가용 (Free)
예시: (1 워드 = 4 바이트)
- 24바이트(0x18) 크기의 할당된(Allocated) 블록:
0x00000018(크기)0x1(할당됨) =0x00000019(헤더 값)
- 40바이트(0x28) 크기의 가용(Free) 블록:
0x00000028(크기)0x0(가용) =0x00000028(헤더 값)
암시적 가용 리스트 (Implicit Free List)
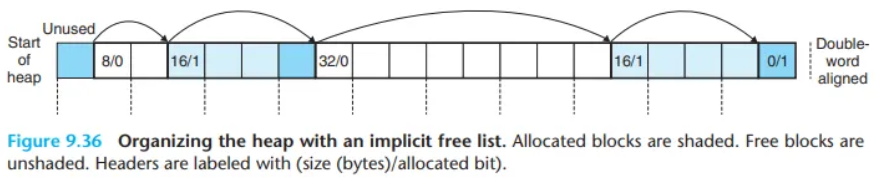
(CSAPP 그림 9.36 참조) 이 블록 형식을 사용하여 힙(heap)을 연속된 할당/가용 블록의 시퀀스로 구성할 수 있습니다.
"암시적(Implicit)" 리스트라고 부르는 이유:
가용 블록들을 연결하기 위한 명시적인 next 포인터가 없습니다. 대신, 가용 블록들은 헤더의 크기(size) 필드에 의해 암시적으로 연결됩니다.
- 탐색 방식: 할당기는 힙에 있는 모든 블록을 순차적으로 탐색(traverse)해야만 가용 블록 전체를 탐색할 수 있습니다. (현재 블록 주소 + 현재 블록 크기 = 다음 블록 주소)
- 종료 블록: 힙의 끝을 표시하기 위해
size = 0이고allocated bit = 1로 설정된 특별한 종결 헤더(terminating header)가 필요합니다.
장점과 단점
- 장점: 구현이 단순합니다(Simplicity).
- 단점 (치명적):
malloc을 위한 배치(placement) 등 가용 리스트를 검색해야 하는 모든 작업의 비용이, 힙에 있는 '전체' 블록 수 (할당된 블록 + 가용 블록)에 비례(Linear)합니다. ()
최소 블록 크기 (Minimum Block Size)
시스템의 정렬 요구사항과 할당기의 블록 형식은 '최소 블록 크기'를 강제합니다.
- (예시) 8바이트 정렬 요구사항 하에서:
1워드: 헤더를 위해 필요합니다.1워드: 8바이트 정렬을 맞추기 위한 최소한의 페이로드/패딩 공간으로 필요합니다.- 결과: 최소 블록 크기는 2워드 (8바이트)가 됩니다.
- 만약 애플리케이션이 1바이트(
malloc(1))를 요청하더라도, 할당기는 8바이트짜리 블록을 생성해야 합니다.
9.9.7 할당 블록 배치하기 (Placing Allocated Blocks)
애플리케이션이 바이트 블록을 요청하면, 할당기는 가용 리스트(free list)에서 이 요청을 감당할 만큼 충분히 큰 가용 블록을 검색합니다. 이 검색을 수행하는 방식을 배치 정책(placement policy)이라고 합니다.
일반적인 정책으로는 First Fit, Next Fit, Best Fit이 있습니다.
1. First Fit (최초 적합)
- 정책: 가용 리스트의 처음부터 검색을 시작해서, 요청을 만족하는 첫 번째 가용 블록을 선택합니다.
- 장점: 리스트의 뒤쪽(끝)에 큰 가용 블록들을 남겨두는 경향이 있습니다.
- 단점: 리스트의 앞쪽(시작) 부분에 작은 메모리 "파편(splinters)"들을 남기는 경향이 있으며, 이는 나중에 더 큰 블록을 찾기 위한 검색 시간을 증가시킵니다.
2. Next Fit (다음 적합)
- 정책: First Fit과 유사하지만, 매번 검색을 리스트의 '처음'에서 시작하는 대신, 이전 검색이 중단되었던 위치에서부터 다음 검색을 시작합니다.
- (Donald Knuth가 제안. "지난번에 이 블록에서 찾았다면, 다음번엔 그 블록의 남은 부분에서 또 찾을 가능성이 높다"는 아이디어에서 착안)
- 장점: 리스트 앞부분이 작은 파편으로 가득 찰 경우, First Fit보다 훨씬 빠르게 동작할 수 있습니다.
- 단점: 일부 연구에 따르면, 메모리 사용률(utilization)은 First Fit보다 더 나쁠 수 있습니다.
3. Best Fit (최적 적합)
- 정책: 모든 가용 블록을 검사하여, 요청한 크기를 만족하는 가용 블록 중 가장 크기가 작은(가장 딱 맞는) 블록을 선택합니다.
- 장점: 메모리 사용률(utilization) 측면에서 First Fit이나 Next Fit보다 일반적으로 더 좋습니다.
- 단점: (방금 배운 '암시적 가용 리스트' 같은 단순한 구조에서는) 가장 딱 맞는 것을 찾기 위해 힙(heap) 전체를 완전 탐색(exhaustive search)해야만 합니다.
- (참고: 이후 배울 ' segregated free list' 같은 더 복잡한 자료구조는, 힙 전체를 탐색하지 않고도 Best Fit과 유사한 효과를 낼 수 있습니다.)
9.9.8 가용 블록 분할하기 (Splitting Free Blocks)
할당기가 요청에 맞는(fit) 가용 블록을 찾은 후, 그 블록 중 얼마나 많이 할당할 것인지에 대한 또 다른 정책 결정을 내려야 합니다.
1. 전체 블록 사용 (Use the entire block)
- 동작: 찾은 가용 블록 전체를 할당합니다.
- 장점: 단순하고 빠릅니다.
- 단점 (치명적): 내부 단편화(Internal Fragmentation)를 유발합니다. (예: 100바이트 요청에 1000바이트 블록을 통째로 주면, 할당된 블록 내부에 900바이트가 낭비됨)
- 예외: 만약 Best Fit 등을 사용해 찾은 블록이 요청과 크기가 거의 같다면(good fit) 이 방식도 괜찮을 수 있습니다.
2. 블록 분할 (Split the free block) - (일반적인 방식)
- 동작: 낭비(내부 단편화)를 피하기 위해, 할당기는 보통 가용 블록을 두 부분으로 분할(split)합니다.
- 결과:
- 첫 번째 부분: 사용자가 요청한 크기의 할당된 블록(allocated block)이 됩니다.
- 두 번째 부분 (나머지): 새로운 가용 블록(free block)이 되어 리스트에 남습니다.
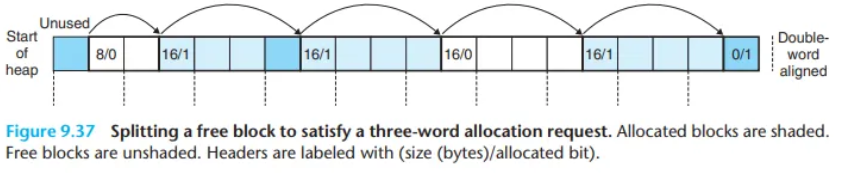
(예: CSAPP 그림 9.37은 8워드 가용 블록을 3워드 요청에 맞춰 3워드(할당)와 4워드(새 가용) 블록으로 분할하는 것을 보여줍니다.)
9.9.9 추가 힙 메모리 획득하기 (Getting Additional Heap Memory)
할당기가 요청된 블록에 맞는(fit) 가용 블록을 찾지 못했을 때 어떻게 해야 할까요?
- 1단계: 병합 시도 (Coalescing)
- (다음 섹션에서 다룰) 메모리상에 물리적으로 인접한 가용 블록들을 병합(merging)하여 더 큰 가용 블록을 만들려고 시도합니다.
- 2단계: 커널에 요청 (sbrk)
- 만약 병합으로도 충분히 큰 블록을 만들지 못했거나, 이미 모든 가용 블록이 병합된 상태라면, 할당기는
sbrk함수를 호출하여 커널에 추가적인 힙 메모리를 요청합니다.
- 만약 병합으로도 충분히 큰 블록을 만들지 못했거나, 이미 모든 가용 블록이 병합된 상태라면, 할당기는
- 3단계: 새 블록 사용
- 할당기는 커널로부터 받은 이 추가 메모리를 하나의 거대한 새 가용 블록으로 만듭니다.
