📖 01. 람다식(Lambda Expression)

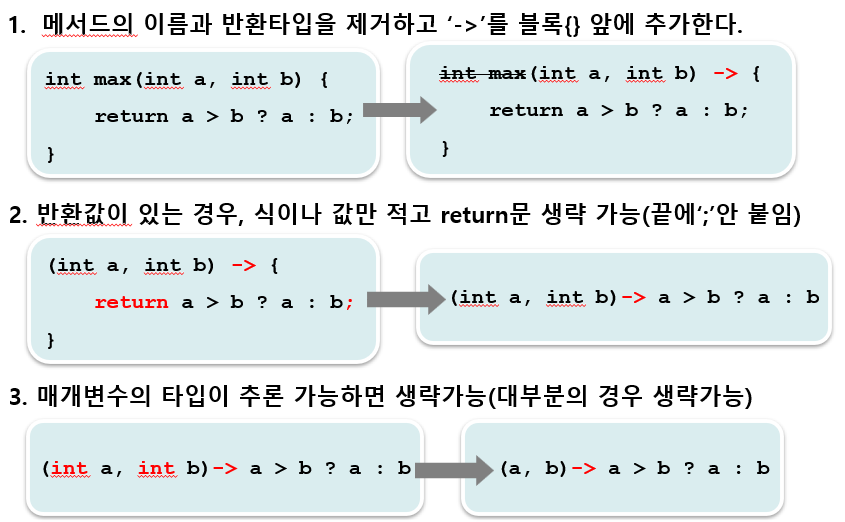
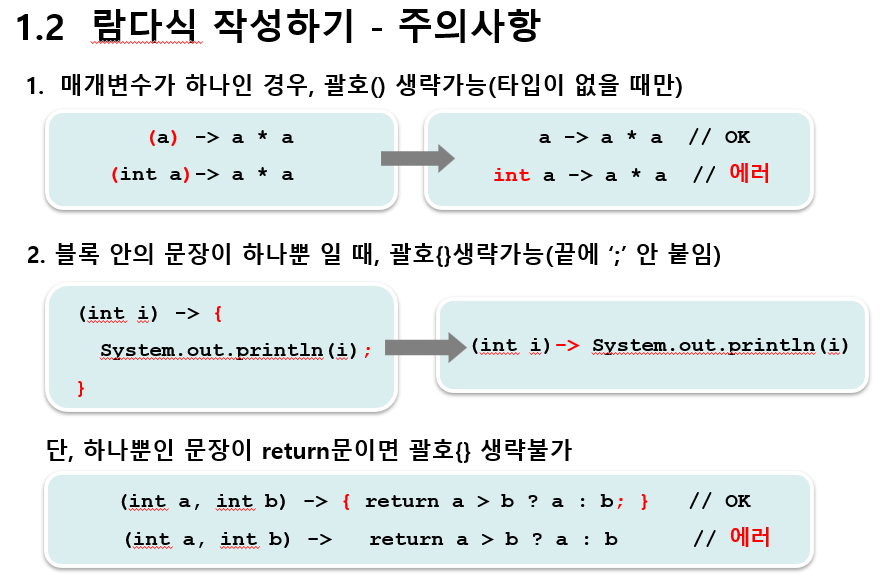
📖 02. 람다식 작성하기
📖 03. 람다식의 예

📖 04. 람다식은 익명 함수? 익명 객체!
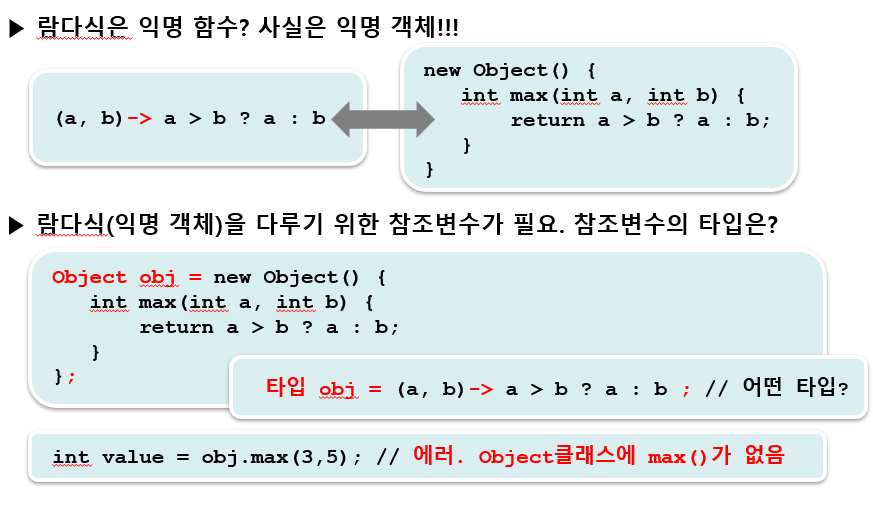
-> 참조변수의 타입은? : 참조형이므로 클래스 또는 인터페이스가 가능하다. 그리고 람다식과 동등한 메서드가 정의되어 있는 것이어야 한다. 그래야 참조변수로 익명 객체(람다식)의 메서드를 호출 할 수 있다.
📖 05. 함수형 인터페이스(Functional Interface)

