
동시성 (Concurrency)이란?
8장에서 배운 것처럼, 논리적 제어 흐름(logical control flow)이 시간상으로 겹치면 동시성(concurrent)을 갖는다고 합니다. 동시성(concurrency)이라고 알려진 이 일반적인 현상은 컴퓨터 시스템의 다양한 레벨에서 나타납니다.
- 예시: 하드웨어 예외 처리기, 프로세스, 리눅스 시그널 핸들러 등
지금까지 우리는 동시성을 주로 운영체제 커널이 여러 애플리케이션 프로그램을 실행하기 위해 사용하는 메커니즘으로 다루었습니다.
하지만 동시성은 커널에만 국한되지 않고 애플리케이션 프로그램에서도 중요한 역할을 합니다. (예: 리눅스 시그널 핸들러가 Ctrl+C 입력 같은 비동기 이벤트에 응답하는 것)
애플리케이션 레벨 동시성 활용 사례
애플리케이션 레벨의 동시성은 다음과 같은 방식들로 유용합니다:
- 느린 I/O 장치 접근
- 애플리케이션이 디스크 같은 느린 I/O를 기다릴 때, 커널은 다른 프로세스를 실행시켜 CPU를 바쁘게 유지합니다.
- 이와 유사하게, 개별 애플리케이션도 I/O 요청과 유용한 작업을 겹치게 함으로써 동시성을 활용할 수 있습니다.
- 사용자와의 상호작용
- 사용자는 동시에 여러 작업을 수행하길 원합니다. (예: 문서 인쇄 중 창 크기 조절)
- 최신 윈도우 시스템은 동시성을 사용해 이 기능을 제공하며, 사용자 요청(예: 마우스 클릭)마다 별도의 동시적 논리 흐름을 생성하여 작업을 수행합니다.
- 작업 지연을 통한 지연 시간(latency) 감소
- 때때로 애플리케이션은 덜 중요한 작업을 지연시키고 이를 동시에 수행함으로써, 특정 핵심 작업의 지연 시간을 줄일 수 있습니다.
- (예: 동적 저장소 할당자가
free작업의 속도를 높이기 위해, 메모리 병합(coalescing) 작업을 낮은 우선순위의 동시 흐름으로 지연시켜 나중에 처리함)
- 다중 네트워크 클라이언트 서비스
- 11장의 반복(iterative) 서버는 한 번에 한 클라이언트만 처리하므로 비현실적입니다. (느린 클라이언트 하나가 전체 서버를 막을 수 있음)
- 더 나은 접근 방식은 각 클라이언트를 위해 별도의 논리 흐름을 생성하는 동시성 서버(concurrent server)를 구축하는 것입니다. 이를 통해 여러 클라이언트를 동시에 서비스할 수 있습니다.
- 멀티코어 머신에서의 병렬 컴퓨팅
- 최신 멀티코어 프로세서(다중 CPU) 환경에서, 동시적 흐름으로 분할된 애플리케이션은 흐름이 병렬(parallel)로 실행될 수 있기 때문에 단일 프로세서 머신보다 더 빠르게 실행되는 경우가 많습니다.
동시성 프로그래밍 접근 방식
애플리케이션 레벨 동시성을 사용하는 프로그램을 동시성 프로그램(concurrent programs)이라고 합니다. 최신 운영체제는 이를 구축하기 위한 세 가지 기본 접근 방식을 제공합니다:
- 프로세스 (Processes)
- 각 논리 흐름이 커널에 의해 스케줄링되는 프로세스입니다.
- 프로세스들은 별도의 가상 주소 공간을 가집니다.
- 따라서 서로 통신하려면 명시적인 프로세스 간 통신(IPC) 메커니즘이 필요합니다.
- I/O 멀티플렉싱 (I/O Multiplexing)
- 단일 프로세스 컨텍스트 내에서 애플리케이션이 직접 자신의 논리 흐름을 스케줄링하는 방식입니다.
- 논리 흐름은 파일 디스크립터의 데이터 도착에 따라 상태가 변하는 상태 머신(state machine)으로 모델링됩니다.
- 단일 프로세스이므로 모든 흐름이 동일한 주소 공간을 공유합니다.
- 스레드 (Threads)
- 단일 프로세스 컨텍스트 내에서 실행되며 커널에 의해 스케줄링되는 논리 흐름입니다.
- 커널 스케줄링 (프로세스 방식)과 동일한 가상 주소 공간 공유 (I/O 멀티플렉싱 방식)의 특징을 모두 가진 하이브리드(hybrid) 형태입니다.
12.1 프로세스를 이용한 동시성 프로그래밍
동시성 프로그램을 구축하는 가장 간단한 방법은 fork, exec, waitpid와 같이 익숙한 함수를 사용하여 프로세스를 활용하는 것입니다.
예를 들어, 동시성 서버를 구축하는 자연스러운 접근 방식은 부모 프로세스가 클라이언트 연결 요청을 accept (수락)하고, 새로운 각 클라이언트를 서비스하기 위해 새로운 자식 프로세스를 생성하는 것입니다.
프로세스 기반 동시성 서버의 동작 방식
이것이 어떻게 작동하는지 보기 위해, 2개의 클라이언트와 리스닝 디스크립터(예: 3번)에서 연결 요청을 기다리는 서버가 있다고 가정해 봅시다.
-
클라이언트 1 연결
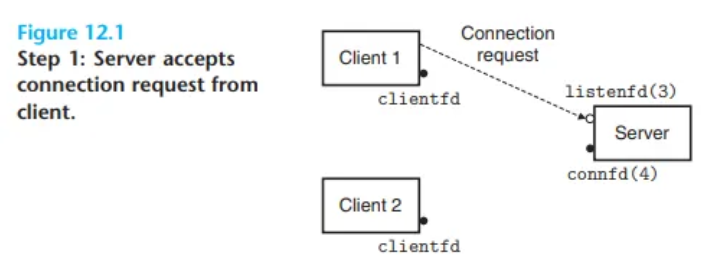
- 서버가 클라이언트 1의 연결 요청을 수락(
accept)하고, 연결 디스크립터(connected descriptor, 예: 4번)를 반환받습니다. (Figure 12.1)
- 서버가 클라이언트 1의 연결 요청을 수락(
-
자식 프로세스 생성 (
fork)- 연결 요청을 수락한 후, 서버(부모)는
fork를 통해 자식 프로세스를 생성합니다. - 자식은 서버(부모)의 디스크립터 테이블 사본을 그대로 물려받습니다.
- 연결 요청을 수락한 후, 서버(부모)는
-
디스크립터 정리 (매우 중요)
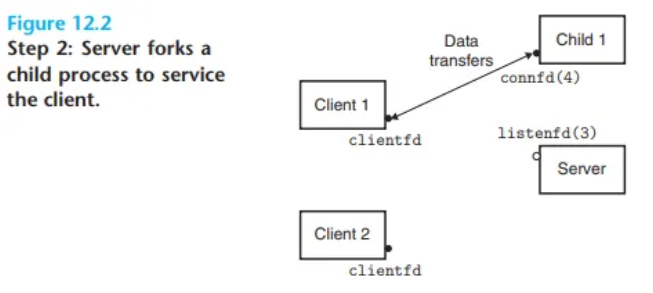
- 자식 프로세스: 더 이상 필요 없는 리스닝 디스크립터(3번)의 사본을 닫습니다. (자식은 새 클라이언트를 받을 필요가 없기 때문)
- 부모 프로세스: 더 이상 필요 없는 연결 디스크립터(4번)의 사본을 닫습니다. (부모는 이 클라이언트와 직접 통신할 필요가 없기 때문)
- 이 정리가 끝나면, 자식 프로세스가 클라이언트를 서비스하는 상황이 됩니다. (Figure 12.2)
부모가 연결 디스크립터를 닫아야 하는 이유
부모와 자식의 연결 디스크립터는 동일한 파일 테이블 엔트리(file table entry)를 가리킵니다.
