
12.5 세마포를 이용한 스레드 동기화
공유 변수는 편리하지만, 동기화 오류(synchronization errors)라는 고약한 문제를 일으킬 가능성을 도입합니다.

Figure 12.16의 badcnt.c 프로그램을 살펴봅시다. 이 프로그램은 두 개의 스레드를 생성하며, 각 스레드는 cnt라는 전역 공유 카운터 변수를 증가시킵니다.
각 스레드가 카운터를 niters 번씩 증가시키므로, 우리는 최종값이 가 될 것으로 기대합니다. 이는 매우 간단하고 명확해 보입니다.
하지만 리눅스 시스템에서 badcnt.c를 실행하면, 틀린 답이 나올 뿐만 아니라 실행할 때마다 다른 답이 나옵니다!
linux> ./badcnt 1000000
BOOM! cnt=1445085
linux> ./badcnt 1000000
BOOM! cnt=1915220
linux> ./badcnt 1000000
BOOM! cnt=1404746문제의 원인: 원자성(Atomic)이 깨진 연산
무엇이 잘못된 것일까요? 이 문제를 명확히 이해하려면, Figure 12.17에 나온 카운터 루프(lines 40–41)의 어셈블리 코드를 살펴봐야 합니다.
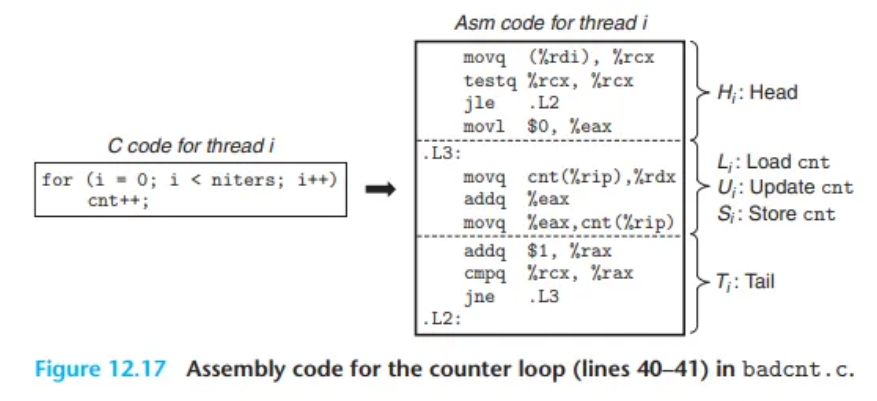
핵심은 C 코드 한 줄인 cnt++가 실제로는 단일 명령어가 아니라는 것입니다. 스레드 의 루프 코드를 5개 부분으로 나눌 수 있습니다.
- (Head): 루프의 시작 부분 (지역 변수 조작)
- (Load): 공유 변수
cnt를 스레드 의 레지스터%rdx_i로 불러오는 명령어. - (Update): 레지스터
%rdx_i의 값을 수정(증가)하는 명령어. - (Store): 수정된
%rdx_i의 값을 다시 공유 변수cnt에 저장하는 명령어. - (Tail): 루프의 끝 부분 (지역 변수 조작)
여기서 와 는 지역 스택 변수만 다루지만, , , 는 공유 카운터 변수 cnt의 내용을 조작합니다.
명령어 순서(Interleaving) 문제
두 스레드가 동시에 실행될 때, 기계어 명령어들은 어떤 순서로든 차례대로(interleaving, 뒤섞여서) 완료됩니다. 불행히도, 이 순서 중 일부는 올바른 결과를 생성하지만, 다른 순서들은 그렇지 않습니다.
여기서 핵심은 이것입니다: 일반적으로 프로그래머는 운영체제가 스레드에 대해 올바른 순서를 선택할지 예측할 방법이 없습니다.