- 이 새 블록을 가용 리스트(free list)에 삽입한 후, 사용자가 요청한 블록을 이 새 블록 안에 배치(place)시킵니다.
9.9.10 가용 블록 병합하기 (Coalescing Free Blocks)
할당기가 할당된 블록을 해제(free)할 때, 방금 해제된 블록의 양옆에 다른 가용 블록이 인접해 있을 수 있습니다.
거짓 단편화 (False Fragmentation)
이렇게 인접한 가용 블록들은 "거짓 단편화(false fragmentation)"라는 현상을 유발할 수 있습니다. 이는 사용 가능한 가용 메모리의 총량은 많지만, 전부 쓸모없는 작은 조각으로 잘게 나뉘어 있는 상태를 말합니다.
- 예시 (그림 9.38):
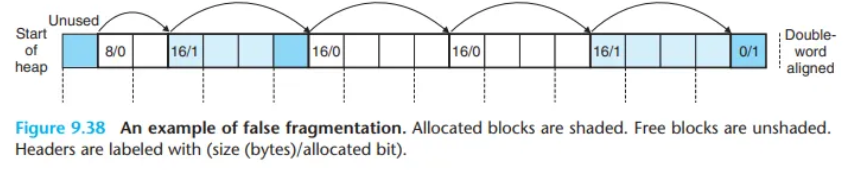
- `[...][3워드 가용 블록][3워드 할당 블록]` 상태에서 `free()`가 호출됩니다.
- `[...][3워드 가용 블록][3워드 가용 블록]`이 됩니다.
- 이 상태에서 **4워드 블록을 요청**하면, **총 6워드**의 가용 공간이 있음에도 불구하고 요청은 **실패**합니다.병합 (Coalescing)
거짓 단편화를 해결하기 위해, 모든 실용적인 할당기는 병합(coalescing)이라는 과정, 즉 인접한 가용 블록들을 합치는(merge) 작업을 반드시 수행해야 합니다.
병합 정책: 언제 합칠 것인가?
- 즉시 병합 (Immediate Coalescing)
- 동작:
free()가 호출될 때마다 매번 인접한 블록을 확인하고 병합합니다. - 장점: 구현이 간단(Straightforward)하며, 상수 시간()에 수행될 수 있습니다.
- 단점: 특정 요청 패턴에서 "스래싱(thrashing)"을 유발할 수 있습니다. (예: 방금 병합했던 블록을 곧바로 다시 분할(split)하고, 또 해제해서 병합하는 불필요한 작업 반복)
- 동작:
- 지연 병합 (Deferred Coalescing)
- 동작:
free()시에는 병합하지 않고, 나중의 특정 시점까지 기다립니다. (예:malloc()요청이 실패했을 때, 힙 전체를 스캔하며 모든 가용 블록을 병합함)
- 동작:
(이후의 논의에서는 즉시 병합을 가정하고 설명하지만, 실제 고성능 할당기들은 종종 지연 병합 방식을 선택합니다.)
9.9.11 경계 태그를 이용한 병합 (Coalescing with Boundary Tags)
할당기가 어떻게 병합(coalescing)을 구현할까요? 우리가 해제하려는 블록을 '현재 블록'이라고 부릅시다.
'다음(next)' 가용 블록(메모리상)을 병합하는 것은 간단하고 효율적입니다. 현재 블록의 헤더가 다음 블록의 헤더를 가리키고, 이 헤더를 검사하여 다음 블록이 가용 상태인지 판별할 수 있습니다. 만약 가용 상태라면, 다음 블록의 크기를 현재 블록 헤더의 크기에 더하기만 하면 되며, 이 블록들은 상수 시간()에 병합됩니다.
이전 블록 병합의 문제점
하지만 '이전(previous)' 블록은 어떻게 병합할까요? 헤더만 있는 암시적 가용 리스트에서는, 힙 전체 리스트를 검색(search)하고, 현재 블록에 도달할 때까지 이전 블록의 위치를 기억하는 것이 유일한 옵션입니다. 이는 free를 호출할 때마다 힙의 전체 크기에 비례하는 시간()이 필요함을 의미합니다.
더 복잡한 가용 리스트 조직을 사용하더라도, 이 검색 시간은 상수 시간이 아닙니다.
해결책: 경계 태그 (Boundary Tags)
Knuth는 경계 태그(boundary tags)라는 영리하고 일반적인 기법을 개발했으며, 이를 통해 상수 시간()에 이전 블록을 병합할 수 있습니다.
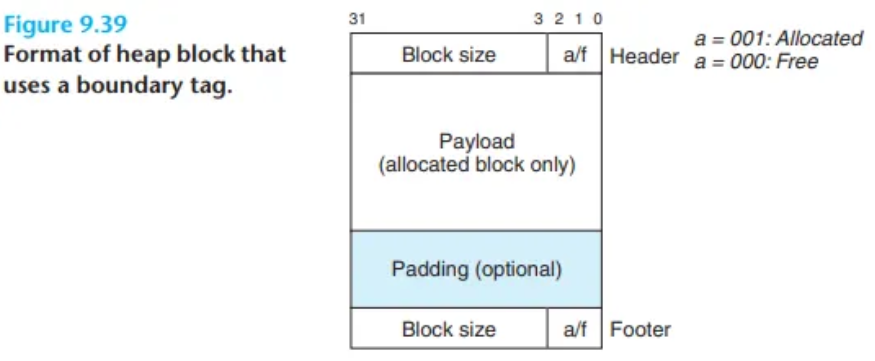
(CSAPP 그림 9.39 참조) 이 아이디어는 각 블록의 끝에 헤더의 복제본(replica)인 꼬리표(footer) (경계 태그)를 추가하는 것입니다. 만약 각 블록이 꼬리표를 포함한다면, 할당기는 현재 블록의 시작 위치에서 항상 한 워드(word) 거리에 있는 이전 블록의 꼬리표를 검사함으로써, 이전 블록의 시작 위치와 상태(할당/가용)를 파악할 수 있습니다.
4가지 병합 시나리오
할당기가 현재 블록을 해제할 때 발생할 수 있는 모든 경우는 다음과 같습니다. (CSAPP 그림 9.40 참조)
- 이전 블록과 다음 블록이 모두 할당됨(Allocated).
- 이전 블록은 할당됨, 다음 블록은 가용(Free).
- 이전 블록은 가용(Free), 다음 블록은 할당됨.
- 이전 블록과 다음 블록이 모두 가용(Free).
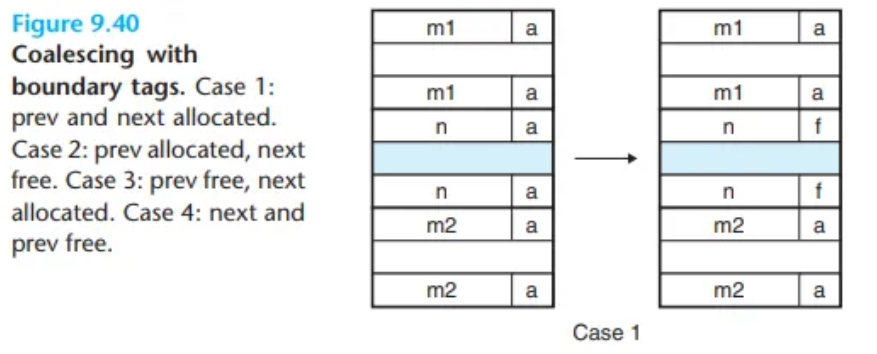
- Case 1 (A/A): 병합 불가. 현재 블록의 상태만 (할당됨 가용)으로 변경합니다.
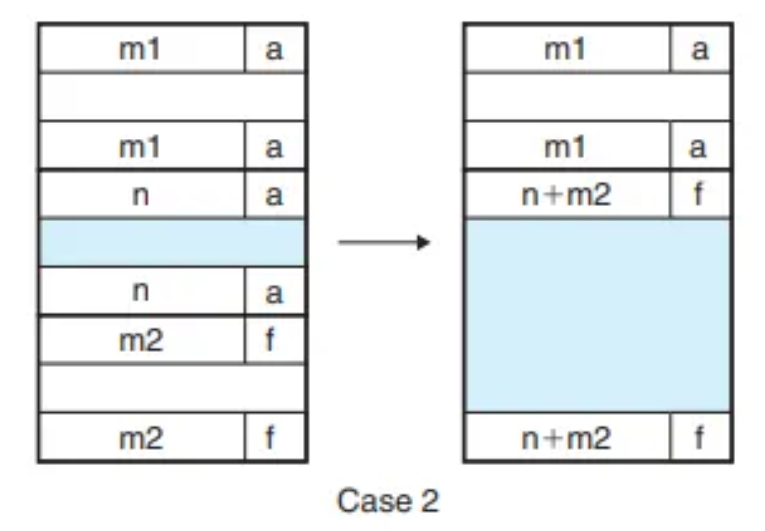
- Case 2 (A/F): (현재 + 다음) 블록을 병합. 현재 블록의 헤더와 다음 블록의 꼬리표를 두 블록의 합친 크기로 업데이트합니다.