만약 부모 프로세스가 자신의 연결 디스크립터 사본(4번)을 닫지 않는다면, (자식 프로세스가 종료된 후에도) 이 파일 테이블 엔트리는 절대 릴리즈(release)되지 않을 것입니다.
결과적으로 이는 메모리 누수(memory leak)로 이어지고, 결국 가용 메모리를 모두 소모하여 시스템을 다운시킬 수 있습니다.
다중 클라이언트 처리 (동시성)
-
클라이언트 2 연결
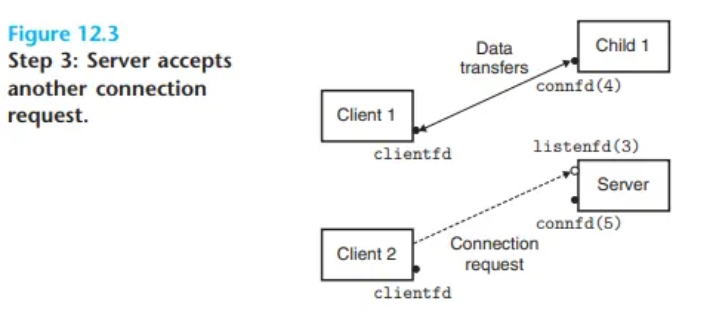
- 부모가 클라이언트 1을 위한 자식을 생성한 후, 다시 루프를 돌아 다음 연결 요청을 기다립니다.
- 이때 클라이언트 2로부터 새로운 연결 요청을 수락하고, 새로운 연결 디스크립터(예: 5번)를 받습니다. (Figure 12.3)
-
두 번째 자식 생성
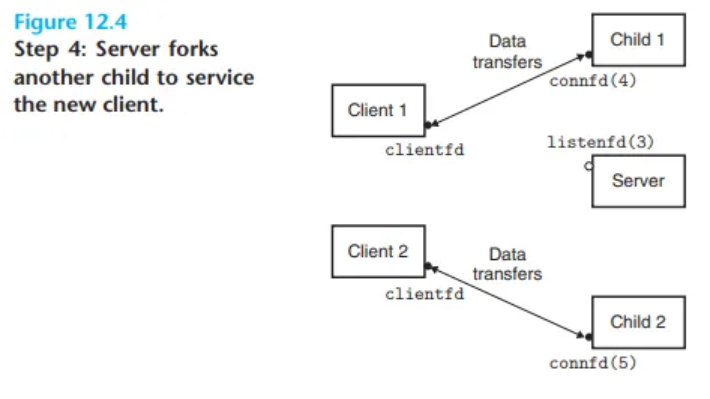
- 부모는 또
fork를 호출하여 두 번째 자식 프로세스를 생성합니다. - 이 두 번째 자식은 연결 디스크립터 5번을 사용하여 클라이언트 2의 서비스를 시작합니다. (Figure 12.4)
- 부모는 또
이 시점에서 부모는 다음 연결 요청을 기다리고, 두 자식 프로세스는 각자의 클라이언트를 동시에(concurrently) 서비스하게 됩니다.
12.1.1 프로세스 기반 동시성 서버

Figure 12.5는 프로세스를 기반으로 하는 동시성 에코 서버의 코드를 보여줍니다. (29행에서 호출되는 echo 함수는 Figure 11.22의 것입니다.)
이 서버 코드에는 몇 가지 중요한 점이 있습니다:
SIGCHLD핸들러 (좀비 회수)
첫째, 서버는 일반적으로 오랜 시간 동안 실행되므로, 좀비 자식(zombie children)을 회수(reap)하는SIGCHLD핸들러를 반드시 포함해야 합니다 (lines 4–9).SIGCHLD핸들러가 실행되는 동안SIGCHLD시그널은 블록(blocked)되고, 리눅스 시그널은 큐(queued)에 쌓이지 않기 때문에,SIGCHLD핸들러는 (한 번에) 여러 좀비 자식을 회수할 준비가 되어 있어야 합니다.connfd닫기 (메모리 누수 방지)
둘째, 부모와 자식은 각자의connfd(연결 디스크립터) 사본을 반드시 닫아야 합니다 (부모 line 33, 자식 line 30). 앞서 언급했듯이, 이는 특히 부모가 메모리 누수(memory leak)를 피하기 위해 매우 중요합니다.- 연결 종료 시점 (참조 카운트)
마지막으로, 소켓의 파일 테이블 엔트리에 있는 참조 카운트(reference count) 때문에, 클라이언트로의 연결은 부모와 자식 양쪽의connfd사본이 모두 닫힐 때까지 (즉, 참조 카운트가 0이 될 때까지) 실제로 종료되지 않습니다.
12.1.2 프로세스 방식의 장단점
프로세스는 부모와 자식 간에 상태 정보를 공유하는 깔끔한 모델을 가지고 있습니다: 파일 테이블은 공유되지만 사용자 주소 공간은 공유되지 않습니다.
프로세스마다 별도의 주소 공간을 갖는 것은 장점이자 단점입니다.
장점 (Advantage)
- 한 프로세스가 다른 프로세스의 가상 메모리를 실수로 덮어쓰는 것이 불가능합니다.
- 이는 많은 혼란스러운 오류를 제거해주는 명백한 장점입니다.
단점 (Disadvantage)
- 별도의 주소 공간은 프로세스 간의 상태 정보 공유를 더 어렵게 만듭니다. 정보를 공유하려면, 명시적인 IPC (프로세스 간 통신) 메커니즘을 사용해야 합니다.
- 프로세스 기반 설계는 속도가 느린 경향이 있습니다. 이는 프로세스 제어(process control)와 IPC의 오버헤드가 높기 때문입니다.
부가 설명: Unix IPC
여러분은 이미 이 텍스트에서 여러 IPC(프로세스 간 통신) 예시를 접했습니다.
- 8장의
waitpid함수와 시그널(signals)은 같은 호스트에서 실행 중인 프로세스 간에 아주 작은 메시지를 보낼 수 있게 해주는 원시적인(primitive) IPC 메커니즘입니다. - 11장의 소켓(sockets) 인터페이스는 다른 호스트에 있는 프로세스 간에 임의의 바이트 스트림(byte streams)을 교환할 수 있게 해주는 중요한 형태의 IPC입니다.
하지만, "Unix IPC"라는 용어는 일반적으로 같은 호스트에서 실행 중인 다른 프로세스들과 통신할 수 있게 해주는 잡다한(hodgepodge) 기술들을 지칭할 때 예약되어 있습니다.
- 예시: 파이프(pipes), FIFO(Named Pipes), System V 공유 메모리(shared memory), System V 세마포(semaphores).
12.2 I/O 멀티플렉싱을 이용한 동시성 프로그래밍
1. 문제 상황: 두 개의 I/O 이벤트를 동시에 처리해야 한다면?
에코 서버가 다음 두 가지 독립적인 I/O 이벤트를 처리해야 한다고 가정해 봅시다:
- 네트워크 클라이언트의 연결 요청
- 키보드를 통한 표준 입력의 사용자 인터랙티브 명령
어떤 이벤트를 먼저 기다려야 할까요? 어느 쪽도 이상적이지 않습니다.
accept에서 연결 요청을 기다리면 (블로킹되면), 표준 입력으로 들어온 명령에 응답할 수 없습니다.read에서 입력 명령을 기다리면 (블로킹되면), 새로운 클라이언트 연결 요청에 응답할 수 없습니다.