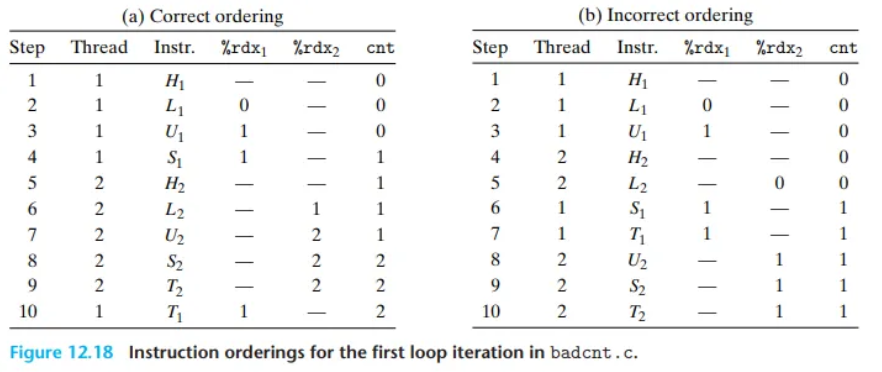
(a) 올바른 순서 (Correct ordering, Figure 12.18a)
- 스레드 1이
L_1(0 로드),U_1(1로 증가),S_1(1 저장)을 순서대로 실행합니다. - (이때
cnt의 메모리 값은 1이 됩니다.) - 스레드 2가
L_2(1 로드),U_2(2로 증가),S_2(2 저장)를 순서대로 실행합니다. - (이때
cnt의 메모리 값은 2가 됩니다.) - 결과:
cnt= 2 (정상)
(b) 잘못된 순서 (Incorrect ordering, Figure 12.18b)
- (스레드 1):
L_1(레지스터%rdx_1에 0을 로드) - (스레드 1):
U_1(레지스터%rdx_1을 1로 증가) - (스레드 2):
L_2(메모리의cnt는 아직 0이므로, 레지스터%rdx_2에 0을 로드) - (스레드 1):
S_1(자신의 레지스터 값 1을cnt에 저장.cnt= 1) - (스레드 2):
U_2(자신의 레지스터%rdx_2를 1로 증가) - (스레드 2):
S_2(자신의 레지스터 값 1을cnt에 저장.cnt= 1) - 결과:
cnt= 1 (오류!)
이 문제는 스레드 2가 cnt를 로드(Step 5)할 때, 스레드 1이 cnt를 로드(Step 2)한 후이면서, 스레드 1이 수정된 값을 저장(Step 6)하기 전에 발생했습니다.
결국, 두 스레드 모두 업데이트된 카운터 값으로 1을 저장하게 됩니다. (즉, 스레드 1의 작업이 무시됩니다.)
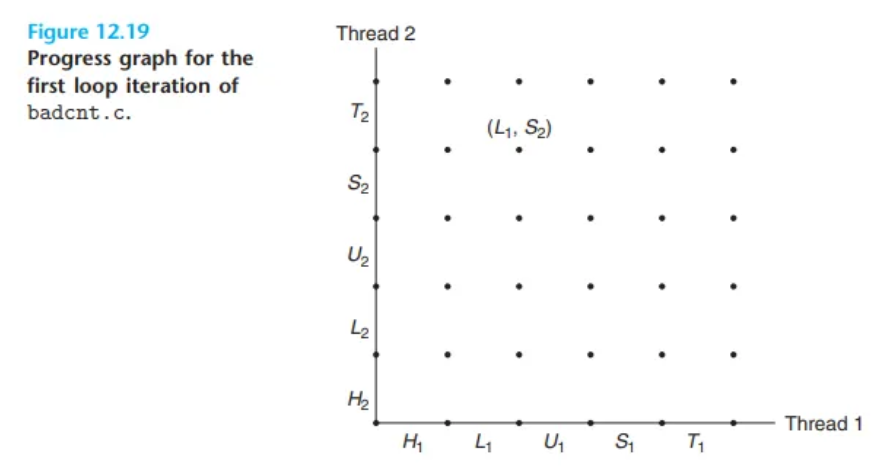
12.5.1 진행 그래프 (Progress Graphs)
- 진행 그래프(Progress graph)는 개의 동시성 스레드 실행을 차원 데카르트 공간의 경로(trajectory)로 모델링하는 도구입니다.
- 각 축 는 스레드 의 진행 상태를 나타냅니다.
- 각 점 은 스레드 가 명령어 를 완료했음을 나타내는 상태입니다.
- 원점은 어떤 스레드도 아직 명령어를 완료하지 않은 초기 상태입니다.
(Figure 12.19는 badcnt.c의 두 스레드를 2차원 그래프로 보여줍니다. 축은 스레드 1, 축은 스레드 2입니다.)
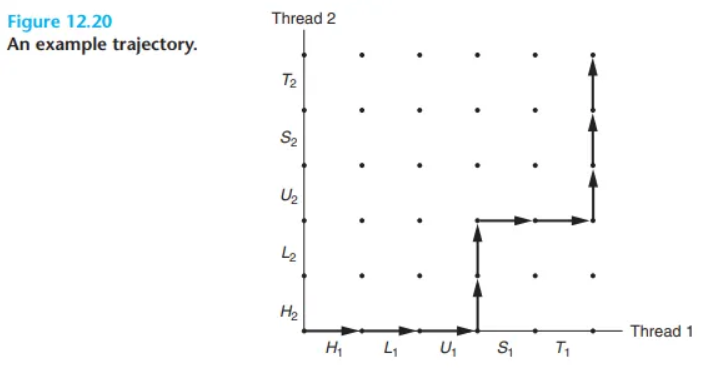
실행 경로 (Trajectory)
진행 그래프는 명령어 실행을 한 상태에서 다른 상태로의 전이(transition)로 모델링합니다.
- 합법적 전이 (Legal transitions):
- 오른쪽으로 이동: 스레드 1이 명령어 하나를 완료함.