-> 함수형 인터페이스의 추상 메서드의 매개변수와 반환값과 람다식이 일치해야 한다.
-> 1 : 1 로 람다식과 메서드가 일치해야 하기 때문에 함수형 인터페이스를 사용해야 한다.
📖 06. 함수형 인터페이스 타입의 매개변수, 반환 타입
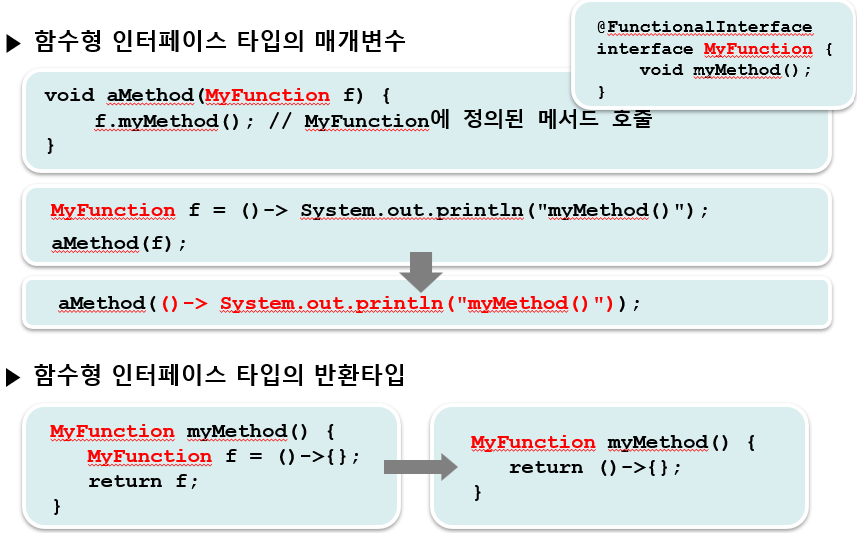
-> 람다식을 참조변수로 다룰 수 있다는 것은 메서드를 통해 람다식을 주고받을 수 있다는 것을 의미한다. 즉, 변수처럼 메서드를 주고받는 것이 가능해진 것이다.
<예제 14-1 >
✍️ 입력
@FunctionalInterface
interface MyFunction {
void run(); // public abstract void run();
}
class Ex14_1 {
static void execute(MyFunction f) { // 매개변수의 타입이 MyFunction인 메서드
f.run();
}
static MyFunction getMyFunction() { // 반환 타입이 MyFunction인 메서드
MyFunction f = () -> System.out.println("f3.run()");
return f;
}
public static void main(String[] args) {
// 람다식으로 MyFunction의 run()을 구현
MyFunction f1 = ()-> System.out.println("f1.run()");
MyFunction f2 = new MyFunction() { // 익명클래스로 run()을 구현
public void run() { // public을 반드시 붙여야 함
System.out.println("f2.run()");
}
};
MyFunction f3 = getMyFunction();
f1.run();
f2.run();
f3.run();
execute(f1);
execute( ()-> System.out.println("run()") );
}
}💻 출력
f1.run()
f2.run()
f3.run()
f1.run()
run()
📖 07. java.util.function패키지


-> 3개이상의 매개변수를 받고 싶다면 직접 만들어주자!

📖 08. java.util.function패키지 예제
<예제 14-2 >
✍️ 입력
import java.util.function.*;
import java.util.*;
class Ex14_2 {
public static void main(String[] args) {
Supplier<Integer> s = ()-> (int)(Math.random()*100)+1;
Consumer<Integer> c = i -> System.out.print(i+", ");
Predicate<Integer> p = i -> i%2==0;
Function<Integer, Integer> f = i -> i/10*10; // i의 일의 자리를 없앤다.
List<Integer> list = new ArrayList<>();
makeRandomList(s, list);
System.out.println(list);
printEvenNum(p, c, list);
List<Integer> newList = doSomething(f, list);
System.out.println(newList);
}
static <T> List<T> doSomething(Function<T, T> f, List<T> list) {
List<T> newList = new ArrayList<T>(list.size());
for(T i : list) {
newList.add(f.apply(i));
}
return newList;
}
static <T> void printEvenNum(Predicate<T> p, Consumer<T> c, List<T> list) {
System.out.print("[");
for(T i : list) {
if(p.test(i))
c.accept(i);
}
System.out.println("]");
}
static <T> void makeRandomList(Supplier<T> s, List<T> list) {
for(int i=0;i<10;i++) {
list.add(s.get());
}
}
}💻 출력
[3, 21, 6, 65, 64, 54, 73, 100, 21, 38]
[6, 64, 54, 100, 38, ]
[0, 20, 0, 60, 60, 50, 70, 100, 20, 30]
📖 09. Predicate의 결합

📖 10. Predicate의 결합 예제
<예제 14-3 >
✍️ 입력
import java.util.function.*;
class Ex14_3 {
public static void main(String[] args) {
Function<String, Integer> f = (s) -> Integer.parseInt(s, 16);
Function<Integer, String> g = (i) -> Integer.toBinaryString(i);
Function<String, String> h = f.andThen(g);
Function<Integer, Integer> h2 = f.compose(g);
System.out.println(h.apply("FF")); // "FF" → 255 → "11111111"
System.out.println(h2.apply(2)); // 2 → "10" → 16
Function<String, String> f2 = x -> x; // 항등 함수(identity function)
System.out.println(f2.apply("AAA")); // AAA가 그대로 출력됨
Predicate<Integer> p = i -> i < 100;
Predicate<Integer> q = i -> i < 200;
Predicate<Integer> r = i -> i%2 == 0;
Predicate<Integer> notP = p.negate(); // i >= 100
Predicate<Integer> all = notP.and(q.or(r));
System.out.println(all.test(150)); // true
String str1 = "abc";
String str2 = "abc";
// str1과 str2가 같은지 비교한 결과를 반환
Predicate<String> p2 = Predicate.isEqual(str1);
boolean result = p2.test(str2);
System.out.println(result);
}
}💻 출력
11111111
16
AAA
true
true
📖 11. 컬렉션 프레임웍과 함수형 인터페이스