2. 해결책: I/O 멀티플렉싱과 select 함수
이 딜레마의 한 가지 해결책은 I/O 멀티플렉싱(I/O multiplexing)이라는 기법입니다.
기본 아이디어는 select 함수를 사용하여 커널에 프로세스를 일시 중단(suspend)하도록 요청하고, 하나 이상의 I/O 이벤트가 발생한 후에만 애플리케이션으로 제어권을 반환받는 것입니다.
- (이 챕터에서는 "읽기 준비가 된 디스크립터 집합을 기다리는" 시나리오에만 초점을 맞춥니다.)
3. select 함수와 fd_set 매크로
select 함수는 fd_set이라는 디스크립터 집합(descriptor sets)을 다룹니다.
#include <sys/select.h>
/*
* n: 감시할 파일 디스크립터 범위 (최대 디스크립터 번호 + 1)
* fdset (read set): 읽기 이벤트를 감시할 디스크립터 집합
* 리턴값: 준비된 디스크립터의 개수, 오류 시 -1
*/
int select(int n, fd_set *fdset, NULL, NULL, NULL);
/* fd_set 조작 매크로 */
FD_ZERO(fd_set *fdset); /* fdset의 모든 비트를 0으로 초기화 */
FD_SET(int fd, fd_set *fdset); /* fdset에 fd 비트를 1로 설정 (추가) */
FD_CLR(int fd, fd_set *fdset); /* fdset에서 fd 비트를 0으로 설정 (제거) */
FD_ISSET(int fd, fd_set *fdset); /* fdset에 fd 비트가 1인지 확인 */논리적으로, fd_set은 비트 벡터(bit vector)입니다. k번째 비트 b_k가 1이면 디스크립터 k가 집합에 포함되었음을 의미합니다.
4. select 함수의 동작 방식
- 입력 (Read Set):
select함수는fdset(우리가 읽기 집합(read set)이라 부름)을 입력으로 받습니다. - 블로킹 (Blocking):
select는read_set에 포함된 디스크립터 중 최소 하나라도 "읽기 준비"가 될 때까지 프로세스를 블록시킵니다.- (참고: "읽기 준비"란 해당 디스크립터에서 1바이트를 읽는 요청이 블록되지 않음을 의미합니다.)
- 부작용 (Side Effect):
select가 리턴될 때, 커널은 입력으로 전달한fdset을 수정하여, 읽기 준비가 된 디스크립터들로만 구성된 부분집합인 준비된 집합(ready set)으로 덮어씁니다. - 리턴 값: 함수는 이
ready_set에 포함된 디스크립터의 개수(cardinality)를 반환합니다.
⚠️ 중요: 이 부작용 때문에, select가 리턴된 후 루프를 돌아 다시 select를 호출하기 전에는 매번 read_set을 원본으로 다시 갱신해줘야 합니다.
5. 예제: select를 사용한 반복 서버 (Figure 12.6)

select를 사용하여 표준 입력과 리스닝 디스크립터를 동시에 처리하는 서버 예제입니다.
- 초기화 (비어있는
read_set)listenfd를 열고(line 16),FD_ZERO를 호출하여 빈read_set을 만듭니다.read_set (Ø): [0 0 0 0](stdin=0, listenfd=3 가정)
read_set구성 (감시 대상 추가)FD_SET을 사용하여STDIN_FILENO(0번)과listenfd(3번)을read_set에 추가합니다.read_set ({0,3}): [1 0 0 1]
select호출 (대기)
서버 루프 안에서select를 호출합니다(line 24).select는listenfd나stdin둘 중 하나라도 읽기 가능해질 때까지 블록됩니다.
- (가정: 사용자가 키보드로 엔터 키를 입력함)
-stdin(0번) 디스크립터가 "읽기 준비" 상태가 됩니다.
-select가 리턴되며,fdset인자를ready_set으로 덮어씁니다.
-ready_set ({0}): [0 0 0 1]ready_set확인 (이벤트 처리)select가 리턴된 후,FD_ISSET매크로를 사용하여 어떤 디스크립터가 준비되었는지 확인합니다.FD_ISSET(STDIN_FILENO, ...)(line 25): 표준 입력이 준비되었으므로command()함수를 호출하여 명령을 처리합니다.FD_ISSET(listenfd, ...)(line 27): 리스닝 디스크립터가 준비되었다면accept를 호출하고echo함수를 실행합니다.
6. 예제 코드(Figure 12.6)의 한계
이 프로그램은 select의 좋은 예시이지만, 여전히 아쉬운 점이 있습니다.
- 문제점:
echo함수(line 30)는 클라이언트가 연결을 끊을 때까지(EOF) 계속해서 입력을 에코합니다. - 결과: 서버가 한 클라이언트와
echo를 수행하는 동안(블로킹됨), 관리자가 표준 입력에 명령을 입력해도 서버는 해당 클라이언트 작업이 끝날 때까지 명령에 응답하지 않습니다. - 더 나은 접근: 서버 루프를 돌 때마다 (최대) 텍스트 한 줄만 에코하는 등, 더 세분화된(finer granularity) 방식으로 멀티플렉싱을 해야 합니다.
12.2.1 I/O 멀티플렉싱 기반의 동시성 이벤트 기반 서버
I/O 멀티플렉싱은 이벤트 기반 동시성 프로그램(concurrent event-driven programs)의 기초로 사용될 수 있습니다. 이벤트 기반 프로그램에서는 특정 이벤트의 결과로 논리적 흐름이 진행됩니다.
1. 상태 머신 (State Machines) 모델
- 개념: 논리적 흐름을 상태 머신으로 모델링합니다.
- 구성: 상태 머신은 (상태, 입력 이벤트, 트랜지션)의 집합입니다.
- 트랜지션(전이): (현재 상태, 입력 이벤트) 쌍을 (다음 상태)로 매핑(mapping)합니다. (상태 머신은 보통 유향 그래프로 표현됩니다.)
- 실행: 상태 머신은 초기 상태에서 시작하여, 각 입력 이벤트가 발생할 때마다 현재 상태에서 다음 상태로의 트랜지션을 실행합니다.
I/O 멀티플렉싱 기반의 동시성 서버는 새로운 클라이언트 마다, 새로운 상태 머신 를 생성하고 이를 연결 디스크립터 와 연결합니다. (Figure 12.7에서 설명하듯이)
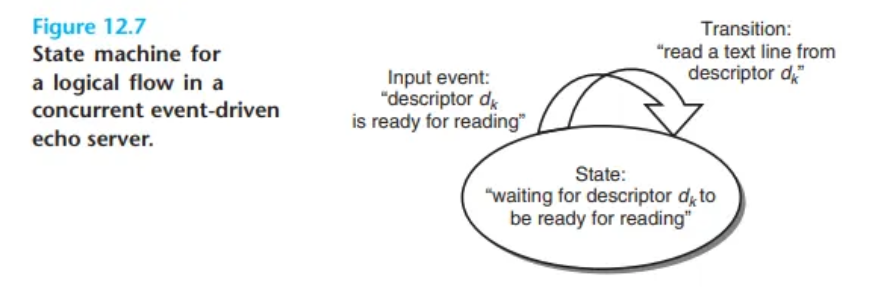
- 상태: "디스크립터 가 읽기 준비되기를 기다림"
- 입력 이벤트: "디스크립터 가 읽기 준비됨"
- 트랜지션: "디스크립터 에서 텍스트 한 줄을 읽음"
서버는 select 함수를 사용하여 이러한 입력 이벤트의 발생을 ㄹ감지합니다. 각 연결 디스크립터가 읽기 준비가 되면, 서버는 해당 상태 머신에 대한 트랜지션(즉, 디스크립터에서 텍스트 한 줄을 읽고 에코하는 작업)을 실행합니다.