- 위쪽으로 이동: 스레드 2가 명령어 하나를 완료함.
- 불법적 전이 (Illegal transitions):
- 대각선 이동: 두 명령어가 동시에 완료될 수 없습니다.
- 아래쪽/왼쪽 이동: 프로그램은 거꾸로 실행되지 않습니다.
프로그램의 실행 히스토리는 이 상태 공간을 통과하는 하나의 경로(trajectory)로 모델링됩니다. (Figure 12.20은 특정 명령어 순서에 해당하는 경로를 보여줍니다.)
임계 구역과 상호 배제
스레드 에서, 공유 변수 cnt의 내용을 조작하는 명령어들(, , )은 임계 구역(critical section)을 구성합니다.
- 이 임계 구역은 다른 스레드의 임계 구역과 뒤섞여서(interleaved) 실행되어서는 안 됩니다.
- 즉, 각 스레드가 자신의 임계 구역을 실행하는 동안 공유 변수에 대한 상호 배타적인 접근(mutually exclusive access)을 보장해야 합니다. 이 현상을 일반적으로 상호 배제(mutual exclusion)라고 합니다.
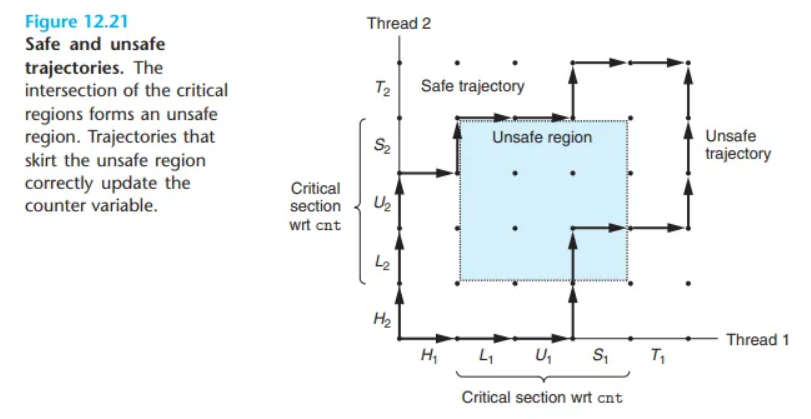
위험 영역 (Unsafe Region)
진행 그래프 상에서, 두 임계 구역이 교차(intersection)하는 영역은 위험 영역(unsafe region)이라고 알려진 상태 공간 영역을 정의합니다.
- Figure 12.21은
cnt변수에 대한 위험 영역을 보여줍니다. - (참고: 위험 영역의 경계선(perimeter)은 위험 영역에 포함되지 않습니다.)
- 안전한 경로 (Safe Trajectory): 위험 영역을 비껴가는 경로입니다.
- 안전하지 않은 경로 (Unsafe Trajectory): 위험 영역의 어떤 부분이라도 건드리는 경로입니다.
- (Figure 12.18b의 "잘못된 순서"가 바로 이 위험 영역을 통과하는 경로에 해당합니다.)
동기화의 목표
안전한 경로만이 공유 카운터를 올바르게 업데이트합니다.
공유 데이터를 사용하는 동시성 프로그램의 올바른 실행을 보장하려면, 스레드들이 항상 안전한 경로를 갖도록 스레드들을 어떻게든 동기화(synchronize)해야 합니다.
(이를 위한 고전적인 접근 방식이 바로 다음에 소개할 '세마포'입니다.)
12.5.2 세마포 (Semaphores)
동시성 프로그래밍의 선구자인 에츠허르 다익스트라(Edsger Dijkstra)는 세마포(semaphore)라는 특별한 타입의 변수에 기반한, 서로 다른 실행 스레드를 동기화하는 고전적인 해법을 제안했습니다.
세마포 는 음이 아닌 정수 값을 갖는 전역 변수이며, 오직 다음과 같은 두 가지 특별한 연산, P와 V에 의해서만 조작될 수 있습니다.
- P(s):
- 만약 가 0이 아니면(non-zero), 는 를 1 감소시키고 즉시 리턴합니다.
- 만약 가 0이면, 가 0이 아닌 값이 될 때까지 (그리고 연산에 의해 스레드가 재시작될 때까지) 스레드를 일시 중단(suspend)시킵니다.
- 스레드가 재시작된 후, 연산은 를 1 감소시키고 제어권을 호출자에게 반환합니다.
- V(s):
- 연산은 를 1 증가시킵니다.
- 만약 가 0이 되기를 기다리며 연산에서 블록(block)된 스레드들이 있다면, 연산은 이 스레드들 중 정확히 하나를 재시작시킵니다.
- 재시작된 스레드는 를 1 감소시키며 자신의 연산을 완료합니다.