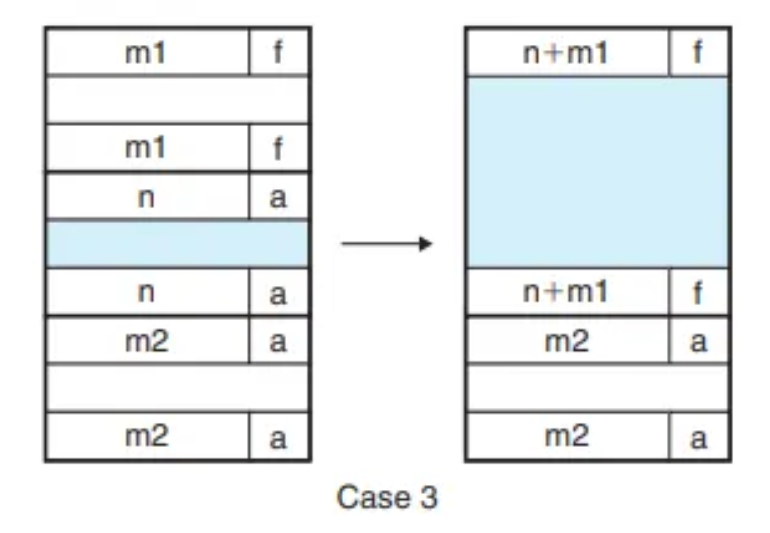
- Case 3 (F/A): (이전 + 현재) 블록을 병합. 이전 블록의 헤더와 현재 블록의 꼬리표를 두 블록의 합친 크기로 업데이트합니다.
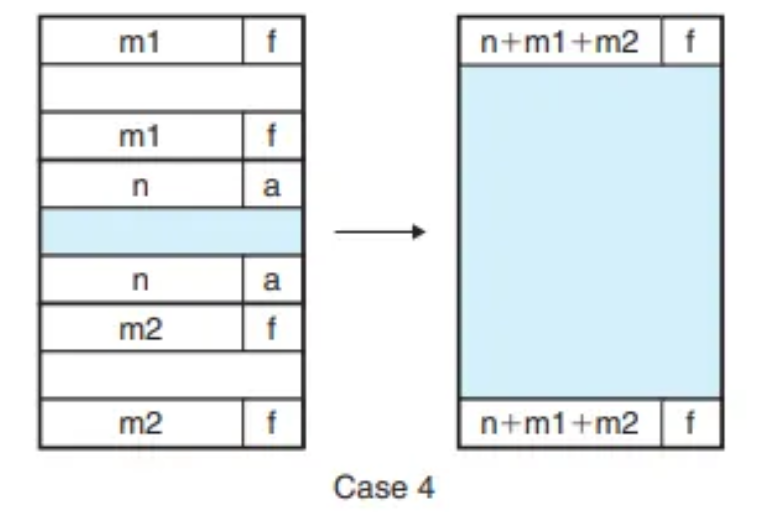
- Case 4 (F/F): (이전 + 현재 + 다음) 세 블록을 병합. 이전 블록의 헤더와 다음 블록의 꼬리표를 세 블록의 합친 크기로 업데이트합니다.
각 케이스 모두, 병합은 상수 시간()에 수행됩니다.
경계 태그의 단점과 최적화
경계 태그는 훌륭한 아이디어지만, 잠재적인 단점이 있습니다. 모든 블록이 헤더와 꼬리표를 둘 다 포함해야 하므로, 애플리케이션이 작은 블록들을 많이 조작할 경우 상당한 메모리 오버헤드(overhead)를 유발할 수 있습니다. (예: 그래프 노드가 몇 워드 크기라면, 헤더와 꼬리표가 할당된 블록의 절반을 차지할 수 있음)
최적화 기법:
다행히, 할당된(Allocated) 블록에서는 꼬리표를 제거할 수 있는 영리한 최적화가 있습니다.
- 관찰: 우리가 병합을 시도할 때, '이전' 블록 꼬리표의 '크기' 정보는 오직 '이전' 블록이 '가용(Free)' 상태일 때만 (Case 3, 4) 필요합니다.
- 해결: 만약 '이전' 블록의 할당/가용 비트(1 bit)를, '현재' 블록 헤더의 여분 비트(예: 하위 3비트 중 하나)에 저장한다면,
- 결과: 할당된 블록은 꼬리표가 필요 없어지고, 그 공간을 페이로드로 쓸 수 있습니다. (단, 가용 블록은 여전히 꼬리표가 필요합니다.)
9.9.12 종합: 간단한 할당기 구현하기
할당기를 만드는 것은 매우 도전적인 작업입니다. 블록 형식, 가용 리스트 형식, 배치(placement), 분할(splitting), 병합(coalescing) 정책 등 수많은 대안이 존재하여 설계 공간(design space)이 넓습니다.
또 다른 어려움은 저수준(low-level) 시스템 프로그래밍의 전형인 오류를 유발하기 쉬운 포인터 캐스팅(pointer casting)과 포인터 연산(pointer arithmetic)에 의존하며, 안전하고 익숙한 타입 시스템의 경계를 벗어나 프로그래밍해야 한다는 점입니다.
C++이나 Java와 같은 고수준 언어에 익숙한 학생들은 이런 스타일의 프로그래밍을 처음 접했을 때 개념적인 벽(conceptual wall)에 부딪히곤 합니다.
이 장벽을 넘을 수 있도록, 이 섹션에서는 암시적 가용 리스트(implicit free list)와 즉시 경계 태그 병합(immediate boundary-tag coalescing)에 기반한 간단한 할당기 구현을 단계별로 살펴볼 것입니다.
이 할당기의 최대 블록 크기는 입니다. 코드는 32비트(gcc -m32) 또는 64비트(gcc -m64) 프로세스에서 수정 없이 실행되는 64-bit clean 코드입니다.
간단한 할당기의 전체 구조

1. memlib.c: 메모리 시스템 모델
(CSAPP 그림 9.41 참조) 여기서 구현할 할당기(mm.c)는 시스템의 실제 malloc과 충돌하는 것을 피하기 위해, memlib.c 패키지가 제공하는 메모리 시스템 모델 위에서 동작합니다.
mem_init(): 힙(heap)으로 사용될 가상 메모리를, double-word로 정렬된 거대한 바이트 배열로 모델링합니다.mem_heap~mem_brk: (할당기가 커널로부터) 할당받은 가상 메모리 영역입니다.mem_brk이후: 아직 할당받지 않은 가상 메모리 영역입니다.mem_sbrk(incr):- 할당기(
mm.c)가 추가 힙 메모리를 요청하기 위해 이 함수를 호출합니다. - 시스템
sbrk와 동일한 인터페이스와 의미를 가지지만, 힙을 축소시키는 요청은 거부합니다.
- 할당기(
2. mm.c: 할당기 인터페이스
실제 할당기 로직은 mm.c 파일에 구현되며, 애플리케이션(사용자 프로그램)에 다음 세 가지 함수를 제공(export)합니다.
extern int mm_init(void);- 할당기를 초기화합니다. 성공 시 0, 실패 시 -1을 반환합니다.
extern void *mm_malloc (size_t size);- 시스템
malloc함수와 인터페이스 및 의미가 동일합니다.
- 시스템
extern void mm_free (void *ptr);- 시스템
free함수와 인터페이스 및 의미가 동일합니다.
- 시스템
3. mm.c: 내부 구현 상세
- 블록 형식: (이전 섹션의 그림 9.39) 경계 태그(Boundary Tags)를 사용합니다. (헤더 + 페이로드 + 꼬리표)
- 최소 블록 크기: 16바이트입니다.
- 가용 리스트 조직: 암시적 가용 리스트(Implicit Free List)를 사용합니다.