2. 코드 분석: 이벤트 기반 에코 서버
Figure 12.8은 I/O 멀티플렉싱 기반의 동시성 이벤트 기반 서버의 전체 예제 코드입니다.
main 함수 (Figure 12.8)

서버는 활성 클라이언트 집합을 pool 구조체(lines 3–11)로 관리합니다.
init_pool(line 27)을 호출하여 풀을 초기화합니다.- 서버는 무한 루프에 진입합니다.
- 매 루프마다
select함수를 호출하여(line 32) 두 가지 종류의 입력 이벤트를 감지합니다.- 새 클라이언트로부터의 연결 요청 (리스닝 디스크립터
listenfd가 준비됨) - 기존 클라이언트의 데이터 도착 (연결 디스크립터
connfd가 준비됨)
- 새 클라이언트로부터의 연결 요청 (리스닝 디스크립터
listenfd가 준비되면 (즉, 새 연결 요청이 도착하면, line 35), 서버는 연결을 수락(Accept, line 37)하고add_client함수를 호출하여 클라이언트를 풀에 추가합니다(line 38).- 마지막으로,
check_clients함수를 호출하여(line 42) 준비된 각 연결 디스크립터로부터 텍스트 한 줄씩 에코합니다. (이전 12.2 예제의 문제를 해결함)
init_pool 함수 (Figure 12.9)
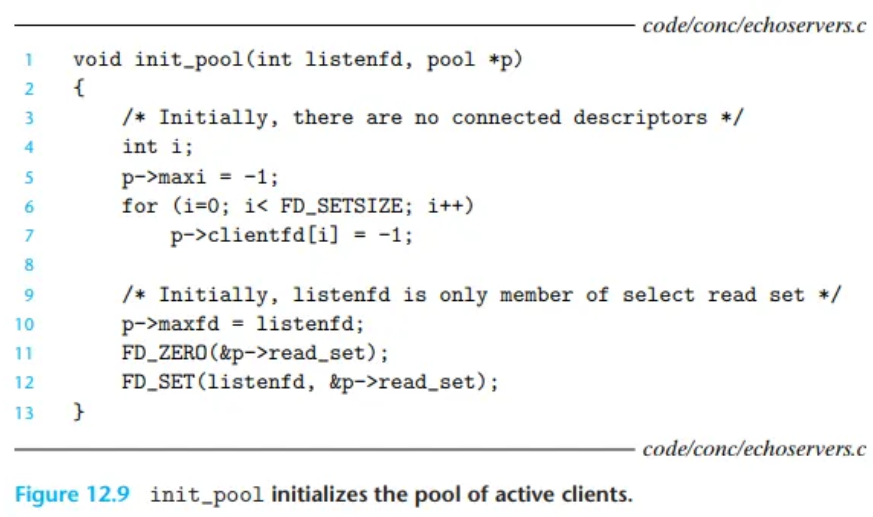
클라이언트 풀을 초기화합니다.
clientfd배열은 연결 디스크립터 집합을 나타내며,1은 사용 가능한 슬롯을 의미합니다.- 초기에는 연결된 디스크립터가 없으므로 모든 슬롯을
1로 설정합니다(lines 5–7). - 초기에는
listenfd가select의read_set에 포함된 유일한 디스크립터입니다(lines 10–12). (즉, 처음엔 새 연결만 감시)
add_client 함수 (Figure 12.10)
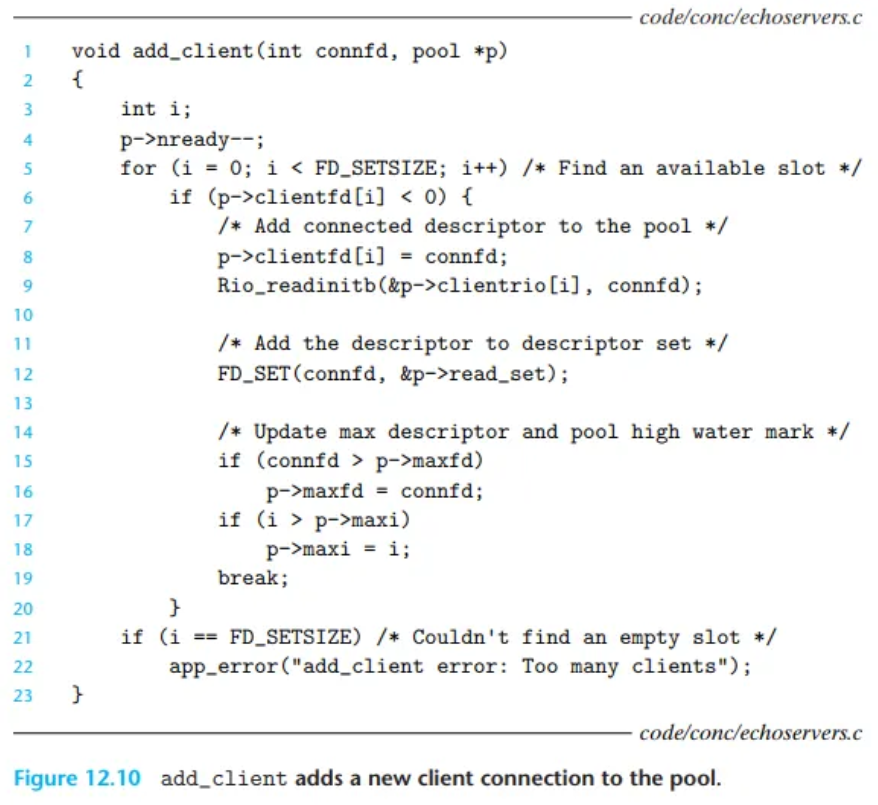
새로운 클라이언트를 활성 클라이언트 풀에 추가합니다.
clientfd배열에서 빈 슬롯(-1인 곳)을 찾습니다(line 5).connfd를 배열에 추가하고(line 8),rio_readlineb를 호출할 수 있도록 해당 클라이언트를 위한Rio읽기 버퍼를 초기화합니다(line 9).FD_SET: 새connfd를select의read_set에 추가합니다(line 12). (★ 이제부터 이 클라이언트의 데이터 도착도 감시 대상이 됩니다.)- 풀의 전역 속성을 업데이트합니다.
maxfd(lines 15–16):select함수에 넘겨줄 디스크립터 번호의 최댓값을 추적합니다.maxi(lines 17–18):check_clients함수가 전체 배열을 검색할 필요 없이, 현재까지 사용된clientfd배열의 가장 큰 인덱스를 추적합니다. (최적화)
check_clients 함수 (Figure 12.11)

준비된(ready) 각 연결 디스크립터로부터 텍스트 한 줄을 에코합니다.
maxi인덱스까지만 루프를 돕니다(line 7).FD_ISSET:select가 반환한ready_set을 확인하여, 현재 디스크립터(connfd)가 "읽기 준비" 상태인지 확인합니다(line 12).- (준비되었다면)
rio_readlineb를 호출하여 텍스트 한 줄을 읽습니다(line 15). - (읽기 성공 시) 해당 라인을 클라이언트에게 다시 에코합니다(lines 15–18).
- (EOF 감지 시 -
rio_readlineb가 0을 반환)- 클라이언트가 연결을 닫았다는 의미입니다.
- 서버도
Close(connfd)로 연결을 닫습니다(line 23). FD_CLR:read_set에서 이 디스크립터를 제거합니다(line 24). (더 이상 감시하지 않음)clientfd[i] = -1: 풀(pool)에서 해당 슬롯을 비워 재사용할 수 있게 합니다(line 25).