원자성(Indivisibility) 및 중요 속성
연산에서의 "검사(test)"와 "감소(decrement)"는 불가분(indivisibly, 원자적으로) 일어납니다. 즉, 일단 세마포 가 0이 아닌 값이 되면, 의 감소는 어떠한 중단(interruption) 없이 발생합니다. 연산에서의 "증가" 역시 (값을 불러오고, 증가시키고, 저장하는 과정이) 중단 없이 불가분하게 일어납니다.
의 정의는 대기 중인 스레드가 어떤 순서로 재시작될지 정의하지 않는다는 점에 유의해야 합니다. 유일한 요구 사항은 가 정확히 하나의 대기 중인 스레드를 재시작해야 한다는 것입니다. 따라서 여러 스레드가 세마포에서 대기 중일 때, 연산의 결과로 어떤 스레드가 재시작될지 예측할 수 없습니다.
와 의 정의는, 올바르게 초기화된 세마포 값이 실행 중에 절대 음수(-)가 될 수 없음을 보장합니다. 이 속성은 세마포 불변성(semaphore invariant)이라고 알려져 있으며, 다음 섹션에서 보게 될 것처럼 동시성 프로그램의 경로(trajectories)를 제어하는 강력한 도구를 제공합니다.
Posix 세마포 함수
Posix 표준은 세마포를 조작하기 위한 다양한 함수를 정의합니다.
#include <semaphore.h>
int sem_init(sem_t *sem, 0, unsigned int value);
int sem_wait(sem_t *s); /* P(s) */
int sem_post(sem_t *s); /* V(s) */
// 성공 시 0, 오류 시 -1 반환sem_init 함수는 세마포 sem을 value 값으로 초기화합니다. 각 세마포는 사용되기 전에 반드시 초기화되어야 합니다. (우리의 목적상 가운데 인자는 항상 0입니다.)
프로그램은 sem_wait 함수와 sem_post 함수를 호출하여 각각 P 연산과 V 연산을 수행합니다. (CSAPP에서는 간결함을 위해, 이 함수들을 감싼 다음과 같은 래퍼(wrapper) 함수를 사용할 것입니다.)
#include "csapp.h"
void P(sem_t *s); /* sem_wait의 래퍼 함수 */
void V(sem_t *s); /* sem_post의 래퍼 함수 */
// (리턴값 없음)12.5.3 상호 배제를 위해 세마포 사용하기
세마포는 공유 변수에 대한 상호 배타적인 접근(mutually exclusive access)을 보장하는 편리한 방법을 제공합니다. 기본 아이디어는 각 공유 변수(또는 연관된 변수 집합)에 대해 초기값이 1인 세마포 를 하나씩 연관시키고, 해당 임계 구역(critical section)을 P(s)와 V(s) 연산으로 감싸는 것입니다.
용어 정리
- 이진 세마포 (Binary Semaphore): 공유 변수를 보호하기 위해 이런 식으로 사용되는 세마포를 말합니다. 값은 항상 0 또는 1입니다.
- 뮤텍스 (Mutex): 상호 배제(Mutual Exclusion)를 제공하는 것이 목적인 이진 세마포를 종종 뮤텍스라고 부릅니다.
- Locking (잠금): 뮤텍스에
P연산을 수행하는 것. - Unlocking (해제):
V연산을 수행하는 것. - Holding (보유): 락을 획득(lock)했지만 아직 해제(unlock)하지 않은 스레드를 "뮤텍스를 보유(holding)하고 있다"고 말합니다.
- 카운팅 세마포 (Counting Semaphore): (이진 세마포와 달리) 가용 자원 집합의 '개수'를 세는 카운터로 사용되는 세마포입니다.
진행 그래프로 이해하기 (Figure 12.22)
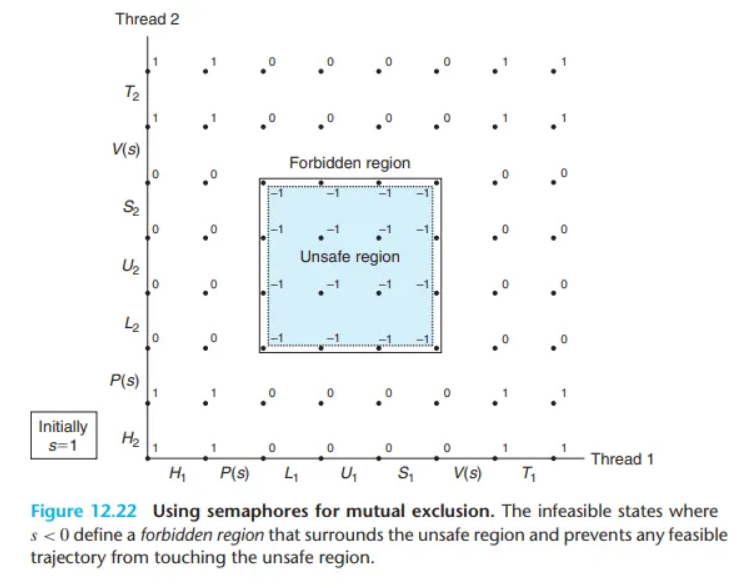
Figure 12.22의 진행 그래프는 이진 세마포를 사용하여 카운터 프로그램을 올바르게 동기화하는 방법을 보여줍니다.