힙의 고정적인 구조 (Heap Structure)
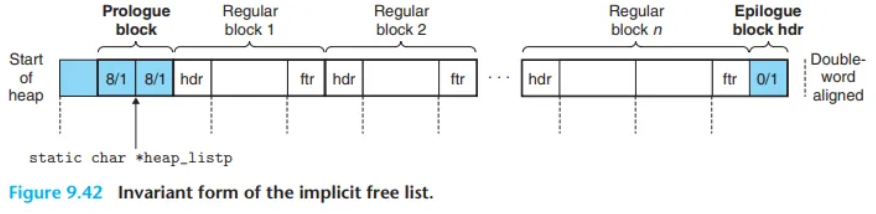
(CSAPP 그림 9.42 참조) 힙은 항상 다음과 같은 고정된 형태를 유지합니다.
[패딩] - [프롤로그 블록] - [일반 블록들...] - [에필로그 블록]
- 정렬 패딩 (Alignment Padding)
- 힙의 맨 첫 번째 워드(4B)입니다.
- Double-word 정렬을 맞추기 위한 미사용 패딩입니다.
- 프롤로그 블록 (Prologue Block)
- 패딩 바로 뒤에 오는 8바이트 크기의 할당된(Allocated) 블록입니다.
- 헤더와 꼬리표로만 구성됩니다.
- 초기화(
mm_init) 시 생성되며, 절대 해제되지 않습니다.
- 일반 블록 (Regular Blocks)
mm_malloc이나mm_free에 의해 생성되는 0개 이상의 블록들입니다.
- 에필로그 블록 (Epilogue Block)
- 힙의 맨 마지막에 위치하는 크기가 0인 할당된(Allocated) 블록입니다.
- 헤더로만 구성됩니다.
핵심:프롤로그와 에필로그 블록은 항상 '할당된' 상태로 존재함으로써, free() 시 병합 (Coalescing)을 수행할 때 힙의 맨 처음이나 맨 끝인지 검사할 필요가 없는 경계 조건(Edge Condition)을 제거하는 트릭입니다.
heap_listp (전역 변수):
- 할당기가 사용하는 유일한
static전역 변수입니다. - 항상 프롤로그 블록을 가리킵니다.
가용 리스트 조작을 위한 기본 상수 및 매크로
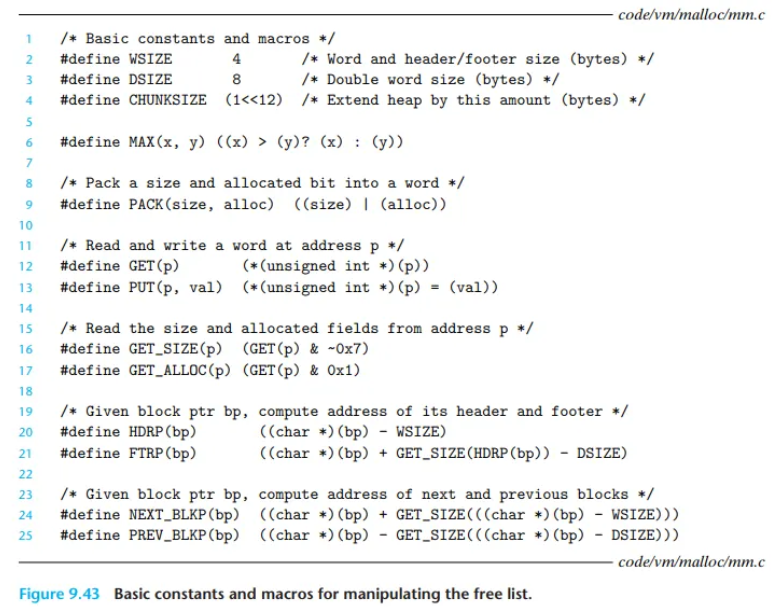
malloc 구현 코드는 복잡한 포인터 연산과 캐스팅을 많이 사용하기 때문에, 이를 단순화하고 가독성을 높이기 위해 매크로(Macro) 세트를 정의합니다.
1. 기본 상수 (Basic constants)
WSIZE(라인 2): 워드(Word)이자 헤더/꼬리표의 크기 (4 바이트).DSIZE(라인 3): 더블 워드(Double word) 크기 (8 바이트). 8바이트 정렬(alignment)의 기준이 됩니다.CHUNKSIZE(라인 4): 힙(heap)을 확장할 때의 기본 크기 ( 바이트, 즉 4KB).
2. 헤더/꼬리표 조작 매크로
PACK(size, alloc)(라인 9)- 역할: 블록의
size와alloc비트(1=할당, 0=가용)를 비트OR연산(|)으로 결합합니다. - 목적: 4바이트(1워드)짜리 헤더(Header) 또는 꼬리표(Footer)에 크기와 상태 정보를 동시에 압축해서 저장할 값을 만듭니다.
- 역할: 블록의
GET(p)(라인 12) /PUT(p, val)(라인 13)- 역할:
GET은p주소의 워드(4바이트) 값을 읽고,PUT은p주소에val값을 씁니다. - 핵심 (캐스팅):
p는 보통(void *)포인터이므로 직접 역참조(p)할 수 없습니다. 따라서(unsigned int *)로 캐스팅하여 4바이트 워드 단위로 메모리를 읽고 씁니다.
- 역할:
GET_SIZE(p)(라인 16) /GET_ALLOC(p)(라인 17)- 역할:
p주소에 있는 헤더/꼬리표 값에서 '크기'와 '할당 비트'를 각각 추출합니다. GET_SIZE: 비트 마스킹(& ~0x7)을 통해 하위 3비트(플래그 비트)를 제거하고 순수한 블록 크기만 반환합니다. (~0x7=...1111 1000)GET_ALLOC: 비트 마스킹(& 0x1)을 통해 최하위 1비트(할당 비트)만 추출하여 반환합니다.
- 역할:
3. 블록 포인터(bp) 조작 매크로
※ 중요: 여기서 bp는 블록의 시작점(헤더)이 아니라, 헤더 바로 뒤의 첫 번째 페이로드 바이트(payload byte)를 가리키는 블록 포인터(block pointer)입니다. mm_malloc이 사용자에게 반환하는 주소입니다.
<-- (이전 블록) --> | HEADER | PAYLOAD | FOOTER | <-- (다음 블록) -->
| (WSIZE) | (bp가 여기를 가리킴) | (WSIZE) |
^ ^ ^
| | |
HDRP(bp) bp FTRP(bp)HDRP(bp)(라인 20)- 역할: '헤더 포인터(Header Pointer)'를 반환합니다.
- 계산:
bp주소에서WSIZE(4바이트)만큼 앞으로 이동하여 헤더의 시작 주소를 계산합니다.
FTRP(bp)(라인 21)- 역할: '꼬리표 포인터(Footer Pointer)'를 반환합니다.
- 계산:
HDRP(bp)에서 블록 크기를 읽은 뒤,bp주소에서 (블록 전체 크기 - 헤더/꼬리표 크기)만큼 뒤로 이동하여 꼬리표의 시작 주소를 계산합니다.
NEXT_BLKP(bp)(라인 24)- 역할: 다음 블록의 블록 포인터(bp)를 반환합니다.
- 계산:
HDRP(bp)에서 현재 블록의 크기를 읽은 뒤,bp주소에서 (현재 블록 크기)만큼 뒤로 이동하여 다음 블록의 페이로드 시작 주소를 계산합니다.
PREV_BLKP(bp)(라인 25)- 역할: 이전 블록의 블록 포인터(bp)를 반환합니다.
- 계산:
bp주소에서DSIZE(8바이트)만큼 앞으로 이동하여 이전 블록의 꼬리표 주소로 갑니다.GET_SIZE로 이전 블록의 크기를 읽습니다.bp주소에서 (이전 블록 크기)만큼 앞으로 이동하여 이전 블록의 페이로드 시작 주소를 계산합니다.
매크로 조합 (예시)
이 매크로들은 복잡한 포인터 연산을 숨기고 조합하여 사용할 수 있습니다. 예를 들어, 다음 블록의 크기를 알고 싶다면 다음과 같이 작성합니다.
size_t size = GET_SIZE(HDRP(NEXT_BLKP(bp)));초기 가용 리스트 생성하기
애플리케이션은 mm_malloc이나 mm_free를 호출하기 전에, 반드시 mm_init 함수(그림 9.44)를 호출하여 힙(heap)을 초기화해야 합니다.
mm_init 함수 (그림 9.44)

mm_init 함수는 메모리 시스템(mem_sbrk)으로부터 4 워드(words)를 가져와서, 비어있는 가용 리스트를 생성하도록 초기화합니다 (라인 4–10). 이 4워드는 [정렬 패딩], [프롤로그 헤더], [프롤로그 꼬리표], [에필로그 헤더]를 만드는 데 사용됩니다.