3. 요약 (상태 머신 관점)
select함수: 입력 이벤트를 감지합니다.add_client함수: 새로운 논리적 흐름 (상태 머신)을 생성합니다.check_clients함수: 입력 라인을 에코함으로써 상태 전이(transition)를 수행하고, 클라이언트가 완료되면(EOF) 상태 머신을 삭제합니다.
12.2.2 I/O 멀티플렉싱의 장단점
Figure 12.8의 서버(이벤트 기반 서버)는 I/O 멀티플렉싱 기반 이벤트 기반 프로그래밍의 장단점을 잘 보여줍니다.
장점 (Advantages)
- 더 강력한 프로그램 제어권
- 이벤트 기반 설계는 프로세스 기반 설계보다 프로그래머에게 더 많은 제어권을 줍니다.
- 예를 들어, 특정 클라이언트에게 우선순위 서비스를 제공하는 동시성 서버를 상상해 볼 수 있는데, 이는 프로세스 기반 서버로는 구현하기 어렵습니다.
- 쉬운 데이터 공유
- I/O 멀티플렉싱 기반 서버는 단일 프로세스의 컨텍스트에서 실행되므로, 모든 논리적 흐름이 프로세스의 전체 주소 공간에 접근할 수 있습니다.
- 이는 흐름(flow) 간의 데이터 공유를 매우 쉽게 만듭니다.
- 쉬운 디버깅
- 단일 프로세스로 실행된다는 것의 또 다른 장점은,
gdb와 같은 익숙한 디버깅 도구를 사용하여 일반적인 순차 프로그램처럼 동시성 서버를 디버깅할 수 있다는 것입니다.
- 단일 프로세스로 실행된다는 것의 또 다른 장점은,
- 높은 효율성
- 이벤트 기반 설계는 새로운 흐름을 스케줄링하기 위해 프로세스 문맥 교환(context switch)이 필요 없기 때문에, 프로세스 기반 설계보다 훨씬 더 효율적인 경우가 많습니다.
단점 (Disadvantages)
- 코딩 복잡성
- 이벤트 기반 설계의 가장 큰 단점은 코딩 복잡성입니다. 우리가 만든 이벤트 기반 에코 서버는 프로세스 기반 서버보다 3배나 더 많은 코드를 필요로 합니다.
- 세분화(Granularity) 문제
- 불행히도, 동시성의 세분화(granularity) 단위가 작아질수록 복잡성은 더욱 증가합니다.
- (여기서 '세분화'란 각 논리적 흐름이 타임 슬라이스 당 실행하는 명령어 수를 의미합니다. 우리 예제에서는 '텍스트 한 줄을 전부 읽는 것'이 세분화 단위입니다.)
- 어떤 흐름이 텍스트 한 줄을 읽는 동안에는, 다른 어떤 흐름도 진행할 수 없습니다. (세분화 큰 경우)
- 악의적인 클라이언트에 대한 취약점
- 위 세분화 문제로 인해, 만약 악의적인 클라이언트가 텍스트의 일부만 보내고 멈춰버리면, 서버는 그 클라이언트에게 계속 매달리게 되어 다른 모든 클라이언트의 작업이 막히게 됩니다.
- (부분적인 텍스트 라인을 처리하도록 이벤트 기반 서버를 수정하는 것은 간단하지 않은 작업이지만, 프로세스 기반 설계에서는 이런 문제가 자동으로 깔끔하게 처리됩니다.)
- 멀티코어 활용 불가
- 이벤트 기반 설계(단일 프로세스)는 멀티코어 프로세서를 완전히 활용할 수 없습니다.
12.3 스레드를 이용한 동시성 프로그래밍
지금까지 우리는 동시성 논리 흐름을 만들기 위한 두 가지 접근 방식을 살펴보았습니다.
- 프로세스 기반: 각 흐름마다 별도의 프로세스를 사용합니다. 커널이 각 프로세스를 자동으로 스케줄링하지만, 각 프로세스는 자신만의 사적인(private) 주소 공간을 가져서 흐름 간 데이터 공유가 어렵습니다.
- I/O 멀티플렉싱 기반: 우리(프로그래머)가 직접 논리 흐름을 만들고 I/O 멀티플렉싱을 사용해 흐름을 명시적으로 스케줄링합니다. 단일 프로세스이므로 모든 흐름이 전체 주소 공간을 공유합니다.
이 섹션에서는 이 두 가지 방식의 하이브리드(hybrid)인 세 번째 접근 방식, 즉 스레드(threads)를 소개합니다.
스레드란 무엇인가?
- 스레드(thread)는 프로세스 컨텍스트 내에서 실행되는 논리적 흐름입니다. (지금까지 우리 프로그램들은 프로세스당 단일 스레드로 구성되었습니다.) 하지만 최신 시스템에서는 단일 프로세스 내에서 여러 스레드가 동시에 실행되는 프로그램을 작성할 수 있습니다.
- 스레드는 커널에 의해 자동으로 스케줄링됩니다.
- 각 스레드는 고유한 스레드 컨텍스트(thread context)를 가집니다.
- 고유한 정수 스레드 ID (TID)
- 스택 (Stack)
- 스택 포인터
- 프로그램 카운터 (PC)
- 범용 레지스터
- 조건 코드
- 한 프로세스 내에서 실행되는 모든 스레드는 해당 프로세스의 전체 가상 주소 공간을 공유합니다.
스레드: 하이브리드 접근 방식
스레드 기반 논리 흐름은 프로세스 기반 흐름과 I/O 멀티플렉싱 기반 흐름의 특징을 결합합니다.
- 프로세스와의 공통점:
- 스레드는 커널에 의해 자동으로 스케줄링됩니다.
- 커널은 스레드를 정수 ID(TID)로 식별합니다.
- I/O 멀티플렉싱과의 공통점:
- 여러 스레드가 단일 프로세스의 컨텍스트 내에서 실행됩니다.
- 따라서 프로세스 가상 주소 공간의 전체 내용(코드, 데이터, 힙, 공유 라이브러리, 열린 파일 등)을 모두 공유합니다.
12.3.1 스레드 실행 모델
여러 스레드의 실행 모델은 여러 프로세스의 실행 모델과 어떤 면에서는 유사합니다. (Figure 12.12 참고)
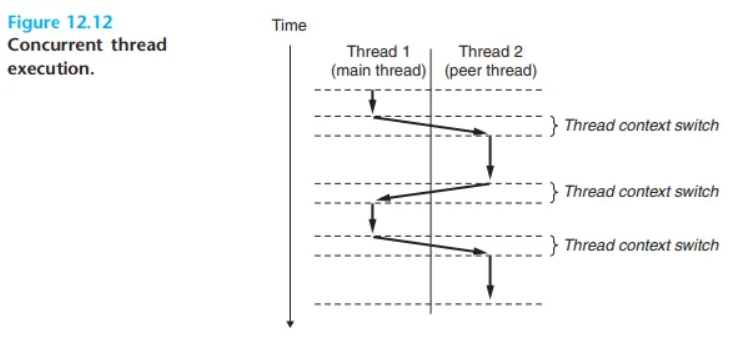
- 시작과 생성:
각 프로세스는 메인 스레드(main thread)라고 불리는 단일 스레드로 시작합니다. 특정 시점에 메인 스레드가 피어 스레드(peer thread)를 생성하고, 이 시점부터 두 스레드는 동시적(concurrently)으로 실행됩니다. - 컨텍스트 스위치:
결국 (메인 스레드가read나sleep같은 느린 시스템 콜을 실행하거나, 또는 시스템의 인터벌 타이머에 의해 인터럽트가 걸려서) 컨텍스트 스위치를 통해 피어 스레드로 제어권이 넘어갑니다. 피어 스레드가 잠시 실행되다가 다시 메인 스레드로 제어권이 넘어오는 식으로 반복됩니다.