📖 12. 컬렉션 프레임웍과 함수형 인터페이스 예제
<예제 14-4 >
✍️ 입력
import java.util.*;
class Ex14_4 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
for(int i=0;i<10;i++)
list.add(i);
// list의 모든 요소를 출력
list.forEach(i->System.out.print(i+","));
System.out.println();
// list에서 2 또는 3의 배수를 제거한다.
list.removeIf(x-> x%2==0 || x%3==0);
System.out.println(list);
list.replaceAll(i->i*10); // list의 각 요소에 10을 곱한다.
System.out.println(list);
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
map.put("4", "4");
// map의 모든 요소를 {k,v}의 형식으로 출력한다.
map.forEach((k,v)-> System.out.print("{"+k+","+v+"},"));
System.out.println();
}
}💻 출력
0,1,2,3,4,5,6,7,8,9,
[1, 5, 7]
[10, 50, 70]
{1,1},{2,2},{3,3},{4,4},
📖 13. 메서드 참조

-> 하나의 메서드만 호출하는 람다식은 '클래스이름::메서드이름' 또는 '참조변수::메서드이름'으로 바꿀 수 있다.
📖 14. 생성자의 메서드 참조

📖 15. 스트림(Stream)

-> 데이터 소스마다 다른 방식으로 다뤄야한다는 문제점을 해결하기 위해 Stream 탄생
-> 스트림은 데이터 소스를 추상화하고, 데이터를 다루는데 자주 사용되는 메서드들을 정의해 놓았다.
-> 추상화? : 데이터 소스가 무엇이던 간에 같은 방식으로 다룰 수 있게 되었다는 것과 코드의 재사용성이 높아진다는 것을 의미한다.
📖 16. 스트림의 특징


📖 17. 스트림 만들기 - 컬렉션 && 📖 18. 배열 && 📖 19. 임의의 수 && 📖 20. 특정 범위의 정수 && 📖 21. 람다식 iterate(), generate() && 📖 22. 파일과 빈 스트림



📖 26,27. 스트림의 중간연산 - skip(), limit(), filter(), distinct()

📖 28,29. 스트림의 중간연산 - sorted(), Comparator의 메서드
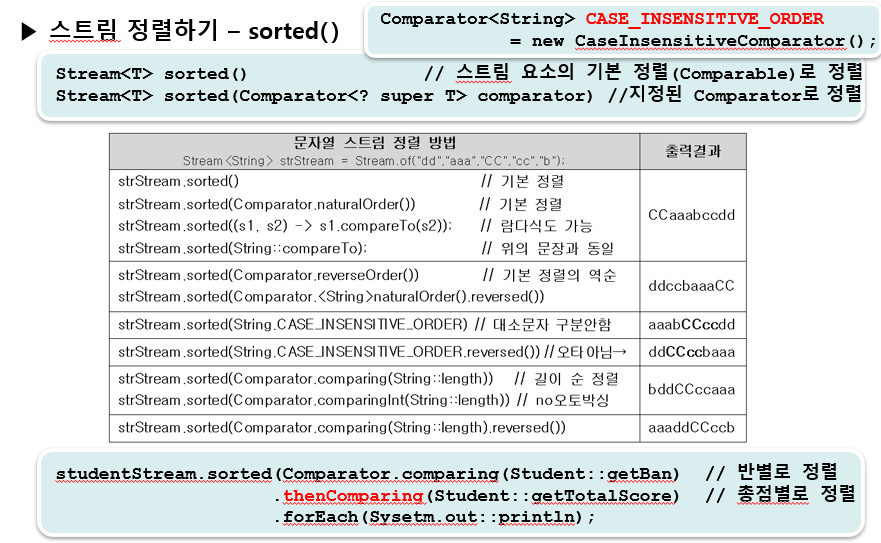
<예제 14-5 >
✍️ 입력
import java.util.*;
import java.util.stream.*;
class Ex14_5 {
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("이자바", 3, 300),
new Student("김자바", 1, 200),
new Student("안자바", 2, 100),
new Student("박자바", 2, 150),
new Student("소자바", 1, 200),
new Student("나자바", 3, 290),
new Student("감자바", 3, 180)
);
studentStream.sorted(Comparator.comparing(Student::getBan) // 반별 정렬
.thenComparing(Comparator.naturalOrder())) // 기본 정렬
.forEach(System.out::println);
}
}
class Student implements Comparable<Student> {
String name;
int ban;
int totalScore;
Student(String name, int ban, int totalScore) {
this.name =name;
this.ban =ban;
this.totalScore =totalScore;
}
public String toString() {
return String.format("[%s, %d, %d]", name, ban, totalScore);
}
String getName() { return name;}
int getBan() { return ban;}
int getTotalScore() { return totalScore;}
// 총점 내림차순을 기본 정렬로 한다.
public int compareTo(Student s) {
return s.totalScore - this.totalScore;
}
}💻 출력
[김자바, 1, 200]
[소자바, 1, 200]
[박자바, 2, 150]
[안자바, 2, 100]
[이자바, 3, 300]
[나자바, 3, 290]
[감자바, 3, 180]
- 스트림의 요소가 Comparable을 구현한 경우, 매개변수 하나짜리를 사용한다.
-> 그렇지 않다면, 매개변수로 정렬기준(Comparator)을 따로 지정해주어야 한다.
📖 30. 스트림의 중간연산 - map()
- map() : 스트림을 특정 형태로 변환해야 할 떄 사용한다.