각 상태는 그 상태에서의 세마포 의 값을 함께 표시합니다.
여기서 핵심 아이디어는, P와 V 연산의 조합이 이 되는 상태의 집합, 즉 "금지된 영역(forbidden region)"을 생성한다는 것입니다.
"세마포 불변성"(세마포 값은 절대 음수가 될 수 없음) 때문에, 실행 가능한 어떠한 경로(trajectory)도 이 "금지된 영역"에 포함된 상태를 가질 수 없습니다.
그리고 이 "금지된 영역"이 (경쟁 상태가 발생하는) "위험 영역(unsafe region)"을 완전히 둘러싸고 있습니다.
결과적으로, 실행 가능한 모든 경로는 "금지된 영역"을 피해서 가야 하므로, "위험 영역" 또한 자동으로 피하게 됩니다. 따라서 모든 실행 경로는 "안전한 경로(safe trajectory)"가 되며, 런타임 시 명령어 순서가 어떻게 되든 관계없이 프로그램은 카운터를 올바르게 증가시킵니다.
운영 관점에서, P와 V 연산이 만든 "금지된 영역"은 여러 스레드가 동시에 "위험 영역" 안의 임계 구역 명령어를 실행하는 것을 불가능하게 만듭니다. 즉, 세마포 연산이 임계 구역에 대한 상호 배타적인 접근을 보장합니다.
badcnt.c 수정하기 (goodcnt.c)
요약하자면, Figure 12.16의 예제 카운터 프로그램을 세마포를 사용해 올바르게 동기화하려면, 먼저 mutex라는 세마포를 선언합니다.
volatile long cnt = 0; /* 카운터 */
sem_t mutex; /* 카운터를 보호할 세마포 */그리고 main 루틴에서 이 세마포를 1로 초기화합니다.
Sem_init(&mutex, 0, 1); /* mutex = 1 */마지막으로, 스레드 루틴에서 공유 변수 cnt를 업데이트하는 부분을 P와 V 연산으로 감싸줍니다.
for (i = 0; i < niters; i++) {
P(&mutex);
cnt++;
V(&mutex);
}이렇게 올바르게 동기화된 프로그램을 실행하면, 이제 매번 정확한 결과가 나옵니다.
linux> ./goodcnt 1000000
OK cnt=2000000
linux> ./goodcnt 1000000
OK cnt=2000000부가 설명: 진행 그래프의 한계
진행 그래프(Progress graph)는 단일 프로세서(uniprocessor)에서의 동시성 프로그램 실행을 시각화하고, 왜 동기화가 필요한지 이해하는 데 좋은 방법을 제공합니다.
하지만 이 그래프는 한계가 있습니다. 특히 멀티프로세서(multiprocessor) (여러 CPU/캐시 쌍이 동일한 메인 메모리를 공유하는 환경)에서의 동시 실행을 설명하는 데 한계가 있습니다.
멀티프로세서는 진행 그래프로 설명할 수 없는 방식으로 동작합니다. 구체적으로, 멀티프로세서 메모리 시스템은 진행 그래프 상의 어떤 경로(trajectory)에도 해당하지 않는 상태에 있을 수 있습니다.
그럼에도 불구하고, 결론은 동일합니다:
단일 프로세서에서 실행하든, 멀티프로세서에서 실행하든 상관없이, 공유 변수에 대한 접근은 항상 동기화해야 합니다.
12.5.4 공유 자원 스케줄링을 위해 세마포 사용하기
상호 배제를 제공하는 것 외에, 세마포의 또 다른 중요한 용도는 공유 자원에 대한 접근을 스케줄링(scheduling)하는 것입니다.
이 시나리오에서, 한 스레드는 프로그램의 어떤 상태 조건이 참(true)이 되었음을 다른 스레드에게 알리기 위해(notify) 세마포 연산을 사용합니다.
이에 대한 고전적이고 유용한 두 가지 예시로 생산자-소비자(producer-consumer) 문제와 읽기-쓰기(readers-writers) 문제가 있습니다.