프로세스와 스레드 실행의 차이점
스레드 실행은 몇 가지 중요한 면에서 프로세스와 다릅니다.
- 컨텍스트 스위치 속도:
스레드 컨텍스트는 프로세스 컨텍스트보다 훨씬 작기 때문에, 스레드 컨텍스트 스위치가 프로세스 컨텍스트 스위치보다 더 빠릅니다. - 계층 구조 (vs 피어 풀):
스레드는 프로세스와 달리 엄격한 부모-자식 계층구조로 구성되지 않습니다.
- 한 프로세스에 연관된 스레드들은 "피어(동료)의 풀(pool of peers)"을 형성합니다. 이는 어떤 스레드가 다른 스레드를 생성했는지와 무관하게 모두 동등한 관계입니다.
- 메인 스레드가 다른 스레드와 구별되는 유일한 점은 "항상 그 프로세스에서 가장 먼저 실행되는 스레드"라는 것뿐입니다. - 피어 풀의 영향:
이러한 "피어 풀" 개념의 주된 영향은 다음과 같습니다.
- 한 스레드가 (부모-자식 관계없이) 자신의 어떤 피어 스레드든 죽일 수 있습니다(kill).
- 한 스레드가 자신의 어떤 피어 스레드든 종료되기를 기다릴 수 있습니다(wait).
- 각 피어 스레드는 동일한 공유 데이터를 읽고 쓸 수 있습니다.
12.3.2 Posix 스레드
Posix 스레드(Pthreads)는 C 프로그램에서 스레드를 조작하기 위한 표준 인터페이스입니다. 1995년에 채택되었으며 모든 리눅스 시스템에서 사용할 수 있습니다. Pthreads는 약 60개의 함수를 정의하며, 프로그램이 스레드를 생성(create), 종료(kill), 회수(reap)하고, 피어 스레드와 데이터를 안전하게 공유하며, 시스템 상태의 변경을 피어 스레드에게 알릴 수(notify) 있게 해줍니다.
"Hello, world!" 예제 분석 (Figure 12.13)

Figure 12.13은 간단한 Pthreads 프로그램입니다.
- 메인 스레드(main thread)가 피어 스레드(peer thread)를 생성합니다.
- 메인 스레드는 피어 스레드가 종료되기를 기다립니다.
- 피어 스레드는
Hello, world!\n를 출력하고 종료합니다. - 메인 스레드는 피어 스레드가 종료된 것을 감지하면,
exit를 호출하여 프로세스를 종료시킵니다.
이것은 우리가 처음 본 스레드 프로그램이므로, 자세히 분석해 보겠습니다.
1. 스레드 루틴 (Thread Routine) (Lines 2, 12-16)
스레드의 코드와 지역 데이터는 스레드 루틴(thread routine) (이 예제에서는 thread 함수) 내에 캡슐화됩니다.
- (Line 2) 프로토타입에서 보듯이, 각 스레드 루틴은 단일 제네릭 포인터(
void *vargp)를 입력으로 받고, 제네릭 포인터(void *)를 반환합니다. - 팁: 만약 스레드 루틴에 여러 인자를 전달하고 싶다면, 그 인자들을
struct에 넣고 그struct의 포인터를 전달해야 합니다. (여러 값을 반환할 때도 마찬가지)
(Lines 12-16) 피어 스레드를 위한 스레드 루틴입니다.
- (Line 14) 문자열을 출력합니다.
- (Line 15)
return문을 실행하여 피어 스레드 자신을 종료시킵니다.
2. 메인 스레드 (Main Thread) (Lines 4-10)
Line 4는 메인 스레드의 코드 시작점입니다.
- (Line 6
pthread_t tid): 피어 스레드의 스레드 ID(TID)를 저장하기 위한tid변수를 선언합니다. - (Line 7
pthread_create(...)):- 새로운 피어 스레드를 생성합니다.
pthread_create호출이 리턴되면, 메인 스레드와 새로 생성된 피어 스레드는 동시적으로 실행됩니다.tid변수에는 새로 생성된 스레드의 ID가 저장됩니다.
- (Line 8
pthread_join(tid, NULL)):- 메인 스레드는
tid가 식별하는 피어 스레드가 종료될 때까지 기다립니다(block).
- 메인 스레드는
- (Line 9
exit(0)):pthread_join이 리턴된 후 (즉, 피어 스레드가 종료된 후), 메인 스레드는exit함수를 호출합니다.exit함수는 프로세스 내에서 현재 실행 중인 모든 스레드를 종료시킵니다. (이 경우에는 피어 스레드는 이미 종료되었으므로, 메인 스레드 자신만 종료됩니다.)
12.3.3 스레드 생성하기 (Creating Threads)
스레드는 pthread_create 함수를 호출하여 다른 스레드를 생성합니다.
#include <pthread.h>/* 스레드 루틴(함수)의 타입 정의 (void*를 받아 void*를 리턴) */
typedef void *(func)(void *);
int pthread_create(pthread_t *tid, pthread_attr_t *attr,
func *f, void *arg);
// 성공 시 0, 오류 시 0이 아닌 값 반환pthread_create 함수는 새로운 스레드를 생성하고, 이 새 스레드의 컨텍스트에서 스레드 루틴(함수) f를 실행시키며, 이때 arg를 입력 인자로 전달합니다.
tid: (출력 인자)pthread_create가 리턴될 때, 새로 생성된 스레드의 ID가 이 포인터가 가리키는 곳에 저장됩니다.attr: 새 스레드의 기본 속성을 변경하는 데 사용될 수 있습니다. (이 속성 변경은 이 책의 범위를 벗어나며, 예제에서는 항상NULL을 인자로 전달할 것입니다.)f: 새 스레드가 실행할 스레드 루틴 (함수 포인터).arg:f함수에 전달될 단일 입력 인자.
자신의 스레드 ID 확인하기
새로 생성된 스레드는 pthread_self 함수를 호출하여 자기 자신의 스레드 ID를 확인할 수 있습니다.
#include <pthread.h>
pthread_t pthread_self(void);
// 호출한 스레드의 ID를 반환12.3.4 스레드 종료하기
스레드는 다음 방식 중 하나로 종료됩니다:
- 스레드의 최상위 스레드 루틴이 반환(return)할 때, 스레드는 암시적으로(implicitly) 종료됩니다.
pthread_exit함수를 호출하여 스레드가 명시적으로(explicitly) 종료됩니다.-
주의: 만약 메인 스레드가
pthread_exit를 호출하면, 메인 스레드는 다른 모든 피어 스레드들이 종료될 때까지 기다립니다. 그 후, 메인 스레드와 전체 프로세스를thread_return값과 함께 종료시킵니다.#include <pthread.h> void pthread_exit(void *thread_return); // (절대 반환하지 않음)
-
- 어떤 피어 스레드가 리눅스
exit함수를 호출합니다. 이 함수는 프로세스와 그 프로세스에 연관된 모든 스레드를 즉시 종료시킵니다. - 다른 피어 스레드가 현재 스레드의 ID를 인자로 하여
pthread_cancel함수를 호출함으로써, 현재 스레드를 (강제로) 종료시킵니다.#include <pthread.h> int pthread_cancel(pthread_t tid); // 성공 시 0, 오류 시 0이 아닌 값 반환
12.3.5 종료된 스레드 회수하기
스레드는 pthread_join 함수를 호출하여 다른 스레드가 종료되기를 기다립니다.
#include <pthread.h>
int pthread_join(pthread_t tid, void **thread_return);
// 성공 시 0, 오류 시 0이 아닌 값 반환pthread_join 함수는 다음 작업들을 수행합니다.