📖 31. 스트림의 중간연산 - map() 예제
<예제 14-6 >
✍️ 입력
import java.io.*;
import java.util.stream.*;
class Ex14_6 {
public static void main(String[] args) {
File[] fileArr = { new File("Ex1.java"), new File("Ex1.bak"),
new File("Ex2.java"), new File("Ex1"), new File("Ex1.txt")
};
Stream<File> fileStream = Stream.of(fileArr);
// map()으로 Stream<File>을 Stream<String>으로 변환
Stream<String> filenameStream = fileStream.map(File::getName);
filenameStream.forEach(System.out::println); // 모든 파일의 이름을 출력
fileStream = Stream.of(fileArr); // 스트림을 다시 생성
fileStream.map(File::getName) // Stream<File> → Stream<String>
.filter(s -> s.indexOf('.')!=-1) // 확장자가 없는 것은 제외
.map(s -> s.substring(s.indexOf('.')+1)) // 확장자만 추출
.map(String::toUpperCase) // 모두 대문자로 변환
.distinct() // 중복 제거
.forEach(System.out::print); // JAVABAKTXT
System.out.println();
}
}💻 출력
Ex1.java
Ex1.bak
Ex2.java
Ex1
Ex1.txt
JAVABAKTXT
📖 32. 스트림의 중간연산 - peek()
- 스트림의 요소를 소모하지 않고 결과를 보고 싶을 때 사용한다.
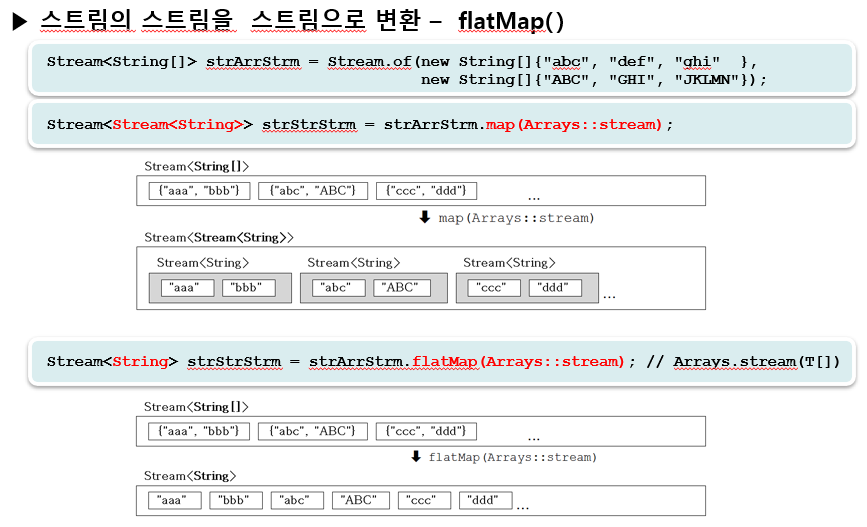
📖 34. 스트림의 중간연산 - flatMap()
<예제 14-7 >
✍️ 입력
import java.util.*;
import java.util.stream.*;
class Ex14_7 {
public static void main(String[] args) {
Stream<String[]> strArrStrm = Stream.of(
new String[]{"abc", "def", "jkl"},
new String[]{"ABC", "GHI", "JKL"}
);
// Stream<Stream<String>> strStrmStrm = strArrStrm.map(Arrays::stream);
Stream<String> strStrm = strArrStrm.flatMap(Arrays::stream);
strStrm.map(String::toLowerCase)
.distinct()
.sorted()
.forEach(System.out::println);
System.out.println();
String[] lineArr = {
"Believe or not It is true",
"Do or do not There is no try",
};
Stream<String> lineStream = Arrays.stream(lineArr);
lineStream.flatMap(line -> Stream.of(line.split(" +")))
.map(String::toLowerCase)
.distinct()
.sorted()
.forEach(System.out::println);
System.out.println();
}
}💻 출력
abc
def
ghi
jkl
believe
do
is
it
no
not
or
there
true
try
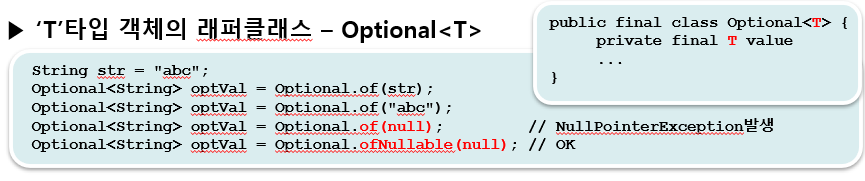
📖 35. Optional<T>
-
'T 타입의 객체'를 감싸는 래퍼 클래스이다.
-> 모든 타입의 객체를 담을 수 있다. -
최종 반환을 Optional객체에 담아서 반환하면, null인지 if문으로 체크하는 대신 Optional에 정의된 메서드를 통해 간단히 처리 할 수 있다.
-> null 체크를 위한 if문 없이도 NullPointerException이 발생하지 않고 보다 안전하게 코드를 작성 할 수 있다.
📖 36. Optional<T>객체 생성하기

- Optional<T>타입의 참조변수를 기본값으로 초기화 할 때는 empty()를 사용한다.
-> null로 초기화 가능하지만 바람직하지 않다.
📖 37. Optional<T>객체의 값 가져오기