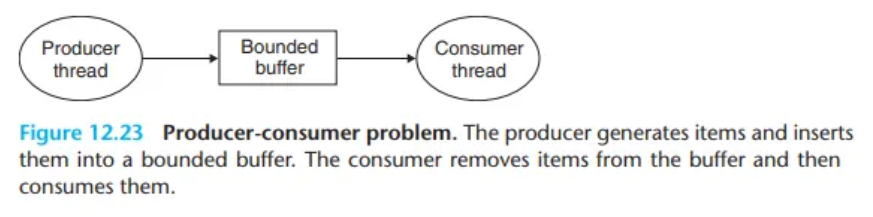
1. 생산자-소비자 문제 (Producer-Consumer Problem)
이 문제는 n개의 슬롯을 가진 공유 유한 버퍼(bounded buffer)를 생산자(Producer) 스레드와 소비자(Consumer) 스레드가 공유하는 상황을 다룹니다.
- 생산자: 새 아이템을 반복적으로 생성하여 버퍼에 삽입합니다.
- 소비자: 버퍼에서 아이템을 반복적으로 제거하여 사용합니다.
동기화 요구사항
이 문제를 해결하기 위해서는 두 가지 동기화가 필요합니다.
- 상호 배제 (Mutual Exclusion): 버퍼 자체(예:
front,rear인덱스)를 수정하는 작업은 원자적(atomic)으로 일어나야 합니다. - 스케줄링 (Scheduling):
- 버퍼가 가득 차면 (슬롯 0개): 생산자는 빈 슬롯이 생길 때까지 대기(wait)해야 합니다.
- 버퍼가 비어있으면 (아이템 0개): 소비자는 새 아이템이 생길 때까지 대기(wait)해야 합니다.
(예: 멀티미디어 인코더(생산자)와 디코더(소비자), GUI의 이벤트 탐지(생산자)와 화면 그리기(소비자))
Sbuf 패키지: 세마포 3개를 이용한 해결책
Figure 12.24와 12.25의 Sbuf 패키지는 이 문제를 세 개의 세마포를 이용해 우아하게 해결합니다.

sbuf_t 구조체는 다음 3개의 세마포를 가집니다.
mutex(뮤텍스): (초기값: 1) 버퍼 접근에 대한 상호 배제를 보장하는 이진 세마포입니다.slots(슬롯): (초기값: ) 사용 가능한 빈 슬롯의 개수를 세는 카운팅 세마포입니다.items(아이템): (초기값: 0) 버퍼에 들어있는 아이템의 개수를 세는 카운팅 세마포입니다.
sbuf_insert (생산자) 함수

void sbuf_insert(sbuf_t *sp, int item) {
P(&sp->slots); // 1. 빈 슬롯을 기다린다. (slots--. 0이면 대기)
P(&sp->mutex); // 2. 버퍼를 잠근다. (상호 배제)
// (버퍼에 아이템 삽입)
V(&sp->mutex); // 3. 버퍼 잠금을 해제한다.
V(&sp->items); // 4. 새 아이템이 생겼다고 알린다. (items++)
}sbuf_remove (소비자) 함수

int sbuf_remove(sbuf_t *sp) {
int item;
P(&sp->items); // 1. 아이템을 기다린다. (items--. 0이면 대기)
P(&sp->mutex); // 2. 버퍼를 잠근다. (상호 배제)
// (버퍼에서 아이템 제거)
V(&sp->mutex); // 3. 버퍼 잠금을 해제한다.
V(&sp->slots); // 4. 빈 슬롯이 생겼다고 알린다. (slots++)
return item;
}2. 읽기-쓰기 문제 (Readers-Writers Problem)
이 문제는 읽기 스레드(Readers)와 쓰기 스레드(Writers)가 공유 객체에 접근할 때 발생합니다.
- 규칙:
- 읽기(Readers): 여러 읽기 스레드가 동시에 객체를 읽는 것은 허용됩니다.
- 쓰기(Writers): 쓰기 스레드는 반드시 독점적으로(exclusive) 접근해야 합니다. (즉, 다른 읽기 스레드나 쓰기 스레드가 없어야 함)
(예: 항공사 예약 시스템 (다수가 좌석 조회, 한 명만 예약), 웹 프록시 캐시 (다수가 캐시 읽기, 한 스레드만 캐시 쓰기))
문제의 변형 (우선순위)
- 제1 문제 (읽기 우선): 읽기 스레드가 기다리지 않도록 합니다. 즉, 쓰기 스레드가 기다리고 있더라도, 읽기 스레드가 있다면 다른 읽기 스레드들이 계속 진입할 수 있습니다.
- 제2 문제 (쓰기 우선): 쓰기 스레드가 준비되면 가능한 한 빨리 쓰기를 수행합니다. 쓰기 스레드가 기다리면, 나중에 도착한 읽기 스레드도 함께 기다려야 합니다.
제1 문제 (읽기 우선)의 해결책
이 해결책은 2개의 세마포와 1개의 카운트 변수를 사용합니다.
w(쓰기 락): (초기값: 1) 공유 객체 자체에 대한 접근을 제어합니다. (읽기/쓰기 모두 사용)mutex(뮤텍스): (초기값: 1)readcnt변수를 보호하기 위한 상호 배제 락입니다.readcnt(카운터): (초기값: 0) 현재 임계 구역에 있는 읽기 스레드의 수를 셉니다.