그 후, extend_heap 함수(그림 9.45)를 호출하여 힙을 CHUNKSIZE (e.g., 4KB) 바이트만큼 확장하고, 이 공간을 '초기 가용 블록(initial free block)'으로 만듭니다. 이 시점에서 할당기는 초기화가 완료되며, 애플리케이션의 할당/해제 요청을 받을 준비가 됩니다.
extend_heap 함수 (그림 9.45)

- 그림 설명
-
extend_heap호출 직전 (초기 상태)(힙 시작) ... | 프롤로그 꼬리표 | 에필로그 헤더 | <--- (커널 영역) | (Size=8, A=1) | (Size=0, A=1) | ^ ^ | | (bp - WSIZE) 위치 mem_brk 위치 -
bp = mem_sbrk(size)호출 (라인 8)<------------- size 바이트만큼 확장됨 -------------> ... | 프롤로그 꼬리표 | 에필로그 헤더 | (새로 할당된 메모리 영역) | | (Size=8, A=1) | (Size=0, A=1) | | ^ ^ | | HDRP(bp) bp (페이로드 시작)3. 새 가용 블록 초기화 (라인 12-14)
A.
PUT(HDRP(bp), PACK(size, 0));(라인 12)... | 프롤로그 꼬리표 | 새 가용 블록 헤더 | (페이로드 영역) ... | (Size=8, A=1) | (Size=size, A=0) | ^ ^ | | HDRP(bp) bpB.
PUT(FTRP(bp), PACK(size, 0));(라인 13)... | 새 헤더 | (페이로드 영역 ... ) | 새 가용 블록 꼬리표 | | (Size=size, A=0)| | (Size=size, A=0) | ^ ^ ^ | | | HDRP(bp) bp FTRP(bp)C.
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1));(라인 14)... | 새 헤더 | ( ... ) | 새 꼬리표 | 신규 에필로그 헤더 | <--- (새로운 힙 끝) | (Size=size, A=0)| | (Size=size, A=0) | (Size=0, A=1) | ^ ^ ^ ^ | | | | HDRP(bp) bp FTRP(bp) HDRP(NEXT_BLKP(bp))4.
coalesce(bp)호출 (라인 17)이제
extend_heap은coalesce함수를 호출합니다.
coalesce는 bp의 "이전" 블록을 확인합니다.
bp - DSIZE 위치에서 "이전 블록의 꼬리표"를 읽습니다.
이 꼬리표는 프롤로그 꼬리표 (Size=8, A=1)입니다.
이전 블록이 "할당됨(A=1)" 상태이므로, 왼쪽 병합은 일어나지 않습니다.
coalesce 함수는 병합 없이 bp를 그대로 반환합니다.
-
extend_heap 함수는 다음 두 가지 상황에서 호출됩니다.
- 힙이 처음 초기화될 때 (
mm_init내부에서) mm_malloc이 적절한 가용 블록을 찾지 못했을 때
정렬 유지 (라인 7–9):extend_heap은 8바이트 정렬을 유지하기 위해, 요청된 크기(size)를 항상 가장 가까운 8바이트(double-word, 2워드)의 배수로 '반올림(rounds up)'합니다. 그리고 이 반올림된 크기만큼 mem_sbrk를 호출하여 힙 공간을 추가로 요청합니다.
새 가용 블록 생성 (라인 12–17) - (중요한 부분):
힙은 double-word 경계로 정렬되어 시작하고, extend_heap도 8바이트의 배수로만 힙을 확장합니다. 따라서 mem_sbrk는 항상 (이전) 에필로그 블록 헤더 바로 뒤에서 시작하는 정렬된 메모리 청크를 반환합니다.
- 이 (이전) 에필로그 헤더는 새로운 가용 블록의 헤더가 됩니다 (라인 12).
- 새로 가져온 메모리 청크의 맨 마지막 워드는 '새로운' 에필로그 블록 헤더가 됩니다 (라인 14).
- 마지막으로, 힙이 확장되기 직전의 마지막 블록이 가용(Free) 상태였을 가능성을 고려하여
coalesce(병합) 함수를 호출합니다 (라인 17). 만약 이전 블록이 가용 상태였다면, 방금 생성한 새 가용 블록과 병합하여 더 큰 단일 가용 블록을 만듭니다.
블록 해제 및 병합하기 (Freeing and Coalescing Blocks)

애플리케이션은 mm_free 함수(그림 9.46)를 호출하여 이전에 할당된 블록을 해제합니다. 이 함수는 요청된 블록(bp)을 해제(free)한 다음, 9.9.11절에서 설명한 경계 태그(boundary-tags) 병합 기법을 사용하여 인접한 가용 블록들을 병합합니다.
coalesce (병합) 헬퍼 함수의 코드는 (이전 그림 9.40에서 설명한) 4가지 케이스(Case 1~4)를 그대로 구현한(straightforward implementation) 것입니다.
핵심적인 설계 트릭 (The Subtle Aspect)
여기에는 다소 미묘한(subtle) 측면이 하나 있습니다.
우리가 선택한 가용 리스트 형식—즉, 항상 '할당됨(allocated)'으로 표시되는 프롤로그(prologue) 블록과 에필로그(epilogue) 블록을 둔 것—은 free 하려는 블록(bp)이 힙(heap)의 맨 처음이나 맨 끝에 위치하는 까다롭고 성가신 경계 조건(edge conditions)을 무시할 수 있게 해줍니다.
만약 이 특별한 '더미(dummy)' 블록들이 없다면, free를 요청할 때마다 매번 이 희귀한 경계 조건들(if (bp == heap_start) 등)을 확인해야 하므로, 코드가 더 지저분해지고(messier), 오류에 더 취약하며(error prone), 더 느려졌을(slower) 것입니다.
- mm_free 설명
이 함수의 목적은mm_free함수 동작 설명bp가 가리키는 '할당된(Allocated)' 블록을 '가용(Free)' 상태로 변경하고, 인접한 다른 가용 블록과 병합(Coalescing)하는 것입니다.size_t size = GET_SIZE(HDRP(bp));-
동작:
free하려는 블록의 전체 크기를 알아냅니다. -
해석:
1.bp는 페이로드(payload) 주소입니다.
2.HDRP(bp): 이 블록의 헤더(Header) 주소를 찾습니다.
3.GET_SIZE(...): 헤더에 저장된 값(e.g.,0x19, 즉 25)에서 할당 비트를 제거(& ~0x7)하고, 순수한 크기(e.g., 24)만 가져옵니다.
PUT(HDRP(bp), PACK(size, 0)); -
동작: 헤더(Header)의 상태를 '가용(Free)'으로 변경합니다.
-
해석:
1.PACK(size, 0):(size | 0)연산을 합니다. (e.g.,24 | 0 = 24)
2. 이 값은 "크기는size이고, 상태는 가용(0)이다"라는 새로운 헤더 값입니다.
3.PUT(...): 이 새로운 값을HDRP(bp)(헤더 주소)에 덮어씁니다. (e.g.,0x190x18)
PUT(FTRP(bp), PACK(size, 0)); -
동작: 꼬리표(Footer)의 상태도 '가용(Free)'으로 변경합니다.
-
해석:
1.FTRP(bp): 이 블록의 꼬리표(Footer) 주소를 찾습니다.
2.PUT(...): 헤더에 썼던 값과 동일한 값(size | 0)을 꼬리표에 덮어씁니다.
3. 이제 이 블록은 헤더와 꼬리표가 모두 '가용' 상태임을 나타냅니다. (경계 태그 완성)
coalesce(bp); -
동작: 병합(Coalescing) 헬퍼 함수를 호출합니다.
-
해석:
mm_free의 핵심 작업입니다.coalesce함수는 방금 '가용' 상태가 된 이 블록(bp)의 '이전' 블록과 '다음' 블록을 확인합니다.- 만약 인접한 블록도 '가용' 상태라면, 그 블록들을 하나로 합쳐서 더 큰 가용 블록으로 만듭니다.
- (이때
coalesce함수는 프롤로그/에필로그 블록 덕분에 경계 검사를 할 필요가 없습니다.)