📖 38. OptionalInt, OptionalLong, OptionalDouble

📖 39. Optional<T> 예제
<예제 14-8 >
✍️ 입력
import java.util.*;
class Ex14_8 {
public static void main(String[] args) {
Optional<String> optStr = Optional.of("abcde");
Optional<Integer> optInt = optStr.map(String::length);
System.out.println("optStr="+optStr.get());
System.out.println("optInt="+optInt.get());
int result1 = Optional.of("123")
.filter(x->x.length() >0)
.map(Integer::parseInt).get();
int result2 = Optional.of("")
.filter(x->x.length() >0)
.map(Integer::parseInt).orElse(-1);
System.out.println("result1="+result1);
System.out.println("result2="+result2);
Optional.of("456").map(Integer::parseInt)
.ifPresent(x->System.out.printf("result3=%d%n",x));
OptionalInt optInt1 = OptionalInt.of(0); // 0을 저장
OptionalInt optInt2 = OptionalInt.empty(); // 빈 객체를 생성
System.out.println(optInt1.isPresent()); // true
System.out.println(optInt2.isPresent()); // false
System.out.println(optInt1.getAsInt()); // 0
// System.out.println(optInt2.getAsInt()); // NoSuchElementException
System.out.println("optInt1="+optInt1);
System.out.println("optInt2="+optInt2);
System.out.println("optInt1.equals(optInt2)?"+optInt1.equals(optInt2));
}
}💻 출력
optStr=abcde
optInt=5
result1=123
result2=-1
result3=456
true
false
0
optInt1=OptionalInt[0]
optInt2=OptionalInt.empty
optInt1.equals(optInt2)?false
📖 40. 스트림의 최종연산 - forEach()

📖 41. 스트림의 최종연산 - 조건검사

📖 42,43. 스트림의 최종연산 - reduce(), reduce()의 이해

- for문과 같이 생각하면 쉽게 적용 할 수 있다.
-> 계산식(람다식)을 for문 아래에 넣는다고 생각하면 된다.
📖 44. 스트림의 최종연산 - reduce() 예제
<예제 14-9 >
✍️ 입력
import java.util.*;
import java.util.stream.*;
class Ex14_9 {
public static void main(String[] args) {
String[] strArr = {
"Inheritance", "Java", "Lambda", "stream",
"OptionalDouble", "IntStream", "count", "sum"
};
Stream.of(strArr).forEach(System.out::println);
boolean noEmptyStr = Stream.of(strArr).noneMatch(s->s.length()==0);
Optional<String> sWord = Stream.of(strArr)
.filter(s->s.charAt(0)=='s').findFirst();
System.out.println("noEmptyStr="+noEmptyStr);
System.out.println("sWord="+ sWord.get());
// Stream<String>을 IntStream으로 변환
IntStream intStream1 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream2 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream3 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream4 = Stream.of(strArr).mapToInt(String::length);
int count = intStream1.reduce(0, (a,b) -> a + 1);
int sum = intStream2.reduce(0, (a,b) -> a + b);
OptionalInt max = intStream3.reduce(Integer::max);
OptionalInt min = intStream4.reduce(Integer::min);
System.out.println("count="+count);
System.out.println("sum="+sum);
System.out.println("max="+ max.getAsInt());
System.out.println("min="+ min.getAsInt());
}
}
💻 출력
Inheritance
Java
Lambda
stream
OptionalDouble
IntStream
count
sum
noEmptyStr=true
sWord=stream
count=8
sum=58
max=14
min=3
📖 45. collect()와 Collectors

-> Collector 인터페이스는 1. 누적할 곳, 2. 누적방법을 포인트로 두고 생각하자.
📖 46. 스트림을 컬렉션, 배열로 변환

-
List나 Set이 아닌 특정 컬렉션을 지정하려면, toCollection()에 원하는 컬렉션의 생성자 참조를 매개변수로 넣어주면 된다.
-
배열로 변환
Student[] stuNames = stuedentStream.toArray(Student[]::new); // OK
Student[] stuNames = stuedentStream.toArray(); // 에러
Object[] stuNames = stuedentStream.toArray(); // OK📖 47. 스트림의 통계 - counting(), summingInt()
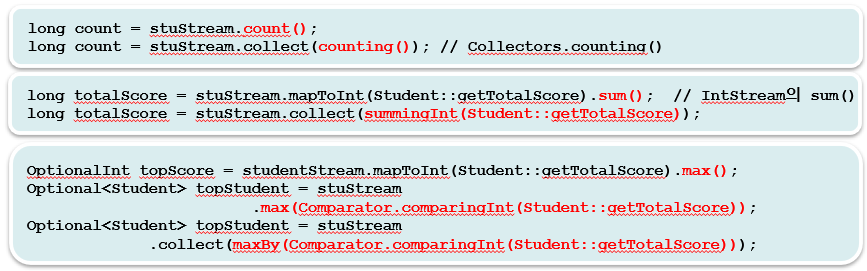
-> collect()를 사용하는 이유는 '그룹별'로 처리가 가능하기 때문이다.
📖 48. 스트림을 리듀싱 - reducing()

-> IntStream을 boxed()를 통해 Stream<Integer>로 변환해야 매개변수 1개짜리 collect()를 쓸 수 있다.
📖 49. 스트림을 문자열로 결합 - joining()

📖 50. 스트림의 그룹화와 분할
- 그룹화 : 스트림의 요소를 특정 기준으로 그룹화하는 것을 의미한다.
- groupingBy() : Function으로 그룹화 한다. (n개 그룹화)
- partioningBy() : predicate로 그룹화 한다. (2개 그룹화)
-> 그룹화와 분할의 결과는 Map에 담겨 반환한다.
📖 51. 스트림의 분할 - partitioningBy()