쓰기(Writer) 로직 (간단함)

P(w); // 객체에 대한 독점 락을 획득
// (쓰기 작업 수행)
V(w); // 객체 락 해제읽기(Reader) 로직 (미묘함)

P(mutex); // readcnt를 잠근다
readcnt++; // 읽기 스레드 수 증가
if (readcnt == 1) // (중요) 내가 "첫 번째" 읽기 스레드라면
P(w); // 쓰기 스레드를 막기 위해 객체 락을 획득
V(mutex); // readcnt 잠금 해제
// (읽기 작업 수행)
P(mutex); // readcnt를 잠근다
readcnt--; // 읽기 스레드 수 감소
if (readcnt == 0) // (중요) 내가 "마지막" 읽기 스레드라면
V(w); // 쓰기 스레드가 진입할 수 있도록 객체 락을 해제
V(mutex); // readcnt 잠금 해제이 방식에서, w 세마포는 첫 번째 읽기 스레드가 락을 잡고, 마지막 읽기 스레드가 락을 해제합니다. 중간에 있는 읽기 스레드들(readcnt가 1 이상일 때)은 w 락을 무시하고 자유롭게 진입합니다.
- 기아(Starvation) 문제: 이 해결책(읽기 우선)은 읽기 스레드들이 계속 이어서 도착할 경우, 쓰기 스레드가 무한정 대기하는 '쓰기 기아(writer starvation)' 상태를 유발할 수 있습니다.
12.5.5 종합: 미리 스레드 생성하기(Prethreading) 기반의 동시성 서버
지금까지 세마포가 공유 변수 접근(상호 배제)과 공유 자원 접근 스케줄링에 어떻게 사용되는지 살펴보았습니다. 이 아이디어들을 미리 스레드 생성하기(prethreading)라는 기법에 기반한 동시성 서버에 적용해 보겠습니다.
1. 문제점과 접근 방식
- 이전 방식의 문제 (Figure 12.14):
이전의 스레드 기반 서버는 새 클라이언트마다 새 스레드를 생성(pthread_create)했습니다. 이 접근 방식은 클라이언트가 새로 올 때마다 스레드를 생성하는 상당한 (nontrivial) 오버헤드(비용)를 유발합니다. - 새로운 방식 (Prethreading):
Prethreading 기반 서버는 이 오버헤드를 줄이기 위해 생산자-소비자(Producer-Consumer) 모델을 사용합니다 (Figure 12.27). - 서버는 **메인 스레드** 1개와 **워커 스레드(Worker threads) 풀(pool)**로 구성됩니다. - **메인 스레드 (생산자):** 클라이언트의 연결 요청을 반복적으로 수락(`Accept`)하고, 그 결과로 생성된 **연결 디스크립터(`connfd`)**를 유한 버퍼(bounded buffer)에 **삽입(Insert)**합니다. - **워커 스레드 (소비자):** 버퍼에서 `connfd`를 반복적으로 **제거(Remove)**하고, 해당 클라이언트를 서비스(service)한 후, 다음 `connfd`를 기다립니다.
2. echoserver-pre.c 구현 (Figure 12.28)
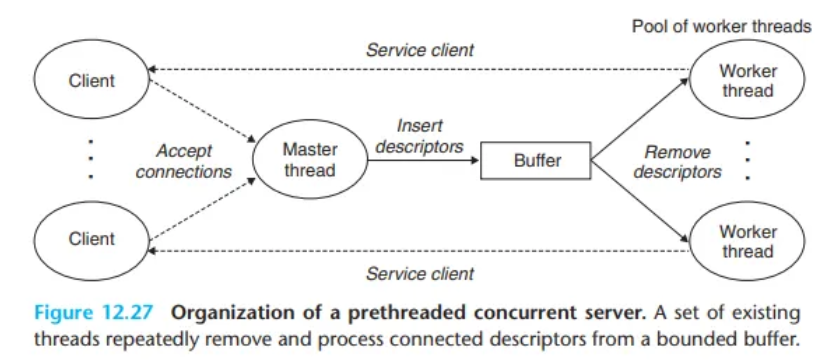
Figure 12.28은 Sbuf 패키지(이전 섹션의 생산자-소비자 버퍼)를 사용하여 prethreaded 동시성 에코 서버를 구현하는 방법을 보여줍니다.
main스레드 (생산자):sbuf_init(line 24): 공유 버퍼sbuf를 초기화합니다.for루프 (lines 25–26):NTHREADS개수만큼 워커 스레드들을 미리 생성합니다.while (1)(lines 28–31): 메인 스레드는 무한 루프에 진입하여,Accept(연결 수락)와sbuf_insert(버퍼에connfd삽입) 작업만 반복 수행합니다.
thread(워커 스레드 루틴):Pthread_detach(line 36): 스레드가join될 필요 없도록 스스로를 분리(detach)합니다.while (1)(lines 38–42):connfd = sbuf_remove(&sbuf)(line 39):Sbuf에서connfd를 꺼냅니다. (만약 버퍼가 비어있으면,sbuf_remove내부의P(&items)에서 블록(block)됩니다.)echo_cnt(connfd)(line 40): 클라이언트 서비스 함수를 호출합니다.Close(connfd)(line 41): 서비스가 끝나면 연결을 닫습니다.- (다시 루프의 처음으로 돌아가 다음
connfd를 기다립니다.)