-
- coalesce 설명
이 함수의 목적은 방금 '가용(Free)' 상태가 된 블록(coalesce(병합) 함수 동작 설명bp)의 양옆을 확인하여, 인접한 블록도 가용 상태라면 하나의 더 큰 가용 블록으로 합치는 것입니다. 이 코드는 경계 태그(Boundary Tag)를 사용하기 때문에 모든 확인과 병합이 상수 시간()에 일어납니다.1. 사전 준비 (라인 3-5)
coalesce함수는 4가지 병합 시나리오를 확인하기 전에,bp의 양옆 블록 상태를 미리 확인합니다.-
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));(라인 3)- 이전(Previous) 블록의 할당 상태를 확인합니다.
PREV_BLKP(bp)이전 블록bpFTRP(...)이전 블록의 꼬리표(Footer) 주소GET_ALLOC(...)할당 비트(1=할당됨,0=가용)를 읽어옵니다.
-
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));(라인 4)- 다음(Next) 블록의 할당 상태를 확인합니다.
NEXT_BLKP(bp)다음 블록bpHDRP(...)다음 블록의 헤더(Header) 주소GET_ALLOC(...)할당 비트를 읽어옵니다.
-
size_t size = GET_SIZE(HDRP(bp));(라인 5)
- 현재(Current) 블록(방금free된)의 크기를 가져옵니다.
2. 4가지 병합 시나리오 (라인 7-27)
이제
prev_alloc과next_alloc변수를 이용해 4가지 경우를 처리합니다.Case 1:
if (prev_alloc && next_alloc)(라인 7) -
상태:
[ 할당됨 ] | [ 현재 (Free) ] | [ 할당됨 ] -
동작: 양옆이 모두 사용 중이므로 병합(Coalescing)이 불가능합니다.
-
처리:
mm_free에서 이미 현재 블록을 '가용'으로 만들었으므로, 아무것도 할 필요가 없습니다.bp를 그대로 반환합니다.Case 2:
else if (prev_alloc && !next_alloc)(라인 11) -
상태:
[ 할당됨 ] | [ 현재 (Free) ] | [ 다음 (Free) ] -
동작: 현재 블록과 다음 블록을 병합합니다.
-
처리:
1.size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
- '다음' 블록의 크기를 읽어와 '현재' 블록의size에 더합니다.
2.PUT(HDRP(bp), PACK(size, 0));
- '현재' 블록의 헤더를 이 새로운 전체size와 '가용(0)' 상태로 덮어씁니다.
3.PUT(FTRP(bp), PACK(size, 0));
-FTRP(bp)는 (1)에서 갱신된size를 사용하므로, '다음' 블록의 꼬리표 위치를 가리킵니다.
- 이 꼬리표를 새로운 전체size와 '가용(0)' 상태로 덮어씁니다.
4.bp는 변경 없이 그대로 반환합니다. (새 블록의 시작점은bp가 맞음)Case 3:
else if (!prev_alloc && next_alloc)(라인 18) -
상태:
[ 이전 (Free) ] | [ 현재 (Free) ] | [ 할당됨 ] -
동작: 이전 블록과 현재 블록을 병합합니다.
-
처리:
1.size += GET_SIZE(HDRP(PREV_BLKP(bp)));
- '이전' 블록의 크기를 읽어와 '현재' 블록의size에 더합니다.
2.PUT(FTRP(bp), PACK(size, 0));
- '현재' 블록의 꼬리표를 이 새로운 전체size와 '가용(0)' 상태로 덮어씁니다.
3.PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
- '이전' 블록의 헤더를 이 새로운 전체size와 '가용(0)' 상태로 덮어씁니다.
4.bp = PREV_BLKP(bp);
- (중요) 이제 합쳐진 더 큰 블록의bp는 '이전' 블록의bp이므로,bp포인터를 '이전' 블록의bp로 갱신합니다.Case 4:
else(라인 24) -
상태:
[ 이전 (Free) ] | [ 현재 (Free) ] | [ 다음 (Free) ] -
동작: 3개 블록을 모두 병합합니다.
-
처리:
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));(주: FTRP가 아닌 HDRP(NEXT...)여야 함)- '이전' 블록과 '다음' 블록의 크기를 모두 읽어와 '현재'
size에 더합니다.
- '이전' 블록과 '다음' 블록의 크기를 모두 읽어와 '현재'
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));- '이전' 블록의 헤더를 이 최종
size와 '가용(0)' 상태로 덮어씁니다.
- '이전' 블록의 헤더를 이 최종
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));- '다음' 블록의 꼬리표를 이 최종
size와 '가용(0)' 상태로 덮어씁니다.
- '다음' 블록의 꼬리표를 이 최종
bp = PREV_BLKP(bp);- 3개 블록이 합쳐진 새 블록의
bp는 '이전' 블록의bp이므로,bp포인터를 갱신합니다.
- 3개 블록이 합쳐진 새 블록의
-
블록 할당하기 (Allocating Blocks)
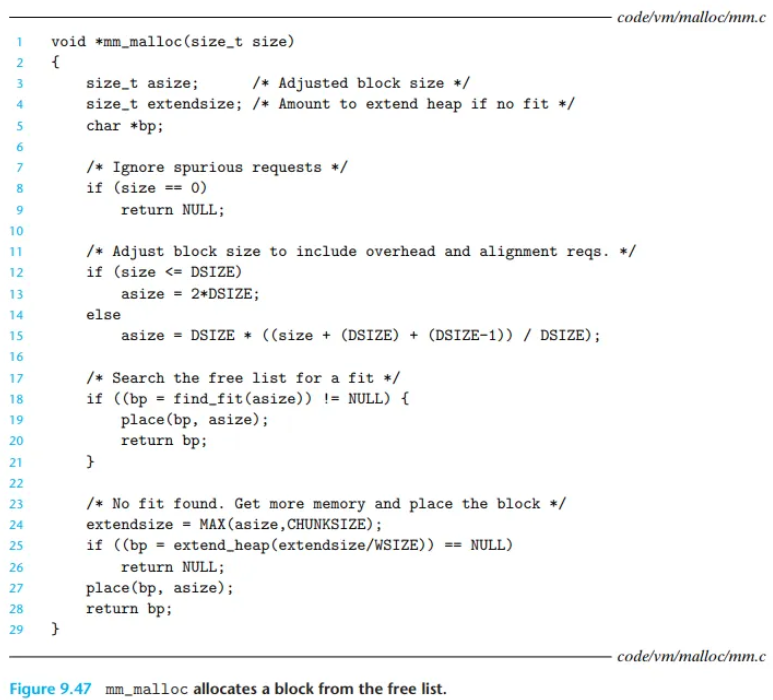
애플리케이션은 mm_malloc 함수(그림 9.47)를 호출하여 size 바이트의 메모리 블록을 요청합니다.
mm_malloc은 요청을 받은 후, 다음 3단계를 거칩니다.
1. 블록 크기 조정 (Adjusting Block Size)
할당기는 헤더(Header)와 꼬리표(Footer)를 위한 오버헤드(overhead) 공간을 추가하고, 8바이트(double-word) 정렬 요구사항을 만족시키기 위해 사용자가 요청한 size를 조정해야 합니다.
- 최소 블록 크기 (라인 12-13):
- 최소 블록 크기는 16바이트로 강제됩니다.
- (이유: 8바이트는 정렬 요구사항을 만족하기 위해, 8바이트는 헤더와 꼬리표의 오버헤드를 위해 필요합니다.)
- 일반적인 규칙 (라인 15):
- 8바이트보다 큰 요청에 대해서는, (1) 오버헤드 바이트(e.g., 8바이트)를 더한 뒤, (2) 가장 가까운 8의 배수로 반올림(round up)합니다.
2. 가용 리스트 검색 및 배치
크기 조정이 끝나면, 할당기는 적절한 가용 블록을 검색합니다.
- Fit 찾기 (라인 18):
find_fit함수를 호출하여 가용 리스트를 검색합니다.
- Fit 찾은 경우 (라인 19):
place함수를 호출하여 찾은 가용 블록에 요청된 블록을 배치(place)합니다.- (선택 사항) 만약 가용 블록이 요청보다 커서 공간이 남는다면, 블록을 분할(split)합니다.
- 새로 할당된 블록의 주소(
bp)를 반환합니다.
3. Fit을 찾지 못한 경우 (힙 확장)
- 힙 확장 (라인 24-26):
- 가용 리스트에서 적절한 블록을 찾지 못하면,
extend_heap함수를 호출하여 힙(heap)을 확장하고 새로운 가용 블록을 받아옵니다.