- 스레드
tid가 종료될 때까지 블록(block)됩니다 (기다립니다). - 스레드가 종료되면, 해당 스레드 루틴이 반환한 제네릭 (
void *) 포인터 값을thread_return이 가리키는 위치에 할당합니다 (즉, 반환 값을 받아옵니다). - 종료된 스레드가 보유하고 있던 모든 메모리 리소스를 회수(reaps)합니다.
pthread_join의 한계
리눅스의 wait 함수(프로세스용)와 달리, pthread_join 함수는 오직 특정 스레드(tid)가 종료되는 것만 기다릴 수 있다는 점에 유의해야 합니다.
pthread_join에게 (프로세스의 wait(-1, ...)처럼) "임의의(arbitrary) 스레드 중 아무나 하나가" 종료되기를 기다리라고 지시할 방법이 없습니다.
이러한 제약은 우리가 덜 직관적인 다른 메커니즘을 사용하도록 강요함으로써 코드를 복잡하게 만들 수 있습니다. (실제로 Stevens는 이것이 Posix 명세(specification)의 버그라고 강력하게 주장합니다 [110].)
12.3.6 스레드 분리하기
어느 시점에서든 스레드는 결합 가능(joinable) 상태이거나 분리된(detached) 상태입니다.
- 결합 가능 (Joinable) 스레드:
- 다른 스레드에 의해 회수(reaped,
pthread_join)되거나 종료(killed)될 수 있습니다. - 스레드의 메모리 리소스(스택 등)는 다른 스레드에 의해 회수될 때까지 해제되지 않습니다.
- 다른 스레드에 의해 회수(reaped,
- 분리된 (Detached) 스레드:
- 다른 스레드에 의해 회수되거나 종료될 수 없습니다.
- 스레드가 종료될 때 시스템이 자동으로 메모리 리소스를 해제합니다.
기본적으로 스레드는 결합 가능(joinable) 상태로 생성됩니다. 메모리 누수(memory leaks)를 피하기 위해, 모든 joinable 스레드는 (1) 다른 스레드에 의해 명시적으로 회수되거나 (pthread_join), (2) pthread_detach 함수 호출을 통해 분리되어야 합니다.
#include <pthread.h>
int pthread_detach(pthread_t tid);
// 성공 시 0, 오류 시 0이 아닌 값 반환pthread_detach 함수는 joinable 스레드인 tid를 분리시킵니다.
스레드는 pthread_detach(pthread_self())를 인자로 호출하여 자기 자신을 분리시킬 수 있습니다.
분리된 스레드의 활용
(이 책의) 일부 예제에서는 joinable 스레드를 사용하지만, 실제 프로그램에서는 detached 스레드를 사용할 충분한 이유가 있습니다.
- 예시: 고성능 웹 서버는 웹 브라우저로부터 연결 요청을 받을 때마다 새로운 피어 스레드를 생성할 수 있습니다.
- 각 연결은 별도의 스레드에 의해 독립적으로 처리됩니다.
- 이때 서버(메인 스레드)가 각 피어 스레드가 종료될 때까지 명시적으로 기다리는(
join) 것은 불필요하며 바람직하지도 않습니다. - 해결책: 이 경우, 각 피어 스레드는 (클라이언트 요청) 처리를 시작하기 전에 스스로를 분리(detach)해야 합니다.
12.3.7 스레드 초기화하기
pthread_once 함수는 스레드 루틴과 연관된 (공유) 상태를 (단 한 번만) 초기화할 수 있게 해줍니다.
#include <pthread.h>// 제어 변수 초기화
pthread_once_t once_control = PTHREAD_ONCE_INIT;
int pthread_once(pthread_once_t *once_control, void (*init_routine)(void));
// (항상 0을 반환)once_control 변수는 전역(global) 변수 또는 정적(static) 변수여야 하며, 항상 PTHREAD_ONCE_INIT 값으로 초기화해야 합니다.
동작 방식:once_control 변수를 인자로 하여 pthread_once를 처음 호출하면, 이 함수는 init_routine을 호출합니다. (init_routine은 입력 인자와 반환 값이 없는 함수입니다.)
이후 동일한 once_control 변수를 사용하여 pthread_once를 다시 호출하면 (다른 스레드에서 호출하더라도) 아무 작업도 수행하지 않습니다.
용도:pthread_once 함수는 여러 스레드에 의해 공유되는 전역 변수를 동적으로 (그리고 딱 한 번만) 초기화해야 할 때 유용합니다. (12.5.5절에서 예제를 살펴볼 것입니다.)
12.3.8 스레드 기반 동시성 서버
Figure 12.14는 스레드를 기반으로 하는 동시성 에코 서버의 코드입니다.

전체적인 구조는 프로세스 기반 설계와 유사합니다. 메인 스레드가 반복적으로 연결 요청을 기다린 다음, 그 요청을 처리할 피어 스레드를 생성합니다.
코드는 간단해 보이지만, 우리가 자세히 살펴봐야 할 일반적이면서도 미묘한 두 가지 이슈가 있습니다.
1. 문제점 1: connfd 전달 시 발생하는 경쟁 상태 (Race Condition)
첫 번째 이슈는 pthread_create를 호출할 때 연결 디스크립터(connfd)를 피어 스레드에 어떻게 전달하는가입니다. 가장 뻔한 접근 방식은 디스크립터의 주소를 전달하는 것입니다.
[잘못된 예시]
// (메인 스레드)
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen);
Pthread_create(&tid, NULL, thread, connfd); // connfd의 주소를 전달// (피어 스레드)
void *thread(void *vargp) {
int connfd = *((int *)vargp); // 포인터를 역참조
...
}하지만 이 방식은 잘못되었습니다. 이는 피어 스레드의 할당문(connfd = ...)과 메인 스레드의 accept문 사이에 경쟁 상태(race)를 유발하기 때문입니다.
- 경쟁(Race) 시나리오:
- (메인 스레드)
Accept로connfd에 (예)5를 받음. - (메인 스레드)
Pthread_create로 스레드 A 생성 (&connfd전달). - (메인 스레드) 루프를 돌아 다음
Accept에서 블록됨. - (스레드 A)
connfd = *((int *)vargp);실행.5를 가져옴. (→ 성공)
- (메인 스레드)
- [치명적] 경쟁 시나리오:
- (메인 스레드)
Accept로connfd에 (예)5를 받음. - (메인 스레드)
Pthread_create로 스레드 A 생성 (&connfd전달). - (메인 스레드) 즉시 루프를 돌아 다음
Accept실행,connfd에 (예)6을 받음. (메인 스레드의connfd값이 덮어써짐) - (스레드 A) (뒤늦게)
connfd = *((int *)vargp);실행.&connfd를 역참조하여6을 가져옴. (→ 실패)
- (메인 스레드)
- 결과: 이 불행한 결과로, 두 스레드(스레드 A와 다음 스레드 B)가 동일한 디스크립터(6번)에서 입출력을 수행하게 됩니다.
- 해결책 (코드 21-22행):
이 잠재적으로 치명적인 경쟁을 피하려면,accept가 반환하는 각connfd를malloc을 통해 자신만의 동적 할당 메모리 블록에 할당해야 합니다. (Figure 12.14의 21-22행 참고)
2. 문제점 2: 메모리 누수 (Memory Leaks)
다른 이슈는 스레드 루틴에서 메모리 누수를 피하는 것입니다.
- 스레드 자체의 메모리 누수:
우리는 스레드를 명시적으로 회수(pthread_join)하지 않습니다. 따라서 각 스레드는 스스로를 분리(detach)해야 합니다(line 31,pthread_detach). 이렇게 해야 스레드 종료 시 스레드의 메모리 리소스(스택 등)가 시스템에 의해 자동으로 회수됩니다. malloc으로 할당된 메모리 누수:
(문제점 1의 해결책으로) 메인 스레드가 할당했던 메모리 블록을 피어 스레드가 반드시free해줘야 합니다(line 32).