3. echo_cnt 함수: 스레드 안전한 패키지 설계 (Figure 12.29)

echo_cnt 함수는 모든 클라이언트로부터 받은 누적 바이트 수를 byte_cnt라는 전역 변수에 기록하는 echo 버전입니다. 이 코드는 스레드 루틴에서 호출되는 패키지를 초기화하는 일반적인 기법을 보여주므로 중요합니다.
여기서는 byte_cnt 카운터와 mutex 세마포를 초기화해야 합니다.
- 기법 1:
pthread_once를 이용한 초기화- (메인 스레드가 명시적으로
init함수를 호출하는 대신)pthread_once함수(line 19)를 사용합니다. pthread_once는 어떤 스레드든echo_cnt를 최초로 호출했을 때, 초기화 함수(init_echo_cnt)가 단 한 번만 실행되도록 보장합니다.- 장점: 패키지 사용이 쉬워집니다. (메인 스레드가
init호출을 신경 쓸 필요 없음) - 단점:
echo_cnt가 호출될 때마다 (대부분 쓸데없는)pthread_once함수를 호출하는 비용이 듭니다.
- (메인 스레드가 명시적으로
- 기법 2:
P/V를 이용한 상호 배제init_echo_cnt가 실행되면,byte_cnt는 0,mutex는 1로 초기화됩니다.echo_cnt가 실제 작업을 할 때, 공유 변수byte_cnt에 접근하는 부분(lines 23–25)은P(&mutex)와V(&mutex)연산으로 감싸져 보호됩니다.- 이를 통해
badcnt.c에서 발생했던 경쟁 상태(race condition)를 방지하고byte_cnt가 올바르게 증가하도록 보장합니다.
부가 설명: 다른 동기화 기법들
(Aside: Other synchronization mechanisms)
우리는 주로 세마포(semaphores)를 사용하여 스레드를 동기화하는 방법을 보여드렸습니다. 세마포가 단순하고 고전적이며 깔끔한 의미론적 모델을 가지고 있기 때문입니다.
하지만 다른 동기화 기법들도 존재한다는 것을 알아야 합니다.
- Java 모니터 (Java Monitor):
예를 들어, Java 스레드는 "Java 모니터"라는 메커니즘으로 동기화됩니다. 이는 세마포의 상호 배제 및 스케줄링 기능을 더 높은 수준으로 추상화한 것을 제공합니다. (실제로 모니터는 세마포로 구현될 수 있습니다.) - Pthreads 뮤텍스와 조건 변수 (Mutex and Condition Variables):
또 다른 예로, Pthreads 인터페이스는 뮤텍스(mutex)와 조건 변수(condition variables)에 대한 동기화 연산들을 정의합니다.
- Pthreads 뮤텍스: 상호 배제를 위해 사용됩니다.
- Pthreads 조건 변수: 생산자-소비자 프로그램의 유한 버퍼와 같은 공유 자원에 대한 접근을 스케줄링(scheduling)하기 위해 사용됩니다.
부가 설명: 스레드 기반의 이벤트 기반 프로그램
(Aside: Event-driven programs based on threads)
I/O 멀티플렉싱만이 이벤트 기반(event-driven) 프로그램을 작성하는 유일한 방법은 아닙니다.
예를 들어, 우리가 방금 개발한 동시성 prethreaded 서버 (12.5.5절) 역시 메인 스레드와 워커 스레드를 위한 간단한 상태 머신을 가진 이벤트 기반 서버라는 것을 눈치챘을 것입니다.
- 메인 스레드 (생산자):
- 2개의 상태: "연결 요청 기다림" (accept), "버퍼의 빈 슬롯 기다림" (P(slots))
- 2개의 이벤트: "연결 요청 도착", "버퍼 슬롯 사용 가능" (V(slots))
- 2개의 트랜지션(상태 전이): "연결 요청 수락", "버퍼 아이템 삽입"
- 각 워커 스레드 (소비자):
- 1개의 상태: "버퍼 아이템 기다림" (P(items))
- 1개의 이벤트: "버퍼 아이템 사용 가능" (V(items))
- 1개의 트랜지션(상태 전이): "버퍼 아이템 제거"