-> 4번째에서 value의 반환값이 Student이고 싶다면 maxBy(...) 대신 collectingAndThen(maxBy(comparingInt(Student::getScore)), Optional::get)을 사용하자
📖 52. 스트림의 분할 - partitioningBy() 예제
<예제 14-10 >
✍️ 입력
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
import static java.util.stream.Collectors.*;
import static java.util.Comparator.*;
class Student2 {
String name;
boolean isMale; // 성별
int hak; // 학년
int ban; // 반
int score;
Student2(String name, boolean isMale, int hak, int ban, int score) {
this.name = name;
this.isMale = isMale;
this.hak = hak;
this.ban = ban;
this.score = score;
}
String getName() { return name; }
boolean isMale() { return isMale; }
int getHak() { return hak; }
int getBan() { return ban; }
int getScore() { return score; }
public String toString() {
return String.format("[%s, %s, %d학년 %d반, %3d점]",
name, isMale ? "남":"여", hak, ban, score);
}
// groupingBy()에서 사용
enum Level { HIGH, MID, LOW } // 성적을 상, 중, 하 세 단계로 분류
}
class Ex14_10 {
public static void main(String[] args) {
Student2[] stuArr = {
new Student2("나자바", true, 1, 1, 300),
new Student2("김지미", false, 1, 1, 250),
new Student2("김자바", true, 1, 1, 200),
new Student2("이지미", false, 1, 2, 150),
new Student2("남자바", true, 1, 2, 100),
new Student2("안지미", false, 1, 2, 50),
new Student2("황지미", false, 1, 3, 100),
new Student2("강지미", false, 1, 3, 150),
new Student2("이자바", true, 1, 3, 200),
new Student2("나자바", true, 2, 1, 300),
new Student2("김지미", false, 2, 1, 250),
new Student2("김자바", true, 2, 1, 200),
new Student2("이지미", false, 2, 2, 150),
new Student2("남자바", true, 2, 2, 100),
new Student2("안지미", false, 2, 2, 50),
new Student2("황지미", false, 2, 3, 100),
new Student2("강지미", false, 2, 3, 150),
new Student2("이자바", true, 2, 3, 200)
};
System.out.printf("1. 단순분할(성별로 분할)%n");
Map<Boolean, List<Student2>> stuBySex = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale));
List<Student2> maleStudent = stuBySex.get(true);
List<Student2> femaleStudent = stuBySex.get(false);
for(Student2 s : maleStudent) System.out.println(s);
for(Student2 s : femaleStudent) System.out.println(s);
System.out.printf("%n2. 단순분할 + 통계(성별 학생수)%n");
Map<Boolean, Long> stuNumBySex = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale, counting()));
System.out.println("남학생 수 :"+ stuNumBySex.get(true));
System.out.println("여학생 수 :"+ stuNumBySex.get(false));
System.out.printf("%n3. 단순분할 + 통계(성별 1등)%n");
Map<Boolean, Optional<Student2>> topScoreBySex = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale,
maxBy(comparingInt(Student2::getScore))
));
System.out.println("남학생 1등 :"+ topScoreBySex.get(true));
System.out.println("여학생 1등 :"+ topScoreBySex.get(false));
Map<Boolean, Student2> topScoreBySex2 = Stream.of(stuArr)
.collect(partitioningBy(Student2::isMale,
collectingAndThen(
maxBy(comparingInt(Student2::getScore)), Optional::get
)
));
System.out.println("남학생 1등 :"+ topScoreBySex2.get(true));
System.out.println("여학생 1등 :"+ topScoreBySex2.get(false));
System.out.printf("%n4. 다중분할(성별 불합격자, 100점 이하)%n");
Map<Boolean, Map<Boolean, List<Student2>>> failedStuBySex =
Stream.of(stuArr).collect(partitioningBy(Student2::isMale,
partitioningBy(s -> s.getScore() <= 100))
);
List<Student2> failedMaleStu = failedStuBySex.get(true).get(true);
List<Student2> failedFemaleStu = failedStuBySex.get(false).get(true);
for(Student2 s : failedMaleStu) System.out.println(s);
for(Student2 s : failedFemaleStu) System.out.println(s);
}
}
💻 출력
1. 단순분할(성별로 분할)
[나자바, 남, 1학년 1반, 300점]
[김자바, 남, 1학년 1반, 200점]
[남자바, 남, 1학년 2반, 100점]
[이자바, 남, 1학년 3반, 200점]
[나자바, 남, 2학년 1반, 300점]
[김자바, 남, 2학년 1반, 200점]
[남자바, 남, 2학년 2반, 100점]
[이자바, 남, 2학년 3반, 200점]
[김지미, 여, 1학년 1반, 250점]
[이지미, 여, 1학년 2반, 150점]
[안지미, 여, 1학년 2반, 50점]
[황지미, 여, 1학년 3반, 100점]
[강지미, 여, 1학년 3반, 150점]
[김지미, 여, 2학년 1반, 250점]
[이지미, 여, 2학년 2반, 150점]
[안지미, 여, 2학년 2반, 50점]
[황지미, 여, 2학년 3반, 100점]
[강지미, 여, 2학년 3반, 150점]
2. 단순분할 + 통계(성별 학생수)
남학생 수 :8
여학생 수 :10
3. 단순분할 + 통계(성별 1등)
남학생 1등 :Optional[[나자바, 남, 1학년 1반, 300점]]
여학생 1등 :Optional[[김지미, 여, 1학년 1반, 250점]]
남학생 1등 :[나자바, 남, 1학년 1반, 300점]
여학생 1등 :[김지미, 여, 1학년 1반, 250점]
4. 다중분할(성별 불합격자, 100점 이하)
[남자바, 남, 1학년 2반, 100점]
[남자바, 남, 2학년 2반, 100점]
[안지미, 여, 1학년 2반, 50점]
[황지미, 여, 1학년 3반, 100점]
[안지미, 여, 2학년 2반, 50점]
[황지미, 여, 2학년 3반, 100점]
📖 53. 스트림의 그룹화 - groupingBy()