- 가용 리스트에서 적절한 블록을 찾지 못하면,
- 배치 (라인 27):
- 방금 새로 받은 이 가용 블록에 요청된 블록을 배치(place)합니다.
- (선택 사항) 이 새 블록도 필요하면 분할(split)합니다.
- 새로 할당된 블록의 주소(
bp)를 반환합니다.
9.9.13 명시적 가용 리스트 (Explicit Free Lists)
암시적 리스트의 한계
암시적 가용 리스트(Implicit free list)는 할당기의 기본 개념을 소개하는 간단한 방법입니다.
하지만 블록 할당 시간이 힙(heap)의 전체 블록 수 (할당된 블록 + 가용 블록)에 비례()하기 때문에, 암시적 리스트는 범용(general-purpose) 할당기로는 적합하지 않습니다. (물론 힙 블록 수가 적다고 미리 알려진 특수 목적 할당기에는 괜찮을 수 있습니다.)
명시적 리스트의 구조 (Explicit List)
더 나은 접근 방식은 가용 블록(free block)들만 따로 명시적(explicit) 자료구조로 관리하는 것입니다.
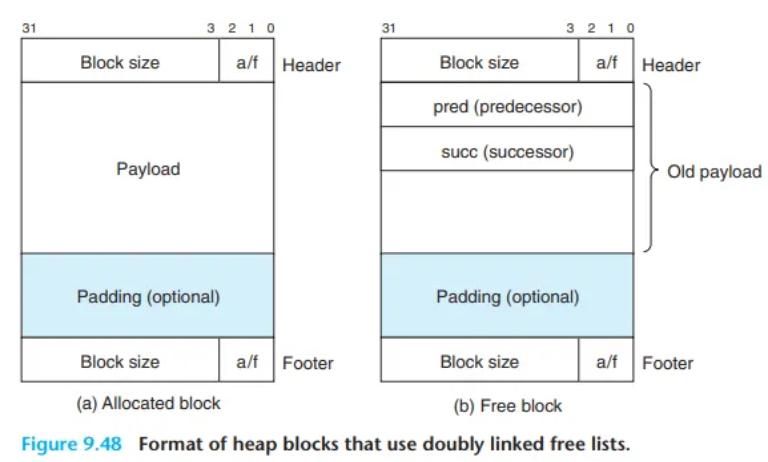
- 핵심 아이디어: 어차피 가용 블록의 본체(페이로드)는 프로그램이 사용하지 않으므로, 이 자료구조를 구현하는 포인터(pointer)들을 가용 블록의 본체(body) 내부에 저장하면 됩니다.
- 구현: (그림 9.48 참조) 각 가용 블록 내부에
pred(predecessor, 이전 노드)와succ(successor, 다음 노드) 포인터를 포함시켜, 힙(heap)을 이중 연결 가용 리스트(doubly linked free list)로 구성할 수 있습니다.
성능 및 정렬 정책
- 할당 성능 (Allocation Time):
- 이중 연결 리스트를 사용하면, First-fit 할당 시간이 (힙의 '전체' 블록 수에 비례)하는 것에서 (힙의 '가용' 블록 수에 비례)하는 것으로 줄어듭니다.
- 해제 성능 (Free Time) 및 정렬 정책:
- 블록을 해제(
free)하는 시간은 리스트의 블록을 정렬하는 정책에 따라 선형 시간()이 될 수도, 상수 시간()이 될 수도 있습니다.
- 블록을 해제(
- LIFO (Last-In First-Out) 순서:
- 정책: 새로 해제된 블록을 리스트의 맨 앞(beginning)에 삽입합니다.
- 성능:
free작업은 상수 시간()에 수행될 수 있습니다. (경계 태그를 사용하면) 병합(coalescing) 또한 상수 시간에 수행될 수 있습니다.
- 주소 순서 (Address order):
- 정책: 리스트의 각 블록이 다음 블록보다 항상 더 낮은 주소를 갖도록 정렬하는 방식입니다.
- 성능:
free작업 시 적절한 삽입 위치(predecessor)를 찾기 위해 선형 시간() 검색이 필요합니다. - 장점 (Trade-off): 이 방식의 장점은 LIFO 순서 방식보다 더 나은 메모리 사용률(utilization)을 보이며, Best-fit의 사용률에 근접한다는 것입니다.
명시적 리스트의 단점
명시적 리스트의 일반적인 단점은, 가용 블록이 헤더/꼬리표뿐만 아니라 이 모든 필수 포인터들(pred, succ)을 담을 만큼 충분히 커야 한다는 것입니다.
이는 최소 블록 크기(minimum block size)를 증가시키고 (예: 헤더(4) + pred(8) + succ(8) + 꼬리표(4) = 24바이트), 내부 단편화(internal fragmentation)의 가능성을 높입니다.
9.9.14 분리된 가용 리스트 (Segregated Free Lists)
지금까지 보았듯이, 단일 연결 리스트를 사용하는 할당기는 블록을 할당하는 데 가용 블록의 수에 비례하는 선형 시간()이 필요합니다.
할당 시간을 줄이기 위한 대중적인 접근 방식은 분리 저장소(segregated storage)라고 알려진 기법입니다. 이는 여러 개의 가용 리스트를 유지 관리하며, 각 리스트는 거의 비슷한 크기(roughly the same size)의 블록들만 담도록 하는 것입니다.
핵심 아이디어: 크기 클래스 (Size Classes)
일반적인 아이디어는, 가능한 모든 블록 크기의 집합을 크기 클래스(size classes)라고 불리는 동등 클래스(equivalence classes)로 분할(partition)하는 것입니다.
크기 클래스를 정의하는 방법은 다양합니다. 예를 들어, 블록 크기를 2의 거듭제곱(powers of 2)으로 분할할 수 있습니다:
{1},{2},{3, 4},{5–8}, ...,{1025–2048},{2049–4096},{4097–∞}
또는 작은 블록들은 자신만의 클래스를 할당하고, 큰 블록들만 2의 거듭제곱으로 분할할 수도 있습니다:
{1},{2},{3}, ...,{1023},{1024},{1025–2048},{2049–4096},{4097–∞}
할당기의 동작
할당기는 크기가 증가하는 순서대로 정렬된 가용 리스트의 배열을 유지 관리합니다. (각 크기 클래스당 하나의 가용 리스트)
- 할당기가
n크기의 블록을 필요로 할 때,n에 해당하는 적절한 크기 클래스의 가용 리스트를 검색합니다. - 만약 그 리스트에서 맞는 블록을 찾지 못하면, 그다음으로 큰 크기 클래스의 리스트를 검색합니다.
- 이 과정을 반복합니다.
이 방식은 크기 클래스를 어떻게 정의하는지, 병합(coalescing)이나 분할(splitting)을 언제 수행하는지 등에 따라 수십 가지의 변형(variants)이 존재합니다. 이 개념을 이해하기 위해, 단순 분리 저장소(Simple segregated storage)와 분리 맞춤(Segregated fits)이라는 두 가지 기본 접근 방식을 설명할 것입니다.
단순 분리 저장소 (Simple Segregated Storage)
이 방식은 '분리된 가용 리스트'의 가장 간단한 구현체입니다.
1. 동작 방식 (How it works)
- 고정 크기 블록:
- 각 '크기 클래스(size class)'의 가용 리스트는 모두 동일한 크기의 블록만 포함합니다.
- 이 크기는 해당 클래스에서 가장 큰 요소의 크기로 고정됩니다.
- (예:
{17-32}클래스 리스트는 17, 20, 24바이트 블록이 섞여 있는 것이 아니라, 오직 32바이트짜리 블록들로만 구성됩니다.)
malloc(할당)- 요청한 크기에 맞는 크기 클래스(e.g.,
{17-32}) 리스트를 확인합니다. - 리스트가 비어있지 않다면(Not empty), 리스트의 첫 번째 블록을 꺼내어 통째로(in its entirety) 반환합니다.
- 블록을 절대 분할(Split)하지 않습니다.
- 리스트가 비어있다면(Empty), OS로부터 고정된 크기의 새 메모리 청크(chunk) (e.g., 4KB)를 요청합니다.
- 이 청크를 해당 크기 클래스의 블록 크기(e.g., 32바이트)로 똑같이 쪼개어, 이 블록들을 모두 연결 리스트로 만들어 해당 리스트에 채워 넣고, 그중 하나를 반환합니다.