12.4 스레드 프로그램의 공유 변수
프로그래머의 관점에서 스레드의 매력적인 점 중 하나는 여러 스레드가 동일한 프로그램 변수를 쉽게 공유할 수 있다는 것입니다. 하지만 이러한 공유는 까다로울 수 있습니다. 올바르게 스레드화된(threaded) 프로그램을 작성하려면, '공유'가 무엇을 의미하고 어떻게 작동하는지 명확히 이해해야 합니다.
프로그램의 변수가 공유되는지 아닌지 이해하기 위해 다음의 기본 질문들을 짚어봐야 합니다.
- 스레드의 근본적인(underlying) 메모리 모델은 무엇인가?
- 이 모델을 감안할 때, 변수의 인스턴스들은 메모리에 어떻게 매핑되는가?
- 마지막으로, 이 인스턴스 각각을 몇 개의 스레드가 참조하는가?
어떤 변수는 여러 스레드가 해당 변수의 동일 인스턴스를 참조할 경우에만(if and only if) '공유'됩니다.

공유에 대한 논의를 구체적으로 유지하기 위해, Figure 12.15의 프로그램을 실행 예제로 사용할 것입니다. 다소 인위적이긴 하지만, 공유에 대한 여러 미묘한 점들을 설명하기 때문에 연구할 가치가 있습니다.
이 예제 프로그램은 두 개의 피어 스레드를 생성하는 메인 스레드로 구성됩니다. 메인 스레드는 각 피어 스레드에 고유 ID(0 또는 1)를 전달하고, 피어 스레드는 이 ID를 사용하여 개인화된 메시지와 함께, 스레드 루틴이 호출된 총횟수(cnt)를 출력합니다.
12.4.1 스레드 메모리 모델
동시성 스레드 풀은 하나의 프로세스 컨텍스트 내에서 실행됩니다.
- 개별 소유 (Private):
각 스레드는 자신만의 별도 스레드 컨텍스트(thread context)를 가집니다. 여기에는 스레드 ID, 스택, 스택 포인터, 프로그램 카운터(PC), 조건 코드, 범용 레지스터 값이 포함됩니다. - 공유 (Shared):
각 스레드는 프로세스 컨텍스트의 나머지 부분은 다른 스레드와 공유합니다. 여기에는 전체 사용자 가상 주소 공간이 포함되며, 이 공간은 다음으로 구성됩니다.
- 읽기 전용 텍스트 (코드)
- 읽기/쓰기 데이터
- 힙 (Heap)
- 모든 공유 라이브러리 코드 및 데이터 영역
- 스레드들은 또한 동일한 열린 파일 집합을 공유합니다.
레지스터 vs. 가상 메모리
운영 관점에서, 한 스레드가 다른 스레드의 레지스터 값을 읽거나 쓰는 것은 불가능합니다.
반면에, 어떤 스레드든 공유 가상 메모리의 어떤 위치든 접근할 수 있습니다. 만약 한 스레드가 메모리 위치를 수정하면, 다른 모든 스레드도 (결국) 그 위치를 읽을 때 변경 사항을 보게 됩니다.
요약: 레지스터는 절대 공유되지 않으며, 가상 메모리는 항상 공유됩니다.
stack 스택 영역의 모델
별도의 스레드 스택에 대한 메모리 모델은 그렇게 깔끔하지 않습니다.
이 스택들은 (공유된) 가상 주소 공간의 스택 영역에 포함되어 있으며, "보통은" 각 스레드가 자신의 스택에만 독립적으로 접근합니다.
우리가 "항상"이 아닌 "보통"이라고 말하는 이유는, 스레드 스택들이 다른 스레드로부터 보호되지 않기(not protected) 때문입니다. 따라서, 만약 한 스레드가 어떻게든 다른 스레드의 스택을 가리키는 포인터를 얻게 된다면, 그 스택의 어떤 부분이든 읽고 쓸 수 있습니다.
(Figure 12.15 예제 프로그램의 26행에서 피어 스레드가 전역 변수 ptr을 통해 메인 스레드의 스택 내용을 간접적으로 참조하는 것이 바로 이 예시입니다.)
12.4.2 변수를 메모리에 매핑하기
스레드 C 프로그램의 변수들은 스토리지 클래스(storage classes)에 따라 가상 메모리에 매핑됩니다.
1. 전역 변수 (Global variables)
- 정의: 함수 외부에 선언된 모든 변수.
- 메모리 매핑:
- 런타임 시, 가상 메모리의 읽기/쓰기 영역에 각 전역 변수당 단 하나의 인스턴스만 존재합니다.
- 이 인스턴스는 어떤 스레드에서든 참조할 수 있습니다.
- 예시 (Figure 12.15):
- 5행에 선언된 전역 변수
ptr은 런타임 시 읽기/쓰기 영역에 단 하나의 인스턴스(ptr)만 존재합니다.
- 5행에 선언된 전역 변수
2. stack 지역 자동 변수 (Local automatic variables)
- 정의: 함수 내부에
static속성 없이 선언된 변수. - 메모리 매핑:
- 런타임 시, 각 스레드의 스택은 그 스레드 자신만의 지역 자동 변수 인스턴스들을 포함합니다.
- 이는 여러 스레드가 동일한 스레드 루틴을 실행하는 경우에도 마찬가지입니다.
- 예시 (Figure 12.15):
tid(main 함수 9행): 메인 스레드의 스택에tid.m이라는 인스턴스 하나가 존재합니다.myid(thread 함수 24행): 피어 스레드 0의 스택에myid.p0, 피어 스레드 1의 스택에myid.p1이라는 두 개의 개별 인스턴스가 존재합니다.
3. 지역 정적 변수 (Local static variables)
- 정의: 함수 내부에
static속성을 가지고 선언된 변수. - 메모리 매핑:
- 전역 변수와 마찬가지로, 가상 메모리의 읽기/쓰기 영역에 프로그램 전체에서 단 하나의 인스턴스만 존재합니다.
- 예시 (Figure 12.15):
cnt(thread 함수 25행): 예제 프로그램의 각 피어 스레드가cnt를 선언함에도 불구하고, 런타임 시에는 읽기/쓰기 영역에 단 하나의cnt인스턴스만 존재합니다.- 각 피어 스레드는 이 단일 인스턴스를 함께 읽고 씁니다.
12.4.3 공유 변수 (Shared Variables)
우리는 변수 v의 인스턴스 중 하나가 둘 이상의 스레드에 의해 참조될 경우에만 그 변수를 공유(shared)된다고 말합니다.
cnt(공유됨 O):
예를 들어, 우리 예제 프로그램(Figure 12.15)의cnt변수(지역 정적 변수)는 공유됩니다.cnt는 런타임 시 단 하나의 인스턴스만 가지며, 이 인스턴스를 두 피어 스레드가 모두 참조하기 때문입니다.myid(공유 안 됨 X):
반면에,myid변수(지역 자동 변수)는 공유되지 않습니다.myid는 두 개의 인스턴스(각 스레드의 스택에 하나씩)를 가지며, 각각의 인스턴스는 정확히 하나의 스레드에 의해서만 참조되기 때문입니다.msgs(공유될 수 있음!):
하지만, (main함수의 스택에 있는)msgs와 같은 지역 자동 변수(local automatic variable) 또한 공유될 수 있다는 것을 인지하는 것이 중요합니다. (이 경우,ptr이라는 전역 변수가msgs를 가리키고, 피어 스레드들이ptr을 통해msgs에 접근하므로 공유됩니다.)