📖 54. 스트림의 그룹화 - groupingBy() 예제
<예제 14-11 >
✍️ 입력
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
import static java.util.stream.Collectors.*;
import static java.util.Comparator.*;
class Student3 {
String name;
boolean isMale; // 성별
int hak; // 학년
int ban; // 반
int score;
Student3(String name, boolean isMale, int hak, int ban, int score) {
this.name = name;
this.isMale = isMale;
this.hak = hak;
this.ban = ban;
this.score = score;
}
String getName() { return name; }
boolean isMale() { return isMale; }
int getHak() { return hak; }
int getBan() { return ban; }
int getScore() { return score; }
public String toString() {
return String.format("[%s, %s, %d학년 %d반, %3d점]", name, isMale ? "남" : "여", hak, ban, score);
}
enum Level {
HIGH, MID, LOW
}
}
class Ex14_11 {
public static void main(String[] args) {
Student3[] stuArr = {
new Student3("나자바", true, 1, 1, 300),
new Student3("김지미", false, 1, 1, 250),
new Student3("김자바", true, 1, 1, 200),
new Student3("이지미", false, 1, 2, 150),
new Student3("남자바", true, 1, 2, 100),
new Student3("안지미", false, 1, 2, 50),
new Student3("황지미", false, 1, 3, 100),
new Student3("강지미", false, 1, 3, 150),
// 뒷 페이지에 계속됩니다.
new Student3("이자바", true, 1, 3, 200),
new Student3("나자바", true, 2, 1, 300),
new Student3("김지미", false, 2, 1, 250),
new Student3("김자바", true, 2, 1, 200),
new Student3("이지미", false, 2, 2, 150),
new Student3("남자바", true, 2, 2, 100),
new Student3("안지미", false, 2, 2, 50),
new Student3("황지미", false, 2, 3, 100),
new Student3("강지미", false, 2, 3, 150),
new Student3("이자바", true, 2, 3, 200)
};
System.out.printf("1. 단순그룹화(반별로 그룹화)%n");
Map<Integer, List<Student3>> stuByBan = Stream.of(stuArr)
.collect(groupingBy(Student3::getBan));
for(List<Student3> ban : stuByBan.values()) {
for(Student3 s : ban) {
System.out.println(s);
}
}
System.out.printf("%n2. 단순그룹화(성적별로 그룹화)%n");
Map<Student3.Level, List<Student3>> stuByLevel = Stream.of(stuArr)
.collect(groupingBy(s-> {
if(s.getScore() >= 200) return Student3.Level.HIGH;
else if(s.getScore() >= 100) return Student3.Level.MID;
else return Student3.Level.LOW;
}));
TreeSet<Student3.Level> keySet = new TreeSet<>(stuByLevel.keySet());
for(Student3.Level key : keySet) {
System.out.println("["+key+"]");
for(Student3 s : stuByLevel.get(key))
System.out.println(s);
System.out.println();
}
System.out.printf("%n3. 단순그룹화 + 통계(성적별 학생수)%n");
Map<Student3.Level, Long> stuCntByLevel = Stream.of(stuArr)
.collect(groupingBy(s-> {
if(s.getScore() >= 200) return Student3.Level.HIGH;
else if(s.getScore() >= 100) return Student3.Level.MID;
else return Student3.Level.LOW;
}, counting()));
for(Student3.Level key : stuCntByLevel.keySet())
System.out.printf("[%s] - %d명, ", key, stuCntByLevel.get(key));
System.out.println();
/*
for(List<Student3> level : stuByLevel.values()) {
System.out.println();
for(Student3 s : level) {
System.out.println(s);
}
}
*/
System.out.printf("%n4. 다중그룹화(학년별, 반별)");
Map<Integer, Map<Integer, List<Student3>>> stuByHakAndBan =