- 요청한 크기에 맞는 크기 클래스(e.g.,
free(해제)- 해제할 블록의 크기에 맞는 크기 클래스 리스트를 찾습니다.
- 해당 리스트의 맨 앞(front)에 이 블록을 단순히 삽입(insert)합니다. (LIFO)
- 블록을 절대 병합(Coalesce)하지 않습니다.
2. 장점 (Advantages)
- 속도:
malloc과free모두 리스트의 맨 앞에서 블록을 빼거나 넣기만 하면 되므로, 매우 빠른 상수 시간() 작업입니다.
- 매우 적은 메모리 오버헤드:
- 이 방식은 분할(Splitting)도 없고 병합(Coalescing)도 없습니다.
- (1) 병합을 안 하므로, 꼬리표(Footer)가 필요 없습니다.
- (2) 병합을 안 하므로, 할당/가용 상태 비트도 필요 없습니다.
- (3) 한 리스트의 블록 크기는 모두 동일하므로, 블록 주소만 알면 크기를 유추할 수 있어 헤더(Header)조차 필요 없습니다.
- 결과: 할당된(Allocated) 블록은 헤더와 꼬리표가 전혀 필요 없는(zero overhead) 순수 페이로드(payload)가 됩니다.
- 초소형 최소 블록 크기:
free작업(LIFO)은 이중 연결 리스트가 아닌 단일 연결 리스트(Singly linked list)만으로도 충분합니다.- 따라서 가용(Free) 블록에 필요한 필드는 오직
succ(next) 포인터 1워드(one-word)뿐입니다. - 즉, 최소 블록 크기가 1워드(e.g., 4바이트)에 불과합니다.
3. 단점 (Disadvantages)
이 단순함은 심각한 단편화(fragmentation)를 유발합니다.
- 내부 단편화 (Internal Fragmentation)
- 분할(Splitting)을 절대 하지 않기 때문에 발생합니다.
- (예:
{17-32}클래스 리스트에서malloc(17)을 요청하면 32바이트 블록을 통째로 줘야 하므로, 15바이트가 할당된 블록 내부에서 낭비됩니다.)
- 외부 단편화 (External Fragmentation)
- 병합(Coalescing)을 절대 하지 않기 때문에 발생합니다.
- (예: 32바이트짜리 가용 블록 두 개가 메모리상에 연속으로 붙어 있어도,
malloc(40)요청을 처리하지 못합니다.)
분리 맞춤 (Segregated Fits)
이 접근 방식은 "단순 분리 저장소"의 단점(단편화)을 보완한, 더 정교하고 실용적인 방법입니다.
1. 동작 방식 (How it works)
- 자료구조:
- "단순 분리 저장소"와 마찬가지로, 크기 클래스(size class)별로 가용 리스트의 배열을 유지 관리합니다.
- (핵심 차이점): 각 리스트는 '고정된 크기'의 블록이 아니라, 해당 크기 클래스에 속하는 서로 다른 크기(potentially different-size)의 블록들을 포함할 수 있습니다. (예:
{17-32}클래스 리스트에 20바이트, 24바이트, 32바이트 블록이 모두 존재 가능) - 각 리스트는 명시적(explicit) 또는 암시적(implicit) 리스트로 구성됩니다.
malloc(할당)- 요청한 크기에 맞는 적절한 크기 클래스(appropriate free list)를 결정합니다.
- 해당 리스트에서 First-Fit(최초 적합) 검색을 수행하여 맞는 블록을 찾습니다.
- (Find O): 맞는 블록을 찾으면,
- (선택 사항) 블록을 분할(Split)합니다.
- 남은 조각(fragment)은 알맞은 크기 클래스의 가용 리스트 (현재 리스트이거나 더 작은 리스트)에 삽입합니다.
- (Find X): 맞는 블록을 찾지 못하면,
- 다음으로 더 큰(next larger) 크기 클래스의 리스트를 검색합니다.
- 맞는 블록을 찾을 때까지 이 과정을 반복합니다.
- (모두 실패): 모든 리스트를 검색해도 맞는 블록이 없다면, OS로부터 추가 힙 메모리를 요청(extend_heap)합니다.
- 이 새 메모리에서 블록을 할당하고, 남은 부분은 적절한 크기 클래스 리스트에 배치합니다.
free(해제)- "단순 분리 저장소"와 달리, 병합(Coalesce)을 수행합니다. (인접 블록 확인)
- 병합된 최종 블록을 알맞은 크기 클래스의 가용 리스트에 삽입합니다.
2. 장점 (Advantages)
glibc의 malloc 패키지(C 표준 라이브러리)와 같은 실제 상용 품질(production-quality)의 할당기들이 이 방식을 선호하는 이유입니다.
- 빠른 속도 (Fast):
- 검색(Search)이 힙 전체가 아닌 힙의 특정 부분(particular parts) (특정 크기 클래스)으로 제한되므로, 검색 시간이 단축됩니다.
- 높은 메모리 효율성 (Memory Efficient):
- (흥미로운 사실): '분리된 가용 리스트'에서 단순한 First-Fit 검색을 하는 것이, '전체 힙'에서 Best-Fit(최적 적합) 검색을 하는 것과 유사한(approximates) 효과를 냅니다.
- (이유: Best-Fit을 할 필요 없이, '거의 딱 맞는' 크기 클래스 리스트에서 First-Fit을 하면 되기 때문입니다.)
버디 시스템 (Buddy Systems)
버디 시스템은 분리 맞춤(Segregated Fits) 방식의 특별한 경우로, 모든 크기 클래스(size class)가 2의 거듭제곱인 할당기입니다.
기본 아이디어
전체 힙 크기가 워드(word)라고 할 때, 각 블록 크기 ()에 대해 별도의 가용 리스트를 유지합니다.
- 요청 크기:
malloc요청 크기는 가장 가까운 2의 거듭제곱으로 올림됩니다. (예:malloc(10)16바이트 요청) - 초기 상태: 힙에는 워드 크기의 가용 블록 단 하나만 존재합니다.
할당 (Allocation)
크기의 블록을 할당하는 과정은 다음과 같습니다.
- 을 만족하는 가장 작은 크기의 가용 블록을 찾습니다.
- 만약 이면, 찾은 블록을 바로 반환합니다.
- 만약 이면, 이 블록을 정확히 절반으로 쪼갭니다(split).
- 쪼개진 두 블록( 크기) 중 하나는 계속해서 쪼개고(3단계 반복), 나머지 절반(이를 버디(buddy)라고 함)은 크기 리스트에 넣습니다.
- 가 될 때까지 이 과정을 재귀적으로(recursively) 반복합니다.
해제 (Freeing)
크기의 블록을 해제하는 과정은 할당의 역순입니다.
- 해제된 블록을 리스트에 넣습니다.
- 이 블록의 버디(buddy)를 찾습니다.
- 만약 버디도 가용(Free) 상태라면, 두 블록을 병합(coalesce)하여 크기의 더 큰 블록을 만듭니다.
- 이 더 큰 블록에 대해 2단계를 재귀적으로(recursively) 반복합니다.
- 만약 버디가 할당된(Allocated) 상태라면, 병합을 멈춥니다.
버디 주소 계산
버디 시스템의 핵심적인 특징은, 어떤 블록의 주소와 크기만 알면 그 버디의 주소를 매우 쉽게 계산할 수 있다는 것입니다.
- 블록 크기가 이고 주소가 일 때, 그 버디의 주소는
Addr XOR S입니다. (XOR: 비트 단위 배타적 논리합) - 예시: 32바이트() 블록의 주소가
xxx...x00000이라면, 그 버디의 주소는xxx...x10000입니다. (정확히 한 비트만 다릅니다.)
장단점 및 적합성
- 장점: 버디 주소 계산이 매우 빠르고, 병합/분할이 간단하여 검색(searching)과 병합(coalescing)이 매우 빠릅니다.
- 단점: 블록 크기가 2의 거듭제곱이어야 한다는 제약 때문에, 심각한 내부 단편화(internal fragmentation)를 유발할 수 있습니다. (예:
malloc(17)요청에 32바이트 블록을 할당하면 15바이트가 낭비됨) - 적합성: 이러한 단점 때문에 범용(general-purpose) 작업에는 적합하지 않습니다. 하지만, 할당될 블록 크기가 미리 2의 거듭제곱으로 알려진 특정 응용 프로그램에는 매력적인 선택지가 될 수 있습니다. (예: 커널 메모리 관리 일부)