Stream.of(stuArr)
.collect(groupingBy(Student3::getHak,
groupingBy(Student3::getBan)
));
for(Map<Integer, List<Student3>> hak : stuByHakAndBan.values()) {
for(List<Student3> ban : hak.values()) {
System.out.println();
for(Student3 s : ban)
System.out.println(s);
}
}
System.out.printf("%n5. 다중그룹화 + 통계(학년별, 반별 1등)%n");
Map<Integer, Map<Integer, Student3>> topStuByHakAndBan =
Stream.of(stuArr)
.collect(groupingBy(Student3::getHak,
groupingBy(Student3::getBan,
collectingAndThen(
maxBy(comparingInt(Student3::getScore))
, Optional::get
)
)
));
for(Map<Integer, Student3> ban : topStuByHakAndBan.values())
for(Student3 s : ban.values())
System.out.println(s);
// 뒷 페이지에 계속됩니다.
System.out.printf("%n6. 다중그룹화 + 통계(학년별, 반별 성적그룹)%n");
Map<String, Set<Student3.Level>> stuByScoreGroup = Stream.of(stuArr)
.collect(groupingBy(s-> s.getHak() + "-" + s.getBan(),
mapping(s-> {
if(s.getScore() >= 200) return Student3.Level.HIGH;
else if(s.getScore() >= 100) return Student3.Level.MID;
else return Student3.Level.LOW;
} , toSet())
));
Set<String> keySet2 = stuByScoreGroup.keySet();
for(String key : keySet2) {
System.out.println("["+key+"]" + stuByScoreGroup.get(key));
}
} // main의 끝
}💻 출력
1. 단순그룹화(반별로 그룹화)
[나자바, 남, 1학년 1반, 300점]
[김지미, 여, 1학년 1반, 250점]
[김자바, 남, 1학년 1반, 200점]
[나자바, 남, 2학년 1반, 300점]
[김지미, 여, 2학년 1반, 250점]
[김자바, 남, 2학년 1반, 200점]
[이지미, 여, 1학년 2반, 150점]
[남자바, 남, 1학년 2반, 100점]
[안지미, 여, 1학년 2반, 50점]
[이지미, 여, 2학년 2반, 150점]
[남자바, 남, 2학년 2반, 100점]
[안지미, 여, 2학년 2반, 50점]
[황지미, 여, 1학년 3반, 100점]
[강지미, 여, 1학년 3반, 150점]
[이자바, 남, 1학년 3반, 200점]
[황지미, 여, 2학년 3반, 100점]
[강지미, 여, 2학년 3반, 150점]
[이자바, 남, 2학년 3반, 200점]
2. 단순그룹화(성적별로 그룹화)
[HIGH]
[나자바, 남, 1학년 1반, 300점]
[김지미, 여, 1학년 1반, 250점]
[김자바, 남, 1학년 1반, 200점]
[이자바, 남, 1학년 3반, 200점]
[나자바, 남, 2학년 1반, 300점]
[김지미, 여, 2학년 1반, 250점]
[김자바, 남, 2학년 1반, 200점]
[이자바, 남, 2학년 3반, 200점]
[MID]
[이지미, 여, 1학년 2반, 150점]
[남자바, 남, 1학년 2반, 100점]
[황지미, 여, 1학년 3반, 100점]
[강지미, 여, 1학년 3반, 150점]
[이지미, 여, 2학년 2반, 150점]
[남자바, 남, 2학년 2반, 100점]
[황지미, 여, 2학년 3반, 100점]
[강지미, 여, 2학년 3반, 150점]
[LOW]
[안지미, 여, 1학년 2반, 50점]
[안지미, 여, 2학년 2반, 50점]
3. 단순그룹화 + 통계(성적별 학생수)
[HIGH] - 8명, [MID] - 8명, [LOW] - 2명,
4. 다중그룹화(학년별, 반별)
[나자바, 남, 1학년 1반, 300점]
[김지미, 여, 1학년 1반, 250점]
[김자바, 남, 1학년 1반, 200점]
[이지미, 여, 1학년 2반, 150점]
[남자바, 남, 1학년 2반, 100점]
[안지미, 여, 1학년 2반, 50점]
[황지미, 여, 1학년 3반, 100점]
[강지미, 여, 1학년 3반, 150점]
[이자바, 남, 1학년 3반, 200점]
[나자바, 남, 2학년 1반, 300점]
[김지미, 여, 2학년 1반, 250점]
[김자바, 남, 2학년 1반, 200점]
[이지미, 여, 2학년 2반, 150점]
[남자바, 남, 2학년 2반, 100점]
[안지미, 여, 2학년 2반, 50점]
[황지미, 여, 2학년 3반, 100점]
[강지미, 여, 2학년 3반, 150점]
[이자바, 남, 2학년 3반, 200점]
5. 다중그룹화 + 통계(학년별, 반별 1등)
[나자바, 남, 1학년 1반, 300점]
[이지미, 여, 1학년 2반, 150점]
[이자바, 남, 1학년 3반, 200점]
[나자바, 남, 2학년 1반, 300점]
[이지미, 여, 2학년 2반, 150점]
[이자바, 남, 2학년 3반, 200점]
6. 다중그룹화 + 통계(학년별, 반별 성적그룹)
[1-1][HIGH]
[2-1][HIGH]
[1-2][MID, LOW]
[2-2][MID, LOW]
[1-3][HIGH, MID]
[2-3][HIGH, MID]
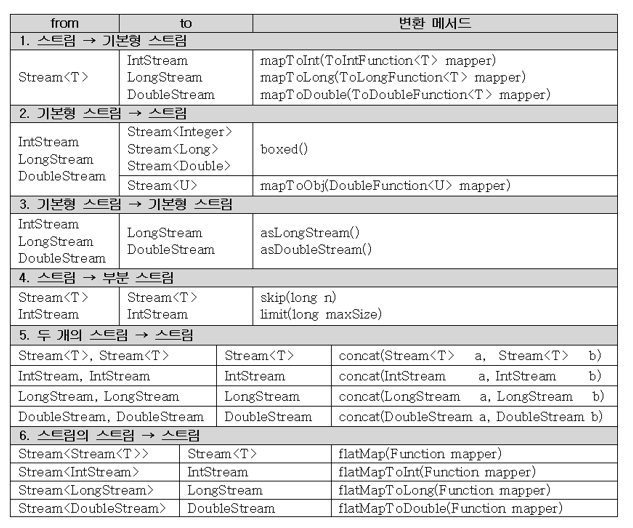
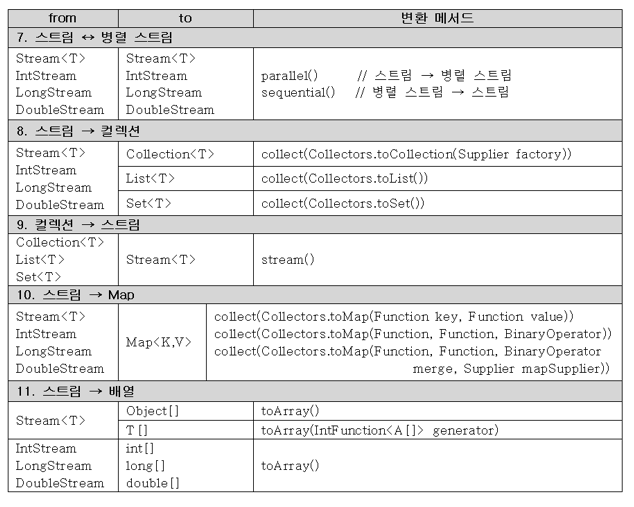
📖 55. 스트림의 변환
[출처] 자바의 정석 <기초편> (남궁 성 지음)
